
Spring Boot + MicrometerでCloudWatch Metricsに送るべきメトリクスと設定方法
Spring Boot でよく利用される Micrometer ですが、Amazon CloudWatch Metrics にメトリクスをエクスポートするための Micrometer CloudWatch Exporter というライブラリがあります。
これを使うと、Micrometer で収集したメトリクスをカスタムメトリクスとしてCloudWatch Metrics に送信することができます。
ただ、CloudWatch Metrics のカスタムメトリクスは、メトリクスの種類とタグごとに料金が発生するため、何も考えず全部を有効化してしまうとコストが膨れ上がります。複数のインスタンス/コンテナをスケールアウトして個別のメトリクスを登録する場合は、さらにコストが増加します。
今回は、主要なメトリクスの選定、各メトリクスの意味や判断の仕方、またそれらの設定方法などをまとめてみました。
想定環境は以下の通りです。
- Kotlin
1.9.25 - JVM:
amazon-corretto-17.0.17.10.1 - Spring Boot
3.5.12 - Infra構成: ALB -> ECS Fargate (2インスタンス) -> Amazon Aurora MySQL
CloudWatch Metricsのカスタムメトリクスの料金
料金体系
カスタムメトリクスは 「メトリクス名 × ディメンションの組み合わせ」1つ を1メトリクスとして月次で課金されます。
同じメトリクス名でも、ディメンションの組み合わせが異なれば別のメトリクスとしてカウントされるため、注意が必要です。
| Tiers | Cost (metric/month) |
|---|---|
| 最初の 10,000 metrics | USD 0.30 |
| 次の 240,000 metrics | USD 0.10 |
| 次の 750,000 metrics | USD 0.05 |
| それ以上 1,000,000 metrics | USD 0.02 |
※2026年3月時点の東京リージョンの料金です。最新の料金は公式サイトを確認してください。
なので、例えば一般的なECSコンテナで稼働するSpringBootのMVCアプリケーションで何も考えずにmicrometerでカスタムメトリクスを登録しようとすると、インスタンス台数: 2台 (Multi-AZ構成) × メトリクス数: 50-100 (タグの組み合わせも考慮して概算) = 100-200メトリクス/月で、ざっくりと$0.3 × 100-200 = $30-60/月 くらいになります。
これに加え、コンテナIDなどをディメンションに含めている場合は、デプロイ時のタスク入れ替えごとに新しいディメンションの組み合わせが生まれメトリクス数が増える点にも注意が必要です。なので、例えば月5回のデプロイでタスク入れ替えが発生する場合、その分新しいメトリクスが増えるため、$150-300/月 くらいになります。
支配的なのはメトリクス数なので、メトリクスの種類やタグの組み合わせを絞ることが重要です。
また、今回は割愛しましたが、PutMetricDataなどのAPIの呼び出し回数に応じた料金も発生します。
メトリクスの選定
長時間観察しないとわからないJVMのGCや障害の調査に役立つconnection poolのメトリクスなどは、常に有効化しておくのが良さそうです。また、AWSを利用する場合は、クラウド側の設定でCPUやMemoryなどメトリクスはある程度取得できるので、Micrometer側での収集は省略できます。
選定にはAIと相談して下記を有効にしました。それぞれのメトリクスの判断の仕方は後述します。
| 系統 | メトリクス | 説明 |
|---|---|---|
| GC系 | jvm.gc.pause.count | GC回数 |
| GC系 | jvm.gc.pause.sum | GCで止まった合計時間 |
| GC系 | jvm.gc.pause.max | 最大停止時間 |
| GC系 | jvm.gc.pause.avg | 平均時間 |
| GC系 | jvm.gc.overhead.value | GCオーバーヘッド |
| GC系 | jvm.gc.live.data.size.value | GC後に生き残るデータ量 (リークのシグナル) |
| GC系 | jvm.gc.max.data.size.value | Old Gen の上限サイズ |
| メモリ系 | jvm.memory.used.value | heap の 利用量(リークが見える) |
| メモリ系 | jvm.memory.max.value | heap max(上限) |
| スレッド系 | jvm.threads.live.value | 現在生存しているスレッドの総数 |
| スレッド系 | jvm.threads.daemon.value | デーモンスレッドの数 |
| スレッド系 | jvm.threads.peak.value | JVM起動後のスレッド数ピーク値 |
| CP系 | hikaricp.connections.active.value | 使用中のコネクション数 |
| CP系 | hikaricp.connections.pending.value | 待機中のスレッド数 |
| CP系 | hikaricp.connections.timeout.count | タイムアウトした回数の累計 |
| CP系 | hikaricp.connections.max.value | プールの最大設定数 |
GC系のメトリクス
GCは、Javaのヒープメモリを管理するための仕組みで、不要になったオブジェクトを自動的に回収します。
GCの各メトリクスを把握することで、アプリケーションのメモリ管理の状態を理解し、パフォーマンスの問題やメモリリークの兆候を早期に検知できます。
また、今回の JVM は Amazon Corretto 17 で、GC はデフォルトの G1 GC(Garbage-First Garbage Collector) を使っています。G1 は 世代別 かつ region ベース の GC で、ヒープを Young 領域と Old 領域 に分けつつ、内部的には多数の region に区切って管理する方式を取っています。若いオブジェクトを主に回収する young GC を高頻度で回し、必要になると並行してOld領域のマーキングを行い、Old領域の回収も行うというのが基本的なサイクルになります。
メトリクスの理解にあたっては、まず下記のG1 GCの基本的な概念を押さえておくとわかりやすいです。
G1GCの基本概念
ヒープ領域の構成
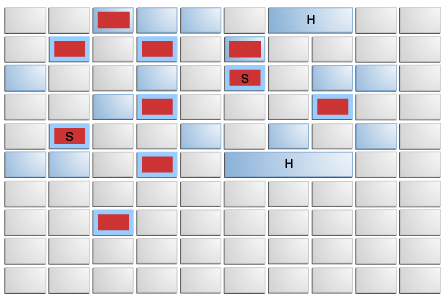
- Young Gen
- eden space: 新しいオブジェクトが最初に割り当てられる領域 (図の赤い部分)
- survivor space: eden space から生き残ったオブジェクトが移される領域 (図のSという文字が書かれた赤い部分)
- Old Gen
- old space: 長期間生き残ったオブジェクトが移される領域 (図の青い部分)
G1GC のサイクル
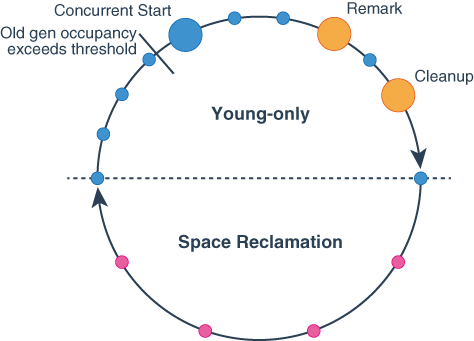
- Young-only phase
- Normal Young GC (STW)
- Young 領域 (eden + survivor) のみを回収する
- 生存オブジェクトは Survivor または Old へ evacuation(コピー)する
- 基本的にはこの Young GC を繰り返す
- Concurrent Start Young GC
- Old 領域の使用率がしきい値に達すると、次の Young GC がこれになる
- Young GC をしながら、Old 領域に対する concurrent marking を開始する
- Concurrent Marking
- アプリケーションと並行して、Old 領域の live object のliveness(生存) 情報を収集する
- この情報は、後続の Space-reclamation phase でどの Old region を回収候補にするか決めるために使われる
- Remark Phase (STW)
- STW で marking の最終調整を行う
- concurrent marking でmarkingできなかったオブジェクトをmarkingする
- この時点で、次の Cleanup phase で回収する Old 領域が決まる
- Cleanup Phase (STW)
- marking 結果を使って、次に回収すべき Old region を整理し、Space-reclamation phase に進むかを決める
- Space-reclamation phase に進む場合、その前に一度Normal Young GCを行う
- Normal Young GC (STW)
- Space-reclamation phase
- Mixed GC (STW)
- Young 領域に加えて、回収効率の高い Old 領域も回収する
- Old 内の live object を別 region に evacuationしてfragmentationを解消する
- これ以上 Old region を回収しても効率が悪いと判断したら終了
- その後、再び Young-only phase に戻る
- Mixed GC (STW)
- その他
- Full GC (STW)
- 通常サイクルで回収しきれない場合の最後の手段
- 例: アプリケーションが liveness 情報の収集中にメモリ不足(
OutOfMemoryError)になった場合、その場で STW の Full GC を行う
- 例: アプリケーションが liveness 情報の収集中にメモリ不足(
- ヒープ全体を対象に不要オブジェクトを回収し、evacuationを行ってヒープのfragmentationを解消する
- 通常サイクルで回収しきれない場合の最後の手段
G1GCの種類
| GC | 説明 |
|---|---|
| Young GC (= Minor GC) | Young 領域(Eden + Survivor)のみを回収。同時にOld領域のconcurrent markingも開始する。最も頻繁に発生するGC |
| Mixed GC | Young GCに加えて、回収効率の高い Old領域も回収する |
| Full GC (= Major GC) | ヒープ全体を対象とした STW な GCで、GCの中でも最も重い処理。 |
- jvm.gc.pause.count
- 意味:GCによってアプリケーションが停止した回数の累計
- 詳細: マイナーGC(若い世代の掃除)やフルGC(全体の掃除)など、すべてのGCイベントで停止した回数をカウントします。
- チェックポイント: この回数が急激に増えている場合、メモリの割り当てと解放が非常に頻繁に行われていることを示します。
- jvm.gc.pause.sum
- 意味:GCによるアプリケーション停止時間の「合計値」
- 詳細: アプリケーションが起動してから、GCのために停止していた時間の総和です。
- チェックポイント: 合計時間が長いほど、スループット(単位時間あたりの処理量)が低下していることを意味します。
- jvm.gc.pause.max
- 意味:GCによる1回あたりの「最大停止時間」
- 詳細: これまで発生したGCの中で、最も長くアプリケーションを止めてしまった時間の値です。
- チェックポイント: いわゆる**「最悪のレスポンス遅延」**の原因を特定するのに役立ちます。例えば、Webアプリで「たまに数秒間無反応になる」といった現象がある場合、この max の値が跳ね上がっていることが多いです。
- jvm.gc.pause.avg
- 意味:GCによるアプリケーション停止時間の「平均値」
- 詳細:
jvm.gc.pause.sum / jvm.gc.pause.countから算出される派生値です。Micrometer の Timer が内部的に保持する統計値であり、CloudWatch Exporter の実装バージョンによっては送信されない場合もあります。 - チェックポイント: 平均値が長い場合、GCが頻繁に発生しているか、あるいはGCの処理自体が重い可能性があります。特に、平均値が数百ミリ秒を超えるような場合は、ユーザー体験に悪影響を与える可能性があるため、注意が必要です。
- jvm.gc.overhead.value
- 意味:GCに費やされている時間の割合(GCオーバーヘッド)
- 詳細: 全実行時間のうち、どの程度がGCの処理に占有されているかを示す割合です(通常はパーセントや0〜1の範囲で表されます)。
- チェックポイント: この値が高い(例:10%を超えるなど)場合、「CPUが本来のビジネスロジックではなく、メモリ掃除ばかりに忙殺されている」状態です。オーバーヘッドがあまりに高くなり(98%以上など)、メモリが解放できない状態が続くと OutOfMemoryError が発生します。
- jvm.gc.live.data.size.value
- 意味: GC後に生き残るOld Gen領域のデータ量
- 詳細: 「掃除しても残った=アプリケーションがずっと使い続けている常駐データ」の量です。
- チェックポイント: この底辺の値がじわじわ上がっているなら、キャッシュが肥大化しているか、どこかでメモリリークが発生している可能性があります。
- jvm.gc.max.data.size.value
- 意味:Old Gen領域が物理的に持てる「最大サイズ」
- 詳細: jvm.memory.max.value(ヒープ全体の上限)のうち、Old Genに割り当て可能な最大枠です。
- チェックポイント:
live.data.sizeがこの max.data.size に近づいてくると、新しいオブジェクトを Old Gen に入れる隙間がなくなり、頻繁に重いGCが発生するようになります。
メモリ系のメトリクス
JVMのメモリ使用状況を把握するためのメトリクスです。
前述のGCの挙動と組み合わせて見ることで、OOMやリークの兆候を早期に検知できます。
- jvm.memory.used.value
- 意味:現在、実際に使用されているメモリ量(バイト単位)
- 詳細: このメトリクスは
areaタグ(heap/nonheap)とidタグ(Eden Space,Survivor Space,Old Gen,Metaspaceなど)の組み合わせで、メモリプールごとに個別のメトリクスとして送信されます。heap の used が右肩上がりで増え続け、GC後も下がらない状態をメモリリークと呼びます。 - チェックポイント: heap 全体の値はGCのたびに激しく上下するのが正常で、グラフが「ノコギリの刃」のような形をしていれば健康的です。特に
id=G1 Old Genの used が増え続けていないかを重点的に確認してください。
- jvm.memory.max.value
- 意味:JVMが使用を許可されているメモリの「最大上限値」
- 詳細: Javaの起動オプション -Xmx で指定した値に相当します。
- チェックポイント: used がこの max に近づくと、JVMはGCを繰り返してメモリを作ろうとします。その結果、先ほどの
jvm.gc.overheadが跳ね上がり、最終的にOutOfMemoryErrorでFull GCが発生し、アプリが落ちる可能性があります。
スレッド系のメトリクス
JVMのスレッドの状態を把握するためのメトリクスです。
スレッドリークや過剰なスレッド生成の兆候を検知できます。ちなみに、JVMのスレッドは、OSのネイティブスレッドと1対1で対応しているため、スレッド数が増えるとOSのリソースも圧迫されます。スレッドリークが発生すると、最終的には新しいスレッドを作成できなくなり、OutOfMemoryError: unable to create new native thread というエラーが発生します。
- jvm.threads.live.value
- 意味:現在生存している(終了していない)スレッドの総数
- 詳細: デーモンスレッドと非デーモンスレッドの両方を含みます。
- チェックポイント: この値が右肩上がりに増え続けている場合、スレッドリーク(処理が終わってもスレッドが破棄されない状態)が発生している可能性があります。リソースを食いつぶし、最終的に
OutOfMemoryError: unable to create new native threadを引き起こします。
- jvm.threads.daemon.value
- 意味:現在生存している「デーモンスレッド」の数
- 詳細: デーモンスレッドとは、メインの処理(非デーモン)をバックグラウンドでサポートするスレッド(例:GC用スレッドなど)です。メインスレッドがすべて終了すると、デーモンスレッドは自動的に終了します。
- チェックポイント:
live数との差分を見ることで、アプリケーション固有のビジネスロジックを実行しているスレッド(非デーモン)がどれくらいあるかを逆算できます。
- jvm.threads.peak.value
- 意味:JVM起動後、スレッド数が最大に達した時の記録(ピーク値)
- 詳細: アプリケーションが動いてきた中で、最もスレッドが必要だった瞬間の数です。
- チェックポイント: 瞬間的な負荷スパイクがどの程度だったかを把握するのに役立ちます。もし現在の live 数が落ち着いていても、peak が異常に高い場合は、過去に一時的に大量のスレッドが生成されたことがわかります。
コネクションプール系のメトリクス
こちらはデータベースのコネクションプールのメトリクスです。
今回は、Spring Boot でデフォルトのコネクションプールである HikariCP のメトリクスを例に挙げます。DBへの接続まわりのパフォーマンスや障害の調査に非常に役立つため、優先的に有効化しておくべきメトリクスの一つです。
- hikaricp.connections.active.value
- 意味:現在、アプリケーションによって「使用中」のコネクション数
- 詳細: スレッドが
getConnection()して、まだclose()していない状態の数です。 - チェックポイント: この値が常に max に張り付いている場合、処理が追いついていないか、コネクションリークの可能性があります。
- hikaricp.connections.pending.value
- 意味:コネクションを借りるために「待機している」スレッド数
- 詳細: プールに空きがないため、新しいコネクションを求めて順番待ちをしているスレッドの数です。
- チェックポイント: 0より大きい値が頻発しているなら、スレッドがDB接続待ちでブロックされており、ユーザーへのレスポンス遅延に直結しています。
- hikaricp.connections.timeout.count
- 意味:コネクション取得に失敗(タイムアウト)した回数の累計
- 詳細: pending 状態で待ち続けた結果、設定された connectionTimeoutを超えてしまい、エラーになった回数です。
- チェックポイント: これがカウントアップされている場合、「一部の処理が失敗している」という危険な状態です。プールの最大数を増やすか、クエリを高速化する必要があります。
- hikaricp.connections.max.value
- 意味:プールできるコネクションの「最大設定数」
- 詳細:
maximumPoolSizeで設定した値そのものです。 - チェックポイント: プールサイズの上限なので、active がこの max に近づいていると、pending や timeout が発生しやすくなります。
設定方法
TL;DR
こちらのリポジトリにコードを置いています。
設定方法
micrometer-registry-cloudwatch を依存に追加
application.yml に CloudWatch Exporter の設定を追加
登録するメトリクスをフィルタする
その他 (補足)
- DBコネクションプールのメトリクスについて
Multi-AZで複数台のDBインスタンスを利用している様な環境の場合は、データソース(writer/reader)ごとにコネクションプールのメトリクスが出るように設定するのが望ましいのですが、ここらへんは利用しているドライバーやコネクションプールの実装に依存するので、今回は割愛します。
ちなみにプロジェクトでは、aws-advanced-jdbc-wrapper を使っており、内部PoolのHikariCPのメトリクスを Micrometer に出すために MicrometerMetricsTrackerFactory で登録をしています。
Driver.setCustomConnectionProvider(
HikariPooledConnectionProvider { hostSpec, _ ->
val config = HikariConfig()
...
config.poolName = "hikari-${hostSpec.role.name.lowercase()}-${hostSpec.host}"
config.metricsTrackerFactory = MicrometerMetricsTrackerFactory(meterRegistry)
return@HikariPooledConnectionProvider config
},
)
- タグの組み合わせについて
例えば jvm.gc.pause に action / cause / gc の3タグが付いていると、その組み合わせ分だけメトリクス数が増えます。MicrometerのデフォルトではGC系メトリクスにこれらのタグが自動付与されるため、そのまま送ると想定より多くのメトリクスが生成されます。
下記のようにフィルタでタグを削除することで、メトリクス数を抑えることができますが、正直ここらへんを絞るべきかは悩みどこだったので、今回は割愛しています。
@Configuration
class MicrometerConfig {
@Bean
fun dropJvmGcPauseTags(): MeterFilter {
return MeterFilter.ignoreTags("action", "cause", "gc")
}
}
登録されたメトリクスの一部紹介
参考までに、CloudWatch Metrics に登録されたメトリクスの一部を紹介します。グラフの見方や、どのような状態のときにどのような値になるのかなども簡単に解説します。
GC系
- 1コンテナの
jvm.gc.pause.avgのグラフ
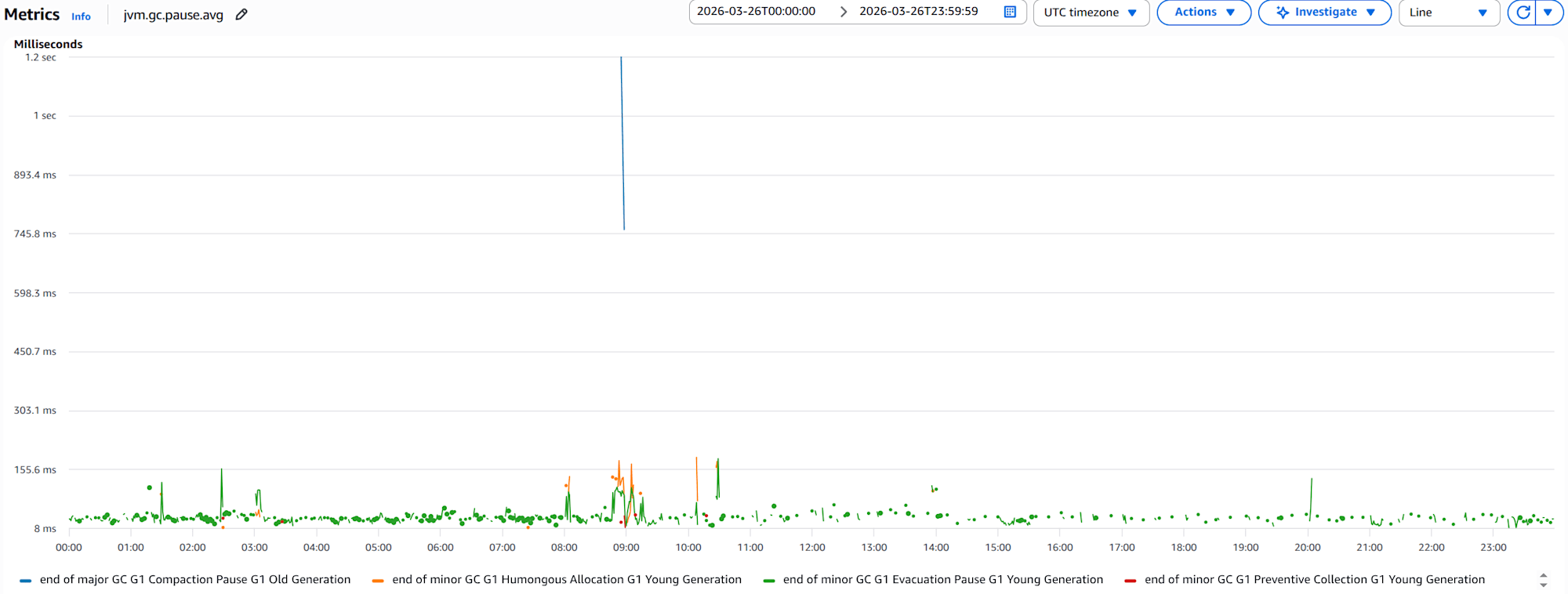
注目すべきは、major GC - G1 Compaction Pause - G1 Old Generation で、GCの平均停止時間が1秒を超えている箇所です。これは、Old Genの回収で1秒以上アプリケーションが停止していることを意味します。ユーザー体験に大きな影響を与える可能性があります。
メモリ系
- 1コンテナの
jvm.memory.used.valueとjvm.memory.max.valueのグラフ
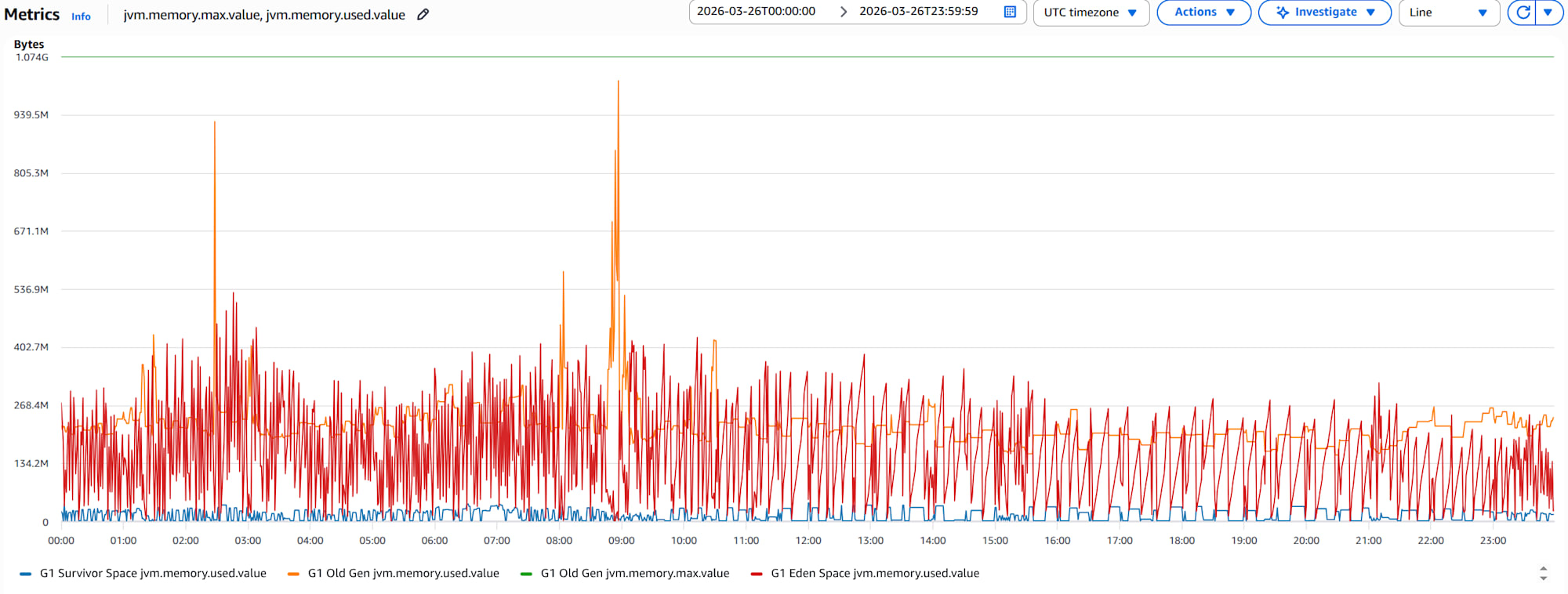
各領域のメモリが徐々に増えつづけているわけではないので、リークの可能性は低そうです。時々Old Genの used が max に近づいている瞬間がありますが、これが頻発していると、GCオーバーヘッドが増え、最悪の場合は OutOfMemoryError でFull GCが発生し、アプリが落ちる可能性があります。
スレッド系
- 1コンテナの
jvm.threads.live.valueとjvm.threads.daemon.valueとjvm.threads.peak.valueのグラフ
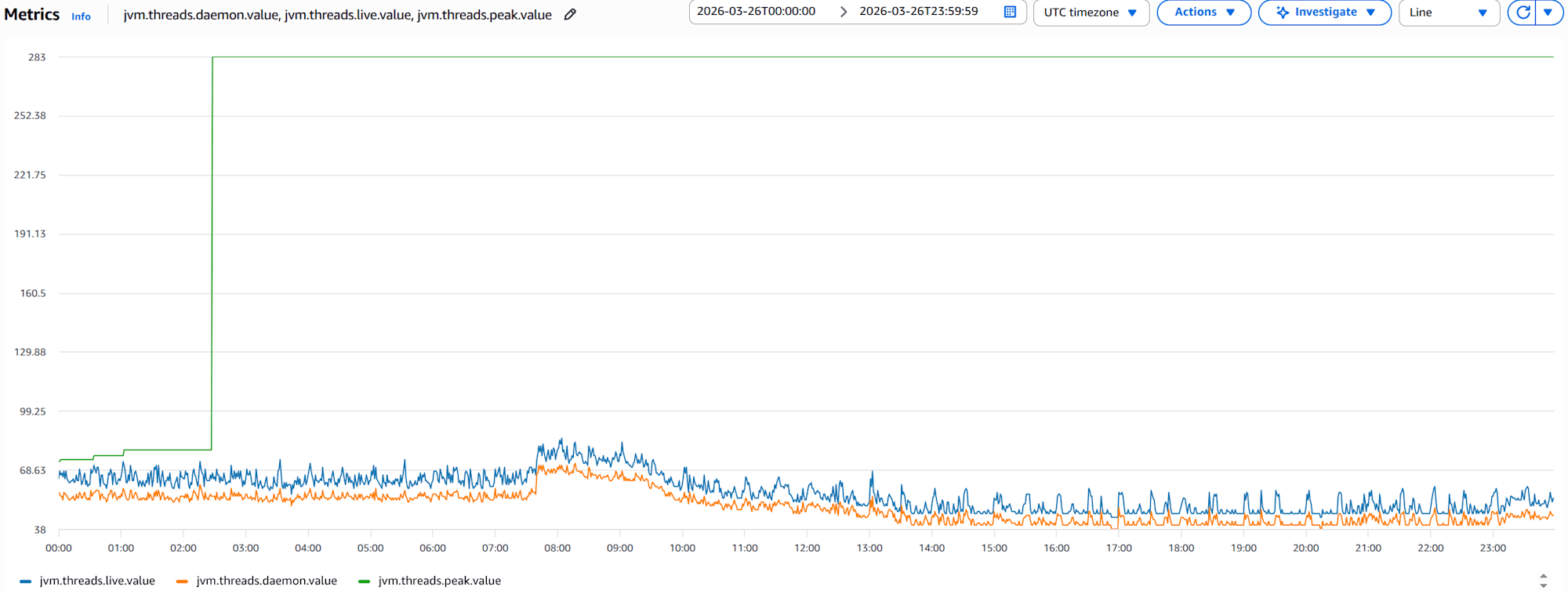
このグラフからは、live スレッドの数が常にデーモンスレッドの数より多いため、アプリケーション固有のスレッドが存在していることがわかります。また、live スレッドの数が安定しているため、スレッドリークの兆候は見られません。一方で、ある地点で peak が跳ね上がっているため、一時的な負荷スパイクがあったことがわかります。
コネクションプール系
- 1コンテナのreader用の
hikaricp.connections.active.valueとhikaricp.connections.pending.valueとhikaricp.connections.timeout.countとhikaricp.connections.max.valueのグラフ
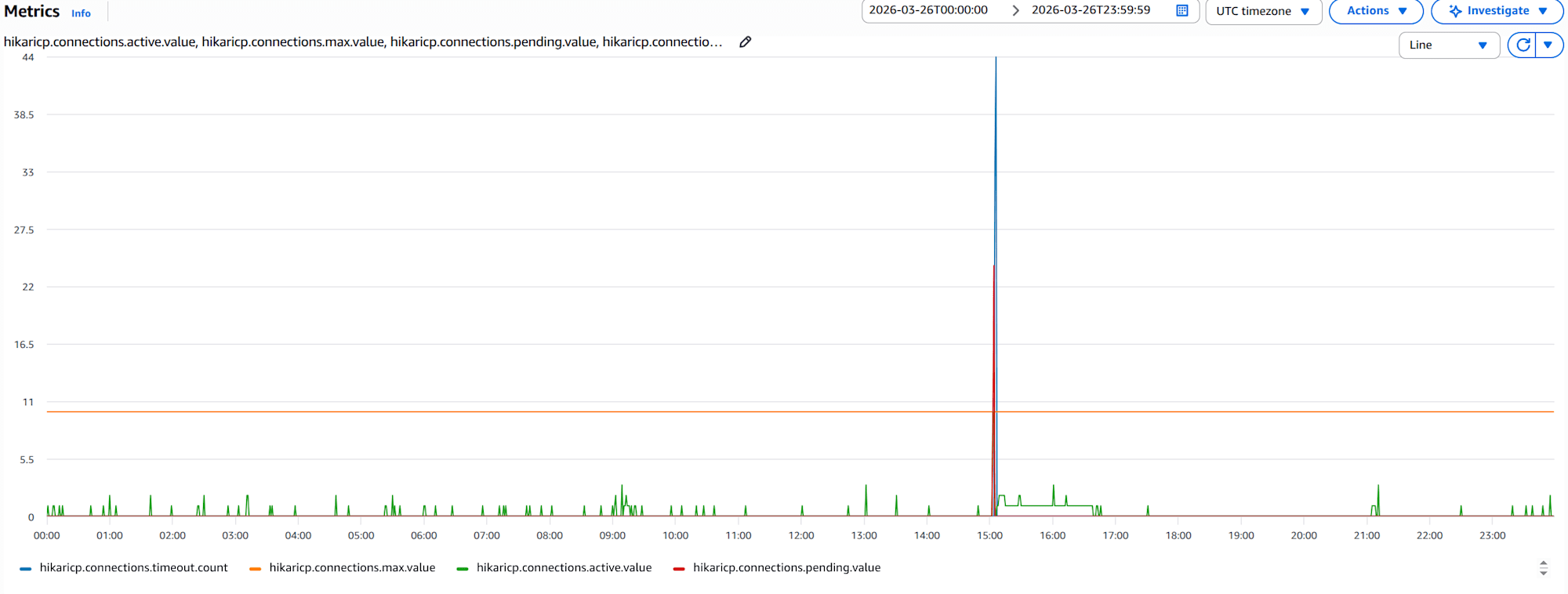
通常は、activeがmaxより小さい値で安定している状態が続いていますが、特定の時間帯で active が max に張り付いている箇所があります。また、同時に pendingと timeout が頻発しているため、ユーザーへのレスポンス遅延や処理の失敗が発生している可能性があります。プールの最大数を増やすか、クエリを高速化する必要があるかもしれません。
まとめ
いかがだったでしょうか。
JVMのGCやメモリ、スレッドのメトリクスは、アプリケーションの健全性を把握するための基本的な指標であり、特にGCオーバーヘッドやコネクションプールの待ちなどは、ユーザー体験に直結するため優先的に有効化すべきです。
一方で、CloudWatch Metrics のカスタムメトリクスは、非常に強力なモニタリングツールですが、コストがかかるため、**「何を送るべきか」**をしっかり選定することが重要です。
どなたかの参考になれば幸いです。








