![[AWS Glue]ジョブブックマークの動作を確認してみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/aws-glue.png)
[AWS Glue]ジョブブックマークの動作を確認してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
AWS Glueでは、ジョブブックマークという機能を使用することにより、最後のジョブ実行以降の増分データのみを処理対象とすることが可能です。
今回は、ジョブブックマークが有効なGlueジョブで、前回のジョブ実行で処理済みのパーティションやS3オブジェクトに増分データが追加された場合の次回のGlueジョブでの動作を確認してみました。
確認すること
具体的は、AWSドキュメントに記載されている下記仕様通りの動作となるかを実際に確認してみます。
S3 に保存されている処理対象のファイルを識別するため、ジョブブックマークはファイル名ではなくオブジェクトの最終変更時刻を確認します。ジョブが最後に実行されてから入力オブジェクトが変更された場合、ジョブが再度実行されるときに入力オブジェクトが再処理されます。
AWS Glue データカタログ内の特定のパーティションの作成タイムスタンプが、ジョブブックマークによってキャプチャされた最後のジョブ実行のタイムスタンプよりも古い場合、パーティションがスキップされます。
確認してみた
環境作成
動作確認環境を作成します。
CloudFormationスタック
@
データソースとなるGlueデータカタログのリソース定義です。パーティションキーは`year`、`month`、`day`となります。
```yaml:template.yaml
RawDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesDataAnalyticsGlueDatabase
TableInput:
Name: devices_raw_data
TableType: EXTERNAL_TABLE
Parameters:
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: device_id
Type: string
- Name: timestamp
Type: bigint
- Name: state
Type: boolean
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesRawDataBucket}/raw-data
SerdeInfo:
Parameters:
paths: "device_id, timestamp, state"
SerializationLibrary: org.apache.hive.hcatalog.data.JsonSerDe
PartitionKeys:
- Name: year
Type: string
- Name: month
Type: string
- Name: day
Type: string
Glueジョブのリソース定義です。ジョブブックマークを有効にする場合はjob-bookmark-optionをjob-bookmark-enableとする必要があります。
DevicesDataETLGlueJob:
Type: AWS::Glue::Job
Properties:
Name: devices-data-etl
Command:
Name: glueetl
PythonVersion: 3
ScriptLocation: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-script/devices-data-etl.py
DefaultArguments:
--job-language: python
--job-bookmark-option: job-bookmark-enable
--TempDir: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-temp-dir
--GLUE_DATABASE_NAME: !Sub ${DevicesDataAnalyticsGlueDatabase}
--SRC_GLUE_TABLE_NAME: !Sub ${RawDataGlueTable}
--DEST_GLUE_TABLE_NAME: !Sub ${IntegratedDataGlueTable}
GlueVersion: 2.0
ExecutionProperty:
MaxConcurrentRuns: 1
MaxRetries: 0
Role: !Ref ExecuteETLJobRole
Glueジョブスクリプト
GlueジョブのPySparkスクリプトは下記のようになります。今回は処理内容ではなく処理対象のデータが何であるかを確認したいので、データソースから取得したデータを変更を加えずデータターゲットに書き込むだけの処理内容となっています。
@
データソースからのデータ取得時にジョブブックマークを使用する場合は、`create_dynamic_frame.from_catalog()`で`transformation_ctx`オプションを指定します。
- [Tracking Processed Data Using Job Bookmarks - AWS Glue](https://docs.aws.amazon.com/glue/latest/dg/monitor-continuations.html)
> For job bookmarks to work properly, enable the job bookmark parameter and set the transformation_ctx parameter. If you don't pass in the transformation_ctx parameter, then job bookmarks are not enabled for a dynamic frame or a table used in the method.
```python:devices-data-etl.py
df = glueContext.create_dynamic_frame.from_catalog(
database = args['GLUE_DATABASE_NAME'],
table_name = args['SRC_GLUE_TABLE_NAME'],
transformation_ctx = 'datasource'
).toDF()
デプロイ
以降のコマンド実行で使用する変数を定義します。
% AWS_REGION=ap-northeast-1
% ACCOUNT_ID=$(aws sts get-caller-identity | jq -r ".Account")
% RAW_DATA_BUCKET=s3://devices-raw-data-${ACCOUNT_ID}-${AWS_REGION}
% DATA_ANALYTICS_BUCKET=s3://devices-data-analytics-${ACCOUNT_ID}-${AWS_REGION}
CloudFormationスタックをデプロイします。
% aws cloudformation deploy \
--template-file template.yaml \
--stack-name devices-data-analytics-stack \
--capabilities CAPABILITY_NAMED_IAM \
--no-fail-on-empty-changeset
GlueジョブのスクリプトをS3バケットにアップロードします。
% aws s3 cp devices-data-etl.py \
${DATA_ANALYTICS_BUCKET}/glue-job-script/devices-data-etl.py
動作確認
確認1:新規パーティション・新規オブジェクト
Glueジョブで未処理の新規パーティションに新規オブジェクトとしてデータが作成された場合のジョブ実行時の動作を確認してみます。(後続の確認2,3と比較のため)
データが記載されたオブジェクトraw-data-A.jsonをS3バケットのパーティションパスに作成します。
{"device_id": "3ff9c44a", "timestamp": 1609348014, "state": true}
% aws s3 cp raw-data-1.json \
${RAW_DATA_BUCKET}/raw-data/year=2021/month=01/day=06/raw-data-A.json
データカタログのパーティションを更新します。
% aws athena start-query-execution \
--query-string "MSCK REPAIR TABLE ${GLUE_DATABASE_NAME}.${RAW_DATA_GLUE_TABLE_NAME}" \
--work-group primary
ジョブを実行します。
% aws glue start-job-run --job-name devices-data-etl
スクリプト内でのdf.show()の出力を見ると、下記のように追加したデータが過不足なく取得できていることが分かります。
>>> df.show()
+---------+----------+-----+----+-----+---+
|device_id| timestamp|state|year|month|day|
+---------+----------+-----+----+-----+---+
| 3ff9c44a|1609348014| true|2021| 01| 06|
+---------+----------+-----+----+-----+---+
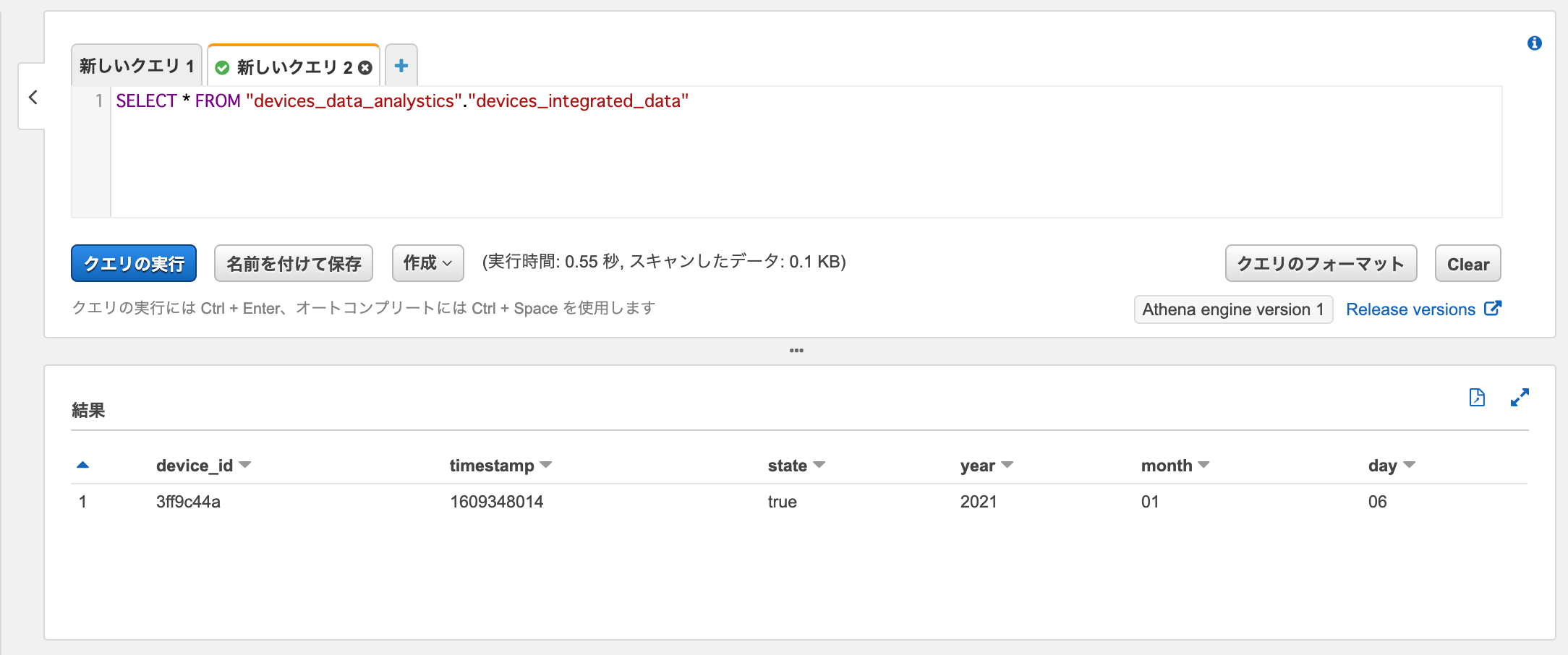
データターゲットのデータカタログからデータを取得してみます。
SELECT * FROM "devices_data_analystics"."devices_integrated_data"
データソースから取得されたデータがデータターゲットにロードされています。
確認2:処理済みパーティション・新規オブジェクト
前回のGlueジョブで処理済みのパーティションに新規オブジェクトとしてデータが作成された場合のジョブ実行時の動作を確認してみます。
データが記載されたオブジェクトraw-data-B.jsonをS3バケットの前回と同じパーティションパスに作成します。
{"device_id": "e36b7dfa", "timestamp": 1609375822, "state": true}
% aws s3 cp raw-data-2.json \
${RAW_DATA_BUCKET}/raw-data/year=2021/month=01/day=06/raw-data-B.json
ジョブを実行します。
% aws glue start-job-run --job-name devices-data-etl
スクリプト内でのdf.show()の出力を見ると、下記のように追加したデータが過不足なく取得できていることが分かります。
>>> df.show()
+---------+----------+-----+----+-----+---+
|device_id| timestamp|state|year|month|day|
+---------+----------+-----+----+-----+---+
| e36b7dfa|1609375822| true|2021| 01| 06|
+---------+----------+-----+----+-----+---+
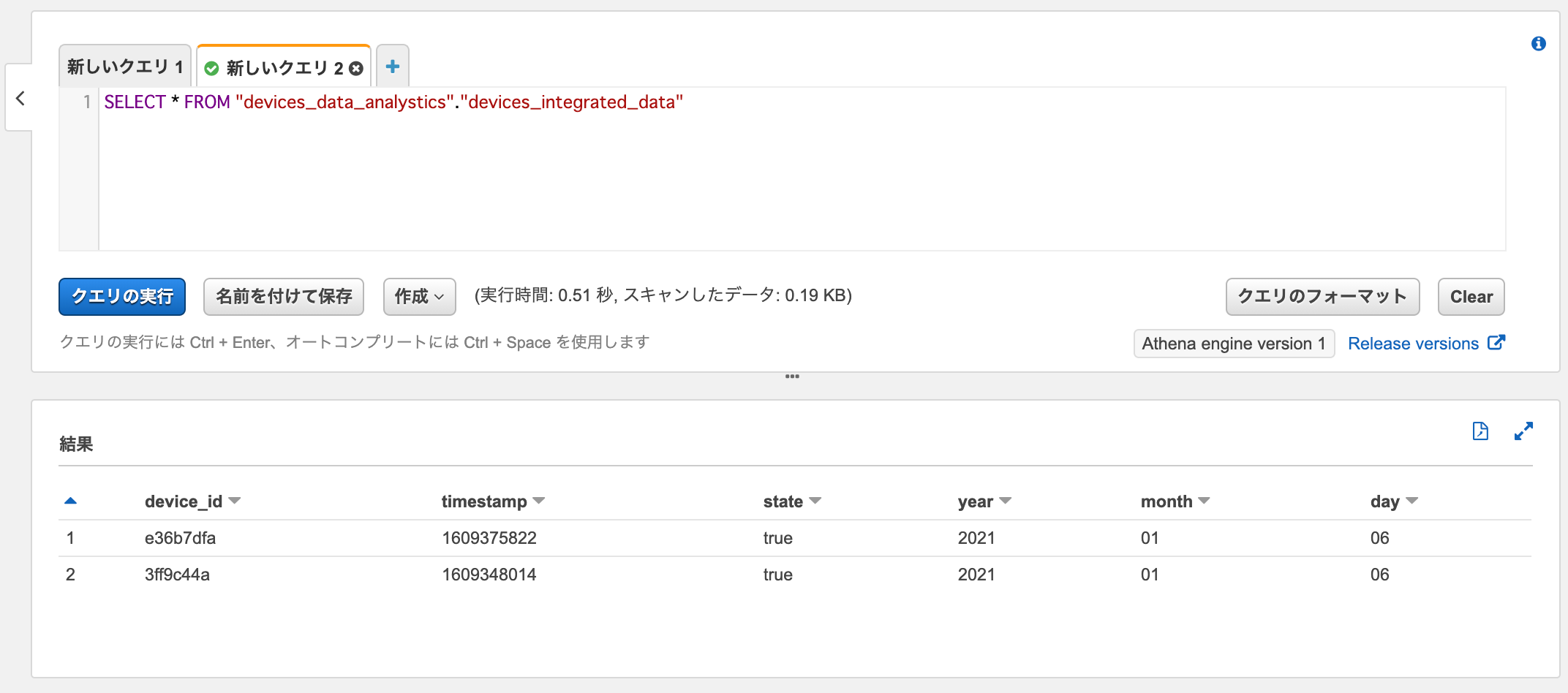
データターゲットのデータカタログからデータを取得してみます。
SELECT * FROM "devices_data_analystics"."devices_integrated_data"
データソースから取得された追加のデータ(device_id=e36b7dfa)がデータターゲットにロードされています。
確認3:処理済みパーティション・処理済みオブジェクト
前回のGlueジョブで処理済みのオブジェクトに追記によりデータが追加された場合のジョブ実行時の動作を確認してみます。
前回処理したものと同じ名前で、2行目にデータが追記されたオブジェクトraw-data-B.jsonを、S3バケットの前回と同じパーティションパスに作成します。
{"device_id": "e36b7dfa", "timestamp": 1609375822, "state": true}
{"device_id": "7d4215d0", "timestamp": 1609497057, "state": false}
% aws s3 cp raw-data-3.json \
${RAW_DATA_BUCKET}/raw-data/year=2021/month=01/day=06/raw-data-B.json
ジョブを実行します。
% aws glue start-job-run --job-name devices-data-etl
スクリプト内でのdf.show()の出力を見ると、下記のように今回追記したデータに加えて、前回処理したデータが重複して取得されていることが分かります。
>>> df.show()
+---------+----------+-----+----+-----+---+
|device_id| timestamp|state|year|month|day|
+---------+----------+-----+----+-----+---+
| e36b7dfa|1609375822| true|2021| 01| 06|
| 7d4215d0|1609497057|false|2021| 01| 06|
+---------+----------+-----+----+-----+---+
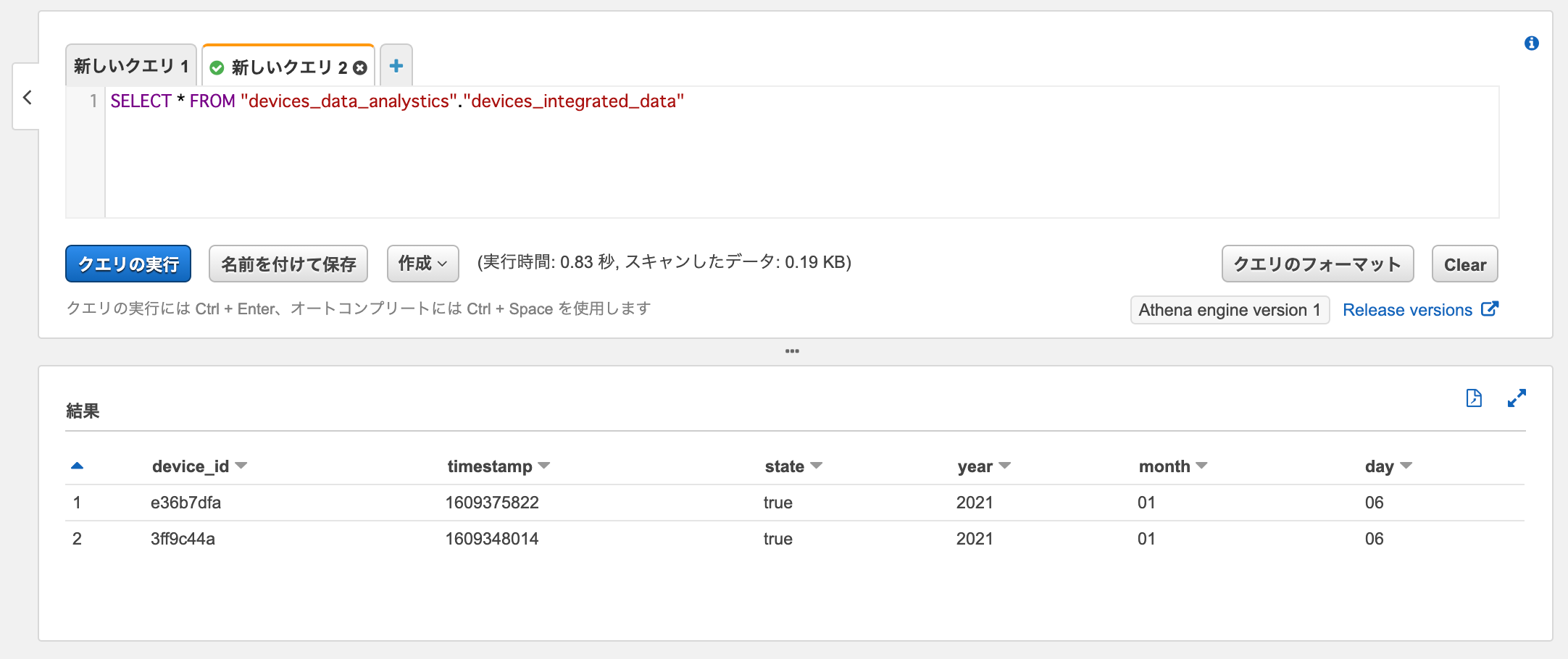
データターゲットのデータカタログからデータを取得してみます。
SELECT * FROM "devices_data_analystics"."devices_integrated_data"
今回はデータターゲットには追加のデータがロードされていませんでした。
この動作は、ジョブブックマークはデータソースからのデータ取得時だけでなく、データターゲットへのデータロード時にも適用させることができるためです。
データターゲットへのデータロード時にジョブブックマークを使用する場合も、write_dynamic_frame.from_catalog()でtransformation_ctxオプションを指定します。
glueContext.write_dynamic_frame.from_catalog(
frame = dyf,
database = args['GLUE_DATABASE_NAME'],
table_name = args['DEST_GLUE_TABLE_NAME'],
transformation_ctx = 'datasink'
)
まとめ
検証結果をまとめると下記の通りとなりました。(データソースからのデータ取得、データターゲットへのデータロードのいずれでもジョブブックマークを有効にした場合)冒頭で示したAWSドキュメント通りの仕様となりました。
- 前回までのジョブで処理済みのパーティション内に作成されたオブジェクトのデータは、データソースからの取得、データターゲットへのロードの対象となる。
- 前回までのジョブで処理済みのオブジェクトにデータが追記された場合は、そのオブジェクトのデータはデータソースからの取得の対象となる(ジョブ内でのデータの重複が発生する)が、データターゲットへのロードの対象とはならない(データの欠損が発生する)。
ちなみに、Amazon Kinesis Data FirehoseによりS3バケットへ配信されたデータをGlueジョブのデータソースとする場合は、レコードが重複なく保持されているバッファごとにランダムな名前のオブジェクトが作成されるので、2.の仕様を懸念する必要はなさそうです。
The frequency of data delivery to Amazon S3 is determined by the Amazon S3 Buffer size and Buffer interval value that you configured for your delivery stream. Kinesis Data Firehose buffers incoming data before it delivers it to Amazon S3.
The Amazon S3 object name follows the pattern DeliveryStreamName-DeliveryStreamVersion-YYYY-MM-dd-HH-MM-SS-RandomString,
おわりに
ジョブブックマークが有効なGlueジョブで、前回のジョブ実行で処理済みのパーティションやS3オブジェクトに増分データが追加された際の動作を確認してみました。
このようにGlueのジョブブックマークはデータの処理履歴を裏側でよろしく管理してくれてとても便利なのでGlueジョブを使う際は是非とも有効活用したいですね。
参考
以上









