Meta AI の Segment Anything Model(SAM) でUSBカメラの映像からオブジェクトを抽出してみました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
1 はじめに
CX 事業本部のdelivery部の平内(SIN)です。
Segment Anything Model(SAM)とは、Meta社が公開した、セグメンテーションのための汎用モデルで、ファインチューニングなしで、あらゆる物体がセグメンテーションできます。

今回は、こちらを使用させて頂いて、USBカメラの画像から、画面中央に写っているものを抽出してみました。
最初に、作業している様子です。画面の枠内にあって、かつ、中心点にある物体が抽出されています。
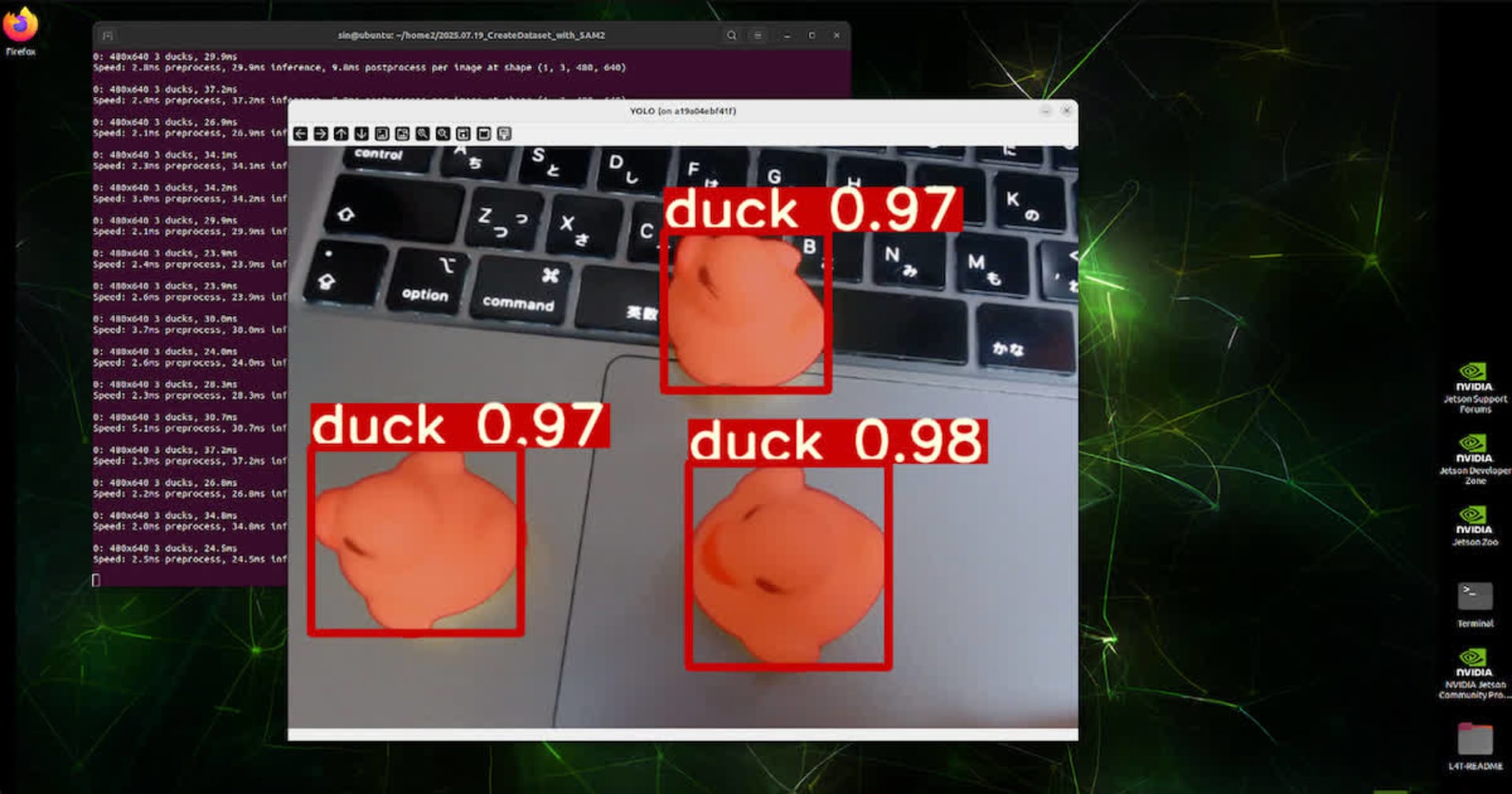
実は、この方法でオブジェクトの背景が消せれば、物体検出モデルのデータセットが簡単に作れるのでは?という魂胆です。
下記のブログでは、グリーンバックで撮影した動画をクロマキー処理してデータセットを作っていますが、この背景準備が必要なくなるのでは?というイメージです。また、背景を用意しなくても良くなると、野外のオブジェクトなど、なんでもデータセットの対象にできるのでは?とも妄想しています。
2 プロンプト
Segment Anything Model(SAM) では、次の2種類の検出方法が提供されています。
- Automatically generating object
- Object masks from prompts
(1) Automatically generating object
自動で画面全体をセグメンテーションしてくれます。
mask_generator = SamAutomaticMaskGenerator(sam) masks = mask_generator.generate(image)
こちらのNotebook「Automatically generating object masks with SAM」でサンプルが紹介されています。

(2) Object masks from prompts
「対象ポイント」、「非対象ポイント」及び、「矩形」による指定と、その組み合わせが利用可能です。
predictor = SamPredictor(sam)
predictor.set_image(image)
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True,
)
こちらのNotebook「Object masks from prompts with SAM」でサンプルが紹介されています。

なお、今回は、(2)の方法を使用しています。画面の中心に位置するオブジェクトを対象とし、かつ、画面の一定枠内に収まるものを組み合わせることで、1つのオブジェクトと認識できるようにしてみました。

3 コード
predictor.predict() で取得できるmaskは、2次元のbool値となっており、コード内では、この真偽値を使用して、検出オブジェクト以外を黒で塗りつぶしています。
shape:(480, 640) type:<class 'numpy.ndarray'> dtype:bool ndim:2
ちなみに、NVIDIA Jetson AGX Orin上のDockerイメージ(l4t-pytorch:r35.2.1-pth2.0-py3)で作業していますが、1フレームの処理に2秒程度かかっています。
import datetime
import numpy as np
import torch
import cv2
from segment_anything import sam_model_registry, SamPredictor
print("PyTorch version:", torch.__version__)
print("CUDA is available:", torch.cuda.is_available())
##################################
# ガイドの表示
##################################
def disp_guide(frame, width, height, input_box):
color = (200, 200, 0)
cv2.rectangle(
frame,
pt1=(input_box[0], input_box[1]),
pt2=(input_box[2], input_box[3]),
color=color,
thickness=2,
)
cv2.line(
frame,
pt1=(0, int(height / 2)),
pt2=(width, int(height / 2)),
color=color,
)
cv2.line(
frame,
pt1=(int(width / 2), 0),
pt2=(int(width / 2), height),
color=color,
)
##################################
# Segment Anything の初期化
##################################
print("initialize SAM")
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
##################################
# Video の初期化
##################################
cap = cv2.VideoCapture(0)
if cap.isOpened() is False:
raise IOError
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
_, frame = cap.read()
h, w, _ = frame.shape
##################################
# オグジェクトを検出するポインタ
##################################
# 画面全体より少し小さい枠
margin = 50
input_box = np.array([margin, margin, w - margin, h - margin])
# 画面の中央
input_point = np.array([[int(w / 2), int(h / 2)]])
input_label = np.array([1])
print("start.")
while True:
try:
ret, frame = cap.read()
if ret is False:
raise IOError
# 検出
predictor.set_image(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
box=input_box,
multimask_output=False,
)
print("{} predicted.".format(datetime.datetime.now()))
# masks.length:1 masks[0].shape:(480, 640)
print("masks.length:{} masks[0].shape:{}".format(len(masks), masks[0].shape))
# mask.shape:(480, 640) type:<class 'numpy.ndarray'> dtype:bool ndim:2
mask = masks[0]
print(
"mask.shape:{} type:{} dtype:{} ndim:{}".format(
mask.shape, type(mask), mask.dtype, mask.ndim
)
)
m = np.copy(frame)
for _h in range(h):
for _w in range(w):
if mask[_h][_w] == False:
m[_h][_w] = 0
disp_guide(frame, w, h, input_box)
cv2.imshow("Frame", frame)
cv2.imshow("Mask", m)
cv2.waitKey(1)
except KeyboardInterrupt:
break
4 最後に
今回は、Segment Anything Model(SAM) を使用して、動画からオブジェクトを切り出してみました。
最初に書いた通り、今回の作業の目的は「物体検出モデル用のデータセット作成」です。これまで、セグメンテーションなんて、データセット作成の作業量が膨大で、とても個人で作業できるものではないと感じていましたが、Meta社によって、気軽に利用できるものになってしまったという印象です。