
S3上のオブジェクトを結合するnpmパッケージで結合順を設定できるようにした話
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
昨年 5 月(2024 年 5 月)に以下のブログを書きました。本記事はそのアップデートブログとなります。
仕組みを簡単に説明すると、マルチパートアップロードで UploadPartCopy と UploadPart を組み合わせて、複数のオブジェクトを 1 つに結合しています。
以前は、5 MiB 以上のオブジェクトとそれ未満のオブジェクトに分けて、まずは 5 MiB 以上の S3 オブジェクトを UploadPartCopy で送り、残りを UploadPart でストリーム転送していました。そのため、S3 オブジェクトの連結順序がサイズによって入れ替わる仕様になっていたのです。
当時のユースケースでは優先度が低かったため、この問題への対応を見送っていましたが、フィードバックをいただき、あらためて需要を感じたため対応することにしました。
仕組み
最初に述べた方法を少し改善したものです。ざっくり説明すると、結合したい S3 オブジェクトを指定した順序で両端キュー(以下 Deque とします)に詰め込み、Deque が空になるまで以下を繰り返します。
- 5 MiB 以上の場合:
UploadPartCopy で 5 GiB ごとに始点・終点を指定したUploadPartCopy の元となるリクエストを作成し、5 MiB 未満の残り部分があれば Deque の先頭に追加する - 5 MiB 未満の場合:
5 MiB になるまで複数の S3 オブジェクトを始点・終点を指定し、UploadPart の元となるリクエストを作成
実際のリクエスト生成部分がこのツールのコアで、150 行程度です。Deque を使わずに配列のみで構成した最小実装は Issue #5 のコメント にも掲載しています(初期の動作検証用のため、参考程度でお願いします)。Deque を使う理由は後述します。
上記のリクエストを作成したら、非同期かつ並行でリクエストを送信します。
最後に Etag をパート順にソートしてマルチパートアップロードを完了します。
Deque を使った理由については後述します。
試してみる
準備
本ライブラリでは、オブジェクト名・サイズ・更新日時でソートが可能です。今回はオブジェクト名でソートした場合の例を紹介します。
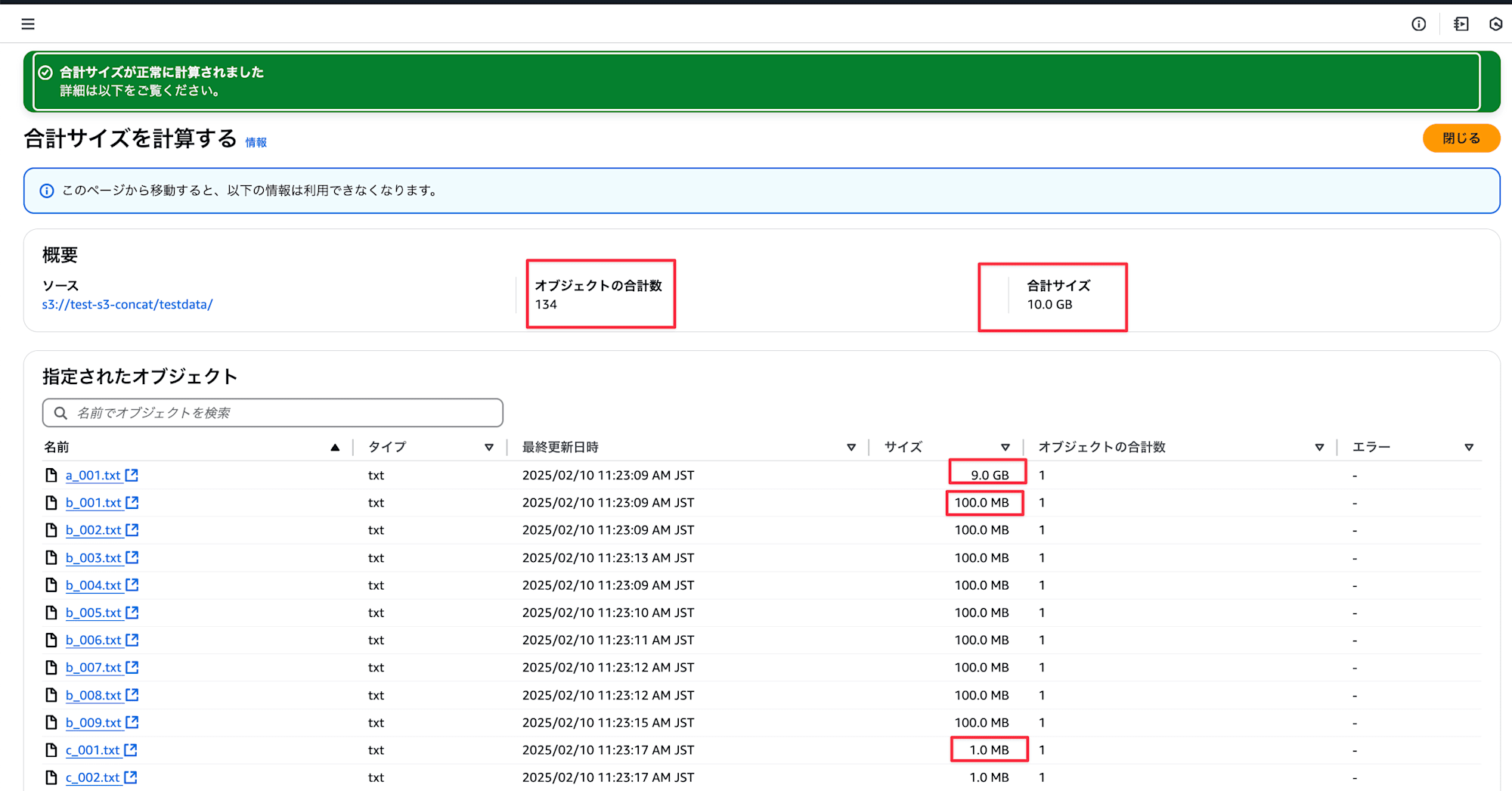
今回は以下のような S3 オブジェクトを用意します。
| サイズ | 個数 | 内容 | オブジェクト名 |
|---|---|---|---|
| 9 GiB | 1 | aaaa\n の繰り返し |
a_001.txt |
| 100 MiB | 9 | bbbb\n の繰り返し |
b_001.txt ~ b_009.txt |
| 1 MiB | 124 | cccc\n の繰り返し |
c_001.txt ~ c_124.txt |
合計 134 個、合計サイズは 10 GiB になります。
期待する結果は下表のとおりです。ファイルはあくまでアルファベットのどれかが先頭/末尾にあることで確認とし、実際の内容が正しく繋がっていれば問題ありません。
| ソート対象 | 昇順 (head) | 昇順 (tail) | 降順 (head) | 降順 (tail) |
|---|---|---|---|---|
| S3 オブジェクト名 | a | c | c | a |
テストファイルの作成
#!/bin/bash
mkdir -p testdata
yes "aaaa" | head -c $((9 * 1024 * 1024 * 1024)) > testdata/a_001.txt
# ---- 100MiBファイル(9個)----
# 行数 = 100MiB / 5バイト = 20971520 行
for i in $(seq -w 1 9); do
yes "bbbb" | head -n 20971520 > testdata/b_00${i}.txt
done
# ---- 1MiBファイル(124個)----
# サイズ指定で作るので最後は行の途中で切れます
for i in $(seq -w 1 124); do
yes "cccc" | head -c $((1024 * 1024)) > testdata/c_${i}.txt
done
./testdata.sh
出力されたファイルを確認します。
$ cd testdata
$ ls
a_001.txt b_005.txt c_001.txt c_006.txt ... c_122.txt
b_001.txt b_006.txt c_002.txt c_007.txt ... c_123.txt
b_002.txt b_007.txt c_003.txt c_008.txt ... c_124.txt
b_003.txt b_008.txt c_004.txt c_009.txt ...
b_004.txt b_009.txt c_005.txt c_010.txt ...
$ eza -l --binary | head -n 11
.rw-r--r--@ 9.0Gi ec2-user 10 Feb 02:17 a_001.txt
.rw-r--r--@ 100Mi ec2-user 10 Feb 02:17 b_001.txt
...
.rw-r--r--@ 1.0Mi ec2-user 10 Feb 02:17 c_001.txt
次に、S3 にアップロードします。
aws s3 sync . s3://test-s3-concat/testdata/
134 ファイル、合計 10 GB アップロードされていることを確認します。
TypeScript(Node.js)の実行は CloudShell 上で実施します。CloudShell のスペックは以下ですが、本ライブラリは 5 GiB 以上は S3 同士の UploadPartCopy を使用し、5 MiB 以下はすべてストリームで流すため、メモリやストレージが少ない環境でも実行可能です。
- 1 vCPU (仮想 CPU)
- 2 GiB RAM
- 1 GB の永続ストレージ
オブジェクト名昇順
import { S3Client } from '@aws-sdk/client-s3';
import { S3Concat } from 's3-concat';
const s3Client = new S3Client({});
const srcBucketName = 'test-s3-concat';
const dstBucketName = 'test-s3-concat';
const dstPrefix = 'destination';
const main = async () => {
const now = Date.now();
const s3Concat = new S3Concat({
s3Client,
srcBucketName: srcBucketName,
dstBucketName: dstBucketName,
dstPrefix,
concatFileName: `concatedfile_${now}.txt`,
pLimit: 10,
joinOrder: 'keyNameAsc',
});
await s3Concat.addFiles('testdata');
const result = await s3Concat.concat();
console.log(JSON.stringify(result));
};
await main();
実行すると、約 1 分半ほどで完了しました。
[cloudshell-user@ip-xx-xxx-xx-xxx s3-concat-esm]$ time npx tsx ./src/index.ts
{"kind":"concatenated","keys":[{"key":"destination/concatedfile_1739155059046.txt","size":10737418240}]}
real 1m25.758s
user 0m3.885s
sys 0m0.958s
S3 上に 10 GiB のファイルが作成されていることを確認します。
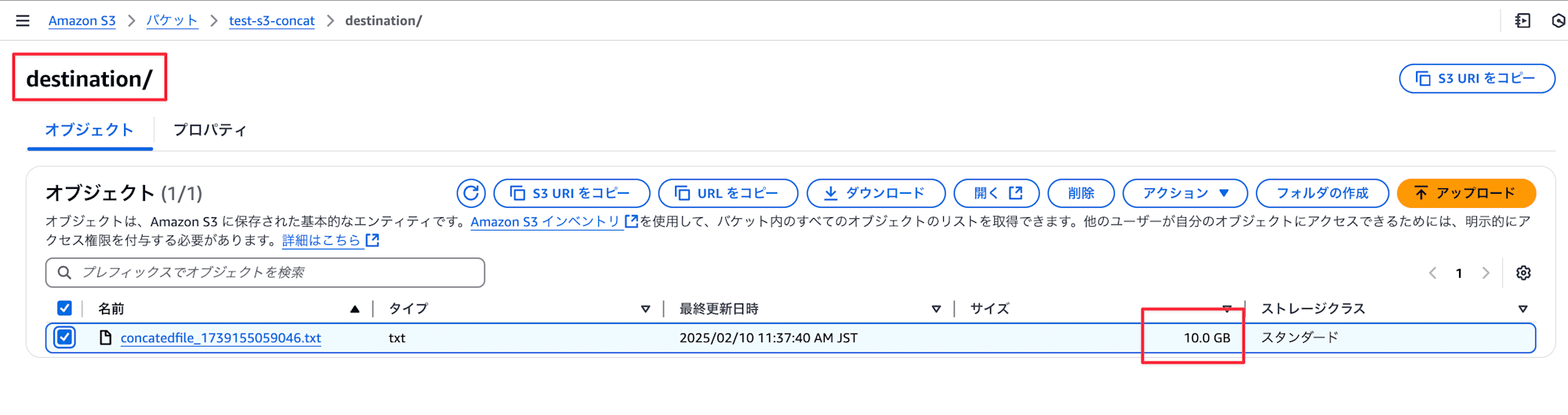
先頭に a_xxx.txt の内容、末尾に c_xxx.txt の内容が連結されていることを確認します。
$ head concatedfile_1739155059046.txt
aaaa
aaaa
aaaa
aaaa
aaaa
aaaa
aaaa
aaaa
aaaa
aaaa
$ tail concatedfile_1739155059046.txt
cccc
cccc
cccc
cccc
cccc
cccc
cccc
cccc
cccc
オブジェクト名降順
- joinOrder: 'keyNameAsc',
+ joinOrder: 'keyNameDesc',
[cloudshell-user@ip-xx-xxx-xx-xxx s3-concat-esm]$ time npx tsx ./src/index.ts
{"kind":"concatenated","keys":[{"key":"destination/concatedfile_1739155403235.txt","size":10737418240}]}
real 1m27.023s
user 0m3.850s
sys 0m0.839s
同様に S3 に 10 GiB ファイルが作成されており、先頭に c_xxx.txt、末尾に a_xxx.txt が連結されていることを確認します。
$ head concatedfile_1739155403235.txt
cccc
cccc
cccc
cccc
cccc
cccc
cccc
cccc
cccc
cccc
$ tail concatedfile_1739155403235.txt
aaaa
aaaa
aaaa
aaaa
aaaa
aaaa
aaaa
aaaa
aaaa
注意したところ
最終パート以外で 5 MiB 以下の S3 オブジェクトが見つかった場合
たとえば 5.0GiB + 0.1MiB のようなオブジェクトは、リクエスト上は 5.0 GiB 部分と 0.1 MiB 部分に分割して扱います。0.1 MiB 部分は最終的に GetObjectCommand のバイト指定でストリーム取得し、UploadPart で送信します。
5 MiB 未満のオブジェクト群は pipeline を使用してストリームを連結し、
その連結ストリームをそのまま UploadPart で送信しています。
連結対象オブジェクトが多い場合
Deque を採用した理由は、先頭への追加・取得が頻繁に発生するためです。以下は先頭への追加と取り出しを 50 万回ほど行った場合のベンチマークです。
---- 配列で unshift / shift ----
Array unshift: 21.085s
Array shift: 19.993s
---- Deque で pushFront / popFront ----
Deque pushFront: 6.598ms
Deque popFront: 2.736ms
ベンチマークソースコード
class Deque<T> {
private capacity: number;
private buffer: (T | undefined)[];
private head: number;
private tail: number;
private _size: number;
constructor(initialCapacity = 8) {
this.capacity = initialCapacity;
this.buffer = new Array<T | undefined>(this.capacity);
this.head = 0;
this.tail = 0;
this._size = 0;
}
public get size(): number {
return this._size;
}
public pushFront(item: T): void {
if (this._size === this.capacity) {
this.resize();
}
this.head = (this.head - 1 + this.capacity) % this.capacity;
this.buffer[this.head] = item;
this._size++;
}
public pushBack(item: T): void {
if (this._size === this.capacity) {
this.resize();
}
this.buffer[this.tail] = item;
this.tail = (this.tail + 1) % this.capacity;
this._size++;
}
public popFront(): T | undefined {
if (this._size === 0) {
return undefined;
}
const item = this.buffer[this.head];
this.buffer[this.head] = undefined;
this.head = (this.head + 1) % this.capacity;
this._size--;
return item;
}
public popBack(): T | undefined {
if (this._size === 0) {
return undefined;
}
this.tail = (this.tail - 1 + this.capacity) % this.capacity;
const item = this.buffer[this.tail];
this.buffer[this.tail] = undefined;
this._size--;
return item;
}
public front(): T | undefined {
if (this._size === 0) {
return undefined;
}
return this.buffer[this.head];
}
public back(): T | undefined {
if (this._size === 0) {
return undefined;
}
return this.buffer[(this.tail - 1 + this.capacity) % this.capacity];
}
private resize() {
const newCapacity = this.capacity * 2;
const newBuffer = new Array<T | undefined>(newCapacity);
for (let i = 0; i < this._size; i++) {
newBuffer[i] = this.buffer[(this.head + i) % this.capacity];
}
this.buffer = newBuffer;
this.head = 0;
this.tail = this._size;
this.capacity = newCapacity;
}
}
function performanceTest() {
const testSize = 500000;
const testArray: number[] = [];
const testDeque = new Deque<number>();
console.log(`\n---- 配列で unshift / shift ----`);
console.time('Array unshift');
for (let i = 0; i < testSize; i++) {
testArray.unshift(i);
}
console.timeEnd('Array unshift');
console.time('Array shift');
while (testArray.length > 0) {
testArray.shift();
}
console.timeEnd('Array shift');
console.log(`\n---- Deque で pushFront / popFront ----`);
console.time('Deque pushFront');
for (let i = 0; i < testSize; i++) {
testDeque.pushFront(i);
}
console.timeEnd('Deque pushFront');
console.time('Deque popFront');
while (testDeque.size > 0) {
testDeque.popFront();
}
console.timeEnd('Deque popFront');
}
performanceTest();
そのほか、非同期リクエスト数を調整できるよう pLimit を設けています。
弱点とその対応策
ストリームは再送できないのでネットワークが不安定な環境だと安定しづらいです。メモリは消費しますが、ストリームをやめてリトライ可能にするオプションをつけても良いと思います。1リクエストは5MiBなためです。ただ並行になると重くなるので、非同期リクエスト数の調整は必要になりそうです。
さいごに
今回は新機能の簡易的な利用例を紹介しました。実際、結合対象を配列で直接指定できた方が便利な気がしてました。需要があれば対応を検討していきます。
また、この実装を Go や Rust に移植し、CLI として提供することも近いうちに取り組みたいと思います。
問題があればこちらまでご報告頂ければと思います。









