
k6 で REST API に負荷テストを実行してみた(段階的負荷テスト・スパイクテスト・耐久テスト)
製造ビジネステクノロジー部の小林です。
前回の記事では、AWS CDK を使って k6 の実行環境を構築しました。今回は REST API エンドポイントに対して、さまざまなパターンの負荷テストを実行してみます。
今回実施する負荷テストのパターン
k6 では options の設定を変えることで様々な負荷パターンを実現できます。今回は以下の 3 パターンを試してみます。
| パターン | 説明 | 所要時間 | ユースケース |
|---|---|---|---|
| Ramping(段階的負荷) | 負荷を徐々に上げていく | 5 分 | システムの限界点を探る |
| Spike(スパイク) | 一気に負荷をかける | 5 分 | 突発的なアクセス増加への耐性確認 |
| Soak(持続テスト) | 一定負荷を長時間維持 | 15 分 | メモリリークや性能劣化を検出 |
前提条件
- 前回構築した k6 実行環境(Graviton EC2)
- テスト対象:REST API(API Gateway + Lambda)
- Lambda のタイムアウト:30 秒
テスト対象の API エンドポイント
今回テストする API は、シンプルな CRUD 操作を提供しています。
Base URL: https://XXXXXXXX.execute-api.ap-northeast-1.amazonaws.com/v1
| メソッド | エンドポイント | 説明 |
|---|---|---|
| GET | /items |
全アイテム取得 |
| POST | /items |
アイテム作成 |
| GET | /items/{id} |
個別アイテム取得 |
| PUT | /items/{id} |
アイテム更新 |
| DELETE | /items/{id} |
アイテム削除 |
テストスクリプトの実装
k6 では options.stages 配列を使って仮想ユーザー数(VU)の変化パターンを定義します。各 stage は duration(期間)と target(目標 VU 数)を指定し、k6 はその期間をかけて現在の VU 数から目標 VU 数へ線形に変化させます。
共通部分:API リクエスト関数
まず、各 API エンドポイントへのリクエストを関数化します。
import http from 'k6/http';
import { check, sleep } from 'k6';
import { Rate, Trend } from 'k6/metrics';
// 環境変数から BASE_URL を取得(未設定時はローカル環境をデフォルトに)
const BASE_URL = __ENV.BASE_URL || 'http://localhost:3000';
// カスタムメトリクス
const errorRate = new Rate('errors');
const itemCreationTrend = new Trend('item_creation_duration');
// 共通ヘッダー
const headers = {
'Content-Type': 'application/json',
};
// 全アイテム取得
export function getAllItems() {
const res = http.get(`${BASE_URL}/items`);
check(res, {
'GET /items - status is 200': (r) => r.status === 200,
});
errorRate.add(res.status !== 200);
return res;
}
// アイテム作成
export function createItem(name: string, description: string) {
const payload = JSON.stringify({ name, description });
const res = http.post(`${BASE_URL}/items`, payload, { headers });
check(res, {
'POST /items - status is 200 or 201': (r) => r.status === 200 || r.status === 201,
});
errorRate.add(res.status !== 200 && res.status !== 201);
itemCreationTrend.add(res.timings.duration);
return res;
}
// 個別アイテム取得
export function getItem(id: string) {
const res = http.get(`${BASE_URL}/items/${id}`);
check(res, {
'GET /items/{id} - status is 200': (r) => r.status === 200,
});
errorRate.add(res.status !== 200);
return res;
}
// アイテム更新
export function updateItem(id: string, name: string, description: string) {
const payload = JSON.stringify({ name, description });
const res = http.put(`${BASE_URL}/items/${id}`, payload, { headers });
check(res, {
'PUT /items/{id} - status is 200': (r) => r.status === 200,
});
errorRate.add(res.status !== 200);
return res;
}
// アイテム削除
export function deleteItem(id: string) {
const res = http.del(`${BASE_URL}/items/${id}`);
check(res, {
'DELETE /items/{id} - status is 200 or 204': (r) => r.status === 200 || r.status === 204,
});
errorRate.add(res.status !== 200 && res.status !== 204);
return res;
}
Ramping(段階的負荷テスト)
負荷を徐々に上げていき、システムがどの程度のリクエストまで耐えられるかを確認します。
import http from 'k6/http';
import { check, sleep } from 'k6';
import { Rate } from 'k6/metrics';
// 環境変数から BASE_URL を取得
const BASE_URL = __ENV.BASE_URL || 'http://localhost:3000';
const errorRate = new Rate('errors');
export const options = {
stages: [
{ duration: '1m', target: 20 }, // 1分かけて20VUまで増加
{ duration: '1m', target: 50 }, // 1分かけて50VUまで増加
{ duration: '1m', target: 100 }, // 1分かけて100VUまで増加
{ duration: '1m', target: 100 }, // 1分間100VUを維持
{ duration: '1m', target: 0 }, // 1分かけて0VUまで減少
],
thresholds: {
http_req_duration: ['p(95)<500'],
errors: ['rate<0.1'],
},
};
export default function () {
const res = http.get(`${BASE_URL}/items`);
check(res, {
'status is 200': (r) => r.status === 200,
});
errorRate.add(res.status !== 200);
sleep(1);
}
ポイント
- 段階的に負荷を増加 : 各ステージで VU 数を徐々に引き上げることで、システムがどの負荷レベルまで耐えられるかを確認できます。
- 維持フェーズ(ステージ 4): 最大負荷に達した後、一定時間維持することで、その負荷での安定性を確認します。
- 緩やかな終了(ステージ 5): 急に負荷を落とすのではなく、徐々に減少させることで、システムの回復挙動も観察できます。
- thresholds の設定: p95 < 500ms という目標を設定し、これを超えるとテストが失敗と判定されます。
負荷の推移イメージ
VUs
100 | ┌────────┐
| / \
50 | ┌───┘ \
| / \
20 | ┌───┘ \
0 |──┘ \───
0 1 2 3 4 5 (分)
Spike(スパイクテスト)
突発的に大量のリクエストが来た場合のシステムの挙動を確認します。
import http from 'k6/http';
import { check, sleep } from 'k6';
import { Rate } from 'k6/metrics';
// 環境変数から BASE_URL を取得
const BASE_URL = __ENV.BASE_URL || 'http://localhost:3000';
const errorRate = new Rate('errors');
export const options = {
stages: [
{ duration: '30s', target: 10 }, // ウォームアップ
{ duration: '30s', target: 200 }, // 30秒で一気に200VUまで急増
{ duration: '1m', target: 200 }, // 1分間200VUを維持
{ duration: '30s', target: 10 }, // 30秒で10VUまで急減
{ duration: '1m30s', target: 10 }, // 1分30秒間安定確認
{ duration: '1m', target: 0 }, // クールダウン
],
thresholds: {
http_req_duration: ['p(95)<500'],
errors: ['rate<0.2'],
},
};
export default function () {
const res = http.get(`${BASE_URL}/items`);
check(res, {
'status is 200': (r) => r.status === 200,
});
errorRate.add(res.status !== 200);
sleep(1);
}
ポイント
- ウォームアップ(ステージ 1): いきなり高負荷をかけるのではなく、まず低負荷で API の準備状態を整えます。
- 急激なスパイク(ステージ 2): わずか 30 秒で 10 → 200 VU へ 20 倍 の負荷増加。ここがスパイクテストの核心です。
- スパイク維持(ステージ 3): 高負荷状態を 1 分間維持し、システムがスパイクに耐えられるかを確認します。
- 急激な減少(ステージ 4): 負荷が急減した際にシステムが正常に回復するかを確認します。
- 安定確認(ステージ 5): スパイク後に低負荷で正常動作するかを確認。メモリリークや状態異常がないかを検証します。
負荷の推移イメージ
VUs
200 | ┌──────────┐
| / \
| / \
| / \
10 |──┘ └──────────────
0 |_____________________________________
0 0.5 1 2 2.5 4 5 (分)
Soak(耐久テスト)- 15 分
一定の負荷を長時間かけ続け、メモリリークや性能劣化の有無を検証します。
import http from 'k6/http';
import { check, sleep } from 'k6';
import { Rate } from 'k6/metrics';
// 環境変数から BASE_URL を取得
const BASE_URL = __ENV.BASE_URL || 'http://localhost:3000';
const errorRate = new Rate('errors');
const headers = {
'Content-Type': 'application/json',
};
export const options = {
stages: [
{ duration: '1m', target: 30 }, // 1分かけて30VUまで増加
{ duration: '13m', target: 30 }, // 13分間30VUを維持
{ duration: '1m', target: 0 }, // 1分かけて終了
],
thresholds: {
http_req_duration: ['p(95)<500', 'p(99)<1000'],
errors: ['rate<0.05'],
},
};
export default function () {
// 全アイテム取得
const listRes = http.get(`${BASE_URL}/items`);
check(listRes, { 'GET /items - status is 200': (r) => r.status === 200 });
errorRate.add(listRes.status !== 200);
sleep(1);
// アイテム作成
const payload = JSON.stringify({
name: `SoakTest-${Date.now()}`,
description: 'Created during soak test',
});
const createRes = http.post(`${BASE_URL}/items`, payload, { headers });
check(createRes, { 'POST /items - status is 200': (r) => r.status === 200 });
errorRate.add(createRes.status !== 200);
// 作成したアイテムを削除
if (createRes.status === 200) {
const body = JSON.parse(createRes.body as string);
if (body.id) {
sleep(1);
const deleteRes = http.del(`${BASE_URL}/items/${body.id}`);
check(deleteRes, { 'DELETE /items/{id} - status is 200': (r) => r.status === 200 });
errorRate.add(deleteRes.status !== 200);
}
}
sleep(1);
}
ポイント
- 長時間の一定負荷(ステージ 2): 13 分間同じ負荷を維持することで、時間経過による性能劣化を検出します。
- 複合的なシナリオ: 単純な GET だけでなく、GET → POST → DELETE という一連の CRUD 操作を実行。これにより、データベースへの書き込み負荷、メモリ使用量の変化、コネクションの増減 などを長時間観察できます。
負荷の推移イメージ
VUs
30 | ┌─────────────────────────────────────────────┐
| / \
|/ \
0 |___________________________________________________
0 1 14 15 (分)
テストの実行
実行環境
今回テストを実行する環境は以下のとおりです。
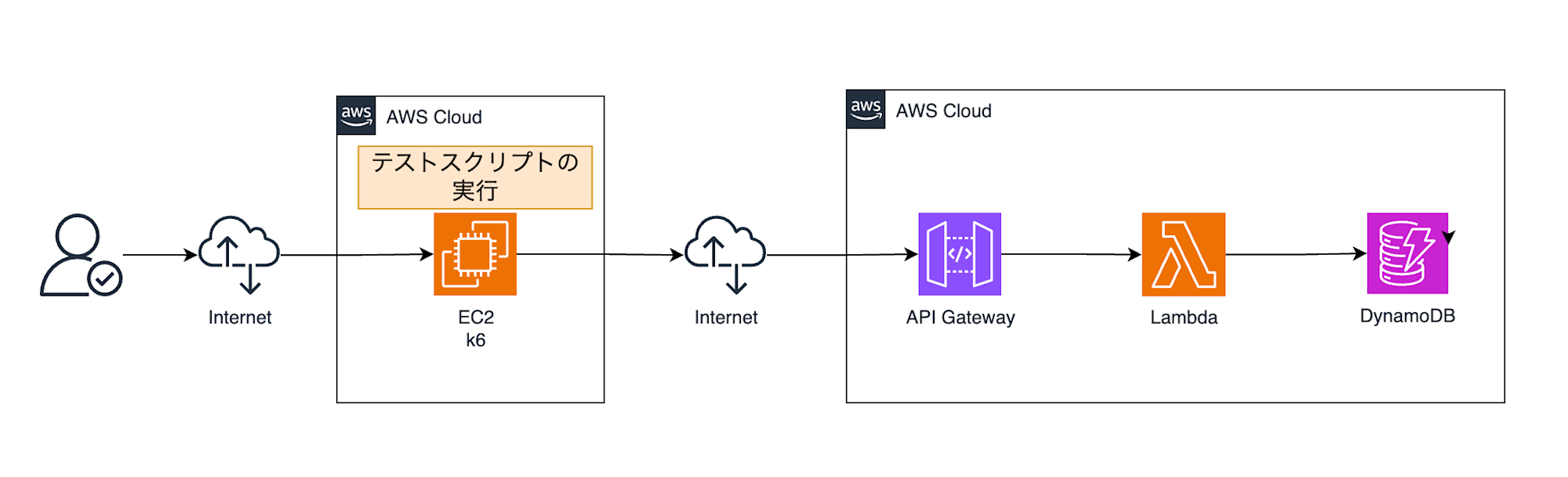
EC2 Instance Connect でインスタンスに接続し、テストを実行していきます。
ビルド
$ npm run build
> k6-project@1.0.0 build
> esbuild *.ts --bundle --target=es2015 --platform=node --outdir=dist --external:k6 --external:k6/*
dist/api-test.js 3.7kb
dist/soak-test.js 3.2kb
dist/spike-test.js 2.6kb
dist/ramping-test.js 2.6kb
⚡ Done in 4ms
各テストの実行
# 環境変数を設定してからテストを実行
$ export BASE_URL=https://XXXXXXXXXX.execute-api.ap-northeast-1.amazonaws.com/v1
# 段階的負荷テスト(約5分)
$ k6 run dist/ramping-test.js
# スパイクテスト(約5分)
$ k6 run dist/spike-test.js
# 持続テスト(15分)
$ k6 run dist/soak-test.js
結果をファイルに出力する場合
$ k6 run --out json=results.json dist/ramping-test.js
実行結果
Ramping(段階的負荷) テストの結果
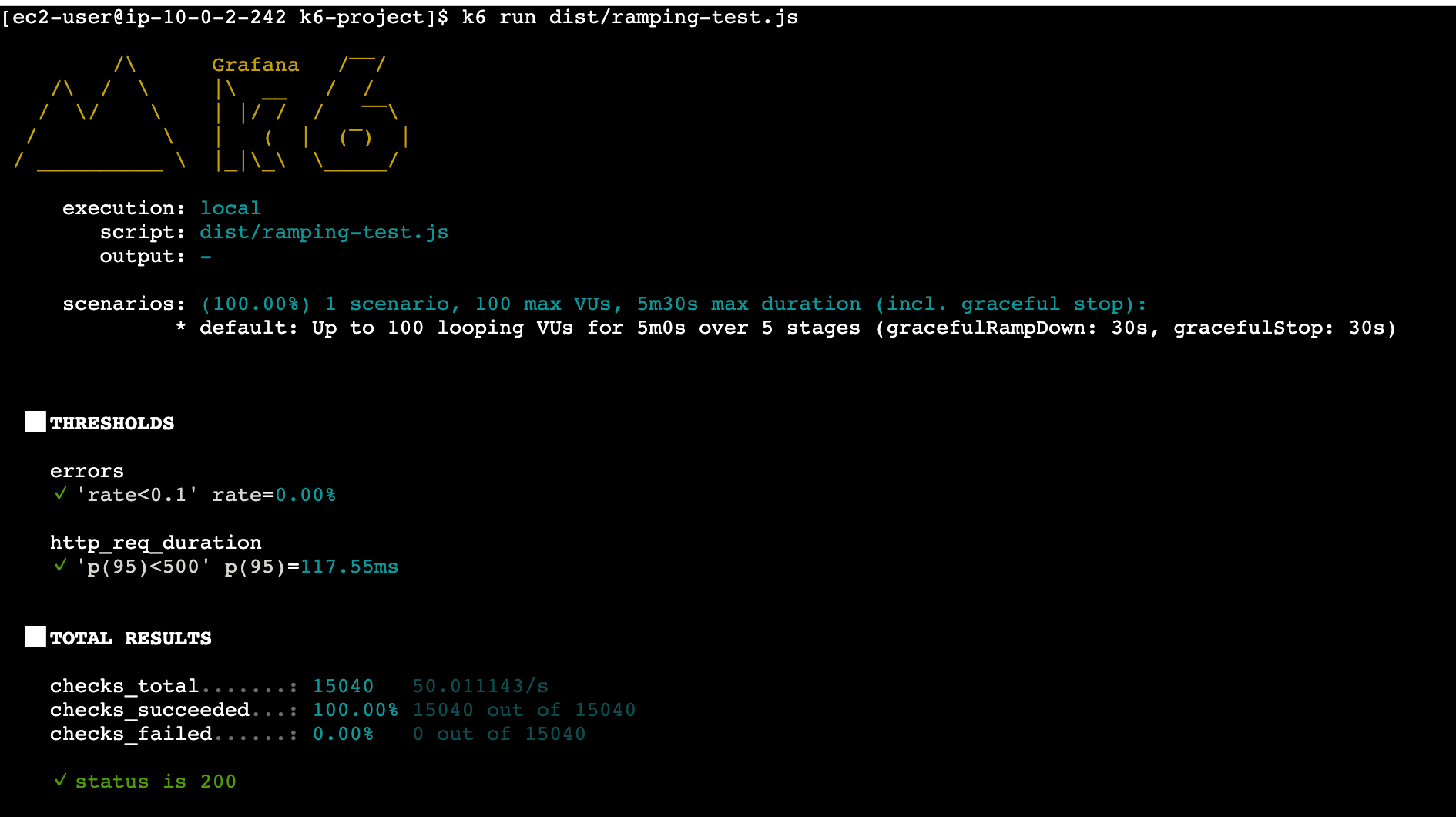
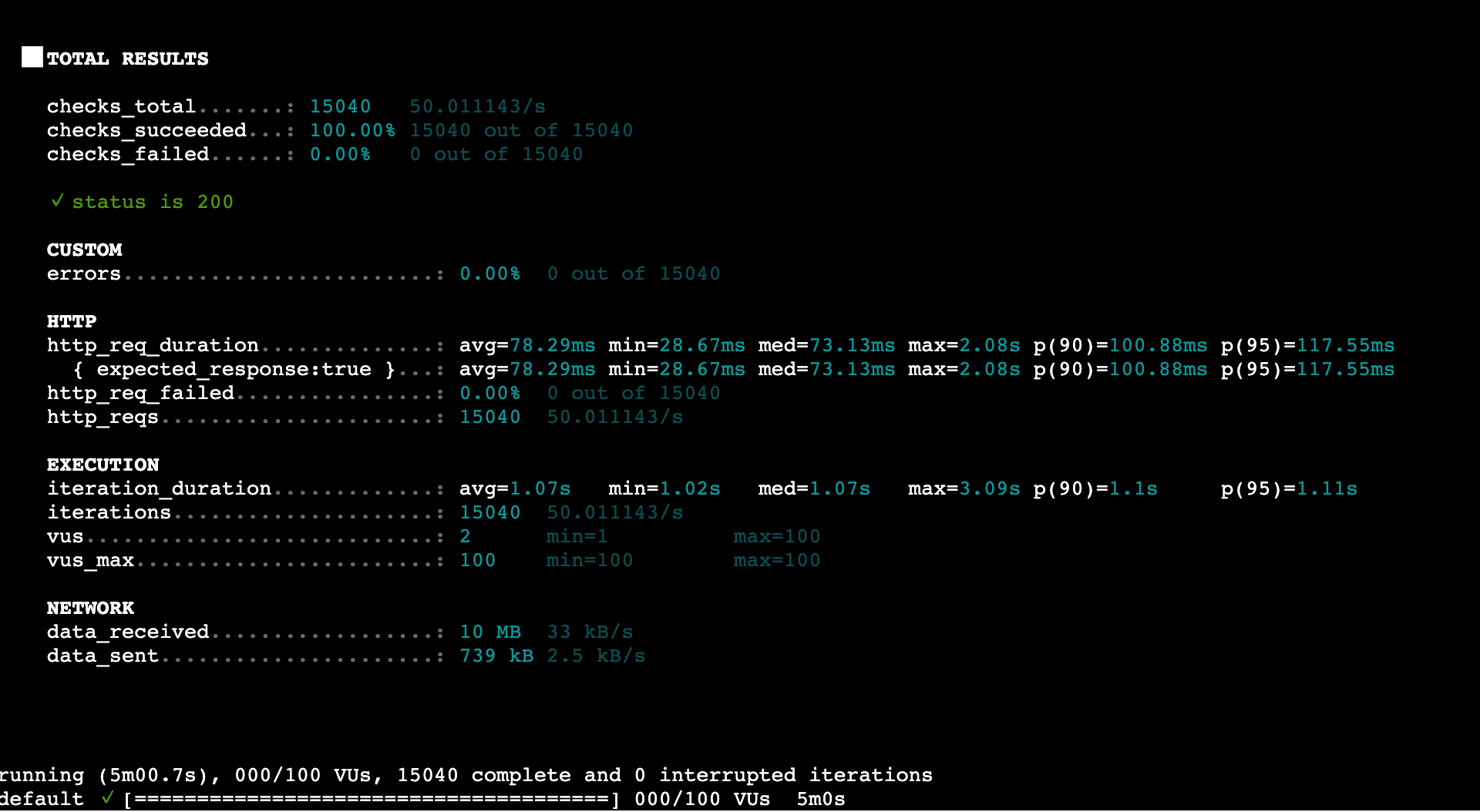
結果サマリー
| メトリクス | 値 |
|---|---|
| 総リクエスト数 | 15,040(約 50 リクエスト/秒) |
| 平均応答時間 | 78.29ms |
| p95 応答時間 | 117.55ms |
| 最大応答時間 | 2.08s |
| エラー率 | 0.00% |
分析
本来、Ramping テストはシステムの限界点を探るために、エラーが発生するまで負荷を上げ続けるのが一般的です。しかし今回は、k6 の使い方と AWS のモニタリング機能の紹介を主な目的としているため、システムが破綻するまでの限界テストは行いませんでした。
代わりに、100 VU の負荷をかけた状態で、CloudWatch メトリクス、Lambda Insights、X-Ray を使ったボトルネックの特定方法を紹介します。
良かった点
- エラー率 0%、全 15,040 リクエストが成功
- p95 応答時間 117.55ms で、目標の 500ms を大きく下回る
- 100 VU 到達時もスロットリングやエラーは発生せず、安定して処理できた
気になる点
- 最大応答時間が 2.08s と、一部のリクエストで遅延が発生
- メモリ使用率が 84% と高め
ボトルネックの調査
AWS コンソールから Lambda のメトリクスと X-Ray トレースを確認し、遅延の原因を調査しました。
Lambda メトリクス
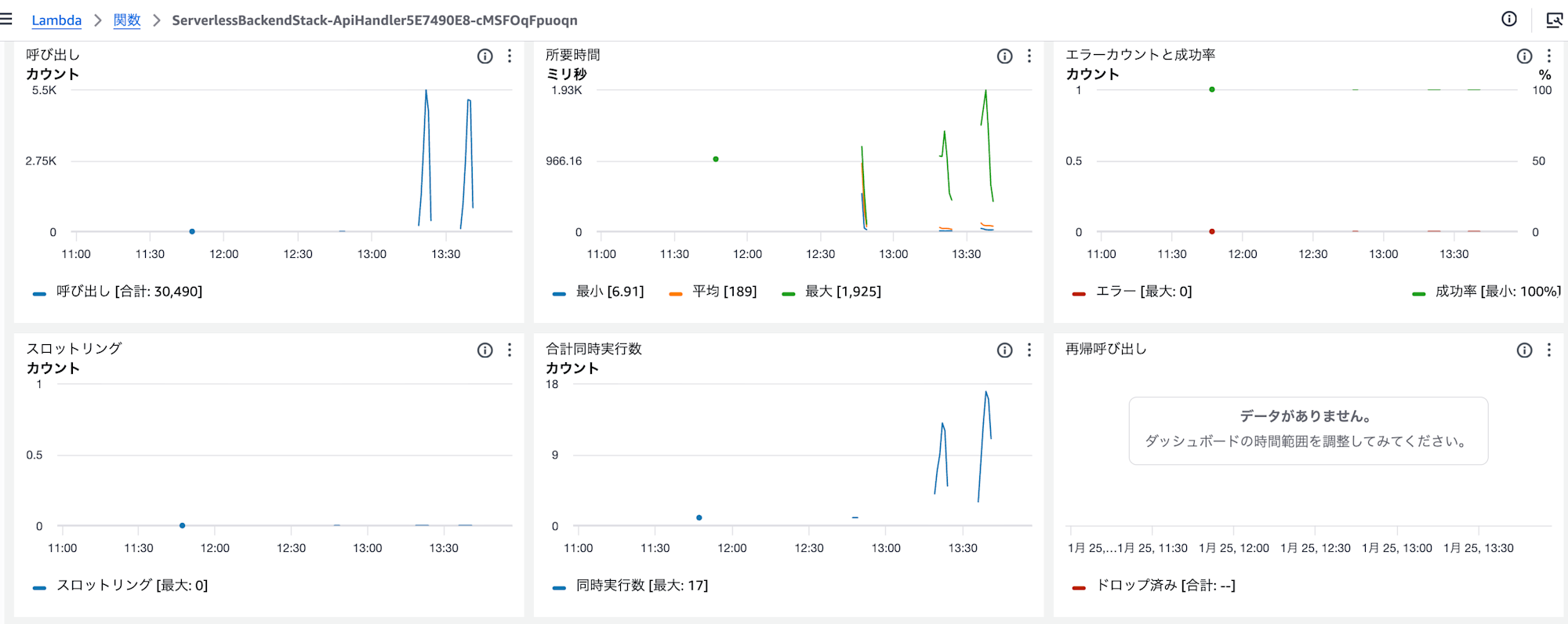
| メトリクス | 値 |
|---|---|
| 呼び出し回数 | 30,486 |
| 平均所要時間 | 79.77ms |
| 最大所要時間 | 1,925ms |
| 最大同時実行数 | 17 |
| スロットリング | 0 |
| エラー | 0 |
スロットリングやエラーは発生しておらず、Lambda 側での制限は問題ありませんでした。
Lambda Insights メトリクス
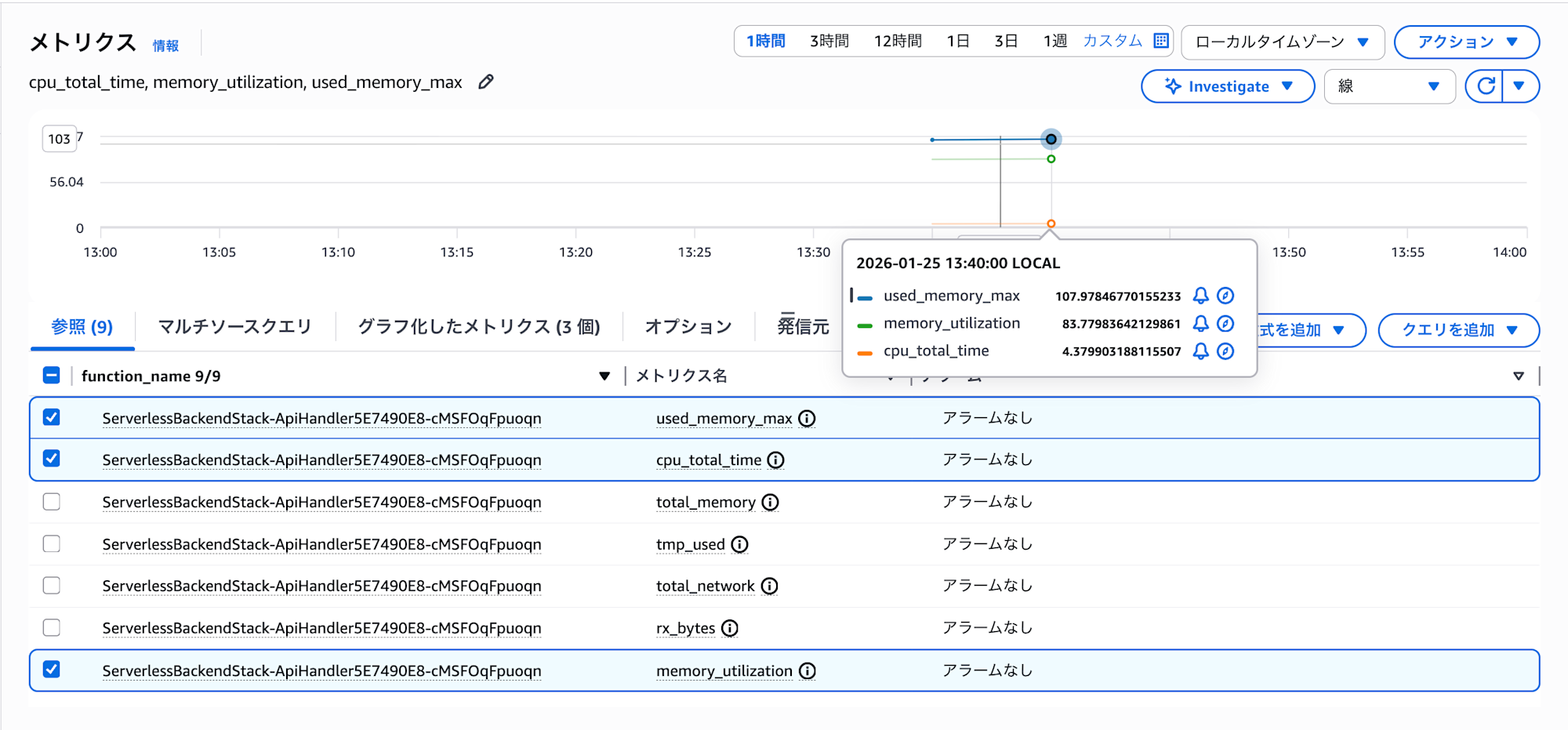
メモリ使用率は 84% と比較的高く、リソースの余裕が限定的な状態でした。一方、CPU 使用時間は低い水準に留まっており、CPU がボトルネックになっている可能性は低いと判断されます。
X-Ray トレースによる遅延分析
最も遅延が大きかったリクエストの内訳を X-Ray で確認しました。
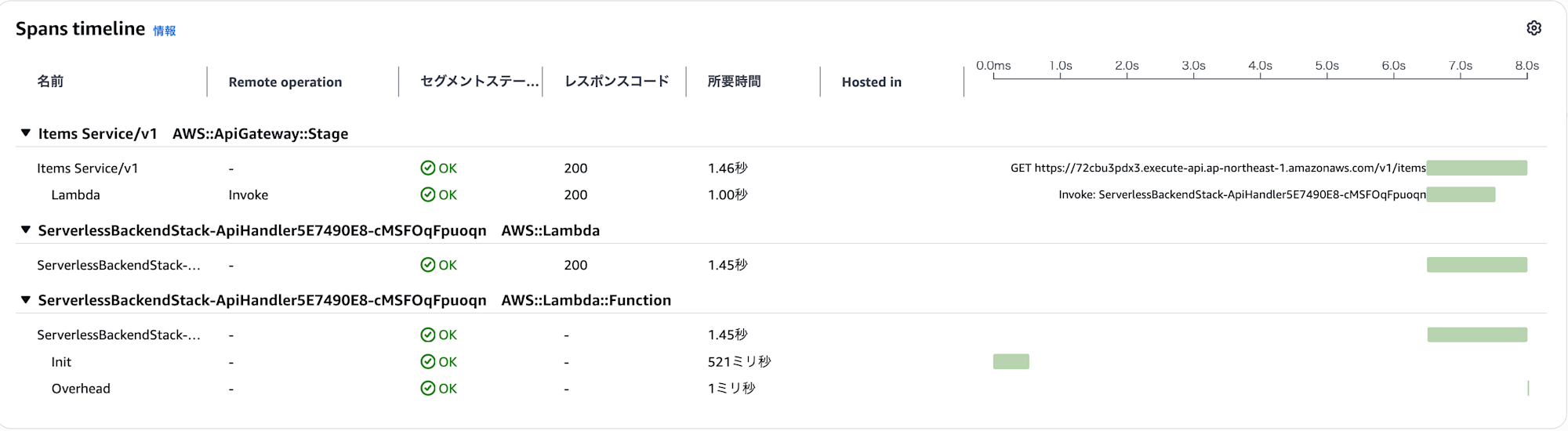
| 処理 | 所要時間 |
|---|---|
| API Gateway 全体 | 1.46s |
| Lambda Invoke | 1.00s |
| Lambda Init(コールドスタート) | 521ms |
| Overhead | 1ms |
分析の結果、遅延の主な原因は Lambda のコールドスタートであることが判明しました。具体的には以下の通りです。
- Lambda 初期化処理(Init)に 521ms を要している。
- 通常の応答時間(約 70 ~ 80ms)に初期化時間が加算されることで、最大 1.9 秒を超える遅延が発生している。
Spike(スパイク) テストの結果
段階的負荷テストで判明したコールドスタートの課題に対応するため、スパイクテストでは Provisioned Concurrency を設定してから実行しました。
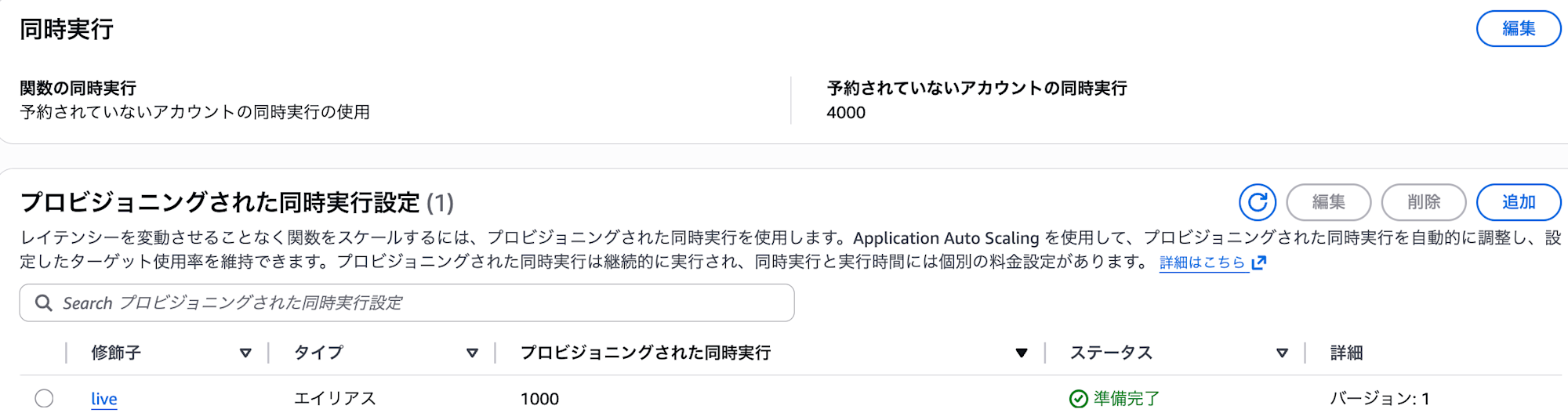
コールドスタート対策:Provisioned Concurrency の設定
スパイクテストでは一気に 200 VU まで負荷が急増するため、コールドスタートが多発する可能性があります。これを防ぐために、Lambda の Provisioned Concurrency を設定しました。(余裕を持って 1000 に設定しています)
結果サマリー
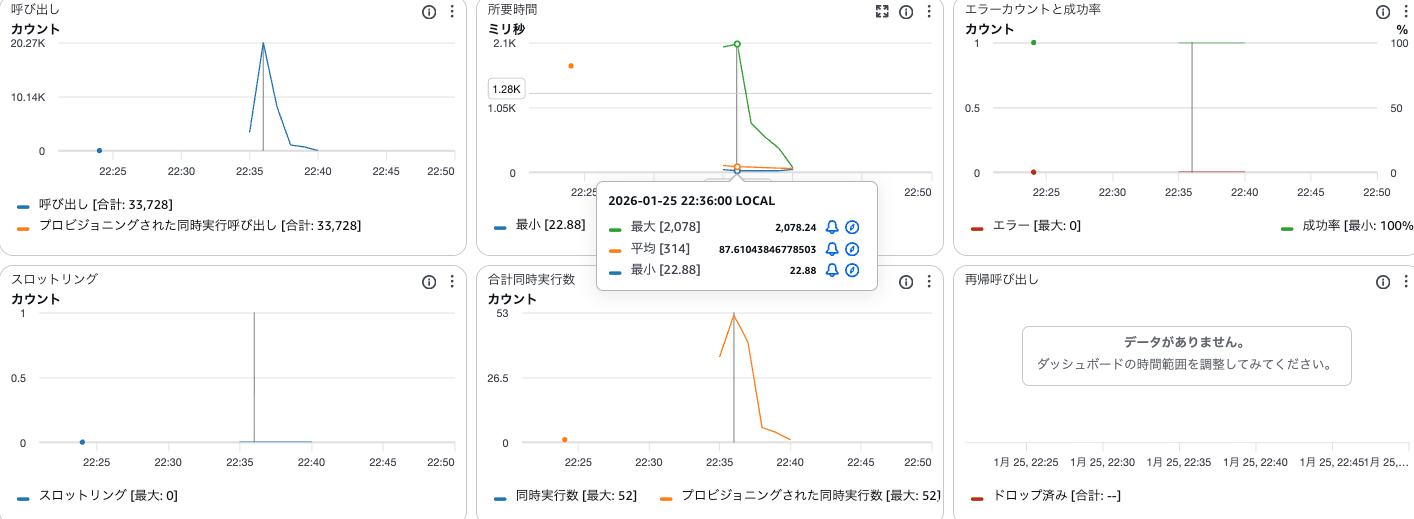
| メトリクス | 値 |
|---|---|
| 総リクエスト数 | 33,727(約 112 リクエスト/秒) |
| 平均応答時間 | 84.44m |
| p95 応答時間 | 120.36ms |
| 最大応答時間 | 2.08s |
| エラー率 | 0.00% |
| 成功率 | 100%(33,727 / 33,727) |
良かった点
- エラー率 0% - 200 VU への急激なスパイクにも関わらず、全 33,727 リクエストが成功
- Provisioned Concurrency の効果 - コールドスタートによる遅延が大幅に減少
- 安定したスループット - 112 リクエスト/秒を維持し、スパイク時も安定して処理
- p95 応答時間 120.36ms - 急激な負荷増加時でも低レイテンシを維持
気になる点
- 最大応答時間 2.08s - 一部のリクエストで遅延が発生
- メモリ使用率 83%(107MB / 128MB) - リソースに余裕が少ない状態
ボトルネックの調査
AWS コンソールから Lambda のメトリクスと X-Ray トレースを確認し、遅延の原因を調査しました。
Lambda メトリクス
| メトリクス | 値 |
|---|---|
| 呼び出し回数 | 33,728 |
| プロビジョニングされた同時実行呼び出し | 33,728(100%) |
| 平均所要時間 | 314ms |
| 最小所要時間 | 22.88ms |
| 最大所要時間 | 2,078ms |
| 最大同時実行数 | 52 |
| スロットリング | 0 |
| エラー | 0 |
プロビジョニングされた同時実行呼び出しが 100% となっており、全てのリクエストが Provisioned Concurrency のインスタンスで処理されました。これにより、コールドスタートは完全に回避できています。
メモリ使用率の課題
Lambda Insights のメトリクスを確認すると、メモリ使用率が約 83%(107MB / 128MB)と高い状態でした。Lambda ではメモリサイズに比例して CPU リソースが割り当てられるため、メモリに余裕がない状態では CPU も制限され、処理速度に影響が出る可能性があります。
X-Ray トレースによる遅延分析
X-Ray で最大遅延が発生したリクエストを確認したところ、コールドスタートではなく、Lambda 関数の処理自体に時間がかかっていることがわかりました。
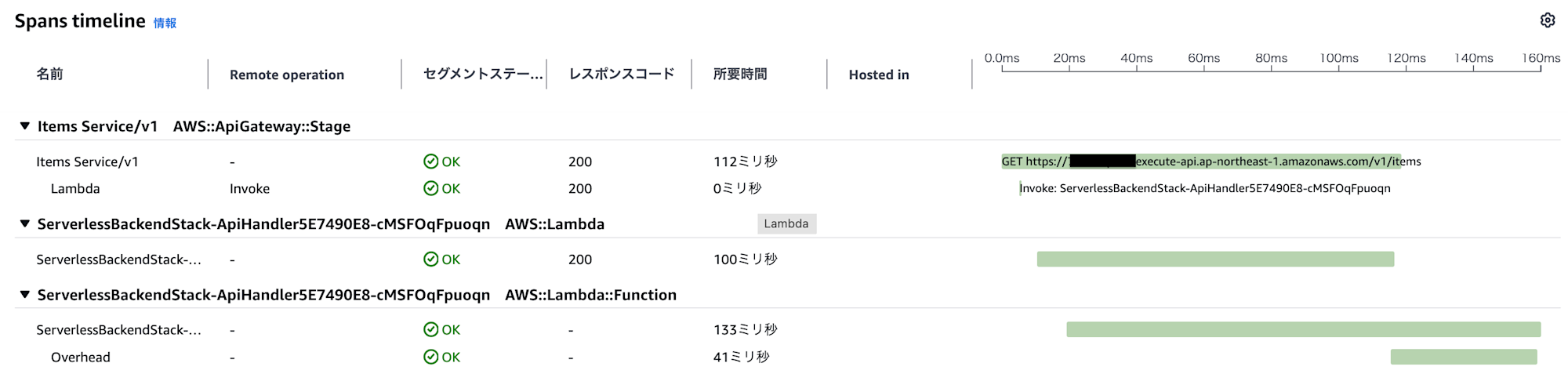
| 処理 | 所要時間 |
|---|---|
| API Gateway 全体 | 112ms |
| Lambda Invoke | 0ms(Provisioned Concurrency により即時起動) |
| Lambda Function | 133ms |
| Overhead | 41ms |
Provisioned Concurrency により Lambda の起動は即時(0ms)となっていますが、関数の処理自体に 133ms かかっています。確認するために、Lambda のメモリを増量して再度テストを実施してみましょう。
Lambda のメモリを増量
上記のとおり、Lambda のメモリが不足している可能性があるため、メモリを 128MB → 256MB に増量して再度負荷テストを行いました。
結果
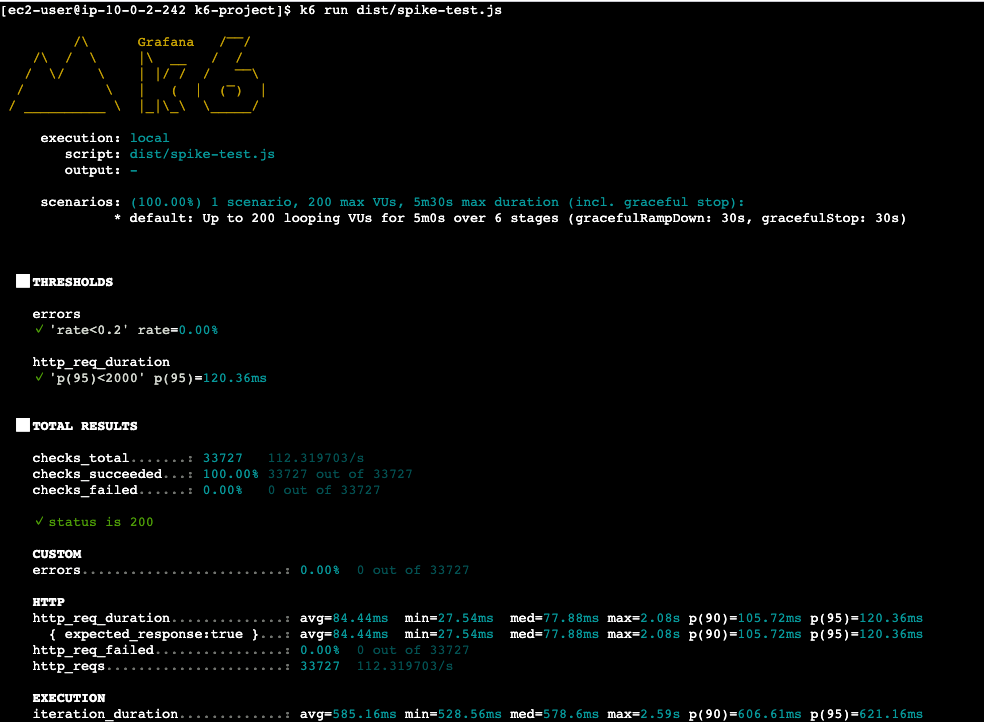
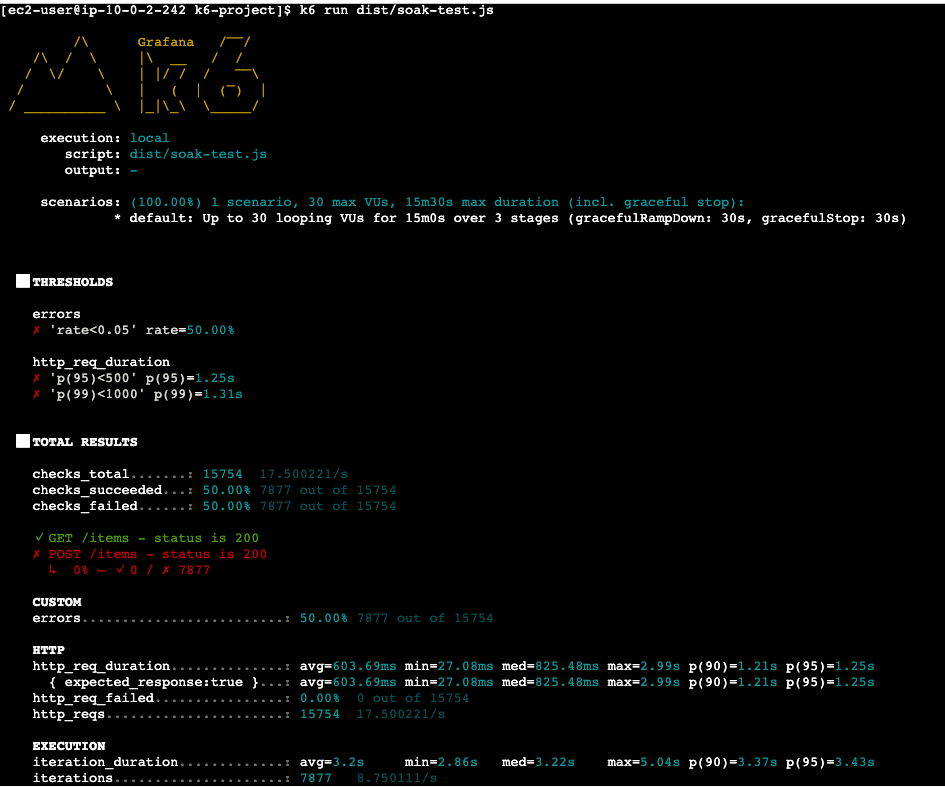
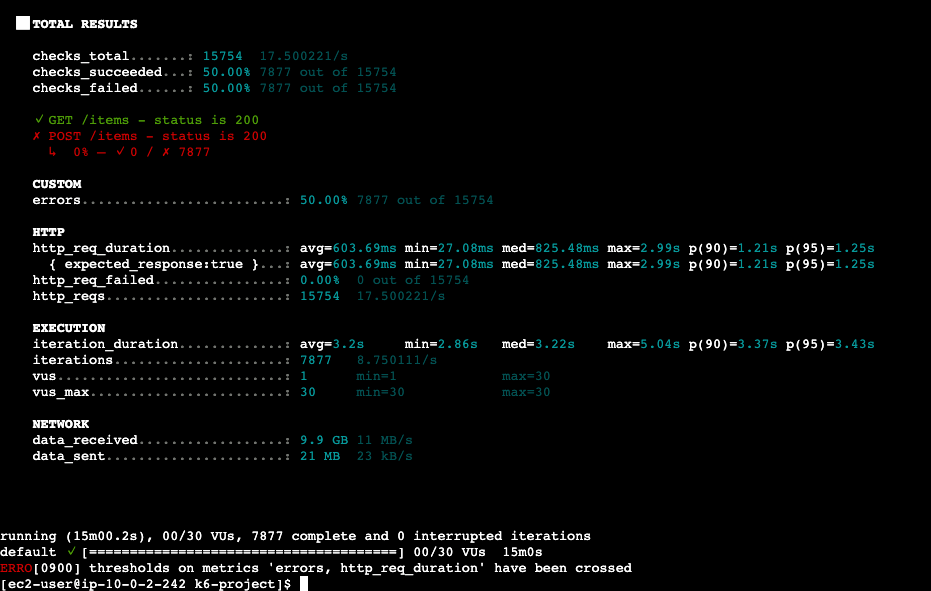
[ec2-user@ip-10-0-2-242 k6-project]$ k6 run dist/spike-test.js
/\ Grafana /‾‾/
/\ / \ |\ __ / /
/ \/ \ | |/ / / ‾‾\
/ \ | ( | (‾) |
/ __________ \ |_|\_\ \_____/
execution: local
script: dist/spike-test.js
output: -
scenarios: (100.00%) 1 scenario, 200 max VUs, 5m30s max duration (incl. graceful stop):
* default: Up to 200 looping VUs for 5m0s over 6 stages (gracefulRampDown: 30s, gracefulStop: 30s)
█ THRESHOLDS
errors
✓ 'rate<0.2' rate=0.00%
http_req_duration
✓ 'p(95)<2000' p(95)=120.36ms
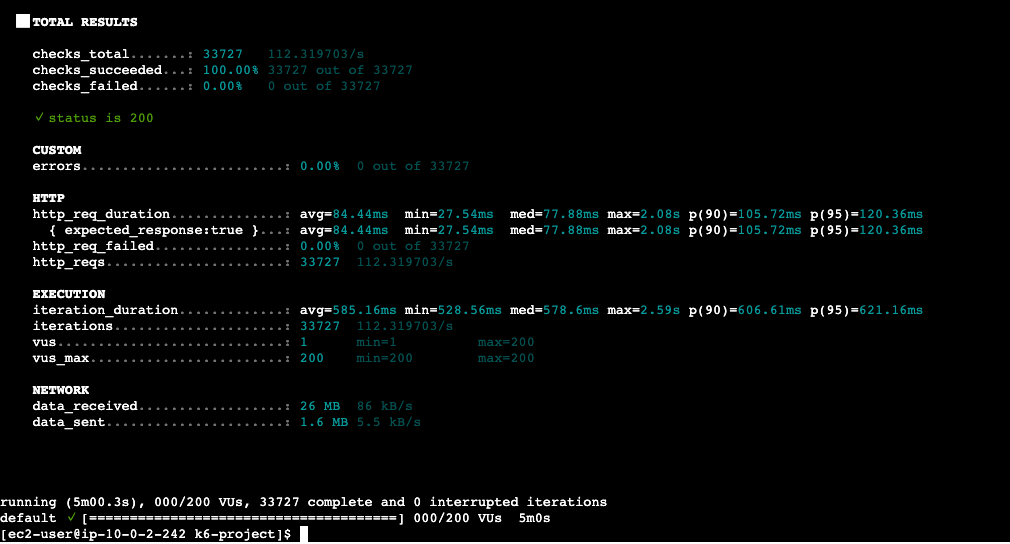
█ TOTAL RESULTS
checks_total.......: 33727 112.319703/s
checks_succeeded...: 100.00% 33727 out of 33727
checks_failed......: 0.00% 0 out of 33727
✓ status is 200
CUSTOM
errors.........................: 0.00% 0 out of 33727
HTTP
http_req_duration..............: avg=84.44ms min=27.54ms med=77.88ms max=2.08s p(90)=105.72ms p(95)=120.36ms
{ expected_response:true }...: avg=84.44ms min=27.54ms med=77.88ms max=2.08s p(90)=105.72ms p(95)=120.36ms
http_req_failed................: 0.00% 0 out of 33727
http_reqs......................: 33727 112.319703/s
EXECUTION
iteration_duration.............: avg=585.16ms min=528.56ms med=578.6ms max=2.59s p(90)=606.61ms p(95)=621.16ms
iterations.....................: 33727 112.319703/s
vus............................: 1 min=1 max=200
vus_max........................: 200 min=200 max=200
NETWORK
data_received..................: 26 MB 86 kB/s
data_sent......................: 1.6 MB 5.5 kB/s
running (5m00.3s), 000/200 VUs, 33727 complete and 0 interrupted iterations
default ✓ [======================================] 000/200 VUs 5m0s
| メトリクス | 128MB | 256MB | 改善率 |
|---|---|---|---|
| 総リクエスト数 | 33,727 | 35,801 | +6% |
| 平均応答時間 | 84.44ms | 50.53ms | 40%改善 |
| p95 応答時間 | 120.36ms | 70.63ms | 41%改善 |
| 最大応答時間 | 2.08s | 971.73ms | 53%改善 |
| スループット | 112 req/s | 119 req/s | +6% |
| エラー率 | 0.00% | 0.00% | - |
メモリ使用率も 83%(107/128MB)から 54%(139/256MB) に改善され、十分な余裕ができました。
Lambda メトリクス(256MB)
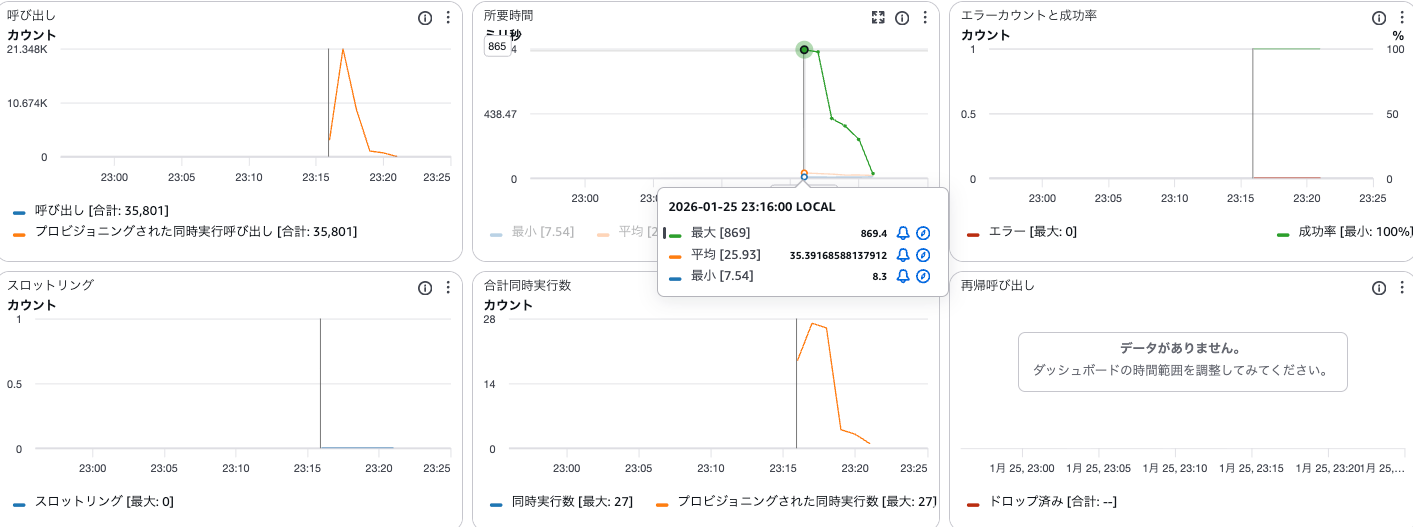
| メトリクス | 128MB | 256MB |
|---|---|---|
| 平均所要時間 | 314ms | 25.93ms |
| 最大所要時間 | 2,078ms | 869ms |
| 最大同時実行数 | 52 | 27 |
平均所要時間が 314ms → 25.93ms と大幅に改善されました。メモリ増加により CPU リソースも増加し、処理速度が向上したことがわかります。
Soak(耐久) テストの結果
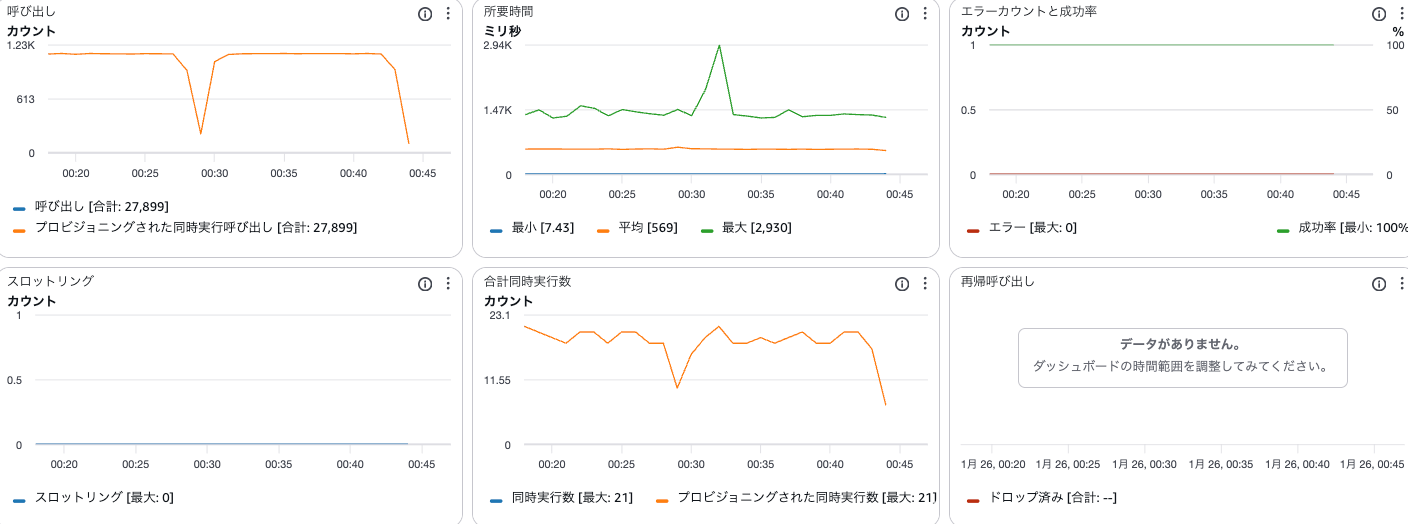
結果サマリー
良かった点
- GET リクエストは 100%成功: 全 44,233 件の GET リクエストが正常に完了
- スループットは安定: 約 86 リクエスト/秒を 15 分間維持
気になる点
- POST リクエストの約 50%が失敗: 44,233 件中 22,269 件(50.3%)がエラー
- レイテンシのしきい値超過: p(95)=1.25s、p(99)=6.48s で目標未達
- 最大レイテンシが 9.69 秒: 一部リクエストが極端に遅延
ボトルネックの調査
AWS コンソールから Lambda のメトリクスと X-Ray トレースを確認し、遅延の原因を調査しました。
Lambda メトリクス
- Duration(最大): 2.93 秒 — タイムアウト(30 秒)には達していないが、通常の 50ms 前後と比較して大幅に増加
- Concurrent Executions: Provisioned Concurrency(500)の範囲内で推移
- メモリ使用率: 安定しており、メモリリークの兆候なし
X-Ray トレースによる遅延分析
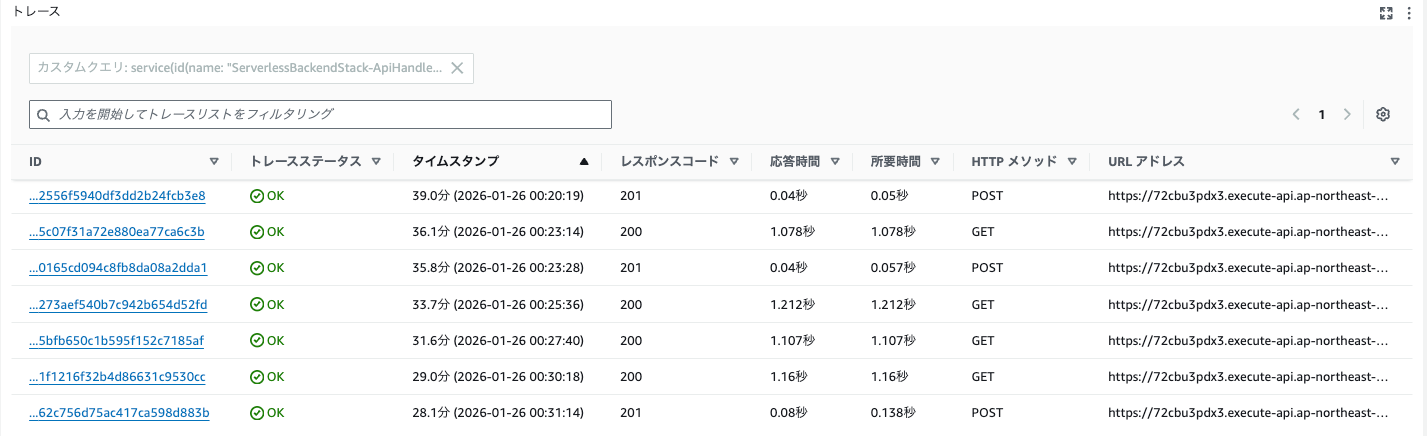
X-Ray のトレースマップを確認すると、GET /items の DynamoDB 呼び出しが 1 秒以上かかっているケースが多数確認されました。テスト開始時は高速だった Scan 操作が、データの蓄積とともに徐々に遅延していく傾向が見られました。
DynamoDB Scan の問題
今回のソースでは、GET /items で DynamoDB の Scan を使用しています。Scan はテーブル全体を読み取る操作のため、データ量が増加するとレイテンシが増加する特性があります。
// GET /items - Get all items
app.get("/items", async (_req: Request, res: Response) => {
const command = new ScanCommand({
TableName: TABLE_NAME,
});
const result = await docClient.send(command);
res.json({ items: result.Items || [] });
});
DynamoDB メトリクス ReturnedItemCount(返却アイテム数)が急増
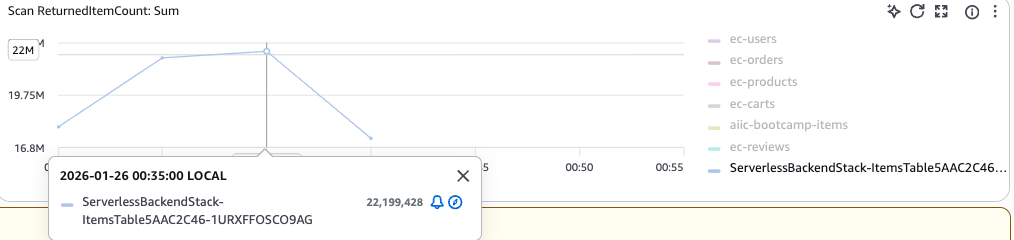
Scan 操作で返却されるアイテム数が時間とともに増加しています。テスト開始時は少数でしたが、POST で継続的にアイテムが追加されるため、後半では 1 回の Scan で数万件を返却する状態になっていました。これがレイテンシ増加の直接的な原因と思われます。
Scan はテーブル全体を読み取る操作です。テスト中に POST で約 22,000 件のアイテムが作成され、毎回の GET リクエストでこれらすべてを取得していました。データ量の増加に比例して Scan のレイテンシが増加し、後半のリクエストが遅延・タイムアウトする原因となりました。インデックスなどを使用し、必要なデータのみを取得する設計が必要になりそうです。
おわりに
今回は k6 を使って、REST API に対して 3 種類の負荷テストを実行しました。
- Ramping テスト:システムの限界点を把握
- Spike テスト:突発的なアクセス増加への耐性を確認
- Soak テスト:長時間運用時の安定性を確認
k6 は stages の設定を変えるだけで様々な負荷パターンを簡単に実現できます。ただ、適切な sleep 時間の設定に悩みました。今回は一律で 1 秒に設定しましたが、本番環境では実際のユーザー行動パターンに基づいた調整が必要です。
この記事がどなたかの参考になれば幸いです。










