
Informatica CLAIRE GPTを試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
データ事業本部ビッグデータチームのyosh-kです。
今回はInformatica CLAIRE GPTについてどのようなことができるか試してみたいと思います。
CLAIRE GPTとは
CLAIRE GPTについては、以下の記事で説明されていたので、その内容を一部抜粋します。
CLAIRE GPT は、Informatica Intelligent Data Management Cloud (IDMC)に自然言語 (NL) インターフェイスを提供し、ユーザーが簡単な会話型のやり取りを通じてデータを検出、設計、管理、使用できるようにします。GenAI を搭載したデータ管理アシスタントです。大規模言語モデル (LLM) を活用して IDMC を強化し、自然言語ベースのチャット インターフェイスを提供します。これにより、複雑なデータ管理ワークフローが自動化され、ビジネスのデータ アクセスが民主化され、データ チームの生産性が向上します。
2024年7月時点でのCLAIRE GPTの機能は以下になります。
- Data discovery:
- 簡単な英語promptを利用して、Cloud Data Governanceおよびカタログで利用可能なデータ資産を検索および発見します。
- Intelligent prompt completion:
- データ セットに関連するプロンプトをいくつか送信し、プロンプト テキスト ボックスに @ と入力すると、会話履歴と、以前のプロンプトに対するCLAIRE GPTの応答に基づいた提案が表示されます。
- Metadata exploration:
- メタデータ調査を使用して、資産の概要、利害関係者、データ プロファイル、データ品質スコア、評価、系統、システム属性などの資産のメタデータを調査、表示、および理解します。データ品質スコアも確認できます。
- Data exploration:
- ソース データを調べ、データ セットのサンプルをプレビューし、データを取得するために使用された SQL コードを確認してから、将来の参照用にデータを CSV ファイルに保存します。プライバシー ガイドラインにより、CLAIRE GPT はサンプル データを保存しません。ブラウザを更新するか、 CLAIRE GPTからログアウトすると、サンプル データは会話に表示されなくなり、ダウンロードできなくなります。
2024 年 4 月のリリースでは、次のソース システムからのサンプル データのみをプレビューできます。 - Amazon Redshift
- Databricks
- Google BigQuery
- Microsoft Azure Synapse
- Snowflake
- ソース データを調べ、データ セットのサンプルをプレビューし、データを取得するために使用された SQL コードを確認してから、将来の参照用にデータを CSV ファイルに保存します。プライバシー ガイドラインにより、CLAIRE GPT はサンプル データを保存しません。ブラウザを更新するか、 CLAIRE GPTからログアウトすると、サンプル データは会話に表示されなくなり、ダウンロードできなくなります。
- Data transformation:
- データを変換して操作を実行することができます。たとえば、データを集約したりフィルタリングしたり、複数のデータセットを結合したりできます。変換されたテーブルを生成するために使用された SQL コードも確認できます。
ソースからデータを読み取り、ターゲットに書き込む ELT パイプラインを作成することで、出力をターゲット テーブルに保存できます。パイプラインを編集、保存、および実行するには、Data Integration でパイプラインをマッピングとして開きます。マッピングは、パイプラインのデータ フロー ロジックを一連の変換として表します。
将来の参照用に、サンプル データを CSV ファイルに保存できます。プライバシーガイドラインにより、CLAIRE GPT はサンプルデータを保存しません。ブラウザを更新するかCLAIRE GPTからログアウトすると、サンプルデータは会話に表示されなくなり、ダウンロードできなくなります。
- データを変換して操作を実行することができます。たとえば、データを集約したりフィルタリングしたり、複数のデータセットを結合したりできます。変換されたテーブルを生成するために使用された SQL コードも確認できます。
CLAIRE GPTシステムの仕組み
詳細なCLAIRE GPTシステムの仕組みについても記事の中で紹介がありました。
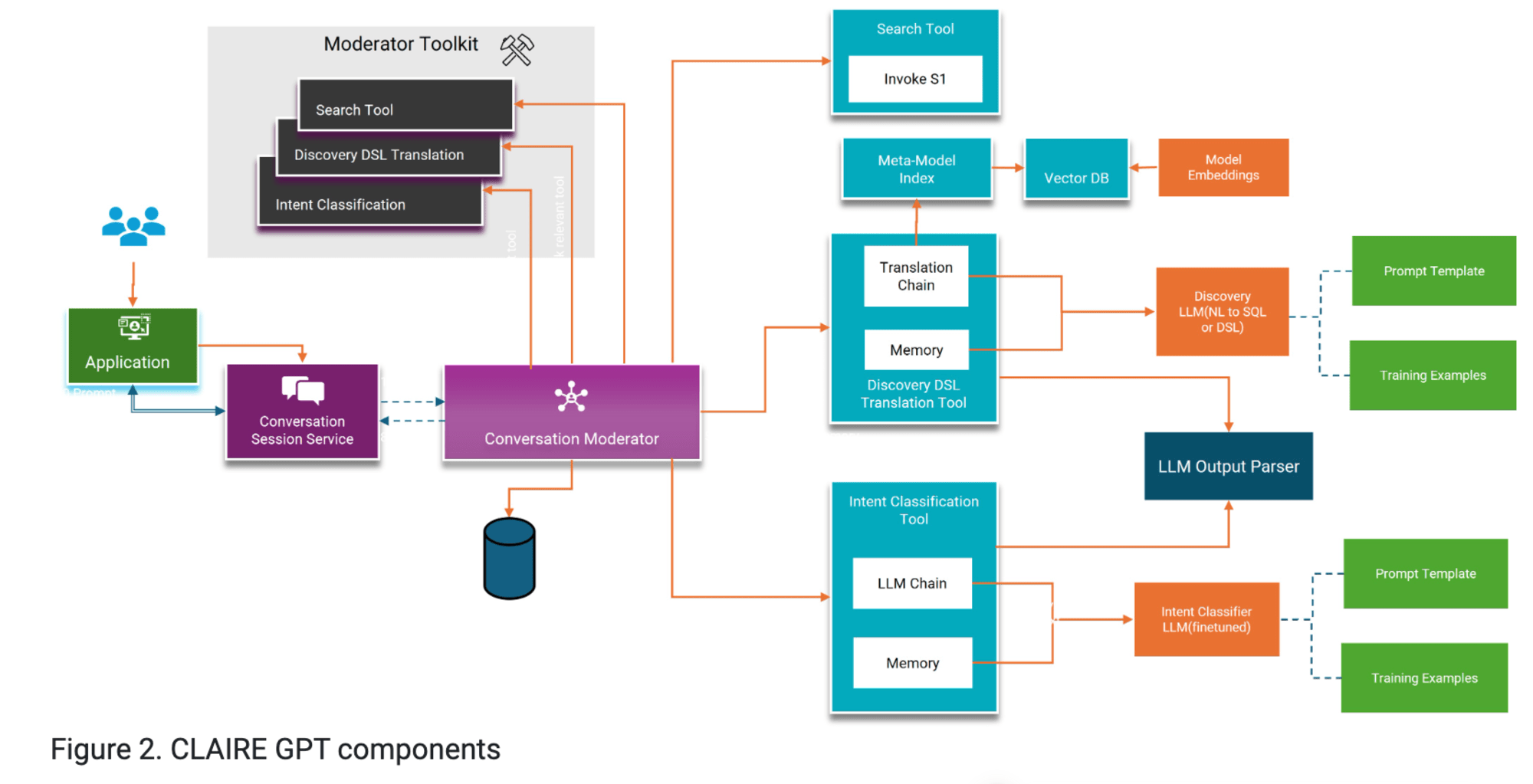
- Intent classification tool: ユーザーのクエリを分析し、重要な用語や意図を抽出します。
- Metadata knowledge graph: 組織のデータ資産に関するメタデータを含み、Informatica CDGCサービスと同じものを使用します。
- Use-case-specific LLMs : 抽出された意図に基づいて、適切な特化型LLMにクエリを送信します。例えば、データ検出クエリは Discovery LLM に送られます。
- Summarizer: 知識グラフからの結果を集約し、ユーザーに読みやすい自然言語の回答を生成します。
このシステムは、ユーザーの自然言語クエリを理解し、関連するデータ資産を見つけ、適切な回答を生成するために設計されています。
CLAIRE GPTの典型的なワークフロー:
- ユーザーがアプリケーションを通じて自然言語クエリを入力します。
- 会話セッションサービスがクエリを受け取り、会話モデレーターに転送します。
- 会話モデレーターは意図分類ツールを使用してクエリの意図を分析します。
- 意図に基づいて、適切なLLM(例:Discovery LLMやIntent Classifier LLM)が選択されます。
- 選択されたLLMがクエリを処理し、必要に応じてDiscovery DSL変換ツールや検索ツールが使用されます。
- LLM出力パーサーが結果を解析し、構造化されたデータに変換します。
- 会話モデレーターが結果を集約し、自然言語の回答を生成します。
- 生成された回答がアプリケーションを通じてユーザーに表示されます。
このシステムにより、CLAIRE GPTは複雑なデータ関連のクエリに対して、正確で関連性の高い回答を提供することができます。また、Informaticaの既存のCloud Data Governance and Catalog(CDGC)サービスと連携することで、組織のデータアセットに関する豊富な知識を活用することができます。
CLAIREの未来
現状は、上記で示した機能ですが、将来的には、以下の機能を予定していると記事に記載があります。
- 自己統合:新たに取り込んだデータを、データ統合プロセスへ自動的に統合します。数百万もの既存のマッピングとユーザー操作から学習して、データを特定し、類似データを処理する統合パターンを見つけ、データを自動的に変換して移動します。
- 開発支援:開発プロセスの際に、例えば下記のような次にとるべき最善策をユーザーに提案し
ます。
• 変換の自動完了
• テンプレートの提案
• 機密データのマスキングタイプの提案
• クレンジングと標準化のためのデータ品質の提案
• パフォーマンスの自動最適化 - 自動マッピング:社内全体を通じてマスターデータエンティティを検出してマスターデータモデルへ自動的にマッピングし、必要な変換と品質ルールを適用します。
- 自己修復:メモリ不足や処理能力不足など、外部システムの問題を効果的に修復します。例えば、処理能力を追加(クラウドバースティング)して、データ量の急増に対応できます。
- 自己調整:履歴情報、現在のデータ量、使用可能なシステムリソースに基づいてスケジュールやコンピューティングリソースを予測および調整し、パフォーマンス基準を満たします。
- 自己保護:機密データを自動的に検出し、保護されている領域から出る前にマスキングを行います。
ポイント
私が気になるCLAIRE GPTのポイントは以下になります。
- 現状はpromptは英語で行う。日本語不可。
- 顧客データは学習されない。ただし、組織固有のトレーニングでは、ユーザーの明示的な許可がある場合に限り、IDMCに保存された顧客データが使用される可能性があります。これは各組織専用のモデルに対してのみ適用され、他の組織や一般的なモデルには影響しません。
- データ検索するには、Metadata Command Centerでカスタム カタログ ソースを作成する必要があります。
- Informatica CLAIRE AI は、OpenAI を使用していない。データ管理に特化した INFA LLM を使用しています。独自の LM は、責任ある AI を厳重に保護するオープンソース言語モデルに基づいています。
事前準備
CLAIRE GPTを利用するには、様々な初期条件をクリアする必要があります。詳細は以下のリンクをご確認ください。
また、CLAIRE GPTのデータカタログ検索機能には、事前にデータカタログを生成する必要があるなどの条件もありますので、機能ごとの前提条件は以下のリンクをご確認ください。
試してみた
Data discovery
まずはデータカタログを検索してみます。
事前にRedshiftカタログを作成したので、そちらを検索してみます。
Find catalog sources type of Redshift
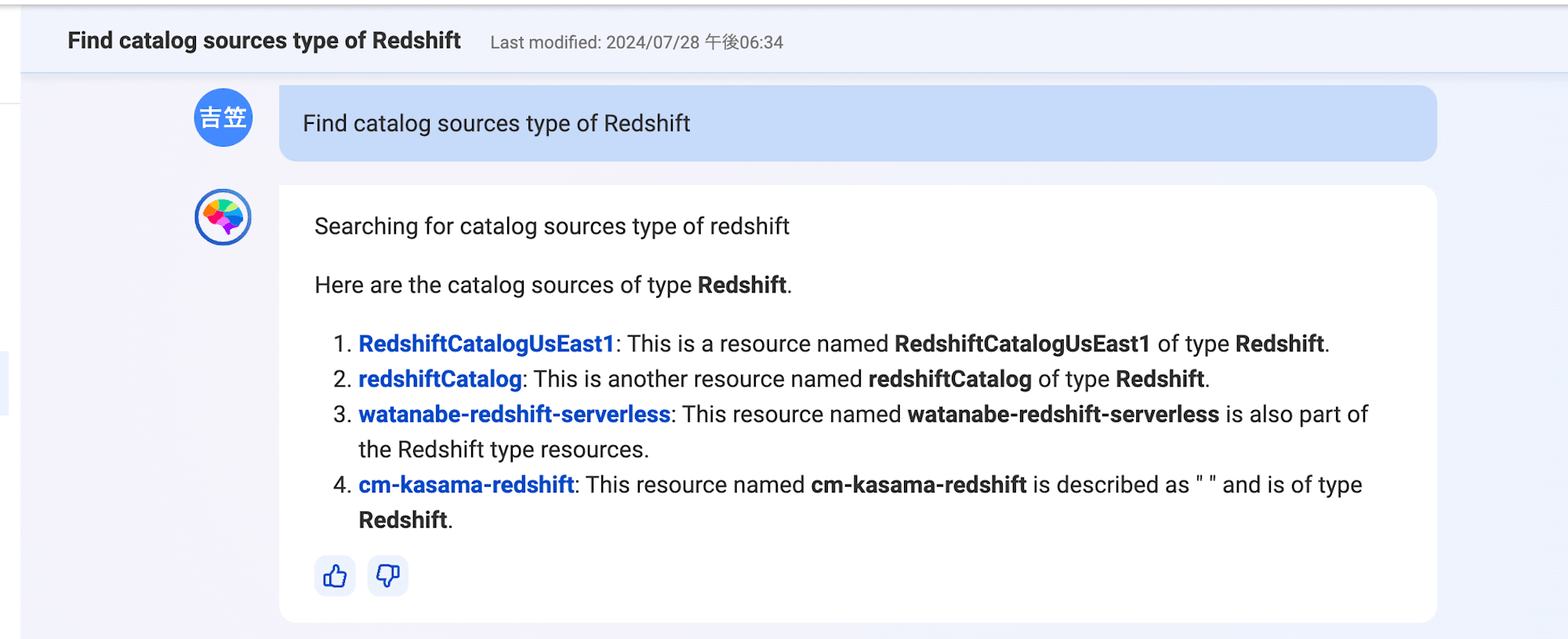
Source typeがRedshiftのデータカタログ一覧が出ましたね。4番目が私が作成したものになります。次に私が作成したRedshift tableの一覧をみてみましょう。自身の名前は@でメンションしました。
show me redshift tables created by 吉貴 笠間
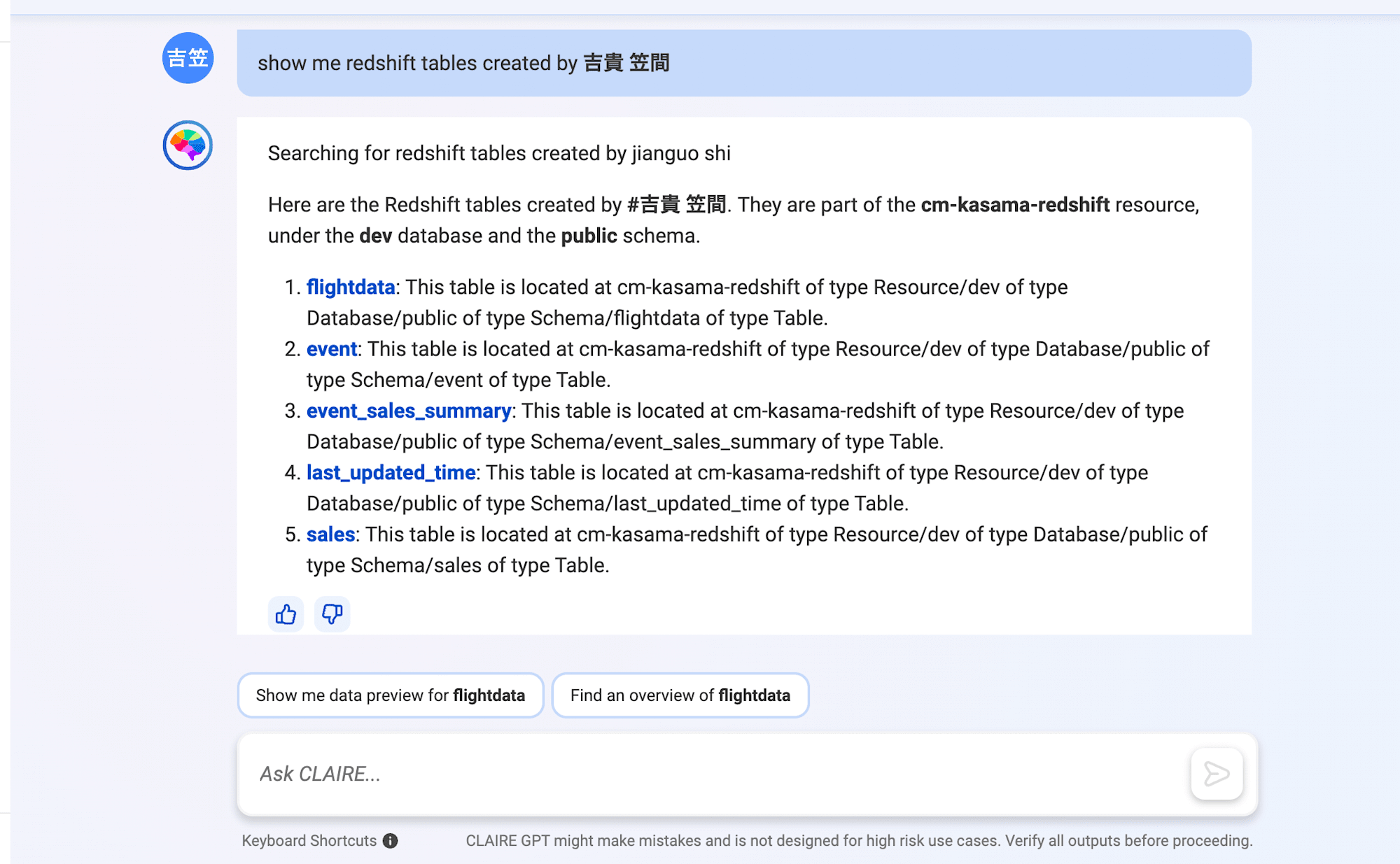
Redshift内のテーブル一覧と概要が表示されました。
Intelligent prompt completion
CLAIRE GPTでは、ボックスに@と入力すると、会話履歴と、以前のプロンプトに対するの応答に基づいた提案が表示されます。ここでは先ほどの会話履歴からRedshift table群が表示されていることがわかります。tableの概要も問題なく表示できました。
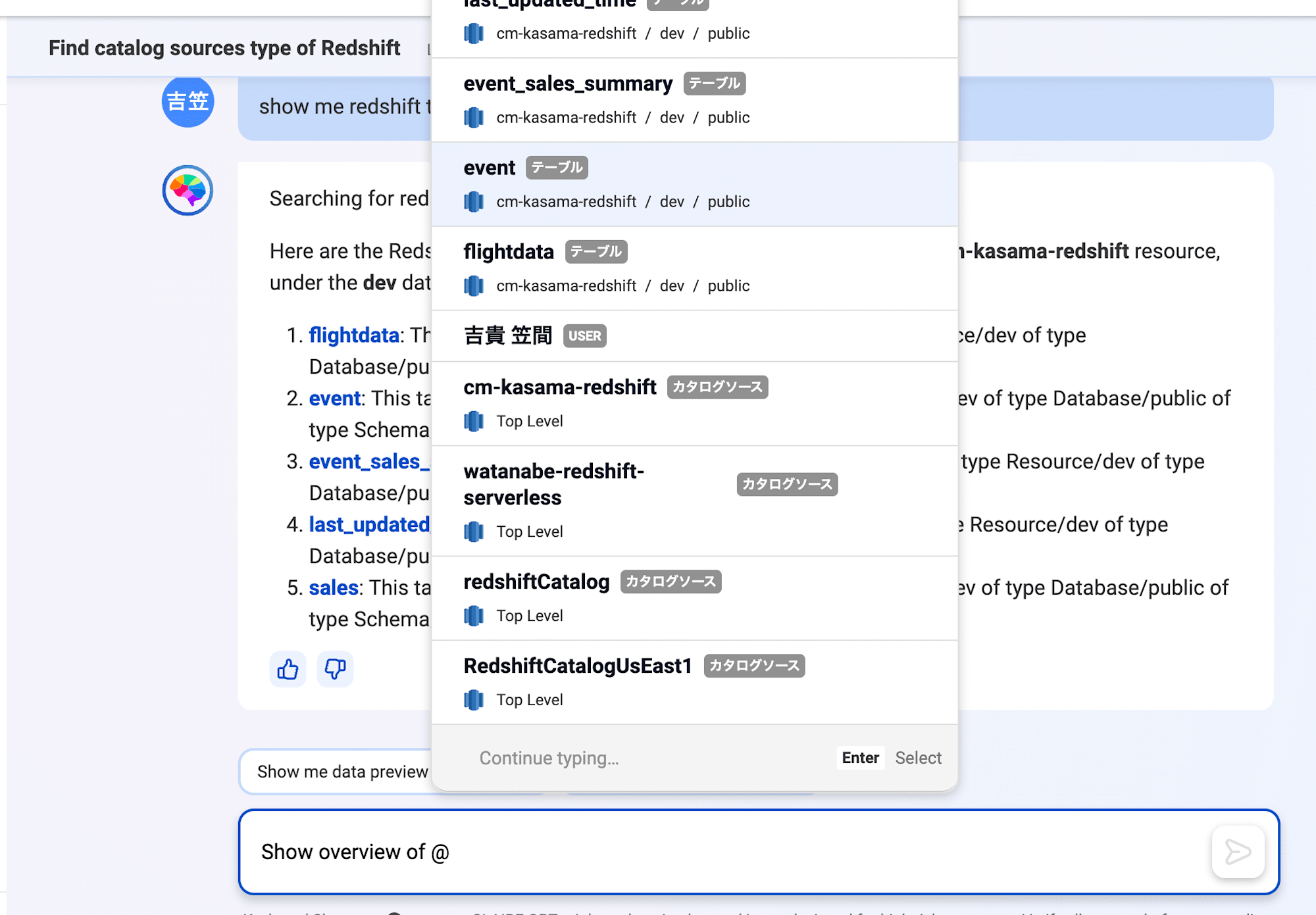
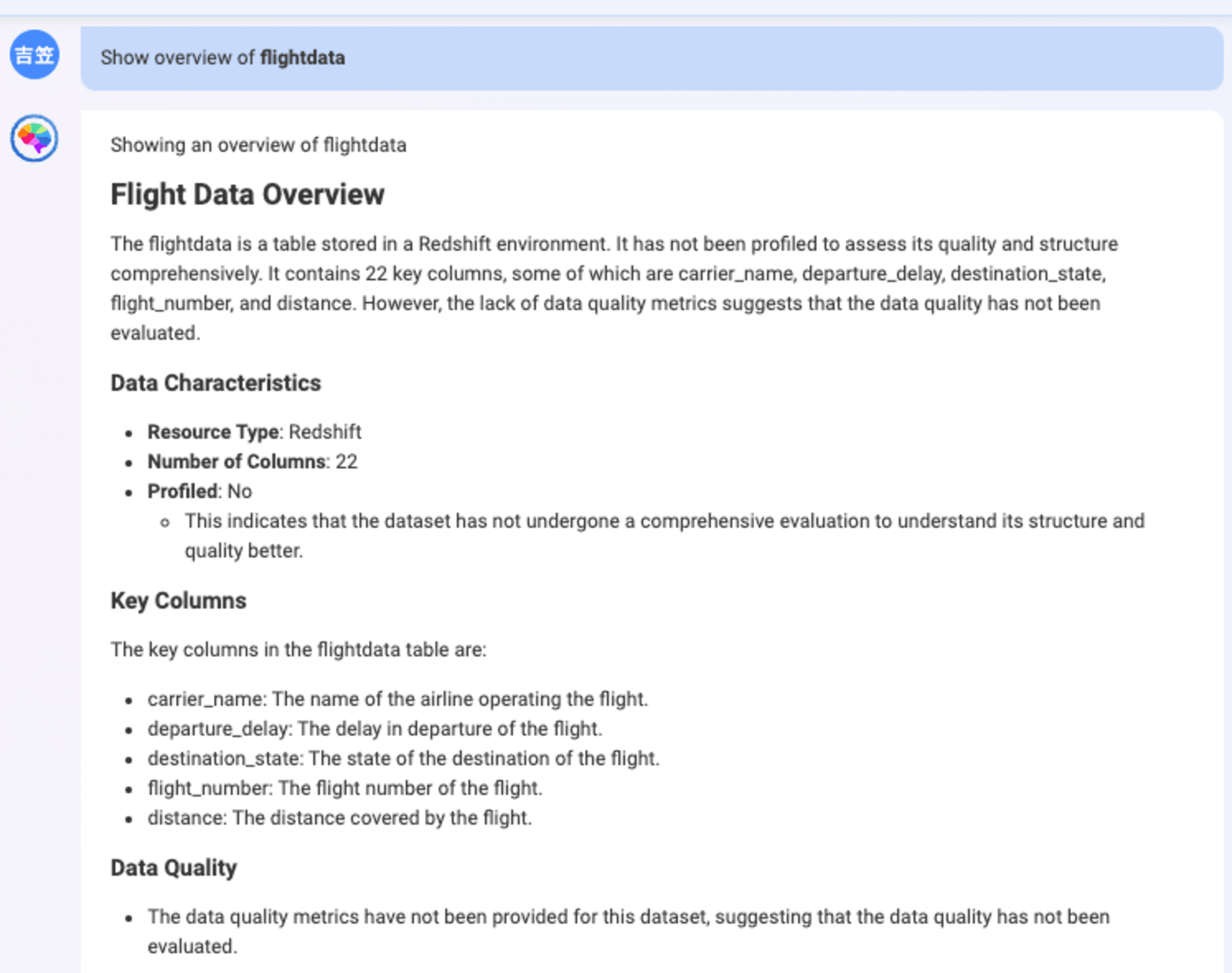
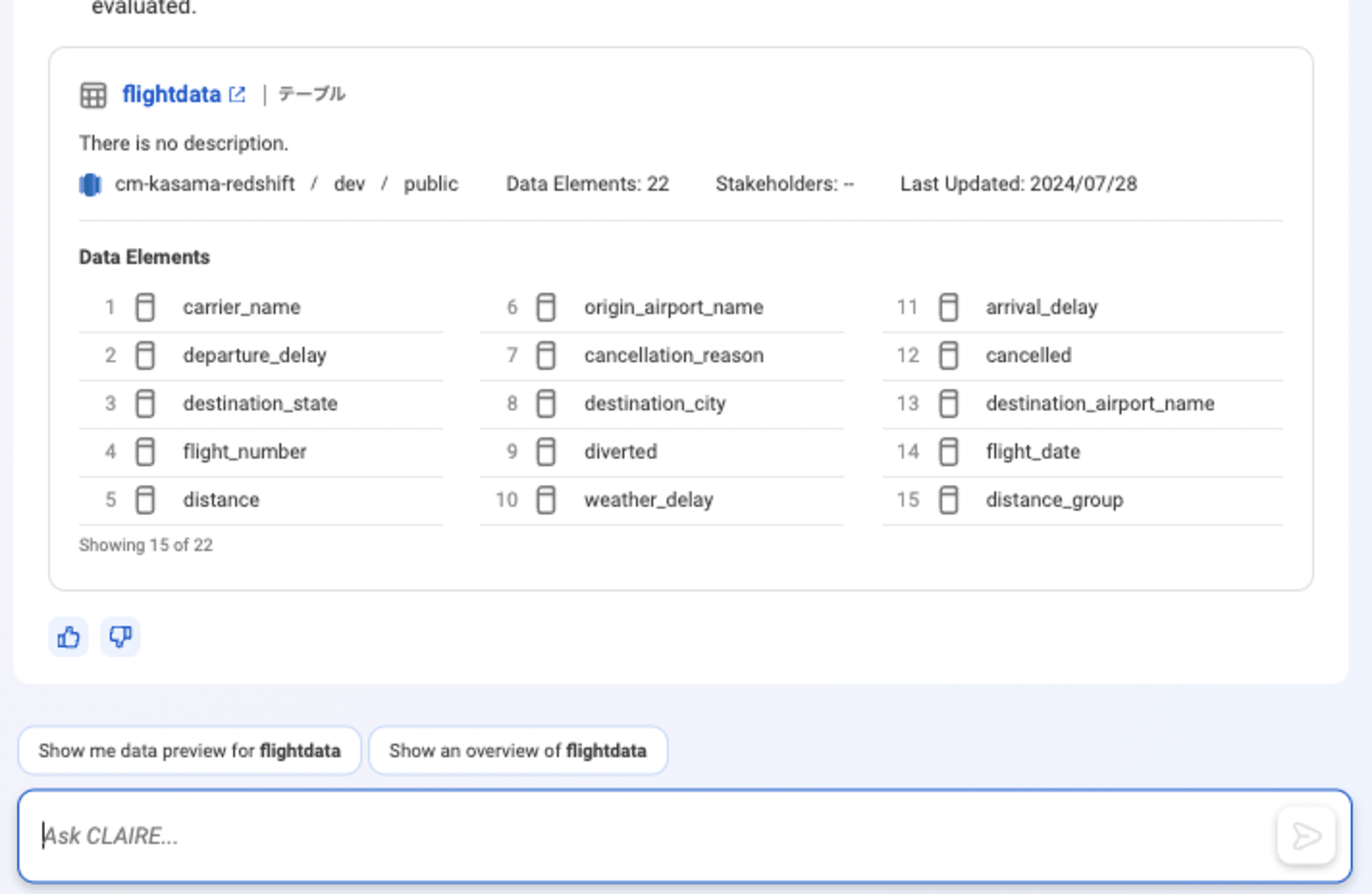
Metadata exploration
こちらは試してみましたがData previewに失敗するので後日調査したいと思います。データはRedshift側に存在することは確認しているので、何かしたらの設定が不足していると想定しています。
show data preview for sales
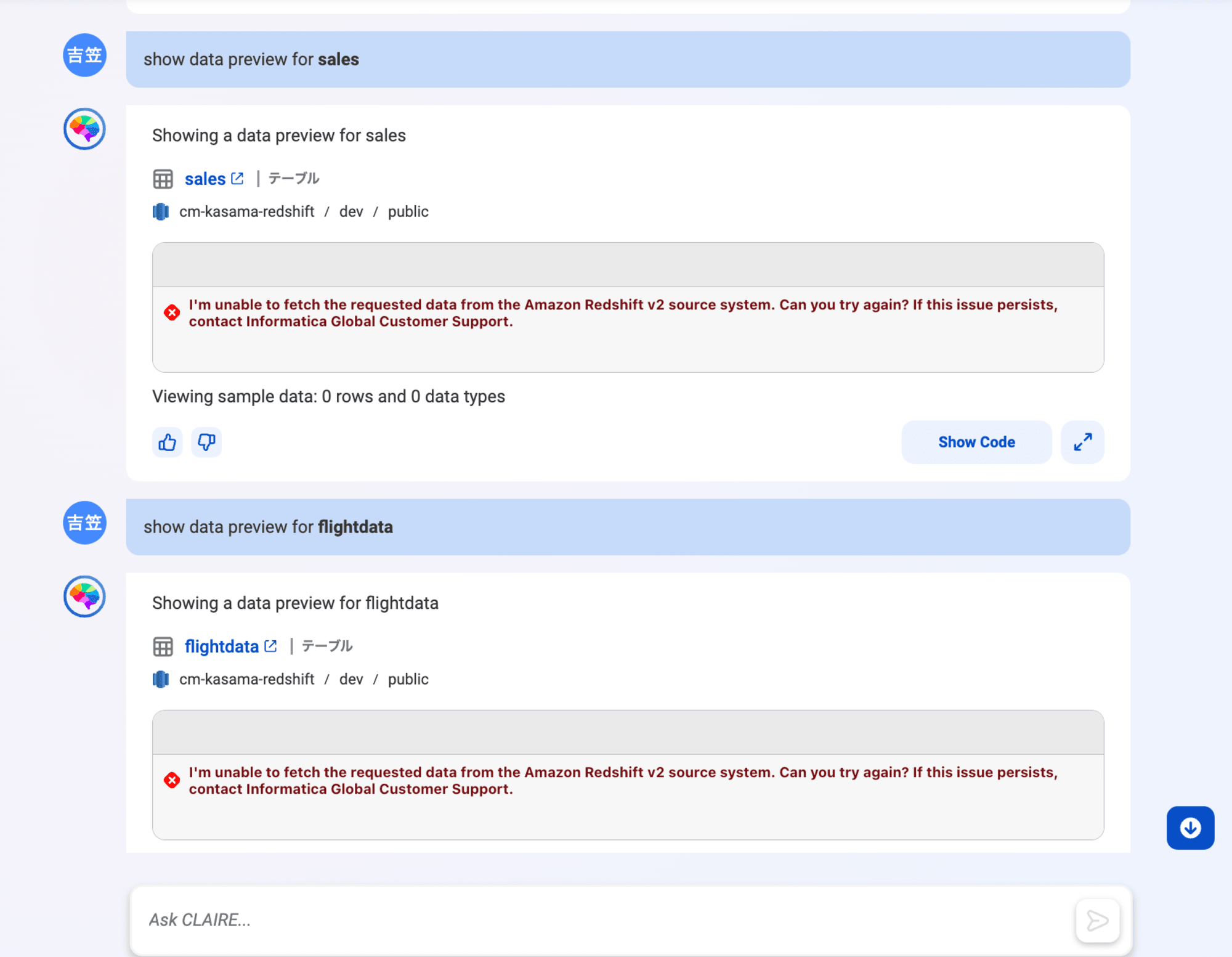
Data exploration
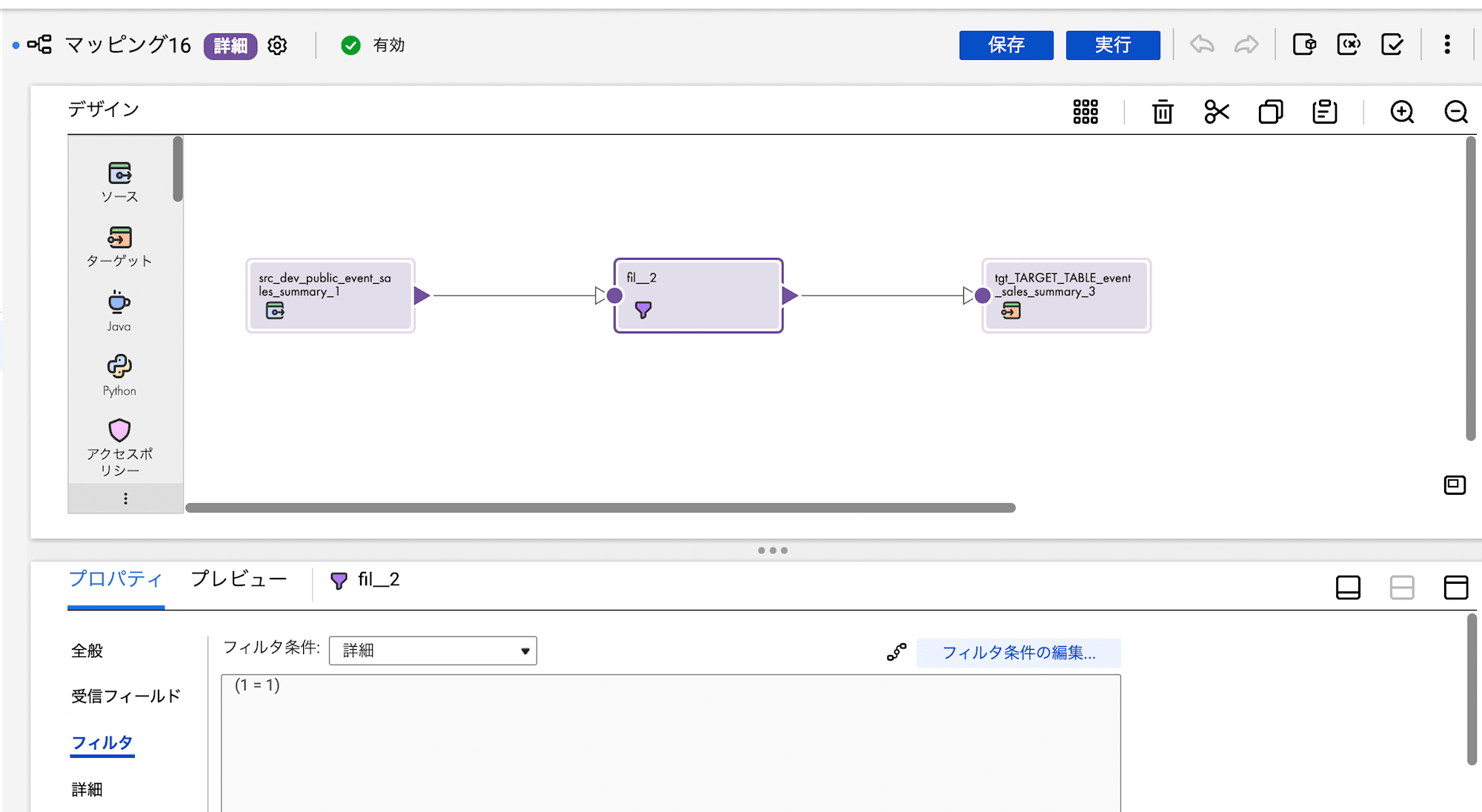
最後にETL Pipelineの作成を試したいと思います。フィルタ機能を加えた標準的な構成で生成してくれました。
Create a mapping for anything about event_sales_summary
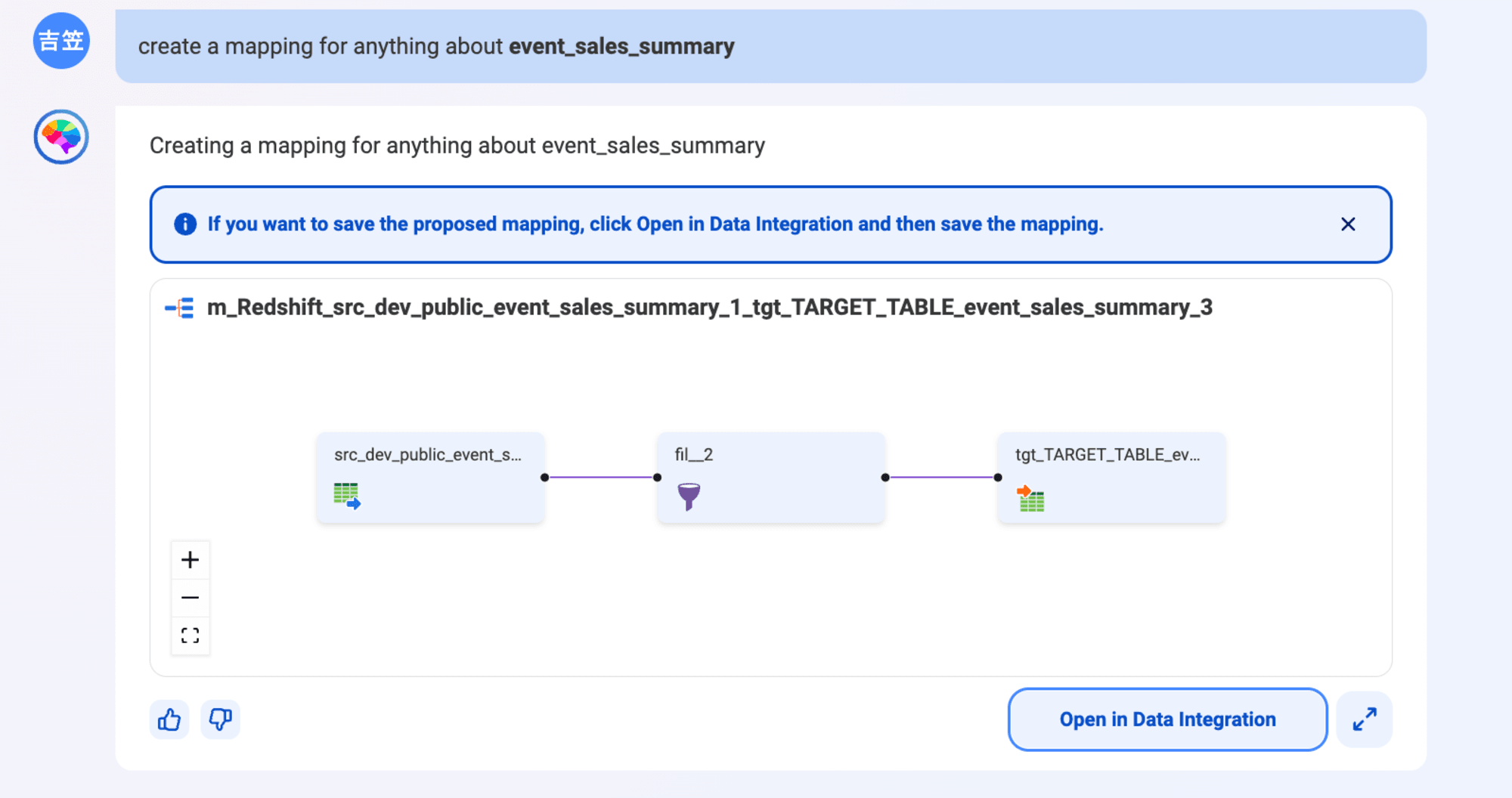
20240729追記
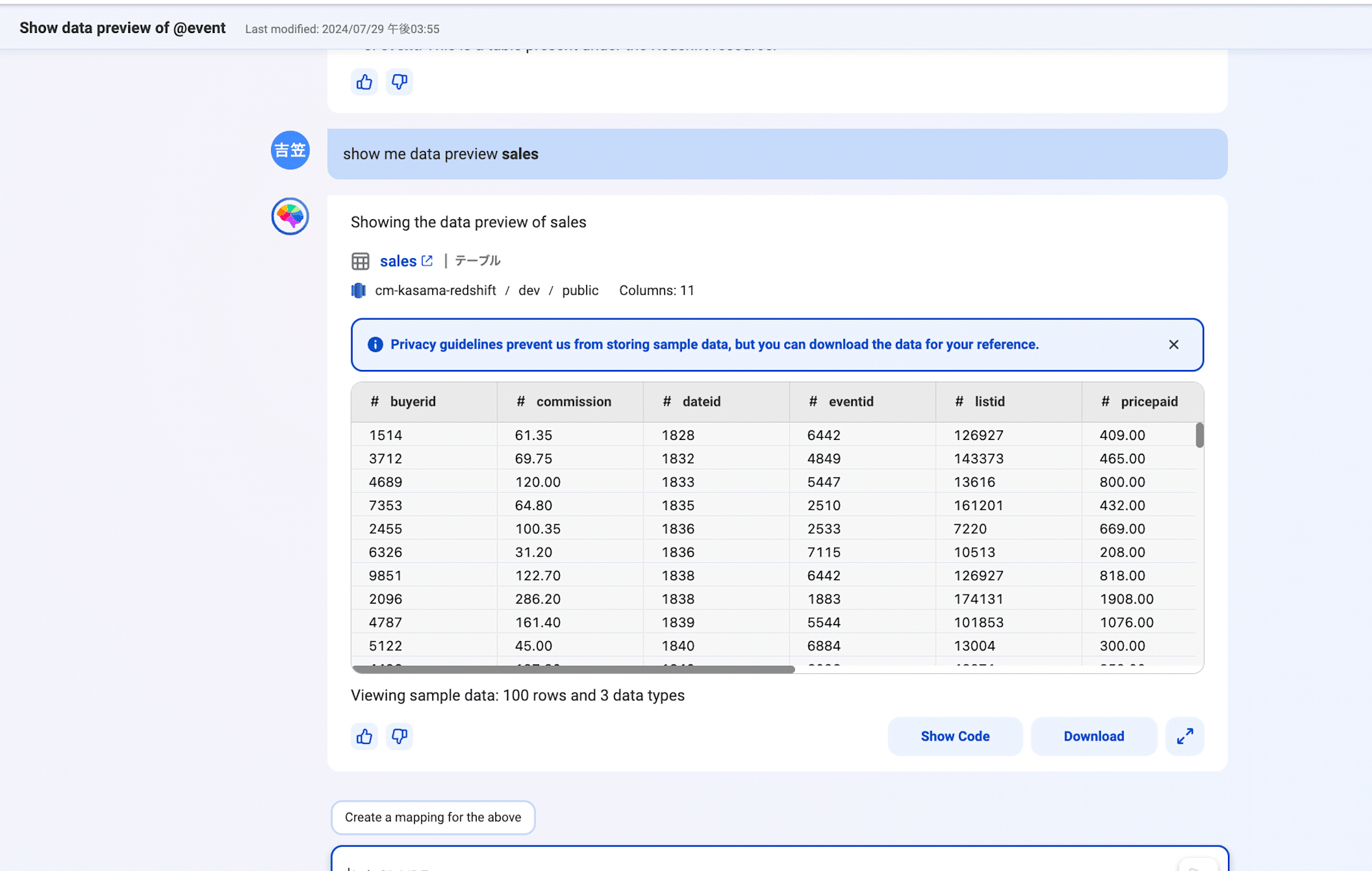
翌日再度試したところ、今回はdata previewに成功しました。
show me data preview sales
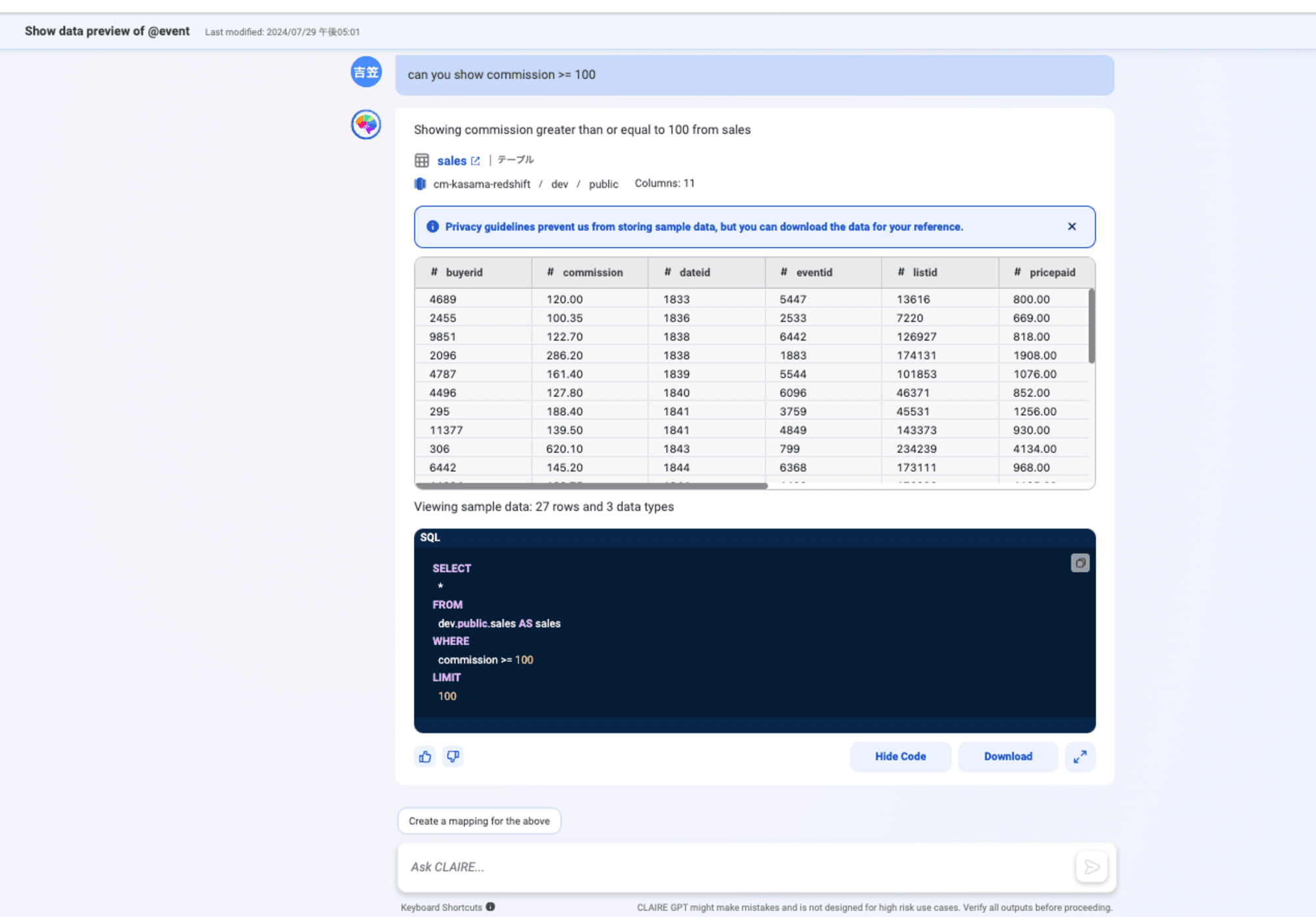
自然言語でテーブルに対して検索もできました。裏側ではSQLが実行されているようです。
can you show commission >= 100
promptの工夫が必要なのか、2つのtableの結合はできませんでした。
Join the event table with the sales table using the eventid column from both tables.

最後に
最後のETLを自然言語で作成できる機能は、まさにあったら便利だなーと感じていた機能でした。複雑なPromptに対しては設定の問題か、失敗することが多かったので引き続き試しながら活用していきたいです。









