
LangGraphのinterruptsでカスタムUIを返すHuman-in-the-Loopを試してみた
はじめに
クラスメソッド発 製造業 Advent Calendar 2025の15日目のエントリです。
もう年の瀬ですね。皆さま今年はどんな一年だったでしょうか。
個人的には2024年の年末に「来年(2025年)はAIエージェント元年になる」と言われていた予測が、まさに現実となった一年だったと感じています。
実際に私の仕事においてAIエージェントは不可欠な存在で、不可逆な進歩です。特に今年の後半にかけてリリースされたプロダクトで、AIエージェントと人間をつなぐ洗練されたUIを体験する機会が増えた気がします。
例えばClaude CodeのPlanモードのAIによる逆質問のUIです。以下のようにユーザーはCLI上で逆質問に対して、UIを使って次の指示を行います。カーソルキーで選択し、スペースでチェックをつける。観点が複数ある場合は観点ごとにページがあり、Tabでページ送り出来ます。どのページにも自由記述する項目があるの便利です。
> これを整理したい
⏺ 整理の方法についていくつか選択肢があります。
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
← ☐ 整理形式 ✔ Submit →
どのような形式で整理したいですか?
❯ 1. [✔] READMEに追記
プロジェクトのREADME.mdにアーキテクチャ説明を追加
2. [ ] 新規ドキュメント作成
docs/ARCHITECTURE.md などに独立したドキュメントとして作成
3. [ ] コード内コメント
各ファイルにコメントを追加して仕組みを説明
4. [ ] Mermaid図を作成
フロー図やシーケンス図をMarkdownで作成
5. [ ] Type something
Submit
Enter to select · Tab/Arrow keys to navigate · Esc to cancel
以前はPlanモードにおけるAIの逆質問は、人間が文章で回答していました。それがUIで選択、操作することで、考えたり、プロンプトを記述する労力を省力化しており、慣れると作業負荷が減っていることが実感できました。これはAIが「ユーザーが次にやりたくなること」を文脈から読み取り、先回りしてUIに落とし込んで提示することで、考えたり、プロンプトを記述する労力を減らしています。
汎用的なチャット(ChatGPTなど)とは異なる、業務SaaSに組み込まれたチャットであれば、プロダクトの特性上「次にやるべきこと」はある程度絞り込まれるケースも多いと思っています。故にプロンプトを考えたり、入力する労力を減らすようなUIを挟むことでより体験が良くするチャンスがあります。
そこで今回は「動画に映っている物体を認識して、データにタグ付けする」というAIワークフローの中で、その途中で人間の承認割り込み+UIを提示しタスク完遂する例を紹介します。この例は動画とその中の物体認識を、HITLを使って柔軟に制御するのは、製造業でも使える場面があると思います。
構成
今回想定するのは、動画管理における「長尺動画へのタグ付け」です。 全フレームをマルチモーダル解析するとコストが高額になるため、ユーザーが必要なシーン(フレーム)だけを選択できる仕様としました。フレーム選択からタグの絞り込みまで、一連の作業をチャットUIだけで手軽に行えるのが特徴です。アウトプットを先にみたい方は 動かしてみる に進んでください。
構成としては、CopilotkitとLangGraph(TypeScript)構成にしました。理由はLangGraphにinterruptsという機能があり、グラフの実行を特定の時点で一時停止し、外部入力を待ってから処理を続行できます。
Copilotkitでも連携可能なuseLangGraphInterruptがあり連携が可能です。恐らく唯一だと思われます。
本記事で利用されるコードは以下に格納していますので、全体感がわからなかった場合に参考にしてください。
実装
概要
AIワークフローの遷移図は以下の通りです。
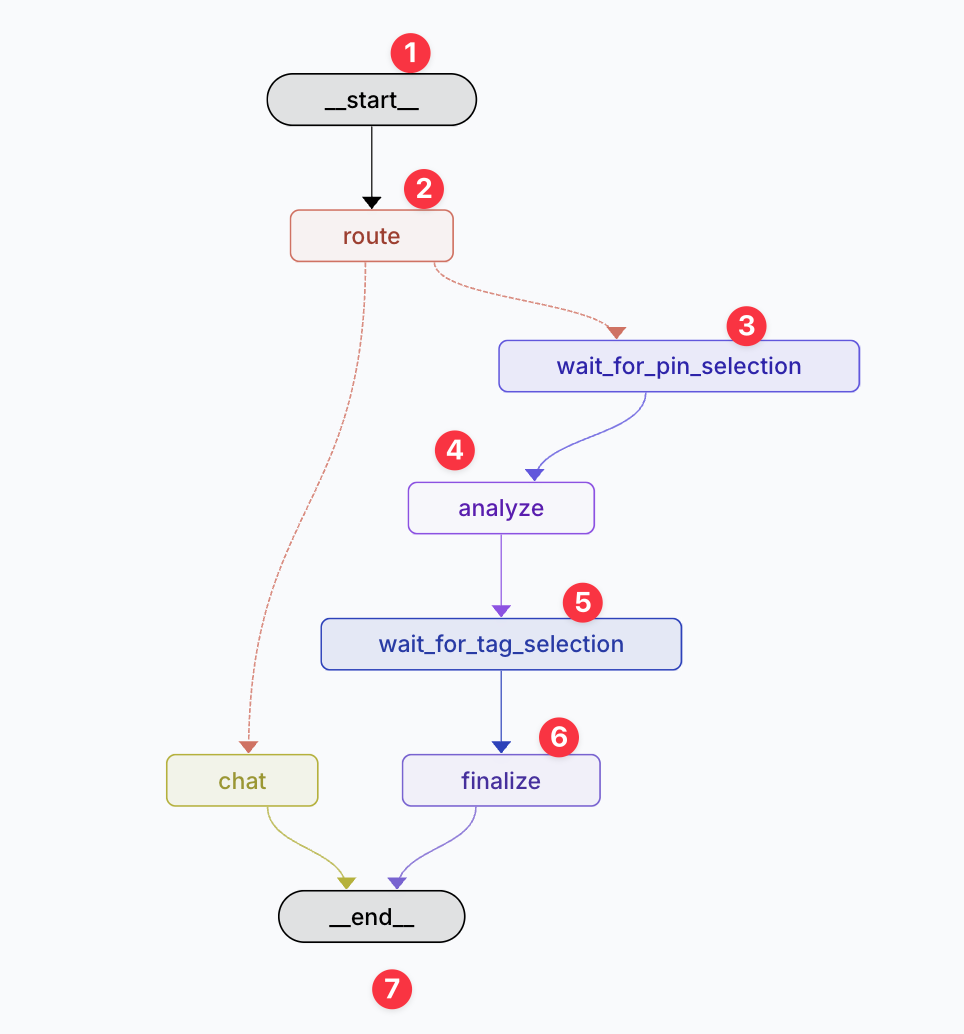
処理としては以下の項1 ~ 9までが実行されます。上記の遷移図丸番号と併せて処理を追えるようにしています。
- (ユーザー) Web画面で動画を解析してとリクエスト
- (サーバー) 遷移図丸1開始
- (サーバー) 遷移図丸2はコンテキストを解釈し適切なノードにルーティングします。動画解析のリクエストなので遷移図丸3へ
- (サーバー) 遷移図丸3では、動画のどのフレームを解析するか?ユーザーに求める割り込みを返却
- (ユーザー) 遷移図丸3の割り込みの内容を、UIを使って選択
- (サーバー) 遷移図丸4で該当のタイムスタンプをマルチモーダル解析し、動画に付与するタグの候補を解析
- (サーバー) 遷移図丸5では、どのタグを選択するか?ユーザーに求める割り込みを返却
- (ユーザー) 遷移図丸5の割り込みの内容を、UIを使って選択
- (サーバー) 遷移図丸6では選択されたタグを返却
人間の選択が挟まるタイミングが項5と項8で、以下の2つのUIを返却します。
- 動画の場所を切り出し、選択、削除するUI
- 決定したタグを選択するUI
実装
LangGraphの定義は以下の通りです。
今回のコアの部分であるHITL部分の解説をします。
まずフレーム選択画面のwait_for_pin_selectionについてです。流れは以下の通りです。
- サーバー側: interrupt(payload) が呼ばれる → LangGraphの実行が一時停止
- フロント側: payload がフロントエンドに送られる → useLangGraphInterrupt の event.value として受け取る
- フロント側: UI側で resolve() が呼ばれるまで待機
- フロント側: resolve(data) が呼ばれる → interrupt() の戻り値として data が返る
- サーバー側: 処理が再開 → JSON.parse(response) 以降が実行される
サーバー側の実装は以下です。動画は決め打ちですが、プロダクトなどでは、動画を別のUIで選択させたり、RAGでretriveしても良いと思います。
フロント側の実装は以下です。LangGraphのノードの返却値がコンポーネントの引数になるようなイメージです。この部分はAI SDKのGenerative UI機能と似ています。
動かしてみる
Screen studioで撮ったので少しエフェクトが入っています。が速度は等倍です。
まず動画解析UIが返却されます。プロダクトなどでは、動画を別のUIで選択させたり、RAGでretriveしても良いと思います。右下の確定して解析ボタンを押下します。
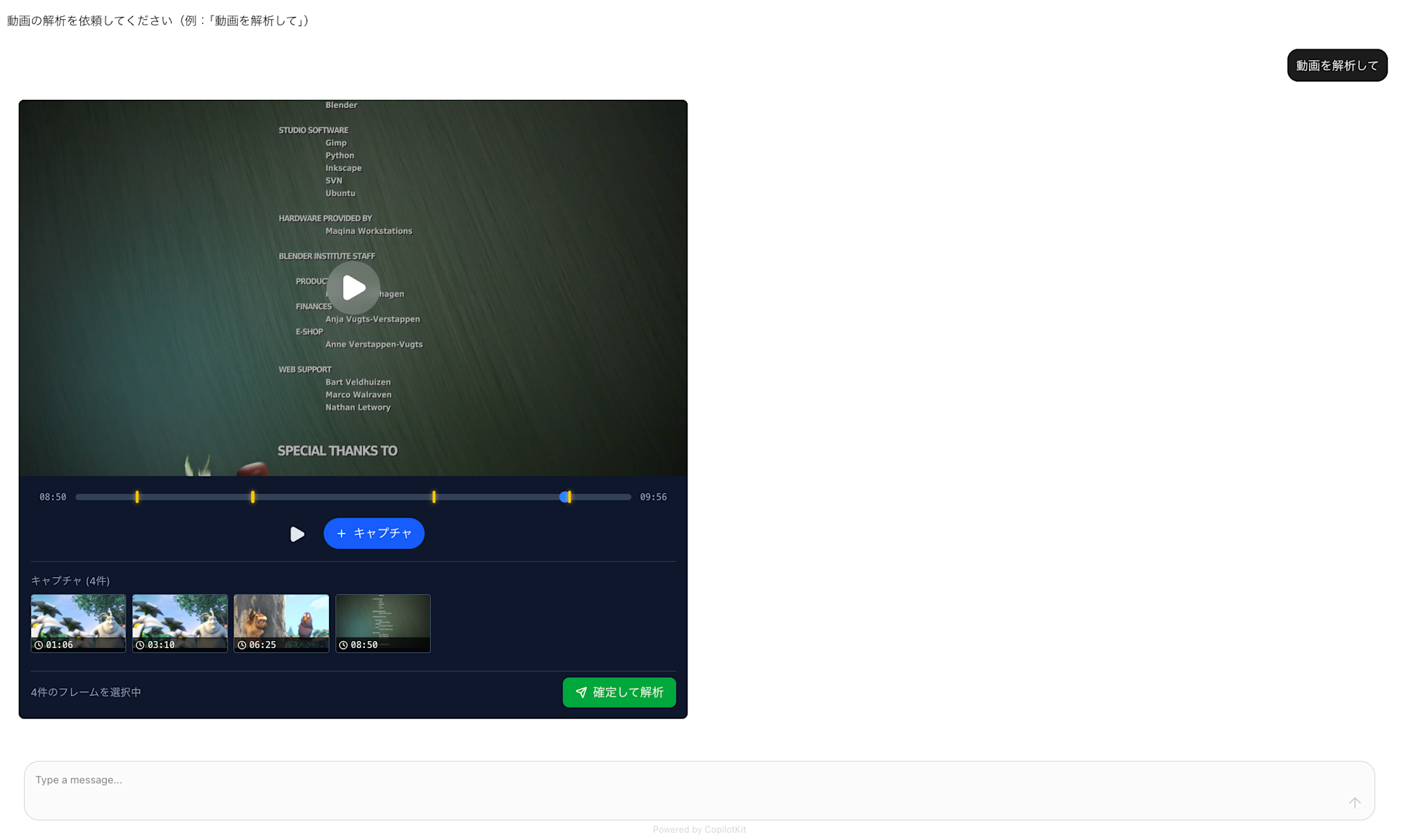
すると、選択したフレームごとにタグの候補が一覧が取得できます。
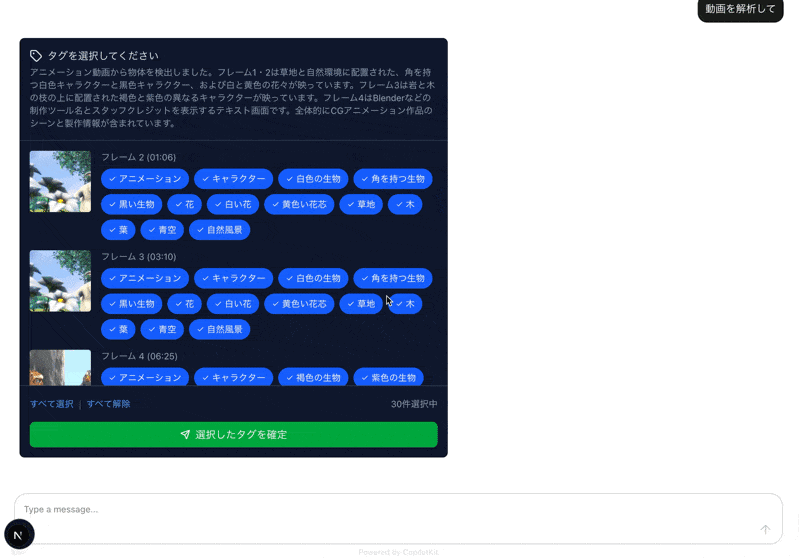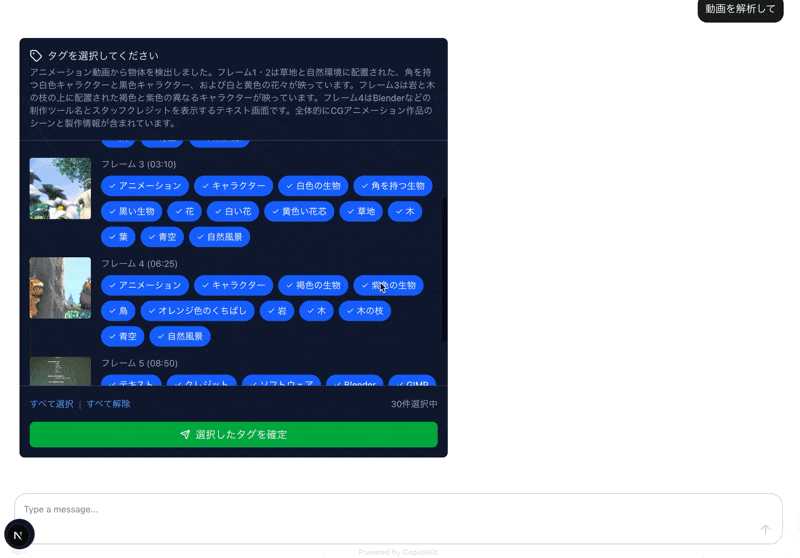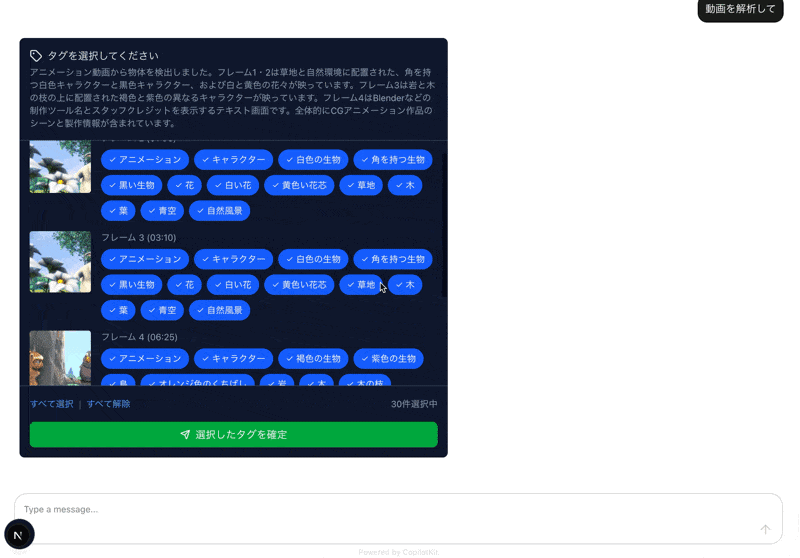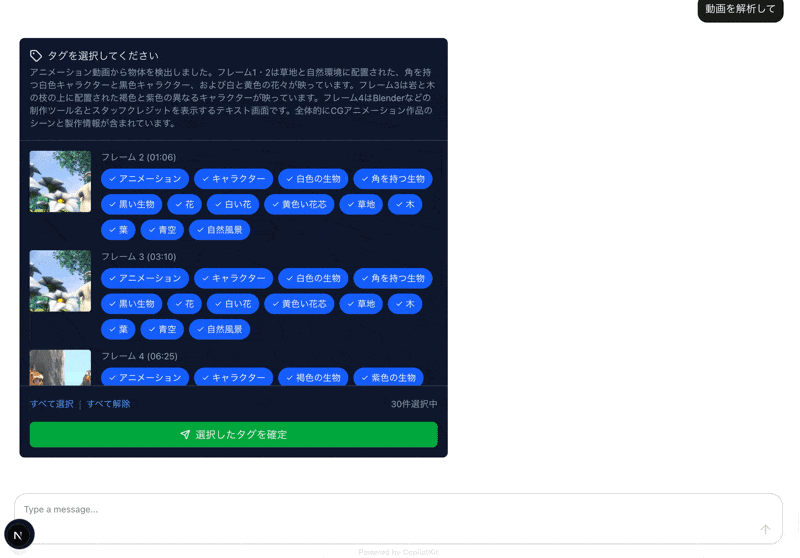
あとは必要タグに絞り込んで終わりなので割愛します。
さいごに
とても簡易な実装でHITL+UIで一味違うチャット体験になることがわかったと思います。実際この構成をホスティングしようと思うとセッション永続化しないといけないので、考慮事項は多いです。今回はメモリサーバーで代用しています。
CopilotkitとStrands構成で同じことをやろうとしたのですが、useHumanInTheLoopが複数発火しない問題や、interruptの思想が異なりハックが必要になりそうだったため、別の機会で試してみようと思います!
ちなみに去年の製造業 Advent Calendar 2024では、MCPとLangChainで電力予測をしていました。エコシステムの進化を感じますね。








