
YOLOv12でエビを見つけ出す。
はじめに
皆様こんにちは、あかいけです。
皆様は画像からエビを見つけ出したいと思ったことはありますか?
私はあります。
というのも先日水族館でエビの写真を撮影した際、
「このエビはどこにいるんだ...」と探すのに苦労した経験がありました。
また料理の写真を整理していたときも、「あのエビ料理どこだっけ?」と探すのが大変で、
エビだけを自動で検出できたら便利だなと思ったわけです。
というわけで今回は物体検出モデルの中でも特に有名なYOLOを使って、
画像からエビを見つけ出してみました。
YOLOってなんだろう?
YOLOは「You Only Look Once」の略で、画像の中から物体を検出するAIモデルです。
名前の通り「一度見るだけ」で画像内の複数の物体を同時に検出できるのが特徴で、
リアルタイム処理が可能なほど高速に動作します。
具体的には以下のように、
物体の種類と位置を四角い枠(バウンディングボックス)で囲んで教えてくれます。
またYOLOには事前学習済みモデルが公開されており、大規模なデータセットで既に学習された重みを利用できます。
これにより、ゼロから学習するよりも少ないデータ量・短い時間で高精度なカスタムモデルを作成することができます。
今回はYOLO12の事前学習済みモデルを活用して、エビ検出に挑戦していきます。
筆者の環境
- CPU: AMD Ryzen 7 5700U
- Memory: DDR4 32GB
- OS: Ubuntu 24.04.2 LTS
- Python: 3.12.3
初期セットアップ
まずはYOLOを動かすための環境を整えていきます。
今回はPythonの仮想環境を使って、クリーンな状態でセットアップしていきます。
Python仮想環境のセットアップ
まずPython仮想環境を作成するためのパッケージをインストールします。
sudo apt install python3.12-venv;
次に仮想環境を作成して有効化し、YOLOのライブラリである ultralytics をインストールします。
このパッケージをインストールすると、yolo コマンドが使えるようになります。
python3 -m venv yolo12-test;
source yolo12-test/bin/activate;
cd yolo12-test;
pip3 install ultralytics;
インストール確認
インストールが完了したら、まずバージョンを確認してみます。
今回は以下のバージョンがインストールされました。
$ yolo version
8.3.212
さらに yolo checks コマンドで環境全体の確認を行います。
このコマンドでは、依存ライブラリのバージョンやシステムのスペックなどが一覧で表示されます。
(yolo12-test) $ yolo checks
Ultralytics 8.3.212 🚀 Python-3.12.3 torch-2.8.0+cu128 CPU (AMD Ryzen 7 5700U with Radeon Graphics)
Setup complete ✅ (16 CPUs, 30.8 GB RAM, 84.1/467.3 GB disk)
OS Linux-6.14.0-33-generic-x86_64-with-glibc2.39
Environment Linux
Python 3.12.3
Install git
Path /home/username/yolo12/yolo12-test/lib/python3.12/site-packages/ultralytics
RAM 30.75 GB
Disk 84.1/467.3 GB
CPU AMD Ryzen 7 5700U with Radeon Graphics
CPU count 16
GPU None
GPU count None
CUDA None
numpy ✅ 2.2.6>=1.23.0
matplotlib ✅ 3.10.7>=3.3.0
opencv-python ✅ 4.12.0.88>=4.6.0
pillow ✅ 11.3.0>=7.1.2
pyyaml ✅ 6.0.3>=5.3.1
requests ✅ 2.32.5>=2.23.0
scipy ✅ 1.16.2>=1.4.1
torch ✅ 2.8.0>=1.8.0
torch ✅ 2.8.0!=2.4.0,>=1.8.0; sys_platform == "win32"
torchvision ✅ 0.23.0>=0.9.0
psutil ✅ 7.1.0
polars ✅ 1.34.0
ultralytics-thop ✅ 2.0.17>=2.0.0
テストしてみる
まずは一番コンパクトな事前学習モデル(yolo12n.pt)を使ってみます。
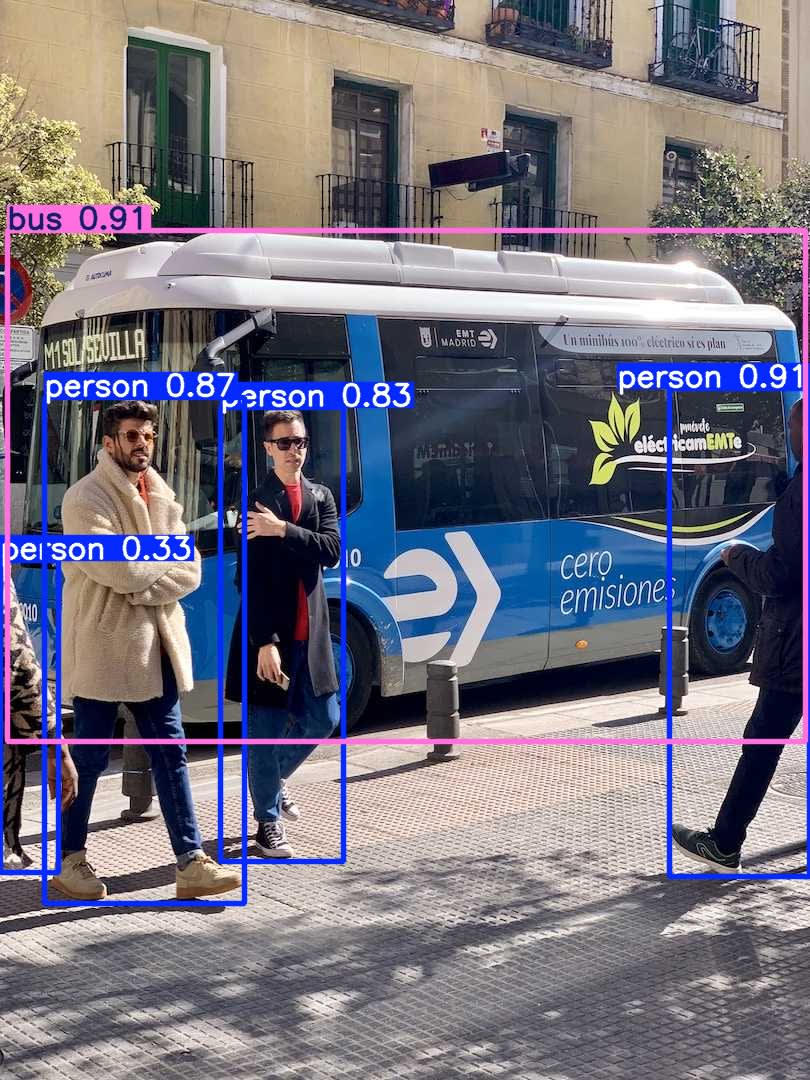
対象の画像はよくサンプルとして使われる、例のバスの写真を使ってみます。
$ yolo predict model=yolo12n.pt source='https://ultralytics.com/images/bus.jpg'
結果は以下の通りで、バスと人間をうまく検出できています。
見切れている人もしっかり検出できているので、この時点で精度の高さを実感しました。
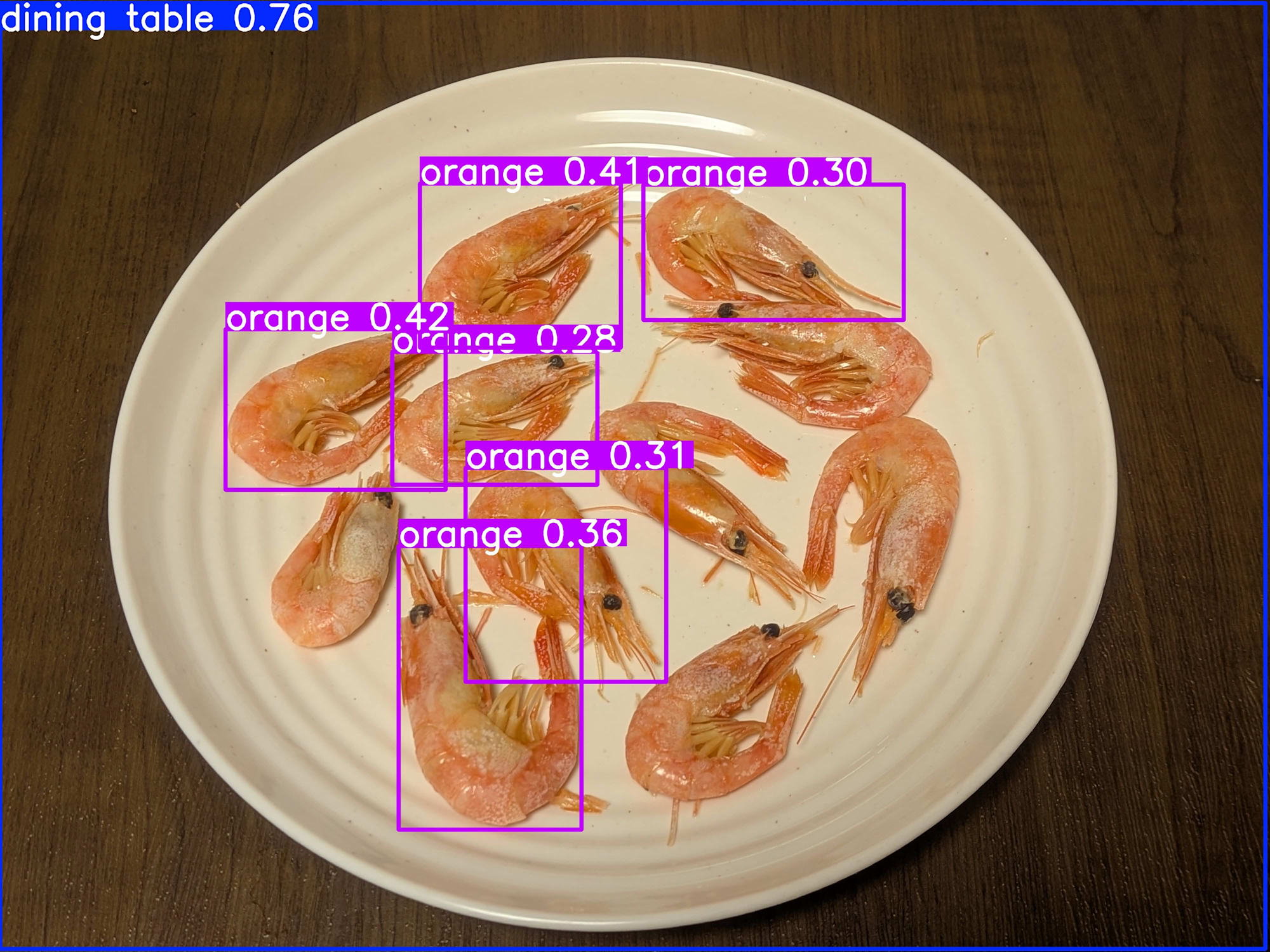
では本題のエビの検出についてですが、
$ yolo predict model=yolo12n.pt source="<画像ファルのパス>"
なんとオレンジとして検出されています。
念の為さらに大きな事前学習モデル(yolo12x.pt)を試してみましたが、
$ yolo predict model=yolo12x.pt source="<画像ファルのパス>"
どうやらエビは検出できないようです。

なぜこのような結果になるかですが、
そもそも事前学習モデルが学習したクラス(物体の種類)の中にエビが含まれていないためです。
実際に以下のコードでクラス名の一覧を確認してみると、
from ultralytics import YOLO
import json
model = YOLO("yolo12n.pt")
path = "https://ultralytics.com/images/bus.jpg"
results = model.predict(source=path, save=True)
classes = results[0].names
print(json.dumps(classes, indent=2, ensure_ascii=False))
クラスにエビ(shrimp)が含まれていません。
なので信頼度スコアは低いですが、
その中でも最も高い信頼度スコアとなった「orange」や「carrot」、「donut」として検出されるというわけです。
{
"0": "person",
"1": "bicycle",
"2": "car",
"3": "motorcycle",
"4": "airplane",
"5": "bus",
"6": "train",
"7": "truck",
"8": "boat",
"9": "traffic light",
"10": "fire hydrant",
"11": "stop sign",
"12": "parking meter",
"13": "bench",
"14": "bird",
"15": "cat",
"16": "dog",
"17": "horse",
"18": "sheep",
"19": "cow",
"20": "elephant",
"21": "bear",
"22": "zebra",
"23": "giraffe",
"24": "backpack",
"25": "umbrella",
"26": "handbag",
"27": "tie",
"28": "suitcase",
"29": "frisbee",
"30": "skis",
"31": "snowboard",
"32": "sports ball",
"33": "kite",
"34": "baseball bat",
"35": "baseball glove",
"36": "skateboard",
"37": "surfboard",
"38": "tennis racket",
"39": "bottle",
"40": "wine glass",
"41": "cup",
"42": "fork",
"43": "knife",
"44": "spoon",
"45": "bowl",
"46": "banana",
"47": "apple",
"48": "sandwich",
"49": "orange",
"50": "broccoli",
"51": "carrot",
"52": "hot dog",
"53": "pizza",
"54": "donut",
"55": "cake",
"56": "chair",
"57": "couch",
"58": "potted plant",
"59": "bed",
"60": "dining table",
"61": "toilet",
"62": "tv",
"63": "laptop",
"64": "mouse",
"65": "remote",
"66": "keyboard",
"67": "cell phone",
"68": "microwave",
"69": "oven",
"70": "toaster",
"71": "sink",
"72": "refrigerator",
"73": "book",
"74": "clock",
"75": "vase",
"76": "scissors",
"77": "teddy bear",
"78": "hair drier",
"79": "toothbrush"
}
カスタムモデルを作ってみる
さて、このままではエビを見つけ出せないのでカスタムモデルを作ってみます。
今回はYOLOの事前学習モデルを利用してファインチューニングしてみます。
データセットの準備
まず問題となるのは、学習元となるデータセットの準備です。
一般的には物体検出のファインチューニングには少なくとも100枚以上の画像を用意することが推奨されていますが、残念ながら私の手元にそんな大量のエビの画像はありません‥。
なので今回は以下で公開されているデータセットをありがたく利用させていただきます。
画像数は驚異の532枚で、さらにバウンディングボックスのアノテーション(物体の位置情報)も付与済みです。
これをゼロから用意することを考えると気が遠くなるので、ほんとにありがたいですね‥。
また上記はダウンロード後に解凍すればそのまま利用でき、
ディレクトリ構成は以下のとおりでした。
.
└── shrimp.v1i.yolov12
├── README.dataset.txt
├── README.roboflow.txt
├── data.yaml
├── test
├── train
└── valid
ファインチューニングしてみる
さて、では実際にファインチューニングしてみます。
ファインチューニング(転移学習)では、事前学習済みモデルの重みを活用します。
今回使用する yolo12n.pt は、大規模なデータセットで学習済みのモデルで、
既に「物体の一般的な特徴を抽出する能力」を持っています。
これをエビ検出用に再学習することで、ゼロから学習するよりも少ないデータ量で高精度なモデルを作成できます。
ファインチューニング用のスクリプトは以下の通りで、
今回はGPUを利用できないため、軽めにエポック数は60にしています。
from ultralytics import YOLO
import multiprocessing
# モデルをロード
model = YOLO('yolo12n.pt')
results = model.train(
data='data.yaml',
# 学習パラメータ
epochs=60,
imgsz=480,
batch=12,
# CPU最適化(Ryzen 7 5700U向け)
device='cpu',
workers=14,
# プロジェクト設定
name='shrimp_detector',
project='runs/detect',
save=True,
patience=25,
# データ拡張
hsv_h=0.012,
hsv_s=0.6,
hsv_v=0.35,
degrees=8,
translate=0.08,
scale=0.4,
fliplr=0.5,
mosaic=0.7,
# パフォーマンス最適化
amp=False,
cache=True,
rect=True,
# 検証・保存設定
val=True,
plots=True,
save_period=15,
# マルチプロセス設定
close_mosaic=10,
# その他の最適化
verbose=True,
seed=42,
)
またデフォルトのdata.yamlのパスだけ相対パスに修正しています。
train: train/images # 相対パスに修正
val: valid/images # 相対パスに修正
test: test/images # 相対パスに修正
nc: 1
names: ['shrimp']
roboflow:
workspace: test-gm8yy
project: shrimp-vyb21
version: 1
license: CC BY 4.0
url: https://universe.roboflow.com/test-gm8yy/shrimp-vyb21/dataset/1
学習開始から、
約1時間ぐらいでモデル作成が完了しました。
60 epochs completed in 1.113 hours.
Optimizer stripped from /home/username/yolo12/shrimp.v1i.yolov12/runs/detect/shrimp_detector/weights/last.pt, 5.5MB
Optimizer stripped from /home/username/shrimp.v1i.yolov12/runs/detect/shrimp_detector/weights/best.pt, 5.5MB
Validating /home/username/shrimp.v1i.yolov12/runs/detect/shrimp_detector/weights/best.pt...
Ultralytics 8.3.212 🚀 Python-3.12.3 torch-2.8.0+cu128 CPU (AMD Ryzen 7 5700U with Radeon Graphics)
YOLOv12n summary (fused): 159 layers, 2,556,923 parameters, 0 gradients, 6.3 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 1.0it/s 1.0s
all 20 23 0.996 1 0.995 0.868
Speed: 0.8ms preprocess, 47.1ms inference, 0.0ms loss, 0.3ms postprocess per image
Results saved to /home/username/yolo12/shrimp.v1i.yolov12/runs/detect/shrimp_detector
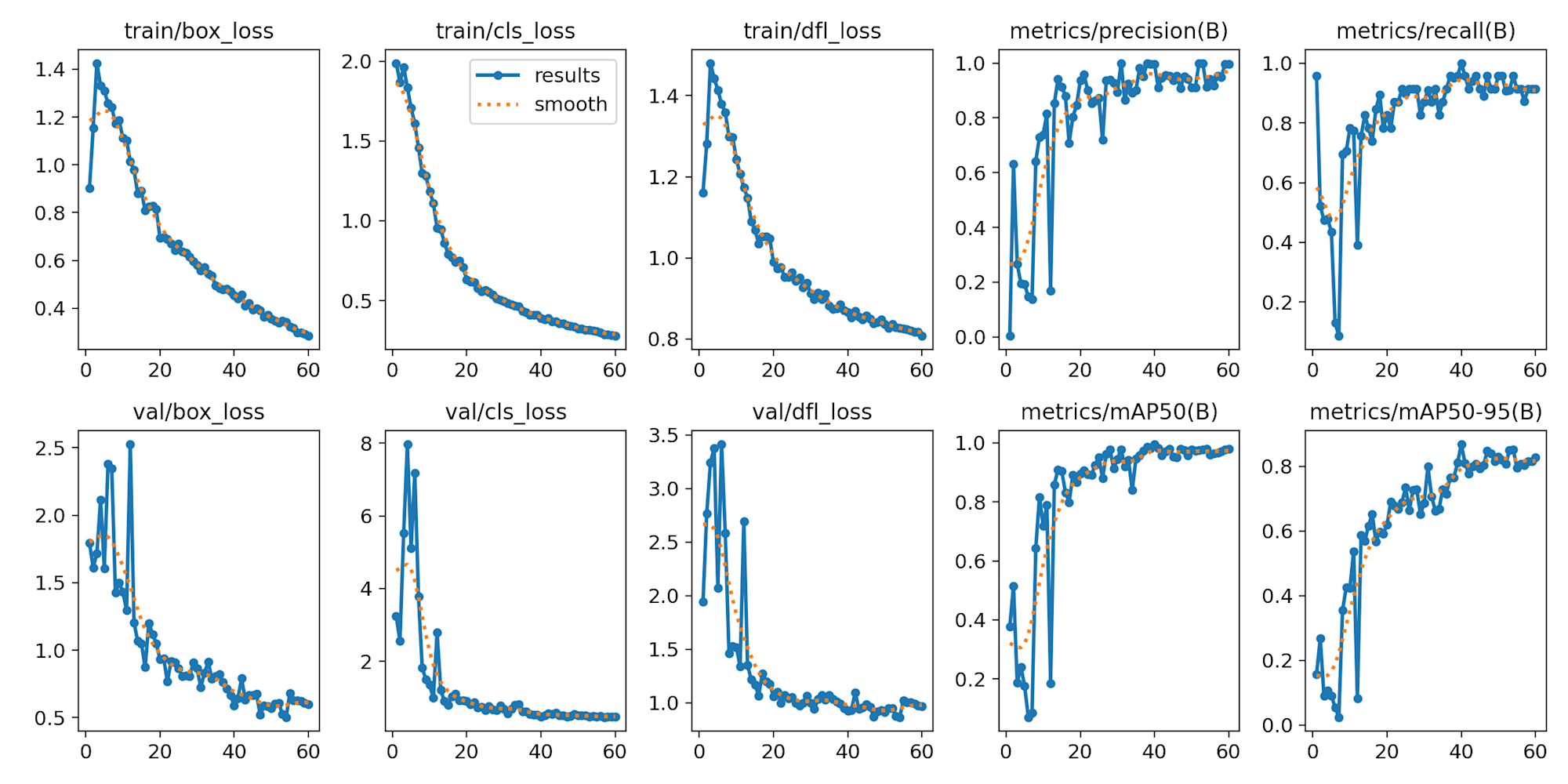
学習結果は以下の通りで、概ね良好です。
各指標の意味は以下の表にまとめました。
| グラフ名 | 説明 | 良い値 |
|---|---|---|
| train/box_loss | バウンディングボックスの位置・サイズの予測誤差(訓練データ) | 低いほど良い |
| train/cls_loss | クラス分類の誤差(訓練データ) | 低いほど良い |
| train/dfl_loss | 分布焦点損失(訓練データ) | 低いほど良い |
| val/box_loss | バウンディングボックスの位置・サイズの予測誤差(検証データ) | 低く安定している |
| val/cls_loss | クラス分類の誤差(検証データ) | 低く安定している |
| val/dfl_loss | 分布焦点損失(検証データ) | 低く安定している |
| metrics/precision(B) | 適合率: エビと予測したもののうち正解の割合 | 高いほど良い (1.0=100%) |
| metrics/recall(B) | 再現率: 実際のエビのうち検出できた割合 | 高いほど良い (1.0=100%) |
| metrics/mAP50(B) | IoU 50%での平均精度 | 高いほど良い (1.0=100%) |
| metrics/mAP50-95(B) | IoU 50-95%での平均精度 | 高いほど良い (1.0=100%) |
推論してみる
では実際に作成したカスタムモデルで推論してみます。
毎回コマンドを打つのもめんどくさいので、以下スクリプトを使ってみます。
from ultralytics import YOLO
import sys
if len(sys.argv) < 3:
print("usega: python predict.py <model> <image>")
print("example: python predict.py best.pt image.jpg")
sys.exit(1)
model_path = sys.argv[1]
image_path = sys.argv[2]
conf = float(sys.argv[3]) if len(sys.argv) > 3 else 0.5
# 推論実行
model = YOLO(model_path)
results = model.predict(
source=image_path,
save=True,
conf=conf,
save_txt=True,
save_conf=True,
)
実際のコマンドは以下のように、モデルのパスと画像ファイルのパスを渡してあげればOKです。
$ python3 predict_shrimp.py <カスタムモデルのパス> <画像ファイルのパス>
実際に使ってみると、
全部ではないですが、ある程度のエビを検出できています。

その他にもいくつか試してみましたが、概ねエビを認識できていそうです。
- しながわ水族館のクルマエビ

- いつかの日の懇親会のエビ寿司

- 日比谷フォートタワーのまるやの海老フライ定食

- コンサルティング部の合宿で食べたシュリンプカレー

- サイゼリヤの小エビのサラダ

- いらすとやの干しエビ・桜えびのイラスト

問題点と原因
さて、一見完璧に見えるエビ検出モデルですが、
重大な問題点があります。
誤検出
前述の海老フライ定食でも発生していましたが、誤検出(False Positive)が高頻度で発生します。
以下はその一例ですが、
猫だったりたい焼きだったり、オレンジ色っぽくて曲線的な物体をエビとして認識してしまうようです。
- めちゃくちゃ眠そうな猫

- TiDBのたい焼き

原因
以下は前述でも紹介した、エビ検知モデルを作成した際の結果をまとめたものです。
上記を見た限りでは、
すべてのパラメータで良好な結果が出ているので、一見問題がないように見受けられます。
しかしこれらはあくまで学習に利用した「データセット」を対象とした結果であり、
今回利用したオープンデータセットには「エビ以外の画像(ネガティブサンプル)」が含まれていませんでした。
またdata.yamlでは「shrimp」のクラスしか定義しておらず、実際に作成したモデルのクラスを確認すると以下の通りです。
{
"0": "shrimp"
}
つまり「エビの学習は完璧」だけど「エビではないものの特徴を知らない」という状況です。
ここで疑問に思うかもしれませんが、事前学習モデル(yolo12n.pt)には80種類のクラスの知識があったはずです。
ファインチューニングを行った際、この事前学習の知識はどうなったのでしょうか?
実はファインチューニング時に data.yaml で新しいクラス定義(今回は「shrimp」のみ)を指定すると、
モデルの出力層(クラス分類を行う最終層)が新しいクラス数に合わせて再構築されます。
そのため事前学習で学んだ「物体の一般的な特徴抽出能力」は残りますが、
「personやcarなどの個別クラスを識別する能力」は失われてしまいます。
結果として、信頼度スコアが低い場合でも、学習済みの唯一のクラスである「shrimp」として検出されてしまうわけです。
そういった意味では、事前学習モデルでエビをorangeやcarrot,donutとして検出するのと本質的には同じ状況と言えそうです。
この問題の解消方法ですが、
前提としてエビだけ検出できればいいので、data.yamlにその他のクラスを追加する必要はありません。
そのためネガティブサンプル(エビではない画像)を追加して、「エビではないもの」を学習させることで、適合率(Precision)を向上させる必要があります。
しかし今回YOLOを初めて利用したということもあり、
私はここで力尽きたので、ネガティブサンプルを追加したファインチューニングはまた次回にやってみようと思います。
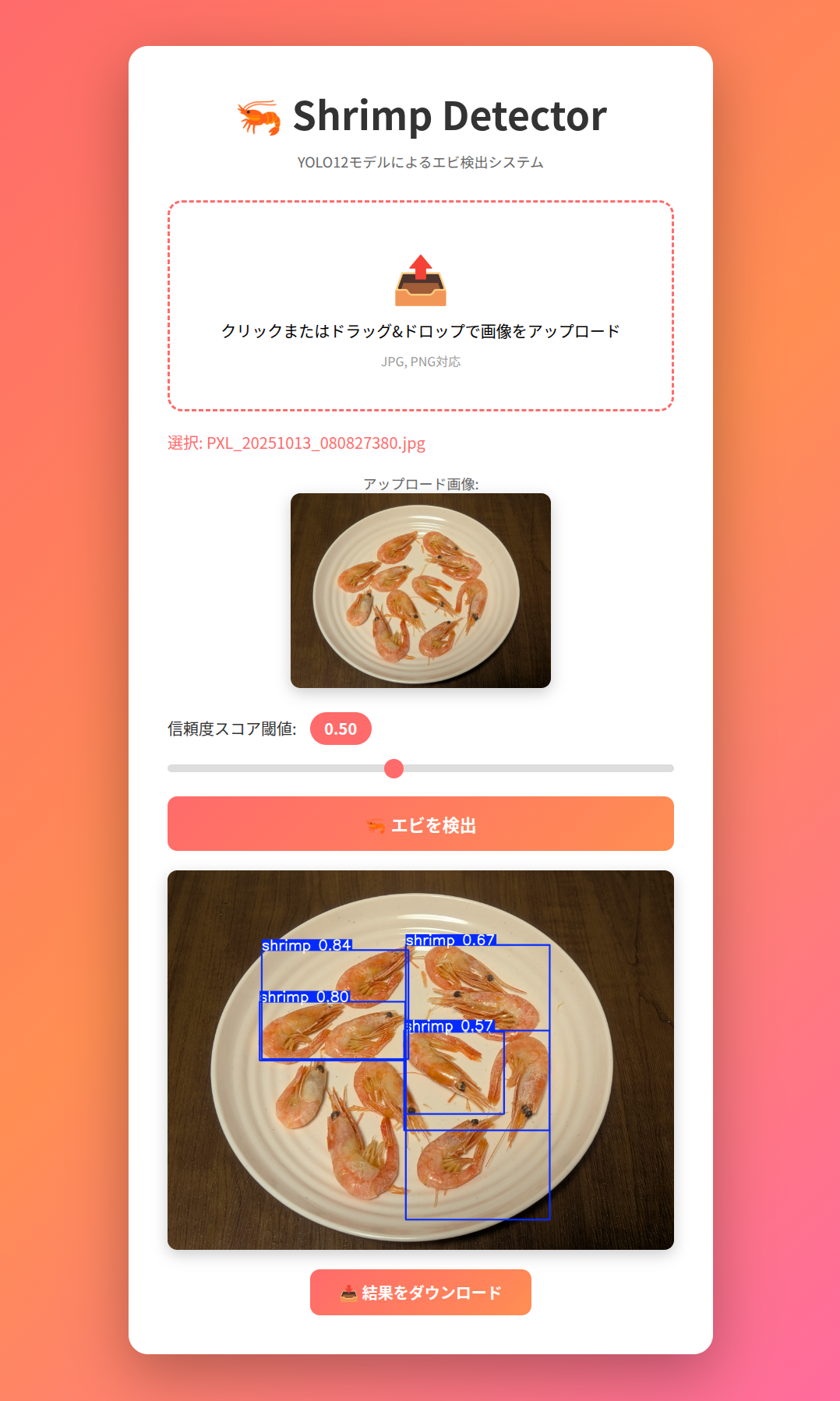
アプリ化してみる
さて、前述の通り色々なものがエビに見えてしまうという問題点はありますが、
せっかくなのでflaskを使ってウェブブラウザから利用できるようにしてみます。
以下はClaude Codeに適当にお願いした実装コードです。
コード
Flask==3.1.2
ultralytics==8.3.212
opencv-python==4.12.0.88
Pillow==11.0.0
numpy==2.2.6
from flask import Flask, request, send_file, render_template
from ultralytics import YOLO
import io
from PIL import Image
import cv2
import numpy as np
app = Flask(__name__)
# モデルのパスを指定
MODEL_PATH = "./shrimp.v1i.yolov12/runs/detect/shrimp_detector/weights/best.pt"
model = YOLO(MODEL_PATH)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/predict', methods=['POST'])
def predict():
if 'image' not in request.files:
return 'No image uploaded', 400
file = request.files['image']
if file.filename == '':
return 'No image selected', 400
# 信頼度スコアの取得(デフォルト0.5)
conf = float(request.form.get('conf', 0.5))
# 画像を読み込み
img_bytes = file.read()
nparr = np.frombuffer(img_bytes, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
# 推論実行(保存なし)
results = model.predict(
source=img,
save=False,
conf=conf,
)
# 結果を画像に描画
result_img = results[0].plot()
# BGR to RGB
result_img_rgb = cv2.cvtColor(result_img, cv2.COLOR_BGR2RGB)
# PILイメージに変換
pil_img = Image.fromarray(result_img_rgb)
# メモリ上のバイトストリームに保存
img_io = io.BytesIO()
pil_img.save(img_io, 'JPEG', quality=95)
img_io.seek(0)
# 検出数を取得
total_detections = len(results[0].boxes)
return send_file(
img_io,
mimetype='image/jpeg',
as_attachment=True,
download_name=f'shrimp_detected_{total_detections}.jpg'
)
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5000)
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>🦐 Shrimp Detector - YOLO12</title>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
background: linear-gradient(135deg, #ff6b6b 0%, #ff8e53 50%, #ff6b9d 100%);
min-height: 100vh;
display: flex;
justify-content: center;
align-items: center;
padding: 20px;
}
.container {
background: white;
border-radius: 20px;
box-shadow: 0 20px 60px rgba(0, 0, 0, 0.3);
padding: 40px;
max-width: 600px;
width: 100%;
}
h1 {
text-align: center;
color: #333;
margin-bottom: 10px;
font-size: 2.5em;
}
.subtitle {
text-align: center;
color: #666;
margin-bottom: 30px;
font-size: 0.9em;
}
.upload-area {
border: 3px dashed #ff6b6b;
border-radius: 15px;
padding: 40px;
text-align: center;
margin-bottom: 20px;
transition: all 0.3s;
cursor: pointer;
}
.upload-area:hover {
background: #fff5f5;
border-color: #ff8e53;
}
.upload-area.dragover {
background: #ffeded;
border-color: #ff8e53;
}
.upload-icon {
font-size: 3em;
margin-bottom: 10px;
}
input[type="file"] {
display: none;
}
.conf-setting {
margin: 20px 0;
}
.conf-setting label {
display: block;
margin-bottom: 10px;
color: #333;
font-weight: 500;
}
.conf-slider {
width: 100%;
height: 8px;
border-radius: 5px;
background: #ddd;
outline: none;
-webkit-appearance: none;
}
.conf-slider::-webkit-slider-thumb {
-webkit-appearance: none;
appearance: none;
width: 20px;
height: 20px;
border-radius: 50%;
background: #ff6b6b;
cursor: pointer;
}
.conf-slider::-moz-range-thumb {
width: 20px;
height: 20px;
border-radius: 50%;
background: #ff6b6b;
cursor: pointer;
border: none;
}
.conf-value {
display: inline-block;
background: #ff6b6b;
color: white;
padding: 5px 15px;
border-radius: 20px;
margin-left: 10px;
font-weight: bold;
}
button {
width: 100%;
padding: 15px;
background: linear-gradient(135deg, #ff6b6b 0%, #ff8e53 100%);
color: white;
border: none;
border-radius: 10px;
font-size: 1.1em;
font-weight: bold;
cursor: pointer;
transition: transform 0.2s;
}
button:hover {
transform: translateY(-2px);
}
button:disabled {
background: #ccc;
cursor: not-allowed;
transform: none;
}
.preview {
margin-top: 20px;
text-align: center;
}
.preview img {
max-width: 100%;
border-radius: 10px;
box-shadow: 0 5px 15px rgba(0, 0, 0, 0.2);
}
.loading {
display: none;
text-align: center;
margin-top: 20px;
}
.spinner {
border: 4px solid #f3f3f3;
border-top: 4px solid #ff6b6b;
border-radius: 50%;
width: 40px;
height: 40px;
animation: spin 1s linear infinite;
margin: 0 auto;
}
@keyframes spin {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
.filename {
margin-top: 15px;
color: #ff6b6b;
font-weight: 500;
}
.download-btn {
display: inline-block;
margin-top: 15px;
padding: 12px 30px;
background: linear-gradient(135deg, #ff6b6b 0%, #ff8e53 100%);
color: white;
text-decoration: none;
border-radius: 10px;
font-weight: bold;
transition: transform 0.2s;
}
.download-btn:hover {
transform: translateY(-2px);
}
.thumbnail {
margin-top: 20px;
text-align: center;
}
.thumbnail img {
max-width: 300px;
max-height: 200px;
border-radius: 10px;
box-shadow: 0 5px 15px rgba(0, 0, 0, 0.2);
}
.thumbnail-label {
margin-top: 10px;
color: #666;
font-size: 0.9em;
}
</style>
</head>
<body>
<div class="container">
<h1>🦐 Shrimp Detector</h1>
<p class="subtitle">YOLO12モデルによるエビ検出システム</p>
<form id="uploadForm" enctype="multipart/form-data">
<div class="upload-area" id="uploadArea">
<div class="upload-icon">📤</div>
<p>クリックまたはドラッグ&ドロップで画像をアップロード</p>
<p style="font-size: 0.8em; color: #999; margin-top: 10px;">JPG, PNG対応</p>
<input type="file" id="imageInput" name="image" accept="image/*" required>
</div>
<div class="filename" id="filename"></div>
<div class="thumbnail" id="thumbnail"></div>
<div class="conf-setting">
<label>
信頼度スコア閾値: <span class="conf-value" id="confValue">0.50</span>
</label>
<input type="range" class="conf-slider" id="confSlider" name="conf" min="0.1" max="1.0" step="0.05" value="0.5">
</div>
<button type="submit" id="detectBtn" disabled>🦐 エビを検出</button>
</form>
<div class="loading" id="loading">
<div class="spinner"></div>
<p style="margin-top: 10px; color: #ff6b6b;">🦐 検出中...</p>
</div>
<div class="preview" id="preview"></div>
</div>
<script>
const uploadArea = document.getElementById('uploadArea');
const imageInput = document.getElementById('imageInput');
const confSlider = document.getElementById('confSlider');
const confValue = document.getElementById('confValue');
const detectBtn = document.getElementById('detectBtn');
const uploadForm = document.getElementById('uploadForm');
const loading = document.getElementById('loading');
const filename = document.getElementById('filename');
const thumbnail = document.getElementById('thumbnail');
// クリックでファイル選択
uploadArea.addEventListener('click', () => imageInput.click());
// ドラッグ&ドロップ
uploadArea.addEventListener('dragover', (e) => {
e.preventDefault();
uploadArea.classList.add('dragover');
});
uploadArea.addEventListener('dragleave', () => {
uploadArea.classList.remove('dragover');
});
uploadArea.addEventListener('drop', (e) => {
e.preventDefault();
uploadArea.classList.remove('dragover');
const files = e.dataTransfer.files;
if (files.length > 0) {
imageInput.files = files;
handleFileSelect();
}
});
// ファイル選択時
imageInput.addEventListener('change', handleFileSelect);
function handleFileSelect() {
if (imageInput.files.length > 0) {
detectBtn.disabled = false;
const file = imageInput.files[0];
filename.textContent = `選択: ${file.name}`;
// サムネイル表示
const reader = new FileReader();
reader.onload = (e) => {
thumbnail.innerHTML = `
<p class="thumbnail-label">アップロード画像:</p>
<img src="${e.target.result}" alt="Uploaded image">
`;
};
reader.readAsDataURL(file);
}
}
// スライダー
confSlider.addEventListener('input', (e) => {
confValue.textContent = parseFloat(e.target.value).toFixed(2);
});
// フォーム送信
uploadForm.addEventListener('submit', async (e) => {
e.preventDefault();
const formData = new FormData(uploadForm);
loading.style.display = 'block';
detectBtn.disabled = true;
document.getElementById('preview').innerHTML = '';
try {
const response = await fetch('/predict', {
method: 'POST',
body: formData
});
if (response.ok) {
const blob = await response.blob();
const url = URL.createObjectURL(blob);
// ファイル名取得
const contentDisposition = response.headers.get('Content-Disposition');
const filenameMatch = contentDisposition?.match(/filename="?(.+)"?/);
const downloadFilename = filenameMatch ? filenameMatch[1] : 'result.jpg';
// プレビュー表示
const previewDiv = document.getElementById('preview');
previewDiv.innerHTML = '';
const img = document.createElement('img');
img.src = url;
previewDiv.appendChild(img);
// ダウンロードボタン
const downloadBtn = document.createElement('a');
downloadBtn.href = url;
downloadBtn.download = downloadFilename;
downloadBtn.className = 'download-btn';
downloadBtn.textContent = '📥 結果をダウンロード';
previewDiv.appendChild(downloadBtn);
} else {
alert('エラーが発生しました');
}
} catch (error) {
alert('エラーが発生しました: ' + error.message);
} finally {
loading.style.display = 'none';
detectBtn.disabled = false;
}
});
</script>
</body>
</html>
あとはライブラリをインストールして、起動するだけです。
$ pip3 install -r requirements.txt
$ python3 app.py
なかなかエビを感じる良いビジュアルです。
さいごに
以上、YOLOv12でエビを見つけ出してみました。
実は物体検出モデル自体初めて触ったのですが、
YOLO + オープンデータセットを利用することで比較的簡単にカスタムモデルを作成することができました。
これを機に、皆様も好きなものを検出するモデルを作成してみてはいかがでしょうか。
結果としてちょっと問題のあるカスタムモデルを生み出してしまいましたが、
今後ネガティブサンプルを追加したファインチューニングでさらに改良していければと思います。
より完成度の高いエビ検出モデルが作成できたら、その際はまたブログにします。










