DevelopersIO 2025 Sapporo で「生成AIで「お客様の声」をストーリーに変える 新潮流「Generative ETL」」というタイトルで登壇しました #devio2025
クラウド事業本部コンサルティング部の石川です。2025 年 9 月 26 日開催された DevelopersIO 2025 Sapporo にて「生成AIで「お客様の声」をストーリーに変える 新潮流「Generative ETL」」をテーマにお話させていただきました。
はじめに
企業にとって、アンケート、レビュー、問い合わせなどで寄せられる 「お客様の声(Voice of Customer, VOC)」は、商品やサービスの改善、顧客満足度の向上に繋がる貴重な情報源です。しかし、その多くが分析しづらい「文章」という定性的な非構造化データであるため、価値を十分に引き出せずにいる企業は少なくありません。
本記事では、この課題を解決する新たな潮流として注目される 「Generative ETL」 について、その概念からAWSを活用した具体的な実現方法、そして得られたインサイトをビジネスアクションに繋げるまでを解説します。
セッションスライド
生成AIで「お客様の声」をストーリーに変える 新潮流「Generative ETL」
「お客様の声」に眠る価値と、活用を阻む壁
なぜ多くの企業が「お客様の声」の活用に苦労しているのでしょうか。 その理由は主に4つあります。

これらの根本的な原因は、「お客様の声」が定性的な 「非構造化データ」 であることです。そのため、データは豊富に存在するにもかかわらず、そこから意味のある知見(インサイト)を引き出せず、多くの戦略的意思決定が断片的な情報に依存せざるを得ない状況でした。
新潮流「Generative ETL」とは?
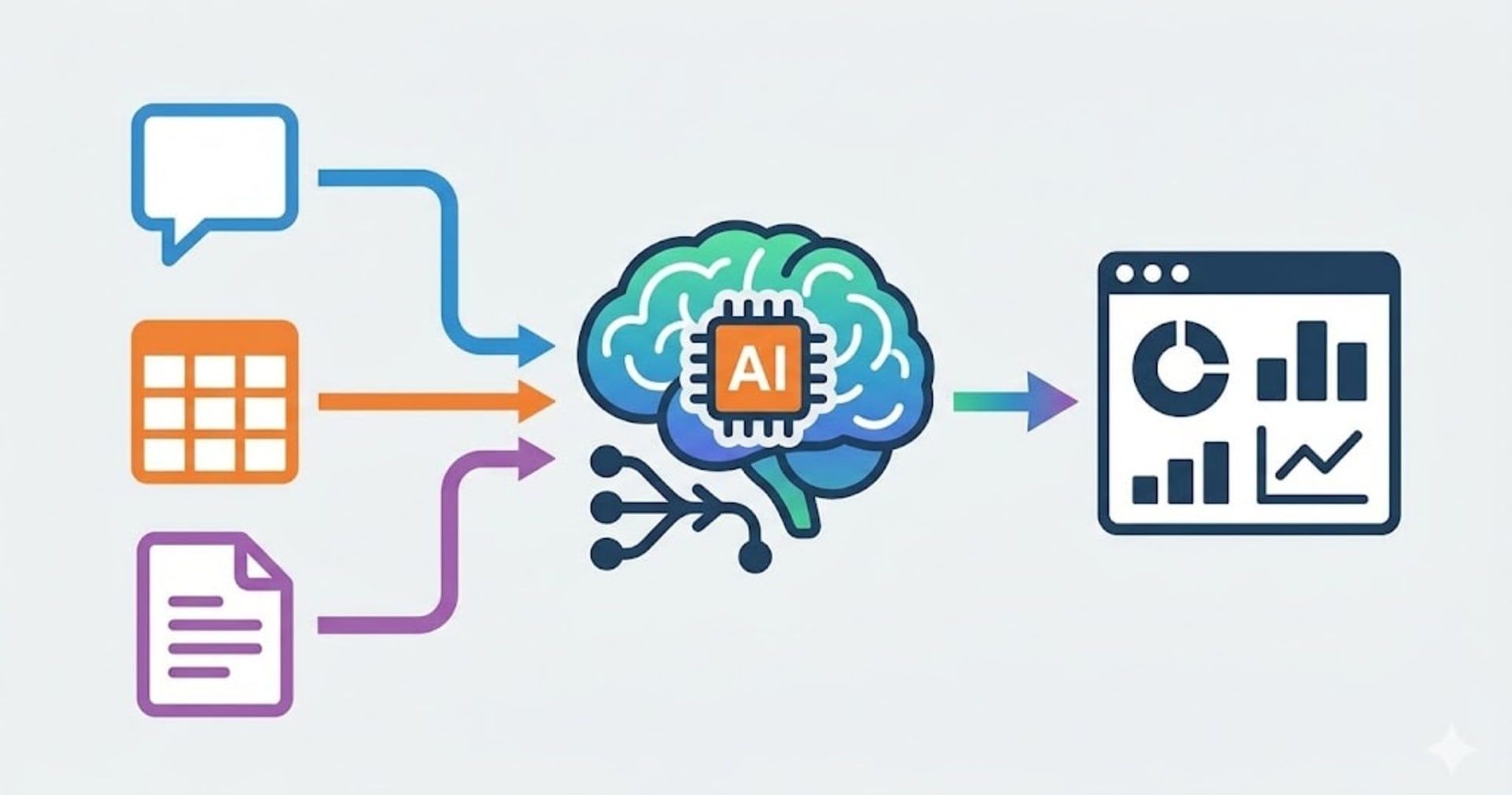
この状況を打開するのが、近年の生成AIの進化と普及です。生成AIを活用し、混沌とした「お客様の声」を、分析可能で意味のある「ストーリー」へと変換する新たなアプローチ、それが『Generative ETL』です。
従来のETLとの違い
従来のETLとGenerative ETLの最大の違いは、 「変換(Transform)」 プロセスの役割にあります。
従来のETLにおける「変換」が、既存の行と列のデータを整理・加工する作業であったのに対し、 Generative ETLにおける「変換」は、生成AIを用いて、構造を持たないデータから意味を読み解き、新たな構造を「生成」 できます。

例えば、一つの顧客レビューという非構造化データに対し、生成AIが以下のような構造化データを「生成」します。
- 「お客様の声」という文章(非構造化データ)に対し、生成AIがその文脈を理解
- 「これは製品の価格に関する意見である」と分類
- 「感情はネガティブである」と判定
- 「競合製品Xについての言及がある」という具体的な情報を抽出
Amazon QuickSightのようなBIツールは、ワードクラウドなど強力な可視化機能を持ちますが、分析できるのはあくまで定量的な構造化データに限られます。そのため、自由記述のテキストである「お客様の声」をそのまま可視化することはできませんでした。
この課題を解決するのがGenerative ETLです。 生成AIが非構造化データである「お客様の声」を、BIツールが理解できる構造化データへと変換することで、これまで埋もれていた価値を可視化・分析するための架け橋となるのです。
AWSで実現するGenerative ETLアーキテクチャ
このGenerative ETLは、AWSのマネージドサービスを組み合わせることで、迅速かつスケーラブルに構築できます。
アーキテクチャの全体像
- Extract(抽出)
- お客様の声を Amazon S3 に集約します。
- Transform(変換)
- AWS Lambda でデータの前処理を行い、Amazon Bedrock のLLMを用いてテキストの分類、感情分析、情報抽出などを実行します。
- Load(格納)
- 構造化されたデータを再び Amazon S3 に格納し、Amazon Athena でクエリできるようにします。
- Visualize(可視化)
- Amazon QuickSight でダッシュボードを構築し、インサイトを可視化します。
データの正規化、形態素解析、係り受け解析などの決定論的な処理と、生成AIならではの非決定論的処理は、処理速度やコスト効率の観点で分離、これら一連の処理は AWS Step Functions を用いて管理します。
Amazon BedrockによるAI駆動のデータ変換
変換プロセスの中核を担うのがAmazon Bedrockです。 高度なテキスト分析を、プロンプトで指示するだけで実現できます。
- タスク1:分類(Categorization)
- プロンプト例: 「以下のレビューを 'UI/UX', '価格', '機能要望' のいずれかに分類し、JSON形式で出力してください。」
- タスク2:感情分析(Sentiment Analysis)
- プロンプト例: 「以下のテキストの感情(ポジティブ, ネガティブ, 中立)を判定し、言及されている特定の側面と関連する感情も抽出してください。」
- タスク3:情報抽出(Information Extraction)
- プロンプト例: 「以下の会話記録から、顧客名, 製品SKU, 報告された問題点を抽出し、JSONオブジェクトで出力してください。」
Amazon QuickSightでインサイトを「ストーリー」に変える
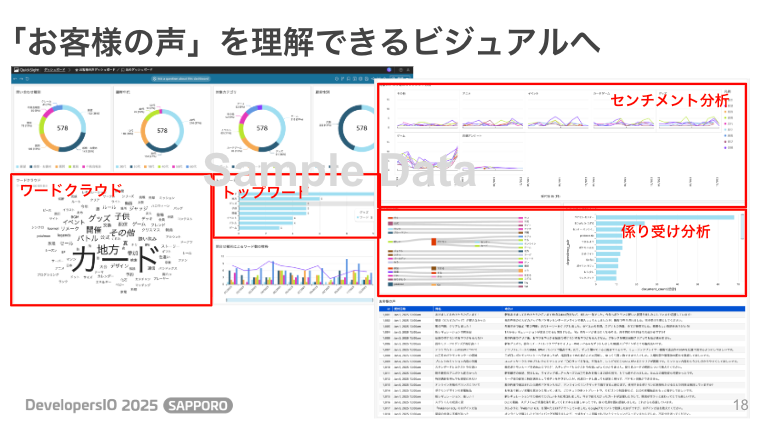
Generative ETLによって構造化されたデータは、Amazon QuickSightで可視化することで、誰もが直感的に理解できるビジュアルへと変わります。 ワードクラウドで話題のキーワードを把握したり、センチメント分析で感情の傾向を掴んだり、係り受け分析で「何がどう評価されているか」を正確に把握したりすることが可能です。
さらに、 QuickSightの生成AI機能「Data Stories」 は、この分析を次のレベルへと引き上げます。「Data Stories」は、ダッシュボード上のデータからインサイトを自動で文章化し、ストーリー形式で分かりやすく説明してくれる機能です。
ストーリーを作成する部ジュアルを選択して、自然言語での指示(プロンプト)だけで、データアナリストが作成したようなレポートが数分で完成します。
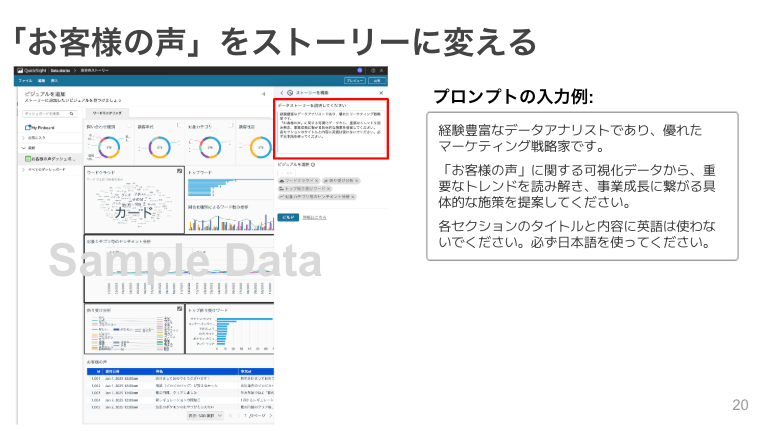
これにより、専門家でなくてもデータに基づいた洞察を手軽に得られ、組織全体の迅速な意思決定を支援します。

インサイトからアクションへ繋げるベストプラクティス
Generative ETLの導入を成功させるためには、以下のプラクティスが推奨されます。
- PoC(概念実証)から始める
- ビジネスインパクトが大きく管理しやすい単一のデータソース(例:主力製品のレビュー)から着手し、小さく始めて迅速に価値を実証する 。
- プロンプトエンジニアリングを磨く
- アウトプットの品質はプロンプトの品質に依存する。明確な指示、具体例の提示、出力形式の指定が鍵 。
- コストを管理する
- リージョン毎の基盤モデルの入力トークン数や出力トークン数をモニタして、利用状況を把握・管理する 。
- QuickSightのDataStoriesはビジネスコンテキストを含める
- データストーリーを作成するプロンプトには、 「小売」など分析対象やビジネス目標を含めるとより良いストーリーが生成される。
最後に
コールセンターへの問い合わせ、アンケートの自由記述欄、SNSへの投稿、レビューサイトの口コミなど、企業には日々大量の「お客様の声」が寄せられます。従来から、形態素解析、構文解析(係り受け解析)、DLA(Deep Learning-based Approach)やNTM(Neural Topic Model)といった機械学習モデルを用いたトピック分類や感情分析が行われてきましたが、生成AI、特に大規模言語モデル(LLM)の登場は、「お客様の声」分析を新たな次元へと引き上げました。
従来の手法が主にデータの「分類」や「可視化」に重点を置いていたのに対し、生成AIは文脈を深く理解し、データから新たな知見や意味を「生成」することを可能にします。これにより、分析は「何が言われているか」の把握に留まらず、「なぜそう言われているのか」「次に何をすべきか」という示唆の抽出へと進化しています。
生成AIとAWSサービスを活用したETLの取り組みは、今後ますます進化していきます。ご質問やご意見があれば、ぜひイベントでお声がけください。