
Step Functionsで大容量S3ファイルを分割処理してRDSに取り込んでみた
こんにちは。クラウド事業本部の桑野です。
みなさん、大容量ファイルをLambda関数で処理しようとしたことはありませんか?
Lambda関数で実装する場合、実行時間の上限は15分です。小規模なファイルであれば問題ありませんが、数万件、数十万件といった大容量のデータを扱う場合、この制限にぶつかってしまうことがあります。
今回は、Step Functionsを使ってこの課題を解決してみました。S3に配置された大容量ファイルを分割し、並列でRDSに取り込み、完了後にSNSで通知するという一連のワークフローを構築することで、15分の壁を超えて安定した処理を実現できます。
非常に実践的な内容なので、同じような課題に直面している方の参考になれば幸いです。
Step Functionsとは
AWS Step Functions は、 最新のアプリケーション向けにサーバーレスオーケストレーションを提供します。オーケストレーションは、ワークフローを複数のステップに分割し、フローロジックを追加し、ステップ間の入出力を追跡することで、ワークフローを一元管理します。
今回は、非常に大きなサイズのS3ファイルをRDSに取り込みます。
しかし、Lambda関数には15分という実行時間の制約があり、ファイルのサイズ次第で15分以内に処理が終わらない可能性があります。
そんな時に、このStep Functionsが活用できます。
処理を15分以内に収まる単位に分割し、次のプロセスに必要な値を渡すことで連鎖的に進めていくというようなイメージです。
さらに、複数の処理を並列で実行したり、エラー時のリトライを組み込んだりすることもできます。
構成内容
下記の構成をTerraformで構築します。
Terraform、およびマイグレーション用のPrisma CLIはそれぞれDockerコンテナから実行します。
- データソースはAmazon RDS for MariaDBを使用
- Step Functionsを使い、S3ファイルの検証・分割・並列RDS取り込み・SNS通知を行うワークフローを構築する
- Step FunctionsはS3イベントを通じて起動する
前提
下記の条件で検証しています。
- OS:macOS Sequoia バージョン 15.6.1
- チップ:Apple M4
- Docker Client:28.4.0
- Docker Server:28.3.3
- Colima:0.8.4
- docker compose:2.39.3
構築手順については以下の記事をご参照ください。
Terraform実行用にAWS CLIのプロファイルが必要になります。
IAMユーザーのクレデンシャルを指定するので、あらかじめアクセスキーとシークレットアクセスキーを発行しておきましょう。
また、以前の記事でPrisma ClientをLambda関数で効率よく実行できるように、Lambdaレイヤーを作成しました。今回はそのソースコードをベースにプログラムやAWSリソースを追加していきます。
構築
コードは下記GitHubリポジトリにて公開しています。
1. Backendプロジェクトのパッケージインストール
backendというコンテナにアクセスします。
以下のコマンドを実行し、ワークスペース全体のパッケージをインストールします。
cd /backend/typescript
pnpm install
2. Prismaのセットアップ
続いて、Prismaの型とエンジンを生成します。
pnpm prisma:generate
3. ソースコードのビルド
Prismaのセットアップが完了したら、Lambda Layers、およびLambda関数のソースコードをビルドします。
Lambda Layers
以下のコマンドを実行します。
pnpm build:layer
Lambda関数
以下のコマンドを実行します。
pnpm build:functions
4. AWS CLIのセットアップ
続いてterraform_runnerというコンテナにアクセスします。
以下のコマンドを実行し、事前に用意していたクレデンシャルを設定します。
aws configure --profile kuwan0-app
5. Terraform実行
クレデンシャルの設定が完了したら、Terraformを使用してリソースを作成します。
cd /terraform-runner/terraform/environments/dev
terraform init
terraform apply
6. マイグレーションの実行
Terraformでデプロイが完了したら、再度backendコンテナにアクセスします。
以下のコマンドを実行し、SSM接続を行います。
まずは、環境変数を設定します。
以下のコマンドを実行し、env.exampleをコピーしたenv.devを作成しましょう。
cp /backend/typescript/environments/.env.example /backend/typescript/environments/.env.dev
env.devを作成したら、DB_SECRET_ARNに、Secrets Managerから確認可能なシークレットのARNを追記します。
AWS_REGION="ap-northeast-1"
AWS_PROFILE="kuwan0-app"
# ご自身のAWS環境に作成したSecrets ManagerのARNに置き換えてください
DB_SECRET_ARN="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
DB_HOST="localhost"
DB_NAME="main"
DB_PORT="3306"
.env.devの編集が完了したらssm start-sessionコマンドを実行します。
instanceIdにはEC2インスタンスのIDを、RDSEndpointにはRDSのエンドポイントをそれぞれ置き換えて実行しましょう。
aws ssm start-session --profile rds-prisma --target instanceId --document-name AWS-StartPortForwardingSessionToRemoteHost --parameters '{"host":["RDSEndpoint"],"portNumber":["3306"],"localPortNumber":["3306"]}'
SSM接続できたら、RDSに対してマイグレーションを行います。
以下のコマンドを実行しましょう。
pnpm prisma:migrate:deploy:dev
All migrations have been successfully applied.と出力されればOKです。
7. SNSのサブスクライブ
今回は処理の完了後にSNSと連携してメール通知を行います。
Terraform実行が完了するとkuwan0-app-dev-csv-bulk-import-notification-sns-topicというSNSトピックが作成されているため、ここにサブスクリプションの登録を行います。
下記の手順に従ってAWSマネジメントコンソールを操作しましょう。
まず、SNSを開きます。kuwan0-appから始まる名前のSNSトピックを選択します。

サブスクリプションタブを開き、サブスクリプションの作成を選択します。
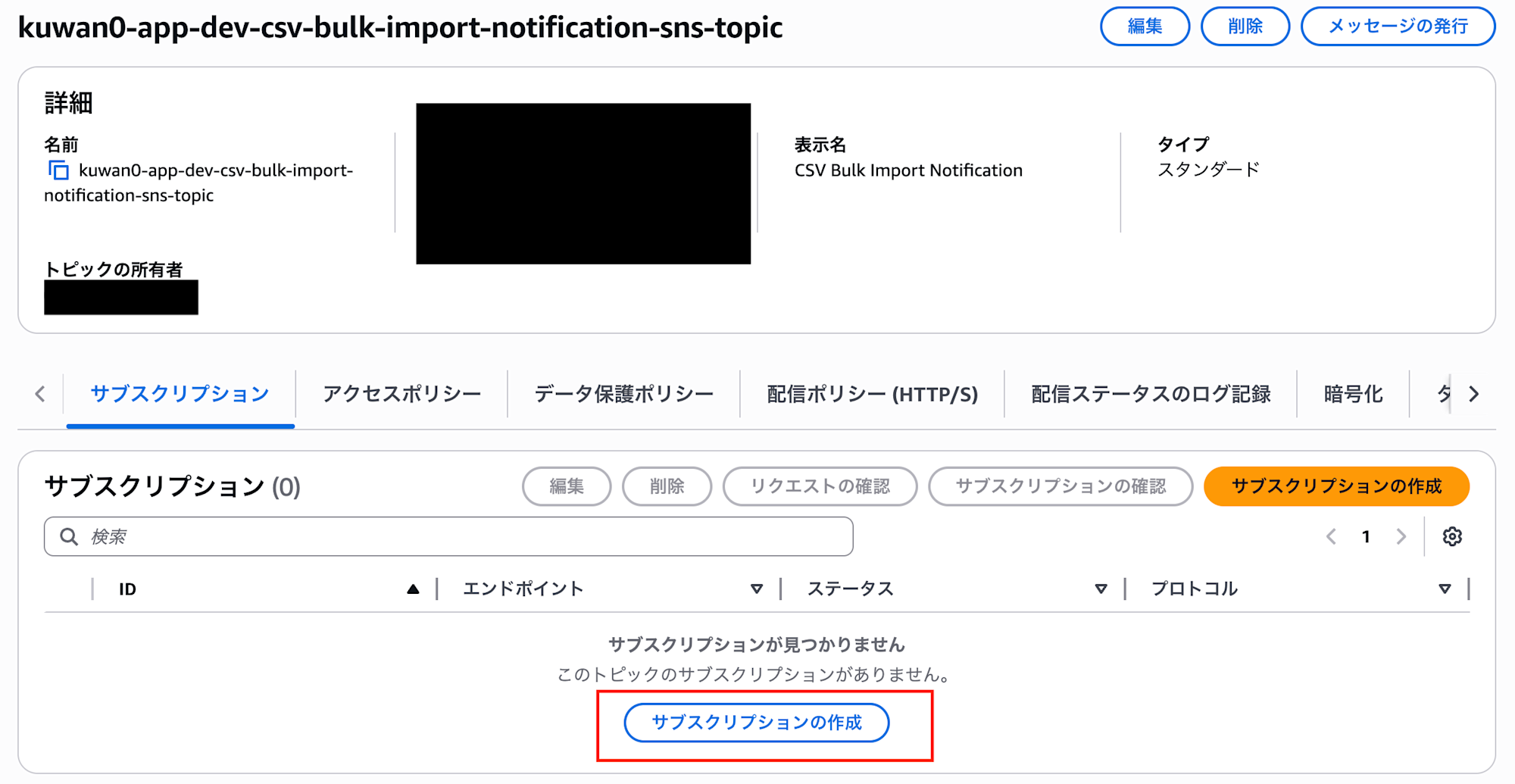
プロトコルにEメール、エンドポイントは通知先のメールアドレスを入力してください。
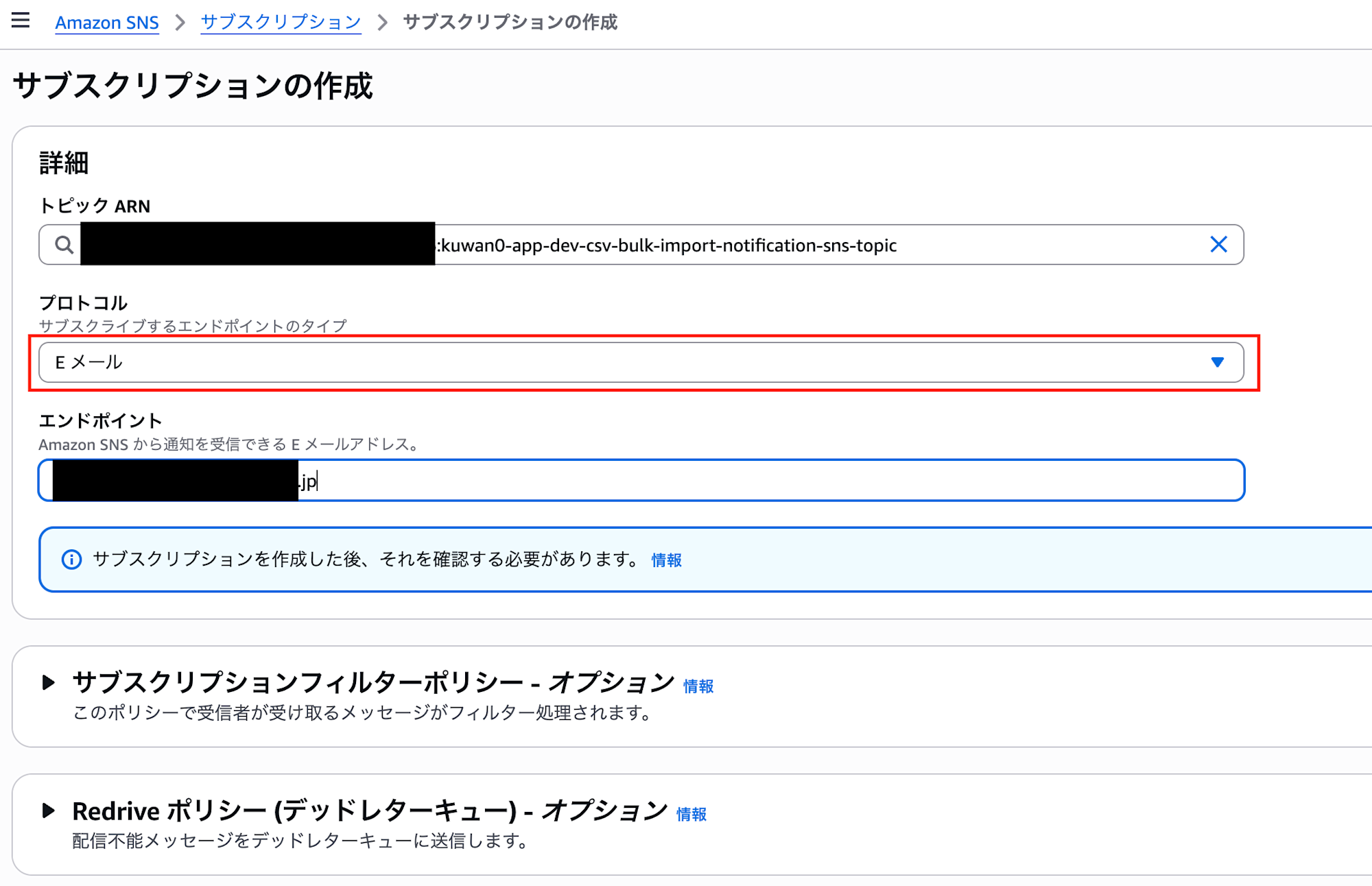
登録後、通知先のメールアドレスにSNSから確認メールが届きます。
メールを開き、Confirm subscriptionリンクをクリックします。
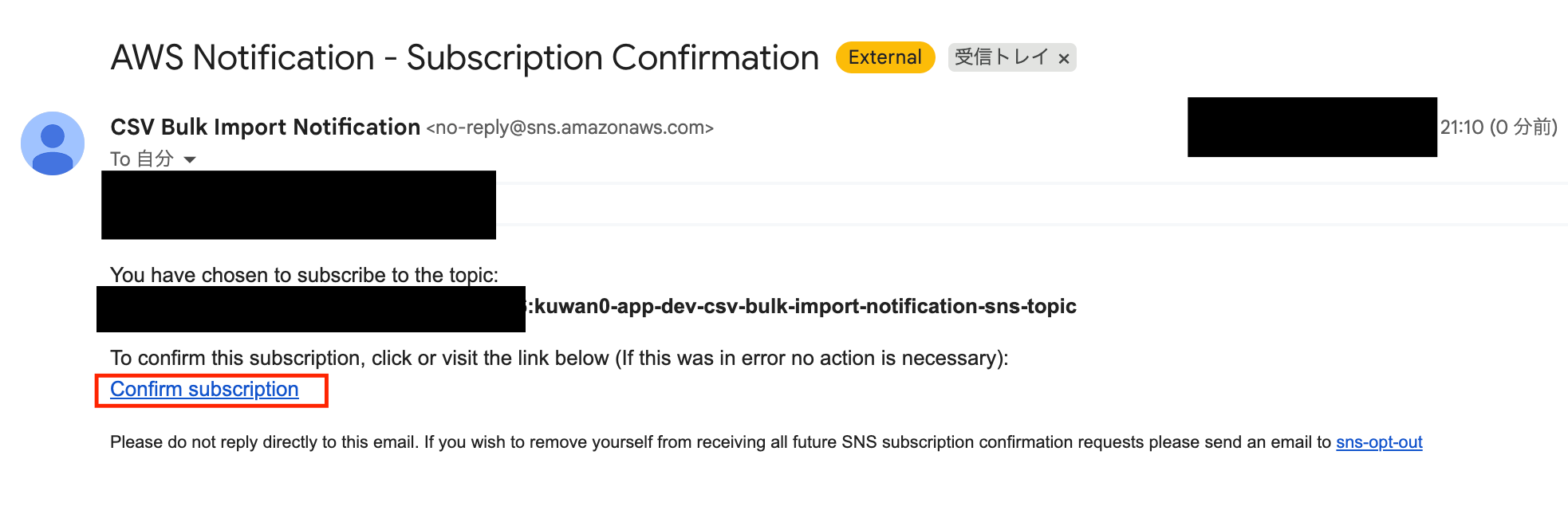
以下の画面が表示されればOKです。
検証・解説
普段はPrisma Studioを使用してレコードの登録状況をチェックしていましたが、Prisma v7ではMariaDBが対応できていないという状況でした。
今回はテスト用のデータ取得クエリをpnpmスクリプトとして用意していますので、そちらでチェックを行います。
1. データベースの確認
再度backendコンテナにアクセスし、SSM接続します。
構築の手順6と同様で準備すればOKです。
SSM接続できたら、以下のコマンドを実行します。
pnpm run test:query:dev
実行結果は以下の通りです。
作成したテーブルのレコードが0であることが確認できます。
============================================================
Statistics
============================================================
Total Todos: 0
Completed Todos: 0
Total Bulk Import Jobs: 0
Completed Jobs: 0
2. Step Functionsの起動
構成内容に記載の通り、S3イベントでStep Functionsを起動します。
まずは、S3にファイルをアップロードします。
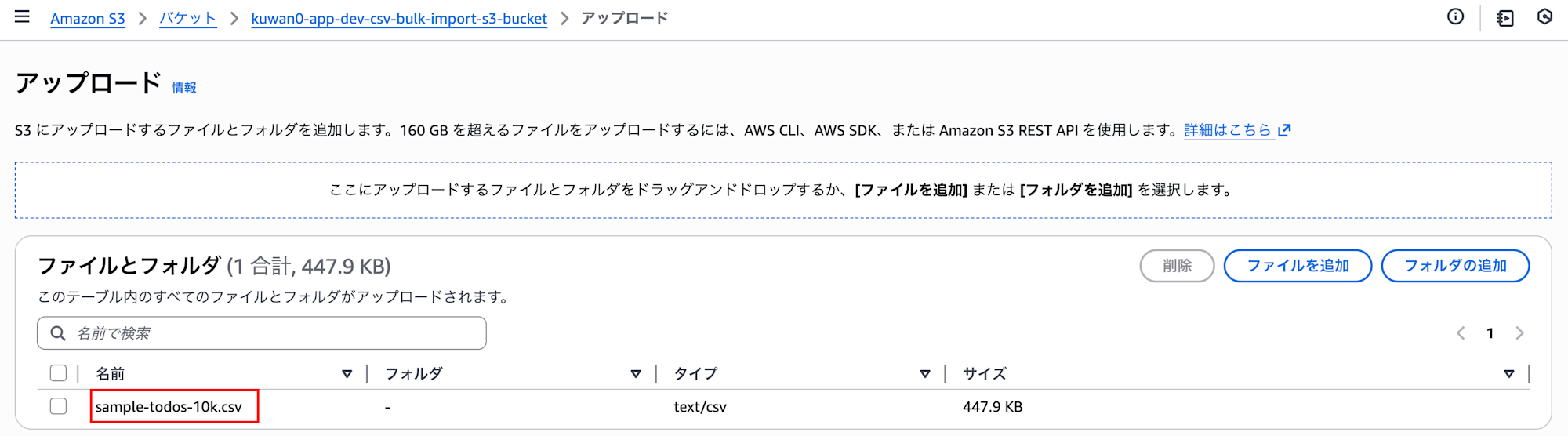
アップロードするファイルはsample-todos-10k.csvです。
1万行あり、これらをtodoテーブルに登録します。
AWSマネジメントコンソールからS3を開き、kuwan0-app-dev-csv-bulk-import-s3-bucketを選択します。
step-functions-test/backend/sample-todos-10k.csvをアップロードします。
3. Step Functionsの確認
続いてAWSマネジメントコンソールからStep Functionsを開き、kuwan0-app-dev-csv-bulk-import-sfn-state-machineを選択します。
S3イベントに反応し、すでに実行が1つされています。
実行を選択し、詳細を確認していきます。
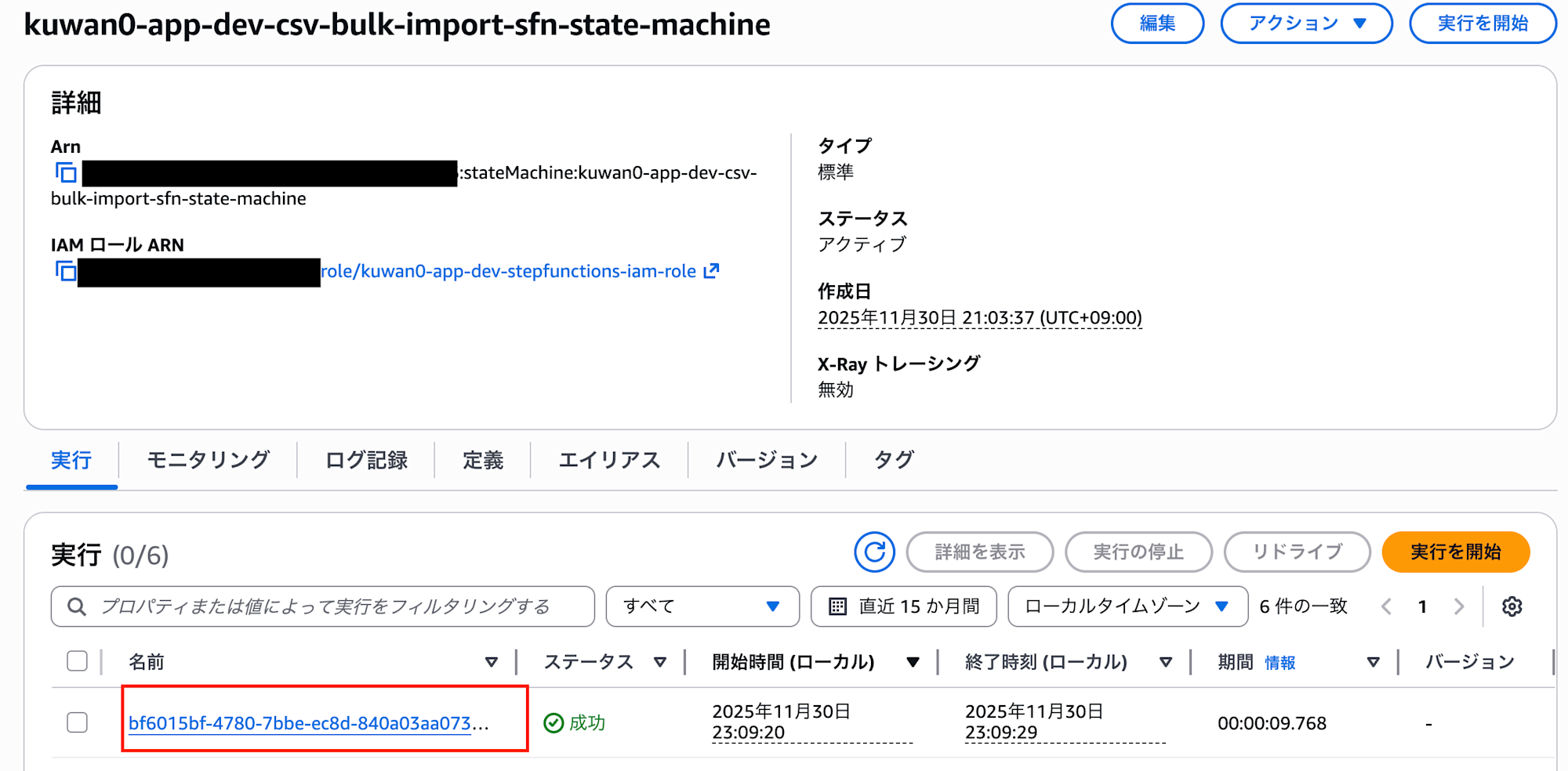
実行の状況や結果を確認することができます。
このワークフローは以下のステートで構成されています。
- ValidateAndSplit: S3ファイルを検証し、分割単位を決定
- ProcessChunks: 分割されたデータを並列でRDSに取り込み(Map State使用)
- CheckJobCompletion: すべての取り込みが完了したか確認
- SendNotification: SNSでメール通知
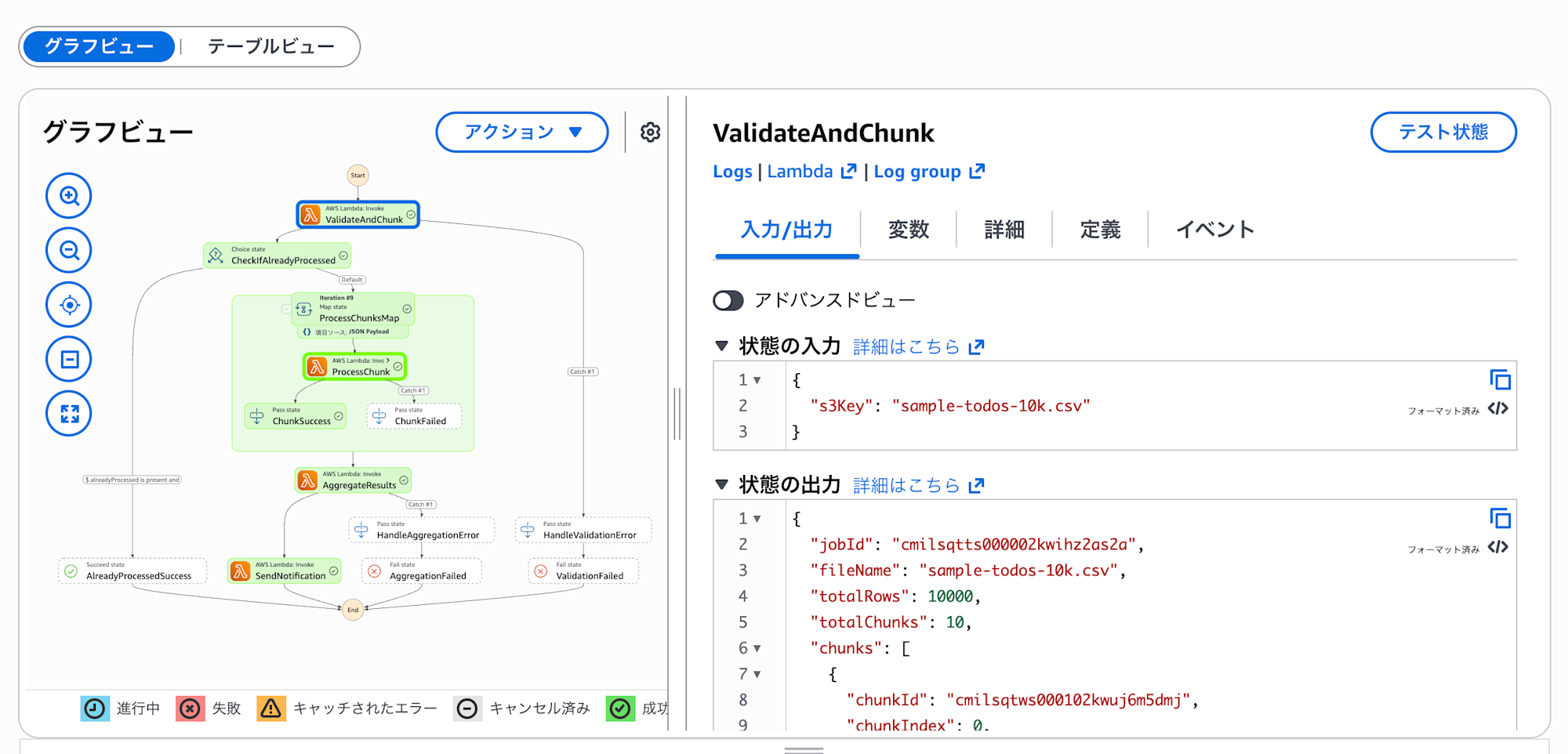
SendNotificationまで成功となっていれば、メールが通知されているはずです。
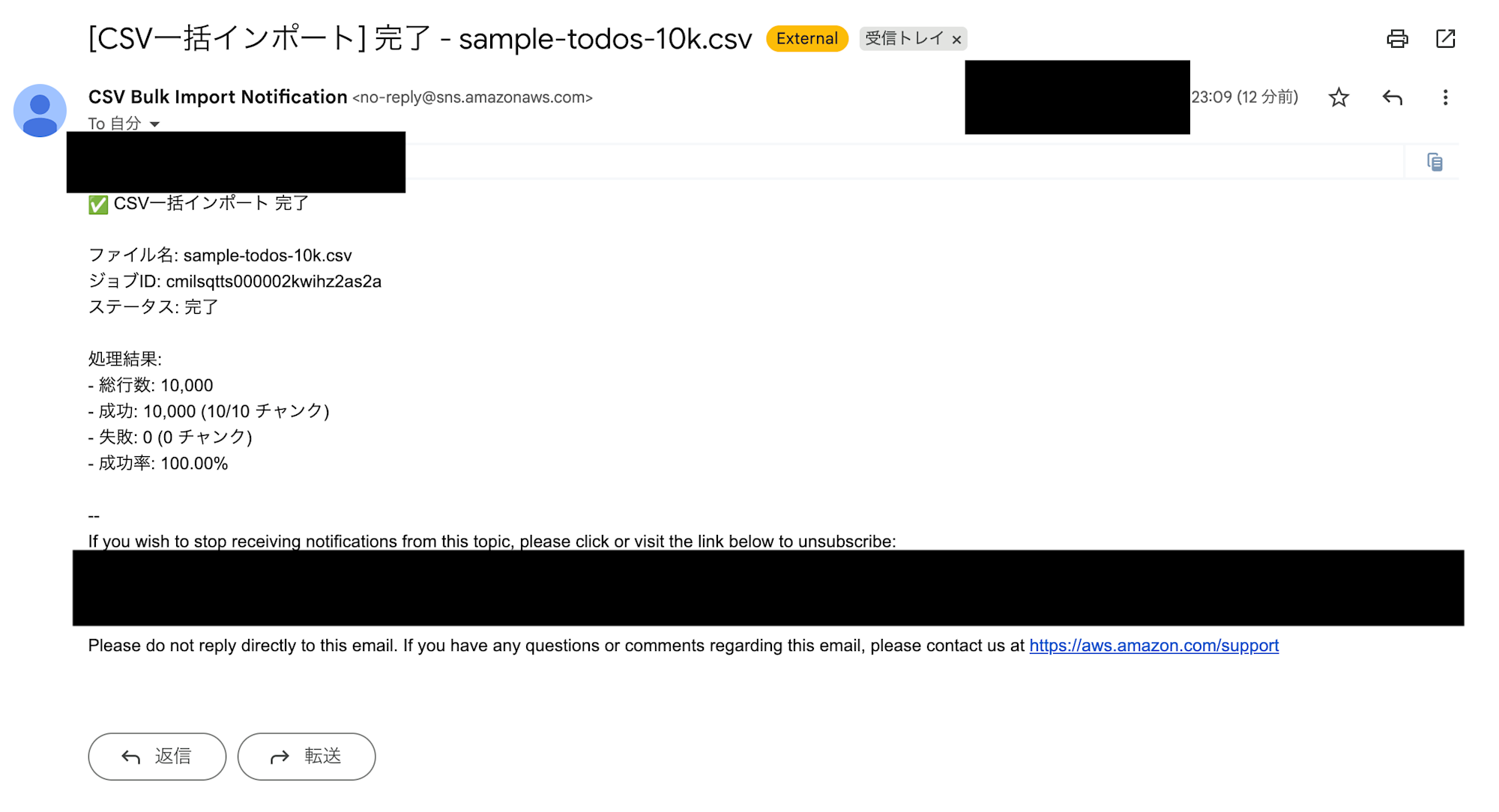
4. 実行結果の確認
手順1同様の条件で以下のコマンドを実行します。
pnpm run test:query:dev
以下の通り、todoが1万件登録されていますね。
Jobも1つ登録され、完了していることがわかります。
============================================================
Statistics
============================================================
Total Todos: 10000
Completed Todos: 2064
Total Bulk Import Jobs: 1
Completed Jobs: 1
5. AWSリソースの削除
今回作成したリソースは、放っておくとお金がかかり続けます。
実施が終わったあと、リソースを残しておく必要がなければ削除することを忘れずに行なっておきましょう。
terraform_runnerコンテナにアクセスし、下記コマンドを実行します。
terraform destroy
まとめ
いかがだったでしょうか?
今回のケースだとファイルの分割、分割ファイルのDB取り込み、ジョブの完了状況のチェック、ジョブ完了後の通知という4つの処理に分けて一つずつ実行することで効率よく処理できました。
こんな感じで、15分で完了しない大きめの処理でも、Step Functionsを組み合わせれば解決できちゃいます。
最近TestState APIによるローカルテストが強化されるアップデートがありましたので、今後そちらも検証できればと思っています。
最後までご覧いただきありがとうございました。










