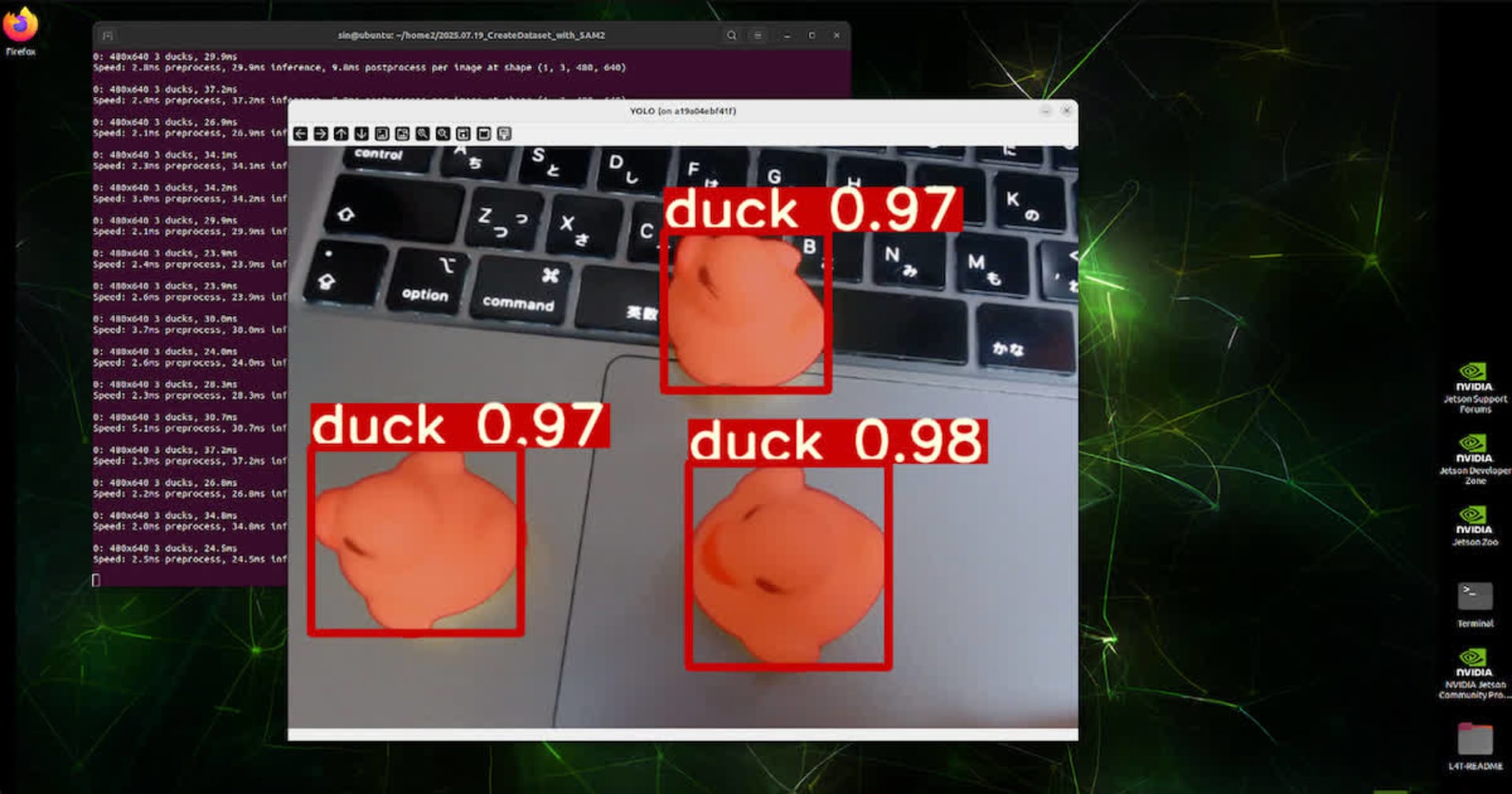
YOLOv5でアヒルを検出するモデルを作ってみました。(NVIDIA Jetson AGX Orin + l4t-pytorch:r35.2.1-pth2.0-py3)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
1 はじめに
CX 事業本部のデリバリー部の平内(SIN)です。
YOLOは、物体検出で広く使用されている深層学習モデルですが、次々と新しいバージョンが発表されています。
【動画あり】早速YOLOv8を使って自作データセットで物体検出してみた
YOLOv7の実装を理解する(YOLOv7のコードを読んでみた)
今回は、現時点で、比較的情報量が多く、簡単に利用可能になっているYOLOv5を使ってみた記録です。
YOLOv5は、PyTorchがベースとなっていますが、使用した NVIDIA Jetson AGX Orin では、pipで最新のPytorch(2.0.0)をインストールしてしまうと、Cuda(GPU)が利用できなかったので、NVIDIAで提供されているDockerイメージ(l4t-pytorch:r35.2.1-pth2.0-py3)を使用した手順についても触れたいと思います。
最初に、作業した動画です。アヒルを検出している場面の後には、回転台で撮影した動画から、アノテーションされたデータセットを生成する作業についても紹介させて頂きました。
2 データセット作成
データセットを作成した手順は、以下の通りです。
- 撮影
- クロマキー処理
- バウンディングボックスで切り抜かれた画像生成
- 背景と合成してデータセット作成(Ground Thruth形式)
- YOLOv5のデータ形式に変換
(1) 撮影
最初に、クロマキー処理で背景を削除するため、グリーンをバックにしてアヒルを撮影しています。アヒルは回転台に乗せ、カメラの角度を変えたり、アヒルをひっくり返したりして、さまざまなアヒルの動画を撮っています。

(2) クロマキー処理
クロマキー処理に使用したのは、Wondershare Filmoraです。
基準のカラーをグリーンとし、オフセットと許容差を調整することで、うまく、背景が消えるように調整して、動画をエクスポートします。

(3) バウンディングボックスで切り抜かれた画像生成
次のプログラムで、動画からアヒルが写っている部分を検出し、透過PNGとして保存しています。検出した矩形で画像を切り抜くことで、最終的にデータセット画像のバウンディングボックスとなります。(アノテーションの自動化)

ソースコードは、こちらです。 mp4_to_png.py
# -*- coding: utf-8 -*-
import shutil
import glob
import os
import cv2
import numpy as np
max = 200 # 1個の動画から生成する画像数
input_path = "./dataset/mp4"
output_path = "./dataset/output_png"
# 矩形検出
def detect_rectangle(img):
# グレースケール
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 背景の多少のノイズは削除する
_, gray_img = cv2.threshold(gray_img, 50, 255, cv2.THRESH_BINARY)
# 輪郭検出
contours, _ = cv2.findContours(gray_img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
rect = None
for contour in contours:
# ある程度の面積が有るものだけを対象にする
area = cv2.contourArea(contour, False);
if area < 1000:
continue
# 輪郭を直線近似する
epsilon = 0.1 * cv2.arcLength(contour, True)
approx = cv2.approxPolyDP(contour, epsilon, True)
# 最大サイズの矩形を取得する
x, y, w, h = cv2.boundingRect(contour)
if(rect != None):
if(w * h < rect[2] * rect[3]):
continue
rect = [x, y, w, h]
return rect
# 透過イメージ保存
def create_transparent_image(img):
# RGBを分離
ch_b, ch_g, ch_r = cv2.split(img[:,:,:3])
# アルファチャンネル生成
h, w, _ = img.shape
ch_a = np.zeros((h, w) ,dtype = 'uint8')
ch_a += 255
# 各チャンネルを結合
rgba_img = cv2.merge((ch_b, ch_g, ch_r, ch_a))
# マスク
color_lower = np.array([0, 0, 0, 255])
# color_upper = np.array([80, 80, 80, 255])
color_upper = np.array([40, 40, 40, 255])
mask = cv2.inRange(rgba_img, color_lower, color_upper)
return cv2.bitwise_not(rgba_img, rgba_img, mask=mask)
def save_image(class_name, img):
path = "{}/{}".format(output_path, class_name)
if os.path.exists(path) == False:
os.makedirs(path)
for i in range(1000):
filename = "{}/{}.png".format(path, i)
if os.path.exists(filename) == False:
cv2.imwrite(filename, img)
print(filename)
return
def main():
os.makedirs(output_path, exist_ok=True)
if(os.path.exists(output_path)==False):
os.makedirs(output_path)
moves = glob.glob("{}/*.mp4".format(input_path))
for move in moves:
basename = os.path.basename(move)
class_name = basename.split('_')[0]
cap = cv2.VideoCapture(move)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
frame_count = cap.get(cv2.CAP_PROP_FRAME_COUNT)
print("width:{} height:{} frames:{}".format(width, height, frame_count))
interval = int(frame_count / max)
counter = 0
while True:
counter += 1
# カメラ画像取得
_, frame = cap.read()
if(frame is None):
break
if(counter%interval != 0):
continue
# 縮小
frame = cv2.resize(frame, (int(width/2), int(height/2)))
# 矩形検出
rect = detect_rectangle(frame)
if(rect != None):
x, y, w, h = rect
# 切り取り
save_img = frame[y: y+h, x: x+w]
# 透過保存
img = create_transparent_image(save_img)
save_image(class_name, img)
# 表示
frame = cv2.rectangle(frame, (x, y), (x+w, y+h),(0,255,0),2)
# 画像表示
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
なお、出力されたPNGには、一部、影だけの画像が含まれてしまっています。これは、クロマキー処理した時、完全に黒にできなかった部分を、アヒルと間違って検出してしまっているためです。


この画像を、そのままにすると、データセットの精度が下がってしまいますので、手動になりますが、丁寧に削除する必要があります。
(4) 背景と合成してデータセット作成(Ground Thruth形式)
続いて、背景として準備した画像(もし、このモデルを使用する場面が決まっていれば、その背景と同じが一番良いと思う)の上に、先のPNG画像をランダム重ねて、データセット用の画像を生成します。PNG画像の外径が、そのままバウンディングイングボックスになりますので、併せてアノテーションデータとして保存します。
アヒルのサイズを変えながら、ランダムに重ねて行きますが、この時、少し、重なるものも入れることが重要です。これは、Traning時にアヒルの周り(背景)も学習するので、重なりの無いデータだけで学習してしまうと、出来上がったモデルが、重なりに弱くなってしまうためです。

ソースコードは、こちらです。 create_dataset.py
"""
変換と合成によりGround Truth形式のデータセットを作成する
"""
import json
import glob
import random
import os
import shutil
import math
import numpy as np
import cv2
from PIL import Image
MAX = 3000 # 生成する画像数
CLASS_NAME=["AHIRU"]
COLORS = [(0,0,175)]
BACKGROUND_IMAGE_PATH = "./dataset/background_images"
TARGET_IMAGE_PATH = "./dataset/output_png"
OUTPUT_PATH = "./dataset/output_ground_truth"
S3Bucket = "s3://ground_truth_dataset"
manifestFile = "output.manifest"
BASE_WIDTH = 200 # 商品の基本サイズは、背景画像とのバランスより、横幅を200を基準とする
BACK_WIDTH = 640 # 背景画像ファイルのサイズを合わせる必要がある
BACK_HEIGHT = 480 # 背景画像ファイルのサイズを合わせる必要がある
# 背景画像取得クラス
class Background:
def __init__(self, backPath):
self.__backPath = backPath
def get(self):
imagePath = random.choice(glob.glob(self.__backPath + '/*.jpg'))
return cv2.imread(imagePath, cv2.IMREAD_UNCHANGED)
# 検出対象取得クラス (base_widthで指定された横幅を基準にリサイズされる)
class Target:
def __init__(self, target_path, base_width, class_name):
self.__target_path = target_path
self.__base_width = base_width
self.__class_name = class_name
def get(self, class_id):
# 商品画像
class_name = self.__class_name[class_id]
image_path = random.choice(glob.glob(self.__target_path + '/' + class_name + '/*.png'))
target_image = cv2.imread(image_path, cv2.IMREAD_UNCHANGED)
# 基準(横)サイズに基づきリサイズ
h, w, _ = target_image.shape
aspect = h/w
target_image = cv2.resize(target_image, (int(self.__base_width * aspect), self.__base_width))
# ランダムに回転させて取り出す
mode = random.randint(0, 3)
if(mode == 0):
target_image = cv2.rotate(target_image, cv2.ROTATE_90_CLOCKWISE)
elif(mode == 1):
target_image = cv2.rotate(target_image, cv2.ROTATE_90_COUNTERCLOCKWISE)
elif(mode == 2):
target_image = cv2.rotate(target_image, cv2.ROTATE_180)
return target_image
# 変換クラス
class Transformer():
def __init__(self, width, height):
self.__width = width
self.__height = height
self.__min_scale = 0.3
self.__max_scale = 1
def warp(self, target_image):
# サイズ変更
target_image = self.__resize(target_image)
# ローテーション
mode = random.randint(0, 3)
if(mode == 0):
target_image = self.__rote(target_image, random.uniform(0, 30))
elif(mode == 1):
target_image = self.__rote(target_image, random.uniform(320, 360))
# 配置位置決定
h, w, _ = target_image.shape
left = random.randint(0, self.__width - w)
top = random.randint(0, self.__height - h)
rect = ((left, top), (left + w, top + h))
# 背景面との合成
new_image = self.__synthesize(target_image, left, top)
return (new_image, rect)
def __resize(self, img):
scale = random.uniform(self.__min_scale, self.__max_scale)
w, h, _ = img.shape
return cv2.resize(img, (int(w * scale), int(h * scale)))
def __rote(self, target_image, angle):
h, w, _ = target_image.shape
rate = h/w
scale = 1
if( rate < 0.9 or 1.1 < rate):
scale = 0.9
elif( rate < 0.8 or 1.2 < rate):
scale = 0.6
center = (int(w/2), int(h/2))
trans = cv2.getRotationMatrix2D(center, angle , scale)
return cv2.warpAffine(target_image, trans, (w,h))
def __synthesize(self, target_image, left, top):
background_image = np.zeros((self.__height, self.__width, 4), np.uint8)
back_pil = Image.fromarray(background_image)
front_pil = Image.fromarray(target_image)
back_pil.paste(front_pil, (left, top), front_pil)
return np.array(back_pil)
class Effecter():
# Gauss
def gauss(self, img, level):
return cv2.blur(img, (level * 2 + 1, level * 2 + 1))
# Noise
def noise(self, img):
img = img.astype('float64')
img[:,:,0] = self.__single_channel_noise(img[:,:,0])
img[:,:,1] = self.__single_channel_noise(img[:,:,1])
img[:,:,2] = self.__single_channel_noise(img[:,:,2])
return img.astype('uint8')
def __single_channel_noise(self, single):
diff = 255 - single.max()
noise = np.random.normal(0, random.randint(1, 100), single.shape)
noise = (noise - noise.min())/(noise.max()-noise.min())
noise= diff*noise
noise= noise.astype(np.uint8)
dst = single + noise
return dst
# バウンディングボックス描画
def box(frame, rect, class_id):
((x1,y1),(x2,y2)) = rect
label = "{}".format(CLASS_NAME[class_id])
img = cv2.rectangle(frame,(x1, y1), (x2, y2), COLORS[class_id],2)
img = cv2.rectangle(img,(x1, y1), (x1 + 150,y1-20), COLORS[class_id], -1)
cv2.putText(img,label,(x1+2, y1-2), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,255), 1, cv2.LINE_AA)
return img
# 背景と商品の合成
def marge_image(background_image, front_image):
back_pil = Image.fromarray(background_image)
front_pil = Image.fromarray(front_image)
back_pil.paste(front_pil, (0, 0), front_pil)
return np.array(back_pil)
# Manifest生成クラス
class Manifest:
def __init__(self, class_name):
self.__lines = ''
self.__class_map={}
for i in range(len(class_name)):
self.__class_map[str(i)] = class_name[i]
def appned(self, fileName, data, height, width):
date = "0000-00-00T00:00:00.000000"
line = {
"source-ref": "{}/{}".format(S3Bucket, fileName),
"boxlabel": {
"image_size": [
{
"width": width,
"height": height,
"depth": 3
}
],
"annotations": []
},
"boxlabel-metadata": {
"job-name": "xxxxxxx",
"class-map": self.__class_map,
"human-annotated": "yes",
"objects": {
"confidence": 1
},
"creation-date": date,
"type": "groundtruth/object-detection"
}
}
for i in range(data.max()):
(_, rect, class_id) = data.get(i)
((x1,y1),(x2,y2)) = rect
line["boxlabel"]["annotations"].append({
"class_id": class_id,
"width": x2 - x1,
"top": y1,
"height": y2 - y1,
"left": x1
})
self.__lines += json.dumps(line) + '\n'
def get(self):
return self.__lines
# 1画像分のデータを保持するクラス
class Data:
def __init__(self, rate):
self.__rects = []
self.__images = []
self.__class_ids = []
self.__rate = rate
def get_class_ids(self):
return self.__class_ids
def max(self):
return len(self.__rects)
def get(self, i):
return (self.__images[i], self.__rects[i], self.__class_ids[i])
# 追加(重複率が指定値以上の場合は失敗する)
def append(self, target_image, rect, class_id):
conflict = False
for i in range(len(self.__rects)):
iou = self.__multiplicity(self.__rects[i], rect)
if(iou > self.__rate):
conflict = True
break
if(conflict == False):
self.__rects.append(rect)
self.__images.append(target_image)
self.__class_ids.append(class_id)
return True
return False
# 重複率
def __multiplicity(self, a, b):
(ax_mn, ay_mn) = a[0]
(ax_mx, ay_mx) = a[1]
(bx_mn, by_mn) = b[0]
(bx_mx, by_mx) = b[1]
a_area = (ax_mx - ax_mn + 1) * (ay_mx - ay_mn + 1)
b_area = (bx_mx - bx_mn + 1) * (by_mx - by_mn + 1)
abx_mn = max(ax_mn, bx_mn)
aby_mn = max(ay_mn, by_mn)
abx_mx = min(ax_mx, bx_mx)
aby_mx = min(ay_mx, by_mx)
w = max(0, abx_mx - abx_mn + 1)
h = max(0, aby_mx - aby_mn + 1)
intersect = w*h
return intersect / (a_area + b_area - intersect)
# 各クラスのデータ数が同一になるようにカウントする
class Counter():
def __init__(self, max):
self.__counter = np.zeros(max)
def get(self):
n = np.argmin(self.__counter)
return int(n)
def inc(self, index):
self.__counter[index]+= 1
def print(self):
print(self.__counter)
def main():
# 出力先の初期化
if os.path.exists(OUTPUT_PATH):
shutil.rmtree(OUTPUT_PATH)
os.mkdir(OUTPUT_PATH)
target = Target(TARGET_IMAGE_PATH, BASE_WIDTH, CLASS_NAME)
background = Background(BACKGROUND_IMAGE_PATH)
transformer = Transformer(BACK_WIDTH, BACK_HEIGHT)
manifest = Manifest(CLASS_NAME)
counter = Counter(len(CLASS_NAME))
effecter = Effecter()
no = 0
while(True):
# 背景画像の取得
background_image = background.get()
# 商品データ
data = Data(0.1)
for _ in range(20):
# 現時点で作成数の少ないクラスIDを取得
class_id = counter.get()
# 商品画像の取得
target_image = target.get(class_id)
# 変換
(transform_image, rect) = transformer.warp(target_image)
frame = marge_image(background_image, transform_image)
# 商品の追加(重複した場合は、失敗する)
ret = data.append(transform_image, rect, class_id)
if(ret):
counter.inc(class_id)
print("max:{}".format(data.max()))
frame = background_image
for index in range(data.max()):
(target_image, _, _) = data.get(index)
# 合成
frame = marge_image(frame, target_image)
# アルファチャンネル削除
frame = cv2.cvtColor(frame, cv2.COLOR_BGRA2BGR)
# エフェクト
frame = effecter.gauss(frame, random.randint(0, 2))
frame = effecter.noise(frame)
# 画像名
fileName = "{:05d}.png".format(no)
no+=1
# 画像保存
cv2.imwrite("{}/{}".format(OUTPUT_PATH, fileName), frame)
# manifest追加
manifest.appned(fileName, data, frame.shape[0], frame.shape[1])
for i in range(data.max()):
(_, rect, class_id) = data.get(i)
# バウンディングボックス描画(確認用)
frame = box(frame, rect, class_id)
counter.print()
print("no:{}".format(no))
if(MAX <= no):
break
# 表示(確認用)
cv2.imshow("frame", frame)
cv2.waitKey(1)
# manifest 保存
with open('{}/{}'.format(OUTPUT_PATH, manifestFile), 'w') as f:
f.write(manifest.get())
main()
(5) YOLOv5のデータ形式に変換
上記のプログラムは、実は、Amazon SageMaker Ground Truthで使用する形式になってます。
個人的な都合で恐縮なのですが、過去の作業経緯から、データセットは、全て一旦、Ground Truthの形式に寄せておいて、利用に合わせて変換しているためです。

[Amazon SageMaker] オブジェクト検出におけるGround Truthを中心としたデータセット作成環境について
そして、YOLOv5形式へのコンバート用のプログラムです。
ソースコードは、こちらです。 convert_ground_truth_to_yolo5.py
"""
Ground Truth形式のデータセットをYolo用に変換する
"""
import json
import glob
import os
import shutil
# 定義
inputPath = './dataset/output_ground_truth'
outputPath = './dataset/yolo'
manifest = 'output.manifest'
# 学習用と検証用の分割比率
ratio = 0.8 # 80%対、20%に分割する
# 1件のJデータを表現するクラス
class Data():
def __init__(self, src):
# プロジェクト名の取得
for key in src.keys():
index = key.rfind("-metadata")
if(index!=-1):
projectName = key[0:index]
# メタデータの取得
metadata = src[projectName + '-metadata']
class_map = metadata["class-map"]
# 画像名の取得
self.imgFileName = os.path.basename(src["source-ref"])
self.baseName = self.imgFileName.split('.')[0]
# 画像サイズの取得
project = src[projectName]
image_size = project["image_size"]
self.img_width = image_size[0]["width"]
self.img_height = image_size[0]["height"]
self.annotations = []
# アノテーションの取得
for annotation in project["annotations"]:
class_id = annotation["class_id"]
top = annotation["top"]
left = annotation["left"]
width = annotation["width"]
height = annotation["height"]
self.annotations.append({
"label": class_map[str(class_id)],
"width": width,
"top": top,
"height": height,
"left": left
})
# 指定されたラベルを含むかどうか
def exsists(self, label):
for annotation in self.annotations:
if(annotation["label"] == label):
return True
return False
def store(self, imagePath, labelPath, inputPath, labels):
cls_list = []
for label in labels:
cls_list.append(label[0])
text = ""
for annotation in self.annotations:
cls_id = cls_list.index(annotation["label"])
top = annotation["top"]
left = annotation["left"]
width = annotation["width"]
height = annotation["height"]
yolo_x = (left + width/2)/self.img_width
yolo_y = (top + height/2)/self.img_height
yolo_w = width/self.img_width
yolo_h = height/self.img_height
text += "{} {:.6f} {:.6f} {:.6f} {:.6f}\n".format(cls_id,yolo_x,yolo_y,yolo_w,yolo_h)
# txtの保存
with open("{}/{}.txt".format(labelPath, self.baseName), mode='w') as f:
f.write(text)
# 画像のコピー
shutil.copyfile("{}/{}".format(inputPath, self.imgFileName),"{}/{}".format(imagePath, self.imgFileName))
# dataListをラベルを含むものと、含まないものに分割する
def deviedDataList(dataList, label):
targetList = []
unTargetList = []
for data in dataList:
if(data.exsists(label)):
targetList.append(data)
else:
unTargetList.append(data)
return (targetList, unTargetList)
# ラベルの件数の少ない順に並べ替える(配列のインデックスが、クラスIDとなる)
def getLabel(dataList):
labels = {}
for data in dataList:
for annotation in data.annotations:
label = annotation["label"]
if(label in labels):
labels[label] += 1
else:
labels[label] = 1
# ラベルの件数の少ない順に並べ替える(配列のインデックスが、クラスIDとなる)
labels = sorted(labels.items(), key=lambda x:x[1])
return labels
# 全てのJSONデータを読み込む
def getDataList(inputPath, manifest):
dataList = []
with open("{}/{}".format(inputPath, manifest), 'r') as f:
srcList = f.read().split('\n')
for src in srcList:
if(src != ''):
json_src = json.loads(src)
dataList.append(Data(json.loads(src)))
return dataList
def main():
# 出力先フォルダ生成
train_images = "{}/train/images".format(outputPath)
validation_images = "{}/valid/images".format(outputPath)
train_labels = "{}/train/labels".format(outputPath)
validation_labels = "{}/valid/labels".format(outputPath)
os.makedirs(outputPath, exist_ok=True)
os.makedirs(train_images, exist_ok=True)
os.makedirs(validation_images, exist_ok=True)
os.makedirs(train_labels, exist_ok=True)
os.makedirs(validation_labels, exist_ok=True)
# 全てのJSONデータを読み込む
dataList = getDataList(inputPath, manifest)
log = "全データ: {}件 ".format(len(dataList))
# ラベルの件数の少ない順に並べ替える(配列のインデックスが、クラスIDとなる)
labels = getLabel(dataList)
for i,label in enumerate(labels):
log += "[{}]{}: {}件 ".format(i, label[0], label[1])
print(log)
# 保存済みリスト
storedList = []
log = ''
# ラベルの数の少ないものから優先して分割する
for i,label in enumerate(labels):
log = ''
log += "{} => ".format(label[0])
# dataListをラベルが含まれるものと、含まないものに分割する
(targetList, unTargetList) = deviedDataList(dataList, label[0])
# 保存済みリストから、当該ラベルで既に保存済の件数をカウントする
(include, notInclude) = deviedDataList(storedList, label[0])
storedCounst = len(include)
# train用に必要な件数
# count = int(label[1] * ratio) - storedCounst
count = int((len(dataList)* ratio))
log += "{}:".format(count)
# train側への保存
for i in range(count):
data = targetList.pop()
data.store(train_images, train_labels, inputPath, labels)
storedList.append(data)
# validation側への保存
log += "{} ".format(len(targetList))
for data in targetList:
data.store(validation_images, validation_labels, inputPath, labels)
storedList.append(data)
dataList = unTargetList
log += "残り:{}件".format(len(dataList))
print(log)
main()
変換されたデータセットは、以下のような形になります。 画像は、3,000枚、アノテーションは、20,000件ぐらいで、8:2で学習・検証用に分割されています。
data.yaml
train: yolo_data/train/images val: yolo_data/valid/images nc: 1 names: ["AHIRU"]
(venv)$ tree ./yolo_data/
./yolo_data/
├── data.yaml
├── train
│ ├── images
│ │ ├── 00600.png
│ │ ├── 00601.png
・・・略・・・
│ │ ├── 02998.png
│ │ └── 02999.png
│ ├── labels
│ │ ├── 00600.txt
│ │ ├── 00601.txt
・・・略・・・
│ │ ├── 02998.txt
│ │ └── 02999.txt
│ └── labels.cache
└── valid
├── images
│ ├── 00000.png
│ ├── 00001.png
・・・略・・・
│ ├── 00598.png
│ └── 00599.png
├── labels
│ ├── 00000.txt
│ ├── 00001.txt
・・・略・・・
│ ├── 00598.txt
│ └── 00599.txt
└── labels.cache
6 directories, 6004 files
3 学習
ここまで、Macで作業してきましたが、ここからは、Jetsonで進めます。
(1) cuda.is_available()
最初に書いた通り、Jetson上では、PyTorchをpipでインストールしてしまうと、GPUが認識されませんが、Nvidiaのページには、用意されたモジュールをセットアップする手順が案内されています。
Installing PyTorch for Jetson Platform
2023/04/15現在、ダウンロードできるのは、v1.14とv2.0のようです。

また、セットアップ済みのDockerイメージも用意されています。
NVIDIA L4T PyTorch
Traningには、今回、Dockerイメージの方を使用しました。
$ sudo docker pull nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3 $ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE nvcr.io/nvidia/l4t-pytorch r35.2.1-pth2.0-py3 853b58c1dce6 2 months ago 11.7GB $ sudo docker run -it --rm --runtime nvidia --shm-size=1g -v /home/sin/work3:/home --network host nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3 #
Dockerイメージでは、PyTorch2.0に合わせて、torchaudio及び、torchvisionもインストールされています。
# pip list | grep torch torch 2.0.0a0+ec3941ad.nv23.2 torchaudio 0.13.1+b90d798 torchvision 0.14.1a0+5e8e2f1
そして、GPU及び、OpenCVも利用可能となっています。
# python3 -c 'import torch;print(torch.cuda.is_available())' True # python3 -c 'import cv2;print(cv2.__version__)' 4.5.0
(2) OpenCV
YOLOv5は、Gihubからダウンロードして使用します。
$ git clone https://github.com/ultralytics/yolov5 $ cd yolov5 $ pip install -r requirements.txt
ここで、注意なのですが、実は、DockerイメージでセットアップされているOpenCVは、pipでインストールされたものでは無いため、cloneしたrequirements.txtを使用してしまうと、競合してうまく動作できません。
pip install する前に、requirements.txtのopencvの行を無効化しておいてください
$ grep open requirements.txt #opencv-python>=4.1.1
(3) Traning
作成したデータセットを作業ディレクトリの中のyolo_dataに配置し、学習を開始します。
$ python train.py --data yolo_data/data.yaml --cfg yolov5s.yaml --weights '' --batch-size 8 --epochs 300
今回用意したデータセットでは、1Epochが、2分程度でした。

jtopコマンドで確認すると、GPUが使われていることを確認できます。


出来上がったモデルは、14Mbyte程度でした。
$ ls -la weights/ -rw-r--r-- 1 root root 14386045 Apr 10 10:15 best.pt -rw-r--r-- 1 root root 14386045 Apr 10 10:15 last.pt
results.csvの抜粋
epoch, metrics/mAP_0.5, metrics/mAP_0.5:0.95,
0, 0.059469, 0.014931,
1, 0.52676, 0.22932,
2, 0.94052, 0.56556,
・・・略・・・
297, 0.995, 0.97299,
298, 0.995, 0.97284,
299, 0.995, 0.97298,

4 推論
ちょっと、Docker上からGUIのカメラを使用すると、解像度がうまく操作できなくて、ここでは、requirements.txtからライブラリをインストールして使用しています。
python -m venv venv source venv/bin/activate (venv) $ pip install -r requirements.txt (venv) $ pyton3 index.py

USBカメラの画像で推論して表示するコードは以下のとおりです。 ちょっと気をつけないといけないのは、モデルのRGBとOpenCVのRBGの順序が違うので、合わせてから推論しないと、うまく検出できないことす。
ソースコードは、こちらです。 index.py
import torch
import cv2
import numpy as np
model = torch.hub.load('.', 'custom', path='./runs/train/exp/weights/best.pt', source='local')
model.conf = 0.85
colors = {
0: (0,0,255),
1: (255,0,255)
}
names = {
0: "AHIRU",
1: "unknown"
}
cap = cv2.VideoCapture(0)
if cap.isOpened() is False:
raise IOError
while(True):
try:
ret, img = cap.read()
if ret is False:
raise IOError
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = model(img)
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
for obj in results.pred[0]:
x1, y1, x2, y2, conf, cat = obj.numpy()
x1, y1, x2, y2, cat = int(x1), int(y1), int(x2), int(y2), int(cat)
print(x1, y1, x2, y2, conf, cat)
if conf > 0.581 and cat in colors.keys():
cv2.rectangle(img, (x1, y1), (x2, y2), colors[cat], 2)
cv2.putText(img, f'{names[cat]},{conf:.2f}', (x1, y1-8), cv2.FONT_HERSHEY_PLAIN, 1.5, colors[cat], 2, 2)
print(results)
cv2.imshow('YOLO', img)
cv2.waitKey(1)
except KeyboardInterrupt:
break
cap.release()
cv2.destroyAllWindows()
5 最後に
今回は、Jetson AGX OrinでYOLOv5のモデルを作成してみました。
紹介させて頂いた、クロマキー処理や、背景と合成することデータセットを作成する手法は、以下のブログで紹介したものと同じです。
非常に細かいですが、色々とノウハウが溜まったので、今回、改めてまとめさせて頂きました。 長文にお付き合い頂き、ありがとうございます。
6 参考リンク
【動画あり】早速YOLOv8を使って自作データセットで物体検出してみた
YOLOv7の実装を理解する(YOLOv7のコードを読んでみた)
[Amazon SageMaker] 画像合成によるデータセット作成時における背景の扱いについて