Strands AgentsのCode InterpreterビルトインツールでS3と連携してみた
はじめに
こんにちは、スーパーマーケットが大好きなコンサルティング部の神野です。
前回の記事でStrands Agentsの ビルトインツールAgentCoreCodeInterpreter を使って、AgentCore Code Interpreterにファイルを明示的に渡す・取り出す方法を紹介しました。
前回はローカルファイルをサンドボックスに書き込む方法でしたが、大規模なデータセットを扱う際はS3を使いたいケースもありますよね。
AWS公式ドキュメントを確認すると、カスタムCode Interpreterを作成することでS3と連携できると記載がありました。
You can create a custom Code Interpreter tool with an execution role to upload/download files from Amazon S3.
随分前からうろ覚えでできる認識はあったので、今回は試してみたいと思います。
カスタムCode Interpreterを作成して、S3連携をやってみます。
前提
本検証は下記バージョンを使用しました。
| 項目 | バージョン |
|---|---|
| Python | 3.12 |
| strands-agents | 1.20.0 |
| strands-agents-tools | 0.2.18 |
| AWS CLI | 2.28.8 |
また、AWSリソースを操作できる必要な権限を持っていることを前提とします。
試してみる
S3バケット・Code Interpreterが使用するIAMロールはAWS CLIをベースに、カスタムCode Interpreterはコンソール上で作成する方がわかりやすいかと思い、コンソール上で作成します。
S3バケットの作成
まず、Code InterpreterがアクセスするためのS3バケットを作成します。
# アカウントIDを取得
ACCOUNT_ID=$(aws sts get-caller-identity --query "Account" --output text)
REGION="us-west-2"
BUCKET_NAME="code-interpreter-artifacts-${ACCOUNT_ID}"
# S3バケットを作成
aws s3 mb s3://${BUCKET_NAME} --region ${REGION}
# プレフィックスとしてオブジェクトを配置
aws s3api put-object --bucket ${BUCKET_NAME} --key input/
aws s3api put-object --bucket ${BUCKET_NAME} --key output/
input/ にはCode Interpreterに渡すファイルを、output/ にはCode Interpreterが生成したファイルを保存する想定です。
IAMロールの作成
Code InterpreterがS3にアクセスするためのIAMロールを作成します。
まず、信頼ポリシーをファイルに保存します。
cat << 'EOF' > trust-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock-agentcore.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
次に、S3アクセス用の権限ポリシーを作成します。
先ほど設定した BUCKET_NAME 環境変数を使って、アカウントIDが自動で埋め込まれるようにしています。
cat << EOF > s3-access-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3Access",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::${BUCKET_NAME}",
"arn:aws:s3:::${BUCKET_NAME}/*"
]
}
]
}
EOF
環境変数 BUCKET_NAME はS3バケット作成時に設定したものをそのまま使用しています。ターミナルのセッションが切れた場合は、再度設定してから実行してくださいね。
IAMロールを作成し、ポリシーをアタッチします。
# IAMロールを作成
aws iam create-role \
--role-name CodeInterpreterS3Role \
--assume-role-policy-document file://trust-policy.json
# インラインポリシーをアタッチ
aws iam put-role-policy \
--role-name CodeInterpreterS3Role \
--policy-name S3AccessPolicy \
--policy-document file://s3-access-policy.json
# ロールARNを確認
aws iam get-role --role-name CodeInterpreterS3Role --query "Role.Arn" --output text
ロールARNが表示されればOKです。ロール名は後で使用します。
カスタムCode Interpreterの作成
AWSコンソールからカスタムCode Interpreterを作成します。
- Amazon Bedrock AgentCore のコンソールを開き、左メニューから
Built-in tools→Code Interpreterを選択します Createボタンをクリックします
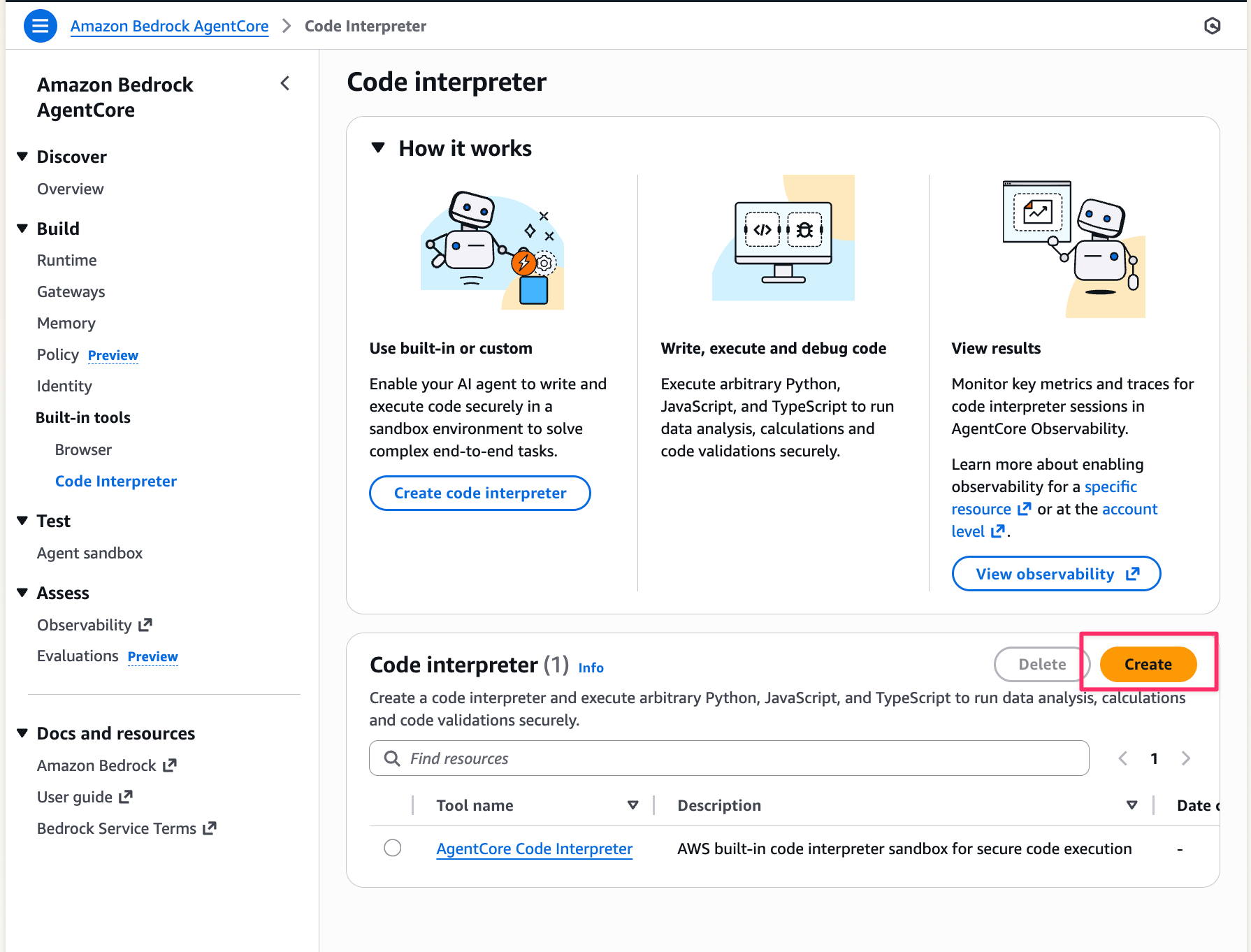
- 下記の情報を入力し、
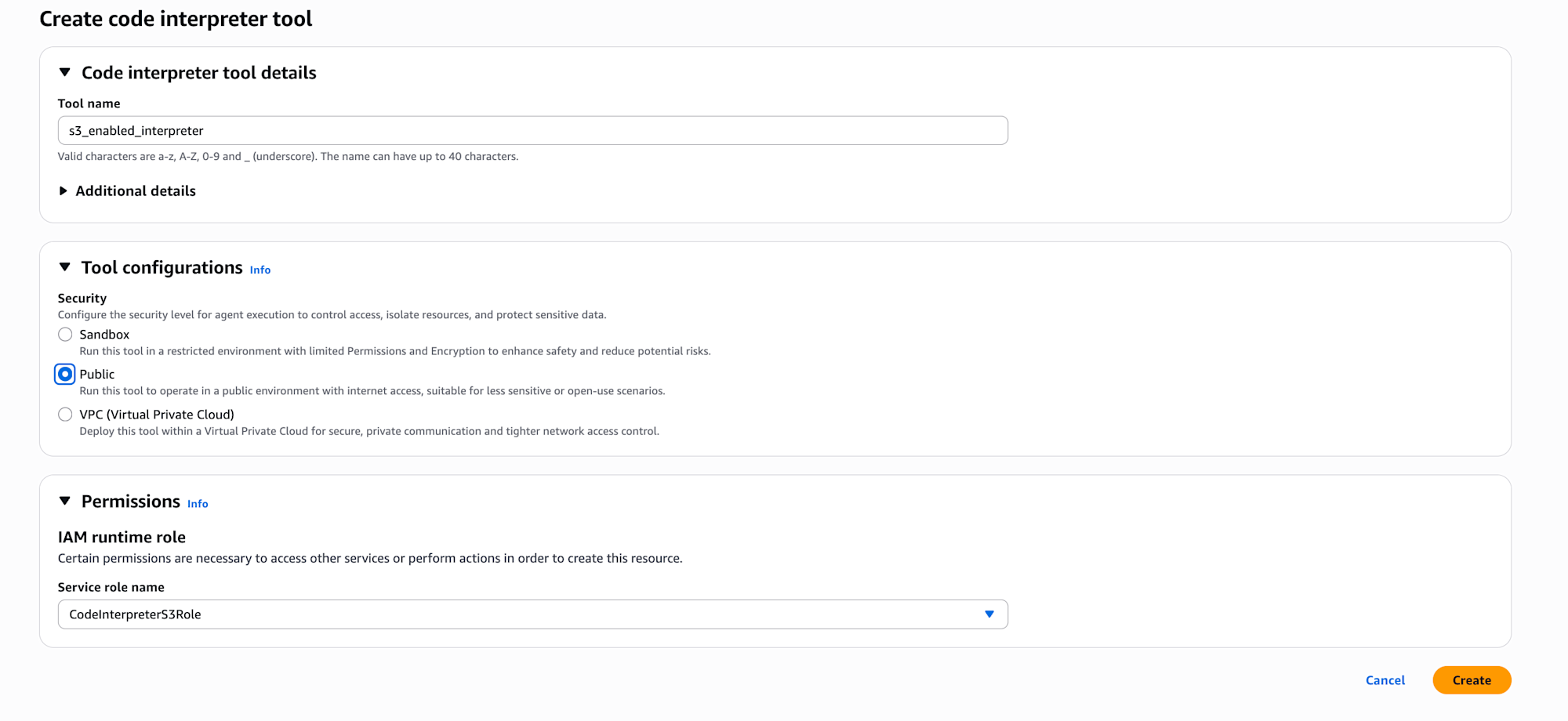
Createボタンを選択します。- Tool name:
s3-enabled-interpreter(任意の名前) - Security:
Publicを選択 - Service Role Name: 先ほど作成した
CodeInterpreterS3Roleを選択
- Tool name:
今までデフォルトのAgentCore Code Interpreterしか触ったことがなかったので、カスタムで作ることもできてネットワークの設定やIAMロールの設定はここから行えるんだと発見です。
Network modeについて
公式ドキュメントを確認すると、Network modeについて下記の記載があります。
セキュリティ要件や連携したいサービスなどに応じてモードを選択する必要がありますね。
| モード | 説明 | ユースケース |
|---|---|---|
| Public | パブリックインターネットへのアクセスが可能 | 外部APIとの連携、pip installが必要な場合 |
| Sandbox | 外部ネットワークへのアクセスは制限 | セキュリティ要件が厳しい場合 |
| VPC | VPC内のプライベートリソース(DB、内部APIなど)へアクセス可能 | プライベートサブネット内のリソースにアクセスしたい場合 |
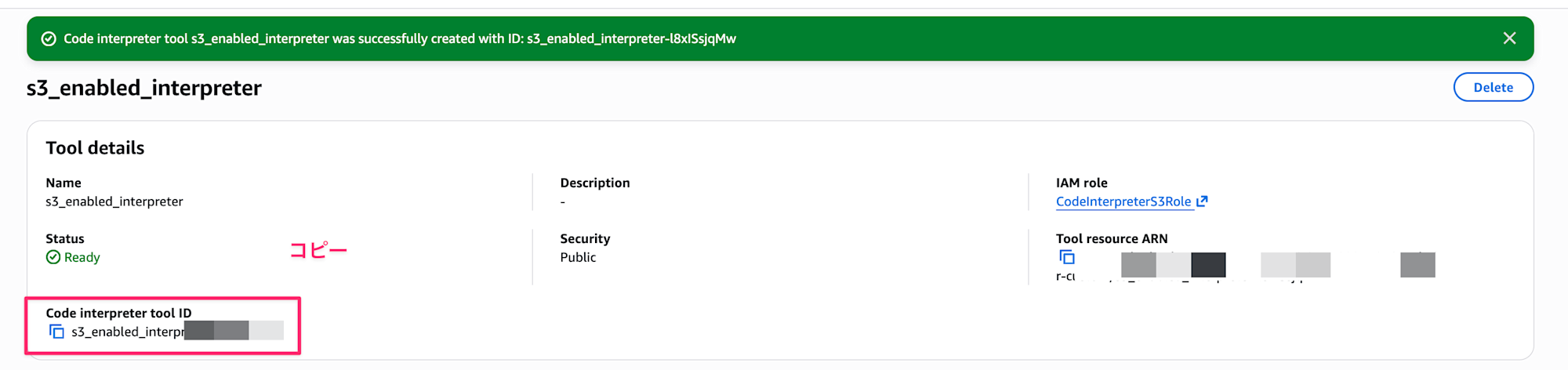
作成したらCode Interpreter tool IDを控えておきます。後に使用します。
テスト用データセットの準備
今回はニューヨーク市が公開している NYC Taxi Trip データを使用します。このデータセットはニューヨーク市のタクシー乗車記録です。
上記のリンクから Yellow Taxi Trip Records の 2025年1月分(Parquetファイル)をダウンロードしてください。
ダウンロードしたら、下記コマンドでS3にアップロードします。
# バケットにアップロード
aws s3 cp yellow_tripdata_2025-01.parquet s3://${BUCKET_NAME}/input/
Strands AgentsのビルトインツールでカスタムCode Interpreterを使う
Strands Agentsのビルトインツールである AgentCoreCodeInterpreter で、identifier パラメータにカスタムCode InterpreterのIDを指定してS3連携を試してみます。
from strands import Agent
from strands.models import BedrockModel
from strands_tools.code_interpreter import AgentCoreCodeInterpreter
import os
# カスタムCode Interpreter ID
CODE_INTERPRETER_ID = "XXXXXXXXXXXX" # 作成したIDに置き換え
ACCOUNT_ID = os.popen("aws sts get-caller-identity --query Account --output text").read().strip()
BUCKET_NAME = f"code-interpreter-artifacts-{ACCOUNT_ID}"
model = BedrockModel(
model_id="us.anthropic.claude-sonnet-4-5-20250929-v1:0",
region_name="us-west-2"
)
# カスタムCode InterpreterのIDを指定
code_interpreter = AgentCoreCodeInterpreter(
region="us-west-2",
identifier=CODE_INTERPRETER_ID # ここがポイント!
)
agent = Agent(
model=model,
tools=[code_interpreter.code_interpreter],
system_prompt=f"""あなたはデータアナリストです。
Code InterpreterはS3へのアクセス権限を持っています。
executeCommandでaws s3 cpコマンドを使ってファイルのダウンロード・アップロードが可能です。
バケット名: {BUCKET_NAME}
"""
)
response = agent(f"""
s3://{BUCKET_NAME}/input/yellow_tripdata_2025-01.parquet をダウンロードして、
NYCタクシーデータを分析してください。
以下の分析を行ってください:
1. データの基本統計(レコード数、期間など)
2. 時間帯別の乗車数の傾向
3. 平均運賃と平均乗車距離
分析結果をCSVファイルにまとめて s3://{BUCKET_NAME}/output/ にアップロードしてください。
""")
identifier パラメータにカスタムCode InterpreterのIDを指定することで使用できるんですね!
逆にidentifierに何も指定しないと、aws.codeinterpreter.v1が使われる仕組みになっています。
フォルトのaws.codeinterpreter.v1にはIAMロールが紐づいていないため、S3へのアクセス権限がありません。そのため、S3連携したい場合はカスタムCode Interpreterを作成してIAMロールを紐づける必要があるといった流れが今回やったことですね。
システムプロンプトではS3アクセス可能なことと、executeCommand でaws cliが使用でき、NYC Taxi データの分析を依頼し、結果をS3にアップロードするようお願いしてみます。
実行してみると下記のように出力されました。
NYCタクシーデータの分析を行います。まずS3からデータをダウンロードして、分析を実施します。
Tool #1: code_interpreter
データのダウンロードが完了しました。次に、データを読み込んで分析を行います。
Tool #2: code_interpreter
良いですね!データが正常に読み込まれました。次に、詳細な分析を行います。
Tool #3: code_interpreter
Tool #4: code_interpreter
Tool #5: code_interpreter
素晴らしい!次に、これらの分析結果をCSVファイルにまとめます。
Tool #6: code_interpreter
Tool #7: code_interpreter
Tool #8: code_interpreter
Tool #9: code_interpreter
Tool #10: code_interpreter
Tool #11: code_interpreter
完璧です!次にこれらのファイルをS3にアップロードします。
Tool #12: code_interpreter
Tool #13: code_interpreter
Tool #14: code_interpreter
Tool #15: code_interpreter
Tool #16: code_interpreter
Tool #17: code_interpreter
完璧です!最後に分析結果のサマリーを作成します。
Tool #18: code_interpreter
## 分析完了しました!🎉
NYCタクシーデータ(2025年1月)の分析が完了しました。以下が主な結果です:
### 📊 主要な発見
**1. データ概要**
- 総レコード数:**3,475,226回**の乗車
- 分析期間:32日間(2024/12/31 ~ 2025/02/01)
- 有効データ率:93.63%
**2. 時間帯別の傾向**
- **ピーク時間帯**:18時(夕方6時)に267,951回で最多
- **オフピーク**:早朝4時が最少(20,033回)
- ピークとオフピークの差は約**13.4倍**
**3. 運賃と乗車距離**
- 平均運賃:**$17.95**(中央値:$12.80)
- 平均合計金額:**$26.81**(中央値:$20.35)
- 平均乗車距離:**3.17マイル**(中央値:1.70マイル)
- 平均乗車時間:**15.11分**
**4. 興味深い発見**
- 早朝5時の乗車は運賃が最も高く($25.42)、距離も最長(5.78マイル)
- 木曜日が最も乗車数が多い(571,830回)
- 1人乗車が全体の**69.2%**を占める
### 📁 出力ファイル
以下の5つのCSVファイルをS3にアップロードしました:
1. **01_basic_statistics.csv** - 基本統計サマリ
2. **02_hourly_trips.csv** - 時間帯別乗車数
3. **03_hourly_statistics.csv** - 時間帯別平均統計
4. **04_weekday_statistics.csv** - 曜日別統計
5. **05_passenger_statistics.csv** - 乗客数別統計
すべてのファイルは `s3://code-interpreter-artifacts-xxx/output/` に保存されています。## 分析完了しました!🎉
S3バケットを見るとしっかりとファイルがアップロードされています。
試しに01_basic_statistics.csvをダウンロードして確認すると分析結果が記載されていますね!
項目,値
総レコード数,"3,475,226"
期間開始,2024-12-31 20:47:55
期間終了,2025-02-01 00:00:44
期間日数,32
クリーニング後データ数,"3,253,701"
クリーニング後データ率,93.63%
平均運賃(USD),$17.95
中央運賃(USD),$12.80
平均合計金額(USD),$26.81
中央合計金額(USD),$20.35
平均乗車距離(マイル),3.17
中央乗車距離(マイル),1.70
平均乗車時間(分),15.11
ピーク時間帯,18時
ピーク時乗車数,"267,951"
オフピーク時間帯,4時
オフピーク時乗車数,"20,033"
おわりに
Strands AgentsのCode InterpreterビルトインツールでS3連携を試してみました!
大容量のファイルなどを使用する際は活用したいですね。
カスタムでCode Interpreterを作成する必要がある、ビルトインツールではidentifierを指定する必要がありますが、そこまで難しくなく連携できましたね!
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございましたー!!