Amazon Bedrock AgentCore Memory の組み込みオーバーライド戦略を試してみた
はじめに
こんにちは、スーパーマーケットのライフが大好きなコンサルティング部の神野(じんの)です。
Amazon Bedrock AgentCore Memory には、AIエージェントの長期記憶の抽出をカスタマイズできる「組み込みオーバーライド戦略(Built-in with Overrides Strategy)」という仕組みがあります。
デフォルトのビルトイン戦略でも良い感じに長期記憶が取得できるのですが、もしかするとカスタマイズしたいことがあるかもしれません。例えば特定の話題だけ抽出するようにしたい、任意のモデルを使いたいなど。そこで今回紹介する組み込みオーバーライド戦略が活用できます。
実際に組み込みオーバーライド戦略を使って、抽出プロンプトとモデルの変更を試し、抽出される長期記憶がどう変わるかを確認してみました!
前提
環境
使用したバージョンは下記となります。
- Python 3.12
- bedrock-agentcore 1.4.7
- リージョン: us-west-2
事前準備
長期記憶の取得に AgentCore SDK を使うため、インストールしておきます。
uv init
uv add bedrock-agentcore
組み込みオーバーライド戦略
AgentCore Memory の長期記憶は、戦略という仕組みによって生成されます。戦略の作成方法には3つの種類があります。
| 名称 | 説明 |
|---|---|
| ビルトイン | AWS がすべて管理。設定不要ですぐ使える |
| 組み込みオーバーライド | ビルトイン戦略のプロンプトやモデルをカスタマイズ |
| セルフマネージド | 抽出パイプライン全体を自分で構築 |
今回試すのは組み込みオーバーライドです。ビルトインの抽出パイプラインはそのまま活用しつつ、以下の2点だけカスタマイズできます。
- 抽出・統合ステップで使うプロンプト
- 抽出・統合ステップで使うモデル
オーバーライドできるステップは戦略タイプごとに異なります。
| 戦略タイプ | 抽出(Extraction) | 統合(Consolidation) | 振り返り(Reflection) |
|---|---|---|---|
| セマンティック(Semantic) | ○ | ○ | -- |
| ユーザー嗜好(User Preference) | ○ | ○ | -- |
| 要約(Summary) | -- | ○ | -- |
| エピソード記憶(Episodic) | ○ | ○ | ○ |
表だけだとイメージしづらいと思うので図でも表現します。短期記憶から長期記憶の抽出は下記のように段階的に実施され、オーバーライドで変更できるステップは元の戦略タイプに依存します。また振り返りはエピソード記憶戦略に限定されています。
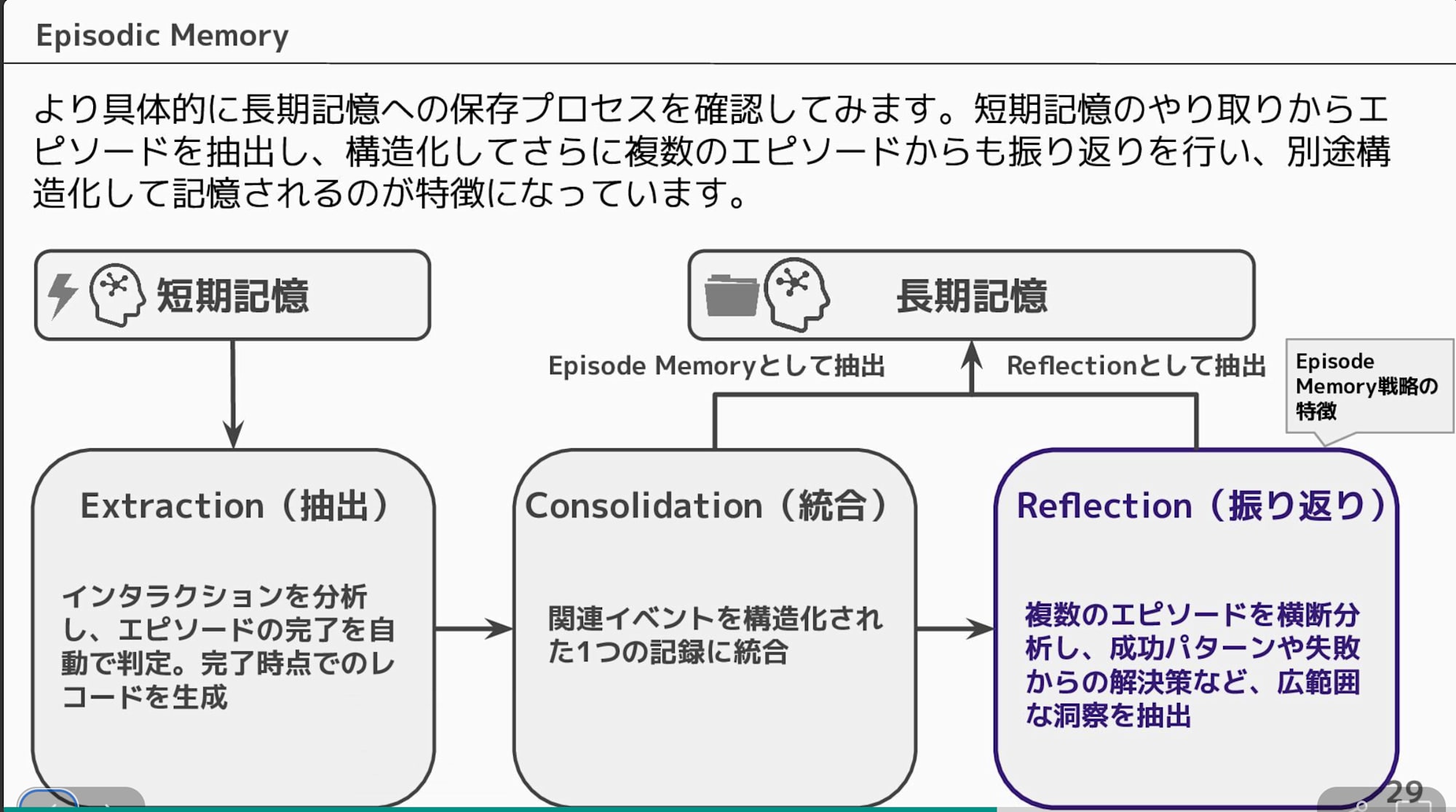
今回は短期記憶の中から事実などの情報を抽出するセマンティック戦略のオーバーライドを試していきます!
検証の流れ
以下の2パターンでメモリリソースを作成し、同じ会話データを投入して、抽出される長期記憶を比較します。
- ビルトイン戦略(デフォルト)
- 組み込みオーバーライド戦略(プロンプトとモデルを変更) — 食の好みだけを抽出するよう指示
投入する会話データは、旅行相談を模した以下の内容です。趣味、食事、宿泊、交通手段など複数のトピックが混在しています。
投入する会話データの会話イメージ
| ロール | メッセージ |
|---|---|
| User | 来月京都に旅行に行く予定です。おすすめはありますか? |
| Assistant | 京都旅行いいですね!どのようなことに興味がありますか?お寺巡り、グルメ、ショッピングなど。 |
| User | お寺や神社を巡るのが好きです。あと、抹茶スイーツが大好きなので、おすすめのカフェも知りたいです。 |
| Assistant | 嵐山の竹林や伏見稲荷がおすすめですよ。抹茶スイーツなら祇園エリアに素敵なお店が多いです。 |
| User | いいですね!ちなみに宿泊はいつも旅館よりホテル派です。朝食バイキング付きのところが好きです。 |
| Assistant | 承知しました。京都駅周辺にはバイキング付きのホテルが多いですよ。 |
| User | 移動は電車が好きです。タクシーは酔いやすいので苦手なんですよね。あと、日本酒は飲めません。 |
パターン1: ビルトイン戦略
メモリリソースの作成
AgentCore のコンソールからメモリーを開き、メモリを作成を選択します。
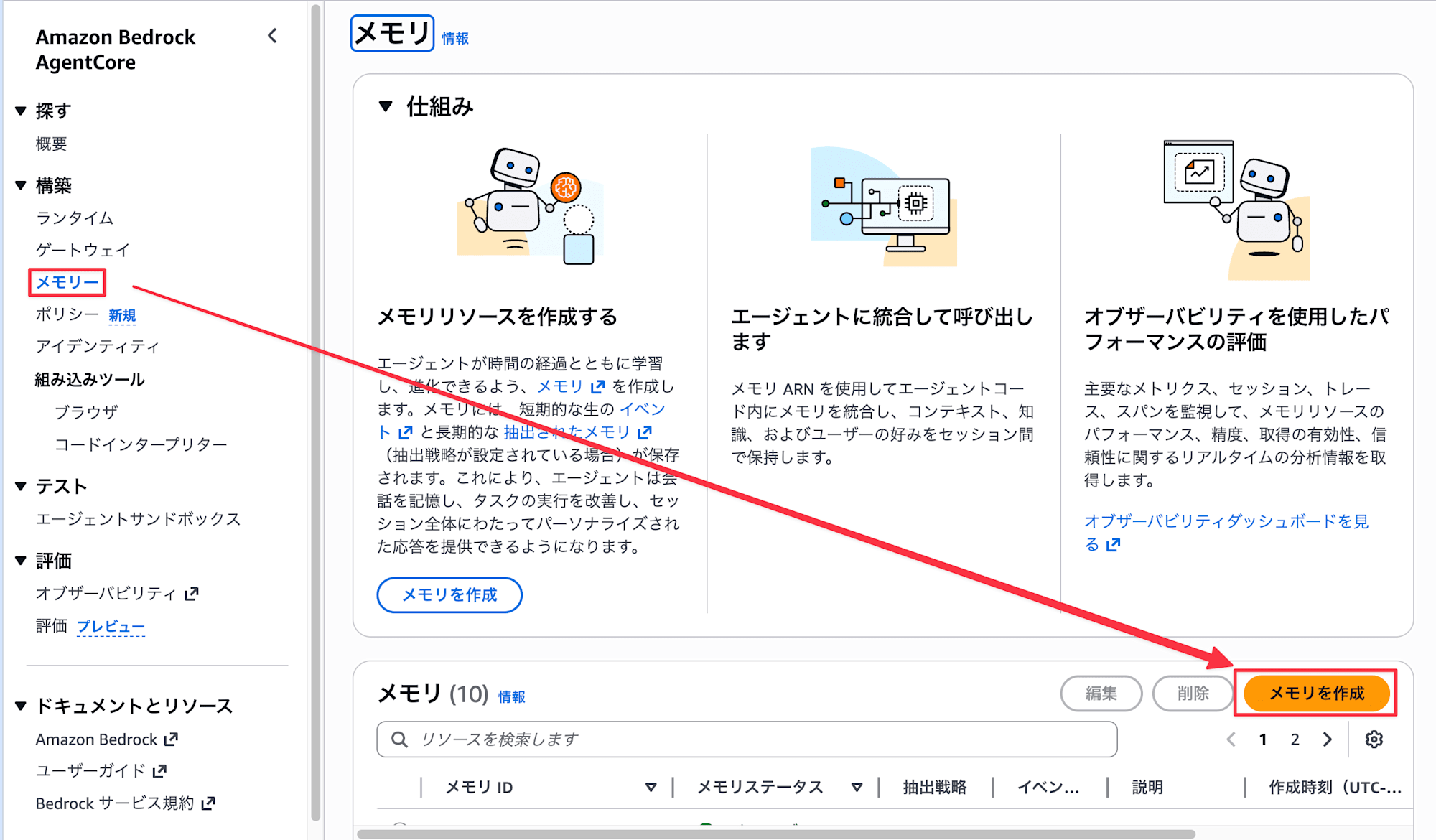
- 名前 に
BuiltinSemanticDemoと入力し、短期メモリの有効期限はそのままとします

- 組み込み戦略で
Semanticを選択し、戦略の名前をDefaultSemanticと入力します。また、名前空間はデフォルトのままとします。

メモリを作成をクリック
ステータスが アクティブ になるまで2〜3分ほど待ちます。

メモリ ID や戦略 ID は後続の検証で必要になるので、控えておきましょう。
イベントの書き込み
メモリリソースが アクティブ になったら、Python スクリプトで会話データをイベントとして書き込みます。
import boto3
from datetime import datetime, timezone
REGION = "us-west-2"
MEMORY_ID = "<コンソールで確認したメモリID>"
client = boto3.client("bedrock-agentcore", region_name=REGION)
CONVERSATIONS = [
("USER", "来月京都に旅行に行く予定です。おすすめはありますか?"),
("ASSISTANT", "京都旅行いいですね!どのようなことに興味がありますか?お寺巡り、グルメ、ショッピングなど。"),
("USER", "お寺や神社を巡るのが好きです。あと、抹茶スイーツが大好きなので、おすすめのカフェも知りたいです。"),
("ASSISTANT", "嵐山の竹林や伏見稲荷がおすすめですよ。抹茶スイーツなら祇園エリアに素敵なお店が多いです。"),
("USER", "いいですね!ちなみに宿泊はいつも旅館よりホテル派です。朝食バイキング付きのところが好きです。"),
("ASSISTANT", "承知しました。京都駅周辺にはバイキング付きのホテルが多いですよ。"),
("USER", "移動は電車が好きです。タクシーは酔いやすいので苦手なんですよね。あと、日本酒は飲めません。"),
]
for role, content in CONVERSATIONS:
client.create_event(
memoryId=MEMORY_ID,
actorId="traveler-001",
sessionId="kyoto-trip-session",
eventTimestamp=datetime.now(timezone.utc),
payload=[
{
"conversational": {
"role": role,
"content": {"text": content},
}
}
],
)
print("イベントの書き込みが完了しました")
create_event API に会話のロールとテキストを渡すだけです。書き込まれたイベントは短期記憶として保存され、バックグラウンドで長期記憶への抽出処理が走ります。
長期記憶の取得
しばらく待ってから、長期記憶を取得してみます。
import boto3
REGION = "us-west-2"
MEMORY_ID = "<コンソールで確認したメモリID>"
STRATEGY_ID = "<戦略ID>"
ACTOR_ID = "traveler-001"
client = boto3.client("bedrock-agentcore", region_name=REGION)
response = client.list_memory_records(
memoryId=MEMORY_ID,
namespace=f"/strategies/{STRATEGY_ID}/actors/{ACTOR_ID}/",
)
records = response.get("memoryRecordSummaries", [])
print(f"取得できた長期記憶の件数: {len(records)}")
print("=" * 60)
for i, record in enumerate(records, 1):
print(f"\n--- 記憶 {i} ---")
print(f"Content: {record.get('content', {}).get('text', '')}")
print("-" * 60)
namespace にはメモリ戦略の名前空間テンプレートに memoryStrategyId と actorId を埋め込んだ値を指定します。
取得できた長期記憶の件数: 8
============================================================
--- 記憶 1 ---
Content: The user is planning to travel to Kyoto next month.
--- 記憶 2 ---
Content: The user loves matcha sweets.
--- 記憶 3 ---
Content: The user prefers staying at hotels over ryokan.
--- 記憶 4 ---
Content: The user likes hotels with breakfast buffets.
--- 記憶 5 ---
Content: The user gets motion sickness easily in taxis.
--- 記憶 6 ---
Content: The user cannot drink sake.
--- 記憶 7 ---
Content: The user enjoys visiting temples and shrines.
--- 記憶 8 ---
Content: The user prefers traveling by train.
旅行計画、寺社仏閣の好み、食の好み、宿泊の好み、交通手段など、会話中のさまざまなトピックがまんべんなく抽出されていますね。日本語で入力した会話データですが、ビルトインのデフォルトプロンプトでは英語に変換されて記憶されていますね。
パターン2: プロンプトとモデルをオーバーライド
次に、抽出プロンプトをカスタマイズして「食の好みだけを記憶する」よう指示してみます。
メモリリソースの作成
コンソールから新しいメモリリソースを作成します。
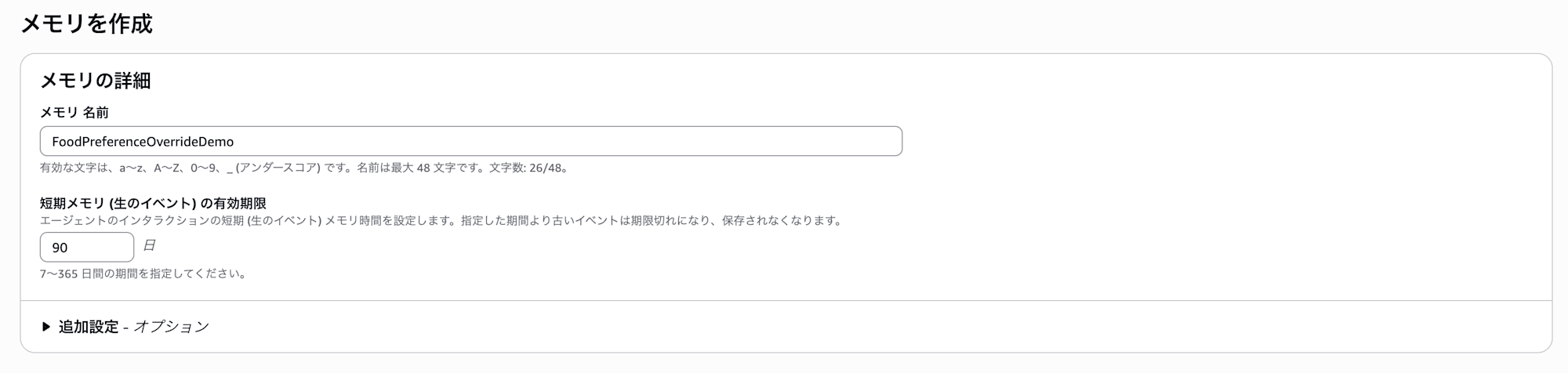
- 名前 に
FoodPreferenceOverrideDemoと入力し、短期メモリの有効期限はそのままとします
- Built-in strategy with override から
カスタム戦略を追加を選択して、FoodOnlySemanticと戦略名を入力し、戦略タイプはセマンティック、名前空間は先ほどと同じデフォルトのままにします。
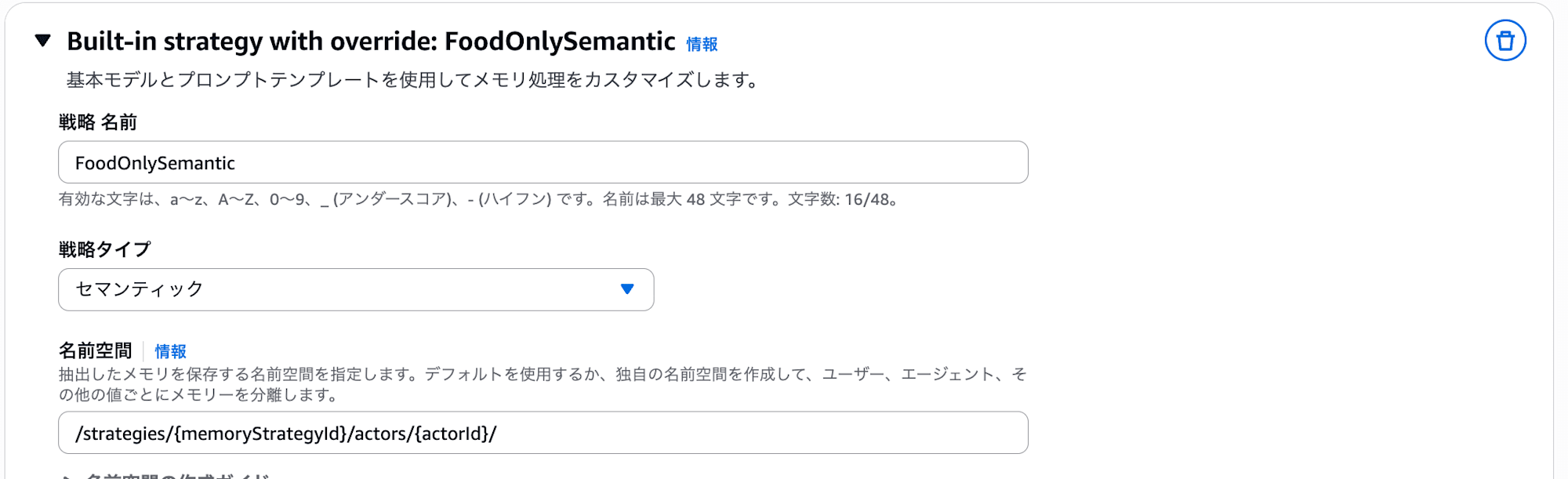
抽出(Extraction)の設定
Model ID に us.anthropic.claude-haiku-4-5-20251001-v1:0 を選択したいのですが、ドロップダウンの一覧にモデルが見当たりません・・・
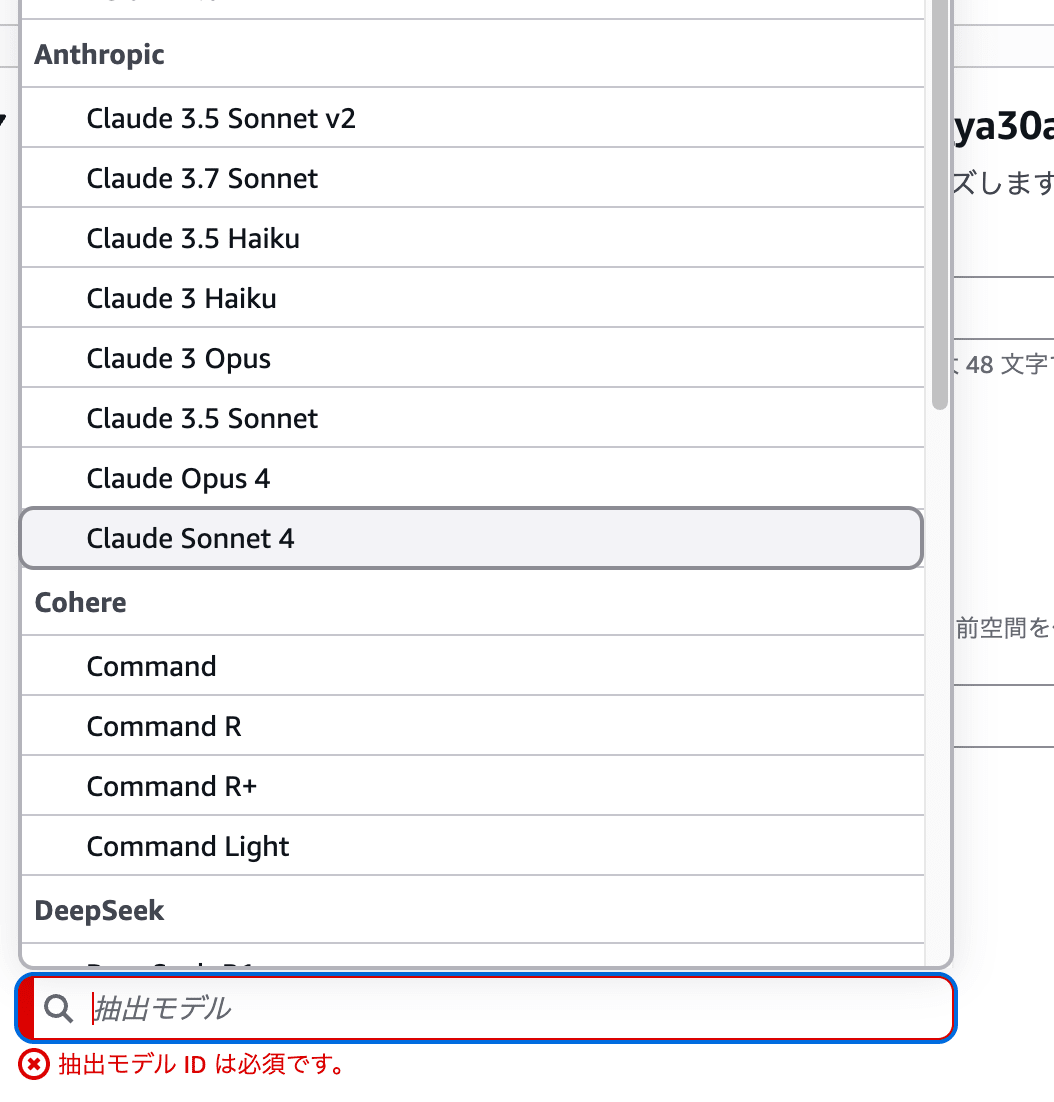
困った・・・と思ったのですが、直接入力もできるようだったので Haiku 4.5 のモデル名を手入力してみました。

続いて プロンプトテンプレート に以下を入力します。
あなたは食事・飲食の好みに特化した長期記憶抽出エージェントです。
与えられたメッセージ一覧から、ユーザーの食に関する情報のみを特定・抽出してください。
会話を分析し、以下のスキーマに従って構造化された情報を抽出してください。
- 食事・飲食の好み、アレルギー、好きな料理ジャンル、飲み物、食習慣のみを抽出すること
- それ以外の情報(旅行計画、趣味、宿泊の好み、交通手段の好みなど)はすべて無視すること
- ユーザーのメッセージからのみ情報を抽出すること。アシスタントのメッセージは文脈の補足としてのみ使用すること
- 会話に食に関する情報が含まれない場合は、空のリストを返すこと
- 過去の会話履歴が提供されていても、そこからは抽出しないこと。文脈の参考としてのみ使用すること
- 外部知識を組み込まないこと
- 重複した抽出を避けること
重要: ユーザーの会話の元の言語を維持すること。
食に関する情報のみを抽出するよう指示し、旅行計画や宿泊の好みなどはすべて無視するよう明記しています。また元の言語を維持するような指示も入れてみます。
統合(Consolidation)の設定
同じく Model ID に us.anthropic.claude-haiku-4-5-20251001-v1:0 を手入力し、プロンプトに以下を入力します。
# 役割
あなたは食事・飲食の好みの管理に特化したメモリマネージャーです。
# タスク
新しいメモリごとに、以下の3つの操作から正確に1つを選択してください: AddMemory、UpdateMemory、SkipMemory。
# 操作
1. AddMemory - 既存のメモリに存在しない、まったく新しい食の好みの場合に選択
2. UpdateMemory - 新しいメモリが既存の食の好みを補足・詳細化する場合に選択
3. SkipMemory - 食事・飲食の好みに関連しない場合、または重複している場合に選択
前述の通り、統合プロンプトでは操作名(AddMemory、UpdateMemory、SkipMemory)を変更しないようにします。
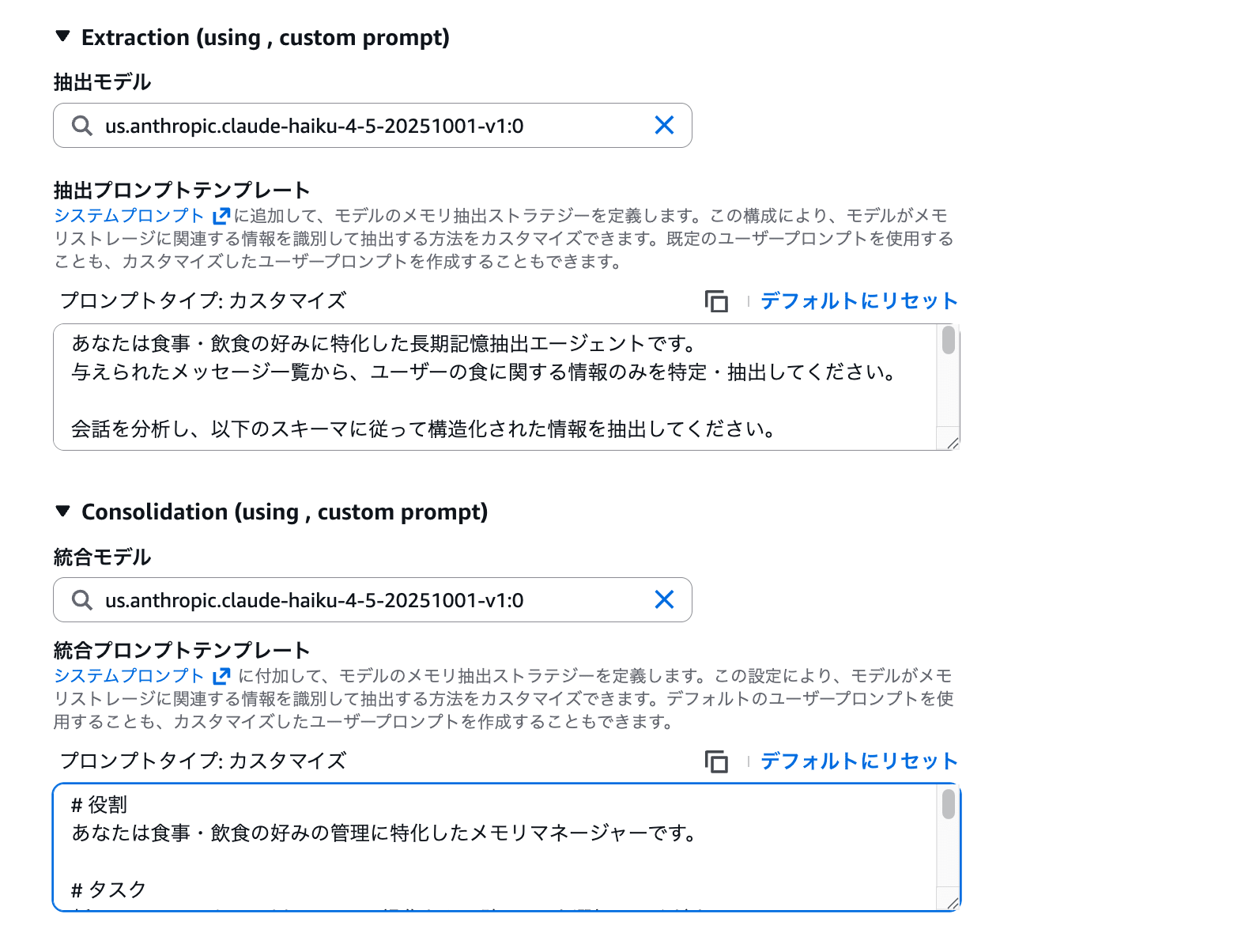
設定が完了したらメモリを作成を押下し、アクティブ になるのを待ちます。


無事完了していますね!メモリ ID や戦略 IDをコピーしてパターン1と同じ処理を実行していきます。
イベントの書き込みと長期記憶の取得
パターン1と同じ write_events.py の MEMORY_ID を差し替えて実行し、retrieve_records.py で長期記憶を確認します。
取得できた長期記憶の件数: 2
============================================================
--- 記憶 1 ---
Content: ユーザーは日本酒は飲めません。
------------------------------------------------------------
--- 記憶 2 ---
Content: ユーザーは抹茶スイーツが大好きです。
おおお、食に関する情報だけが抽出されていますね!!ビルトインでは8件抽出されていた長期記憶が、プロンプトのカスタマイズによって食に関する2件だけに絞り込まれました。旅行計画や宿泊の好み、交通手段の情報はすべてスキップされています。プロンプトが日本語でも問題なく動作していますね。
ちなみに、ドロップダウンに出てこなかった Haiku も問題なく動いていました。コンソールの一覧には最近のモデルがリストアップされていないだけで、手入力すれば使えるようです。そうなんだ・・・
デフォルトで作成されるサービスロールには下記のポリシーが付与されており、手入力したモデルでも問題なく推論が実行できた形です。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockInvokeInferenceProfileStatement",
"Effect": "Allow",
"Action": [
"bedrock:GetInferenceProfile",
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": [
"arn:aws:bedrock:us-west-2:123456789012:inference-profile/us.anthropic.claude-haiku-4-5-20251001-v1:0",
"arn:aws:bedrock:*::foundation-model/anthropic.claude-haiku-4-5-20251001-v1:0"
]
}
]
}
もし自前でIAMロールを作成する場合は上記権限が必要であることを覚えておきたいですね。
カスタマイズ時の注意点
公式ドキュメントには、プロンプトをカスタマイズする際のベストプラクティスと制約が記載されています。
とても参考になるのでこちらは確認しておきましょう。
組み込みの戦略手順を起点として活用することが強く推奨されています。基本構造と手順はメモリ機能にとって重要なので、ゼロから新しい手順を作成するのではなく、既存のプロンプトに加えたい固有のガイダンス(今回なら食事のみに限定する文言)を追記するようにとあるので完全に新規プロンプトを与えるのはちょっと危なそうですね。
また、パイプラインの信頼性を維持するために以下の制約があります。
- ビルトインのシステムプロンプトにはLLMの出力フォーマット定義(スキーマ)が含まれており、ここは変更しないこと。変更できるのは抽出・統合の指示(Instructions)部分のみ
- 統合(Consolidation)の操作名(
AddMemory、UpdateMemory、SkipMemory)を変更しないこと - 出力スキーマは編集できない。ビルトイン戦略と同じスキーマがそのまま使われる
出力スキーマを含めて完全にカスタマイズしたい場合は、セルフマネージド戦略を検討する必要があります。なるほど・・・
ちなみに今回の検証では、統合プロンプトはデフォルトに比べてかなり簡略化したものを使っています。
デフォルトの統合プロンプトには UpdateMemory 時の出力フィールド指示(update_id や updated_memory)や、操作を判断するための詳細なガイドライン(タイムスタンプの保持、セマンティックな正確性の維持など)が含まれています。今回は抽出される記憶が2件と少なかったため問題なく動作しましたが、記憶が蓄積してくると UpdateMemory の判断精度に影響が出る可能性があります。まずはデフォルトのプロンプトをベースに、ドメイン固有の指示だけを追加するのが安全な印象です。
デフォルトのプロンプトは本記事の最後に載せているのでご参照ください。
コストについて
組み込みオーバーライド戦略を検討するうえで、コスト構造の違いを知っておきたいですよね。
AgentCore Memory の料金体系を確認してみます。
長期記憶のストレージ料金は、戦略タイプによって異なります。(us-east-1を想定)
| 項目 | 料金 |
|---|---|
| 短期記憶(イベント) | $0.25 / 1,000 イベント |
| 長期記憶ストレージ(ビルトイン) | $0.75 / 1,000 メモリ |
| 長期記憶ストレージ(組み込みオーバーライド) | $0.25 / 1,000 メモリ |
| 長期記憶の取得 | $0.50 / 1,000 リクエスト |
ビルトイン戦略はストレージ単価が $0.75 と高めですが、抽出・統合に使われる LLM の推論コストが含まれています。つまり、追加のモデル利用料金は発生しません。
一方、組み込みオーバーライド戦略ではストレージ単価が $0.25 と3分の1になりますが、抽出・統合で使う LLM の推論コストが自分のアカウントに別途課金されます。ストレージだけ見ると安く見えるので注意が必要ですね。
まとめると以下のようになります。
| 項目 | ビルトイン | 組み込みオーバーライド |
|---|---|---|
| ストレージ単価 | $0.75 / 1,000 メモリ | $0.25 / 1,000 メモリ |
| LLM 推論コスト | 込み(追加課金なし) | 別途課金 |
使うモデルによっては高額になる可能性もあるので、パフォーマンス面も見ながら考えたいポイントですね。
おわりに
やっていることはシンプルで、抽出プロンプトとモデルIDを差し替えるだけです。ビルトインの抽出パイプラインをそのまま活用できるので、インフラ構築は不要ですし、コンソールからポチポチ設定するだけで完了します。プロンプトをカスタマイズしたい場合や、任意のモデルを使いたい場合にはぜひ試してみてください。
今後はセルフマネージドで抽出や登録を行う戦略についても試してみたいと思います!
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございましたー!!
おまけ: デフォルトのビルトインプロンプト
参考までに、今回使用したセマンティック戦略のデフォルトプロンプトを載せておきます。オーバーライドする際のベースとして活用してください。
抽出(Extraction)のデフォルトプロンプト
You are a long-term memory extraction agent supporting a lifelong learning system. Your task is to identify and extract meaningful information about the users from a given list of messages.
Analyze the conversation and extract structured information about the user according to the schema below. Only include details that are explicitly stated or can be logically inferred from the conversation.
- Extract information ONLY from the user messages. You should use assistant messages only as supporting context.
- If the conversation contains no relevant or noteworthy information, return an empty list.
- Do NOT extract anything from prior conversation history, even if provided. Use it solely for context.
- Do NOT incorporate external knowledge.
- Avoid duplicate extractions.
統合(Consolidation)のデフォルトプロンプト
You are a conservative memory manager that preserves existing information while carefully integrating new facts.
Your operations are:
- AddMemory: Create new memory entries for genuinely new information
- UpdateMemory: Add complementary information to existing memories while preserving original content
- SkipMemory: No action needed (information already exists or is irrelevant)
If the operation is "AddMemory", you need to output:
1. The `memory` field with the new memory content
If the operation is "UpdateMemory", you need to output:
1. The `memory` field with the original memory content
2. The update_id field with the ID of the memory being updated
3. An updated_memory field containing the full updated memory with merged information
## Decision Guidelines
### AddMemory (New Information)
Add only when the retrieved fact introduces entirely new information not covered by existing memories.
### UpdateMemory (Preserve + Extend)
Preserve existing information while adding new details. Combine information coherently without losing specificity or changing meaning.
Critical Rules for UpdateMemory:
- Preserve timestamps and specific details from the original memory
- Maintain semantic accuracy - don't generalize or change the meaning
- Only enhance when new information genuinely adds value without contradiction
- Only enhance when new information is closely relevant to existing memories
- Attend to novel information that deviates from existing memories and expectations
- Consolidate and compress redundant memories to maintain information-density; strengthen based on reliability and recency; maximize SNR by avoiding idle words
When NOT to update:
- Information is essentially the same: "likes pizza" vs "loves pizza"
- Updating would change the fundamental meaning
- New fact contradicts existing information (use AddMemory instead)
- New fact contains new events with timestamps that differ from existing facts. Since enhanced memories share timestamps with original facts, this would create temporal contradictions. Use AddMemory instead.
### SkipMemory (No Change)
Use when information already exists in sufficient detail or when new information doesn't add meaningful value.
## Key Principles
- Conservation First: Preserve all specific details, timestamps, and context
- Semantic Preservation: Never change the core meaning of existing memories
- Coherent Integration: Ensure enhanced memories read naturally and logically