
TypeScript の型推論つきバリデーションライブラリ Zod を使ってみた
製造ビジネステクノロジー部の小林です。
TypeScript のバリデーションライブラリの定番 Zod が前から気になっていたので、Zod の基本からよく使うパターンまで触ってみました。
Zod とは
Zod は TypeScript のスキーマ宣言・バリデーションライブラリです。1 つのスキーマから、
- parse / safeParse:スキーマを使った実行時バリデーション
- z.infer<typeof schema> :スキーマから生成される静的な型
の両方を生成できます。つまりスキーマを 1 つ書くだけで「実行時のチェック」と「静的な型」の両方が手に入ります。
たとえば、ユーザーを表すスキーマを 1 つ定義すると、そこから型もチェックも引き出せます。
// スキーマを 1 つ定義する
const userSchema = z.object({
name: z.string().min(1), // 1文字以上の文字列
age: z.int().gte(0), // 0以上の整数
});
// ① このスキーマから TypeScript の型を生成(コンパイル時)
type User = z.infer<typeof userSchema>;
// type User = { name: string; age: number }
// ② 同じスキーマで実行時のバリデーション(ランタイム)
userSchema.safeParse(input);
userSchema という 1 つの定義が、コンパイル時には「型」として、ランタイムには「チェック」として、2 方向に使われているのがポイントです。図にするとこんなイメージです。
Zod を使うメリット
型定義とバリデーションロジックを 1 つのスキーマで管理できるため、保守性が向上します。Zod ありなしで並べると分かりやすいと思います。
Zod を使わない場合、型定義と実行時チェックを別々に書く必要があります。
// 型定義
interface User {
id: string;
name: string;
age: number;
}
// 実行時チェックは別途関数で
function isValidUser(input: unknown): input is User {
if (typeof input !== "object" || input === null) return false;
const u = input as Record<string, unknown>;
if (typeof u.id !== "string") return false;
if (typeof u.name !== "string" || u.name.length === 0) return false;
if (typeof u.age !== "number" || u.age < 0 || u.age > 150) return false;
return true;
}
// フィールドを追加するたびに interface と isValidUser を両方直す必要がある
Zod ありでスキーマ 1 つから型もチェックも取り出せる世界だとこうなります。
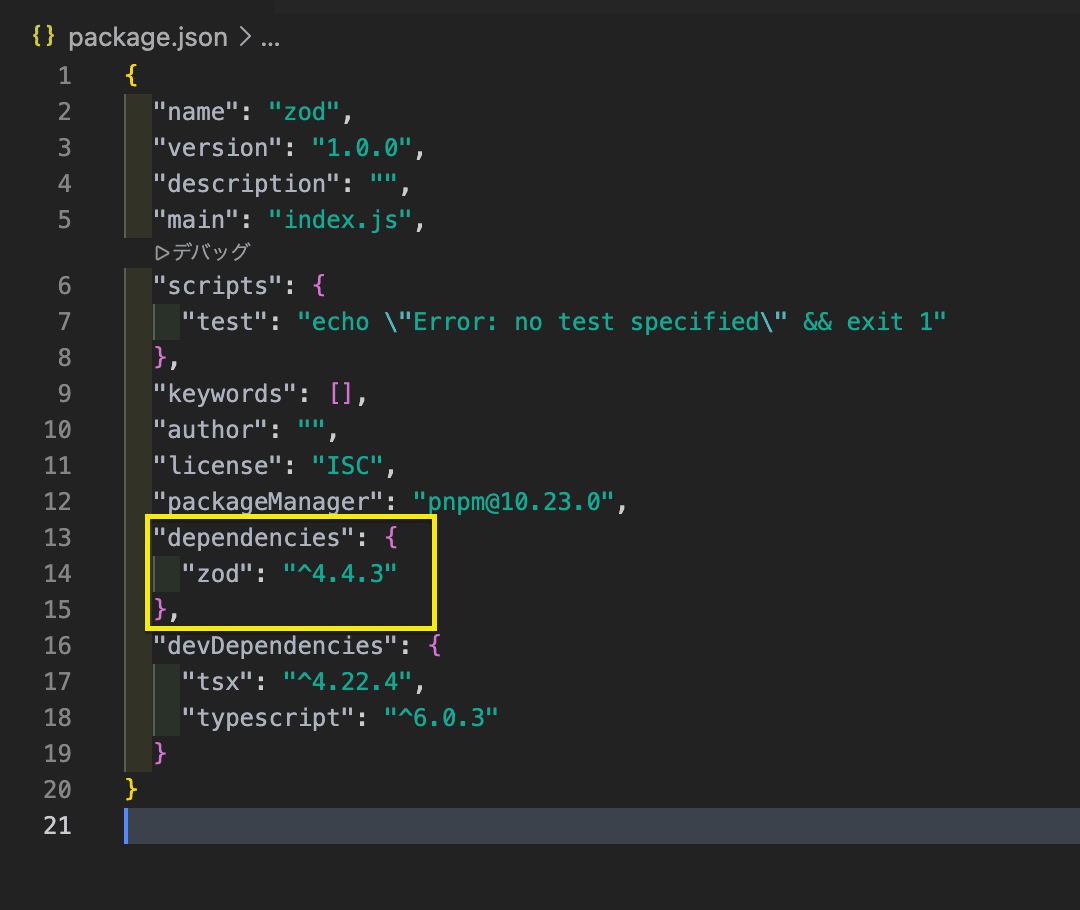
const userSchema = z.object({
id: z.uuidv4(),
name: z.string().min(1),
age: z.int().gte(0).lte(150),
});
type User = z.infer<typeof userSchema>; // 型はここから取り出すだけ
// スキーマを直せば、型もチェックも同時に変わる
使ってみた
まずは動かす環境を用意します。Node.js プロジェクトに Zod と TypeScript を入れるだけです。
mkdir zod && cd zod
pnpm init
pnpm add zod
pnpm add -D tsx typescript
入れるものは 2 つです。
zod: 本体tsx: TypeScript をコンパイルなしでそのまま実行できる CLI。
プリミティブ型を試す
まずは一番基本となるプリミティブ型(文字列・数値など)のバリデーションから動かしてみます。src/index.ts に以下を書きます。
import { z } from "zod";
// 個々の値に対するスキーマ
const nameSchema = z.string().min(1).max(20);
const ageSchema = z.int().gte(0).lte(150);
// 通る値はそのまま返ってくる
console.log(nameSchema.parse("田中太郎")); // → "田中太郎"
console.log(ageSchema.parse(30)); // → 30
// 通らない値は ZodError を投げる
try {
ageSchema.parse(200); // lte(150) に違反
} catch (e) {
console.error("失敗:", (e as Error).message);
}
z.string().min(1).max(20)は「1 文字以上 20 文字以下の文字列」。.min() / .max() をメソッドチェーンで足して制約を重ねられますz.int().gte(0).lte(150)は「0 以上 150 以下の整数」。z.int()はz.int() は Number.MAX_SAFE_INTEGER を超える整数も弾いてくれますparse(...)は、通過すれば入力と同じ値をそのまま返し、ダメなら ZodError を投げます。
email / uuid / url のような一般的なフォーマットは、わざわざ正規表現を書かなくてもトップレベル関数として用意されているので、こんなふうに直接呼べます。
const emailSchema = z.email();
const idSchema = z.uuidv4(); // UUID v4 専用
書いたスキーマで実際にバリデーションが通るか実行してみます。
pnpm tsx src/index.ts
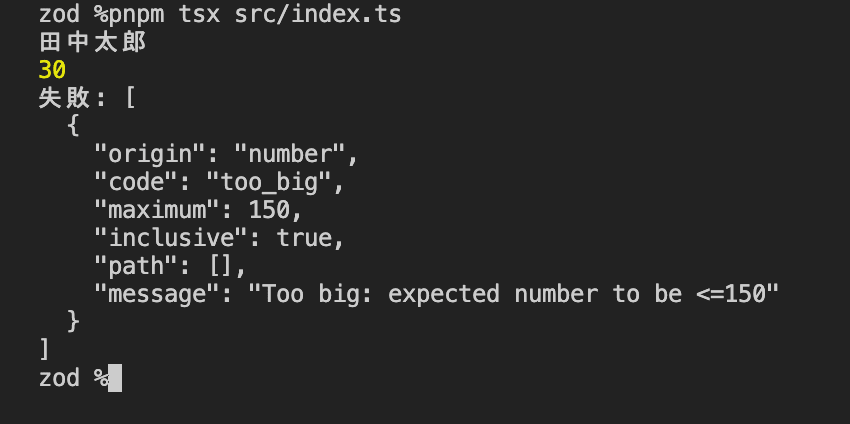
- nameSchema.parse("田中太郎") → 田中太郎、ageSchema.parse(30) → 30 … 通った値はそのまま返ってくる
- ageSchema.parse(200) → 失敗: Too big: expected number to be <=150 … lte(150) に違反したので ZodError が投げられ、catch で拾えている
つまり parse は失敗すると例外を投げるので、失敗の可能性がある場面では try / catch が必要になります。「失敗したら 400 を返す」ような API ハンドラーでは、例外で制御を回すより、次に紹介する safeParse の方が扱いやすいです。
safeParse で失敗を制御フローに組み込む
先ほどの parse は失敗時に例外を投げるため、失敗があり得る場所では毎回 try / catch で囲む必要がありました。
そこで使うのが safeParse です。safeParse は例外を投げず、成否を表す結果オブジェクトを返します。
- 成功時 … { success: true, data: ... }
- 失敗時 … { success: false, error: ... }
なので try / catch は不要で、if (result.success) をチェックするだけで成功・失敗を分岐できます。例外で制御を回さずに済みますね。
実際に、わざと複数のルールに違反する入力を渡して動かしてみます。
const badInput = {
id: "not-a-uuid", // UUID 形式ではない
name: "", // min(1) を満たさない
age: 200, // lte(150) を超えている
deleteFlag: false,
};
const result = userSchema.safeParse(badInput);
if (!result.success) {
// 失敗時: result.error が ZodError、issues に詳細が入る
console.error("バリデーション失敗");
result.error.issues.forEach((issue) => {
console.error(` [${issue.path.join(".")}] ${issue.message}`);
});
} else {
// 成功時: result.data が User 型に絞り込まれている
console.log("OK:", result.data);
}
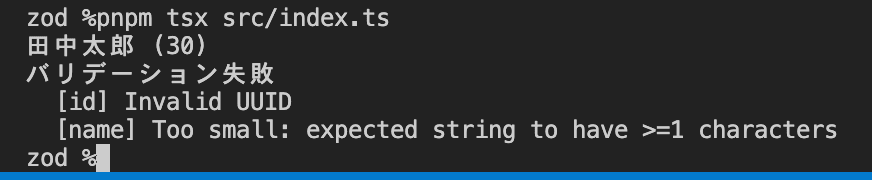
出力を見ると、違反したフィールドごとにエラーが 1 行ずつ並んでいます。safeParse の戻り値は判別共用体になっていて、
- result.success === false のとき … result.error が ZodError で、issues に失敗の詳細が配列で入る
- result.success === true のとき … result.data が User 型に絞り込まれて型安全に使える
という 2 つに分岐します。
parse のように例外を catch しなくても、if (!result.success) のガードだけで失敗を弾けます。
エラーをきれいに整形する
result.error.issues は配列のままなので、フロントにそのまま返したりログに出したりするには少し扱いづらい形です。そこで Zod には、用途に応じてエラーを整形できるトップレベル関数が 3 つ用意されています。
safeParse が失敗したあと、どれを呼ぶかは「何に使いたいか」で決まります。流れを図にするとこんな感じです。
3 つの関数の違いです。
| 関数 | 出力の形 | こんなときに使う |
|---|---|---|
| z.treeifyError(err) | ネスト構造(errors / properties / items) | 配列・ネストしたオブジェクトのエラー位置を構造で追いたい |
| z.flattenError(err) | フラット(formErrors / fieldErrors) | フォームや単層オブジェクトのエラーをフィールド名キーで取りたい |
| z.prettifyError(err) | 人が読める整形済み文字列 | デバッグログ・CLI の出力にそのまま流したい |
同じエラーを 3 つの関数に通して出力を見比べてみます。
import { z } from "zod";
const schema = z.object({
user: z.object({
name: z.string().min(1), // 1文字以上
age: z.int().gte(0), // 0以上の整数
}),
});
// わざと両方とも違反する値を渡す(name は空文字、age はマイナス)
const result = schema.safeParse({ user: { name: "", age: -1 } });
// 同じ error を 3 つの整形関数に通して出力を見比べる
if (!result.success) {
// ① treeifyError: スキーマの構造に沿ったネスト構造で返る
console.log("--- treeifyError ---");
console.log(JSON.stringify(z.treeifyError(result.error), null, 2));
// ② flattenError: { formErrors, fieldErrors } のフラットな形で返る
console.log("--- flattenError ---");
console.log(z.flattenError(result.error));
// ③ prettifyError: 人が読める整形済みの文字列で返る
console.log("--- prettifyError ---");
console.log(z.prettifyError(result.error));
}
1. treeifyError の出力
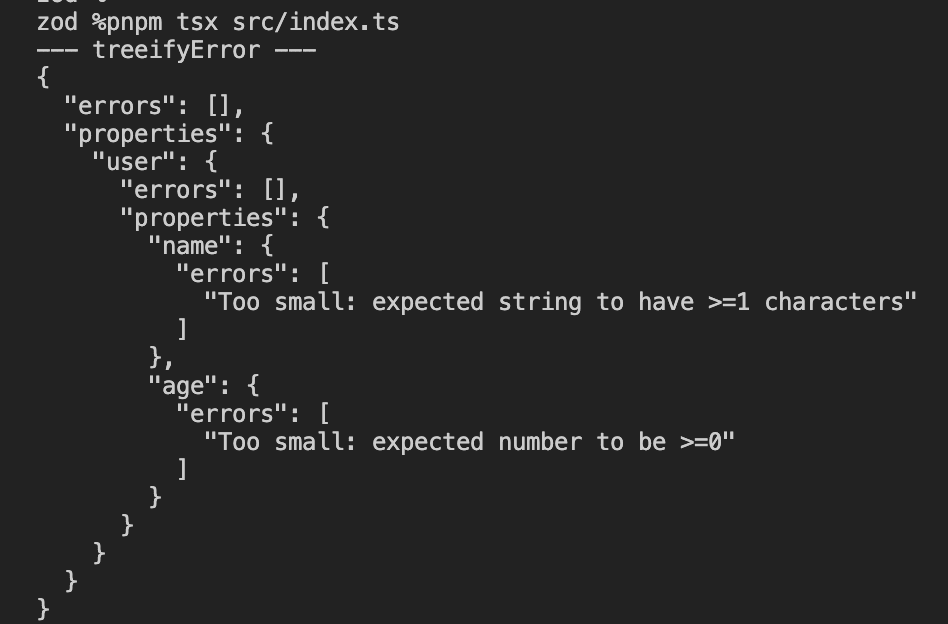
ポイントは、各階層が次の 2 つに分かれていることです。
- errors:その階層自身のエラー
- properties:子フィールドへの再帰(さらに errors と properties を持つ)
つまりエラーまでネストを辿らないと取れません。今回の user.name のエラーであれば properties.user.properties.name.errors という深い位置に入っています。配列が混じる場合は、ここに items も登場します。
スキーマの構造をそのまま辿ってエラー位置を特定したいとき、たとえば深くネストしたオブジェクトや配列を扱うときに向いている形式です。
2. flattenError の出力
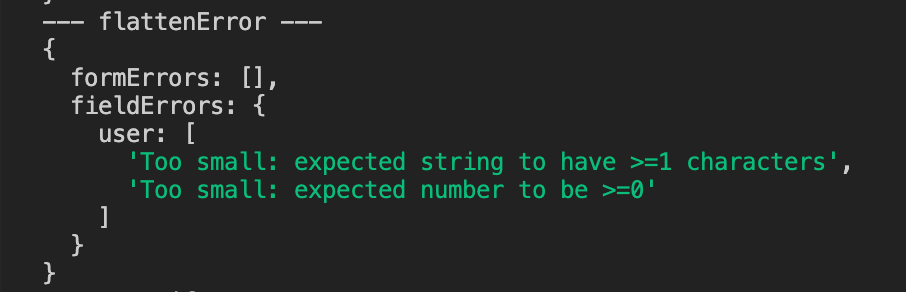
treeifyError と違って、戻り値は次の 2 つを持つフラットな形です。
- formErrors … 特定のフィールドに紐づかないトップレベルのエラー(たとえば z.strictObject で未知キーが来たときなど)
- fieldErrors … フィールド名 → エラーメッセージ配列のマップ
fieldErrors はフィールド名がそのままキーになるので、フロントのフォームで <input> の横にエラーを貼るのにそのまま使えて便利です。
ただし名前のとおりフラットなので、ネストしたオブジェクトの中の個別フィールドまでは拾えません。上の例でも name / age が個別に出るのではなく、user という単一キーにまとめられてしまいます。
3. prettifyError の出力

人が読むだけのケース、たとえば CloudWatch Logs に流すデバッグログや CLI ツールの出力にはこれが一番楽です。整形済みの文字列が返るので、console.log にそのまま流すだけで OK です。
クロスフィールドの検証は .refine()
ここまでは 1 つのフィールド単位の検証でしたが、実際には「開始日時 ≤ 終了日時」のように複数フィールドを見て初めて判定できるルールもあります。こうしたクロスフィールドの検証は、.refine() をスキーマに足すことで表現できます。
const periodSchema = z
.object({
// どちらもオフセット付き ISO 8601 形式(例: 2025-12-31T10:00:00+09:00)
startDateTime: z.iso.datetime({ offset: true }),
endDateTime: z.iso.datetime({ offset: true }),
})
// .refine で複数フィールドにまたがるチェック(開始 <= 終了)を追加
.refine(
(data) => new Date(data.startDateTime) <= new Date(data.endDateTime),
// path でどのフィールドのエラーとして扱うか、error でメッセージを指定
{ path: ["startDateTime"], error: "開始日時は終了日時以前にしてください" }
);
// 開始が終了より後 → .refine のチェックに引っかかる入力
const ng = periodSchema.safeParse({
startDateTime: "2025-12-31T10:00:00+09:00",
endDateTime: "2025-12-01T10:00:00+09:00",
});
if (!ng.success) {
// path で指定した startDateTime にカスタムメッセージが出る
console.log(z.prettifyError(ng.error));
}

- 第 1 引数: boolean を返すチェック関数(true で通過、false でエラー)
path: 指定したフィールド配下にエラーが入るerror: エラーメッセージ
入力を変換する .transform()
バリデーションだけでなく、通った値を別の型に変換することもできます。たとえば「"featured" という文字列が来たら数値 1 として後段に渡す」ような正規化を、スキーマの中に閉じ込められます。
const articleSchema = z.object({
published: z.int().gte(0).lte(1),
featuredFlag: z
.literal("featured") // "featured" のみ受け付ける
.transform(() => 1) // 値を 1 に置き換える
.optional(), // 省略可
});
const parsed = articleSchema.parse({ published: 1, featuredFlag: "featured" });
console.log(parsed); // → { published: 1, featuredFlag: 1 }

featuredFlag のスキーマは、
z.literal("featured")で「文字列"featured"のみ受け付ける」.transform(() => 1)で値を1に置き換える.optional()でこのフィールド自体を省略可にする
未知のキーを弾く z.strictObject()
z.object() のデフォルト挙動では、スキーマに定義していないキーはエラーにならず黙って落とされます。バリデーションは通るのに余分なフィールドだけ消える、という動きなので、意図しない値が紛れていても気づけません。
クライアントが余分なフィールドを送ってきたときに 400 で弾きたい場合は、z.strictObject() を使います。
const schema = z.strictObject({ id: z.string() });
// id は OK だが、定義していない extra が混ざっている
const result = schema.safeParse({ id: "abc", extra: "hoge" });
if (!result.success) {
console.log(z.prettifyError(result.error));
}

z.object() ならスルーされていた extra が、z.strictObject() では Unrecognized key としてしっかりエラーになりました。API の入力チェックでは、想定外のキーを早めに弾けるこちらの方が安心感があります。
スキーマの再利用・合成
同じ制約はあちこちで書きたくないですよね。Zod にはスキーマを使い回すための仕組みがいくつか用意されているので、順に見ていきます。
フィールド単位で使い回す: .shape
定義済みスキーマの個別フィールドは、.shape.<フィールド名> で取り出せます。
const baseUserSchema = z.object({
id: z.uuidv4(),
name: z.string().min(1).max(256),
});
// 別スキーマで .shape から個別フィールドを参照する
const requestSchema = z.object({
userId: baseUserSchema.shape.id, // baseUserSchema の id と同じ制約
userName: baseUserSchema.shape.name, // baseUserSchema の name と同じ制約
});
こうしておけば、id の制約(UUID v4)を変えたくなっても 直すのは baseUserSchema の 1 箇所だけ。参照している側に自動で反映されるので、制約のズレが起きません。
スキーマ全体を合成する: spread
フィールド単位ではなく、スキーマ全体をベースに拡張したい場合は shape の spread(または .extend())を使います。
const userWithRoleSchema = z.object({
...baseUserSchema.shape, // 既存の id / name をそのまま展開
role: z.enum(["admin", "user"]), // role を追加
});
DB スキーマと API スキーマを同じ定義から作る
再利用が効いてくるのが、DB テーブルに対応するスキーマと API リクエストのスキーマを 1 箇所に集約するケースです。両者を別々に書くと、片方だけ制約を直して乖離する…という事故が起きがちですが、.shape で参照しておけばそれを防げます。
// DB テーブルに対応するスキーマ
const fishSchema = z.strictObject({
fishId: z.uuidv4(),
fishName: z.string().min(1).max(256),
species: z.enum(["tuna", "salmon", "mackerel"]),
createDateTime: z.iso.datetime(),
});
// API スキーマは fishSchema からフィールドを再利用する
const apiRequestSchema = z.object({
fish: fishSchema.shape.fish, // DB 側と同じバリデーションを使い回す
});
たとえば fish の正規表現や最大長を見直したくなっても、fishSchema 側を直すだけで API スキーマにも反映されます。
おわりに
今回は TypeScript のバリデーションライブラリである Zod を試してみました。型もチェックもスキーマ 1 つで書けるのは便利ですね。他の機能もまた触ってみます。この記事がどなたかの参考になれば幸いです。
参考リンク







