
分析ワークフローのためのフォーマット「PFA」を知る
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
データ分析の際の開発フェーズでは考えうる多くの分析手法、予測手法を試し、フィードバックをすぐに得るようなプロセスを経て、求められるような結果が得られれば本番環境の予測エンジン等に適用されます。
開発環境の際に用いられた前処理、分析手法、予測手法は開発環境に特有のフレームワーク、言語ではうまく動いているかもしれません。しかしいざそれが本番環境に特有のフレームワーク、言語になったときに、単一の処理に対する記述の違いから、開発環境では生じることがなかったクラッシュにつながったり、スケールアップが上手くいかなかったり、エラーが出たりします。
例えばPythonでローカルないし単一のホスト環境で動かすことを前提に作成した前処理スクリプトを他のHadoopのような分散環境で動かす場合を考えてみます。この場合、分散環境でPythonが動かせる環境であればそのまま前処理スクリプトを移行できますが、なんらかの制約によって分散環境でJVMで動く言語しか扱えない場合、新たにJavaの前処理コードを書き直す必要があります。
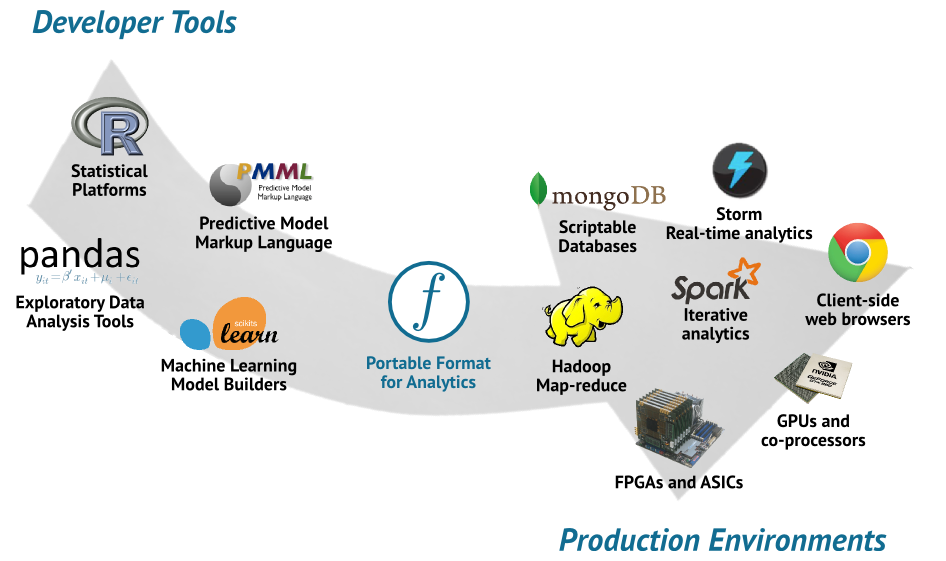 (
(PFA(Portable Format for Analytics)はこのような開発環境から本番環境への移行をスムーズに行うためのデータ分析向け共通言語(DSL)です。
PFA
PFAはローカル、ないしリモートの大規模分散環境におけるパイプラインの機能を抽象化します。つまり、言語や環境に依存しないパイプライン機能を持ったコードを記述出来ます。
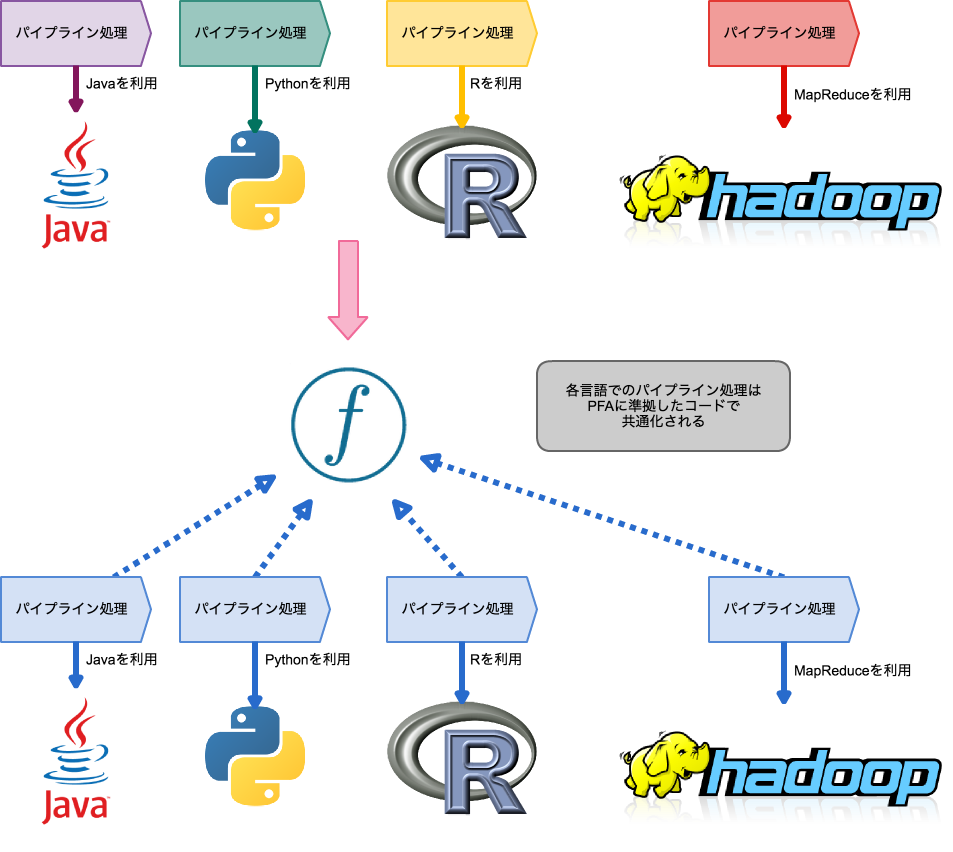
PFAそれ自体はそのコードが動作する環境の変数にアクセスしたり操作する権限を持たないため、本番環境を散らかさずにすみます。パイプライン処理で用いられる前処理やアルゴリズムの数学的な正しさを検証することに集中できます。
このような関心事の分離はパイプライン処理でよく行われるモデルの変更が実際のフレームワークの進歩のスピードと比較して速い速度でなされるために、価値があります。分析・予測向けのモデルはデータ分析の対象を探求する過程でしばし調整され、新しい訓練サンプルによって大幅に変更が加えられる可能性があるためです。
PFAではこのようなパイプライン処理の単位としてScoring engineという概念を導入しています。Scoring engineは機械学習における分類器や回帰予測器、それから入力を平滑化したりフィルタリングするパイプラインも内包しています
PFAを扱う各ライブラリではPFA Documentに準拠したJsonからScoring engineを生成するインターフェイスが用意されています。PFA Documentは入力と出力、及び入力からどのように出力に変換するかを定めるアクションで構成され、Jsonやyaml等で記述を行えます。
その他にもPFAの持つ特徴を列挙すると次のようになります。
- JSONで完全に表現できます。それ故他のプログラムによって簡単に生成、操作可能です。
- 条件分岐、ループ、ユーザ定義関数といった制御構造を定義出来ます。
- 豊富なライブラリ関数があり、ライブラリ関数には機能拡張のためのコールバックを定義できます。
- 言語等のプラットフォームに依らず、同じ入力に対しては同じ出力が得られます。
- 型は静的にチェックされます。Null値も型で安全に扱え、型でレコードを扱うため、欠損値がランタイムエラーを起こすことが無いです。
まずは実際の動作サンプルを確認するために、PFAに準拠したパイプライン処理を行うPythonライブラリであるTitusで動くコードをサラッと見ていきます。Titus自体は以下のGithubリポジトリで管理されています。
opendatagroup/hadrian - Github
コードのサンプル
環境構築にあたってはpyenv等を利用してanaconda-4.0.0をインストールします。
環境情報
- anaconda-4.0.0
anacondaをインストールした後はpipを用いてtitusパッケージを環境にインストールします。
$ pip install titus
データ分析の対象データとしておなじみのIrisデータ・セットを利用します。リンク先のデータをanacondaが実行できる環境にiris.csvというファイルとして置きます。
iris.csv
sepal_length_cm,sepal_width_cm,petal_length_cm,petal_width_cm,class 5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa ....
同じディレクトリでjupyter notebookを起動し、
$ jupyter notebook
以下のコードをうちます。
from titus.genpy import PFAEngine
import csv
pfaDocument = {
"input": {"type": "record",
"name": "Iris",
"fields": [
{"name": "sepal_length_cm", "type": "double"},
{"name": "sepal_width_cm", "type": "double"},
{"name": "petal_length_cm", "type": "double"},
{"name": "petal_width_cm", "type": "double"},
{"name": "class", "type": "string"}
]},
"output": "string",
"action": [
{"if": {"<": ["input.petal_length_cm", 2.5]},
"then": {"string": "Iris-setosa"},
"else":
{"if": {"<": ["input.petal_length_cm", 4.8]},
"then": {"string": "Iris-versicolor"},
"else":
{"if": {"<": ["input.petal_width_cm", 1.7]},
"then": {"string": "Iris-versicolor"},
"else": {"string": "Iris-virginica"}}
}
}
]}
engine, = PFAEngine.fromJson(pfaDocument)
dataset = csv.reader(open("iris.csv"))
fields = dataset.next()
numCorrect = 0.0
numTotal = 0.0
for datum in dataset:
asRecord = dict(zip(fields, datum))
if engine.action(asRecord) == asRecord["class"]:
numCorrect += 1.0
numTotal += 1.0
print "accuracy", numCorrect/numTotal
コードの概要を見ていきます。
l1
titusパッケージはPythonでPFAを扱うためのライブラリです。まずはこちらをインポートします。
l4-l27
PFAフォーマットのJsonから花の種類の分類のためのエンジンを作っています。Jsonの内容をもう少し詳しく見ていきましょう。
- input: PFAドキュメントの入力に相当する部分を定義します。ここでは、入力の型、名前、フィールドの名前と型を指定しています。
- output: PFAドキュメントの出力に相当する部分を定義します。ここでは出力の型として文字列を指定しています。
- action: 入力からどのような操作を行なって出力に変換するかを記述します。内部には制御構造としてif elseが用いられ、petal_length, petal_width を用いてどのような花の種別かを返却するロジックが記述されています。
PFAフォーマットはJsonの他にもPrettyPfaと呼ばれるPFAをより簡易に記述できるようにした形式やyamlをサポートしています。
l28
PFAフォーマットで記述されたJson形式の辞書を元に判別のためのエンジンを作成しています。今回はタプルの2つ目以降を無視していますが、fromJson 自体はPFAドキュメントからScoring Engineのリストを生成するため、必要に応じてタプルの二つ目以降の返り値を用いれます。
l30, 31
Irisデータ・セットを表すCSVファイルからデータセットを読み込み、ヘッダに書かれているフィールドのリストをfields変数に展開しておきます
l33-l39
先ほど生成されたScoring EngineにasRecordを入力して結果を取得、正解率を取得するためにデータ数の合計と、正解データ数の合計を集計しています。
l41
正答率を出力します。
現在PFAを扱っている他のライブラリ群
Titusが置かれたレポジトリには他にもJavaやRでPFAを扱うためのライブラリが管理されています。
- Hadrian : JVM環境でのPFAを扱うライブラリ
- Aurelius : RでPFAを扱うためのライブラリ
蛇足ですが、歴代ローマ皇帝が名前のモチーフになっていそうですね。
まとめ
今回はPFAの紹介を行い、概要をつかむためにPythonのPFAライブラリであるTitusを用いてIrisデータの分類器を作成してみました。PFAには豊富なライブラリ関数群があるので、折にふれてそれらも紹介できればと思っています。






