
ECS Fargate で高いメモリ使用率をトラブルシューティングする方法を教えてください
困っていた内容
ECS Fargate でアプリケーションを実行しています。
ECS サービスのメモリ使用率が高いため、原因を特定したいです。トラブルシューティングする方法を教えてください。
どう対応すればいいの?
メモリ消費量が多いプロセスを特定してください。
ECS サービスレベルの CloudWatch メトリクスでメモリ使用率が高くなると、パフォーマンス低下や、エラーが発生することがあります。
一般的にこれらの問題は、特定プロセスにおけるメモリの大量消費やメモリリーク、ワークロードに対する不十分なメモリ割り当てが原因で発生します。
高いメモリ使用率の根本原因を特定するには、より細かい粒度で切り分けることが重要です。
1.メモリ使用率の傾向を確認する
ECS サービスレベルの CloudWatch メトリクスは、平均・最大・最小の統計が使用できます。
「平均」はすべてのタスクの平均使用率、「最大」はメモリ使用量が最も多いタスクの使用率、「最小」はメモリ使用量が最も少ないタスクの使用率を表します。
Amazon ECS サービスの使用率メトリクス - Amazon Elastic Container Service
統計 Minimum と Maximum は、すべてのタスクの集計計算ではなく、リソース使用率が最も低い個々のタスクと最も高い個々のタスクを表します。
各統計を確認して、メモリ使用率の傾向を把握してください。
例えば、画像のように「最大」と「平均」が大きく乖離している場合、一部のタスクが原因でメモリ使用率が高くなっていることが想定されます。
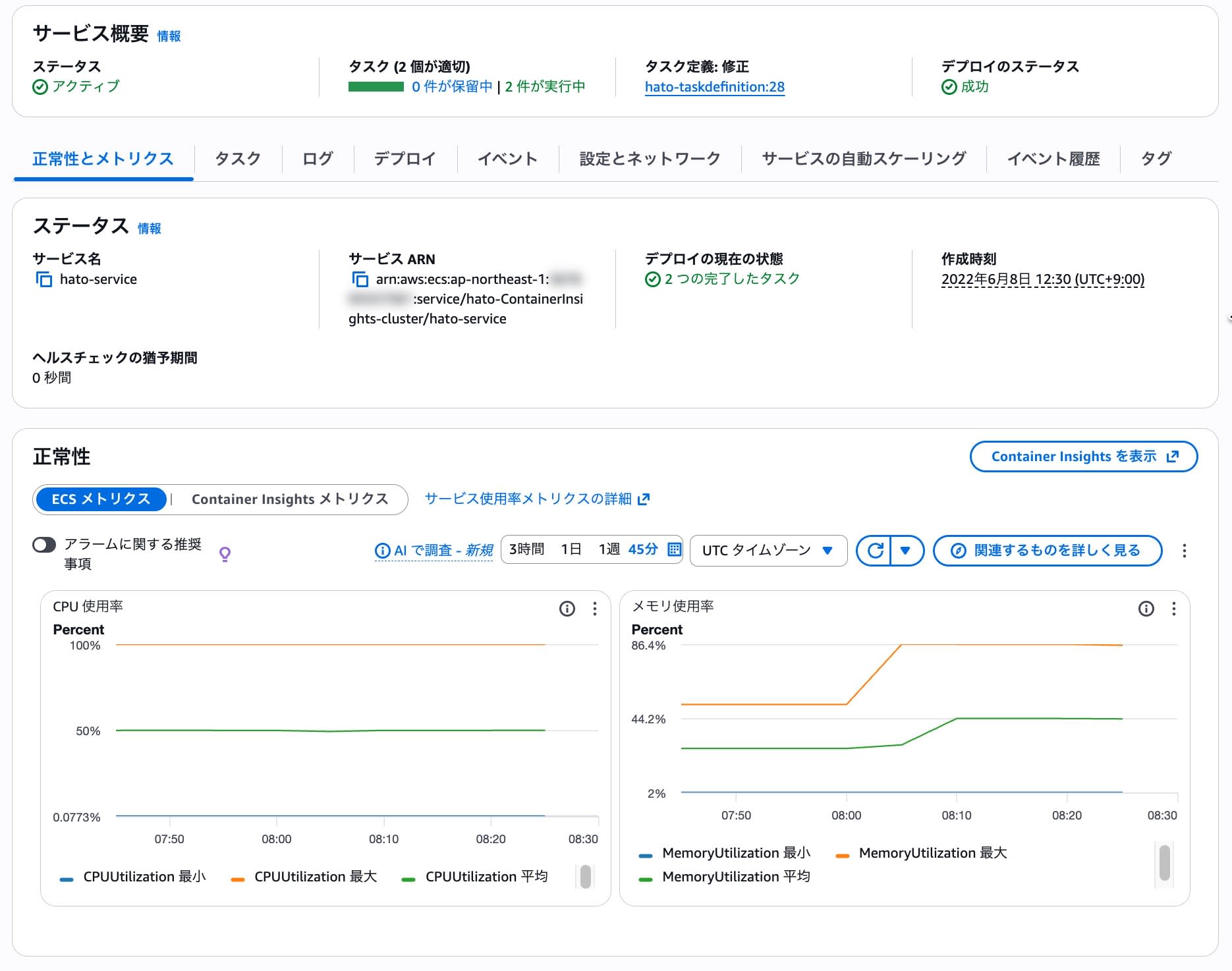
逆に、平均/最大/最小がほぼ同じ値の場合、全体的にメモリ使用率が高くなっていることが想定されます。
また、メモリ使用率の増加が時間経過に伴い右肩上がりになっている場合はメモリリーク、特定のタイミングで急上昇した場合は特定の処理やリクエストに起因することが想定されます。
2.メモリ使用率の高いタスク・コンテナを特定する
(タスク・コンテナを特定済みの場合はスキップできます)
特定のタスクが原因でメモリ使用率が高くなっている場合、具体的なタスク(コンテナ)を特定します。
タスク・コンテナ粒度の調査を行う場合は Container Insights が有用です。Container Insights は、ECS サービスレベルの CloudWatch メトリクスよりも細かい粒度での調査が可能で、画像のようなタスク・コンテナレベルのメモリ使用率が確認できます。
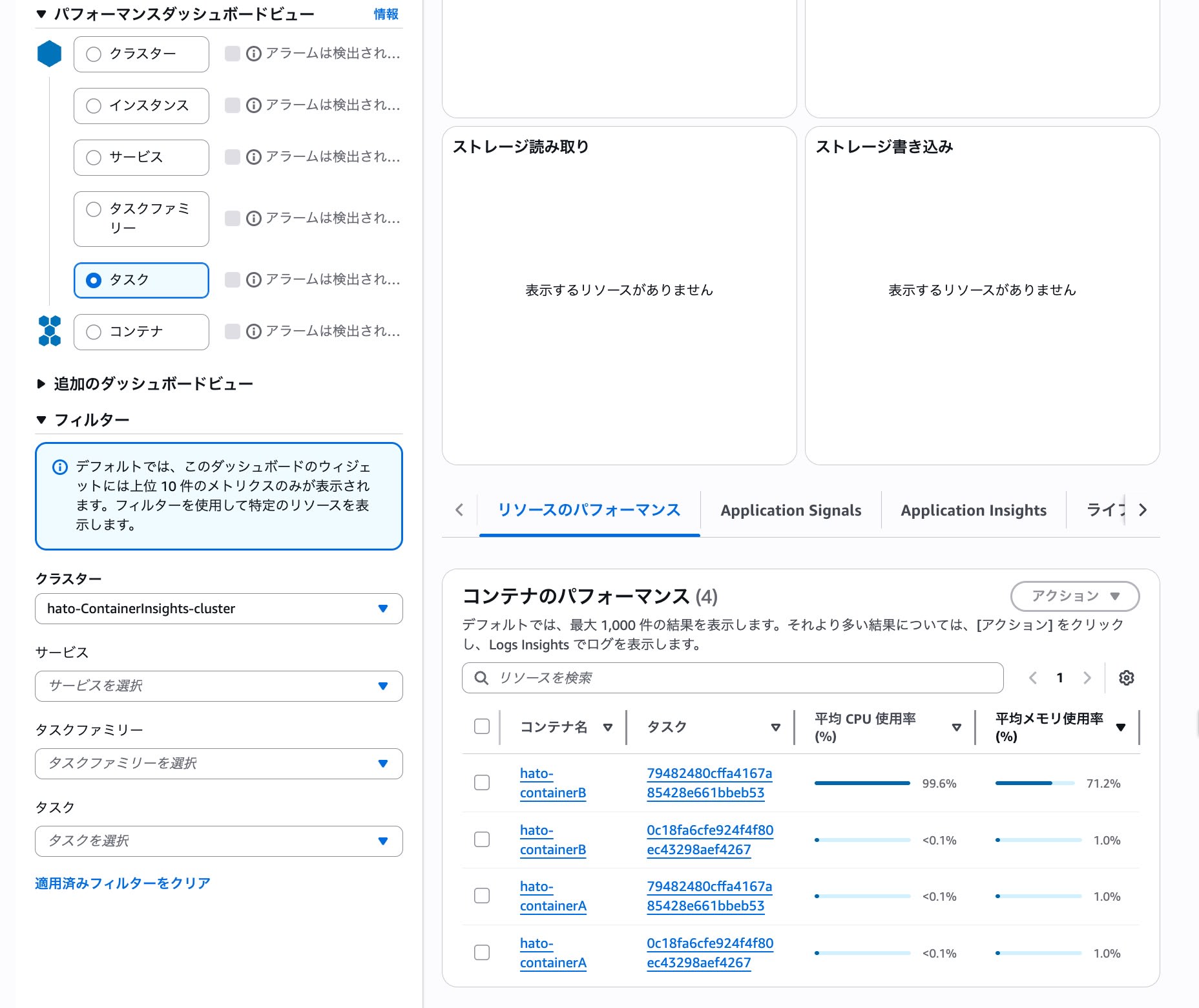
画像の場合、タスク ID:79482480cffa4167a85428e661bbeb53のコンテナ名:hato-containerBだけがメモリ使用率が非常に高くなっていることが確認できます。
3.メモリ消費量の多いプロセスを特定する
メモリ使用率が高いコンテナが確認できた場合、コンテナにシェルアクセスして、具体的にメモリを消費しているプロセスを特定します。
※システム要件からシェルアクセスができない場合は、サイドカーコンテナから監視してください。
ECS Fargate ではコンテナに docker exec することはできないため、ECS Exec でシェルアクセスします。
具体的に ECS Exec では、先ほど特定した「タスク ID」や「コンテナ名」を指定して実行します。
$ aws ecs execute-command --cluster 【クラスター名】 \
--task 【タスク ID】 \
--container 【コンテナ名】 \
--interactive \
--command "/bin/sh"
$ aws ecs execute-command --cluster hato-ecs-cluster \
--task 79482480cffa4167a85428e661bbeb53 \
--container hato-containerB \
--interactive \
--command "/bin/sh"
The Session Manager plugin was installed successfully. Use the AWS CLI to start a session.
Starting session with SessionId: ecs-execute-command-hatokbacd9rcztvufeicfk823y
sh-5.2#
sh-5.2#
sh-5.2#
コンテナで最もメモリを消費しているプロセスを特定するには、コンテナ内で次のコマンドを実行します。
$ ps aux --sort=-%mem | head -n 5
$ ps aux --sort=-%mem | head -n 5
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 520 99.5 44.0 1744332 1741076 pts/0 R+ 08:09 51:33 stress --vm 1 --vm-bytes 1700M --vm-keep
root 22 0.0 0.7 2237036 29412 ? Sl 07:34 0:00 /managed-agents/execute-command/ssm-agent-worker
root 1185 0.4 0.6 1851764 27280 ? Sl 08:59 0:00 /managed-agents/execute-command/ssm-session-worker ecs-execute-command-z55a
root 41 0.1 0.6 1927544 23972 ? Sl 07:35 0:06 /managed-agents/execute-command/ssm-session-worker ecs-execute-command-h3go
上記実行例の場合、stressプロセスが大量にメモリを消費しています。
プロセスが特定できたら、メモリ消費量が設計書などで想定した範囲内か確認します。
想定外の場合は、メモリリークやアルゴリズム最適化の余地がないか、コードレビューを検討してください。
想定内の場合は、スペック不足としてタスク定義によるスペックアップを検討してください。
また、必要に応じて top コマンドなど別の方法でトラブルシューティングを行います。
なお、コンテナ内で free コマンドなどを実行すると基盤側を含めた情報が取得され、タスクサイズや CloudWatch メトリクスで確認した値より大きな値が表示されます。
$ free -h
total used free shared buff/cache available
Mem: 3.8Gi 2.0Gi 519Mi 0.0Ki 1.2Gi 1.5Gi
Swap: 0B 0B 0B
コンテナ内で詳細なメモリサイズを確認したい場合、タスクメタデータエンドポイントの Docker 統計を確認してください。
タスクサイズはhierarchical_memory_limitとなります。
$ curl ${ECS_CONTAINER_METADATA_URI_V4}/stats | jq .memory_stats
...
{
"usage": 1877614592,
"max_usage": 1882972160,
"stats": {
"active_anon": 0,
"active_file": 13111296,
"cache": 43388928,
"dirty": 0,
"hierarchical_memory_limit": 2147483648,
"hierarchical_memsw_limit": 9223372036854771712,
"inactive_anon": 1825849344,
"inactive_file": 30412800,
"mapped_file": 25006080,
"pgfault": 934725,
"pgmajfault": 264,
"pgpgin": 817806,
"pgpgout": 361398,
"rss": 1825984512,
"rss_huge": 0,
"total_active_anon": 0,
"total_active_file": 13111296,
"total_cache": 43388928,
"total_dirty": 0,
"total_inactive_anon": 1825849344,
"total_inactive_file": 30412800,
"total_mapped_file": 25006080,
"total_pgfault": 934725,
"total_pgmajfault": 264,
"total_pgpgin": 817806,
"total_pgpgout": 361398,
"total_rss": 1825984512,
"total_rss_huge": 0,
"total_unevictable": 0,
"total_writeback": 0,
"unevictable": 0,
"writeback": 0
},
"limit": 9223372036854771712
}
参考資料
Amazon CloudWatch を使用して ECS サービスレベルのメトリクスを追跡します。リソース使用状況を詳細に取得するには、Container Insights または 拡張オブザーバビリティ Container Insights を有効にし、CPU 使用率とメモリ使用量のメトリクスを確認します。
- Fargate 上の Amazon ECS タスクのメモリ使用率の高さを監視する | AWS re:Post
- Fargate で Amazon ECS タスクの CPU 使用率が高い場合のトラブルシューティング | AWS re:Post
- ECS Exec を使用してコマンド実行 - Amazon Elastic Container Service
- Container Insights - Amazon CloudWatch
- New – Amazon ECS Exec による AWS Fargate, Amazon EC2 上のコンテナへのアクセス | Amazon Web Services ブログ
- Amazon ECS タスクサイズのベストプラクティス - Amazon Elastic Container Service
- Amazon ECS タスクメタデータエンドポイントバージョン 4 - Amazon Elastic Container Service
- 【小ネタ】AWS/ECS名前空間のMemoryUtilizationメトリクスとECS/ContainerInsights名前空間のMemoryUtilizedメトリクスは単位が違う | DevelopersIO









