
Serenaのバッファ肥大化対策にToDo実行時hooks経由で巨大化ファイル分割について促すプロンプトを提示させてみた
膨大な検索結果バッファ対策に巨大ファイルを検索して分割していたものの、Claudeによる検索プロセスはファイルに応じてTokenを浪費し、手動でのスクリプト実行は忘れがちで、いい塩梅な対策としてhooks化してみました。
2025.08.09
ファイルサイズの肥大化により、Serenaのコマンドでファイルを絞り込んでも、検索結果が多すぎてlimitを超えたバッファが返ってくる状況が頻繁に発生するようになりました。
定期的にサイズと行数をチェックして分割を進めるものの、肥大化したファイルを対象とするためそのチェックプロセスをClaudeに任せるとToken消費量がかなり大きくなります。
hooksで上手く対処できないかなと試してみた結果をまとめました。
ボーダーに掛かったファイルの分割アナウンス
settings.jsonに直接書き込むのは煩雑なので、別ファイルに記述することに。しかし、プロンプトの出力まで含めると作業量がかなり多くなります。思い切ってClaudeを活用しました。プロンプトは以下の通り。
.claude/hooks内にshファイルで、プロジェクト内の本番向けファイルからサイズと行数で分割すべきラインに達している一覧を出しつつ、コピペでClaudeに分割を実行できるようなアウトプットができるスクリプトを作成し、プロジェクト内hooksに追加
出来上がったスクリプトは以下の通り。
#!/bin/bash
# 大きなファイルを分析して分割提案を生成するスクリプト
# プロジェクト内の本番向けファイルから分割すべきファイルを特定し、
# ClaudeにコピペするためのPromptを生成する
INPUT=$(cat)
# ツール入力を取得
TOOL_INPUT=$(echo "$INPUT" | jq -r '.tool_input')
if [ "$TOOL_INPUT" = "null" ] || [ -z "$TOOL_INPUT" ]; then
exit 0
fi
# ファイルパスを取得(MUST utilize tool_input.file_path)
FILE_PATH=$(echo "$TOOL_INPUT" | jq -r '.file_path | select(endswith(".ts") or endswith(".vue") or endswith(".js"))')
if [ -z "$FILE_PATH" ]; then
exit 0
fi
# プロジェクトのルートディレクトリを取得
PROJECT_ROOT="$(pwd)"
# 分析対象の設定
MIN_LINES=500 # 最小行数閾値
LARGE_FILE_LINES=800 # 大きなファイルの閾値
CRITICAL_LINES=1200 # 分割が必要な閾値
echo "🔍 大きなファイル分析レポート - $(date '+%Y-%m-%d %H:%M:%S')"
echo "=========================================================="
echo ""
# 出力ファイル
OUTPUT_FILE="${PROJECT_ROOT}/.claude/large_files_analysis.md"
# Markdownレポートの開始
cat > "$OUTPUT_FILE" << 'EOF'
# 大きなファイル分割分析レポート
## 📊 分析結果サマリー
EOF
echo "📋 分析中のファイルパターン:"
echo " - TypeScript: *.ts"
echo " - Vue.js: *.vue"
echo " - JavaScript: *.js"
echo " - 除外: node_modules/, dist/, build/, .git/, backup/"
echo ""
# 一時ファイル
TEMP_FILE="/tmp/large_files_$$.txt"
RESULTS_FILE="/tmp/results_$$.txt"
# 大きなファイルを検索 (本番向けファイルのみ)
echo "🔍 ファイルサイズと行数を分析中..."
find "$PROJECT_ROOT" -type f \( -name "*.ts" -o -name "*.vue" -o -name "*.js" \) \
-not -path "*/node_modules/*" \
-not -path "*/dist/*" \
-not -path "*/build/*" \
-not -path "*/.git/*" \
-not -path "*/backup/*" \
-not -path "*/test/*" \
-not -path "*/tests/*" \
-not -path "*/spec/*" \
-not -path "*/.next/*" \
-not -path "*/.nuxt/*" \
-not -path "*/coverage/*" \
-not -path "*/tmp/*" \
-not -path "*/temp/*" \
-not -path "*/debug*" \
-not -path "*/dev/*" \
-not -path "*/__pycache__/*" \
-not -path "*/.cache/*" \
-not -name "*.d.ts" \
-not -name "*.min.js" \
-not -name "*.test.*" \
-not -name "*.spec.*" \
| while read -r file; do
if [ -r "$file" ]; then
lines=$(wc -l < "$file" 2>/dev/null || echo "0")
size=$(wc -c < "$file" 2>/dev/null || echo "0")
size_kb=$((size / 1024))
if [ "$lines" -ge $MIN_LINES ]; then
# 相対パスに変換
rel_path="${file#$PROJECT_ROOT/}"
# 分類
if [ "$lines" -ge $CRITICAL_LINES ]; then
priority="🚨 CRITICAL"
elif [ "$lines" -ge $LARGE_FILE_LINES ]; then
priority="⚠️ LARGE"
else
priority="📋 MEDIUM"
fi
echo "$lines|$size_kb|$rel_path|$priority" >> "$TEMP_FILE"
if [ "$priority" == "🚨 CRITICAL" ]; then
echo "$lines|$size_kb|$rel_path|$priority" >> "$DANGAR_FILE"
fi
fi
fi
done
# 結果がない場合の処理
if [ ! -f "$DANGAR_FILE" ] || [ ! -s "$DANGAR_FILE" ]; then
echo "✅ 分割が必要な大きなファイルは見つかりませんでした。"
echo ""
echo "現在のファイルサイズは適切な範囲内です。"
exit 0
fi
# 結果をソートして処理
sort -t'|' -k1,1nr "$TEMP_FILE" > "$RESULTS_FILE"
# 統計情報を計算
TOTAL_FILES=$(wc -l < "$RESULTS_FILE")
CRITICAL_FILES=$(grep "🚨 CRITICAL" "$RESULTS_FILE" | wc -l)
LARGE_FILES=$(grep "⚠️ LARGE" "$RESULTS_FILE" | wc -l)
MEDIUM_FILES=$(grep "📋 MEDIUM" "$RESULTS_FILE" | wc -l)
echo "📊 発見されたファイル数:"
echo " - 🚨 分割が必要 (${CRITICAL_LINES}+ 行): $CRITICAL_FILES ファイル"
echo " - ⚠️ 大きなファイル (${LARGE_FILE_LINES}+ 行): $LARGE_FILES ファイル"
echo " - 📋 注意ファイル (${MIN_LINES}+ 行): $MEDIUM_FILES ファイル"
echo " - 📋 合計: $TOTAL_FILES ファイル"
echo ""
# Markdownレポートに統計を追加
cat >> "$OUTPUT_FILE" << EOF
- **🚨 分割が必要**: ${CRITICAL_FILES} ファイル (${CRITICAL_LINES}+ 行)
- **⚠️ 大きなファイル**: ${LARGE_FILES} ファイル (${LARGE_FILE_LINES}+ 行)
- **📋 注意ファイル**: ${MEDIUM_FILES} ファイル (${MIN_LINES}+ 行)
- **📊 合計**: ${TOTAL_FILES} ファイル
## 📋 ファイル一覧
| 優先度 | ファイルパス | 行数 | サイズ(KB) |
|--------|-------------|------|-----------|
EOF
echo "📋 詳細なファイル一覧:"
echo "┌─────────────┬──────────────────────────────────────────────┬──────┬─────────┐"
echo "│ 優先度 │ ファイルパス │ 行数 │サイズ(KB)│"
echo "├─────────────┼──────────────────────────────────────────────┼──────┼─────────┤"
while IFS='|' read -r lines size_kb rel_path priority; do
printf "│%-12s │%-45s │%5s │%8s │\n" "$priority" "$rel_path" "$lines" "$size_kb"
# Markdownテーブルに追加
echo "| $priority | \`$rel_path\` | $lines | ${size_kb}KB |" >> "$OUTPUT_FILE"
done < "$RESULTS_FILE"
echo "└─────────────┴──────────────────────────────────────────────┴──────┴─────────┘"
echo ""
# Claude用のPromptを生成
cat >> "$OUTPUT_FILE" << 'EOF'
## 🤖 Claude用 分割実行プロンプト
分割が必要なファイルをClaudeで処理する場合、以下のプロンプトをコピペして使用してください:
EOF
echo "🤖 Claude用プロンプト生成中..."
# 分割が必要なファイルのプロンプトを生成
CRITICAL_COUNT=0
while IFS='|' read -r lines size_kb rel_path priority; do
if [[ "$priority" == *"CRITICAL"* ]]; then
CRITICAL_COUNT=$((CRITICAL_COUNT + 1))
# ファイルの種類を判定
case "$rel_path" in
*.vue)
file_type="Vue.js SFC"
;;
*.ts)
if [[ "$rel_path" == *composables* ]]; then
file_type="Vue Composable"
elif [[ "$rel_path" == *server* ]]; then
file_type="Server Module"
elif [[ "$rel_path" == *queue* ]]; then
file_type="Queue System"
else
file_type="TypeScript Module"
fi
;;
*.js)
file_type="JavaScript Module"
;;
*)
file_type="Source File"
;;
esac
cat >> "$OUTPUT_FILE" << EOF
### $CRITICAL_COUNT. $file_type の分割: \`$rel_path\`
\`\`\`
$rel_path (${lines}行, ${size_kb}KB) を機能別に分割してください。
以下の観点で分割を実行:
1. 単一責任の原則に従い、機能ごとに分離
2. 各分割ファイルは200-500行程度に収める
3. 適切なディレクトリ構造で整理
4. 型定義やインターフェースも適切に分離
5. import/export関係を整理
分割対象: $rel_path
現在の行数: ${lines}行
推奨分割数: $((lines / 400 + 1))個程度のモジュール
Claude実行コマンド例:
"$rel_path を機能別に分割して"
\`\`\`
EOF
fi
done < "$RESULTS_FILE"
# 大きなファイルの監視プロンプトも追加
if [ "$LARGE_FILES" -gt 0 ]; then
cat >> "$OUTPUT_FILE" << EOF
## 📋 監視対象ファイル(将来的な分割候補)
以下のファイルは現在は分割不要ですが、今後の成長を監視することをお勧めします:
EOF
while IFS='|' read -r lines size_kb rel_path priority; do
if [[ "$priority" == *"LARGE"* ]]; then
echo "- \`$rel_path\` (${lines}行, ${size_kb}KB)" >> "$OUTPUT_FILE"
fi
done < "$RESULTS_FILE"
fi
# 推奨事項を追加
cat >> "$OUTPUT_FILE" << 'EOF'
## 💡 分割の推奨事項
### 分割の基準
- **🚨 即座に分割**: 1200行以上
- **⚠️ 分割検討**: 800行以上
- **📋 監視対象**: 500行以上
### 分割のベストプラクティス
1. **機能別分割**: 関連する機能をグループ化
2. **適切なサイズ**: 200-500行/ファイル
3. **明確な責任**: 各ファイルは単一の責任を持つ
4. **依存関係の整理**: import/exportを適切に管理
5. **ディレクトリ構造**: 論理的なフォルダ構成
### 分割後の確認項目
- [ ] 各モジュールが適切なサイズ(200-500行)
- [ ] 機能が論理的に分離されている
- [ ] 型定義が適切に共有されている
- [ ] テストが個別に実行できる
- [ ] パフォーマンスに影響がない
EOF
# 一時ファイルの削除
rm -f "$TEMP_FILE" "$RESULTS_FILE"
echo "📄 詳細レポートを生成: .claude/large_files_analysis.md"
echo ""
echo "✅ 分析完了!"
if [ "$CRITICAL_FILES" -gt 0 ]; then
echo ""
echo "🚨 ${CRITICAL_FILES}個のファイルが分割を必要としています。"
echo "📋 .claude/large_files_analysis.md の「Claude用プロンプト」をコピペして分割を実行してください。"
elif [ "$LARGE_FILES" -gt 0 ]; then
echo ""
echo "⚠️ ${LARGE_FILES}個のファイルの将来的な分割を検討することをお勧めします。"
else
echo ""
echo "✅ 現在のところ分割が必要なファイルはありません。"
fi
echo ""
echo "📊 分析レポート: .claude/large_files_analysis.md"
hooksでのみ有効な環境変数を使ってパスを設定します。
{
"PostToolUse": [
{
"matcher": "Write|Edit|MultiEdit",
"hooks": [
{
"type": "command",
"command": "$CLAUDE_PROJECT_DIR/.claude/hooks/analyze_large_files.sh"
}
]
}
]
}
実際の実行結果
該当するファイルがある場合は以下のようなログが出てきます。
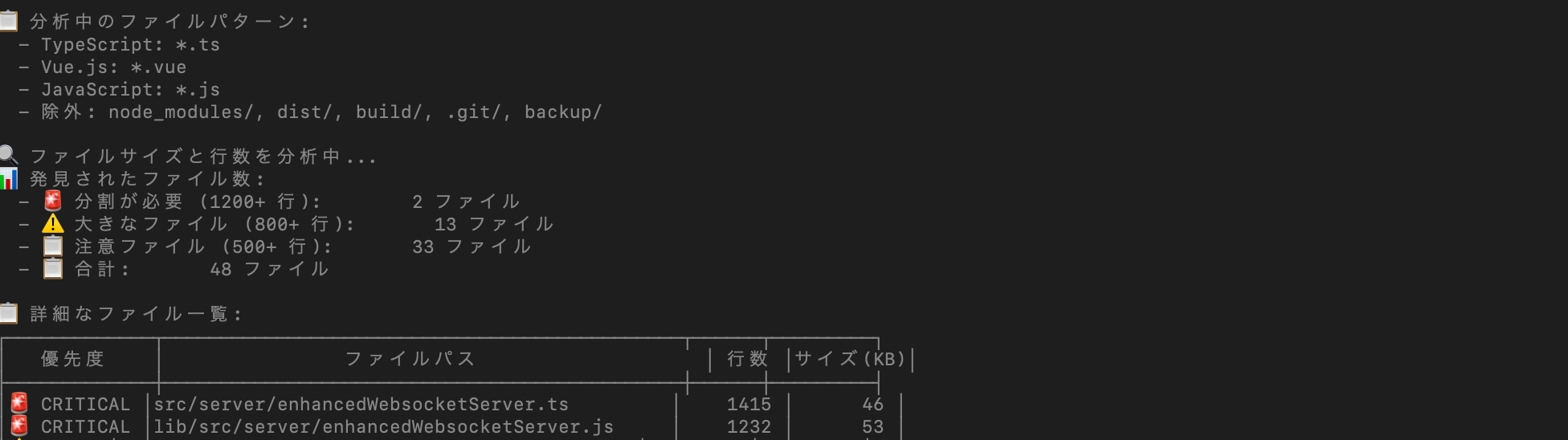
.cloude/large_files_analysis.md内の出力をClaudeにコピペしましょう。
存在しないときはあっさりめです。

あとがき
手動でのスクリプト実行は忘れがちですが、hooksではClaudeの処理と連動して自動的に出力されます。また、hooksの通常ログはToken消費の対象外で、余計なコストがかかりません。
プロンプトでなくても実行できる定期的な操作で心当たりがあれば、hooks化の検討をおすすめします。








