![[iOS 11] 画像解析フレームワークVisionで顔認識を試した結果](https://devio2023-media.developers.io/wp-content/uploads/2017/09/400x400_ios11_vision.png)
[iOS 11] 画像解析フレームワークVisionで顔認識を試した結果
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Vision
この記事ではiOS 11 SDKから利用可能なフレームワークのVisionについて解説します。Vision は、高性能な画像解析フレームワークであり、オブジェクトの検出・追跡・分類などに対応しています。
この名称は、画像処理に関する研究分野Computer Visionに由来しています。
iOS 11ではCore MLというフレームワークも新たに登場しました。こちらはML(Machine Learning:機械学習)に特化したフレームワークで、VisionのバックグラウンドではCore MLが利用されています。つまりVisionは機械学習のうち、画像処理に特化したフレームワークであると言えるでしょう。
Core MLに関しては こちらの記事 をご覧ください。
機能
以下、WWDC17においてVision に関するキーノートで紹介された機能です。
顔検出
画像内に存在する顔を検出します。

また、以下のような状況にも対応しています。
小さい顔

横顔

部分的閉塞

帽子やサングラス

顔ランドマーク検出
顔の中の特徴的な部分(ランドマーク)である目・鼻・口・眉毛・輪郭などを検出します。



画像レジストレーション
画像レジストレーションとは複数のデータを1つの座標系に変換する技術のことです。これを使ってパノラマ画像を作成することもできるようです。

矩形検出
画像内に存在する特定の矩形を検出します。

バーコード検出
QRコードやバーコードを検出します。
余談ですが、iOS 11のカメラアプリでは標準でQRコードを検出できます。

テキスト検出
テキストの検出も可能です。

オブジェクトトラッキング
オブジェクトトラッキングにも対応しています。

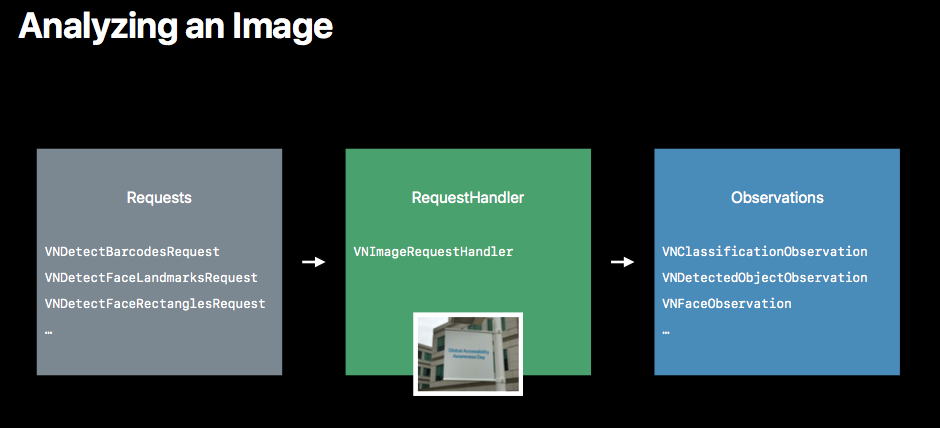
画像の解析
解析のプロセスでは以下の3つのクラスが登場します。
- Request
- RequestHandler
- Observation
Request
ある画像に対しどのような要求を行うかを表すクラスです。
以下のように要求に応じて対応するクラスが存在します。
- 顔検出
- VNDetectFaceRectanglesRequest
- 顔ランドマーク検出
- VNDetectFaceLandmarksRequest
- 画像レジストレーション
- VNImageRegistrationRequest
- 矩形検出
- VNDetectRectanglesRequest
- バーコード検出
- VNDetectBarcodesRequest
- テキスト検出
- VNDetectTextRectanglesRequest
- オブジェクトトラッキング
- VNTrackObjectRequest
RequestHandler
上記Requestを処理(ハンドル)するクラスです。画像やデータを保持し、解析処理を実行します。
- VNImageRequestHandler
トラッキングや画像レジストレーションの場合は以下のとおりです。
- VNSequenceRequestHandler
処理実行時には複数のRequestを設定することも可能です。
例)バーコード検出 + テキスト検出
Observation
観測結果を表すクラスです。Request同様、こちらも要求に対して対応するクラスが存在します。
- 顔検出
- VNFaceObservation
- 顔ランドマーク検出
- VNFaceObservation
- 画像レジストレーション
- VNImageAlignmentObservation
- 矩形検出
- VNRectangleObservation
- バーコード検出
- VNBarcodeObservation
- テキスト検出
- VNTextObservation
- オブジェクトトラッキング
- VNDetectedObjectObservation
顔検出と顔ランドマーク検出のObservationが同じですが、後者では結果にlandmarksというプロパティが付与されています。
実践
それでは実際に顔検出を行ってみましょう。使用する画像はこちらです。

3年前の入社したての頃の写真で、一番右が私。この画像nakayosi@2x.pngに対して処理を実行してみます。
サンプルコード(顔検出)
import Vision
private let originalImage = UIImage(named: "nakayosi")
func faceDetection() {
let request = VNDetectFaceRectanglesRequest { (request, error) in
for observation in request.results as! [VNFaceObservation] {
print(observation)
}
}
if let cgImage = self.originalImage?.cgImage {
let handler = VNImageRequestHandler(cgImage: cgImage, options: [:])
try? handler.perform([request])
}
}
結果はこちら。
<VNFaceObservation: 0x604000182700> 68149739-D1B0-4E89-8FB2-44F33969FAED 1 [0.557461 0.616566 0.069802 0.0930694] ID=0 <VNFaceObservation: 0x6040001828a0> D113842C-B9CA-4D70-88CE-74814860D383 1 [0.722581 0.400897 0.0740046 0.0986728] ID=0 <VNFaceObservation: 0x600000182e50> 69A72E48-0270-4687-B0B4-4F57A8E5DEA3 1 [0.28446 0.639232 0.0771421 0.102856] ID=0
観測結果は3つ。どうやら3人の顔が検出できたようですね。
解説
4行目で顔検出用のRequestを生成しています。引数は処理完了後に実行されるクロージャです。
let request = VNDetectFaceRectanglesRequest { (request, error) in
}
5〜7行目で観測結果を出力しています。観測結果はObservationの配列となっており、複数の要素が返ることがあります。
(5つの顔が検出された場合は要素数5の配列)
for observation in request.results as! [VNFaceObservation] {
print(observation)
}
10行目ではUIImageをCGImageに変換しています。
if let cgImage = self.originalImage?.cgImage {
}
Visionでサポートされている画像の型は以下の通りで、UIImageを利用する際はいずれかの型に変換する必要があります。
- CVPixelBufferRef
- CGImageRef
- CIImage
- NSURL
- NSData
11行目では画像データを渡し、RequestHandlerを生成しています。
let handler = VNImageRequestHandler(cgImage: cgImage, options: [:])
12行目で顔検出処理を実行しています。引数はRequestの配列なので、複数の要求がある場合はここに追加することになります。
try? handler.perform([request])
観測結果の1つに着目してみましょう。
<VNFaceObservation: 0x6040001828a0> D113842C-B9CA-4D70-88CE-74814860D383 1 [0.722581 0.400897 0.0740046 0.0986728] ID=0
この中には[0.722581 0.400897 0.0740046 0.0986728]という値(変数名boundingBox)が含まれており、これが顔が検出された矩形となります。
原点 = (0.722581, 0.400897)
サイズ = (0.0740046, 0.0986728)
どちらも画像サイズに対する比率です。
なお、観測結果として返ってくる値の座標系は原点 (0, 0) が画像左下であり、正の方向が画像右上となっています。
UIKit の座標系は原点 (0, 0) が左上、正の方向が右下なので、UIKitのコンポーネントにマッピングする際はY軸を反転させることを忘れないように注意しましょう。
わかったこと
Visionでできることは
- Requestを生成する
- 画像データを渡しRequestHandlerを生成する
- RequestHandlerにRequestを渡し、解析処理を実行する
- Observationから観測結果を得る
という一連の処理だけです。 つまり、観測結果を画像に描画したりカメラを利用してリアルタイムに解析するという処理を行いたい場合は自前で実装する必要があります。
サンプルコード(顔検出 + 結果の描画)
ということで、やってみましょう。
Appleのサンプルにならって、検出した矩形を緑の枠で囲ってみます。
ViewController.swift
import Vision
private let originalImage = UIImage(named: "nakayosi") @IBOutlet weak var imageView: UIImageView!
func faceDetection() {
let request = VNDetectFaceRectanglesRequest { (request, error) in
var image = self.originalImage
for observation in request.results as! [VNFaceObservation] {
image = self.drawFaceRectangle(image: image, observation: observation)
}
self.imageView.image = image
}
if let cgImage = self.originalImage?.cgImage {
let handler = VNImageRequestHandler(cgImage: cgImage, options: [:])
try? handler.perform([request])
}
}
private func drawFaceRectangle(image: UIImage?, observation: VNFaceObservation) -> UIImage? {
let imageSize = image!.size
UIGraphicsBeginImageContextWithOptions(imageSize, false, 0.0)
let context = UIGraphicsGetCurrentContext()
image?.draw(in: CGRect(origin: .zero, size: imageSize))
context?.setLineWidth(4.0)
context?.setStrokeColor(UIColor.green.cgColor)
context?.stroke(observation.boundingBox.converted(to: imageSize))
let drawnImage = UIGraphicsGetImageFromCurrentImageContext()
UIGraphicsEndImageContext()
return drawnImage
}
extension CGRect {
func converted(to size: CGSize) -> CGRect {
return CGRect(x: self.minX * size.width,
y: (1 - self.maxY) * size.height,
width: self.width * size.width,
height: self.height * size.height)
}
}
結果はこちら。

うまく描画できましたね。
解説
まず画面いっぱいにUIImageViewを設置しました。ここに描画結果を表示します。
@IBOutlet weak var imageView: UIImageView!
faceDetection()メソッドで前述のサンプルコードから変更があった箇所はRequest生成時に引数として渡すクロージャだけです。
let request = VNDetectFaceRectanglesRequest { (request, error) in
var image = self.originalImage
for observation in request.results as! [VNFaceObservation] {
image = self.drawFaceRectangle(image: image, observation: observation)
}
self.imageView.image = image
}
Observationの数だけオリジナルの画像に顔の矩形を描画し、最終的にできあがった画像を画面に表示します。ここで呼び出しているメソッドが以下のdrawFaceRectangle()です。
private func drawFaceRectangle(image: UIImage?, observation: VNFaceObservation) -> UIImage? {
let imageSize = image!.size
UIGraphicsBeginImageContextWithOptions(imageSize, false, 0.0)
let context = UIGraphicsGetCurrentContext()
image?.draw(in: CGRect(origin: .zero, size: imageSize))
context?.setLineWidth(4.0)
context?.setStrokeColor(UIColor.green.cgColor)
context?.stroke(observation.boundingBox.converted(to: imageSize))
let drawnImage = UIGraphicsGetImageFromCurrentImageContext()
UIGraphicsEndImageContext()
return drawnImage
}
ここではCore Graphicsを利用して描画処理を行いました。
描画の方法は色々あると思うので、そこはお好みで。
まずはコンテキストに引数で渡された画像をそのまま描画します。
次に矩形を描画するために線の太さと色を設定します。ここではそれぞれ4.0と緑色にしました。
そして、最後にstroke()メソッドで顔の矩形を描画しています。ここで引数にCGRectを渡していますが、CGRectのextensionとして追加したconverted()メソッドで座標の変換を行っています。
extension CGRect {
func converted(to size: CGSize) -> CGRect {
return CGRect(x: self.minX * size.width,
y: (1 - self.maxY) * size.height,
width: self.width * size.width,
height: self.height * size.height)
}
}
Observationに含まれる値は画像サイズに対する比率でした。
よってそれぞれ幅と高さを掛けることにより画像内での座標を求めています。
またこのとき座標系をUIKitに合わせるためにY軸の反転も行っています。
サンプルコード(オブジェクトトラッキング)
次はリアルタイムでの顔検出がうまくできなかったので、オブジェクトトラッキングを行ってみましょう。
カメラを利用して、タップで選択したオブジェクトを追跡します。
少し長いですが全コードを記載します。
カメラを利用するため、Info.plistにNSCameraUsageDescriptionを追記することをお忘れなく。
<key>NSCameraUsageDescription</key> <string>Use the camera.</string>
ViewController.swift
import UIKit
import AVFoundation
import Vision
class ViewController: UIViewController, AVCaptureVideoDataOutputSampleBufferDelegate {
private let session = AVCaptureSession()
private var previewLayer: AVCaptureVideoPreviewLayer! = nil
private var handler = VNSequenceRequestHandler()
private var currentTarget: VNDetectedObjectObservation?
private var lockOnLayer = CALayer()
override func viewDidLoad() {
super.viewDidLoad()
setup()
}
override func viewDidAppear(_ animated: Bool) {
super.viewDidAppear(animated)
self.session.startRunning()
}
override func viewDidDisappear(_ animated: Bool) {
super.viewDidDisappear(animated)
self.session.stopRunning()
}
private func setup() {
setupVideoProcessing()
setupCameraPreview()
setupTargetView()
}
private func setupVideoProcessing() {
self.session.sessionPreset = .photo
let device = AVCaptureDevice.default(for: .video)
let input = try! AVCaptureDeviceInput(device: device!)
self.session.addInput(input)
let videoDataOutput = AVCaptureVideoDataOutput()
videoDataOutput.videoSettings = [kCVPixelBufferPixelFormatTypeKey as String : Int(kCVPixelFormatType_32BGRA)]
videoDataOutput.alwaysDiscardsLateVideoFrames = true
videoDataOutput.setSampleBufferDelegate(self, queue: .global())
self.session.addOutput(videoDataOutput)
}
private func setupCameraPreview() {
self.previewLayer = AVCaptureVideoPreviewLayer(session: self.session)
self.previewLayer.backgroundColor = UIColor.clear.cgColor
self.previewLayer.videoGravity = .resizeAspectFill
let rootLayer = self.view.layer
rootLayer.masksToBounds = true
self.previewLayer.frame = rootLayer.bounds
rootLayer.addSublayer(self.previewLayer)
}
private func setupTargetView() {
self.lockOnLayer.borderWidth = 4.0
self.lockOnLayer.borderColor = UIColor.green.cgColor
self.previewLayer.addSublayer(self.lockOnLayer)
}
private func handleRectangls(request: VNRequest, error: Error?) {
guard let nextTarget = request.results?.first as? VNDetectedObjectObservation else {
return
}
self.currentTarget = nextTarget
var boundingBox = nextTarget.boundingBox
boundingBox.origin.y = 1 - boundingBox.origin.y
let convertedRect = self.previewLayer.layerRectConverted(fromMetadataOutputRect: boundingBox)
DispatchQueue.main.async {
self.lockOnLayer.frame = convertedRect
}
}
// MARK: - IBAction
@IBAction func tapped(_ sender: UITapGestureRecognizer) {
self.lockOnLayer.frame.size = CGSize(width: 100, height: 100)
self.lockOnLayer.position = sender.location(in: self.view)
var convertedRect = self.previewLayer.metadataOutputRectConverted(fromLayerRect: self.lockOnLayer.frame)
convertedRect.origin.y = 1 - convertedRect.origin.y
self.currentTarget = VNDetectedObjectObservation(boundingBox: convertedRect)
}
@IBAction func longPressed(_ sender: Any) {
self.currentTarget = nil
self.lockOnLayer.frame = .zero
}
// MARK: - AVCaptureVideoDataOutputSampleBufferDelegate
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer),
let target = self.currentTarget else {
return
}
let objectDetectionRequest = VNTrackObjectRequest(detectedObjectObservation: target,
completionHandler: self.handleRectangls)
objectDetectionRequest.trackingLevel = .accurate
try? self.handler.perform([objectDetectionRequest], on: pixelBuffer)
}
}
実行動画
解説
viewDidLoad()で諸々の初期化処理を行っています。
override func viewDidLoad() {
super.viewDidLoad()
setup()
}
private func setup() {
setupVideoProcessing()
setupCameraPreview()
setupTargetView()
}
setupVideoProcessing()とsetupCameraPreview()に関しては説明を割愛します。
ここではAVFoundationフレームワークを利用してカメラを起動するために必要な処理を実施しています。
private func setupVideoProcessing() {
self.session.sessionPreset = .photo
let device = AVCaptureDevice.default(for: .video)
let input = try! AVCaptureDeviceInput(device: device!)
self.session.addInput(input)
let videoDataOutput = AVCaptureVideoDataOutput()
videoDataOutput.videoSettings = [kCVPixelBufferPixelFormatTypeKey as String : Int(kCVPixelFormatType_32BGRA)]
videoDataOutput.alwaysDiscardsLateVideoFrames = true
videoDataOutput.setSampleBufferDelegate(self, queue: .global())
self.session.addOutput(videoDataOutput)
}
private func setupCameraPreview() {
self.previewLayer = AVCaptureVideoPreviewLayer(session: self.session)
self.previewLayer.backgroundColor = UIColor.clear.cgColor
self.previewLayer.videoGravity = .resizeAspectFill
let rootLayer = self.view.layer
rootLayer.masksToBounds = true
self.previewLayer.frame = rootLayer.bounds
rootLayer.addSublayer(self.previewLayer)
}
その後、Viewが表示されたあとにカメラを起動しています。
override func viewDidAppear(_ animated: Bool) {
super.viewDidAppear(animated)
self.session.startRunning()
}
一応Viewが消えたあとにカメラを停止する処理を書きましたが、このサンプルではここは通りません。
override func viewDidDisappear(_ animated: Bool) {
super.viewDidDisappear(animated)
self.session.stopRunning()
}
setupTargetView()ではオブジェクトの矩形を表すLayerを設定しています。
顔検出のサンプルと同様、緑色の枠としました。
これをカメラのレイヤー上にアタッチします。
private func setupTargetView() {
self.lockOnLayer.borderWidth = 4.0
self.lockOnLayer.borderColor = UIColor.green.cgColor
self.previewLayer.addSublayer(self.lockOnLayer)
}
handleRectangls()はVNTrackObjectRequest生成時に第二引数に渡すcompletionHandlerです。少々長いので外出しにしました。
private func handleRectangls(request: VNRequest, error: Error?) {
guard let nextTarget = request.results?.first as? VNDetectedObjectObservation else {
return
}
self.currentTarget = nextTarget
var boundingBox = nextTarget.boundingBox
boundingBox.origin.y = 1 - boundingBox.origin.y
let convertedRect = self.previewLayer.layerRectConverted(fromMetadataOutputRect: boundingBox)
DispatchQueue.main.async {
self.lockOnLayer.frame = convertedRect
}
}
オブジェクトが検出された場合はその矩形を取得し、追跡する緑の枠の位置を更新します。
UIに関する処理なので、更新はメインスレッドで行います。
以下は画面がタップされたときの処理です。タップ位置を中心とし、100 x 100の矩形を ターゲットとするオブジェクトに設定します。
@IBAction func tapped(_ sender: UITapGestureRecognizer) {
self.lockOnLayer.frame.size = CGSize(width: 100, height: 100)
self.lockOnLayer.position = sender.location(in: self.view)
var convertedRect = self.previewLayer.metadataOutputRectConverted(fromLayerRect: self.lockOnLayer.frame)
convertedRect.origin.y = 1 - convertedRect.origin.y
self.currentTarget = VNDetectedObjectObservation(boundingBox: convertedRect)
}
次は画面のロングプレスでターゲットをクリアする処理です。
@IBAction func longPressed(_ sender: Any) {
self.currentTarget = nil
self.lockOnLayer.frame = .zero
}
これらのGestureRecognizerの設定はStoryboardで行いました。
以下はAVCaptureVideoDataOutputSampleBufferDelegateプロトコルのデリゲートメソッドです。
新たなビデオフレームが書き込まれるたびに呼び出されます。
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer),
let target = self.currentTarget else {
return
}
let objectDetectionRequest = VNTrackObjectRequest(detectedObjectObservation: target,
completionHandler: self.handleRectangls)
objectDetectionRequest.trackingLevel = .accurate
try? self.handler.perform([objectDetectionRequest], on: pixelBuffer)
}
オブジェクトトラッキング用にVNTrackObjectRequestのインスタンスを生成しVNSequenceRequestHandlerのperform()メソッドに画像データと共に渡して解析処理を実行します。
まだまだ精度を向上させるための工夫は必要そうですが、ひとまず動くコードは書けました。Visionの動きを実機で試してみたい方は、ぜひ利用してください。
また、Google SamplesではVisionを利用した サンプルコード も公開されています。
まとめ
以上が新フレームワークVisionに関する大まかな説明です。
- Visionは機械学習のうち画像処理に特化したフレームワークであり、オブジェクトの検出/追跡/分類などができる
- 画像解析プロセスでは以下の3つのクラスが重要である
- Request
- RequestHandler
- Observation
- 観測結果はあくまでオブジェクトなので、描画やリアルタイム検出をしたい場合は自前で実装する必要がある
画像の解析という複雑な処理が前述のような短いコードで実現可能となりました。
今後Visionを利用したアプリで、どのようなものが出てくるかが非常に楽しみですね。










