
第6回 Elasticsearch 入門 基本コンセプトを理解する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
第6回 Elasticsearch 入門 基本コンセプト
これまでの記事でも Cluster や Node を始めとする Elasticsearch を構成する要素について触れているのですが、 文章だけでは理解しづらいところもあるので、今回は改めて Elasticsearch の基本コンセプトについて図も交えて解説したいと思います。
それではさっそく。
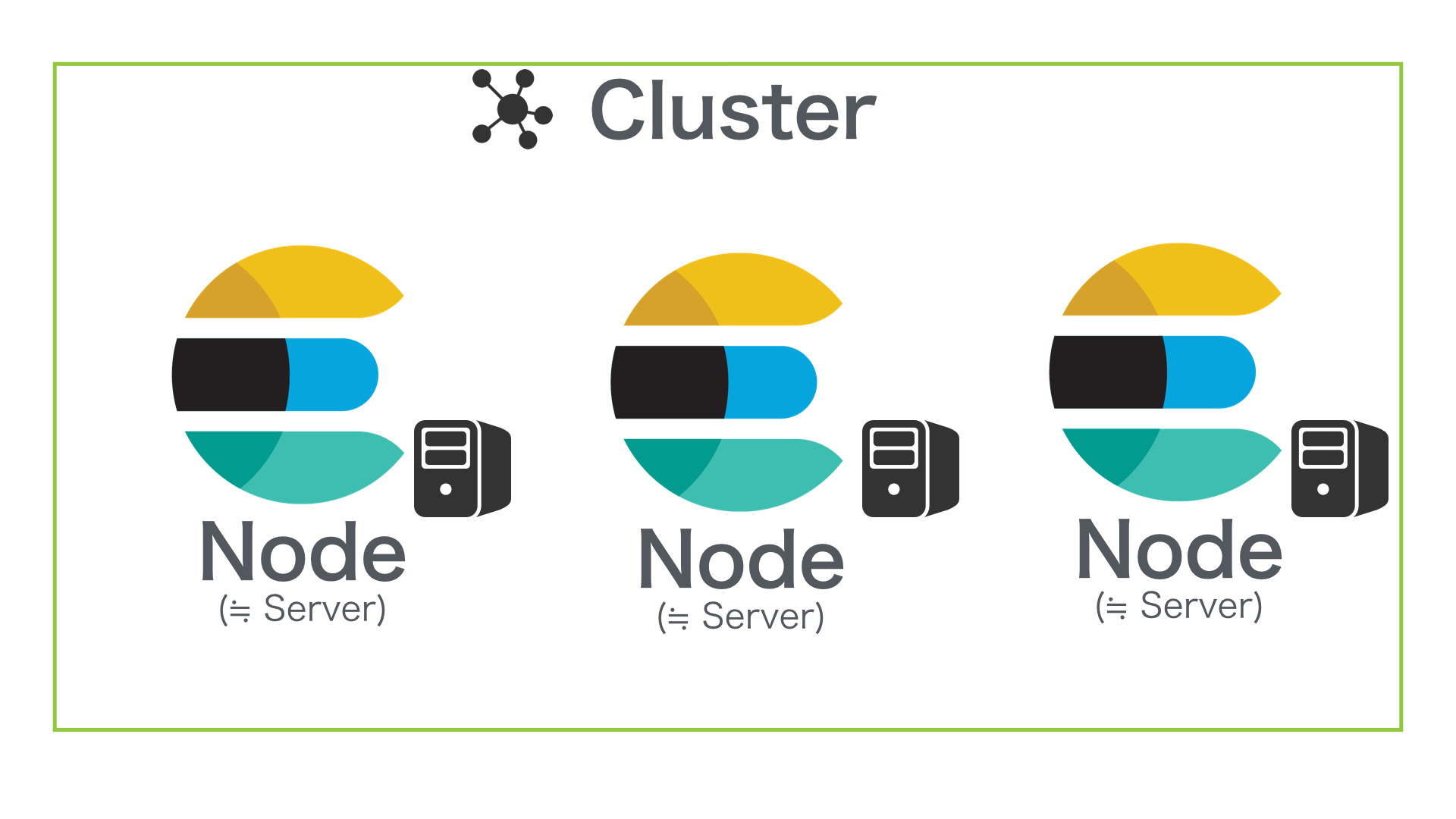
Cluster は Node の集合
Cluster は 1つ以上の Node (Elasticsearch Server) で構成されます。Elasticsearch は検索トラフィックの増加とデータ量や書き込み速度の分散を Node を増やすことで対応することができます。
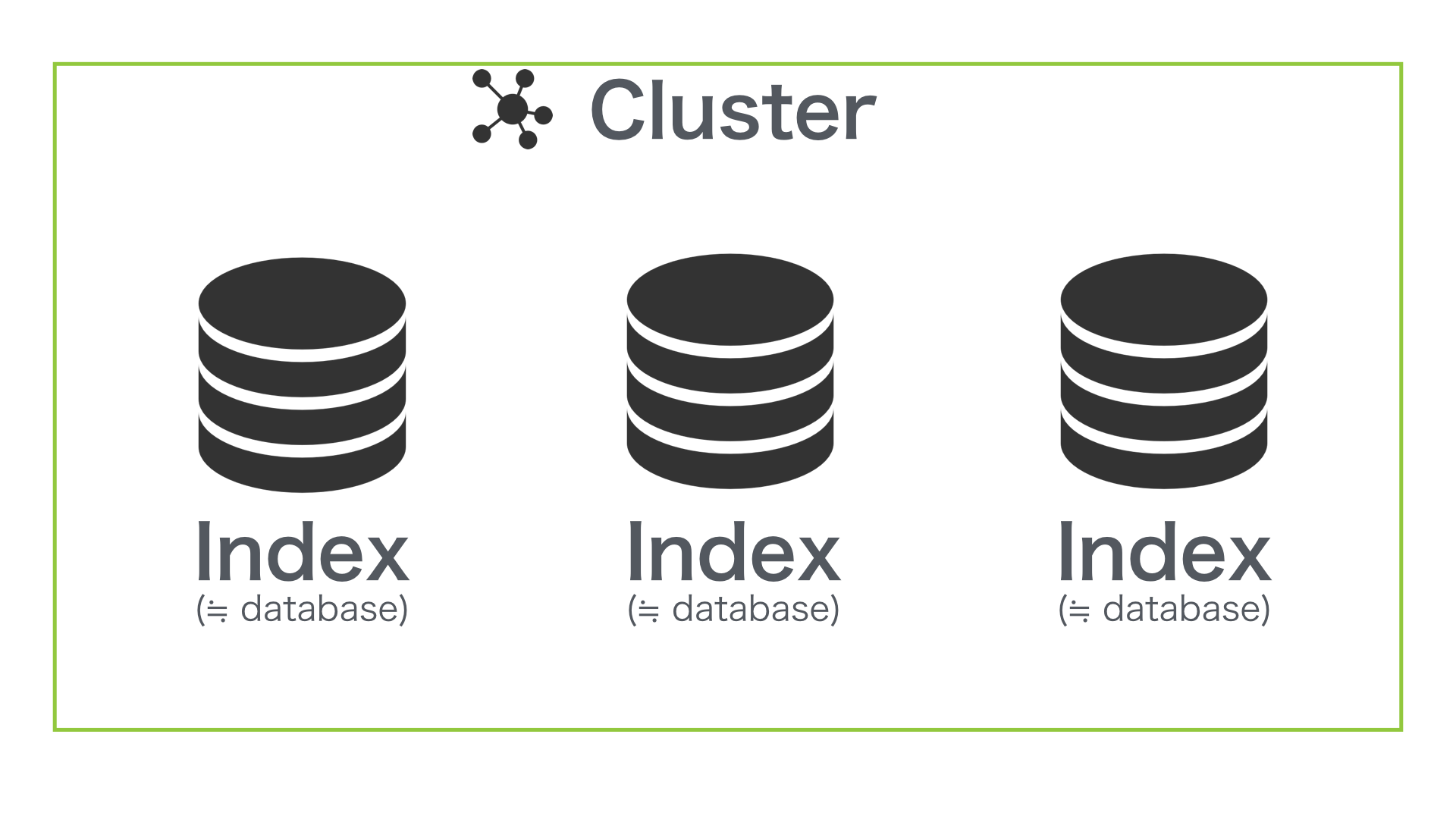
Index は RDB の Database に近い概念
Elasticsearch の Index は、リレーショナル・データベースの Database に相当します。1つの Cluster に複数の Index を作成することができます。また、コンテンツの分析方法などはこの単位で個別に定義することが可能です。
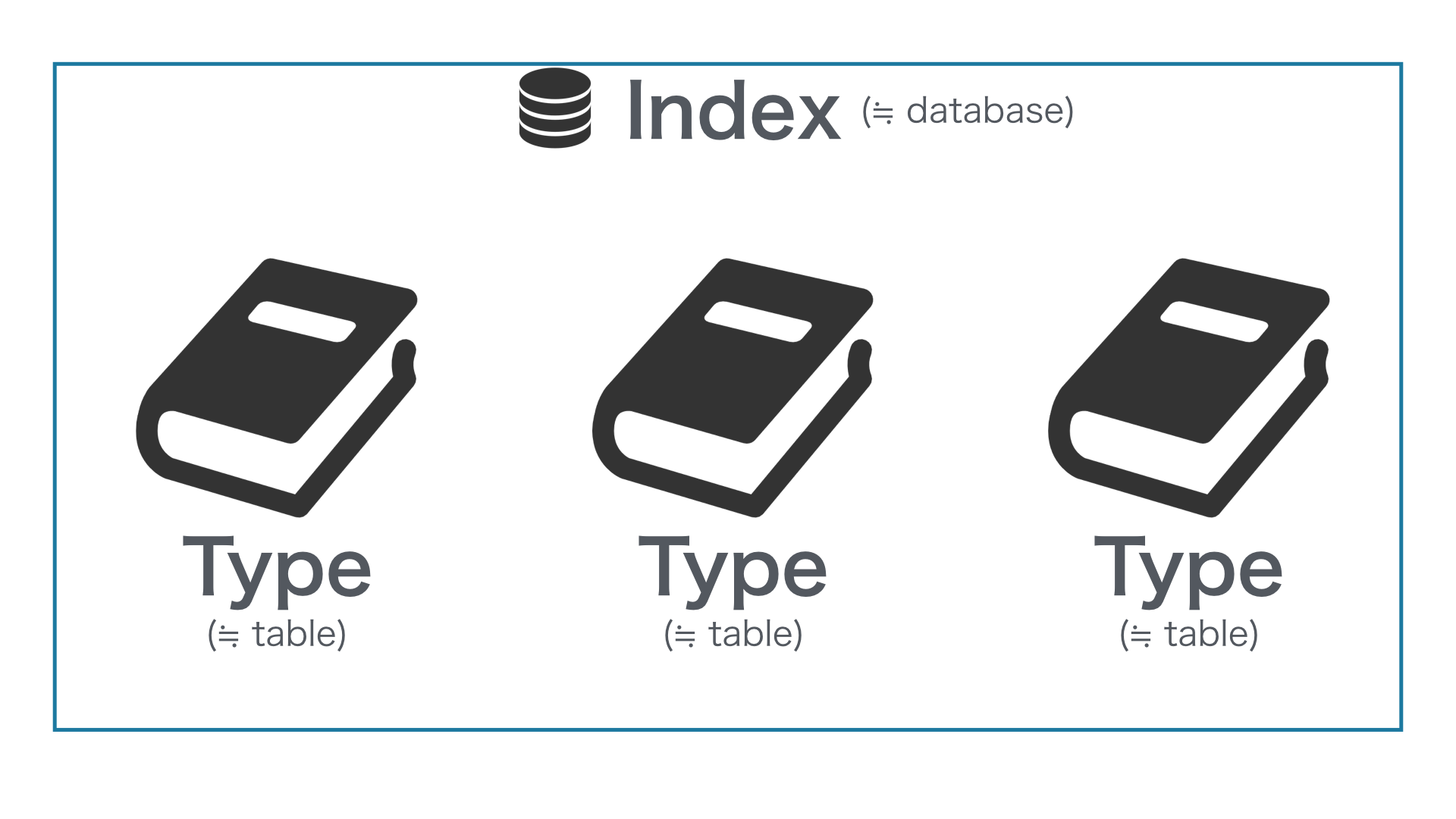
Type は RDB の Table に近い概念
Elasticsearch の Type は、リレーショナル・データベースの Table に相当します。1つの Index に複数の Type を作成することができます。インデックスするデータフィールドの型や分析方法はこの単位で定義することが可能です。
ただ、このあと説明する Shard との兼ね合いもあるので、Type を分ける場合は Index レベルで分けてしまう設計の方が多いような気がします。また、フィールドマッピングのコンフリクトの問題もあり、Type が異なる場合でも、同じ Index 内のすべてのフィールドは同じ Mapping を持つというルールが採用されました。そのため、Type の代わりに Index を別々に作成するように設計することで、よりデータベースのテーブルのように扱うことができます。
Document は RDB の Row に近い概念
Elasticsearch の Document は、リレーショナル・データベースの Row に相当します。Document は複数の Field を持っていて、フラットな情報だけでなく、ネストされた情報も表現できます。JSON フォーマットで表現出来る情報をストアできるという理解でよいでしょう。
また、Document は Type 内で一意識別可能な ID を持ちます。これは、登録する際に指定するともできますし、自動で割り振ることも可能です。

1つの Index はパフォーマンスを分散できるように 複数の Shard から構成される。
1つの Index を作成すると、そのパフォーマンスを分散できるように複数の Shard が作成されます。それはちょうど OS 上のディレクトリと RAID で構成されたハードディスクの関係に近いイメージです。
デフォルトでは、5つの Primary Shard (書き込み可能な Shard) と それと対になる 1つの Replica Shard (読み取り専用) が作成されます。
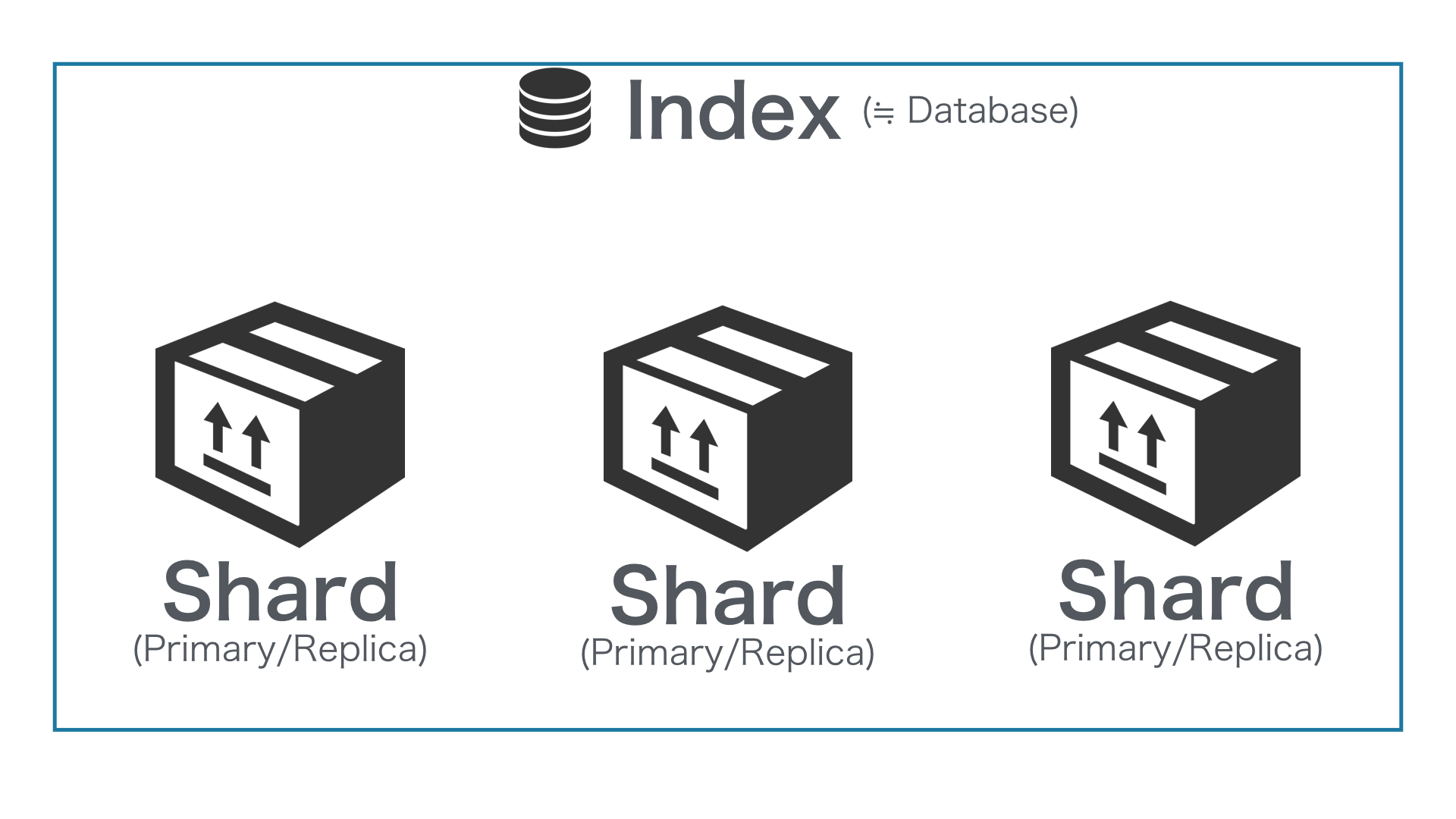
Index は論理的な概念、Shard は物理的な概念
Index は、データを管理する論理的な概念です。API を使用して、Document をインデックスしたり、検索するのはこの Index に対して実行されます。一方 Shard は、その Index を各 Node へ分散して配置するための物理的な概念です。
物理的に Index を各 Node へ分散配置することで、サーバのリソース (CPU、Memory、Disk IO) を分散することができる仕組みなっています。
もちろん1つの Node でも、Shard が配置されるハードディスクを変更したり、RAID 構成にすることで、Index の書き込み速度を向上することもできます。
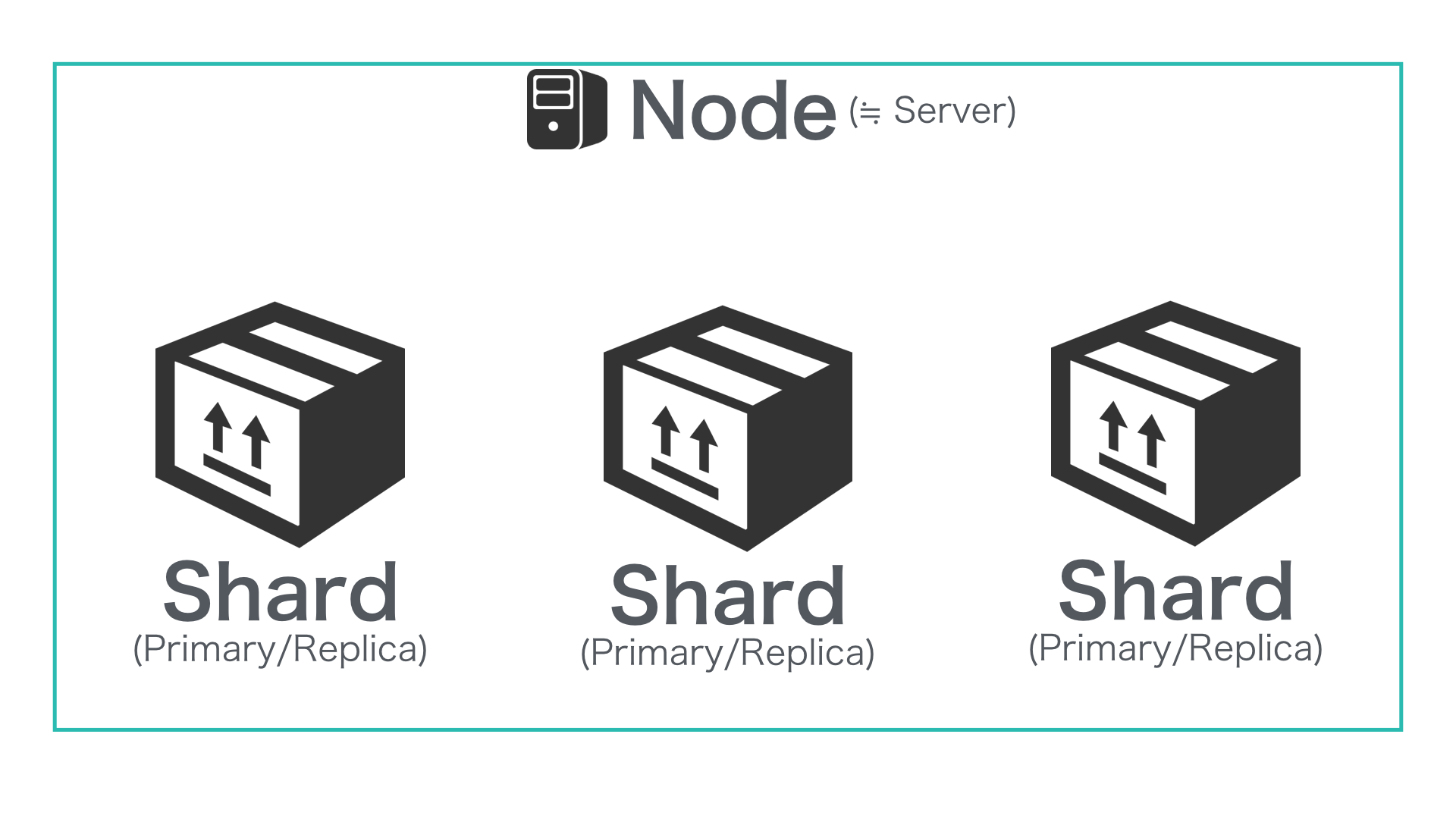
Replica Shard は Primary Shard と同じ Node には配置されない
1つの Node で構成される Elasticsearch に Primary Shard 3 & Replica Shard 1 という設定で Index を作成してみましょう。
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
すると Shard の配置は以下図のように Shard #0 〜 #2 の3つの Primary Shard のみが配置されます。
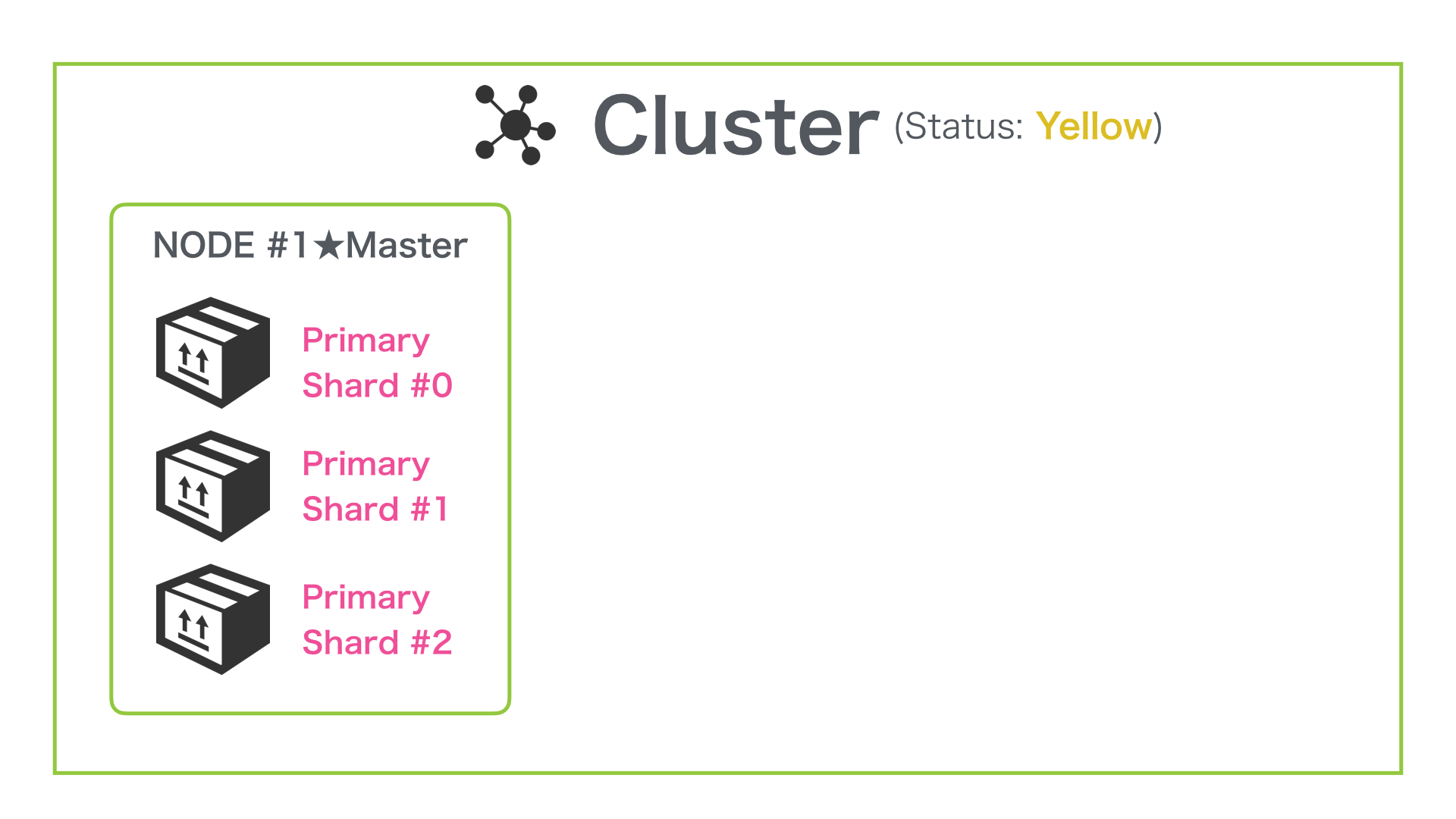
これは、Primary Shard とそれと対になる Replica Shard は同じ Node には配置されないためです。
この状態での Cluster のステータスは Yellow です。(※ 特にインデックスや検索ができないというわけではありません。単に Replica Shard が 1 で設定されているのに、それを配置できないため Yellow になっています。)
Node を増やせば Shard が自動で再配置される
シングル Node からもうひとつ Node を増やして 2 Node 構成にすることで、これまで配置されていなかった Replica Shard は以下の図のように自動的に配置されます。
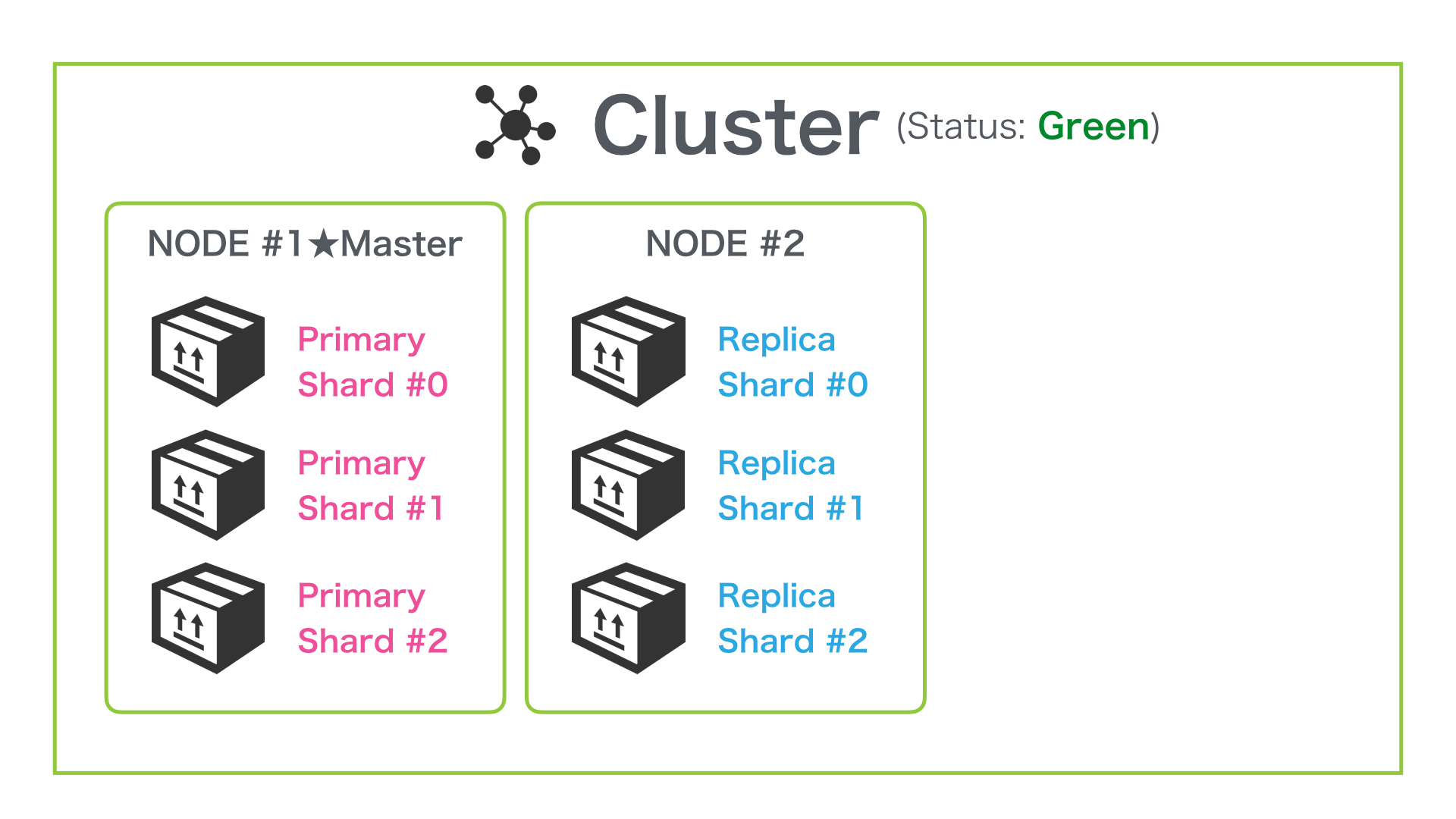
この状態での Cluster のステータスは Green に変わります。設定した Shard 全てが各 Node に配置されたためです。
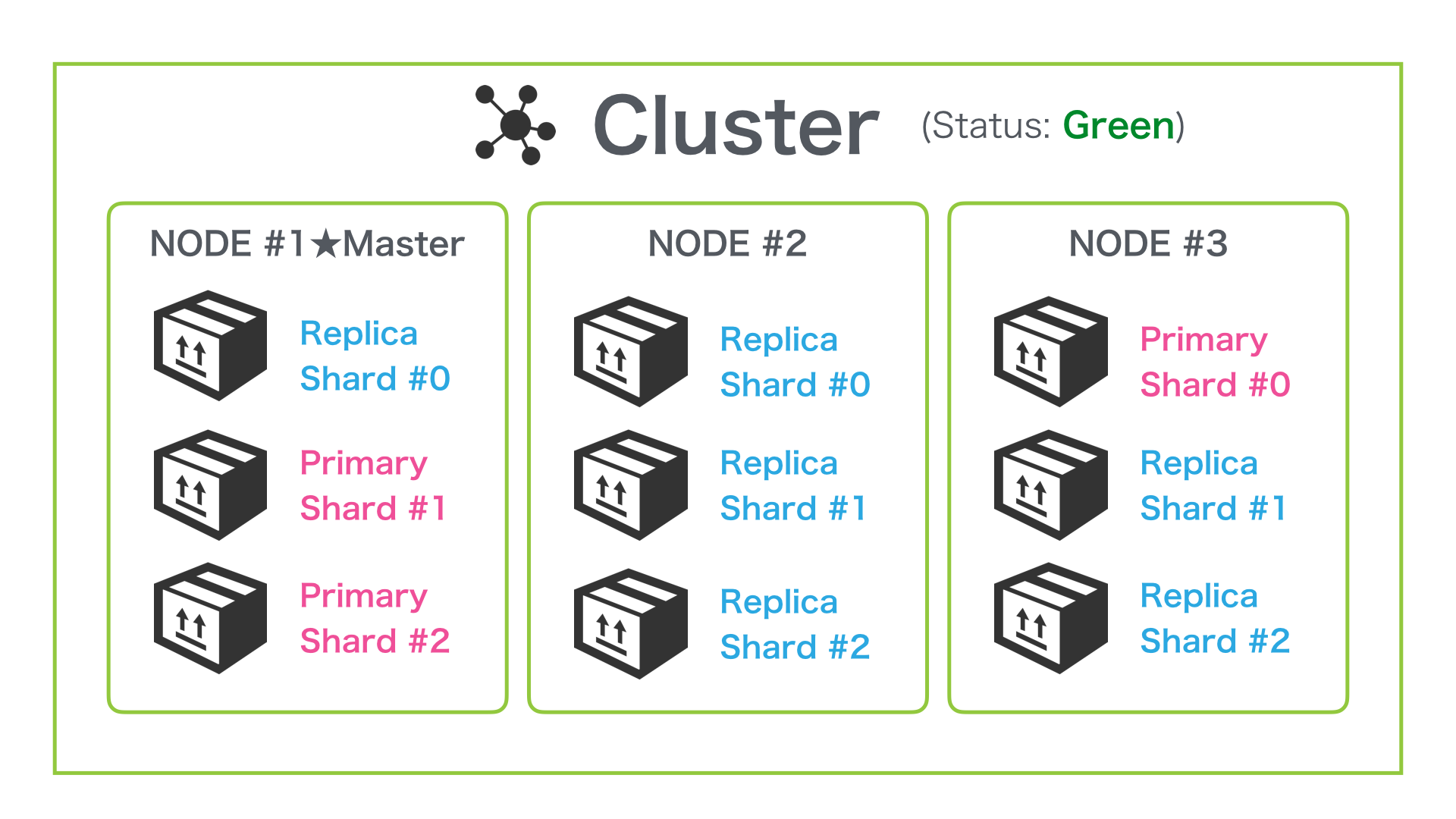
さらに Node を増やしても Shard が分散配置される
もう一つ Node を増やして 3 Node 構成にしてもさらに Shard が分散配置されて以下の図のように自動的に配置されます。
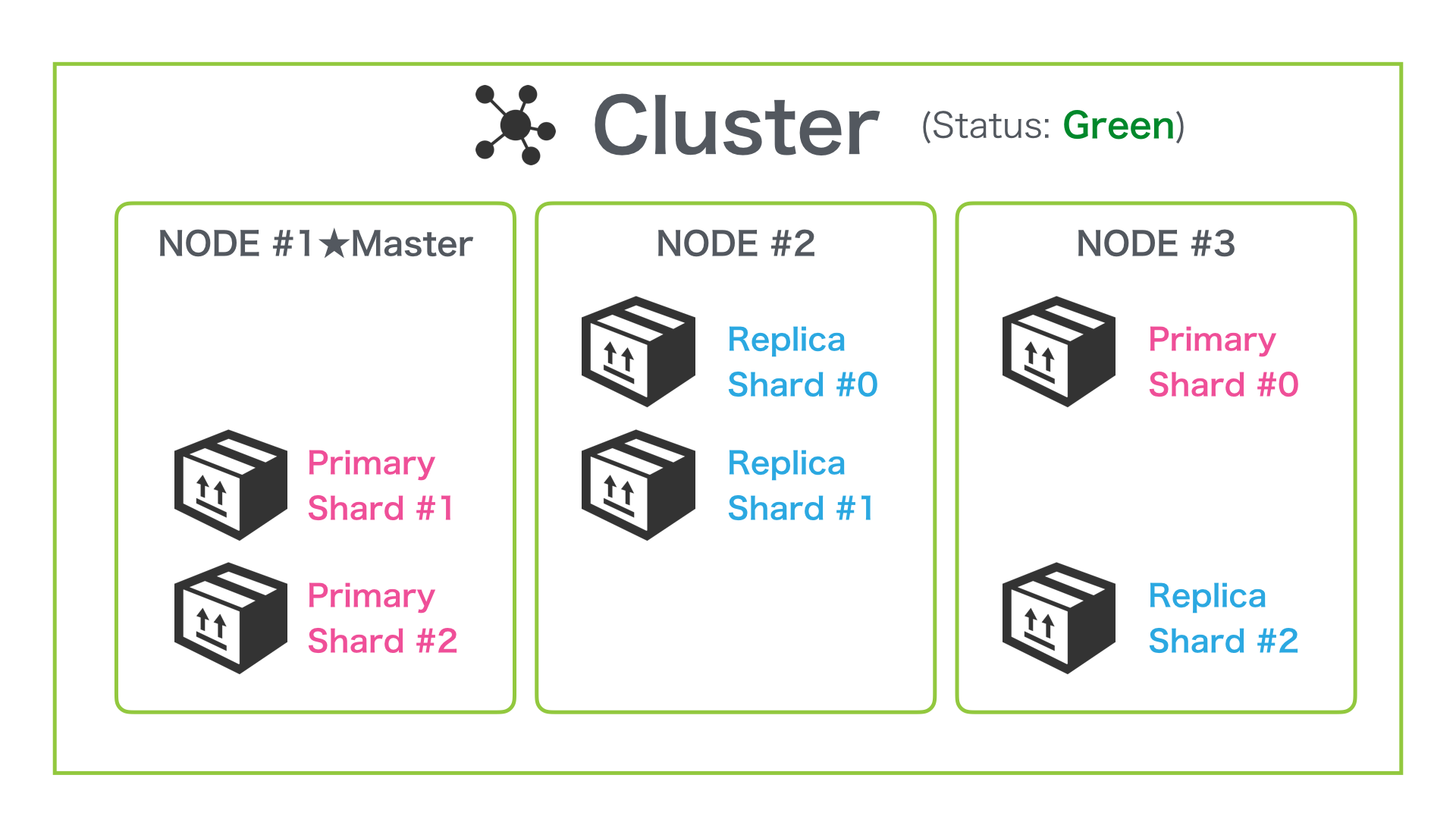
Primary と Replica 合計で、6つの Shard から構成されているため、この Index の設定では、最大で Node を6台まで増やしてリソース (CPU, RAM, I/O) を分散することが可能です。
Replica Shard の数はいつでも変更できる
Primary Shard の数は Index 作成時に固定れます。つまり、Index 作成後は Primary Shard の数は変更できません。
Replica Shard の数はいつでも変更できます。Replica の数を 1 から 2 に変更してみましょう。
PUT /blogs/_settings
{
"number_of_replicas": 2
}
変更すると、以下の図のように 3つの Primary Shard と 6つの Replica Shard が配置されます。
1つの Node につき 1 Shard で構成すると、最大9つの Node で構成することができ、もとの 3 Node に比べ約3倍のパフォーマンスを得ることが可能です。
まとめ
Elasticsearch を理解する上で、今回解説した内容は必ず押さえておきたいところです。わからなくなったらまたこの記事を見直してください。
次回は、ハンズオン形式で Elasticsearch の API の使い方を解説したいと思います。










