
LangGraphで AIエージェントをまなんでいく - その3 ツール呼び出しとルーティング-
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
LLMアプリケーションでは、LLMを呼び出す前後に特定の処理フローを実行することがよくあります。例えば、RAGでは、ユーザーの質問に関連する文書を検索し、それをLLMに渡して応答を文脈に基づかせる仕組みを取ります。
ただし、固定されたフローではなく、LLM自身がより複雑な問題を解決するために適切な処理フローを選択できるシステムが求められる場合があります。このようなシステムが「エージェント」と定義されます。エージェントは、LLMを利用してアプリケーションの制御フローを決定します。
LLMが制御フローを管理する方法には以下が含まれます:
- 複数のパスの中から1つを選択する
- 呼び出すべきツールを選択する
- 生成された答えが十分か、さらなる作業が必要かを判断する
LangGraphを利用して制御を提供するための方法を学んでいきます。
今回もlangchain-academyを使って実装しながら動作を確認してみます。
今回はLangGraphのルーターとツール呼び出しでの制御を試してみます。
ツール呼び出し
LLMアプリケーションから外部のシステムにアクセスしたいとなった時、ツールの呼び出しを使うことで可能になります。
例えばAPIを呼び出したいとなった時は、
- 要求される入力スキーマをモデルに認識させます。
- モデルはユーザーからの自然言語入力に基づいてツールを呼び出すことを選択します。
- ツールのスキーマに従った出力を返します。
多くのLLMプロバイダはツール呼び出しをサポートしており、LangChainのツール呼び出しインターフェースはシンプルです。
任意の Python 関数を ChatModel.bind_tools(function) に渡すことで実装できます。
実際に実装してみて動きを見てみます。
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
llm_with_tools = llm.bind_tools([multiply])
int型の2つの引数を受け取り、その2つを掛け算した結果を返す関数をチャットモデルにバインドする例です。
from langchain_core.messages import HumanMessage
tool_call = llm_with_tools.invoke([HumanMessage(content=f"30に456を掛けると?", name="Lance")])
tool_call
チャットモデルに 30に456を掛けると? というメッセージを渡すと、

ツール・コールというものが返されます。
※ ツールを呼び出すという言語モデルからの決定を表す。 これらは、AIMessage出力の一部として含まれます。
このプロパティは、ToolCalls のリストを返します。
- name: 呼び出されるべきツールの名前
- args: そのツールへの引数
- id: そのツール・コールのID
ツール・コールには、関数の入力スキーマにマッチする特定の引数と、呼び出す関数名があります。
tool_calls=[{'name': 'multiply', 'args': {'a': 30.0, 'b': 456.0}, 'id': 'd840d06b-4584-4369-abf7-9014dc2811c9', 'type': 'tool_call'}]
この時点ではバインドした関数は実行されていませんでした。
ツールを直接呼び出してレスポンスを返す(ツール関数を実行する)には、一般的に2つの異なる方法があります。
ツール関数を直接実行してみる
@tool decorator
@tool デコレーターは、LangChainにおけるツールを簡単に定義・登録するためのデコレーターです。このデコレーターを使うと、関数を簡単にツールとして扱えるようになり、エージェントやLLMからその関数を呼び出すことができます
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
- ツール・コールを利用する
from langchain_core.messages import ToolMessage
tool_message = multiply.invoke(tool_call.tool_calls[0])
tool_message

-引数だけで実行する
from langchain_core.messages import ToolMessage
tool_message = multiply.invoke(tool_call.tool_calls[0]["args"])
tool_message
こっちは関数の結果だけ返ってきますね
ツール呼び出しのグラフにしてみる
LangGraphでツールを呼び出す、もしくは自然言語での応答を返すグラフを作ってみます。
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
# Node
def tool_calling_llm(state: MessagesState):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# Build graph
builder = StateGraph(MessagesState)
builder.add_node("tool_calling_llm", tool_calling_llm)
builder.add_edge(START, "tool_calling_llm")
builder.add_edge("tool_calling_llm", END)
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
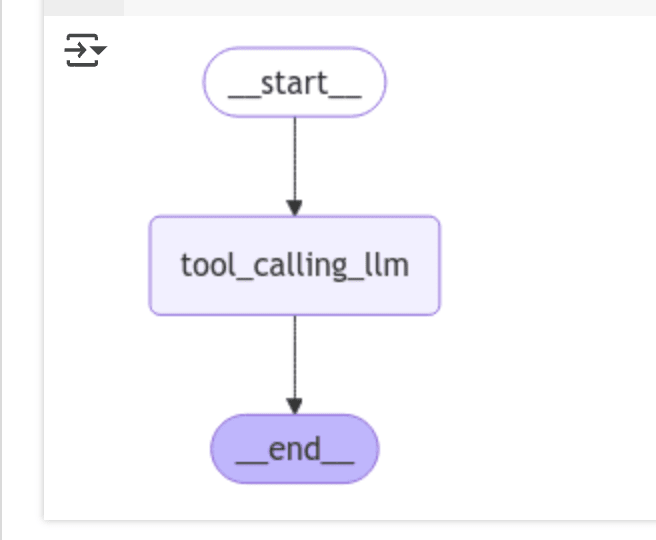
実行してみる
messages = graph.invoke({"messages": HumanMessage(content="こんにちは、どんなことができる?")})
for m in messages['messages']:
m.pretty_print()
messages = graph.invoke({"messages": HumanMessage(content="30に456を掛けると?")})
for m in messages['messages']:
m.pretty_print()

このように、入力内容によってLLMはツールコールかそうでない応答を返しました。
ルーター
ルーターは「選択肢の中から1つを選択して次のステップを決定する」という限定的な制御を提供する仕組みです
ルーターの目的は、特定の選択肢(オプション)の中から、LLMが適切な1つを選び、次のステップを進めることです。
例えば、複数のツールやエージェントが用意されている場合、ルーターを通じてLLMが状況に応じた1つのツールやエージェントを選択します。
簡単な意思決定機構として機能します。
グラフにする
ツール呼び出しで使ったコードを利用し、
ツールのノードをグラフ内に組み込み、必要な条件でツールを呼び出せるようにします。
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
from langgraph.graph import MessagesState
from langgraph.prebuilt import ToolNode
from langgraph.prebuilt import tools_condition
# Node
def tool_calling_llm(state: MessagesState):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# Build graph
builder = StateGraph(MessagesState)
## LLMのツール呼び出しノード
builder.add_node("tool_calling_llm", tool_calling_llm)
## ツールノードを追加
builder.add_node("tools", ToolNode([multiply]))
## ノード間のエッジを定義
builder.add_edge(START, "tool_calling_llm")
builder.add_conditional_edges(
"tool_calling_llm",
# アシスタントからの最新のメッセージ(結果)がツールコールの場合 -> tools_condition routes to tools
# アシスタントからの最新のメッセージ(結果)がツールコールでない場合 -> tools_conditionはENDにルーティングされます。
tools_condition,
)
builder.add_edge("tools", END)
# グラフをコンパイル
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
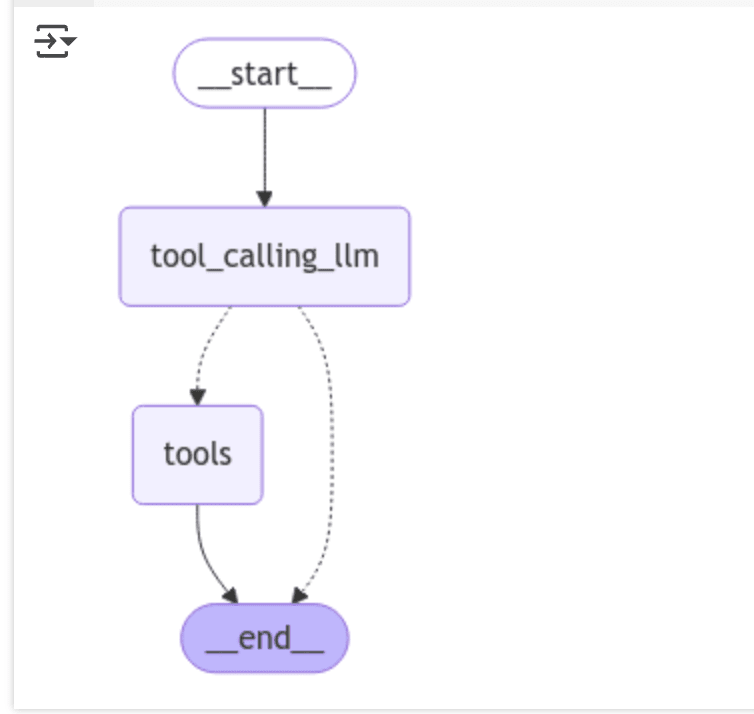
add_conditional_edges でアシスタントからの最新のメッセージ(結果)がツールコールの場合とそうじゃない場合で次のノードを分岐するようにしています。
このグラフを実行して見ます。
from langchain_core.messages import HumanMessage
messages = [HumanMessage(content=" こんにちは")]
messages = graph.invoke({"messages": messages})
for m in messages['messages']:
m.pretty_print()

このメッセージを与えると、ツールを実行せずLLMが応答して終了しました。
from langchain_core.messages import HumanMessage
messages = [HumanMessage(content="75と54を掛け合わせると?")]
messages = graph.invoke({"messages": messages})
for m in messages['messages']:
m.pretty_print()

このメッセージだとツールコールが返ってきて、ツールを実行した結果を返していますね。








