[Swift] 関数の再帰呼び出しは最適化されているか [LLVM]
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
関数の再帰呼び出し
関数の返り値の一部として自分自身の呼び出し結果を用いるような再帰関数は関数型言語によく見られますが、扱う言語によっては再帰呼び出しを行うとスタックオーバーフローしてしまうなど、実用的なテクニックではない場面もあります。
再帰関数は扱う関数の引数を少なくし、場面によってはコード量を削減することにもつながります。
関数型言語の特徴を数多く備えている Swift での再帰関数の最適化について今回調査をしてみました。
コンパイルでの最適化フラグ
iOS 向けのアプリケーションに関しては、Swift コンパイラの最適化フラグについて、プロジェクトを作成した直後の初期設定で、デバグ用とリリース用で異なる設定がされています。
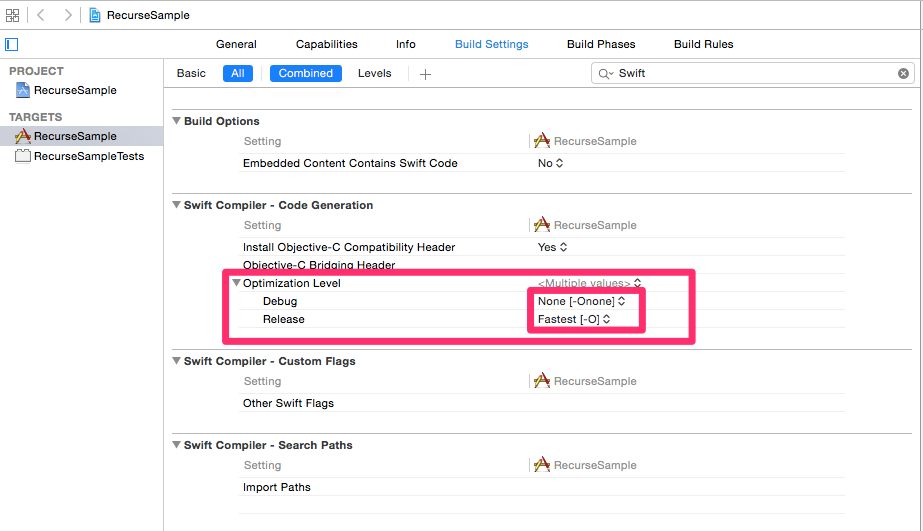
上のスクショはプロジェクト作成直後におけるコンパイラの最適化レベル設定ですが、デバグ用では -Onone フラグを用い、リリース用では -O フラグを用いる事がわかります。
コンパイラのフラグ設定は上記の通りデバグ用とリリース用で異なる事がわかりますが、これをコマンドラインで簡単に再現するため、Swift コンパイル用のコマンド swiftc の最適化フラグについて見てみましょう。
まずコマンドラインで次のように入力してみましょう。すると swiftc コマンドに関する詳細が出てきます。
$ swiftc -h
今回用いる -emit-ir, -Onone, -O フラグについて簡単に見てみましょう。
OVERVIEW: Swift compiler USAGE: swiftc [options] <inputs> MODES: -emit-ir Emit LLVM IR file(s) OPTIONS: -Onone Compile without any optimization -O Compile with optimizations
-emit-ir は対象の Swift ファイルをコンパイルして、LLVM 中間表現を出力します。LLVM 中間表現に関する詳細は邦文での書籍や LLVM Langugage Reference Guideに詳しいです。
-Onone はコンパイラによる最適化を行わないフラグです。Swift のコードは最適化を行わない形で LLVM 中間表現に変換され、各 CPU アーキテクチャ向けにバイナリが生成されます。
-O はコンパイラによる最適化を行うフラグです。こちらは最適化を行って LLVM 中間表現に変換されるため、-Onone とは異なる出力になります。
確認環境
- Xcode 6.1
- Swift 1.1
- iPod Touch 5
- iOS: 8.1
サンプルコード例
今回用いるコードサンプルは以下のような引数 a から 0 までの総和を計算する関数です。
func sumToInt(a: UInt) -> UInt {
if a == 0 {
return 0
}
return a + sumToInt(a - 1)
}
ベンチマークを取る
先ほど見たように、デバグモードではデフォルトで -Onone フラグが設定されていますが、このフラグを入れ替えてサンプルのベンチマークを取ると以下の様な結果を得ました。
テストコード
import XCTest
class RecurseSampleTests: XCTestCase {
func testPerfomance100() {
self.measureBlock {
let result = sumToInt(100)
}
}
func testPerfomance10000() {
self.measureBlock {
let result = sumToInt(10000)
}
}
}
結果ログ
-Onone
Test Case '-[RecurseSampleTests.RecurseSampleTests testPerfomance100]' started. <unknown>:0: Test Case '-[RecurseSampleTests.RecurseSampleTests testPerfomance100]' measured [Time, seconds] average: 0.000, relative standard deviation: 51.857%, values: [0.000053, 0.000020, 0.000018, 0.000017, 0.000017, 0.000017, 0.000017, 0.000016, 0.000017, 0.000017], performanceMetricID:com.apple.XCTPerformanceMetric_WallClockTime, baselineName: "", baselineAverage: , maxPercentRegression: 10.000%, maxPercentRelativeStandardDeviation: 10.000%, maxRegression: 0.100, maxStandardDeviation: 0.100 Test Case '-[RecurseSampleTests.RecurseSampleTests testPerfomance10000]' started. <unknown>:0: Test Case '-[RecurseSampleTests.RecurseSampleTests testPerfomance10000]' measured [Time, seconds] average: 0.001, relative standard deviation: 53.387%, values: [0.002408, 0.001267, 0.000774, 0.000846, 0.000716, 0.000718, 0.000702, 0.000700, 0.000701, 0.000734], performanceMetricID:com.apple.XCTPerformanceMetric_WallClockTime, baselineName: "", baselineAverage: , maxPercentRegression: 10.000%, maxPercentRelativeStandardDeviation: 10.000%, maxRegression: 0.100, maxStandardDeviation: 0.100
-O
Test Case '-[RecurseSampleTests.RecurseSampleTests testPerfomance100]' started. <unknown>:0: Test Case '-[RecurseSampleTests.RecurseSampleTests testPerfomance100]' measured [Time, seconds] average: 0.000, relative standard deviation: 49.749%, values: [0.000040, 0.000017, 0.000014, 0.000013, 0.000013, 0.000013, 0.000013, 0.000013, 0.000013, 0.000013], performanceMetricID:com.apple.XCTPerformanceMetric_WallClockTime, baselineName: "", baselineAverage: , maxPercentRegression: 10.000%, maxPercentRelativeStandardDeviation: 10.000%, maxRegression: 0.100, maxStandardDeviation: 0.100 Test Case '-[RecurseSampleTests.RecurseSampleTests testPerfomance10000]' started. <unknown>:0: Test Case '-[RecurseSampleTests.RecurseSampleTests testPerfomance10000]' measured [Time, seconds] average: 0.000, relative standard deviation: 43.900%, values: [0.000947, 0.000450, 0.000444, 0.000462, 0.000444, 0.000541, 0.000278, 0.000278, 0.000278, 0.000278], performanceMetricID:com.apple.XCTPerformanceMetric_WallClockTime, baselineName: "", baselineAverage: , maxPercentRegression: 10.000%, maxPercentRelativeStandardDeviation: 10.000%, maxRegression: 0.100, maxStandardDeviation: 0.100
average の有効数字の桁数が少ないので隠れていますが、上記のログから計算された平均値は以下の表のとおりです。
| n | -Onone | -O |
|---|---|---|
| 100 | 0.0000209 | 0.0000162 |
| 10000 | 0.0009566 | 0.00044 |
多少なりともコンパイルフラグによって再帰関数に対しても最適化が図られていることが伺えます。
-emit-ir を試す
LLVM 中間表現は CPU アーキテクチャを指定すればプログラムのバイナリと一対一対応する表現ですが、-emit-ir を試すことでどのような中間表現が生成されているかフラグ毎に見てみました。
以下は見出しのコマンドを先ほどの Sum.swift が存在するディレクトリ内で出力した結果になります。
swiftc -emit-ir Sum.swift -Onone
define i64 @_TF3Sum8sumToIntFSuSu(i64) {
entry:
%1 = icmp eq i64 %0, 0
br i1 %1, label %2, label %3
; <label>:2 ; preds = %entry
br label %13
; <label>:3 ; preds = %entry
%4 = call { i64, i1 } @llvm.usub.with.overflow.i64(i64 %0, i64 1)
%5 = extractvalue { i64, i1 } %4, 0
%6 = extractvalue { i64, i1 } %4, 1
br i1 %6, label %15, label %7
; <label>:7 ; preds = %3
%8 = call i64 @_TF3Sum8sumToIntFSuSu(i64 %5)
%9 = call { i64, i1 } @llvm.uadd.with.overflow.i64(i64 %0, i64 %8)
%10 = extractvalue { i64, i1 } %9, 0
%11 = extractvalue { i64, i1 } %9, 1
br i1 %11, label %15, label %12
; <label>:12 ; preds = %7
br label %13
; <label>:13 ; preds = %2, %12
%14 = phi i64 [ %10, %12 ], [ 0, %2 ]
ret i64 %14
; <label>:15 ; preds = %7, %3
call void @llvm.trap()
unreachable
}
swiftc -emit-ir Sum.swift -O
define i64 @_TF3Sum8sumToIntFSuSu(i64) #0 {
entry:
%1 = icmp eq i64 %0, 0
br i1 %1, label %11, label %2
; <label>:2 ; preds = %entry
%3 = tail call { i64, i1 } @llvm.usub.with.overflow.i64(i64 %0, i64 1)
%4 = extractvalue { i64, i1 } %3, 1
br i1 %4, label %13, label %5
; <label>:5 ; preds = %2
%6 = extractvalue { i64, i1 } %3, 0
%7 = tail call i64 @_TF3Sum8sumToIntFSuSu(i64 %6)
%8 = tail call { i64, i1 } @llvm.uadd.with.overflow.i64(i64 %0, i64 %7)
%9 = extractvalue { i64, i1 } %8, 0
%10 = extractvalue { i64, i1 } %8, 1
br i1 %10, label %13, label %11
; <label>:11 ; preds = %5, %entry
%12 = phi i64 [ 0, %entry ], [ %9, %5 ]
ret i64 %12
; <label>:13 ; preds = %5, %2
tail call void @llvm.trap()
unreachable
}
関数内部から他の関数お呼び出す際には、LLVMでも多くのプログラミング言語のように他の関数名を指定して呼び出しますが、その際にcall命令を用います。この命令に tail というマーカーをつけることでCPUに応じたバイナリへの変換で最適化を図る際の目安になります。
上記の2つの例を比較すると、2つ目の例では call 命令の直前に tail マーカーが付けられ、最適化を図るコードをコンパイラが生成してくれている事がわかります。
最後に
リリース時のコンパイルオプションはデフォルトで最適化を図るフラグを立ててくれているため、再帰関数に関しても以上に見たような最適化が図られた LLVM 中間表現が生成されることがわかります。
関数型言語の特徴である再帰関数を Swift でも使用し、副作用の少ないコードを書くようにしていきたいですね。








