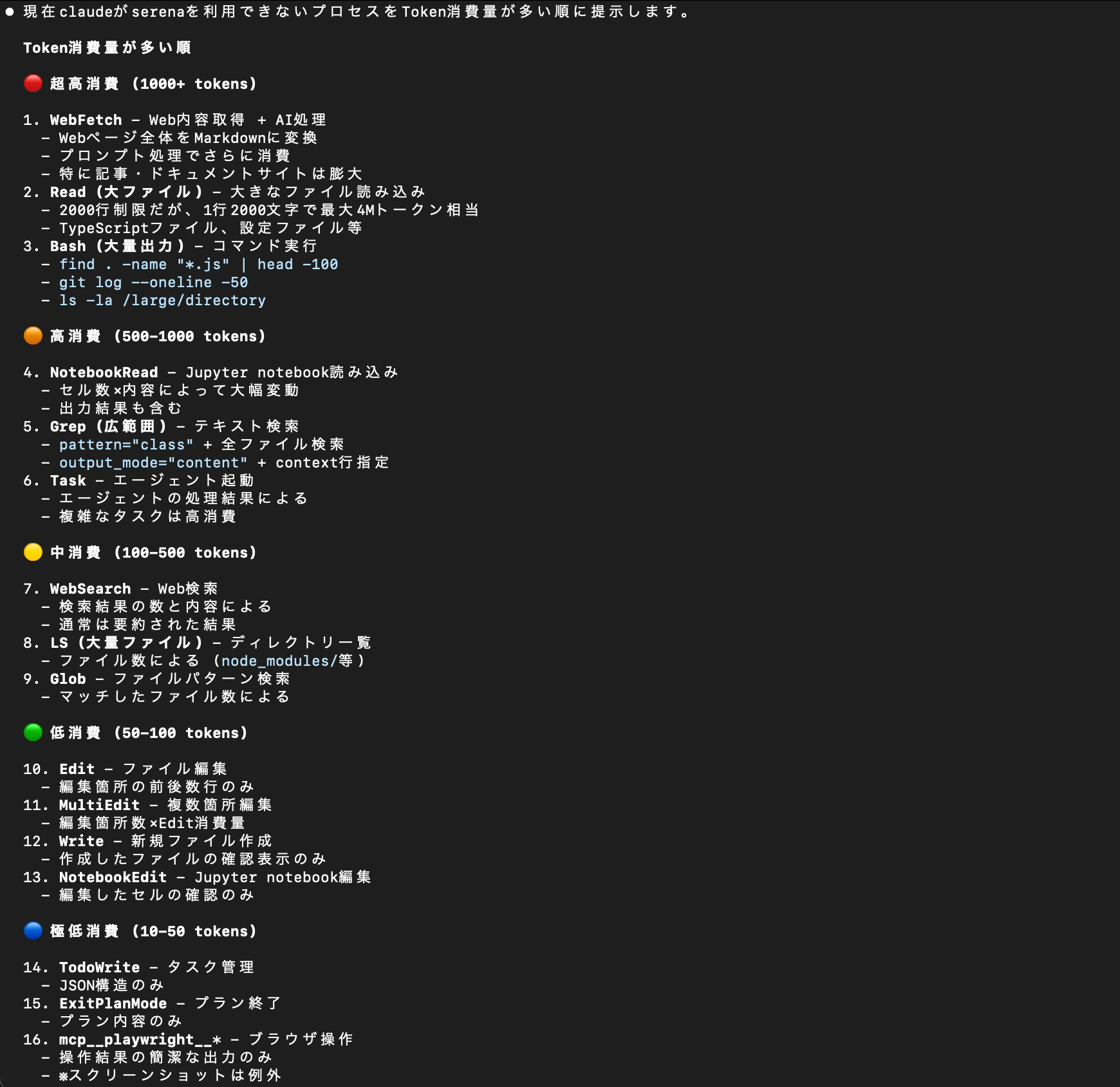
SerenaのレスポンスでApproaching usage limitを回避するアプローチ
Serenaで行える効率のよい解析にてClaudeのToken消費が抑えられることを期待していたところ、衝撃的なログが出てきました。

流石に予想外でした。解析結果が膨大になったのでしょう。Claudeに確認しつつ、出来る対策をやってみました。
Serena向けCLAUDE.mdパラメータ設定
Claudeからの指示が特に絞られていない場合、SerenaのレスポンスはClaudeが直接Readした時とほぼ同じか、それ以上のToken数を消費する可能性があります。これはレスポンスがJSON形式で返されるため、JSONフォーマット自体がToken消費を増加させるためです。
そこで効いてくるのが各種パラメータ設定です。Claudeが提示した使用例としては以下の通り。
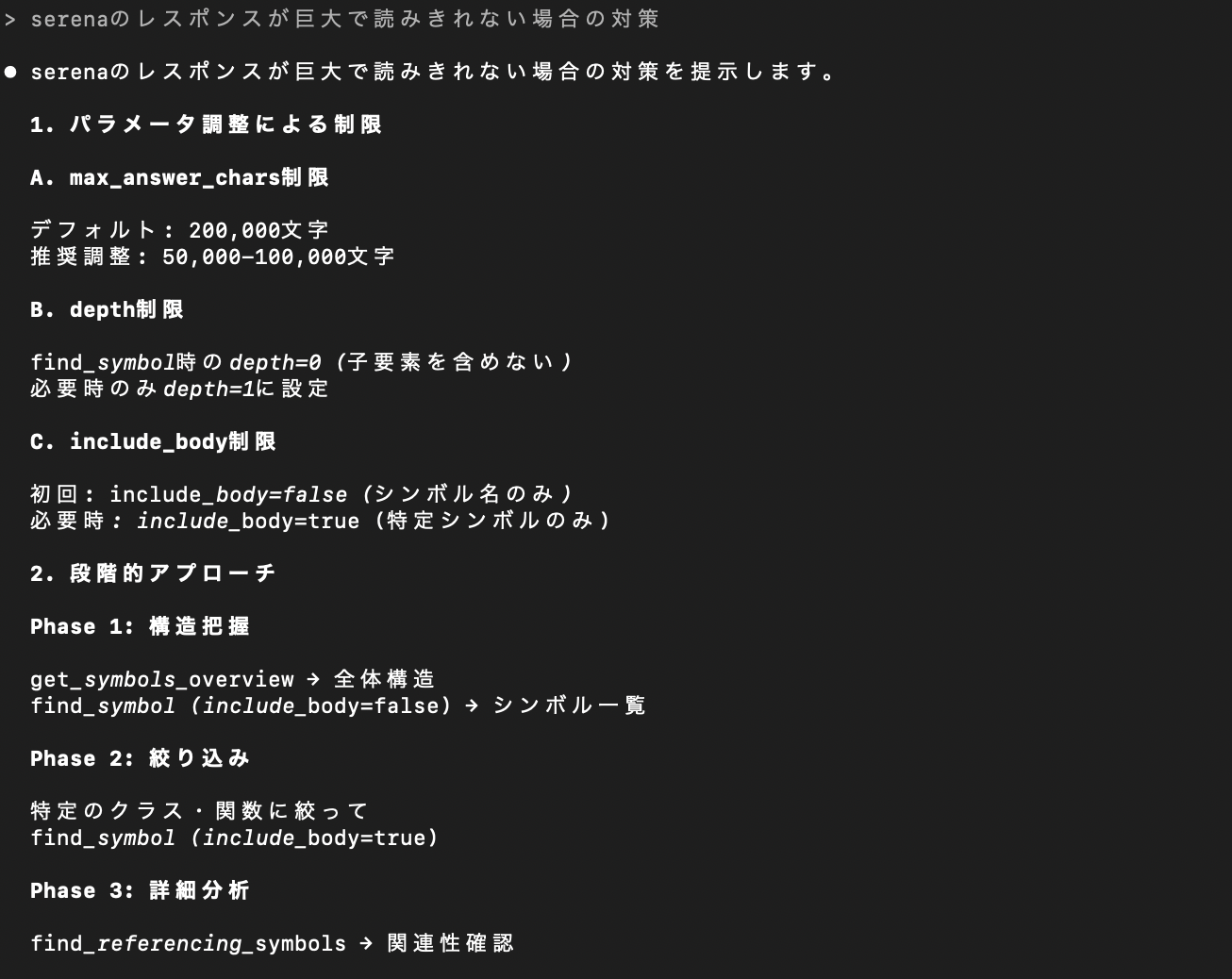
get_symbols_overviewは「効率よくSerena経由で実行して」と明示的に指示するまで使用された形跡がありませんでした。
結果、筆者のCLAUDE.mdには以下の記述を追加しています。これは解析を小さな範囲から段階的に進めるアプローチです。
- Use serena (MCP) as the primary tool for code search and navigation
- Serena Response Management: Use parameter limits (max_answer_chars=50000, include_body=false) and phased approach (overview → targeted analysis → detailed examination)
Serena向けの設定
ClaudeがSerenaに対してToken対策の効いた指示を出せたとしても、Serena自体がToken消費を最適化するとは限りません。そこで.serena/project.ymlに適切な設定を行う必要があります。
ファイルパスやファイルを除外するにはignored_pathsに追加します。重要なポイントとして、ignore_all_files_in_gitignore: true設定により、gitignoreに含まれているファイルは自動的に除外対象となります。この設定は、リポジトリには含めたいがSerenaの解析対象からは除外したいファイルを管理する際に役立ちます。
あとがき
Serenaを導入しただけでは、特別な設定なしにToken消費を抑えるのは難しいようです。Claudeが直接Serenaを利用しないケースもありますが、むしろSerenaから返されたデータをClaudeが処理する際にToken消費が急増するケースが頻繁に見られます。
MCPサーバでしか実行できない機能(Chromeのスクリーンショット取得など)は自動的にMCP経由で処理されます。しかし、Claudeも対応可能な処理については、MCP経由の方が効率的であっても、Claudeが自ら処理してしまうことがあります。このため、効率化を徹底するには、必要に応じてCLAUDE.mdに明示的な指示を追加しておきましょう。
なお、以下のケースはSerenaでも対応できません。気になる場合はplan modeをおすすめします。