
商品名の名寄せに生成AIを使ってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
1. はじめに
データ事業本部のおざわです。最近は生成AI関連のニュースを目にしない日がありませんね。
生成AIの企業向けユースケースとしては、SnowflakeのCortexや開発アシスタントのCopilotといったものが注目されていますが、生成AIはデータマネジメントの領域でも活用されています。
先日、クラメソ日比谷オフィスで開催されたセミナーのデータマネジメントに関するセッションや、2月のウェビナーにもたくさんのお客様がご参加いただき、データマネジメントへの注目度が高まっている印象です。
2. 今回のテーマ
データマネジメントの11領域の中で、「データ品質」の課題を扱います。データ品質を一言でいうと「データが目的に合致しているかの度合い」と言えます。今回は、商品データの集計をしたいが、商品マスターも存在せず、さらに商品名が統一されていないという課題を設定しました。
この課題に対して、生成AIを使った名寄せを行うことで対処したいと思います。
名寄せについて
名寄せは、表記ゆれや重複を統一して同一のエンティティ(商品、顧客など)を一意に識別できるようにするプロセスです。例えば、「くらにゃんお箸セット」と「くらにゃん・おはしセット」は同じ商品ですが、商品名の表記が異なります。このままだと正確な管理や集計、分析が難しくなりますので、何らかの方法でデータを整える必要があります。
従来の対応方法
従来からある名寄せとしては、ルールベースで変換していく方法があります。RedshiftでSQLを使ってルールベースの名寄せを行う場合、以下のような関数を使って文字列を置換していく方法が考えられます。
この場合、すべての変換規則を事前に洗い出す必要があり、新しいパターンが出てきたら都度SQLを修正してメンテナンスしていく手間が発生します。こうした地味に困る課題を解決するためにも生成AIが使えます。
サンプルの商品リスト
サンプルとして使うのは、以下のようなガジェット、電化製品といった商品のリスト200件です。商品名に表記ゆれが発生しており、さらに「セール中」や「ポイントN倍!」のようなプロモーション用の文言が含まれています。こうしたデータは、マスターと紐づけることができればよいですが、現実にはそれが難しいケースもあるかと思います。
1,【新品&今だけポイントUP】Apple iPhone 15 Pro Max 256GB チタニウムナチュラル ★早い者勝ち★
2,アイフォン15プロマックス 256GB ナチュラルチタン ■送料無料&大人気■
3,IPHONE 15 PRO MAX (256G) TITANIUM 国内正規品 特価セール開催中!
4,【24年最新】MacBook Air 15インチ M2チップ ◆台数限定◆
5,マックブックエアー 15 M2 スペースグレイ ★今が買い時★
3. 生成AIによる名寄せ
今回はAWSの生成AIサービスであるAmazon Bedrockを使用します。Amazon Bedrockは、複数の基盤モデル(Foundation Model/FM)を提供し、APIを通じて簡単に利用できるサービスです。今回はAnthropicのClaude 3.5 Sonnetをバージニアリージョンで使用します。
設定とプロンプト
推論パラメータはTemperatureの値を変更しています。Temperatureを簡単に説明すると、モデル出力のランダム性(ばらつき)を制御するパラメータになります。値が0に近いほど出力が決定的(同じ入力に対して同じ出力を返す)になり、1に近いほど多様な出力が生成されます。今回使用したモデルでは、Temperatureのデフォルト値が1に設定されていましたので、なるべく一貫性を保つために0に変更しています。
使用したプロンプトは以下のサンプルコードにあります。ポイントとしては最初に何をやらせるのか生成AIに一言で伝えて、名寄せルールと出力フォーマットを伝えている部分です。
サンプルコード
import time
import textwrap
import pandas as pd
import boto3
import json
import io
class ProductNameDeduper:
"""
商品名の名寄せを行うクラス。
名寄せルールに基づき表記を統一する。
"""
def __init__(self, aws_region: str = "us-east-1"):
session = boto3.Session(region_name=aws_region)
self._model_identifier = "anthropic.claude-3-5-sonnet-20240620-v1:0"
self._bedrock_runtime_client = session.client(
service_name="bedrock-runtime",
region_name=aws_region
)
def __invoke_bedrock(self, context_message: str, customer_input: str) -> str:
"""
Bedrockにリクエストを行う
ThrottlingExceptionが出た際は3回までリトライする。
"""
# リクエストのペイロードを作成
payload = json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4096,
"temperature": 0,
"system": context_message,
"messages": [
{
"role": "user",
"content": [{"type": "text", "text": customer_input}],
}
],
}
)
for _ in range(3):
try:
response = self._bedrock_runtime_client.invoke_model(
modelId=self._model_identifier,
body=payload
)
api_result = json.loads(response.get("body").read())
# 使用トークン数の出力
print(api_result["usage"])
return api_result["content"][0]["text"]
except self._bedrock_runtime_client.exceptions.ThrottlingException as te:
print("Exceeded rate: wait 10 seconds...")
time.sleep(10)
except Exception:
raise
raise RuntimeError("Failed to get response from Bedrock service.")
def identify_and_normalize_products(self, input_data: pd.DataFrame) -> pd.DataFrame:
"""
商品名の名寄せを行って結果をDataFrameで返す
"""
system_prompt_msg = textwrap.dedent("""
あなたはECサイトに掲載された商品名の名寄せを行うアシスタントです。
各商品にはIDと商品名が入力として与えられます。商品名にばらつきがある場合でも、できる限り本来の正しい商品名を推測し、一定のルールに基づいて表記を統一してください。
▼ 名寄せルール
1. 不要な接尾辞や修飾語(例: "~セット", "数量限定"など)は基本的に削除し、商品名の本質的な部分のみを残してください。
2. メーカーやブランド名などが商品名の一部として確実に必要な場合のみ残し、それらにゆらぎがあれば統一した表記に整えてください(例: "Sony"/"SONY"/"ソニー"→"Sony")。
3. バージョンや型番など、商品本体に必須の情報が含まれている場合は残してください(例: "iPhone 13 Pro"など)。
4. カラー、サイズ、容量といった情報は今回の集計には不要なので削除してください。
5. 上記ルールに当てはまらない場合は、可能な範囲で統一し、未知の場合は元の表記を尊重しつつ簡潔にしてください。
▼ 出力フォーマットのルール
1. 出力はCSV形式でヘッダーは不要です。
2. 返事や解説などは一切不要で、CSVの中身のみを返してください。
3. 列は必ず"id","product"の2列だけにしてください。
4. "id"は入力で与えられた値をそのまま出力すること。
5. "product"は上記の名寄せルールに従って統一した商品名を出力してください。
以下がIDと商品名の一覧です。
""")[1:-1]
target_columns = ["id", "product"]
# 結果をまとめるデータフレーム
consolidated_data = pd.DataFrame(columns=target_columns)
batch_size = 20 # 1回あたりの処理件数
for i in range(0, len(input_data), batch_size):
batch_df = input_data[i : i + batch_size].copy()
csv_data = batch_df.to_csv(index=False)
completion = self.__invoke_bedrock(
context_message=system_prompt_msg,
customer_input=csv_data
)
# 返ってきたCSVからDataFrameを生成、列名をそろえる
parsed_result = pd.read_csv(
io.StringIO(completion),
header=None,
names=target_columns
)
consolidated_data = pd.concat(
[consolidated_data, parsed_result],
ignore_index=True
)
print(f"len(consolidated_data) = {len(consolidated_data)}")
return consolidated_data
if __name__ == "__main__":
source_csv = './input/product_list.csv'
print(f"starting: {source_csv}")
# 入力データの読み込み
df_input = pd.read_csv(source_csv)
df_input = df_input[["id","text"]]
print(df_input.head())
# クラスインスタンス化
normalizer = ProductNameDeduper()
# 名寄せ処理を実行
consolidated_result = normalizer.identify_and_normalize_products(df_input)
print(consolidated_result.head())
# 元のDataFrameとマージして出力
final_output = df_input.merge(consolidated_result, how="left", on="id")
final_output.to_csv('./output/result.csv', index=False)
コスト
実行時のコストも気になると思いますので、ざっくりと見積もる方法について共有します。多くの場合、生成AIを使う際に大きなコストになるのは入出力のトークン数になります。一番簡単な見積方法としては、実際に使用するプロンプトとデータの一部を投げてみることです。
print(api_result["usage"])
# {'input_tokens': 1267, 'output_tokens': 256}
今回のコードだと上記の部分で1回のループで使用する入出力トークン数がわかります。現時点でオンデマンドのトークンの料金は以下になっています。
| モデル | 入力トークン1000個あたりの価格 | 出力トークン1000個あたりの価格 |
|---|---|---|
| Claude 3.5 Sonnet | 0.003 USD | 0.015 USD |
少し多めに見積もって入力トークンが1300、出力トークン300として、これを10回実行しますので入力トークンで$0.039、出力トークンで$0.045の計$0.084($1=160円で13.44円)程度で済みそうです。実際に試す際にはモデルごとの最新の料金表をご確認いただければと思います。
4. 結果
全部だと長いので一部を共有します。200件の商品名リストを42件にまとめることができましたが、そのうちの十数件については改善の余地がありそうです。
プロダクト別件数
プロダクト名,件数
AirPods Pro 第2世代,8
Amazon Kindle Oasis Pro,3
Kindle Oasis Pro,4
Apple iPad Pro 13,4
iPad Pro 13,1
iPad Pro 13 M3,2
iPad Air 第6世代,6
Apple iPhone 15 Pro Max,1
iPhone 15 Pro Max,5
Apple Watch Series 9,2
Apple Watch Series 9 45mm,3
Apple Watch Series 9 45mm GPS,2
ASUS ZenBook 14 OLED,7
Bose QuietComfort 45,7
Canon EOS R8,7
DJI Air 3,7
DualSense Edge コントローラー,7
Dyson V15 Detect,1
Dyson V15 Detect Complete,1
Dyson V15 Detect Submarine,6
FUJIFILM X-T5,7
Google Pixel 8 Pro,7
GoPro HERO12 Black,7
HP Spectre x360 14,6
HP x360 14,1
Lenovo ThinkPad X1 Carbon,3
Lenovo ThinkPad X1 Carbon Gen11,4
MacBook Air 15 M2,3
MacBook Air 15インチ M2,3
Nintendo Switch Lite,7
Nintendo Switch Pro コントローラー Zelda Edition,7
Nintendo Switch 有機ELモデル,8
Panasonic LUMIX S5II,7
PlayStation 5 Digital Edition,4
PlayStation 5 デジタルエディション,4
Razer Blade 16,7
Samsung Galaxy S24 Ultra,6
Sony WF-1000XM5,7
Sony WH-1000XM5,7
Surface Pro 9,4
Xiaomi Redmi Note 13 Pro,1
Xiaomi Redmi Note 13 Pro 5G,6
以下、うまく名寄せできていないケースの例です。型番に余計なスペースが入っていたり、ブランド(企業)名が入っていたりいなかったりするケースがありました。このあたりはプロンプトで調整できそうなものもあれば、人間の手で修正するべきものもありそうです。また、今回は20件ずつ商品リストを渡してますが、1回のリクエストに含める商品によっても結果が変わりそうです。
140,【新タイプ】HP Spectre x360 (2024) 限定色 ★先行販売★,HP Spectre x360 14
141,HP x36014 ブルーリバー スペシャルエディション 大感謝祭実施中!,HP x360 14
<中略>
164,【新機種】Amazon Kindle Oasis Pro 32GB ★電子書籍ライフを快適に★,Amazon Kindle Oasis Pro
165,キンドル オアシス プロ 32GB 防水 今ならポイントUP↑,Kindle Oasis Pro
166,Kindle Oasis Pro 2024 電子書籍リーダー ★売れてます★,Kindle Oasis Pro
<中略>
171,【新品】Apple iPhone 15 Pro Max 256GB チタニウムナチュラル,Apple iPhone 15 Pro Max
172,アイフォン15プロマックス 256GB ナチュラルチタン,iPhone 15 Pro Max
173,IPHONE 15 PRO MAX (256G) TITANIUM 国内正規品,iPhone 15 Pro Max
以下はうまくいったケースの例です。商品名をモデル名(iPhone 15 Pro Max)までにするのか、容量・サイズまで含めるのかといった部分はユースケースにもよります。必要であればプロンプトで別項目として出力するよう指示できるかと思います。
1,【新品&今だけポイントUP】Apple iPhone 15 Pro Max 256GB チタニウムナチュラル ★早い者勝ち★,iPhone 15 Pro Max
2,アイフォン15プロマックス 256GB ナチュラルチタン ■送料無料&大人気■,iPhone 15 Pro Max
3,IPHONE 15 PRO MAX (256G) TITANIUM 国内正規品 特価セール開催中!,iPhone 15 Pro Max
4,【24年最新】MacBook Air 15インチ M2チップ ◆台数限定◆,MacBook Air 15インチ M2
5,マックブックエアー 15 M2 スペースグレイ ★今が買い時★,MacBook Air 15インチ M2
<中略>
15,Nintendo Switch 有機ELモデル ホワイト ☆今だけ特別価格☆,Nintendo Switch 有機ELモデル
16,ニンテンドースイッチ OLED 白 キャンペーン中!,Nintendo Switch 有機ELモデル
17,任天堂 Switch 有機EL ■数量限定セール■,Nintendo Switch 有機ELモデル
5. 実運用でのポイントと注意点
最後に実運用する際の注意点についても触れておきます。
出力結果について
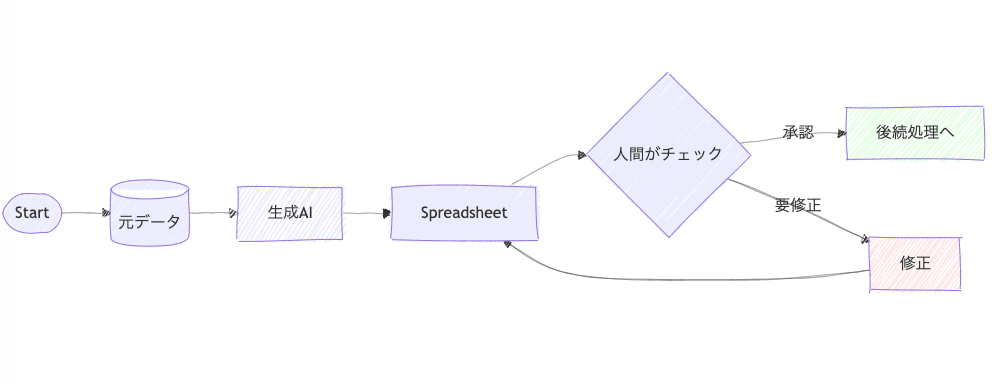
生成AIが毎回同じ結果を返してくれるとは限りません。また、場合によってはドメイン知識をもった人に生成AIの出力結果を確認してもらわないと、そのままではデータが使えないような場合もあるかと思います。こういった人間の手を介したワークフローの案として、ちょっと雑な図ですが、以下のような形で生成AIの出力結果をスプレッドシート等に出力し、承認済みのデータだけを後続の処理で使用するような運用を設計する必要があります。
実装について
また、今回使用したサンプルコードでは、エラー処理は最低限のものになっています。Amazon BedrockのAPIを使用する際、タイミングによってはService Unavailable (503)などのエラーも発生することがありますし、指示した出力形式で応答が返ってこないケースも発生します。本番運用する際には、こうしたケースも想定した実装が必要かと思います。
6. おわりに
本ブログでは、生成AIを使用した名寄せのサンプルをご紹介しました。今回は名寄せを行いましたが、同じようにして商品のカテゴリを付与したり、タグを付けたりといった使い方もできそうです。使用するモデルやプロンプトを変えて、いろいろと試してみていただければと思います!
次回は、データ事業本部の社員が生成AI関連のSaaSアプリケーションを紹介するブログを予定していますので、よろしければご覧になってください。









