
PyIcebergを使ってLambdaからS3 TablesのIcebergテーブルに書き込んでみる
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部の笠原です。
LambdaからS3 TablesのIcebergテーブルにデータを追加したい場合、例えばAthenaのクエリをLambdaから実行したり、Data Firehoseの配信ストリームにLambdaからデータを投入して追加したり、いくつか方法が考えられます。
今回は、AthenaやData Firehoseを使わず、もちろんSparkも使わずに、PyIcebergを使ってLambdaからS3 TablesのIcebergテーブルにデータを書き込んでみたいと思います。
こちらのAWSブログにPyIcebergで接続する方法がまとめられていますので、とても参考になりました。
概要
PyIcebergでカタログを読み込む際に、AWSが用意している「AWS Glue Iceberg REST endpoint」を用います。
https://glue.<AWS_REGION>.amazonaws.com/iceberg
これにより、Apache Iceberg REST仕様に準拠したApache Icebergテーブルに対してアクセスできるため、これを使ってS3 TablesのIcebergテーブルにアクセスします。
S3 Tables
今回は、東京リージョンでテーブルバケットを作成します。
「AWS 分析サービスとの統合」を有効化していない場合は、マネジメントコンソールから「統合を有効にする」をクリックして有効化しておきましょう。
テーブルバケットはマネジメントコンソール上で作っても構いませんが、今回はAWS CLIで作成します。
aws s3tables create-table-bucket \
--name pyiceberg-sample-bucket
namespaceとtableも作成しておきます。
## namespace作成
## namespace名は 'main' としています。
aws s3tables create-namespace \
--table-bucket-arn "arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/pyiceberg-sample-bucket" \
--name main
## テーブル作成
## テーブル名は 'temperature_humidity_histories' としています。
aws s3tables create-table \
--table-bucket-arn "arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/pyiceberg-sample-bucket" \
--namespace main \
--name temperature_humidity_histories \
--format 'ICEBERG' \
--metadata '{"iceberg":{"schema":{"fields":[{"name":"sensor_id","type":"int","required":true},{"name":"created_at","type":"timestamp"},{"name":"temperature","type":"double"},{"name":"humidity","type":"double"}]}}}'
IAMロール
Lambda関数にアタッチするロールのポリシーは、 AWSLambdaBasicExecutionRole に加えて、以下のポリシーを設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"glue:GetCatalog",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetTable",
"glue:GetTables",
"glue:CreateTable",
"glue:UpdateTable"
],
"Resource": [
"arn:aws:glue:ap-northeast-1:<AWS_ACCOUNT_ID>:catalog",
"arn:aws:glue:ap-northeast-1:<AWS_ACCOUNT_ID>:catalog/s3tablescatalog",
"arn:aws:glue:ap-northeast-1:<AWS_ACCOUNT_ID>:catalog/s3tablescatalog/pyiceberg-sample-bucket",
"arn:aws:glue:ap-northeast-1:<AWS_ACCOUNT_ID>:database/s3tablescatalog/pyiceberg-sample-bucket/main",
"arn:aws:glue:ap-northeast-1:<AWS_ACCOUNT_ID>:table/s3tablescatalog/pyiceberg-sample-bucket/main/*"
],
"Effect": "Allow"
},
{
"Action": "lakeformation:GetDataAccess",
"Resource": "*",
"Effect": "Allow"
}
]
}
Lake Formation
上記のIAMロールのS3Tablesへのアクセス権限を付与します。
## データベースへの権限付与
## AWS_PRINCIPAL_ARN は、Lambda関数にアタッチするIAMロールのARN
aws lakeformation grant-permissions \
--catalog-id "${AWS_ACCOUNT_ID}" \
--principal "{\"DataLakePrincipalIdentifier\": \"${AWS_PRINCIPAL_ARN}\"}" \
--resource "{\"Database\": {\"CatalogId\": \"${AWS_ACCOUNT_ID}:s3tablescatalog/${TABLE_BUCKET_NAME}\", \"Name\": \"main\" }}" \
--permissions "ALL"
## テーブルへの権限付与
aws lakeformation grant-permissions \
--catalog-id "${AWS_ACCOUNT_ID}" \
--principal "{\"DataLakePrincipalIdentifier\": \"${AWS_PRINCIPAL_ARN}\"}" \
--resource "{\"Table\": {\"CatalogId\": \"${AWS_ACCOUNT_ID}:s3tablescatalog/${TABLE_BUCKET_NAME}\", \"DatabaseName\": \"main\", \"TableWildcard\": {} }}" \
--permissions "ALL"
権限設定すると、以下のようにLake FormationのData Permissionsの一覧に追加されます。
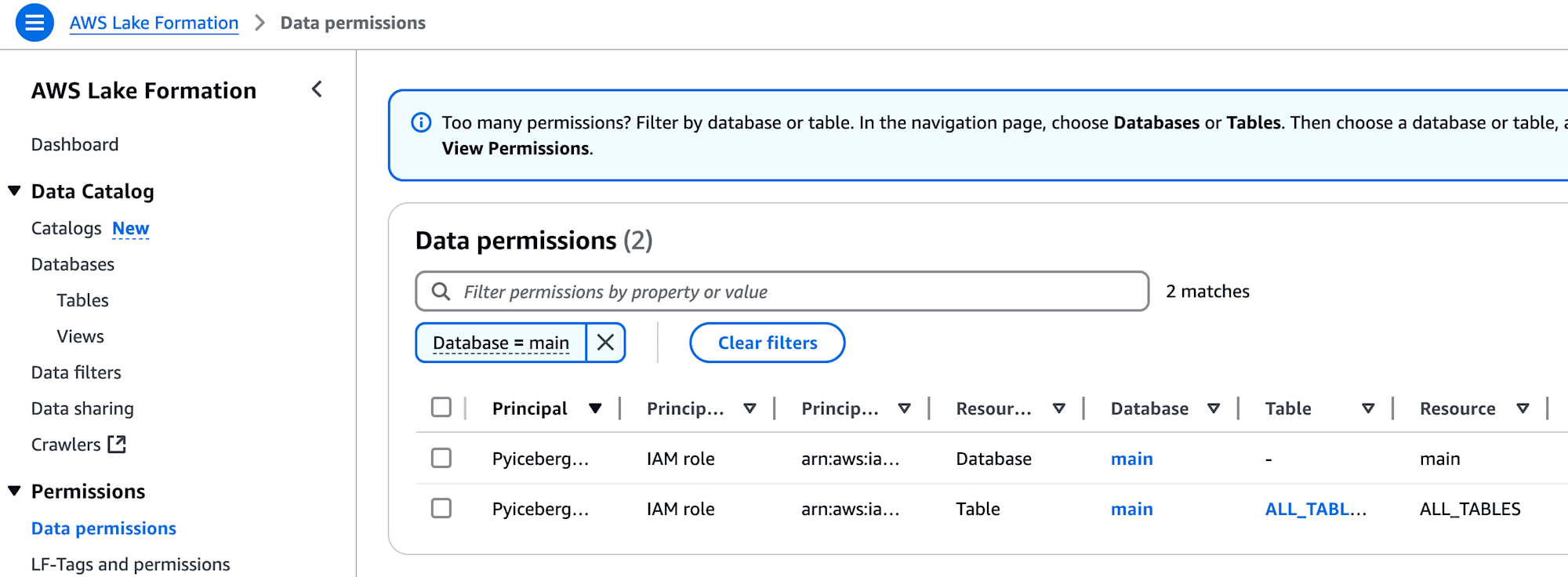
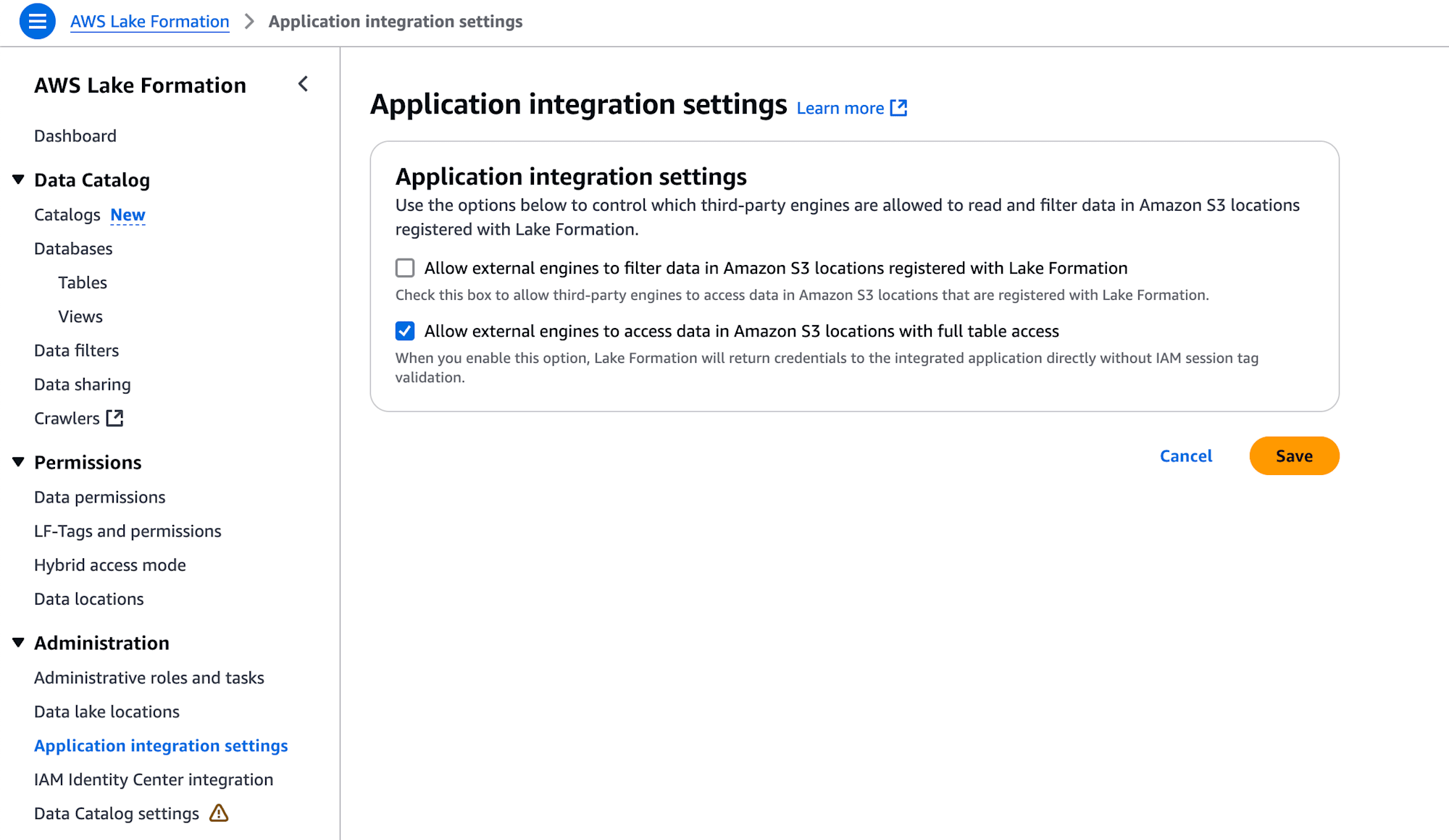
また、「Application integration settings」の「Allow external engines to access data in Amazon S3 Locations with full table access」にチェックを入れておきます。
チェックを入れないと、PyIcebergの load_table() 実行時に 403 AccessDenied でアクセス拒否されるので、忘れずにチェックを入れましょう。
Lambda関数
pyicebergは、ソースと一緒にzipで固めても良いですし、lambda layer使っても構いません。
pip install --only-binary=:all: --platform manylinux2014_x86_64 "pyiceberg[glue,pyarrow]"
なお、pyicebergのオプションの依存関係をたくさん導入すると、Lambdaの展開時容量250MBのクォータに引っかかる場合があります。例えば、以下のようにpandasも導入すると、展開時容量オーバーとなりエラーとなりました。このような場合は、Lambdaコンテナを導入する等で対策してください。
pip install --only-binary=:all: --platform manylinux2014_x86_64 "pyiceberg[glue,pandas,pyarrow]"
ソースはこんな感じです。
import os
import random
import datetime
import pyarrow as pa
from pyiceberg.catalog import load_catalog
def init_rest_catalog(s3table_bucket_name: str, account_id: str, region: str, catalog_name: str = "S3TablesCatalog"):
return load_catalog(
catalog_name,
**{
"type": "rest",
"warehouse": f"{account_id}:s3tablescatalog/{s3table_bucket_name}",
"uri": f"https://glue.{region}.amazonaws.com/iceberg",
"rest.sigv4-enabled": "true",
"rest.signing-name": "glue",
"rest.signing-region": region,
},
)
def handler(event, context):
s3table_bucket_name = os.environ.get("S3TABLE_BUCKET_NAME")
account_id = os.environ.get("ACCOUNT_ID")
region = os.environ.get("REGION")
database_name = os.environ.get("DATABASE_NAME")
table_name = os.environ.get("TABLE_NAME")
JST = datetime.timezone(datetime.timedelta(hours=+9), 'JST')
## REST Catalog
rest_catalog = init_rest_catalog(s3table_bucket_name=s3table_bucket_name, account_id=account_id, region=region)
## Load Table
table = rest_catalog.load_table(f"{database_name}.{table_name}")
## Insert Data
schema = pa.schema([
pa.field('sensor_id', pa.int32(), nullable=False),
pa.field('created_at', pa.timestamp('us')),
pa.field('temperature', pa.float64()),
pa.field('humidity', pa.float64()),
])
sample_data = {
"sensor_id": random.choice(range(1, 11)),
"created_at": datetime.datetime.now(JST),
"temperature": random.normalvariate(20.0, 2),
"humidity": random.normalvariate(40.0, 10),
}
df = pa.Table.from_pylist([sample_data], schema=schema)
table.append(df)
return {
"status_code": 200,
}
「Glue Iceberg REST Endpoint」を使ったカタログの読み込みを以下で行っています。
def init_rest_catalog(s3table_bucket_name: str, account_id: str, region: str, catalog_name: str = "S3TablesCatalog"):
return load_catalog(
catalog_name,
**{
"type": "rest",
"warehouse": f"{account_id}:s3tablescatalog/{s3table_bucket_name}",
"uri": f"https://glue.{region}.amazonaws.com/iceberg",
"rest.sigv4-enabled": "true",
"rest.signing-name": "glue",
"rest.signing-region": region,
},
)
warehouse には、カタログIDを指定します。Glueのデフォルトカタログ {account_id} (数字12桁のAWSアカウントID) ではなく、S3 Tablesのカタログ {account_id}:s3tablescatalog/{s3table_bucket_name} で指定します。
uri は、Glue Iceberg REST Endpointを指定します。
認証情報はIAMロールからの一時認証情報を自動的に利用してアクセスしてくれます。
確認
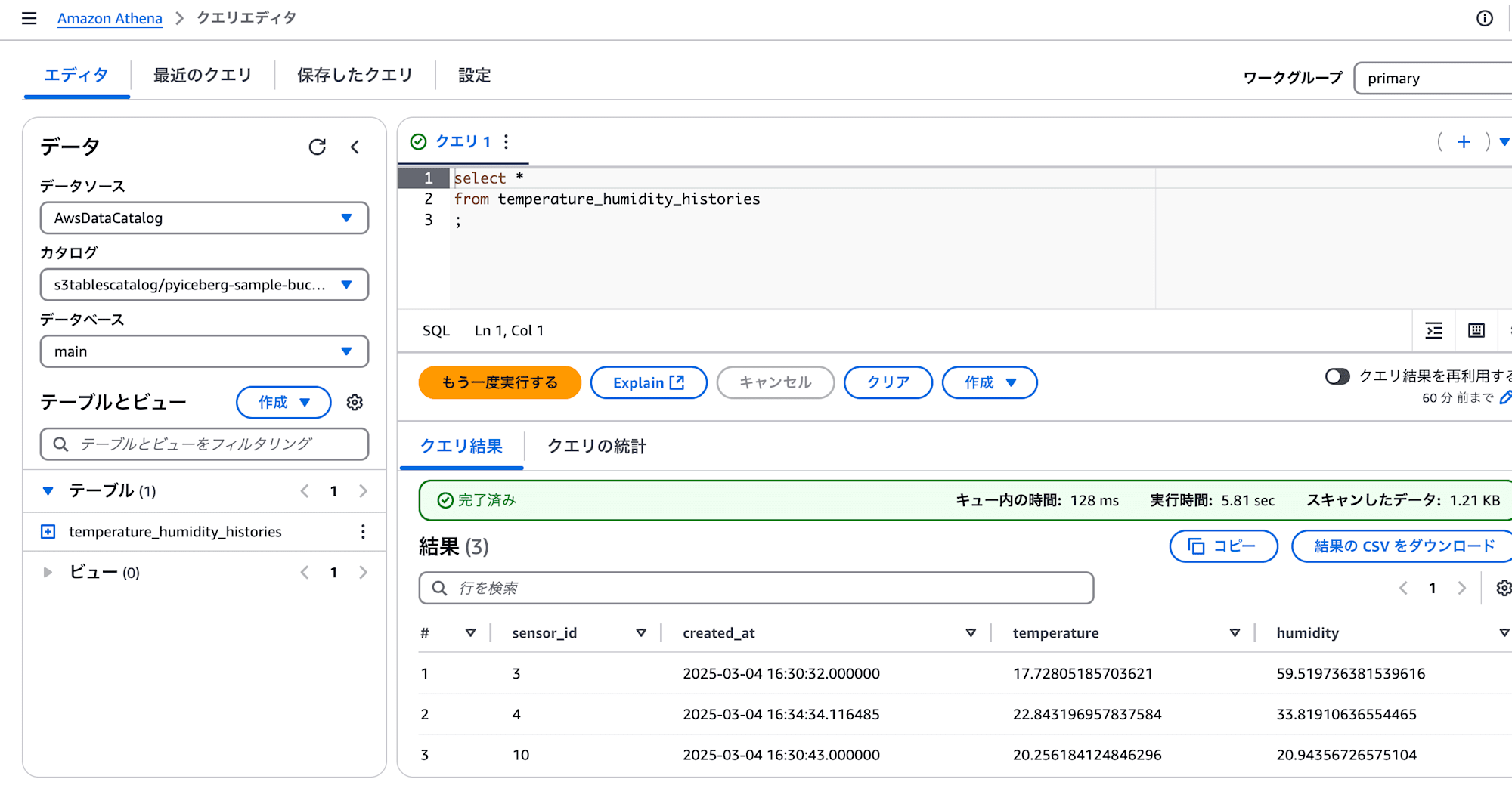
データが格納されたかどうかは、Athenaで確認してみます。
Lambda関数を実行した回数分、データが登録されていることが確認できました。
補足: S3TablesCatalogクラス
PyIcebergのgithubのissueやpull requestには、S3TablesCatalogクラスの実装が確認できます。
導入されれば、よりシンプルにS3 Tablesにアクセスできるようになることが期待されます。
まとめ
いかがでしたでしょうか。
PyIcebergを利用してAWS Glue Iceberg REST endpointにアクセスすることで、LambdaからS3 TablesのIcebergテーブルへデータが追加できました。
PyIcebergを使えば、SQLではないですが、UpdateやDeleteもできるようになっています。データの読み込みは table.scan() あたりを使って取得することもできます。ちょっとしたデータ加工を行う際の選択肢の1つとして検討してみてはいかがでしょうか。











