![[SPS311] 生成 AI を使用したワークロードの運用レジリエンスの構築 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[SPS311] 生成 AI を使用したワークロードの運用レジリエンスの構築 #AWSreInvent
こんにちは。
製造ビジネスのテクノロジー部スマートファクトリーチームの田中孝明です。
AWS re:Invent 2025 で参加したワークショップ [SPS311] 生成 AI を使用したワークロードの運用レジリエンスの構築の内容を整理してご紹介します。
セッション概要
運用のレジリエンス(回復力)を構築するには、リスクを積極的に特定し、軽減する必要があります。このワークショップでは、AWS マネージド Generative AI サービスを実際のシナリオで使用し、準備状況の評価、アーキテクチャの積極的な改善、イベントへの迅速な対応、問題のトラブルシューティング、効果的な可観測性プラクティスの実装方法を学びます。また、AWS Countdown と AWS Well-Architected フレームワークを、運用における Generative AI サービスの利用開始時のリファレンスフレームワークとして活用します。実践的なアクティビティを通じて、問題のデバッグ、異常やインシデントの検出、アーキテクチャの最適化によるワークロードのレジリエンス向上のための戦略を学びます。ご参加にはノートパソコンをご持参ください。
想定シナリオとワークショップの目的
参加者は、クラウド・センター・オブ・エクセレンス(CCoE)チームの主要メンバーという設定です。ミッションは以下のような、かなり現実的なものです。
- ビジネスクリティカルな社内アプリケーションを間もなくリリース
- 組織全体で数千人のユーザーが利用予定
- 現在は単一 EC2 インスタンス構成で、本番向きではない
- リリース当日はピーク時に 1 秒あたり 2,500 接続を想定
- 現在の構成でどこまで耐えられるか不明
- 評価・再設計・実装に使える時間は限られている
ここで AWS と、エージェント型 AI の Kiro がテクニカルパートナーとして登場します。
AWS Countdown プロセスを導入し、インシデント検知・対応体制のオンボーディングを行いつつ、 生成 AI を活用して分析を加速し、評価を自動化し従来の手動アプローチより短時間で改善を行うという流れです。
何を構築するのか
最適化されていない単一インスタンス構成からスタートし、 AWS Countdown と AWS Well-Architected Framework のベストプラクティスを適用して、 本番対応の高い耐障害性を持つシステムへと作り変えていきます。
パフォーマンス要件
- 1 秒あたり 2,500 の同時接続を処理
- 平均レスポンス時間を 250 ミリ秒以下に維持
- 99.5 % 以上の成功率を達成
回復力(レジリエンス)要件
- 単一アベイラビリティゾーン(AZ)障害に対してフォールトトレラントであること
- AZ フェイルオーバー中のダウンタイムは最大 1 分
- RTO(目標復旧時間): 2 時間
- RPO(目標復旧時点): 10 分
Generative AI と MCP
このワークショップでは、生成 AI と MCP を組み合わせて運用レジリエンスの実務を体験できました。
Generative AI の役割
Generative AI は、テキスト、コード、設定ファイルなどの新しいコンテンツを生成し、 単なる定型分析にとどまらず、人間に近い形で提案やアウトプットを作ることができます。
ワークショップでは特に以下のような場面で活用します。
- 既存インフラストラクチャの分析
- ベストプラクティスに基づく改善提案
- 変更内容の具体的な実装手順(コードや設定ファイル、Draw.io で開けるアーキテクチャ図)の生成
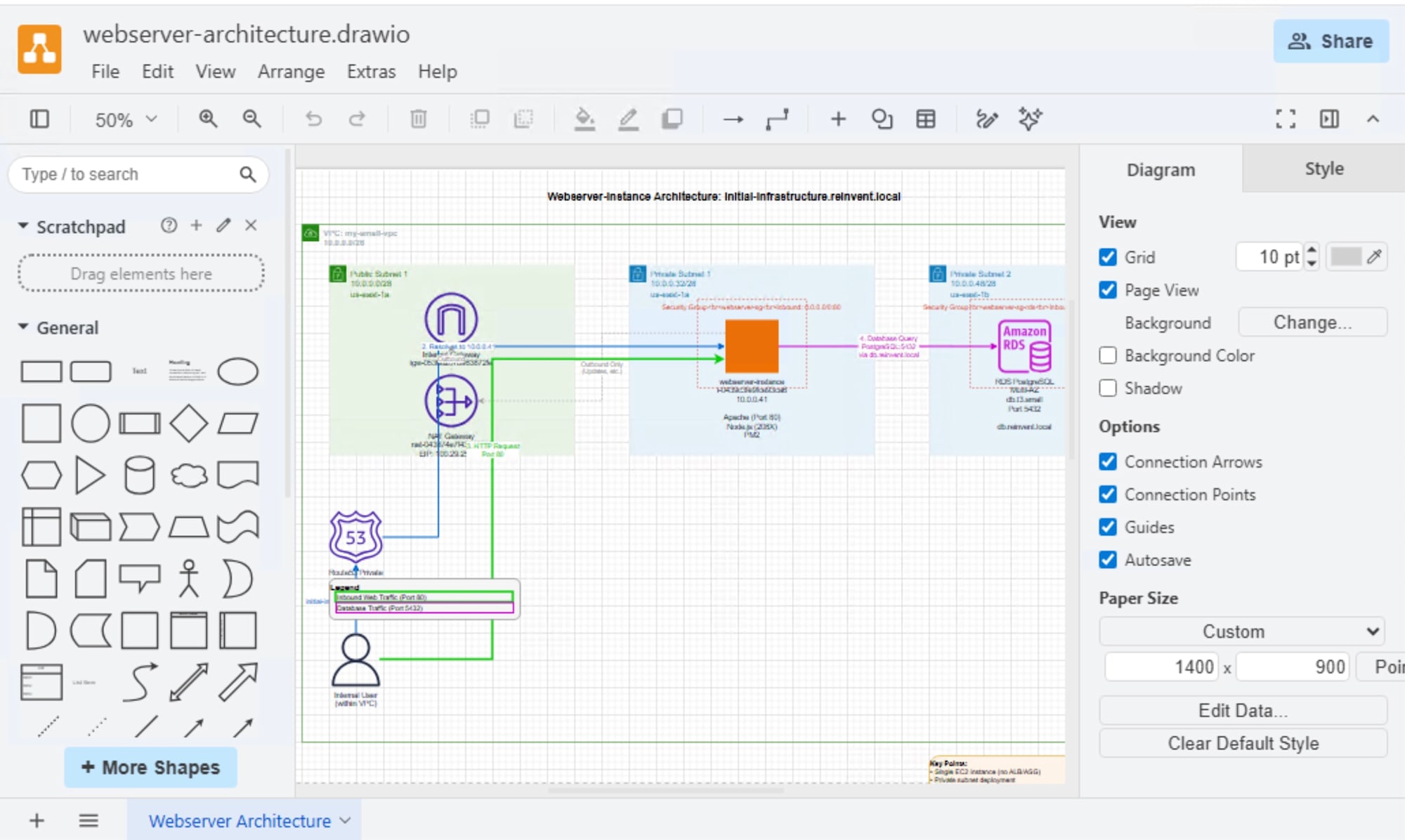
MCP とは
MCP(Model Context Protocol)は、 LLM アプリケーションと外部データソース・ツールの間をつなぐオープンプロトコルです。
MCP サーバーが標準化されたインターフェースとなることで、 Kiro のような AI アシスタントが AWS 環境と対話できるようになります。
- AWS 設定の読み取り
- スクリプトの実行
- 実行結果やメトリクスのリアルタイム監視
このワークショップでは、以下の 3 つの MCP サーバーを利用しました。
Kiro IDE
Kiro は IDE と CLI を備えたエージェント型 AI で、 仕様駆動開発によりプロトタイプから本番環境までの移行を支援するツールです。
- ユーザーのプロンプトを詳細な仕様に落とし込む
- 仕様から実用的なコード、ドキュメント、テストコードを生成
- チームで共有できるレベルの成果物まで一気に持っていける
Kiro のエージェントは、以下のようなタスクを支援・自動化します。
- 難易度の高い技術課題の分解・解決支援
- 技術ドキュメントの生成
- ユニットテストの自動生成と補助
これにより、プロトタイプ段階だけでなく、 開発ライフサイクル全体を通して、エンジニアが主導権を握りながら開発を進められるようになります。
運用レジリエンスにおける Kiro の価値
運用レジリエンスは、「障害を起こさないこと」だけが目的ではありません。
不可避な問題が起きたときに、どれだけ早く状況を理解できるか、どれだけ早く原因を診断できるか、どれだけ早く解決策を実施できるかが重要になります。
Kiro は、コードベースと AWS 環境の両方を理解している AI ペアプログラマー として機能します。
- インフラストラクチャコード(Terraform、CDK、CloudFormation)のデバッグ
- テンプレートのレビューと改善提案
- Runbook の作成支援
- 本番障害発生時のトラブルシューティング補助
これらを通じて、作業スピードの向上とヒューマンエラーの低減に貢献します。
Kiro IDE はワークショップ用の Windows EC2 インスタンスにプリインストールされており、AWS SSM Fleet Manager からそのインスタンスに接続して利用します。
CLI での操作方法も記載されていました。
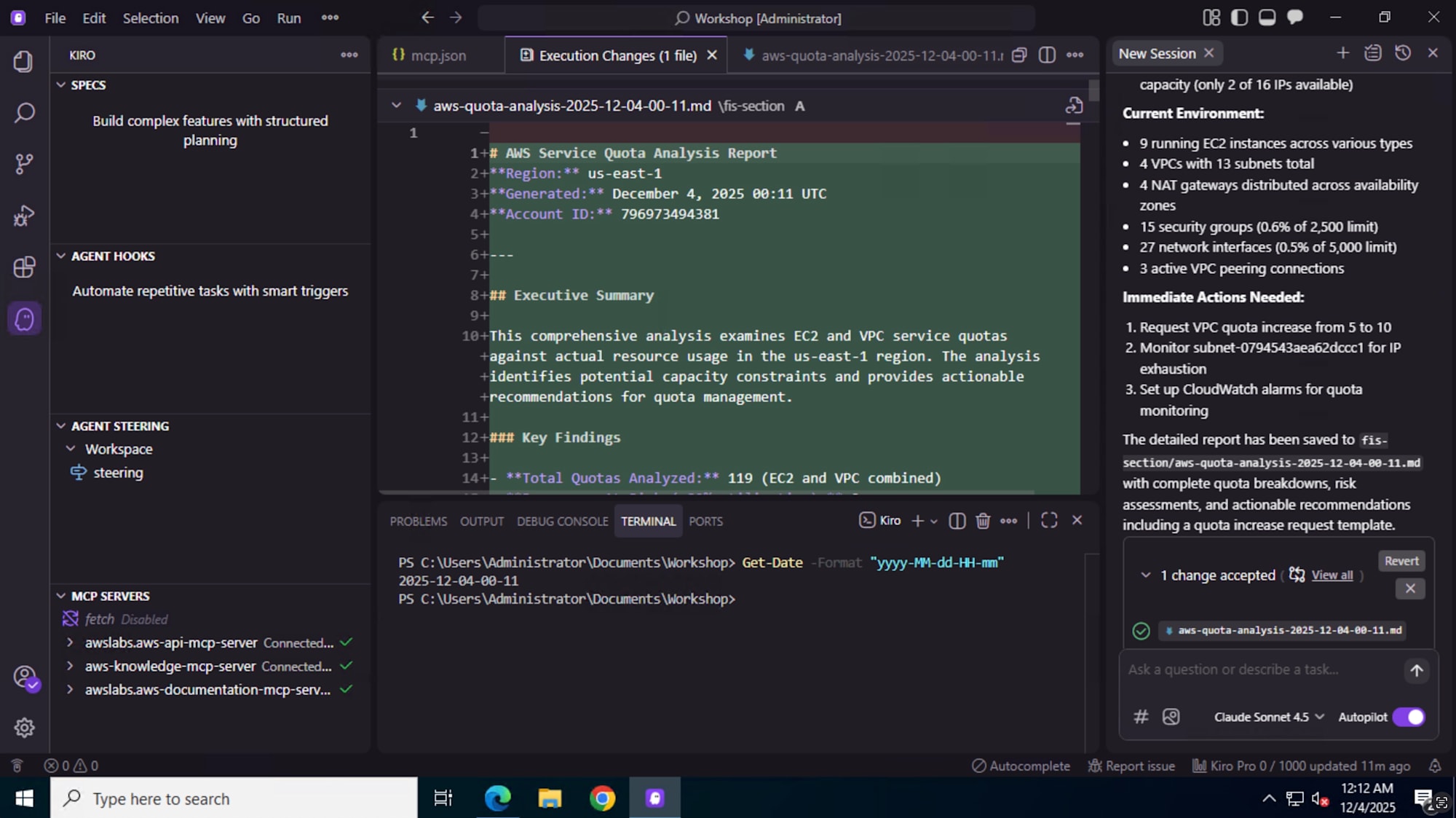
Kiro からサービスクォータを確認する
Kiro を AWS MCP Server と連携させることで、 サービスクォータの確認や増加申請プロセスの支援も可能になります。
- サービスクォータには、AWS マネジメントコンソールから直接アクセス可能
- 現在値の確認だけでなく、クォータ増加リクエストもコンソールから実行可能
- Kiro 経由で「どのクォータがボトルネックになっているか」「どのクォータを増やすべきか」の分析や案内を受けられる
こうした情報を生成 AI からインタラクティブに扱えることで、 キャパシティプランニングやリリース前チェックが効率化されます。
初期アーキテクチャ、可観測性、負荷テストの評価
ワークショップの構成としては、AWS コンソールを直接操作する従来型の手順と Kiro のチャット画面から指示を出して実施する手順の 2 パターンが用意されています。
コンソール操作は「参考実装」として示されており、 主眼は「Kiro にどこまで任せられるか」「どれくらい手間が減るか」を体感することに置かれています。
AWS ユーザー通知の追加
運用レジリエンスには、インシデント発生時に関係者へ即時に通知が届くことが不可欠です。
ワークショップでは、CloudWatch アラームやインシデント検知と連携した通知設定の追加を行います。
- 通知チャネルの設定(メール、Slack など)
- 通知内容の整備(どのメトリクス・どの閾値で通知するか)
- 通知を受けてからの Runbook(初動対応手順)のひな型作成
このあたりも Kiro によるテンプレート生成・設定支援が可能で、 「何を、どの閾値で監視するべきか」を AI と指示しながら決めていく流れになっていました。
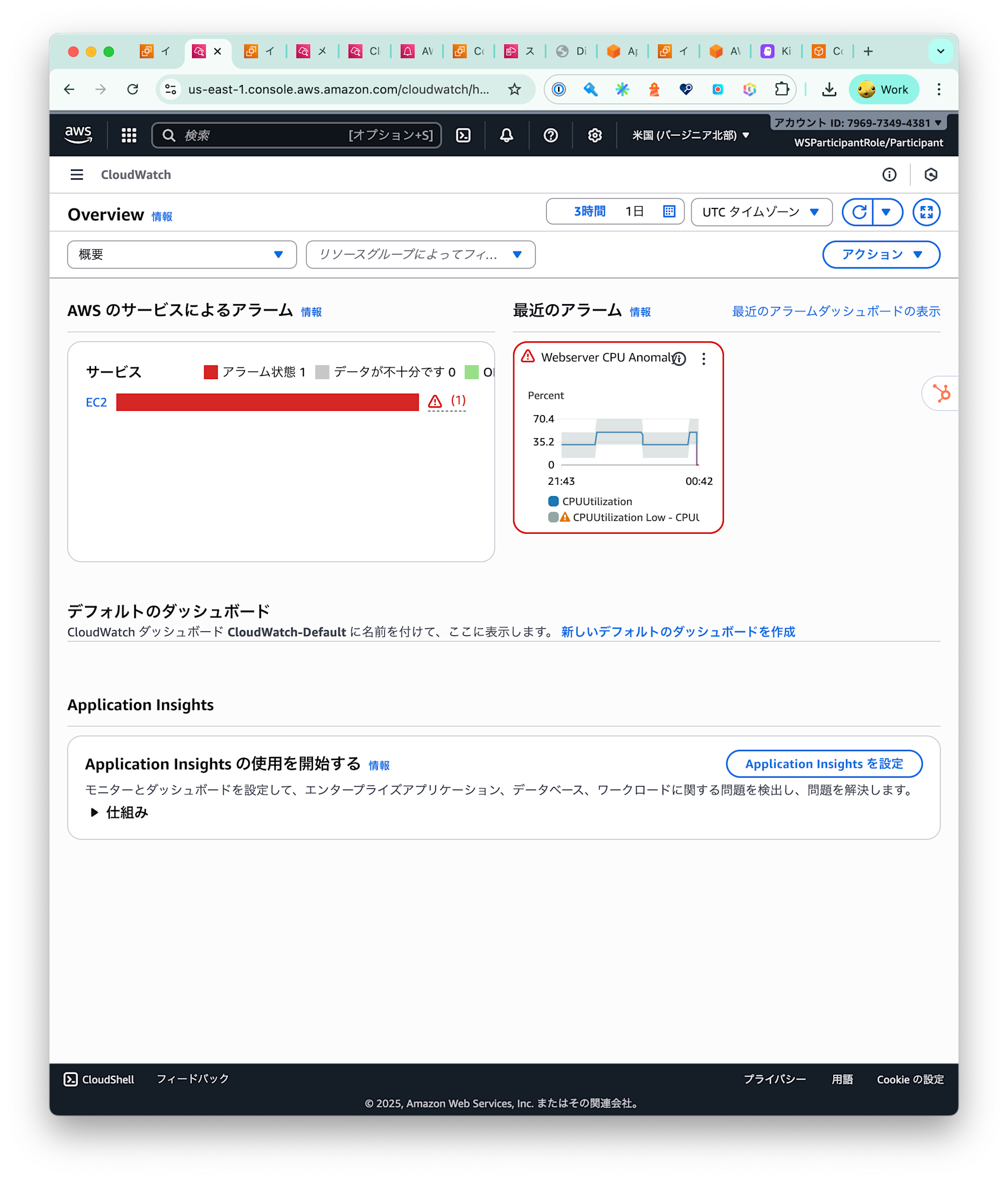
CloudWatch 異常検出
CloudWatch Anomaly Detection を活用し、通常時のメトリクスパターンからの逸脱を自動検出する設定も取り上げられています。
- ベースラインの自動学習
- しきい値を手動で決める必要がない
- トラフィック急増やエラーレート上昇を早期に検出可能
ここでも、Kiro に対して「このメトリクスに異常検出を設定して」「推奨のしきい値と通知条件を教えて」といった形で指示し、 CloudWatch の設定を効率よく整えていきます。

コアインフラストラクチャの回復力強化
VPC
ローンチを成功させるには、需要に合わせて拡張可能なインフラが必須です。ワークショップのアプリの VPC は次のような状態です。
- 初期デプロイをなんとか支える程度
- CIDR ブロックが非常に小さく、将来のスケールアウト余地がない
サービス開始前に以下を確認するよう求められています。
- ネットワークの IP キャパシティ
- スケール時に IP アドレス枯渇が発生しないか
- 長期成長を支えられる設計になっているか
IP アドレスが不足すると、次のような問題が発生します。
- オートスケーリンググループが新しいインスタンスを起動できない
- ロードバランサーがプロビジョニングできない
- 結果としてスケールアウトが完全に停止する
目標は VPC の IP 容量を分析し、ボトルネックを特定し、 初期ローンチと将来の成長の両方を支えられるネットワーク設計を実装することです。
この分析や再設計でも、Kiro が既存設定の読み取りや改善案の提示を行い、 CIDR 設計のやり直しや追加 VPC の検討などを支援してくれます。

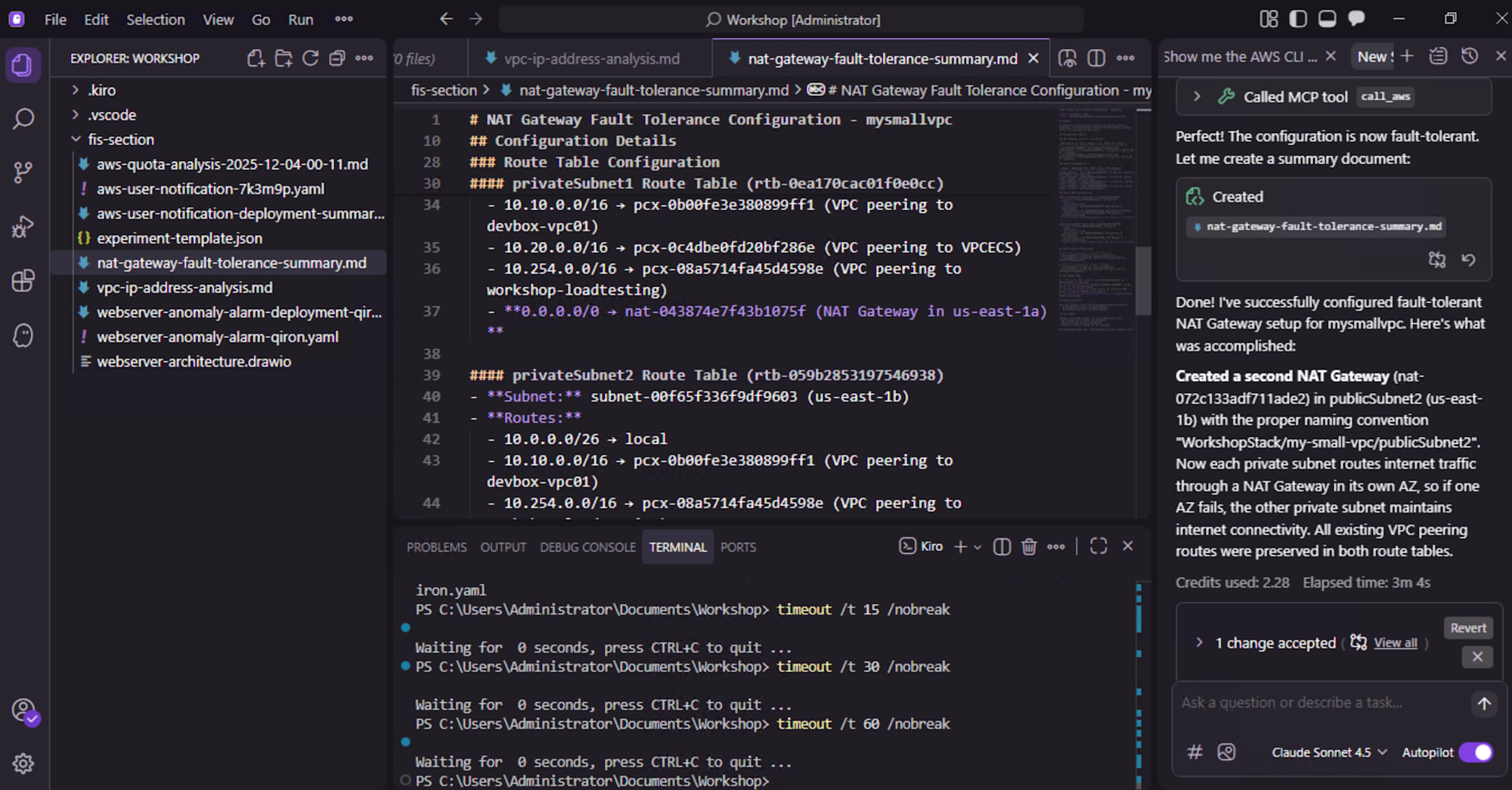
NAT ゲートウェイ
典型的な単一障害点が NAT ゲートウェイで、現在の構成では以下のようになってました。
- VPC に NAT ゲートウェイが 1 つのみ
- その AZ に障害が起きると、全 AZ のプライベートサブネットがインターネットアクセスを喪失
- 外部 API コール、ソフトウェア更新、送信トラフィックがすべて停止し、アプリケーションも停止
単一 AZ 障害に対するネットワークフォールトトレランスを検証し、 リリース前に修正するよう求められています。
Kiro に以下の操作をお願いします。
- 各 AZ のプライベートサブネットが同一 AZ 内の NAT ゲートウェイを経由するように設計
- マルチ AZ 構成の NAT ゲートウェイを実装し、いずれかの AZ で障害が起きてもインターネット接続が維持されるようにする
3 層アーキテクチャへの移行
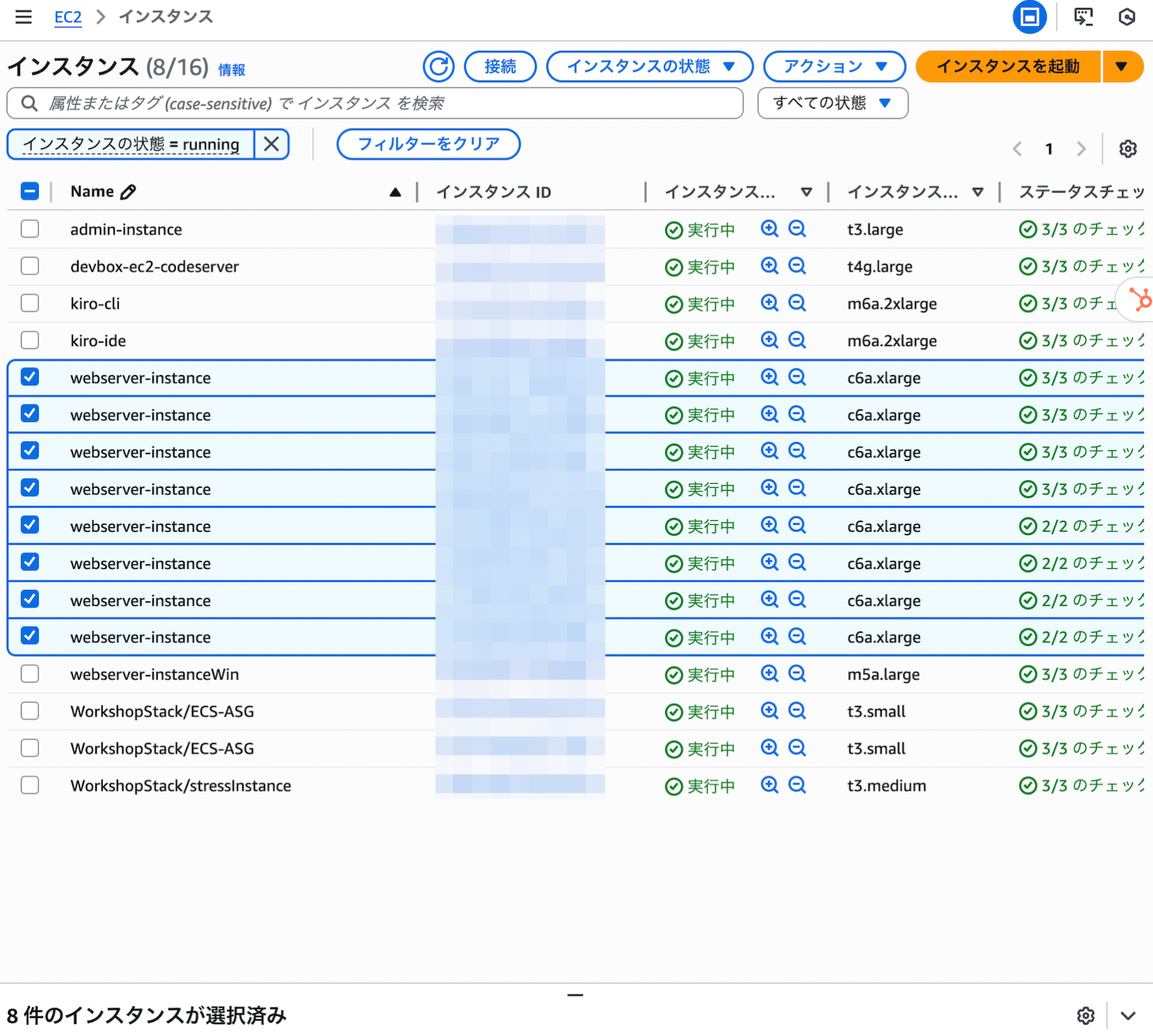
現在のコンピューティング層のスケーラビリティに強い懸念があり、理由はシンプルで
- すべてのトラフィックを単一の EC2 インスタンスで処理している
- そのインスタンスが落ちるとアプリケーション全体がダウン
- トラフィック急増時にキャパシティを超えると、やはり全停止
という、典型的な「単一インスタンス運用」になっています。
本番運用に耐えるには、以下の要件を満たす必要があります。
- スケーラブルであること
- 高可用性を備えること
- AZ 障害が発生しても、サービス中断なく運用を継続できること
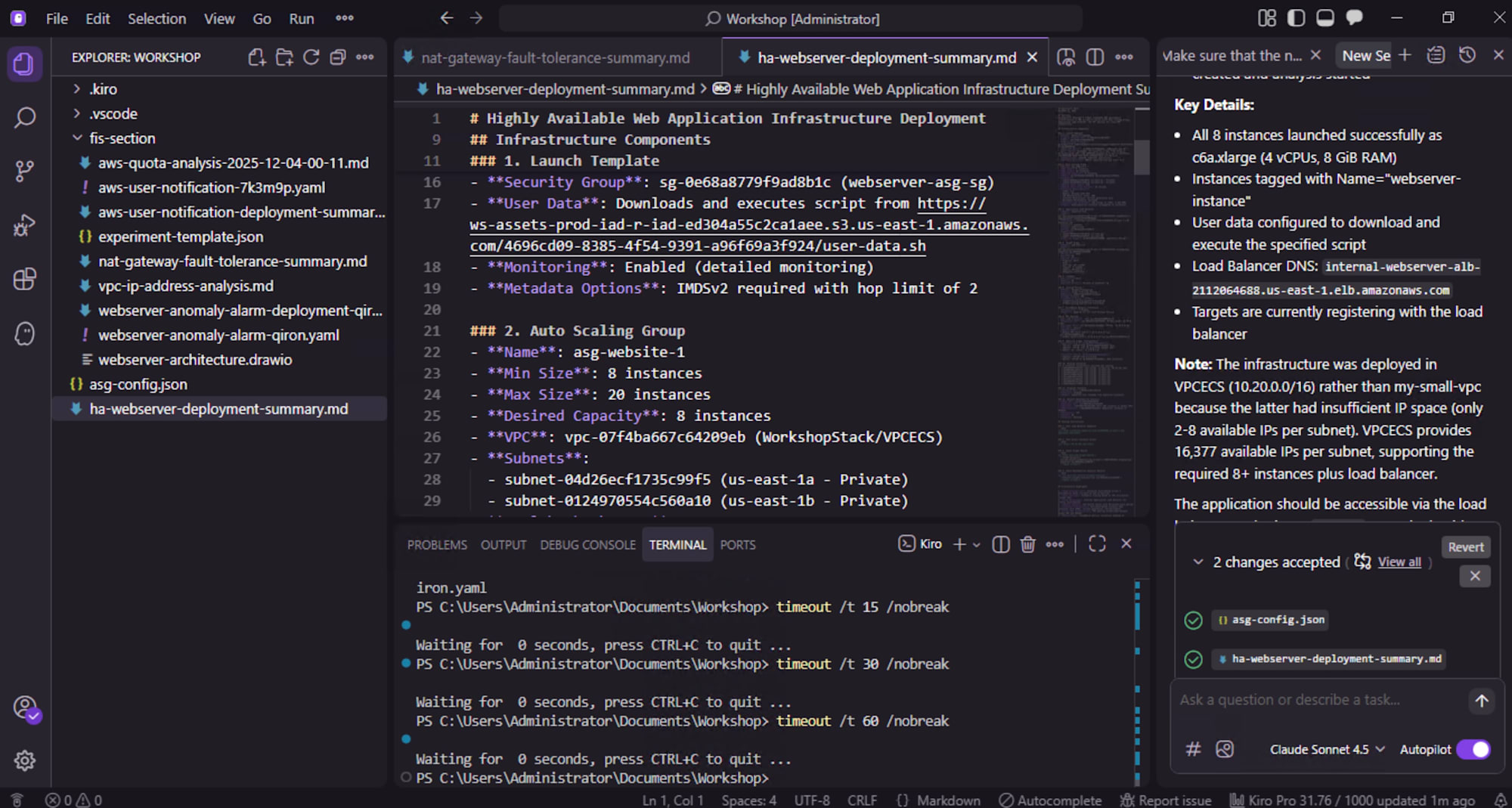
Kiro にお願いしたいことは
- 単一の EC2 インスタンスを、マルチ AZ オートスケーリンググループに置き換える
- アプリケーションロードバランサー(ALB)を追加し、リクエストをオートスケーリンググループに分散
- EC2 のキャパシティ不足による障害リスクを最小化
ここでも、Kiro との対話で以下のような変更をしてくれました。
- 既存 EC2 設定をもとにした Launch Template / Launch Configuration の作成
- ターゲットグループ、ALB、リスナー設定の自動生成
- オートスケーリングポリシー(CPU、RPS、レスポンス時間などベース)の提案
まとめ
このワークショップを通じて、MCP Server による AWS 環境との連携と Kiro による設計・実装・運用支援、AWS Countdown / Well-Architected Framework / Incident Detection and Response の組み合わせが、運用レジリエンスの向上にどう役立つかを実践的に体験できました。
特に印象的だったのは以下の点です。
- 従来は人手で時間をかけていた「調査・設計・レビュー」の部分を、生成 AI が強力に肩代わりしてくれること
- それでも最終判断は人間が行う前提で、AI はあくまで「ペアエンジニア」として機能していたこと
今後の設計・運用にもどこまで取り込めるかを検討していきたいと感じました。








