
プロジェクトデータをCLAUDE.md及びその参照からSerenaメモリへ移動させてみた
CLAUDE.mdに只管プロジェクト設計のmdファイル参照を入れていましたが、セッション開始時に70000 Token程既に埋まっていたことに気が付きました。セッションを消したほうがよいのかClaudeに確認したところ、mdファイル参照の撤去一択でした。

以下の回答をみるに、参照を削除することにて発生するデメリットもそう多くはなさそうです。

Claudeから提案されたSerenaメモリへの追加方法については、「そのうちメモリにまとまります」といった曖昧な情報が多かったため、確実な記載方法を知りたい身として実際に試した結果をここにまとめました。
Serenaメモリへの追記
Claudeの入力欄で mcp__serena__write_memoryにて、memory_name:とcontent:を指定します。
実際の手順としては、適当なテキストエディタにて以下の構成を入力し、コピペでClaudeに貼り付けます。
mcp__serena__write_memory
- memory_name: architecture
- content:
---
title: Test
---
# Architecture
...
以下のような実行結果が出力されます。

なお、memory_nameには細かい制約があります。
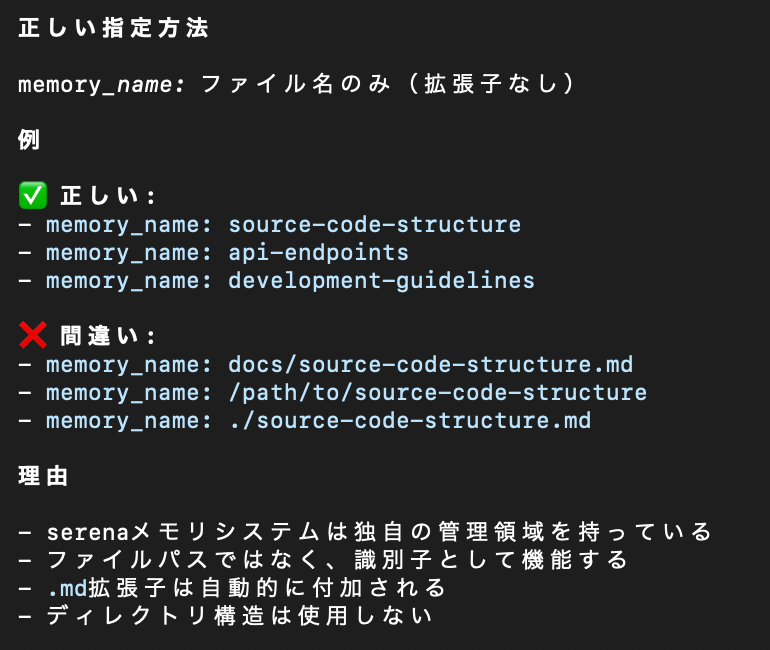
以下の指示でも可能ですが、APIがエラーを返すこともあるようです。


既存メモリを確認する
mcp__serena__read_memoryにて確認可能です。存在するメモリ確認にはmcp__serena__list_memoriesを使います。
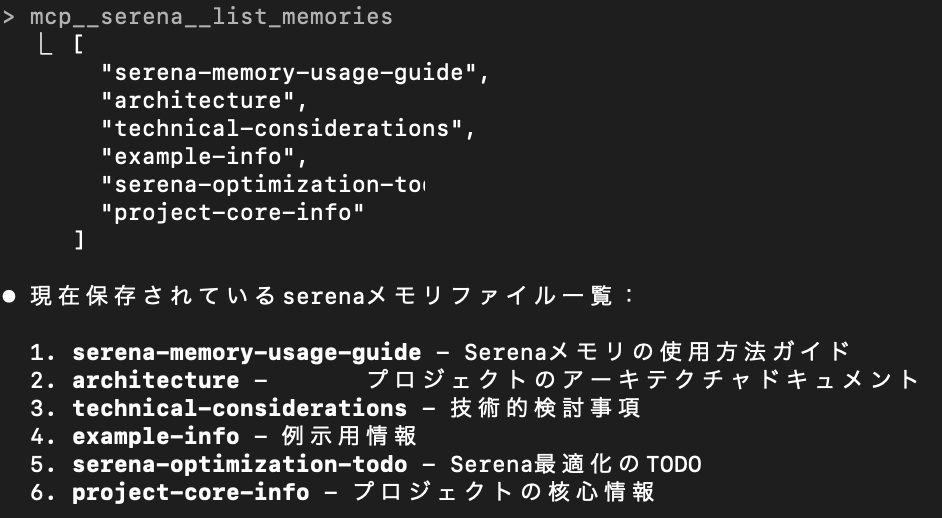
メモリの仕様について確認したい場合は以下のコマンドがおすすめです。
mcp__serena__read_memory serena-memory-usage-guide
あとがき
注意すべき点としては、メモリに追加されるテキストは一度Claudeを経由します。つまり必ず一度は相応のToken消費が行われるということです。Approaching usage limitの警告が出ている時は控えましょう。
なお、「Serenaが扱うのだから日本語でもToken消費量に違いはない」と期待したくなりますが、残念ながら現実はそう甘くありません。

簡潔な1〜2行程度のデータであれば、記述してもToken消費量はそれほど多くありません。そのため、AIが参照するほど重要でないメモなら日本語でも問題ないでしょう。









