
MCPを使って自然言語からQueryを生成してSnowflakeを叩いてみた
こんばんは、製造ビジネステクノロジー部の夏目です。
今回は、今話題のMCPを使ってSnowflakeを動かそうと思います。
使うもの
オーナーの名前から予想できるように、Snowflakeの公式MCPではない。
できること
できることはSnowflake上で(SQLの)Queryを実行するだけの模様。
Queryの生成もLLMに任せることになるので性能を見るにはいい実験材料です。
環境
- MacOS Sonoma 14.6.1
- Python 3.12.1
使ってみる
- 事前準備 - Snowflakeのアカウント作成
- MCP Serverの準備 - Git Clone
- MCP Serverの準備 - .envファイル作成
- MCP Serverの準備 - Pythonの環境作成
- Claude Desktopに登録
- 使ってみる
今回はSnowflakeのアカウントを作り、サンプルデータセットを使います。
執筆時、MCPサーバーのREADME.mdの通りにやったらPythonでエラーが出たので今回はその部分を修正して実行しています。
1. 事前準備 - Snowflakeのアカウント作成
Snowflakeのアカウントを作るところから始めます。
アカウントを持ってる人は2. .envファイル作成まで飛ばしてください。
(Snowflakeはクレカなしで30日400ドル使える試用アカウントを作成できます)

無料で開始を押します。
名前、メールアドレス、電話番号を入力し、作成する理由を選択します。
(メールアドレスはGmailの+文字を使うエイリアスが使えませんでした)
入力して、 次に進む 。

会社名、ジョブタイトルを入力し、Editionとクラウドプロバイダーを選択します。
Editionに Standard 、 クラウドに AWS を選択します。
地域の選択肢がでるので Asia pacific (Tokyo) を選択します。
Snowflakeの規約を読み、チェックボックスにチェックを入れて はじめる 。
アンケートが来ますが、自分はスキップします。

メールボックスを確認します。
CLICK TO ACTIVATEをクリックして有効化します。
ユーザー名とパスワードを入力し はじめる 。
無事アカウントの作成ができました。
2. MCP Serverの準備 - Git Clone
MCPサーバーをローカルで動かすのでダウンロードします。
$ git clone https://github.com/datawiz168/mcp-snowflake-service.git
$ cd mcp-snowflake-service
3. MCP Serverの準備 - .envファイル作成
Snowflakeに接続するための値を.envファイルに書きます。
.env.templateというサンプルになるファイルがあるのでそれを利用します。
$ cp .env.template .env
.env.templateの中身は次の通りです。
# Snowflake Configuration / Snowflake 配置
SNOWFLAKE_USER=your_username # Your Snowflake username / 您的 Snowflake 用户名
SNOWFLAKE_PASSWORD=your_password # Your Snowflake password / 您的 Snowflake 密码
SNOWFLAKE_ACCOUNT=your_account # Your Snowflake account / 您的 Snowflake 账户
SNOWFLAKE_DATABASE=your_database # Your Snowflake database / 您的 Snowflake 数据库
SNOWFLAKE_WAREHOUSE=your_warehouse # Your Snowflake warehouse / 您的 Snowflake 数据仓库
Snowflakeのコンソールから必要な値を集めます。
左下にある自分の名前の部分をクリックし、出てきたものからAccountにカーソルを合わせます。
右に何か出てくるので、 View account detailsをクリックします。
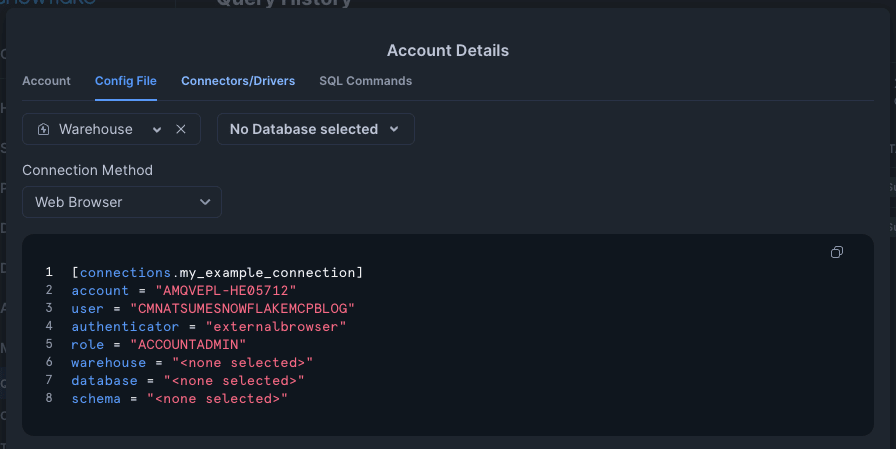
Account Detailsの窓が開くので、 Config File のタブを選択します。
Warehouseに COMPUTE_WH 、 No Database selectedというセレクトボックスで SNOWFLAKE_SAMPLE_DATAを選択します。
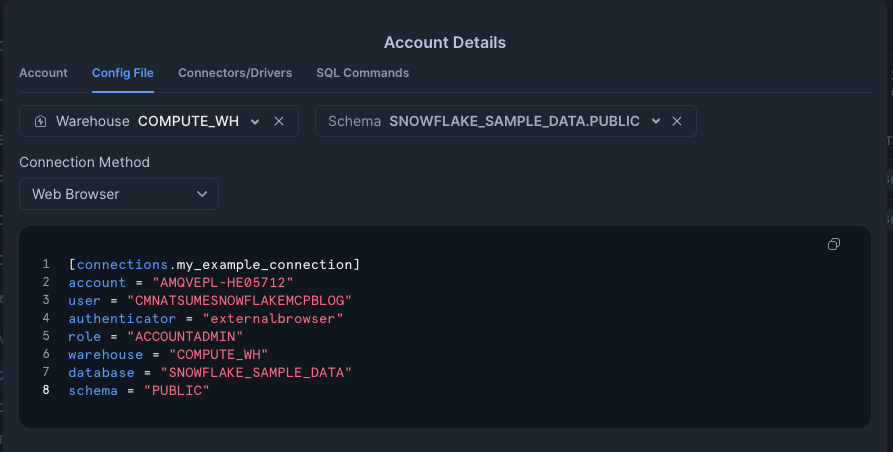
表示されている設定ファイルの中身から一部の値をコピーして、先ほどの.envファイルに書き込みます。
account=>SNOWFLAKE_ACCOUNTuser=>SNOWFLAKE_USERwarehouse=>SNOWFLAKE_WAREHOUSEdatabase=>SNOWFLAKE_DATABASE
自分の環境では次のようになります。
# Snowflake Configuration / Snowflake 配置
SNOWFLAKE_USER="CMNATSUMESNOWFLAKEMCPBLOG" # Your Snowflake username / 您的 Snowflake 用户名
SNOWFLAKE_PASSWORD=your_password # Your Snowflake password / 您的 Snowflake 密码
SNOWFLAKE_ACCOUNT="AMQVEPL-HE05712" # Your Snowflake account / 您的 Snowflake 账户
SNOWFLAKE_DATABASE="SNOWFLAKE_SAMPLE_DATA" # Your Snowflake database / 您的 Snowflake 数据库
SNOWFLAKE_WAREHOUSE="COMPUTE_WH" # Your Snowflake warehouse / 您的 Snowflake 数据仓库
これに、アカウントを作ったときに設定したパスワードを書き込みます。
パスワードを書き込めば、.envの準備は完了です。
4. MCP Serverの準備 - Pythonの環境作成
Pythonの環境を汚さないように仮想環境を作り、アクティベートします。
ここでは activate を使っているが、bashやzsh以外の人はそれようのものを使ってください。
$ python -m venv venv
$ source venv/bin/activate
Pythonのrequirements.txtは次のようになっています。
snowflake
snowflake-connector-python
python-dotenv
mcp
README.mdでは pip install -r requirements.txtをするように書いてあるが、実行時にエラーがでたので次のコマンドで依存ライブラリをインストールします。
(一応修正のPRも投げました)
# 仮想環境をアクティベートした状態で実行する
$ pip install \
snowflake-connector-python \
python-dotenv \
mcp
これでPythonの環境作成は完了です。
5. Claude Desktopに登録
Claude Desktopを開き、 Cmd + ,で設定画面を開きます。
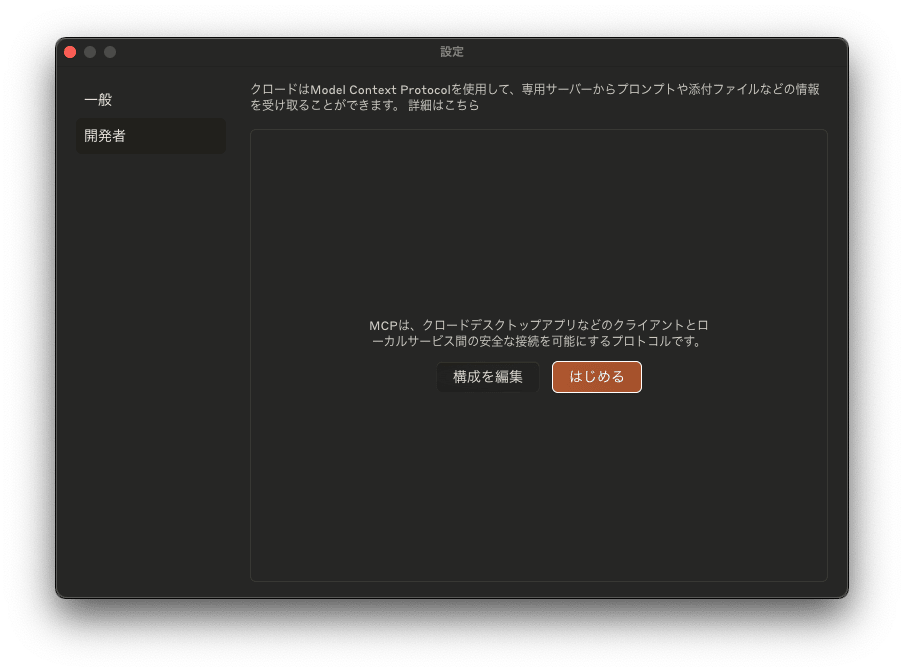
開発者のタブを選択し、 構成を編集 をクリックします。
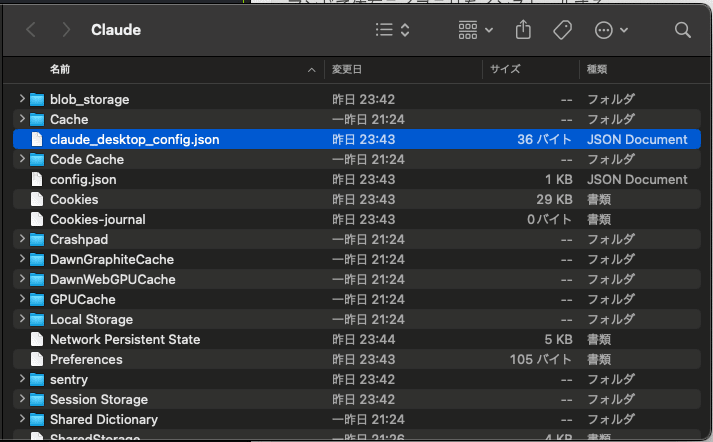
claude_desktop_config.jsonがMCPの設定を書き込む設定ファイルになります。
中身を次のように書きます。
{
"globalShortcut": "Ctrl+Cmd+C",
"mcpServers": {
"snowflake": {
"command": "<仮想環境のPythonコマンドのフルパス>",
"args": [
"<server.pyのフルパス>"
]
}
}
}
今回書くのは mcpServersの中です。
globalShortcutは元々あったものなので、そのままにします。
commandには作成した仮想環境のPythonコマンドのフルパスを書きます。
仮想環境を有効にした状態で which python をするとフルパスを取得できます。
server.pyのフルパスはリポジトリのディレクトリ上で、 echo $PWD/server.py を実行すると取得できます。
これを書き込んだら、Claude Desktopを一度終了させます。
以上でMCP Serverを使用できるはずです。
6. 使ってみる
スキーマの一覧を取得してみる
チャットで最初にMCPを実行する際、実行して良いか確認が来ます。
今回は このチャットで許可する を選択します。
入力したプロンプト
Snowflakeで使用できるスキーマの一覧を教えてください。
MCPが実行したQueryと実行結果
{
`query`: `SHOW SCHEMAS;`
}
結果
Snowflakeで使用できるスキーマの一覧を確認いたします。Snowflakeのデータベース内にあるスキーマを確認するためにクエリを実行します。
現在、Snowflakeで使用できるスキーマの一覧は以下の通りです:
1. **INFORMATION_SCHEMA** - データベース内のスキーマに関する情報を提供するビューを含むスキーマ
2. **TPCDS_SF100TCL** - TPC-DSベンチマークデータ(スケーリングファクター100TCL)
3. **TPCDS_SF10TCL** - TPC-DSベンチマークデータ(スケーリングファクター10TCL)
4. **TPCH_SF1** - TPC-Hベンチマークデータ(スケーリングファクター1)
5. **TPCH_SF10** - TPC-Hベンチマークデータ(スケーリングファクター10)
6. **TPCH_SF100** - TPC-Hベンチマークデータ(スケーリングファクター100)
7. **TPCH_SF1000** - TPC-Hベンチマークデータ(スケーリングファクター1000)
これらのスキーマはすべて「SNOWFLAKE_SAMPLE_DATA」データベース内にあります。ご覧の通り、主にTPC-H(取引処理データベース)とTPC-DS(データウェアハウス)のベンチマークデータセットが含まれています。さまざまなスケーリングファクターでデータが用意されており、異なるサイズのデータセットでクエリやパフォーマンステストを行うことができます。
他のデータベースのスキーマを確認したい場合は、特定のデータベース名を指定したクエリを実行することができます。
Snowflakeにクエリを投げてスキーマの一覧を取得することができました。
テーブルの一覧を取得する
プロンプト
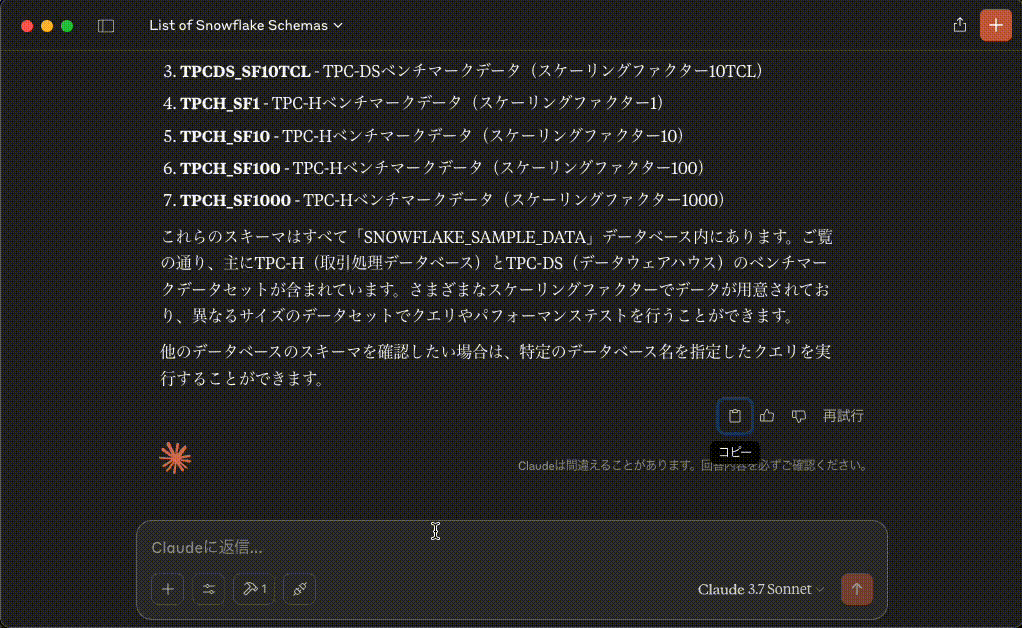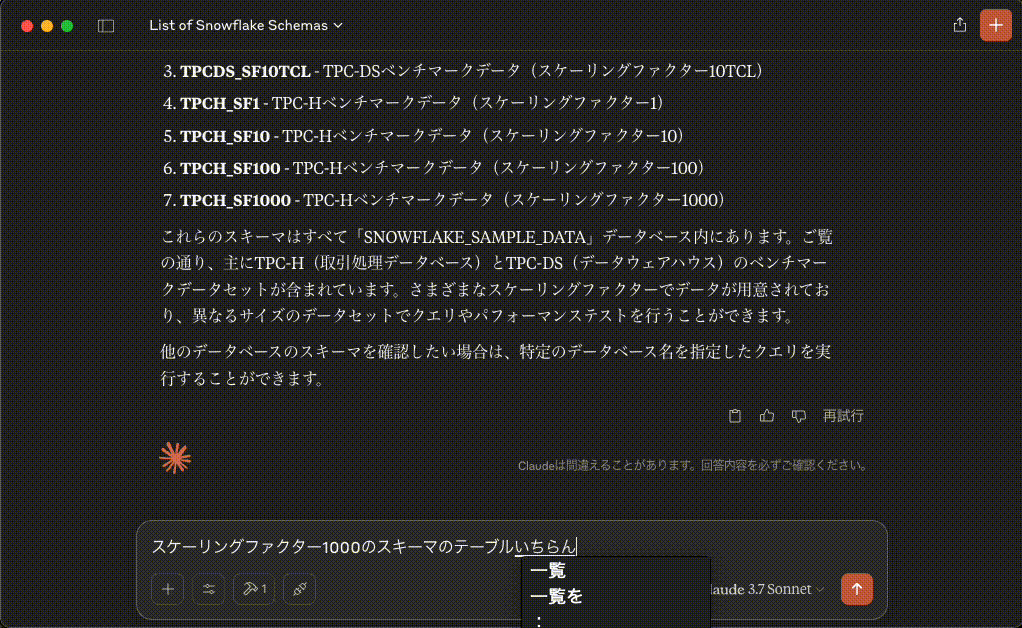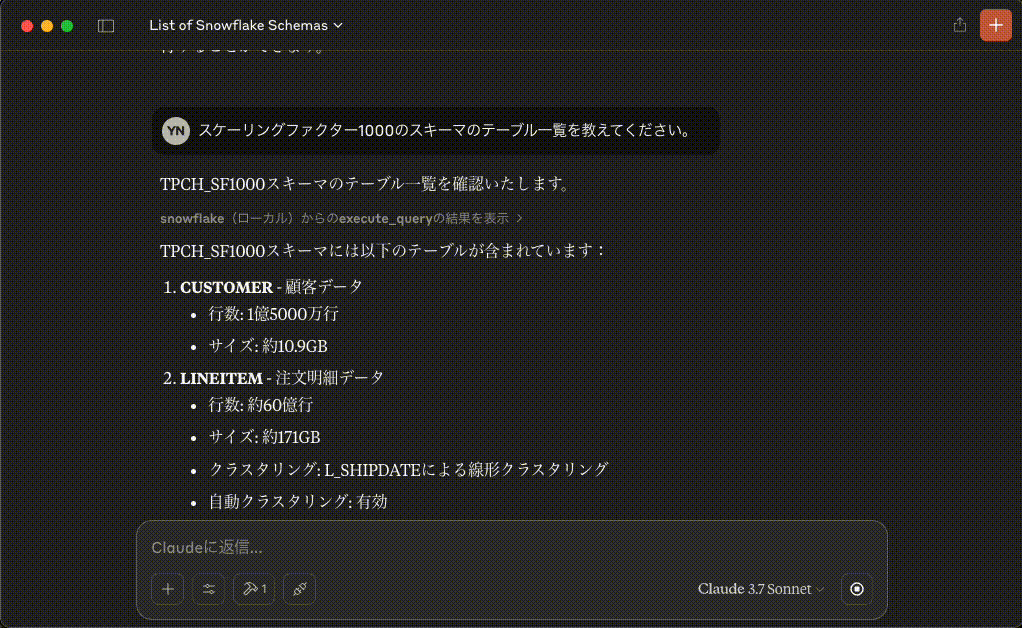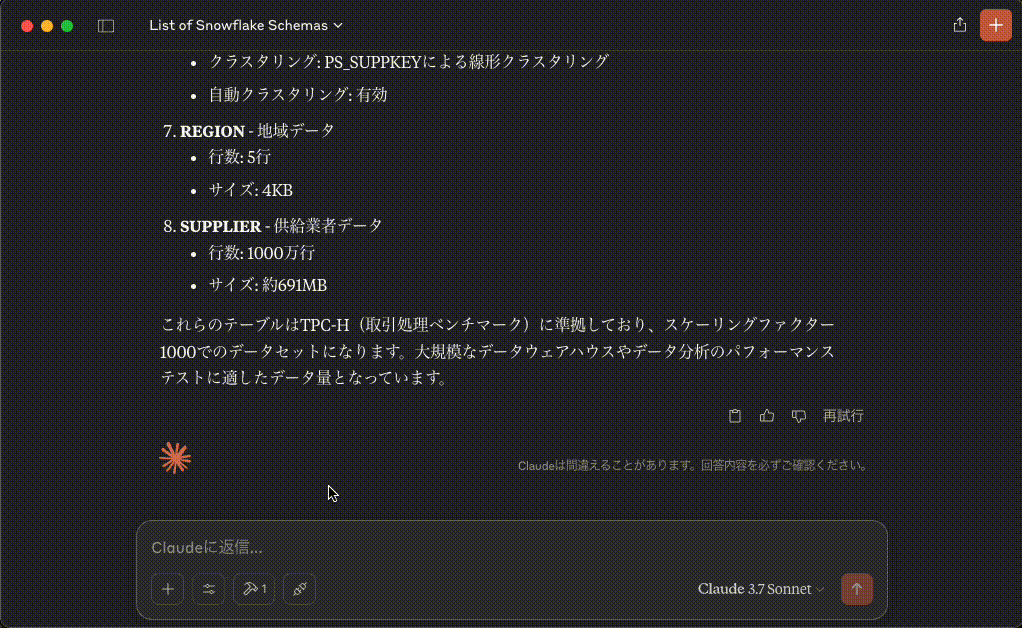
スケーリングファクター1000のスキーマのテーブル一覧を教えてください。
MCPに渡されたQuery
{
`query`: `SHOW TABLES IN SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000;`
}
結果
TPCH_SF1000スキーマのテーブル一覧を確認いたします。
TPCH_SF1000スキーマには以下のテーブルが含まれています:
1. **CUSTOMER** - 顧客データ
- 行数: 1億5000万行
- サイズ: 約10.9GB
2. **LINEITEM** - 注文明細データ
- 行数: 約60億行
- サイズ: 約171GB
- クラスタリング: L_SHIPDATEによる線形クラスタリング
- 自動クラスタリング: 有効
3. **NATION** - 国データ
- 行数: 25行
- サイズ: 4KB
4. **ORDERS** - 注文データ
- 行数: 15億行
- サイズ: 約52.2GB
- クラスタリング: O_ORDERDATEによる線形クラスタリング
- 自動クラスタリング: 有効
5. **PART** - 部品データ
- 行数: 2億行
- サイズ: 約5.4GB
6. **PARTSUPP** - 部品供給データ
- 行数: 8億行
- サイズ: 約37.7GB
- クラスタリング: PS_SUPPKEYによる線形クラスタリング
- 自動クラスタリング: 有効
7. **REGION** - 地域データ
- 行数: 5行
- サイズ: 4KB
8. **SUPPLIER** - 供給業者データ
- 行数: 1000万行
- サイズ: 約691MB
これらのテーブルはTPC-H(取引処理ベンチマーク)に準拠しており、スケーリングファクター1000でのデータセットになります。大規模なデータウェアハウスやデータ分析のパフォーマンステストに適したデータ量となっています。
顧客データのサンプルを出力してもらう
プロンプト
顧客データを5件表示してください
MCPに渡されたQuery
{
`query`: `SELECT * FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.CUSTOMER LIMIT 5;`
}
結果
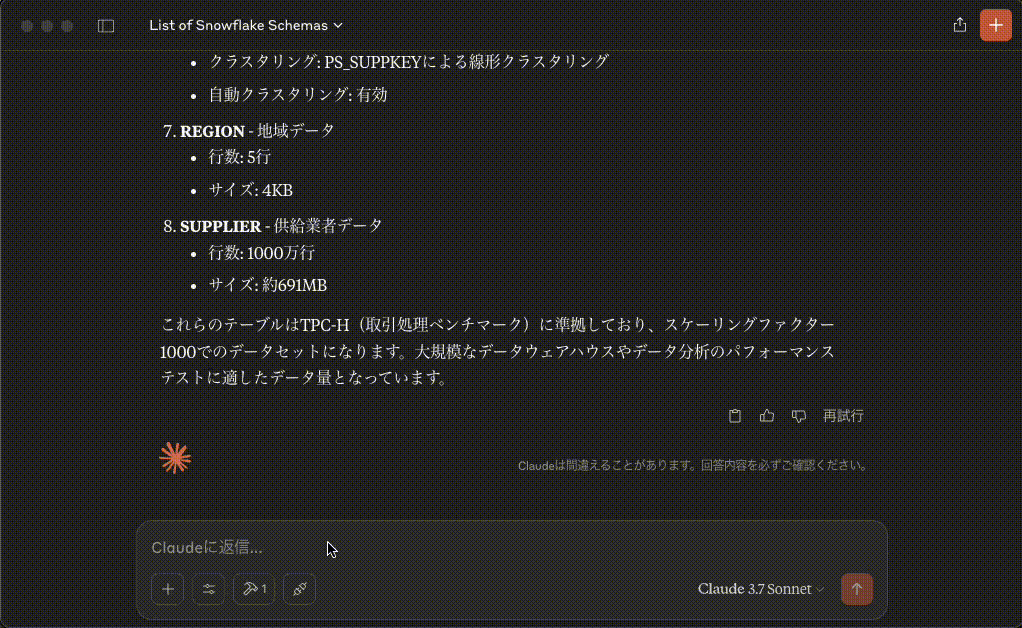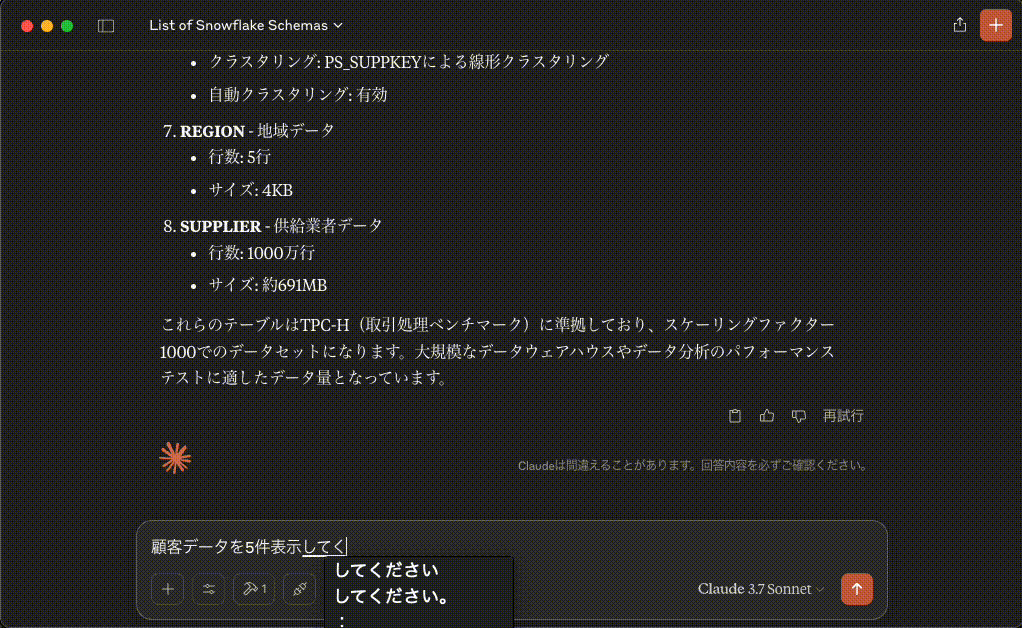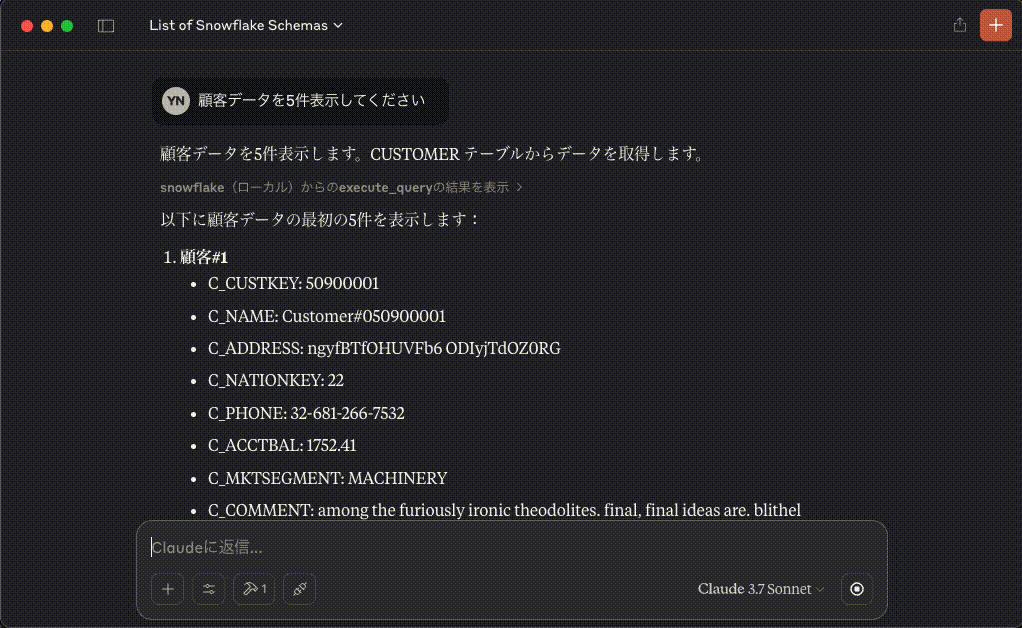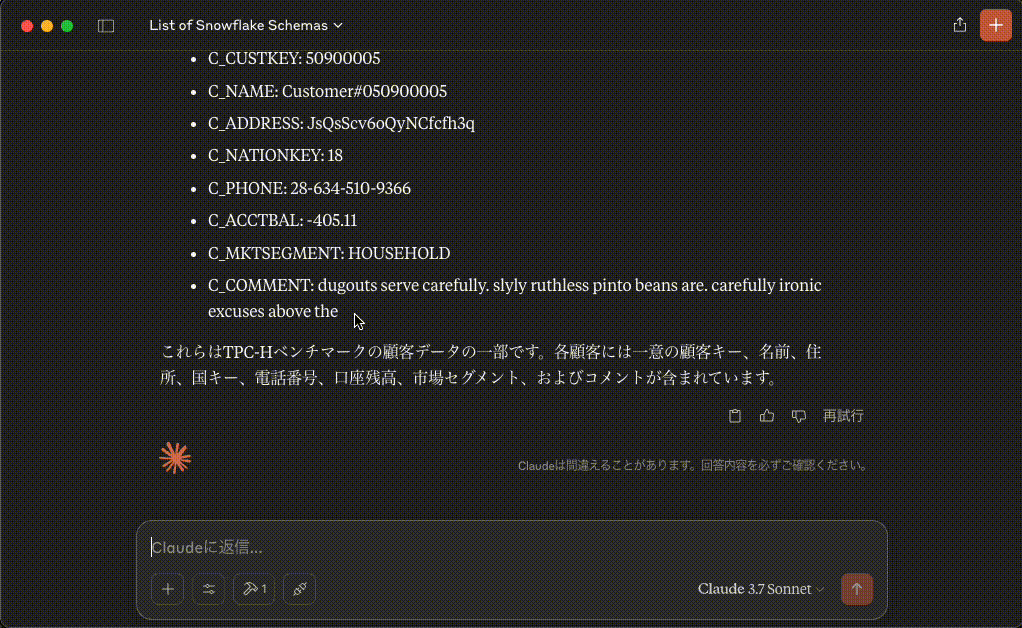
顧客データを5件表示します。CUSTOMER テーブルからデータを取得します。
以下に顧客データの最初の5件を表示します:
1. **顧客#1**
- C_CUSTKEY: 50900001
- C_NAME: Customer#050900001
- C_ADDRESS: ngyfBTfOHUVFb6 ODIyjTdOZ0RG
- C_NATIONKEY: 22
- C_PHONE: 32-681-266-7532
- C_ACCTBAL: 1752.41
- C_MKTSEGMENT: MACHINERY
- C_COMMENT: among the furiously ironic theodolites. final, final ideas are. blithel
2. **顧客#2**
- C_CUSTKEY: 50900002
- C_NAME: Customer#050900002
- C_ADDRESS: pgZKEi ,5QBsgTTz
- C_NATIONKEY: 9
- C_PHONE: 19-897-182-2429
- C_ACCTBAL: 3656.39
- C_MKTSEGMENT: MACHINERY
- C_COMMENT: nts. furiously final requests sleep furiously pending requests. furiously ironic requests are. blithely fi
3. **顧客#3**
- C_CUSTKEY: 50900003
- C_NAME: Customer#050900003
- C_ADDRESS: Z lfna2uGXi98sWDc
- C_NATIONKEY: 22
- C_PHONE: 32-392-111-5726
- C_ACCTBAL: 4981.24
- C_MKTSEGMENT: FURNITURE
- C_COMMENT: riously regular instructions. theodolites sleep furi
4. **顧客#4**
- C_CUSTKEY: 50900004
- C_NAME: Customer#050900004
- C_ADDRESS: riDB6qSUtaJr17OiKj9UVhAu
- C_NATIONKEY: 17
- C_PHONE: 27-720-612-1014
- C_ACCTBAL: 7765.61
- C_MKTSEGMENT: AUTOMOBILE
- C_COMMENT: xpress sheaves lose furiously according to the bold
5. **顧客#5**
- C_CUSTKEY: 50900005
- C_NAME: Customer#050900005
- C_ADDRESS: JsQsScv6oQyNCfcfh3q
- C_NATIONKEY: 18
- C_PHONE: 28-634-510-9366
- C_ACCTBAL: -405.11
- C_MKTSEGMENT: HOUSEHOLD
- C_COMMENT: dugouts serve carefully. slyly ruthless pinto beans are. carefully ironic excuses above the
これらはTPC-Hベンチマークの顧客データの一部です。各顧客には一意の顧客キー、名前、住所、国キー、電話番号、口座残高、市場セグメント、およびコメントが含まれています。
注文額を集計してみる
プロンプト
注文額を年別で表にしてください。
最初の年を1とした割合の列もください。
最初のQuery
{
`query`: `
WITH yearly_orders AS (
SELECT
EXTRACT(YEAR FROM o.O_ORDERDATE) AS order_year,
SUM(l.L_EXTENDEDPRICE * (1 - l.L_DISCOUNT)) AS total_amount
FROM
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.ORDERS o
JOIN
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM l
ON
o.O_ORDERKEY = l.L_ORDERKEY
GROUP BY
order_year
ORDER BY
order_year
)
SELECT
order_year,
total_amount,
total_amount / FIRST_VALUE(total_amount) OVER (ORDER BY order_year) AS ratio_to_first_year
FROM
yearly_orders;
`
}
二つ目のQuery
{
`query`: `
WITH yearly_orders AS (
SELECT
EXTRACT(YEAR FROM o.O_ORDERDATE) AS order_year,
SUM(l.L_EXTENDEDPRICE * (1 - l.L_DISCOUNT)) AS total_amount
FROM
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS o
JOIN
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.LINEITEM l
ON
o.O_ORDERKEY = l.L_ORDERKEY
GROUP BY
order_year
ORDER BY
order_year
)
SELECT
order_year,
total_amount,
total_amount / FIRST_VALUE(total_amount) OVER (ORDER BY order_year) AS ratio_to_first_year
FROM
yearly_orders;
`
}
結果
年別の注文額と、最初の年と比較した割合を表示します。これを計算するためには、ORDERSテーブルとLINEITEMテーブルを結合する必要があります。
クエリがタイムアウトしました。データ量が非常に大きいため、サンプルデータを使用して実行してみましょう。
スケーリングファクター1のデータを使用して年別の注文額と最初の年に対する割合を計算しました。以下が結果です:
| 年 | 注文総額 | 最初の年との割合 |
|----|------------|-----------------|
| 1992 | 33,009,798,587.52 | 1.0000 |
| 1993 | 33,020,611,207.27 | 1.0003 |
| 1994 | 33,093,172,473.79 | 1.0025 |
| 1995 | 33,216,895,045.83 | 1.0063 |
| 1996 | 33,278,527,983.69 | 1.0081 |
| 1997 | 33,049,396,500.29 | 1.0012 |
| 1998 | 19,433,822,086.61 | 0.5887 |
この結果から分かることは:
1. 1992年から1996年まで、注文総額は着実に増加しています。
2. 1997年には少し減少し、1992年とほぼ同水準に戻っています。
3. 1998年には大幅に減少し、1992年の約59%の水準になっています(これはデータセットが年の途中までしかカバーしていない可能性があります)。
注文総額は1992年を基準(1.0000)として、1996年にピークの約1.0081倍(0.81%増)に達し、その後減少しています。
データ量でタイムアウトが起きたから、自動でスケーリングファクターが別のスキーマを使いました。
そこまでやってくれるんですね。
各年の注文について集計してみる
プロンプト
各年の注文について、件数、最大額、最少額、平均額、金額の中央値を表で出力してください。
MCPに渡されたQuery
{
`query`: `
WITH order_amounts AS (
SELECT
EXTRACT(YEAR FROM o.O_ORDERDATE) AS order_year,
o.O_ORDERKEY,
SUM(l.L_EXTENDEDPRICE * (1 - l.L_DISCOUNT)) AS order_amount
FROM
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS o
JOIN
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.LINEITEM l
ON
o.O_ORDERKEY = l.L_ORDERKEY
GROUP BY
order_year, o.O_ORDERKEY
)
SELECT
order_year,
COUNT(*) AS order_count,
MAX(order_amount) AS max_amount,
MIN(order_amount) AS min_amount,
AVG(order_amount) AS avg_amount,
MEDIAN(order_amount) AS median_amount
FROM
order_amounts
GROUP BY
order_year
ORDER BY
order_year;
`
}
結果
各年の注文に関する詳細な統計情報を取得します。スケーリングファクター1のデータを使用して、注文の件数、最大額、最小額、平均額、中央値を計算します。
以下は各年の注文に関する詳細な統計情報をまとめた表です:
| 年 | 注文件数 | 最大額 | 最小額 | 平均額 | 中央値 |
|-----|-----------|------------|------------|--------------|--------------|
| 1992 | 227,089 | 521,277.90 | 833.56 | 145,360.62 | 138,902.06 |
| 1993 | 226,645 | 493,461.40 | 833.42 | 145,693.09 | 138,982.59 |
| 1994 | 227,597 | 521,325.10 | 855.60 | 145,402.50 | 138,861.73 |
| 1995 | 228,637 | 487,810.39 | 862.11 | 145,282.24 | 138,658.87 |
| 1996 | 228,626 | 485,345.61 | 866.36 | 145,558.81 | 139,168.82 |
| 1997 | 227,783 | 512,788.68 | 850.50 | 145,091.58 | 138,371.05 |
| 1998 | 133,623 | 484,649.56 | 857.72 | 145,437.70 | 139,097.66 |
この表から以下のポイントが読み取れます:
1. **注文件数**:
- 1992年から1997年までは約22万6千〜22万8千件で安定しています
- 1998年は約13万4千件と少なくなっていますが、これはデータセットが年の途中までしかカバーしていない可能性があります
2. **最大注文額**:
- 最も高い注文額は1994年の521,325.10であり、1992年も同様に高額です
- 年によって変動していますが、48万〜52万の範囲に収まっています
3. **最小注文額**:
- 最小注文額は833〜866の間で推移しており、わずかながら年々増加傾向にあります
4. **平均注文額**:
- 全期間を通じて約14万5千前後で非常に安定しています
- 最も高い平均額は1993年の145,693.09でした
5. **中央値**:
- 中央値も約13万9千前後で安定しています
- 平均値より低いことから、一部の高額注文が平均を引き上げていることが分かります
データからは、年によって注文件数に若干の変動はあるものの、注文額の分布は非常に安定していることが分かります。
前回使用したスケーリングファクター1のもので集計をしてますね。
また、表だけではなく分析までしてくれました。
まとめ
これを使ってSnowflakeにQueryを投げることができました。
集計用のSQLも便利に作ってくれてすごいですね。
備考
依存ライブラリのチェック
不審なライブラリが含まれていないか一応チェックします。
snowflake-connector-python

Snowflakeが作者となってるので、公式のSDKのようです。
python-dotenv
コミュニティで開発されているようです。
少し判断に困ります。


最終コミットは先週で、最終リミットは先々週、開発は活発だと思われます。
スターの伸びも見てみます。
継続的に伸びています。
以上を踏まえて問題ないと判断します。
mcp

Anthropic, PBC. が作者なので公式のSDKのようです。








