
SQLite3データをData Firehose経由でS3 TablesのIcebergテーブルに格納する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部の笠原です。
今回は、SQLite3のデータベースファイルを読み込んで、Data Firehose経由でS3 TablesのIcebergテーブルに格納してみたいと思います。
なるべくCDKで実装してみましたが、一部CDK (CloudFormation)では対応していない箇所がありますので、その部分は別途AWS CLIを使ったシェルスクリプトを起動して設定します。
環境
以下の環境で確認しています。
- AWS CDK: 2.178.1
- AWS CLI: 2.23.10
- Node: 22.13.1
- TypeScript: 5.6.3
- Python: 3.12.8
サンプルコード
以下のGitHubに格納しております。
概要図
今回の構成は以下のとおりです。
オレゴンリージョン (us-west-2) で試していますが、東京リージョン (ap-northeast-1) でも動作するはずです。
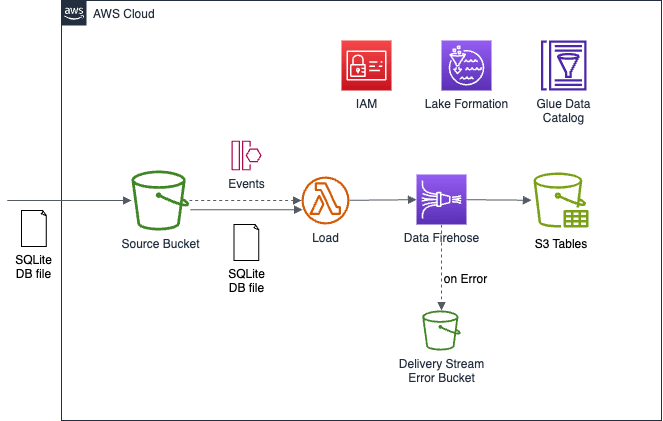
S3バケットにSQLite3のデータベースファイルをアップロードしてもらうと、Lambda関数が起動してデータベースファイルを読み込みます。
Lambda関数内で読み込んだデータをData Firehoseのストリームに「Direct PUT」します。
Data Firehoseのストリームの送信先にIcebergテーブルを指定できますので、今回はS3 Tablesで作成したIcebergテーブルに送信します。
構成要素
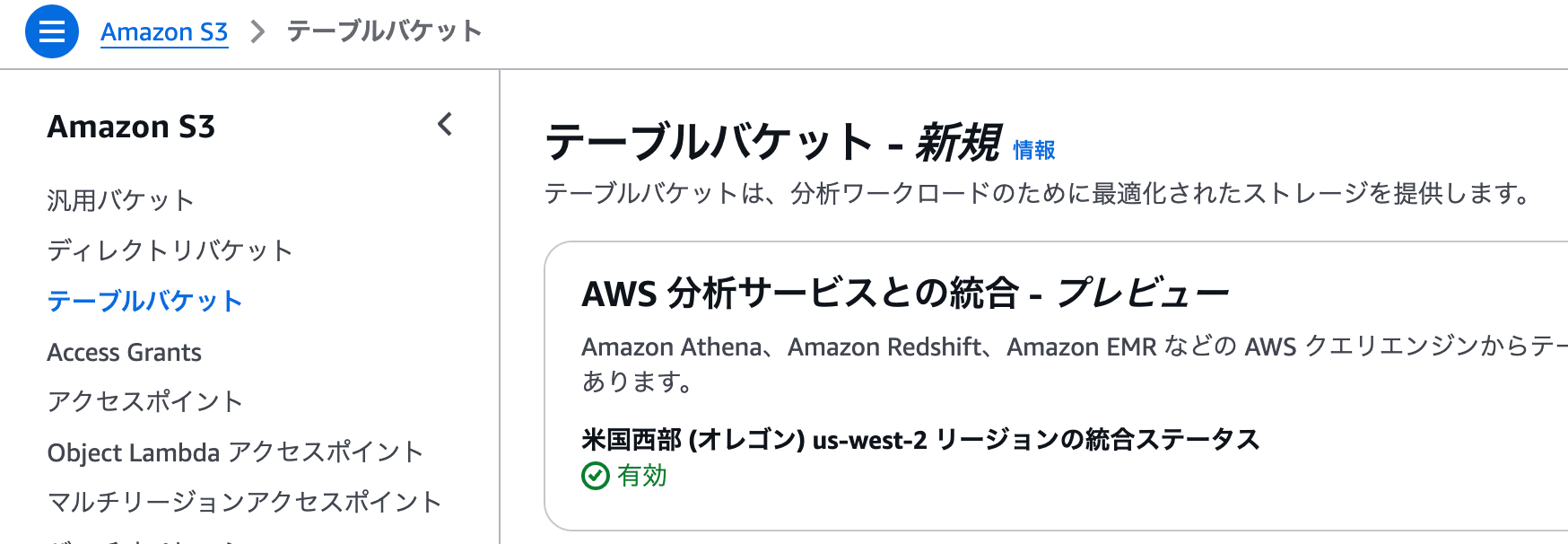
事前にS3のテーブルバケットにて、「AWS 分析サービスとの統合 - プレビュー」を有効にしておきます。
AWSマネジメントコンソール上で「統合を有効にする」をクリックして、有効化しておきましょう。
SQLite3 データベースファイル
SQLite3のデータベースファイルを作成します。
今回はPython3のスクリプトで作成しました。
データベースファイルには、2つのテーブルが入っていて、その中の1つのテーブル temperature_humidity_histories をIcebergテーブルに配信することを想定します。
データの中身は適当なランダム数値を割り当てています。
import sqlite3
import random
from datetime import datetime, timedelta
## create database.
with sqlite3.connect("main.db") as con:
cur = con.cursor()
## create tables.
cur.execute("""
CREATE TABLE IF NOT EXISTS temperature_humidity_histories (
sensor_id,
created_at,
temperature,
humidity
)
""")
cur.execute("""
CREATE TABLE IF NOT EXISTS thermohygrometers (
sensor_id,
sensor_name
)
""")
## insert data
sensor_cnt = 10
sensors = [ (i, f'meter{i}',) for i in range(1, sensor_cnt+1) ]
cur.executemany("""
INSERT INTO thermohygrometers VALUES (?, ?)
""", sensors)
days_cnt = 60
base_date = datetime.now() - timedelta(days=days_cnt)
datelist = [
(base_date + timedelta(days=d)).strftime('%Y-%m-%d %H:%M:%S')
for d in range(days_cnt)
]
histories = [
(random.choice(range(1, sensor_cnt+1)),
date,
random.normalvariate(20.0, 2),
random.normalvariate(40.0, 10),)
for date in datelist
]
cur.executemany("""
INSERT INTO temperature_humidity_histories VALUES (?, ?, ?, ?)
""", histories)
con.commit()
実行すると、 main.db というデータベースファイルが作成されます。
このファイルをS3のソース用バケットに格納します。
S3
最初にS3バケットを用意します。
今回は以下の3つを作成します。
- ソース用バケット
- SQLite3のデータベースファイルをアップロードしていただく汎用バケット
- ストリーム用バケット
- Firehoseの配信失敗時にバックアップデータを格納する汎用バケット
- ターゲットIcebergテーブルバケット
- Firehose配信先となるテーブルバケット
S3 TablesはまだL1コンストラクトしか用意されていませんので、
今回はこのL1コンストラクトの CfnTableBucket クラスで作成しています。
また、ソース用のS3バケットにEventBridgeへの通知を有効化しています。
EventBridgeを介してLambda関数を起動します。
import { Bucket } from 'aws-cdk-lib/aws-s3';
import { CfnTableBucket } from 'aws-cdk-lib/aws-s3tables';
// S3 Bucket
// ソース用バケット
this.srcBucket = new Bucket(this, 'SourceBucket', {
removalPolicy: cdk.RemovalPolicy.RETAIN,
eventBridgeEnabled: true, // EventBridgeへのイベント通知を有効化
});
// ストリーム用バケット (配信失敗時のバックアップデータ格納先)
this.deliveryStreamBucket = new Bucket(this, 'DeliveryStreamBucket', {
removalPolicy: cdk.RemovalPolicy.RETAIN,
});
// S3 Table Bucket
// ターゲットIcebergテーブルバケット
this.targetTableBucket = new CfnTableBucket(this, 'TableBucket', {
tableBucketName: 'firehose-s3table',
});
Icebergテーブル作成
ターゲットとなるS3 Tablesのテーブルバケットを作成したら、
S3 TablesのIcebergに対して、namespaceとtableを作成します。
namespaceとtableの作成には、今回はAWS CLIを利用します。
その際、Lake FormationのData Parmissionsにて、操作するプリンシパル(IAMユーザやIAMロール)に対して、利用するカタログとデータベースを操作する権限をAWS CLIで付与します。
今回は、実際にAWS CLIを操作するIAMユーザ/IAMロールのARNを指定します。
## テーブルバケットのカタログに対する権限追加
aws lakeformation grant-permissions \
--catalog-id "${AWS_ACCOUNT_ID}" \
--principal "{\"DataLakePrincipalIdentifier\": \"${AWS_PRINCIPAL_ARN}\"}" \
--resource "{\"Catalog\": {\"Id\": \"${AWS_ACCOUNT_ID}:s3tablescatalog/${TABLE_BUCKET_NAME}\"}}" \
--permissions "ALL" \
--permissions-with-grant-option "ALL"
## namespace (database) 作成
## namespace名は 'main' としています。
aws s3tables create-namespace \
--table-bucket-arn ${TABLE_BUCKET_ARN} \
--namespace main
## テーブルバケットのnamespace (database)に対する権限追加
aws lakeformation grant-permissions \
--catalog-id "${AWS_ACCOUNT_ID}" \
--principal "{\"DataLakePrincipalIdentifier\": \"${AWS_PRINCIPAL_ARN}\"}" \
--resource "{\"Database\": { \"CatalogId\": \"${AWS_ACCOUNT_ID}:s3tablescatalog/${TABLE_BUCKET_NAME}\", \"Name\": \"main\" }}" \
--permissions "ALL" \
--permissions-with-grant-option "ALL"
## テーブル作成
## テーブル名は 'temperature_humidity_histories' としています。
aws s3tables create-table \
--table-bucket-arn ${TABLE_BUCKET_ARN} \
--namespace main \
--name temperature_humidity_histories \
--format 'ICEBERG' \
--metadata '{"iceberg":{"schema":{"fields":[{"name":"sensor_id","type":"int","required":true},{"name":"created_at","type":"timestamp"},{"name":"temperature","type":"double"},{"name":"humidity","type":"double"}]}}}'
IAMロール
今回利用するIAMロールは以下です。
- Lambda関数用ロール
- Data Firehose配信ストリーム用ロール
- Data Firehose配信失敗時のバックアップS3バケットにアクセスするためのロール
配信失敗時のS3バケットにアクセスするためのロールは作らずに、配信ストリーム用のロールと兼務して使ってもOKですが、
今回は分けてみました。
Lambda関数は、 service-role/AWSLambdaBasicExecutionRole の他、
ソースのS3バケットとData Firehoseの配信ストリームにアクセスできればOKです。
Data Firehose配信ストリーム用ロールは、AWSドキュメントを参考にしつつ、
ドキュメントに記載されていた Glueへのアクセスリソースでは権限不足だったので、今回はリソースを "*" にしています。
import { Role, ServicePrincipal, ManagedPolicy, PolicyStatement } from 'aws-cdk-lib/aws-iam';
// IAM Role
// Lambda 関数用ロール
const loadFunctionRole = new Role(this, 'LoadFunctionRole', {
assumedBy: new ServicePrincipal('lambda.amazonaws.com'),
managedPolicies: [
ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole'),
ManagedPolicy.fromAwsManagedPolicyName('AmazonS3FullAccess'),
ManagedPolicy.fromAwsManagedPolicyName('AmazonKinesisFirehoseFullAccess'),
],
});
// Data Firehose 配信ストリーム用ロール
const deliveryStreamIcebergRole = new Role(this, 'DeliveryStreamIcebergRole', {
assumedBy: new ServicePrincipal('firehose.amazonaws.com'),
});
deliveryStreamIcebergRole.addToPolicy(new PolicyStatement({
actions: [
"glue:GetTable",
"glue:GetDatabase",
"glue:UpdateTable",
],
resources: ["*"],
}));
deliveryStreamIcebergRole.addToPolicy(new PolicyStatement({
actions: [
"lakeformation:GetDataAccess",
],
resources: [
"*",
],
}));
deliveryStreamIcebergRole.addToPolicy(new PolicyStatement({
actions: [
"logs:PutLogEvents",
],
resources: [
"*"
],
}));
// Data Firehose の配信失敗時のバックアップ先S3にアクセスするロール
const deliveryStreamS3Role = new Role(this, 'DeleveryStreamS3Role', {
assumedBy: new ServicePrincipal('firehose.amazonaws.com'),
});
deliveryStreamS3Role.addToPolicy(new PolicyStatement({
actions: [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject",
],
resources: [
`${props?.deliveryStreamBucket.bucketArn}`,
`${props?.deliveryStreamBucket.bucketArn}/*`,
],
}));
deliveryStreamS3Role.addToPolicy(new PolicyStatement({
actions: [
"logs:PutLogEvents",
],
resources: [
"*"
],
}));
Lake Formation
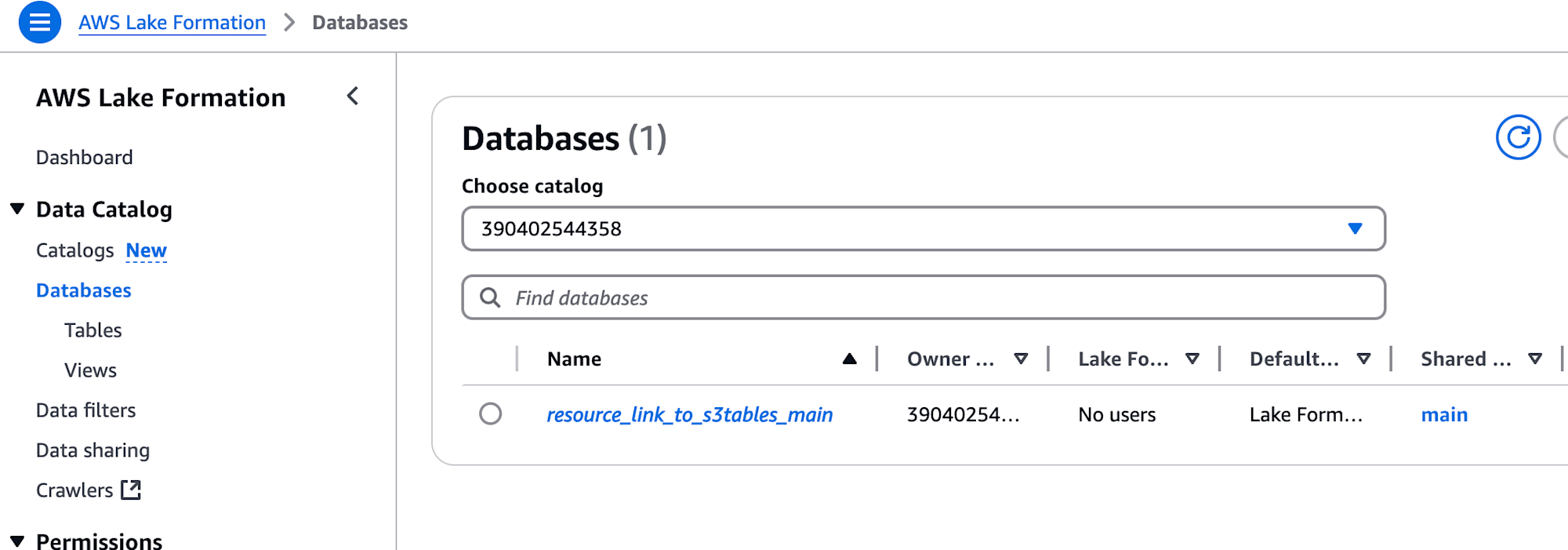
1. Icebergデータベースへのリソースリンクの作成
Lake FormationのDatabases内にある「Create database」からリソースリンクを作成することができます。これによって、S3 Tablesのカタログ {AWS_ACCOUNT_ID}:s3tablescatalog/{TABLE_BUCKET_NAME} にあるIcebergのデータベースを、Glueのデフォルトカタログ {AWS_ACCOUNT_ID} から参照することができます。
Data Firehoseの考慮事項には、以下のようにデフォルトのAWS Glueカタログのみをサポートするとの記載がありますので、このためにリソースリンクを作成します。
Amazon S3 テーブルバケット内のテーブルへの配信の場合、Firehose はデフォルトの AWS Glue カタログのみをサポートします。
AWS CLIやAWS CDK (CloudFormation)では、Glue Databaseでデータベースのリソースリンクを定義できます。
import { CfnDatabase } from 'aws-cdk-lib/aws-glue';
// Resource Link for S3 Tables Database
const s3tablesResourceLink = new CfnDatabase(this, 'S3TablesResourceLink', {
catalogId: `${props?.env?.account}`,
databaseInput: {
name: dbResourceLinkName,
targetDatabase: {
catalogId: `${props?.env?.account}:s3tablescatalog/${props?.targetTableBucket.tableBucketName}`,
databaseName: databaseName,
},
},
});
設定したリソースリンクは、AWSマネジメントコンソール上では Lake Formation の Databases 項目に一覧が表示されます。
2. 権限付与
Firehoseの配信ストリームにアタッチするIAMロールに対して、Icebergデータベースやテーブルを操作する権限を付与します。
私が試したところ、以下3つの権限設定が必要でした。
- データベースのリソースリンクへの権限付与
- データベースのリソースリンク先のテーブルへの権限付与
- 実際のS3Tablesのテーブルへの権限付与
データベースのリソースリンクへの権限付与については、AWS CDK (Cloudformation)でも設定可能でした。
permissions は DESCRIBE で十分です。
import { CfnPrincipalPermissions } from 'aws-cdk-lib/aws-lakeformation';
// Lake Formation
new CfnPrincipalPermissions(this, 'ResourceLinkPermission', {
principal: {
dataLakePrincipalIdentifier: deliveryStreamIcebergRole.roleArn,
},
resource: { // リソースリンク(DB)に対する権限付与
database: {
catalogId: s3tablesResourceLink.catalogId,
name: dbResourceLinkName,
},
},
permissions: ["DESCRIBE"],
permissionsWithGrantOption: [],
});
他2つは、AWS CDK (Cloudformation)で設定しようとするとエラーとなったため、
今回はAWS CLIで設定します。
--principal オプションの DataLakePrincipalIdentifier は、権限付与対象のIAMユーザ/IAMロールのARNを指定する必要があり、今回はData Firehose配信ストリームにアタッチするIAMロールのARNを指定します。
また、 --resource オプションの "TableWildcard": {} は、すべてのテーブル(ALL_TABLES) を対象とする場合の設定方法になります。
## データベースリソースリンク先のテーブルへの権限付与
## AWS_PRINCIPAL_ARN は、Data Firehoseの配信ストリームにアタッチするIAMロールのARN
aws lakeformation grant-permissions \
--catalog-id "${AWS_ACCOUNT_ID}" \
--principal "{\"DataLakePrincipalIdentifier\": \"${AWS_PRINCIPAL_ARN}\"}" \
--resource "{\"Table\": {\"CatalogId\": \"${AWS_ACCOUNT_ID}\", \"DatabaseName\": \"resource_link_to_s3tables_main\", \"TableWildcard\": {} }}" \
--permissions "ALL"
## 実際のS3Tablesのテーブルへの権限付与
aws lakeformation grant-permissions \
--catalog-id "${AWS_ACCOUNT_ID}" \
--principal "{\"DataLakePrincipalIdentifier\": \"${AWS_PRINCIPAL_ARN}\"}" \
--resource "{\"Table\": {\"CatalogId\": \"${AWS_ACCOUNT_ID}:s3tablescatalog/${TABLE_BUCKET_NAME}\", \"DatabaseName\": \"main\", \"TableWildcard\": {} }}" \
--permissions "ALL"
Data Firehose
Data Firehoseの配信先にIcebergテーブルを指定することができます。
icebergDestinationConfiguration にて、適宜設定を行います。
AWS CDKではL2コンストラクトで用意されている配信先は、現時点でS3バケットのみなので、
今回はL1コンストラクト CfnDeliveryStream で定義します。
import { CfnDeliveryStream } from 'aws-cdk-lib/aws-kinesisfirehose';
// Data Firehose
const deliveryStream = new CfnDeliveryStream(this, 'DeliveryStream', {
deliveryStreamType: 'DirectPut',
icebergDestinationConfiguration: {
roleArn: deliveryStreamIcebergRole.roleArn,
bufferingHints: {
intervalInSeconds: 30, // 開発向けに早くデータを反映してもらうため
sizeInMBs: 5,
},
retryOptions: {
durationInSeconds: 30, // 再試行時間も短めにした
},
catalogConfiguration: {
catalogArn: `arn:aws:glue:${props?.env?.region}:${props?.env?.account}:catalog`,
},
destinationTableConfigurationList: [{
destinationDatabaseName: dbResourceLinkName,
destinationTableName: tableName,
uniqueKeys: ['sensor_id', 'created_at'], // UpdateやDeleteの際に使われるが、今回はInsertしかしないので無視される
s3ErrorOutputPrefix: `dstErrIceberg/${dbResourceLinkName}/${tableName}`,
}],
s3Configuration: {
// 配信エラー発生時のバックアップ先S3バケットの設定
bucketArn: `${props?.deliveryStreamBucket.bucketArn}`,
roleArn: deliveryStreamS3Role.roleArn,
cloudWatchLoggingOptions: {
// バックアップエラー発生時のCloudWatch Logs設定
enabled: true,
logGroupName: backupLogGroup.logGroupName,
logStreamName: backupLogStream.logStreamName,
},
},
cloudWatchLoggingOptions: {
// 配信エラー発生時のCloudWatch Logs設定
enabled: true,
logGroupName: streamLogGroup.logGroupName,
logStreamName: streamLogStream.logStreamName,
},
},
});
ちなみに、配信先のテーブルは複数可能です。
その際、配信元のデータ内に配信先のテーブルを指定することで、Data Firehose側で振り分けてくれます。
今回は配信先を1つにして単一テーブルに対してデータを送るようにしているので、複数宛の振り分け機能は試していません。
Lambda
Lambda関数では、S3のソースバケットに配置されたSQLite3データベースファイルを読み込んで、
Data Firehoseの配信ストリームにデータレコードを投入します。
import os
import shutil
import sqlite3
import boto3
import botocore
import json
from datetime import datetime
from pprint import pprint
def handler(event, _):
if event.get("Records"):
## S3イベント通知
src_bucket = event["Records"][0]["s3"]["bucket"]["name"]
src_objkey = event["Records"][0]["s3"]["object"]["key"]
else:
## EventBridgeイベント通知
src_bucket = event["detail"]["bucket"]["name"]
src_objkey = event["detail"]["object"]["key"]
delivery_stream = os.environ.get('TGT_STREAM')
target_table = os.environ.get('TGT_TABLE')
s3_client = boto3.client('s3')
firehose_client = boto3.client('firehose')
## download sqlite database file.
tmp_dir = '/tmp/load'
local_path = os.path.join(tmp_dir, os.path.dirname(src_objkey))
if not os.path.exists(local_path):
os.makedirs(local_path)
local_objkey = os.path.join(local_path, os.path.basename(src_objkey))
s3_client.download_file(src_bucket, src_objkey, local_objkey)
with sqlite3.connect(local_objkey) as con:
cur = con.cursor()
## scan "temperature_humidity_histories" table data
batch_size = 10
cur.execute(f"""
SELECT sensor_id,
created_at,
temperature,
humidity
FROM {target_table}
""")
rows = cur.fetchmany(batch_size)
while (rows is not None) and rows:
data = [ {
"sensor_id": row[0],
"created_at": datetime.strptime(row[1], '%Y-%m-%d %H:%M:%S').strftime('%Y-%m-%dT%H:%M:%SZ'),
"temperature": row[2],
"humidity": row[3] } for row in rows ]
records = [ { "Data": json.dumps(record).encode() } for record in data ]
res = firehose_client.put_record_batch(
DeliveryStreamName=delivery_stream,
Records=records,
)
print("\nstream response:")
pprint(res)
rows = cur.fetchmany(batch_size)
cur.close()
shutil.rmtree(local_path)
return {
"src_bucket": src_bucket,
}
CDK上での定義は以下のとおりです。
今回は、S3バケット作成用のスタックとそれ以外のスタックで分けた影響で、
S3イベント通知をLambda関数のトリガーにするとスタックの循環参照でエラーになるため、
EventBridgeを介してLambda関数を起動します。
ソース用のS3バケットにEventBridgeへの通知を有効化したのは、このためです。
import { Function, Runtime, Code } from 'aws-cdk-lib/aws-lambda';
import { Rule } from 'aws-cdk-lib/aws-events';
import { LambdaFunction as targetLambdaFunction } from 'aws-cdk-lib/aws-events-targets';
// Lambda Function
const loadFunction = new Function(this, 'LoadFunction', {
runtime: Runtime.PYTHON_3_12,
code: Code.fromAsset('lambda/load'),
handler: 'lambda_function.handler',
memorySize: 256,
timeout: cdk.Duration.seconds(10),
role: loadFunctionRole,
environment: {
SRC_BUCKET: `${props?.sourceBucket.bucketName}`,
TGT_STREAM: deliveryStream.ref,
TGT_TABLE: tableName,
},
});
// EventBridge Rule
const onCreateS3Object = new Rule(this, 'onCreateS3ObjectRule', {
eventPattern: {
source: ["aws.s3"],
detailType: ["Object Created"],
detail: {
bucket: {
name: [props?.sourceBucket.bucketName]
},
},
},
targets: [
new targetLambdaFunction(loadFunction, {}),
]
});
動作確認
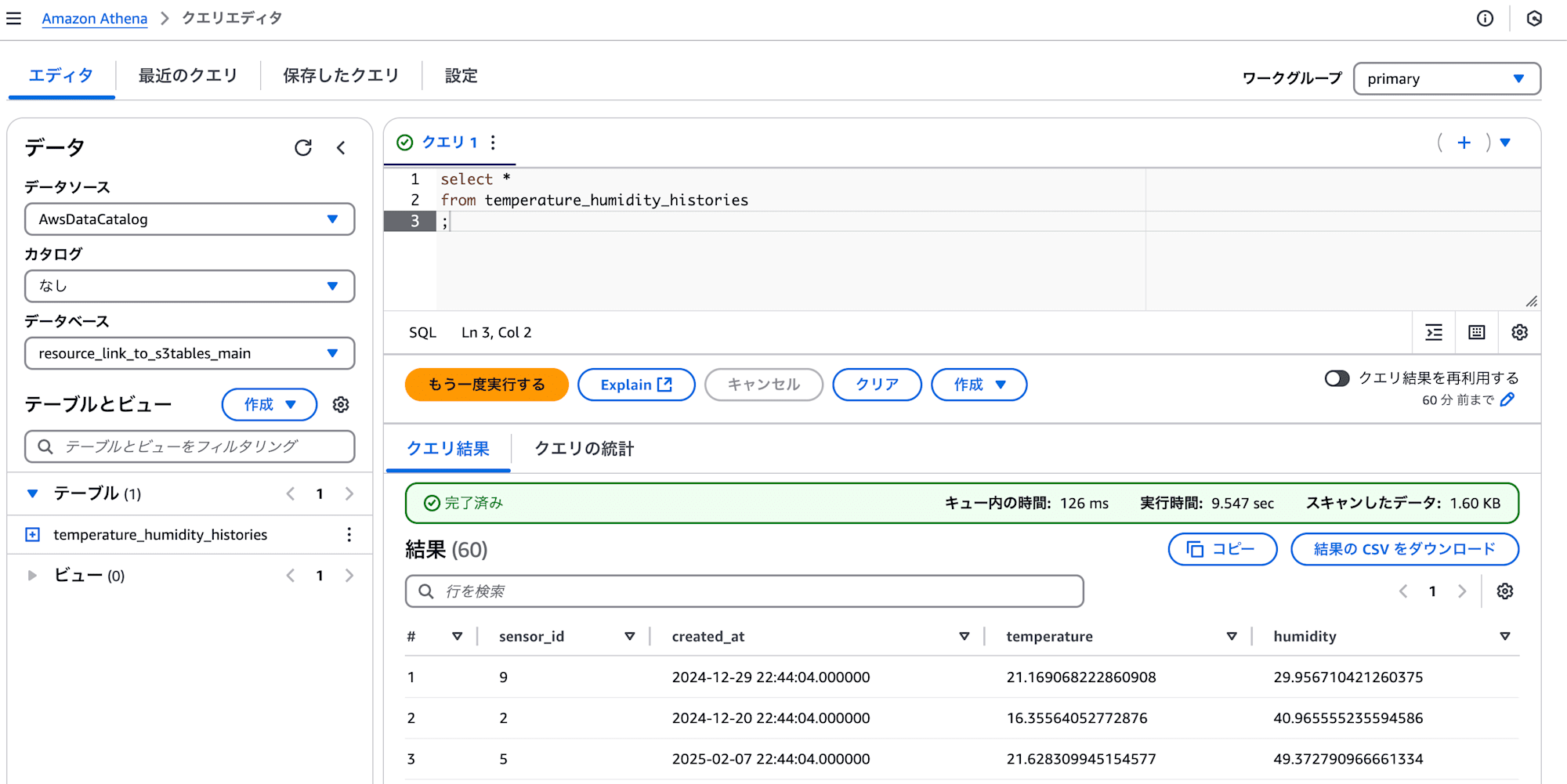
最初に作成したSQLite3データベースファイル main.db をソース用S3バケットにアップロードします。
その後しばらくすると、S3 TablesのIcebergテーブルに格納されるはずなので、Athenaで確認してみましょう。
Athenaで、データベースにリソースリンク resource_link_to_s3tables_main を指定して、以下のクエリを実行すると、結果が返るはずです。
select *
from temperature_humidity_histories
;
まとめ
今回は、以下のことを意識して試してみました。
- なるべくAWS CDKで動作環境を構築する
- AWS CDKで現状対応できない部分はAWS CLIを利用する
- Data Firehoseの配信先のIcebergは、S3 Tablesのテーブルバケットとする
- SQLite3のデータベースファイルをPythonで扱う
参考になれば、幸いです。










