
Amazon Bedrock AgentCore Memory の blob ペイロードを試してみた
はじめに
こんにちは、スーパーマーケットが大好きなコンサルティング部の神野です。
皆さんはAgentCore Memory使っていますか?Amazon Bedrock AgentCore Memory には、会話メッセージを保存する conversational ペイロードのほかに、任意の JSON やバイナリデータを保存できる blob ペイロードが用意されています。
Blob: For storing binary format data, such as images and documents, or data that is unique to your agent, such as data stored in JSON format.
会話だけかと思いきやバイナリも対応しているので、画像やドキュメントなどもチャットに組み込んだりすることが可能です。
今回はこの blob を使って、会話メッセージとドキュメント(Markdown や JSON ファイル)を1つの event にまとめて保存・復元できるか試してみました!
「この会話のときにこのドキュメントが共有された」という文脈をセットで記録する下記のようなイメージです。
[1つの Event]
├─ payload[0]: conversational (USER) ← 会話メッセージ
├─ payload[1]: conversational (ASSISTANT) ← 会話メッセージ
├─ payload[2]: blob (document) ← 議事録.md
└─ payload[3]: blob (document) ← 仕様書.json
前提
使用環境
| 項目 | バージョン / 値 |
|---|---|
| Python | 3.12 |
| strands-agents | 1.29.0 |
| strands-agents-tools | 0.2.22 |
| bedrock-agentcore SDK | 1.4.3 |
| AWS リージョン | us-east-1 |
事前準備
- AWS アカウントがセットアップ済みであること
- Amazon Bedrock、AgentCore Memory を操作できる IAM 権限があること
AgentCore Memory リソースの作成
今回はAWS マネジメントコンソールから Memory リソースを作成します。
- AgentCore のコンソールを開き、左メニューから
メモリーを選択し、メモリを作成を選択
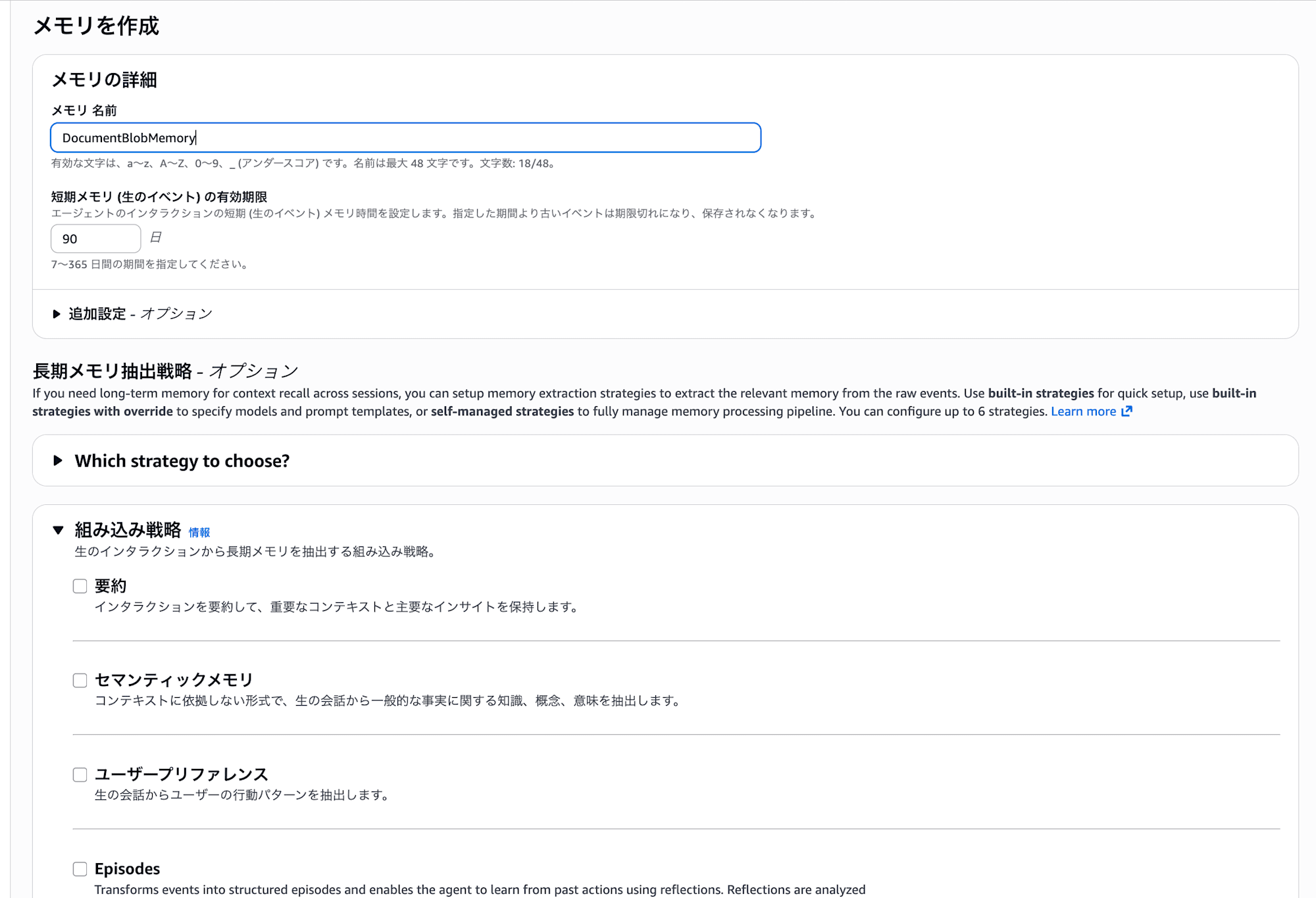
- 以下を入力して作成
- 名前: 任意の名前(例:
DocumentBlobMemory) - 短期メモリの有効期限: イベントの有効期限日数(例:
90) - 今回は長期記憶は使用しないので特に設定しません
- 名前: 任意の名前(例:
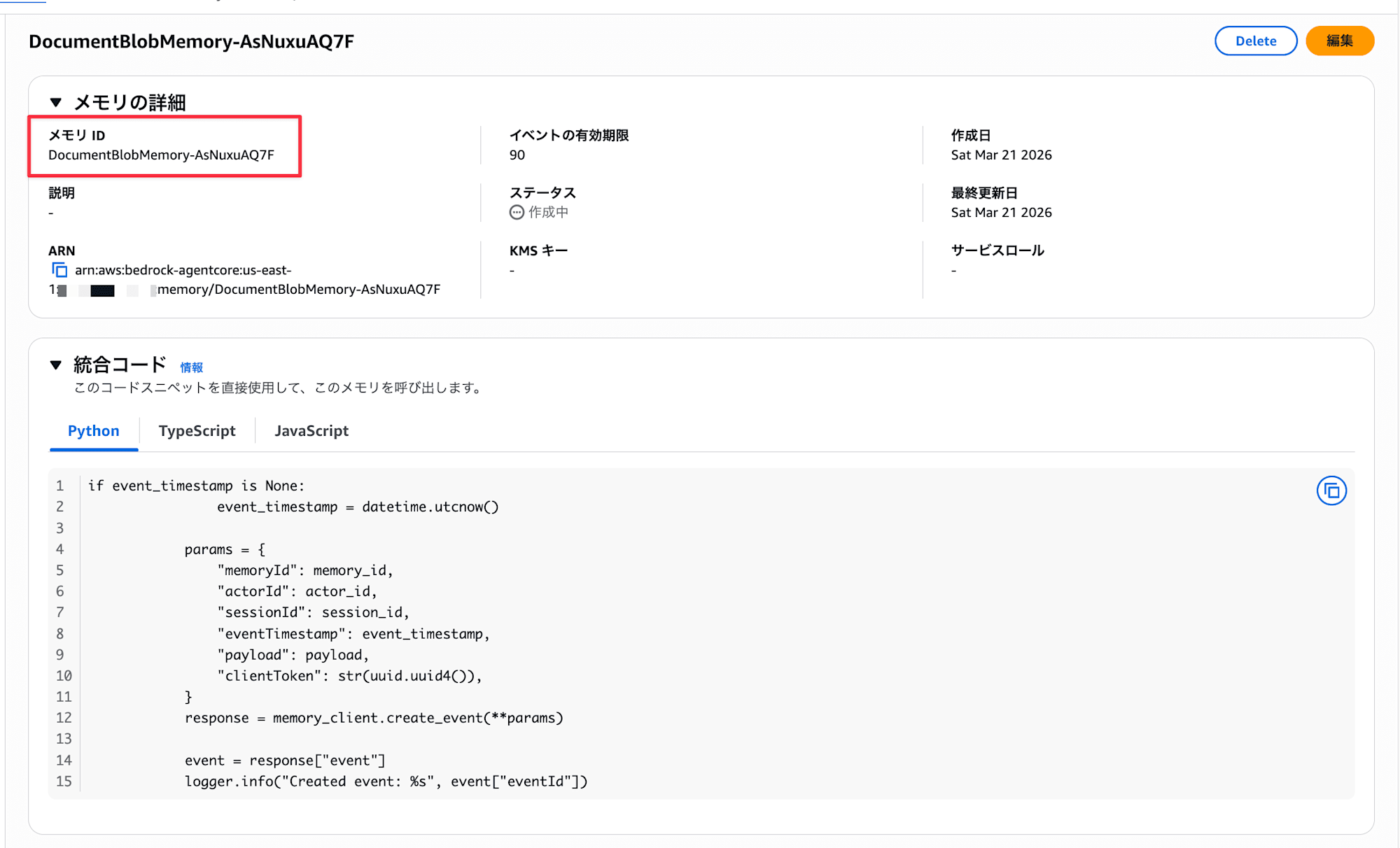
- 作成後、一覧画面で Memory ID を確認

取得した Memory ID を環境変数に設定しておきます。
export AGENTCORE_MEMORY_ID="取得した Memory ID"
プロジェクトのセットアップ
uv init
uv add strands-agents strands-agents-tools bedrock-agentcore
AgentCore Memory の blob ペイロード
AgentCore Memory の Event には、ペイロードとして 2 つの型が用意されています。
| ペイロード型 | 用途 |
|---|---|
conversational |
会話メッセージ(role + content)の保存。長期記憶(LTM)の抽出対象になる |
blob |
任意の JSON / バイナリデータの保存。LTM の抽出対象にはならない |
1つの event の payload 配列には両方を混ぜて入れることができます。これを利用して、会話メッセージとドキュメントをセットで保存するのが今回のアプローチです。
注意点としてはblobは長期記憶の対象になりません。バイナリなのでそれはそうだろって感じですよね。
また、Strands Agents の AgentCoreMemorySessionManager は conversational ペイロードを扱う Session Manager なので、blob の保存・復元はできません。今回のように blob を使いたい場合は AgentCore Memory の API を直接呼んで自前で管理する必要があります。
実装
流れとしてはbase64エンコードしてJSONに変換して、会話イベントとまとめて保存する形になります。
まずは添付ファイルの変換を行うヘルパーを実装します。
ドキュメント保存・復元ヘルパー
ファイルの base64 エンコード/デコードと、conversational + blob の混在保存を行うヘルパーを実装します。
import base64
import json
import mimetypes
from datetime import datetime, timezone
from pathlib import Path
import boto3
def create_client(region_name: str = "us-east-1"):
return boto3.client("bedrock-agentcore", region_name=region_name)
def encode_file(file_path: str | Path) -> dict:
"""ファイルを base64 エンコードして blob 用 dict にする"""
path = Path(file_path)
content_type = mimetypes.guess_type(str(path))[0] or "application/octet-stream"
data = path.read_bytes()
return {
"type": "document",
"filename": path.name,
"content_type": content_type,
"data_base64": base64.b64encode(data).decode("ascii"),
"size_bytes": len(data),
}
def decode_file(blob_dict: dict, output_dir: str | Path = ".") -> Path:
"""blob dict からファイルを復元する"""
output_dir = Path(output_dir)
output_dir.mkdir(parents=True, exist_ok=True)
filename = blob_dict["filename"]
data = base64.b64decode(blob_dict["data_base64"])
out_path = output_dir / filename
out_path.write_bytes(data)
return out_path
encode_file でファイルをバイナリ読み込みして base64 エンコード、decode_file でその逆を行います。バイナリレベルで処理するので Markdown でも JSON でも画像でも同じ関数で扱えます。
blob として保存する JSON のイメージはこんな感じです。
{
"type": "document",
"filename": "meeting_notes.md",
"content_type": "text/markdown",
"data_base64": "IyDjg5fjg63jgrjjgqfjgq/jg4jlrprkvov...",
"size_bytes": 523
}
| フィールド | 内容 |
|---|---|
type |
"document" 固定。他の blob データと区別するためのタグ |
filename |
元のファイル名 |
content_type |
MIME タイプ(text/markdown、image/png など) |
data_base64 |
ファイル本体の base64 エンコード文字列 |
size_bytes |
元のファイルサイズ(バイト) |
続いて、会話メッセージとドキュメントを1つの event にまとめて保存・復元する関数です。
def save_conversation_with_docs(
client,
memory_id: str,
actor_id: str,
session_id: str,
user_message: str,
assistant_message: str,
documents: list[str | Path] | None = None,
) -> str:
"""会話メッセージとドキュメントを1つの event にまとめて保存する"""
payload = [
{
"conversational": {
"content": {"text": user_message},
"role": "USER",
}
},
{
"conversational": {
"content": {"text": assistant_message},
"role": "ASSISTANT",
}
},
]
if documents:
for doc_path in documents:
encoded = encode_file(doc_path)
encoded["saved_at"] = datetime.now(timezone.utc).isoformat()
payload.append({"blob": json.dumps(encoded)})
response = client.create_event(
memoryId=memory_id,
actorId=actor_id,
sessionId=session_id,
eventTimestamp=int(datetime.now(timezone.utc).timestamp()),
payload=payload,
)
event_id = response["event"]["eventId"]
print(f"Event saved: {event_id} (messages: 2, docs: {len(documents or [])})")
return event_id
payload 配列の先頭に conversational(USER と ASSISTANT)を入れ、その後ろにドキュメントの blob を追加しています。ドキュメントがない会話ターンでは conversational だけの event になります。
encode_file で作った dict を json.dumps() で文字列化してから blob に渡しています。
def load_conversation_with_docs(
client,
memory_id: str,
actor_id: str,
session_id: str,
restore_dir: str | Path = "restored_docs",
) -> list[dict]:
"""セッション内の全 event を取得し、会話とドキュメントをセットで復元する"""
response = client.list_events(
memoryId=memory_id,
actorId=actor_id,
sessionId=session_id,
)
events = response.get("events", [])
results = []
for event in reversed(events):
entry = {
"event_id": event["eventId"],
"messages": [],
"documents": [],
}
for payload_item in event.get("payload", []):
if "conversational" in payload_item:
conv = payload_item["conversational"]
entry["messages"].append({
"role": conv["role"],
"text": conv["content"]["text"],
})
if "blob" in payload_item:
blob_raw = payload_item["blob"]
if isinstance(blob_raw, str):
try:
blob = json.loads(blob_raw)
except json.JSONDecodeError:
continue
else:
blob = blob_raw
if isinstance(blob, dict) and blob.get("type") == "document":
restored_path = decode_file(blob, output_dir=restore_dir)
entry["documents"].append({
"filename": blob["filename"],
"content_type": blob.get("content_type", "unknown"),
"size_bytes": blob.get("size_bytes", 0),
"restored_path": restored_path,
})
results.append(entry)
return results
list_events は新しい順で返ってくるので、reversed() で古い順に並べ直して会話の流れを時系列で復元しています。blob の中で type が "document" のものだけを decode_file でファイルに復元します。
ドキュメント対応エージェントの実装
ヘルパーができたので、これを使ったエージェントを実装します。添付ファイルを保存する、保存した添付ファイルを一覧で取得するシンプルなエージェントです。
import os
from pathlib import Path
from strands import Agent, tool
from strands.types.tools import ToolContext
from doc_helper import (
create_client,
load_conversation_with_docs,
save_conversation_with_docs,
)
MEMORY_ID = os.environ["AGENTCORE_MEMORY_ID"]
ACTOR_ID = "doc_demo_user"
SESSION_ID = "doc_session_v1"
REGION = "us-east-1"
RESTORE_DIR = "restored_docs"
agentcore_client = create_client(REGION)
@tool(context=True)
def attach_document(file_path: str, tool_context: ToolContext):
"""ドキュメントを添付リストに追加する。次の保存時に blob として AgentCore Memory に保存される。
Args:
file_path: 添付するファイルのパス
"""
path = Path(file_path)
if not path.exists():
return f"ファイルが見つかりません: {file_path}"
pending = tool_context.agent.state.get("pending_documents") or []
pending.append(str(path))
tool_context.agent.state.set("pending_documents", pending)
size_kb = path.stat().st_size / 1024
return f"'{path.name}' を添付リストに追加しました({size_kb:.1f} KB)"
@tool(context=True)
def list_attachments(tool_context: ToolContext):
"""現在の添付リストと、過去に復元されたドキュメントを表示する"""
pending = tool_context.agent.state.get("pending_documents") or []
history = tool_context.agent.state.get("document_history") or []
lines = ["=== 添付待ちドキュメント ==="]
if pending:
for p in pending:
lines.append(f" - {Path(p).name}")
else:
lines.append(" (なし)")
lines.append("\n=== 過去のドキュメント履歴 ===")
if history:
for h in history:
lines.append(f" - {h['filename']} ({h['content_type']}, {h['size_bytes']} bytes)")
else:
lines.append(" (なし)")
return "\n".join(lines)
attach_document ツールで指定ファイルを agent.state の添付リストに追加し、list_attachments で添付待ち・過去ドキュメントの一覧を表示します。
続いて、エージェントの起動・会話ループ・保存の部分です。
def main():
# 1. 前回のセッションから会話+ドキュメントを復元
history = load_conversation_with_docs(
agentcore_client, MEMORY_ID, ACTOR_ID, SESSION_ID,
restore_dir=RESTORE_DIR,
)
doc_history = []
if history:
print(f"セッションから {len(history)} 件の会話+ドキュメントを復元しました")
for entry in history:
for doc in entry["documents"]:
doc_history.append({
"filename": doc["filename"],
"content_type": doc["content_type"],
"size_bytes": doc["size_bytes"],
"restored_path": str(doc["restored_path"]),
})
print(f" 復元: {doc['filename']} -> {doc['restored_path']}")
else:
print("過去のセッションはありません。新規開始します。")
# 2. エージェントを作成
agent = Agent(
system_prompt=(
"あなたはドキュメント管理アシスタントです。\n"
"ユーザーの質問に答えつつ、ドキュメントの添付・管理もサポートします。\n"
"- attach_document: ファイルを添付リストに追加\n"
"- list_attachments: 添付リストと履歴を表示\n"
"\nドキュメントを添付したい場合は、ファイルパスを教えてもらって"
" attach_document を使ってください。"
),
tools=[attach_document, list_attachments],
state={
"pending_documents": [],
"document_history": doc_history,
},
)
# 3. 会話ループ
try:
while True:
user_input = input("\nYou: ").strip()
if user_input.lower() in ("quit", "exit", "q"):
break
result = agent(user_input)
assistant_text = str(result)
# 4. 毎ターン、会話+添付ドキュメントを event として保存
pending = agent.state.get("pending_documents") or []
save_conversation_with_docs(
agentcore_client,
MEMORY_ID,
ACTOR_ID,
SESSION_ID,
user_message=user_input,
assistant_message=assistant_text[:500],
documents=pending if pending else None,
)
if pending:
print(f" ({len(pending)} 件のドキュメントを blob として保存しました)")
agent.state.set("pending_documents", [])
except KeyboardInterrupt:
print("\n中断されました")
print("セッション終了。")
if __name__ == "__main__":
main()
起動時に load_conversation_with_docs で会話+ドキュメントを復元し、毎ターンの会話後に save_conversation_with_docs で保存します。ドキュメントが添付されている場合は conversational と blob が1つの event にまとまり、ドキュメントなしなら conversational だけの event になります。
動作確認
サンプルドキュメントの準備
検証用に、議事録と API 仕様書の2つのサンプルドキュメントを用意しました。
# プロジェクト定例会議メモ
**日時**: 2026-03-10 14:00-15:00
**参加者**: 田中、佐藤、鈴木
## アジェンダ
### 1. 進捗報告
- フロントエンド: ダッシュボード画面の実装完了(田中)
- バックエンド: API v2 のエンドポイント追加中(佐藤)
- インフラ: ECS タスク定義の更新準備中(鈴木)
### 2. 課題
- API レスポンスタイムが目標の 200ms を超えるケースがある
- データベースのインデックス見直しが必要
{
"openapi": "3.0.0",
"info": {
"title": "Sample Project API",
"version": "2.0.0",
"description": "プロジェクト管理用 API"
},
"paths": {
"/tasks": {
"get": {
"summary": "タスク一覧取得",
...
}
}
}
}
エージェントで試してみる
実際にエージェントを起動してドキュメントを添付してみます。
uv run document_agent.py
過去のセッションはありません。新規開始します。
You: sample_docs/meeting_notes.md を添付して
Tool: attach_document
'meeting_notes.md' を添付リストに追加しました(0.5 KB)
Event saved: 0000001773100200000#a1b2c3d4 (messages: 2, docs: 1)
(1 件のドキュメントを blob として保存しました)
You: sample_docs/api_spec.json も添付して
Tool: attach_document
'api_spec.json' を添付リストに追加しました(0.8 KB)
Event saved: 0000001773100201000#e5f6a7b8 (messages: 2, docs: 1)
(1 件のドキュメントを blob として保存しました)
You: ^C
中断されました
セッション終了。
会話メッセージとドキュメントがセットで保存されていますね。次にプロセスを再起動して、復元されるか確認します。
セッションから 2 件の会話+ドキュメントを復元しました
復元: meeting_notes.md -> restored_docs/meeting_notes.md
復元: api_spec.json -> restored_docs/api_spec.json
You:
AgentCore Memory には以下のような構造で保存されており、これを list_events で取得してドキュメントを復元しています。
{
"eventId": "0000001773100200000#a1b2c3d4",
"payload": [
{
"conversational": {
"role": "USER",
"content": { "text": "sample_docs/meeting_notes.md を添付して" }
}
},
{
"conversational": {
"role": "ASSISTANT",
"content": { "text": "'meeting_notes.md' を添付リストに追加しました" }
}
},
{
"blob": "{\"type\": \"document\", \"filename\": \"meeting_notes.md\", \"content_type\": \"text/markdown\", \"data_base64\": \"IyDjg5fjg63jgrjjgqfjgq...\", \"size_bytes\": 523}"
}
]
}
restored_docs/ フォルダを見ると、先ほど添付したファイルが復元されています。
restored_docs/
├── meeting_notes.md
└── api_spec.json
プロセスを再起動しても、会話で共有したドキュメントがちゃんと復元されていますね!!
画像ファイル(PNG、JPEG など)もまったく同じ方法で保存・復元できます。encode_file はバイナリとして読み込んで base64 エンコードするだけなので、ファイル形式は特に意識する必要はありません。
今回はシンプルな小さいファイルなので base64 でそのまま blob に入れていますが、大容量ファイルの場合は工夫の余地があります。実際に試したところ、133 KB の画像や 2 MB の PDF は問題なく保存できましたが、11.4 MB の PDF では 413 エラーが返ってきました。AgentCore Memory のクォータとして 1 イベントあたり 10 MB のサイズ上限があるためここを超過したからエラーになったかと思われます。
また、復元したドキュメントをエージェントに渡す際、LLM のコンテキストウィンドウも無限ではないので、大きなファイルをそのまま全文渡すのは現実的ではありませんし、バイナリのまま渡してもノイズになるかと思います。読み込ませたい場合は別途変換してLLMに渡すか、S3 に保存して参照パスだけを blob に状態として記録し、必要な部分だけを取得してコンテキストに渡すといった設計を選択する必要があるかもしれませんね。
少しはまったポイント
blob に dict をそのまま渡すと復元できない
blob には dict をそのまま渡すこともできるのですが、list_events で取得するとキーがクォートされていない文字列に変換されて返ってきます。
payload.append({"blob": {"type": "agent_state", "data": {"count": 1}}})
{type=agent_state, data={count=1}}
これは JSON ではないので json.loads() でパースできません。保存時に json.dumps() で文字列化しておけば、取得時もそのまま JSON 文字列で返ってくるのでパースできます。
payload.append({"blob": json.dumps({"type": "agent_state", "data": {"count": 1}})})
'{"type": "agent_state", "data": {"count": 1}}'
おわりに
base64 エンコードを組み合わせることで、Markdown ドキュメントや JSON ファイルなどのバイナリデータも blob として保存・復元できることが確認できました。さらに conversational と blob を1つの event に混在させることで、「この会話のときにこのドキュメントが共有された」という文脈をセットでMemoryで記憶できるのは良いですね。
今回は小さなファイルでの検証でしたが、実用的なシーンではファイルサイズや LLM のコンテキストを考慮した設計が必要になってきます。S3 との連携や、必要な部分だけを抽出してコンテキストに渡す仕組みなど、工夫のしがいがありそうです。ファイルの実体はS3に格納して、パスなどの状態をblobとして持たせるのが良さそうに感じました。
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございました!









