
MotherDuckのLLM機能を使ってテキストデータから情報を抜き出してみた
はじめに
データ事業本部のおざわです。
また愛車(16歳)の警告灯が点灯しました。手がかかるほど愛着がわいてくるものです。
先日、ECL(Extract-Contextualize-Load)なる概念について書かれたブログを目にしました。テキストデータのような非構造化データからLLMを使ってコンテキスト(意味のある情報)を抽出するといった話をみて、ずいぶん昔に働いていた事業会社でお客様とのチャット履歴がDBに眠っていたのを思い出しました。
恐らく他の会社でもチャット履歴や商品のレビュー、アンケートの自由回答など、データとして保存されていても有効活用されていないデータがありそうです。ちょっと調べてみたところ、こちらのMotherDuck公式ブログの記事を発見しました。
A large portion of an organization’s data often exists in unstructured form - text - making it hard to analyze when compared to well-organized, formatted, structured data. In the past, analyzing such unstructured data posed a significant challenge due to complex or otherwise limited tooling. However, with large language models (LLMs), transforming and analyzing unstructured data is now much more accessible. These models can extract valuable information and produce structured, typed outputs from unstructured sources, greatly simplifying the data transformation process.
DeepL翻訳
組織のデータの大部分は、構造化されていないテキスト形式で存在することが多く、よく整理され、フォーマットされた構造化データと比較すると、分析が困難である。 以前は、このような非構造化データを分析することは、複雑なツールや限られたツールのために大きな課題となっていました。 しかし、大規模言語モデル(LLM)を使用することで、非構造化データの変換と分析がより身近になりました。 これらのモデルは、非構造化ソースから貴重な情報を抽出し、構造化された型付き出力を生成することができ、データ変換プロセスを大幅に簡素化する。
いいですね。このブログに書いてある方法であれば基本的にはSQLだけで完結しますので、DBに眠っているテキストデータを試しに掘り起こしてみるにはよさそうと思い、さっそく試してみました。
MotherDuck
クラウド上でDuckDBを動かせるMotherDuckですが、いくつかAI関連の機能も用意されており、トライアル中でもこの機能を利用できます。
有料版MotherDuckの料金プランやAI機能の価格については公式サイトに記載されています。
テキストデータ
今回サンプルとして使用するテキストデータは、HuggingFaceで公開されているAmazonの商品レビューの日本語データセットです。 ここから以下のような項目の抽出を行います。
| 項目 | 説明 |
|---|---|
| sentiment | レビューの感情(センチメント)を返す。値は positive、neutral または negative |
| product_features | レビューで言及されている機能 |
| pros | レビューで言及されているメリットや肯定的な側面 |
| cons | レビューで言及されているデメリットや否定的な側面 |
| mentions_price | レビューが価格情報に言及しているかどうか |
| mentions_shipping | レビューが配送情報に言及しているかどうか |
| mentions_packaging | レビューが梱包情報に言及しているかどうか |
| purchase_reason | レビューで言及されている購入理由 |
| quality_concerns | レビューで言及された品質に関する懸念 |
テキストデータからどういった観点で情報を抽出するかは、ケース・バイ・ケースになると思いますが、今回はさきほどのMotherDuckのブログに記載されていたものから何個かピックアップして使っています。
やったこと
dbtの設定やモデルについて確認していきます。
リネージはこんな形になっています。
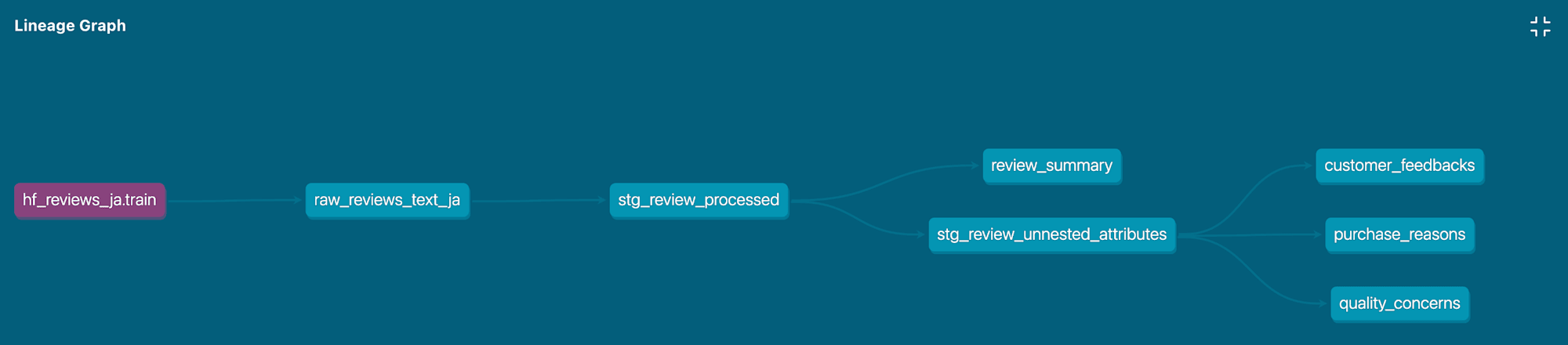
最初にHuggingFaceのデータセットから200字数以上の商品レビューを抜き出しています。続いてLLMにレビューのテキストを投げて、返ってきたデータを集計したり、見たい内容のテキストを抜き出すということをしています。
設定
profiles.ymlです。typeはduckdb、pathはmd:のあとにMotherDuck上で作成したデータベース名と払い出したトークンを指定します。MotherDuckのサインアップ方法やトークンの取得方法については、こちらのブログに説明がありますのでご確認ください。
my_ecl_trial:
outputs:
dev:
type: duckdb
path: "md:my_db?motherduck_token={{ env_var('MOTHERDUCK_TOKEN') }}"
threads: 4
extensions:
- httpfs
- parquet
target: dev
ソースの指定
データソースは以下のような形で指定しています。
sources:
- name: hf_reviews_ja
meta:
external_location: "hf://datasets/SetFit/amazon_reviews_multi_ja@~parquet/default/train/0000.parquet"
tables:
- name: train
hf:// プリフィクスを使うことで、まるで手元にデータがあるかのように公開データセットが使えます。毎回エンドポイントにアクセスするのを防ぎたければ、CREATE TABLEすることでローカルにデータセットを保存できます。今回、DuckDBがすごいなと改めて感じたポイントでした。DuckDBの公式ブログに使い方が掲載されていますのでご興味がある方は見てみてください。
dbtモデル
raw_reviews_text_ja
レビューの文字数が200字以上あるデータを評価ごとに20件ずつ、計100件取得しています。
{{ config(materialized='view') }}
with source_data as (
select
id,
text as review_text,
label as stars,
row_number() over (partition by label order by random()) AS row_num
from {{ source('hf_reviews_ja', 'train') }}
where length(text) >= 200
),
final as (
select
id,
review_text,
stars
from source_data
WHERE row_num <= 20
order by stars
)
select *
from final
stg_review_processed
今回のキモになる部分のモデルです。執筆時点ではプレビュー公開になっているprompt関数を使っています。ドキュメントによるとOpenAIのgpt-4o-miniがデフォルトで使用され、gpt-4oも選ぶことができるようです。
{{ config(materialized="table") }}
select id, prompt_struct_response.*
from
(
select
id,
prompt(
'あなたはテキストから分析に必要な情報(コンテキスト)を抽出するAIアシスタントです。\n'
|| '顧客の商品レビューのテキストから情報を抜き出してください。指示した形式のデータを返し、レスポンスは日本語にしてください。\n'
|| '以下が情報を抜き出すレビューになります:'
|| '```'
|| review_text
|| '```',
struct := {
sentiment:'VARCHAR',
product_features:'VARCHAR[]',
pros:'VARCHAR[]',
cons:'VARCHAR[]',
mentions_price:'BOOLEAN',
mentions_shipping:'BOOLEAN',
mentions_packaging:'BOOLEAN',
purchase_reason:'VARCHAR[]',
quality_concerns:'VARCHAR[]',
},
struct_descr := {
sentiment:'レビューの感情(センチメント)を返す。値は `positive`、`neutral` または `negative` のみ取ることができる',
product_features:'レビューで言及されている機能のリスト、言及がない場合は空の配列を返す',
pros:'レビューで言及されているメリットや肯定的な側面のリスト、言及がない場合は空の配列を返す',
cons:'レビューで言及されているデメリットや否定的な側面のリスト、言及がない場合は空の配列を返す',
mentions_price:'レビューが価格情報に言及しているかどうかを示す',
mentions_shipping:'レビューが配送情報に言及しているかどうかを示す',
mentions_packaging:'レビューが梱包情報に言及しているかどうかを示す',
purchase_reason:'レビューで言及されている購入理由のリスト、言及がない場合は空の配列を返す',
quality_concerns:'レビューで言及された品質に関する懸念のリスト、言及がない場合は空の配列を返す',
}
) as prompt_struct_response
from {{ ref('raw_reviews_text_ja') }}
)
selectした項目に加えて、structで指定した項目が結果として返ってきます。このモデルを実行して作られるテーブルの定義をMotherDuckで見てみると以下のようになっています。
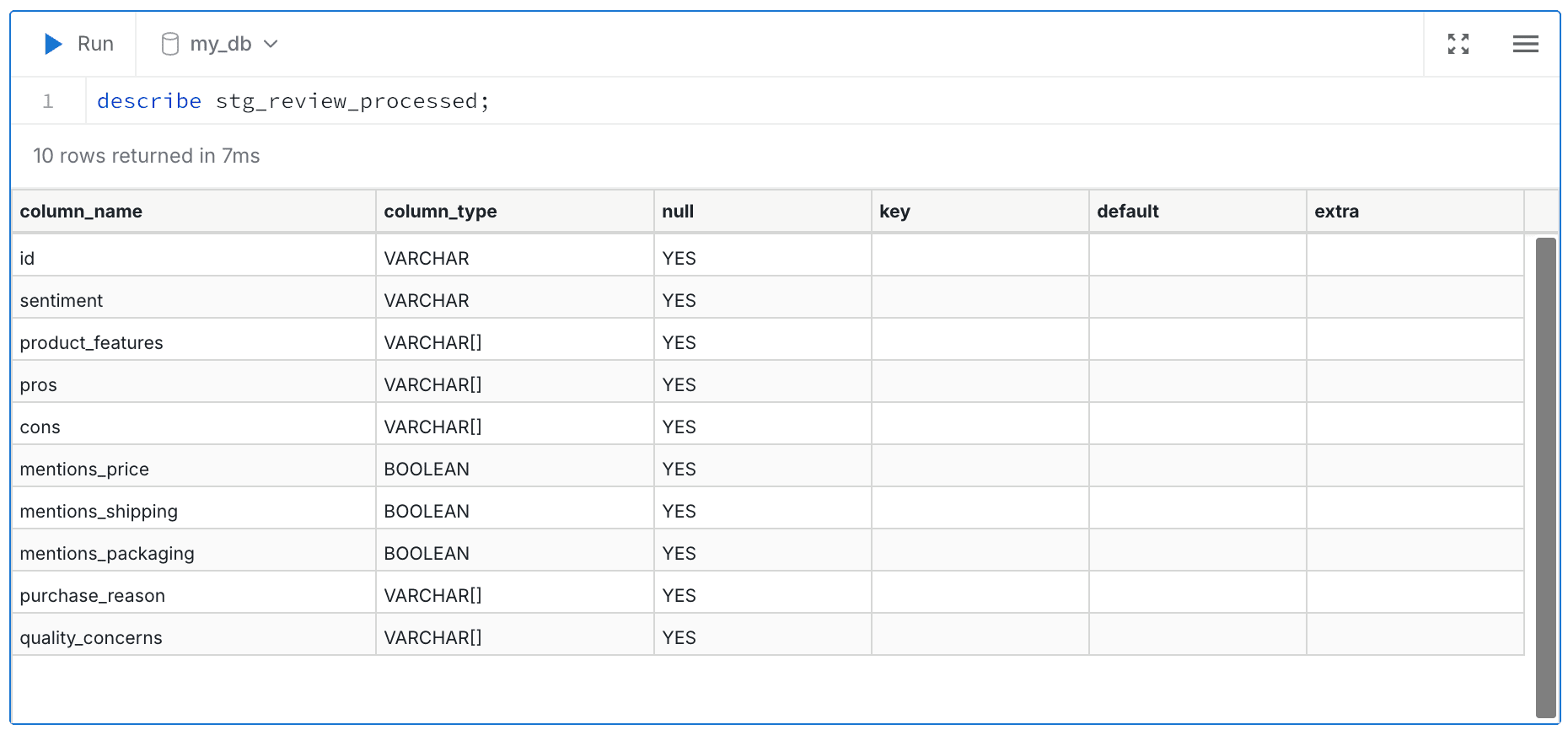
struct_descrはこのままモデルに渡されますので、実際の運用でやる場合はprompt_textと合わせて何度か試行錯誤が必要そうです。このブログで使用しているprompt_textとstruct_descrはMotherDuckのブログに記載されているものとほぼ同じになっています。今回、ブログを書くにあたって読みやすくするために日本語に書き直しています。
stg_review_unnested_attributes
配列から欲しいテキストを抜き出しています。
{{ config(materialized="view") }}
select
id,
sentiment,
replace(unnest(product_features), '"','') as product_features,
replace(unnest(pros), '"','') as pros,
replace(unnest(cons), '"','') as cons,
replace(unnest(purchase_reason), '"','') as purchase_reason,
replace(unnest(quality_concerns), '"','') as quality_concerns
from {{ ref("stg_review_processed") }}
簡単な集計ですが、各センチメント(positive, neutral, negative)で件数を数えてみました。
- 価格について言及している
- 配送について言及している
- 梱包について言及している
{{ config(materialized="view") }}
select
sentiment,
count(*) as count,
sum(case when mentions_price = true then 1 else 0 end) as price_count,
sum(case when mentions_shipping = true then 1 else 0 end) as shipping_count,
sum(case when mentions_packaging = true then 1 else 0 end) as packaging_count
from {{ ref("stg_review_processed") }}
group by
sentiment
その他
レビューで言及されている購入理由と品質課題、製品のよいところ、悪いところをテキストで抽出しています。抽出したテキストの一覧はQuickSightのワードクラウドで出したらおもしろそうです。
purchase_reasons
{{ config(materialized="view") }}
select
purchase_reason as feedback
from {{ ref('stg_review_unnested_attributes') }} as attr
where length(attr.purchase_reason) > 0
quality_concerns
{{ config(materialized="view") }}
select
sentiment,
quality_concerns as feedback
from {{ ref('stg_review_unnested_attributes') }} as attr
where length(attr.quality_concerns) > 0
customer_feedbacks
{{ config(materialized="view") }}
select
sentiment,
pros as feedback
from {{ ref('stg_review_unnested_attributes') }} as attr
where attr.sentiment like 'positive' and length(attr.pros) > 0
union
select
sentiment,
cons as feedback
from {{ ref('stg_review_unnested_attributes') }} as attr
where attr.sentiment like 'negative' and length(attr.cons) > 0
実行結果
❯ dbt run
05:37:00 Running with dbt=1.9.3
05:37:00 Registered adapter: duckdb=1.9.2
05:37:01 Found 7 models, 1 source, 426 macros
05:37:01
05:37:01 Concurrency: 4 threads (target='dev')
05:37:01
05:37:38 1 of 7 START sql view model main.raw_reviews_text_ja ........................... [RUN]
05:37:41 1 of 7 OK created sql view model main.raw_reviews_text_ja ...................... [OK in 2.98s]
05:37:41 2 of 7 START sql table model main.stg_review_processed ......................... [RUN]
05:37:54 2 of 7 OK created sql table model main.stg_review_processed .................... [OK in 13.56s]
05:37:54 3 of 7 START sql view model main.review_summary ................................ [RUN]
05:37:54 4 of 7 START sql view model main.stg_review_unnested_attributes ................ [RUN]
05:37:57 3 of 7 OK created sql view model main.review_summary ........................... [OK in 3.20s]
05:37:57 4 of 7 OK created sql view model main.stg_review_unnested_attributes ........... [OK in 3.20s]
05:37:57 5 of 7 START sql view model main.customer_feedbacks ............................ [RUN]
05:37:57 6 of 7 START sql view model main.purchase_reasons .............................. [RUN]
05:37:57 7 of 7 START sql view model main.quality_concerns .............................. [RUN]
05:38:01 5 of 7 OK created sql view model main.customer_feedbacks ....................... [OK in 3.19s]
05:38:01 6 of 7 OK created sql view model main.purchase_reasons ......................... [OK in 3.19s]
05:38:01 7 of 7 OK created sql view model main.quality_concerns ......................... [OK in 3.60s]
05:38:01
05:38:01 Finished running 1 table model, 6 view models in 0 hours 1 minutes and 0.41 seconds (60.41s).
05:38:01
05:38:01 Completed successfully
05:38:01
05:38:01 Done. PASS=7 WARN=0 ERROR=0 SKIP=0 TOTAL=7
今回は100件の商品レビューをLLMに投げていますが、LLMを使っているモデル自体は14秒程度で終わっています。全体でも1分くらいでしたので、個人的にはサクサク動いているのではないかと感じました。
MotherDuck上で結果を見てみます。
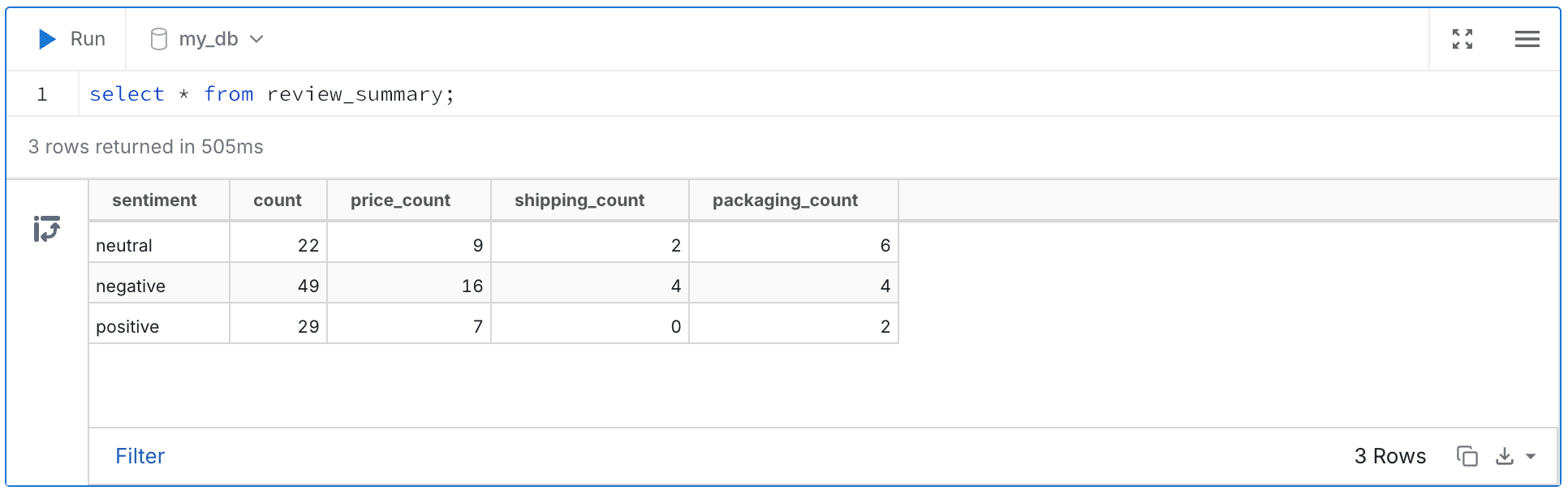
サマリ
ネガティブ、ニュートラルなレビューの場合、配送や梱包についての言及が増えているようです。
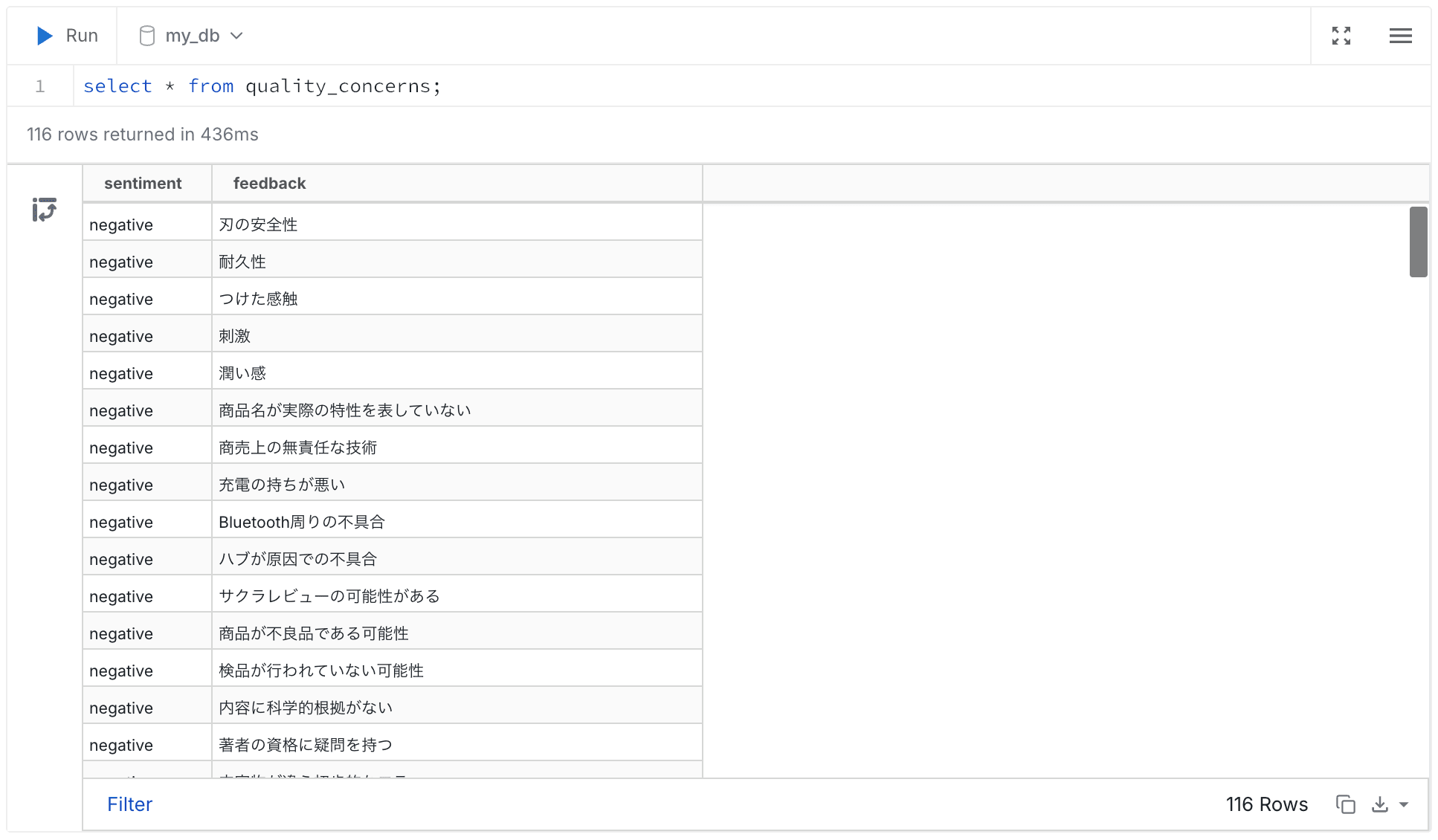
品質課題
今回はいろいろな商品のレビューが混ざってしまっていますが、商品ごと、カテゴリごとに分けると課題が見えてきそうです。
購入理由
こちらも品質課題と同様、色々な商品が混ざっているのでわかりにくいですが、商品ごとにまとめると自社製品がお客様に売れている理由が見えてきそうです。
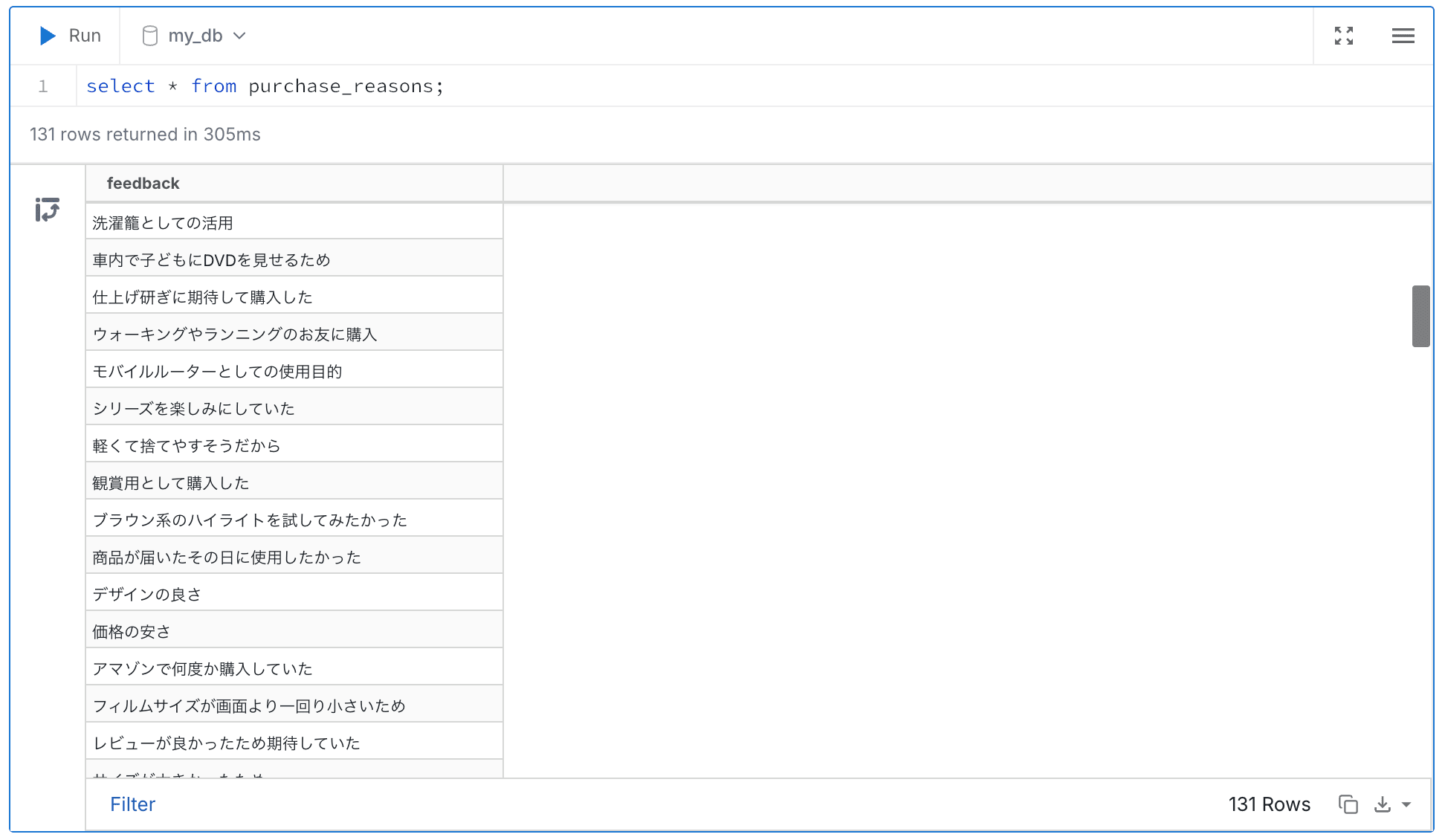
フィードバック
最後に製品のpros/consのテキストです。
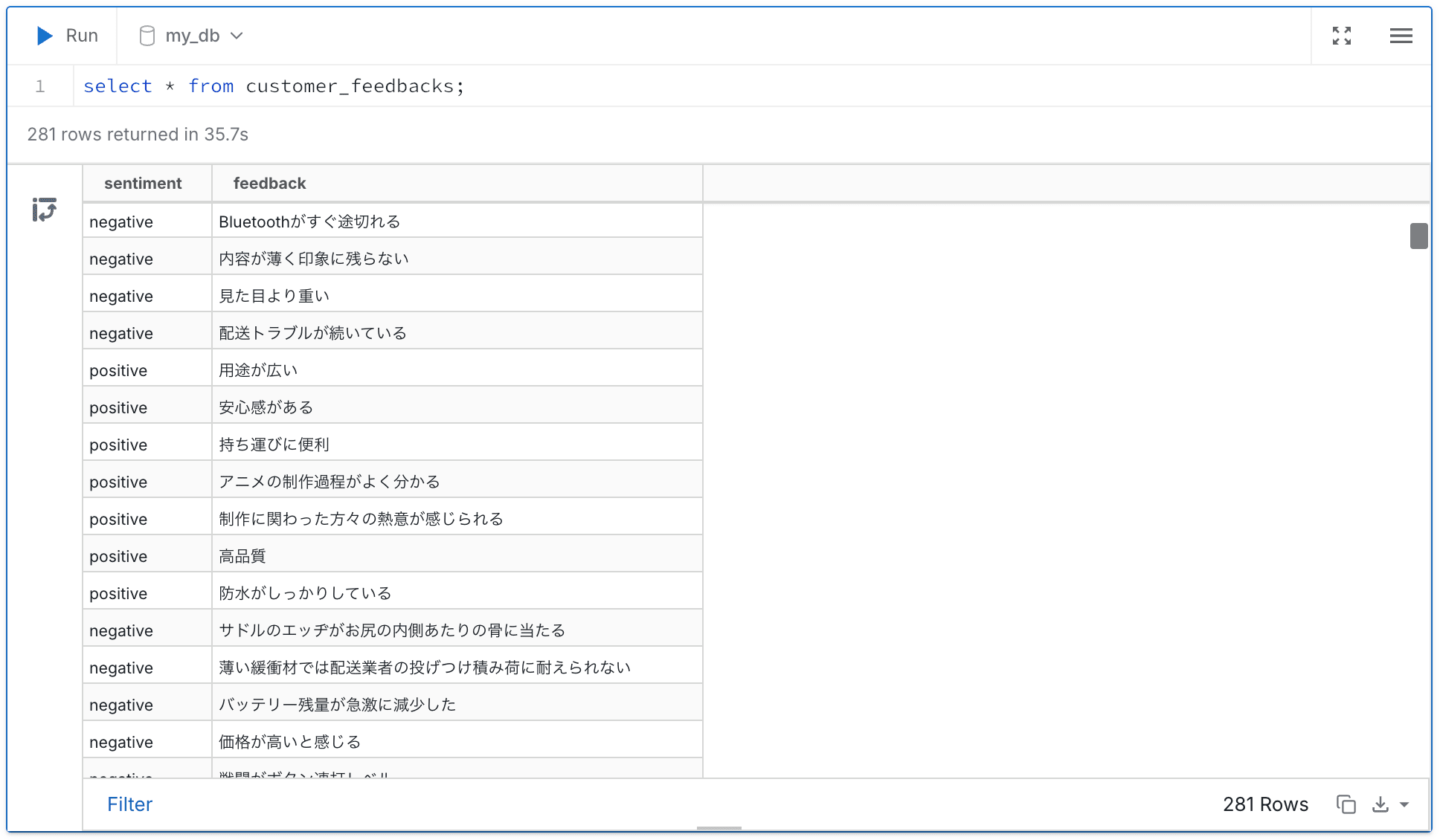
おわりに
以上、簡単な例ですがMotherDuckのLLM機能を使って商品レビューのテキストデータから情報を抜き出してみました。今回はMotherDuckのprompt関数を使用しましたが、他のDWH製品であってもレスポンス形式を指定できる関数があれば似たようなことができるのではないかと思います。
眠っているテキストデータがあれば掘り起こしてみてください。
参考リンク









