グラフ型データベースAmazon Neptuneでレコメンデーション検索を試してみる(後編)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
サーバーレス開発部@大阪の岩田です。
本エントリは「CM大阪盛り上げる会」の「データ分析部」活動の第二段となります。 前回のエントリはこちらです↓
今回は、前回構築したNeptune環境を使って、実際にレコメンデーション処理を試していきたいと思います。 以後はTinkerPop3のドキュメントで紹介されているレシピに準じた形で進めていきます。
Neptuneへのデータロード
まずはテスト用のデータをロードします。 Neptuneへのデータロードは
- ロード対象のデータをS3にUP
- データロード用のNeptuneのエンドポイントにリクエストを発行
という流れで行います。 ロードできるデータの形式は何パターンかあるのですが、今回はクエリ言語にGremlinを選択しているため、「Gremlinロードデータ形式」を使用します。 この形式ではUTF8で
- 頂点(vertex)
- エッジ(Edge)
それぞれCSVファイルを用意します。 頂点(vertex)がいわゆるノードにあたり、エッジ(Edge)がノード間のリレーションにあたります。 今回はユーザー別の購買履歴を表現するために、それぞれ下記のようなCSVファイルを用意しました。
~id, name:String, ~label 1,"alice","person" 2,"bob","person" 3,"jon","person" 4,"jack","person" 5,"jil","person" 6,"product 1","product" 7,"product 2","product" 8,"product 3","product" 9,"product 4","product" 10,"product 5","product" 11,"product 6","product" 12,"product 7","product" 13,"product 8","product" 14,"product 9","product" 15,"product 10","product"
~id, ~from, ~to, ~label 16,1,8,"bought" 17,1,9,"bought" 18,1,10,"bought" 19,1,11,"bought" 20,1,12,"bought" 21,2,6,"bought" 22,2,7,"bought" 23,2,8,"bought" 24,2,9,"bought" 25,2,10,"bought" 26,3,11,"bought" 27,3,12,"bought" 28,3,13,"bought" 29,3,14,"bought" 30,3,15,"bought" 31,4,6,"bought" 32,4,8,"bought" 33,4,10,"bought" 34,4,12,"bought" 35,4,14,"bought" 36,5,7,"bought" 37,5,9,"bought" 38,5,11,"bought" 39,5,13,"bought"
RDBのJOINで表すと下記の様なイメージです。
| user_id | user_name | product_id | product_name |
|---|---|---|---|
| 1 | alice | 8 | product 3 |
| 1 | alice | 9 | product 4 |
| 1 | alice | 10 | product 5 |
| 1 | alice | 11 | product 6 |
| 1 | alice | 12 | product 7 |
| 2 | bob | 6 | product 1 |
| 2 | bob | 7 | product 2 |
| 2 | bob | 8 | product 3 |
| 2 | bob | 9 | product 4 |
| 2 | bob | 10 | product 5 |
| 3 | jon | 11 | product 6 |
| 3 | jon | 12 | product 7 |
| 3 | jon | 13 | product 8 |
| 3 | jon | 14 | product 9 |
| 3 | jon | 15 | product 10 |
| 4 | jack | 6 | product 1 |
| 4 | jack | 8 | product 3 |
| 4 | jack | 10 | product 5 |
| 4 | jack | 12 | product 7 |
| 4 | jack | 14 | product 9 |
| 5 | jil | 7 | product 2 |
| 5 | jil | 9 | product 4 |
| 5 | jil | 11 | product 6 |
| 5 | jil | 13 | product 8 |
可視化すると下記のようなイメージです。 ※可視化にはvis.jsというJSのライブラリを使用しました。
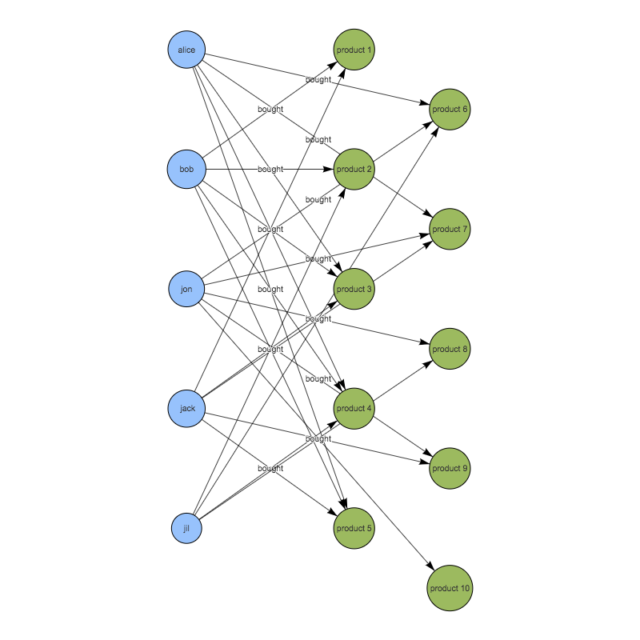
このデータをNeptuneにロードしていきます。
NeptuneへのIAMロールのアタッチ
前述のようにNeptuneへのデータロードはS3を使用します。NeptuneがS3にアクセスできるように前回作成したIAMロールをアタッチします。
aws neptune add-role-to-db-cluster --db-cluster-identifier dbcluster-xxxxxxx --region us-east-1 --role-arn arn:aws:iam::xxxxxxxxxxxx:role/xxxxxxxxxx
これでNeptuneがS3にアクセスできる様になりました。
データロード用エンドポイントへのリクエスト
次にNeptuneのデータロード用エンドポイントに対してリクエストを発行し、データをロードしていきます。 まずはvertex.csvをロードします。
リクエストには読み込み対象のファイルのURI、データロード時に使用するロールのARN等をJSON形式で渡してやります。
[ec2-user@ip-10-0-0-17 ~]$ curl -XPOST -H 'Content-Type: application/json' http://dbcluster-xxxxxx.cluster-xxxxxx.us-east-1.neptune.amazonaws.com:8182/loader -d '{
"source" : "s3://neptune-s3bucket-xxxxxx/vertex.csv",
"format" : "csv",
"iamRoleArn" : "arn:aws:iam::xxxxxxxxxx:role/neptune-NeptuneRole-xxxxxxxx",
"region" : "us-east-1",
"failOnError" : "FALSE"
}'
{
"status" : "200 OK",
"payload" : {
"loadId" : "xxxxxx"
}
}
srouceは先ほどS3バケットにUPしたCSVファイルのURIを、iamRoleArnは前回のエントリでNeptuneにアタッチしたIAMロールのArnをセットします。
同様にedge.csvをロードします。
[ec2-user@ip-10-0-0-17 ~]$ curl -XPOST -H 'Content-Type: application/json' http://dbcluster-xxxxxxxx.cluster-xxxxxxxx.us-east-1.neptune.amazonaws.com:8182/loader -d '{
"source" : "s3://neptune-s3bucket-xxxxxxxx/edge.csv",
"format" : "csv",
"iamRoleArn" : "arn:aws:iam::xxxxxxxxxxxx:role/neptune-NeptuneRole-xxxxxxxx",
"region" : "us-east-1",
"failOnError" : "FALSE"
}'
{
"status" : "200 OK",
"payload" : {
"loadId" : "xxxxxx"
}
}
ステータスの確認
ロードのリクエストを投げたら、ステータスを確認します。 先ほどロードのリクエストを発行した際に戻って来たloadIdを指定して、ローダーステータス取得用のエンドポイントにアクセスします。
[ec2-user@ip-10-0-0-17 ~]$ curl http://dbcluster-xxxxxxx.cluster-xxxxxxx.us-east-1.neptune.amazonaws.com:8182/loader?loadId=xxxxxx
{
"status" : "200 OK",
"payload" : {
"feedCount" : [
{
"LOAD_COMPLETED" : 1
}
],
"overallStatus" : {
"fullUri" : "s3://neptune-s3bucket-xxxxxxx/vertex.csv",
"runNumber" : 1,
"retryNumber" : 0,
"status" : "LOAD_COMPLETED",
"totalTimeSpent" : 3,
"totalRecords" : 30,
"totalDuplicates" : 0,
"parsingErrors" : 0,
"datatypeMismatchErrors" : 0,
"insertErrors" : 0
}
}
}
[ec2-user@ip-10-0-0-17 ~]$curl http://dbcluster-xxxxxxx.cluster-xxxxxxx.us-east-1.neptune.amazonaws.com:8182/loader?loadId=xxxxxxx
{
"status" : "200 OK",
"payload" : {
"feedCount" : [
{
"LOAD_COMPLETED" : 1
}
],
"overallStatus" : {
"fullUri" : "s3://neptune-s3bucket-xxxxxxx/edge.csv",
"runNumber" : 1,
"retryNumber" : 0,
"status" : "LOAD_COMPLETED",
"totalTimeSpent" : 3,
"totalRecords" : 25,
"totalDuplicates" : 0,
"parsingErrors" : 0,
"datatypeMismatchErrors" : 0,
"insertErrors" : 0
}
}
}
LOAD_COMPLETEDと表示されていればロード完了です!
レコメンデーション検索
データのロードができたら実際にレコメンデーション検索を試していきます。 前回紹介した手順でNeptuneに接続、クエリを発行していきます。
1. aliceが購入したことのある商品一覧を検索
gremlin> g.V().has('name','alice').out('bought').values('name')
==>product 3
==>product 4
==>product 5
==>product 6
==>product 7
RDBだとこんなイメージです。
| user_id | user_name | product_id | product_name |
|---|---|---|---|
| 1 | alice | 8 | product 3 |
| 1 | alice | 9 | product 4 |
| 1 | alice | 10 | product 5 |
| 1 | alice | 11 | product 6 |
| 1 | alice | 12 | product 7 |
可視化するとこんなイメージです。
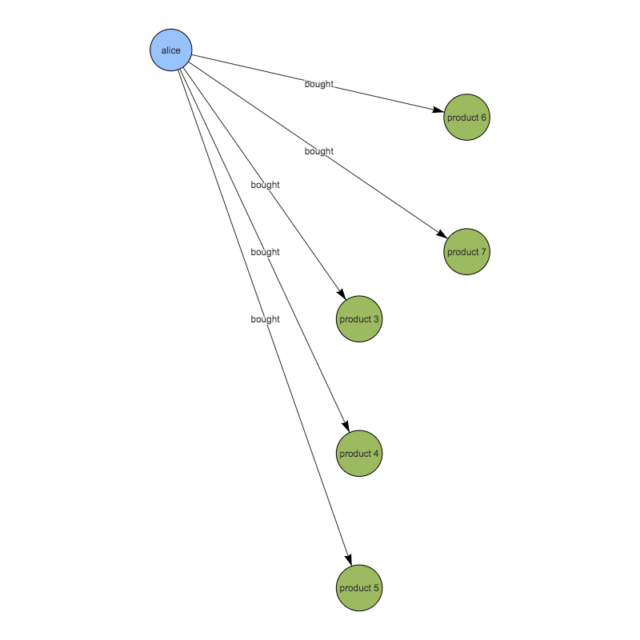
2. 1.で抽出した商品を購入したことがある人を検索 ※ただしalice本人は除く
g.V().has('name','alice').as('her').
out('bought').
in('bought').where(neq('her')).
values('name')
==>bob
==>jack
==>bob
==>jil
==>bob
==>jack
==>jon
==>jil
==>jon
==>jack
RDBだとこんな感じ
| user_id | user_name | product_id | product_name | user_id2 | user_name2 |
|---|---|---|---|---|---|
| 1 | alice | 8 | product 3 | 2 | bob |
| 1 | alice | 8 | product 3 | 4 | jack |
| 1 | alice | 9 | product 4 | 2 | bob |
| 1 | alice | 9 | product 4 | 5 | jil |
| 1 | alice | 10 | product 5 | 2 | bob |
| 1 | alice | 10 | product 5 | 4 | jack |
| 1 | alice | 11 | product 6 | 3 | jon |
| 1 | alice | 11 | product 6 | 5 | jil |
| 1 | alice | 12 | product 7 | 3 | jon |
| 1 | alice | 12 | product 7 | 4 | jack |
可視化するとこんな感じ
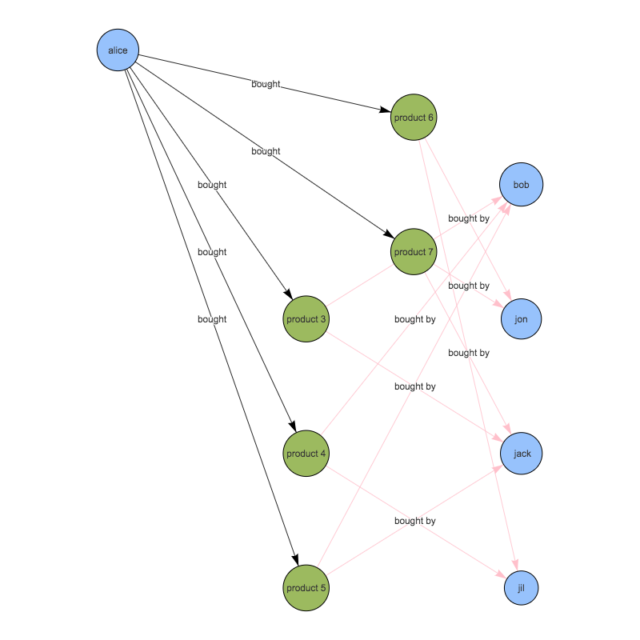
この検索結果を見ると、bobとjackが3件、jilとjonは2件抽出されています。 bobとjackの方がjilとjonよりもaliceと嗜好が近いと分析できます。 よって、jil・jonが購入している商品よりもbob・jackが購入している商品の方が、よりaliceに対してオススメできる。と考えられます。
3. 2.で抽出した人たちが購入したことのある商品を検索
g.V().has('name','alice').as('her').
out('bought').
in('bought').where(neq('her')).
out('bought').
dedup().values('name')
==>product 1
==>product 2
==>product 3
==>product 4
==>product 5
==>product 7
==>product 9
==>product 6
==>product 8
==>product 10
RDBだと、、、長くなるのでやめます。 可視化するとこんな感じ
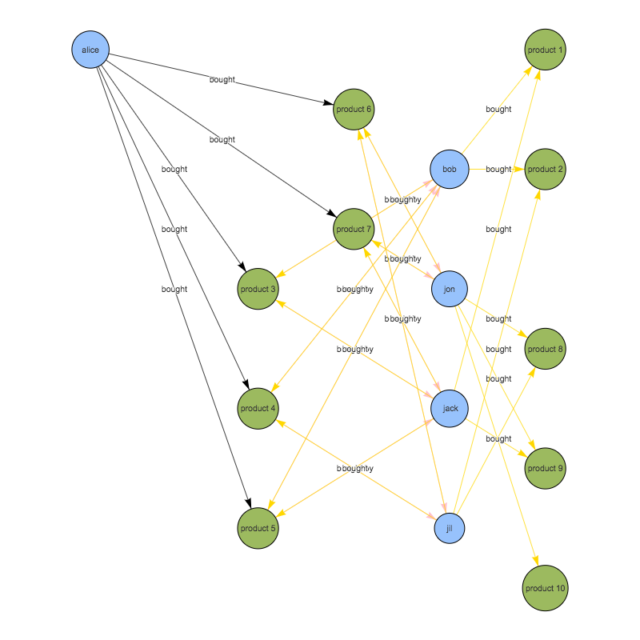
4. 3.で抽出した商品から、aliceが購入したことのある商品を除外
g.V().has('name','alice').as('her').
out('bought').aggregate('self').
in('bought').where(neq('her')).
out('bought').where(without('self')).
dedup().values('name')
==>product 1
==>product 2
==>product 9
==>product 8
==>product 10
可視化するとこんな感じ
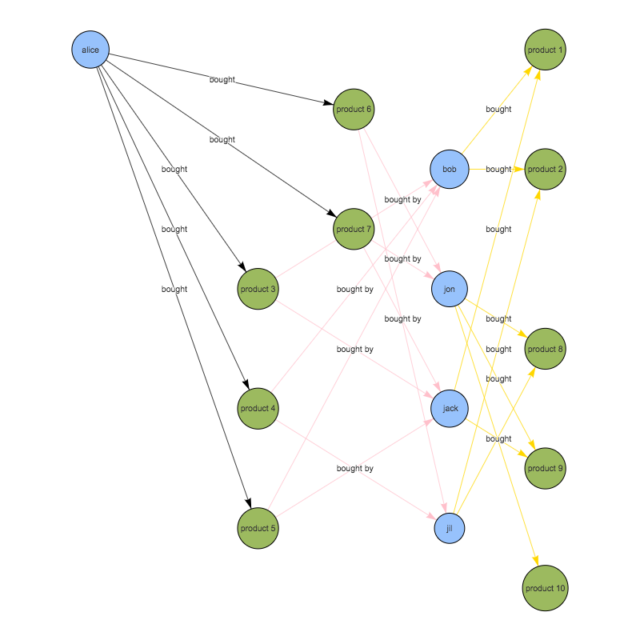
3との違いが分かりづらいですが、Product 3〜7に戻ってくる矢印が無くなっています。
5. 4.で抽出した商品を件数でソート
g.V().has('person','name','alice').as('her').
out('bought').aggregate('self').
in('bought').where(neq('her')).
out('bought').where(without('self')).
groupCount().
order(local).
by(values, decr)
==>{v[6]=6, v[14]=5, v[7]=5, v[13]=4, v[15]=2}
これでaliceに対するオススメ商品の一覧が完成です。 一番オススメなのはID:6のproduct 1となりました。 下記のイメージを見ていただくと分かるのですが、aliceからproduct 1に到達するための経路は6通りと最多になっているからです。
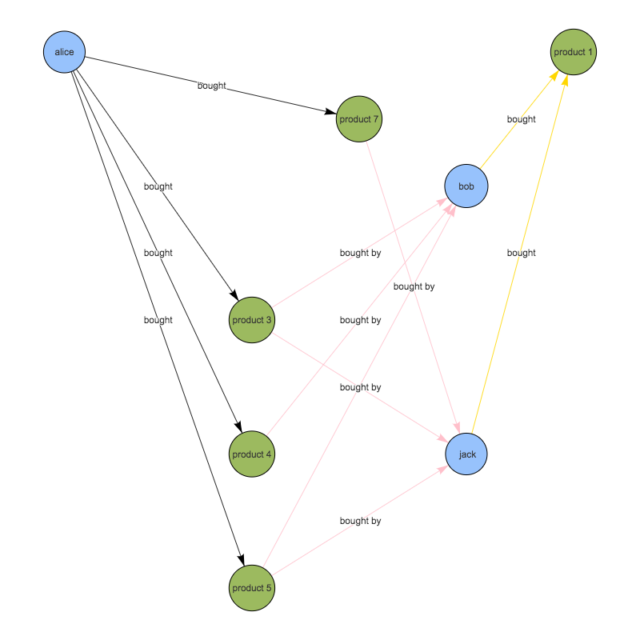
どの商品も「alice以外に2人から購入されている」という点は同じなのですが、product 1を他の商品と比較すると、aliceと嗜好の近いbob・jackが購入していることが決め手となりました。
まとめ
前・後編と2回に分けてNeptuneを触ってみましたが、クエリ言語のGremlinに馴染みが無かったので色々と苦労しました。 GremlinやNeptuneはまだまだ日本語の情報が少ないので、このエントリが誰かのお役に立てばと思います。
Neptuneを触ってみて個人的におもしろいなと思ったのが、データのロードにS3を使用している点です。 例えばですが、夜間バッチでRDSやDynamoDBからデータを抽出してS3にUP S3へのUPをトリガにLambdaが起動してNeptuneへのにデータロードを起動、さらに後続の分析処理を起動して... といった使い方ができるのかなと思いました。
今後もしっかりとNeptuneの動向を追いかけていきたいと思います!








