![[書籍]「実践 Apache Iceberg」のハンズオン環境の構築ガイド](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1761292699/user-gen-eyecatch/kl6hemhkl8ifuwk4n77d.jpg)
[書籍]「実践 Apache Iceberg」のハンズオン環境の構築ガイド
クラウド事業本部コンサルティング部の石川です。先日ご紹介した 書籍「実践 Apache Iceberg」 は、手を動かしながら学ぶことを重視しており、全体を通じて多くの章にハンズオンがあり、しかも共著者または関係者によるハンズオンリポジトリが公開されています。本日は、ハンズオンをサクッと導入する方法を解説します。
先日のブログはこちらから
**なお、2025年10月29日(水)に目黒 AWS Startup Loftsで『実践 Apache Iceberg』という書籍の出版記念イベントがあります。本記事執筆時点では ** オフライン(現地)はもちろん、オンラインでも登録できますのでご興味がある方はぜひご登録してください。
ハンズオンのリポジトリ
書籍「実践 Apache Iceberg」では、Apache Icebergを簡単に試せるコンテナ環境が用意されており、特定の有償サービスのアカウント作成も不要で、すぐに手を動かせる環境が公開されています。
ハンズオンコンテンツ一覧
以下、README.mdより、各章とハンズオンコンテンツの対応は以下の通りです。
前提条件と必要なツール
システム要件
- ディスク容量: 60GB以上の空き容量
- 約40GBに達しました。
- OS: macOS, Linux, Windows 10/11
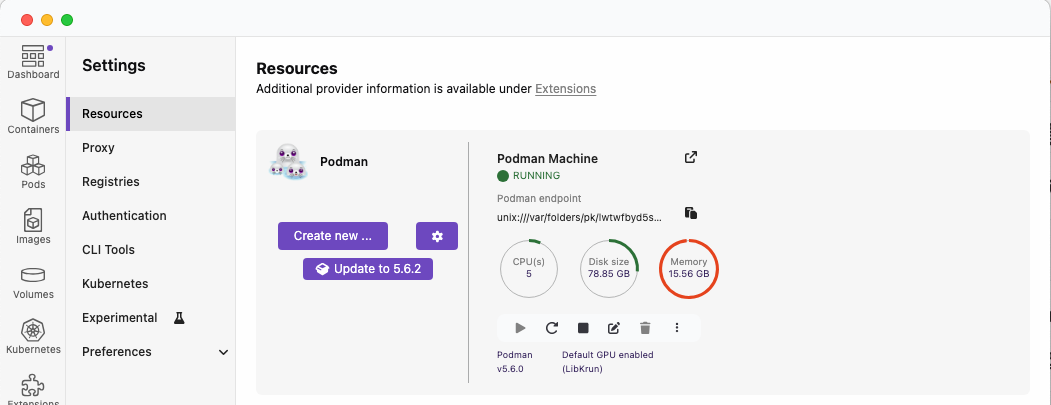
- 私の環境は、MacBook Air (M4)、macOS Sequoia 15.6.1、podman version 5.6.0
- メモリ: 16GB以上推奨(Docker環境用)
- 様々な実験を行った結果、PodmanのVMで約20GBまではモリモリ確保
- PodmanのVMが約16GB、使用率が98%でも動作
必要なソフトウェア
-
コンテナランタイム
-
Docker Engine (Linux)
-
Podman と Podman Compose
このブログの設定をすることで、
podman-composeがdocker-composeのエイリアスとしてそのまま使えます。
-
その他のツール
- Git
- Webブラウザ(Chrome, Firefox, Safari等)
- ターミナル/コマンドプロンプト
ハンズオン環境セットアップ
1. リポジトリのクローン
GitHubのパブリックなリポジトリからハンズオンコンテンツをダウンロード(clone)します。
git clone https://github.com/murashitas/iceberg_book_handson.git && cd iceberg_book_handson
注意: Trinoの設定ファイルの修正
最新バージョンのTrinoではdiscovery-server.enabledプロパティが廃止されています。このパラメータを削除しないと起動に失敗します。
- trino/etc/config.propertiesから8行目のdiscovery-server.enabled=trueを削除
2. Docker環境の起動
初回起動
ハンズオンコンテンツから下記のコマンドを実行して環境を構築します。
docker-compose up --build
コンテナイメージのダウンロードとNYCタクシーデータセットのダウンロードに時間がかかります。私の環境では22分程度でした。
docker-compose up --buildを実行すると、一般には実行が終わりプロンプトに戻るのですが、これは、終わることなく実行し、標準出力にログが出力されます。なので、構築が終わったタイミングを把握するのが難しいのですが、kafkaのメッセージが出たら使い始めることができます。
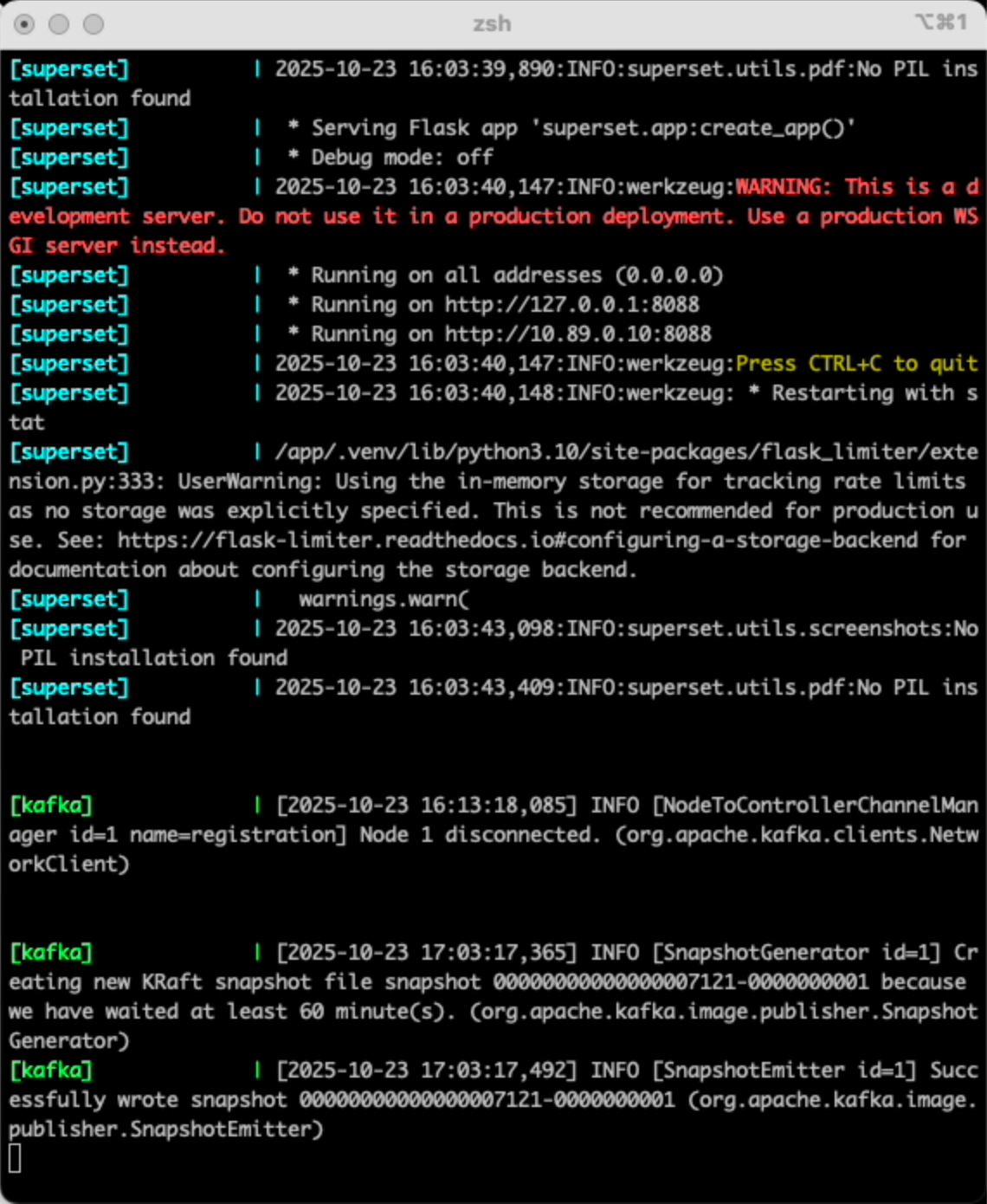
サービスの実行状況の確認
別のターミナルを起動して、サービスが正常に起動したことを確認した。flink-sql-client以外は全て起動しています。
% docker-compose ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f75702e9e533 docker.io/apache/iceberg-rest-fixture:1.8.1 java -jar iceberg... 12 hours ago Up 12 hours 0.0.0.0:8181->8181/tcp iceberg-rest
a6d4e774e61b docker.io/bitnamilegacy/minio:latest /opt/bitnami/scri... 12 hours ago Up 12 hours (healthy) 0.0.0.0:9000->9000/tcp, 9001/tcp minio
1988af2dedc7 localhost/iceberg_book_handson_flink-jobmanager:latest jobmanager 12 hours ago Up 12 hours 0.0.0.0:8081->8081/tcp, 6123/tcp flink-jobmanager
3f036f31daab docker.io/trinodb/trino:latest /usr/lib/trino/bi... 12 hours ago Up 2 hours (unhealthy) 0.0.0.0:8085->8085/tcp, 8080/tcp trino
e781382db712 localhost/iceberg_book_handson_hive:latest 12 hours ago Up 12 hours 0.0.0.0:10000->10000/tcp, 0.0.0.0:10002->10002/tcp, 9083/tcp hive
23186d79a939 docker.io/apache/kafka:3.7.0 /etc/kafka/docker... 12 hours ago Up 12 hours 0.0.0.0:9092->9092/tcp kafka
e5c72a83ffa6 docker.io/bitnamilegacy/minio-object-browser:latest 12 hours ago Up 12 hours 0.0.0.0:9001->9090/tcp minio-console
1c3ae5db5fee localhost/iceberg_book_handson_flink-taskmanager:latest taskmanager 12 hours ago Up 12 hours 6123/tcp, 8081/tcp flink-taskmanager
9561114d9dc1 localhost/iceberg_book_handson_flink-sql-client:latest bin/sql-client.sh... 12 hours ago Exited (0) 12 hours ago 6123/tcp, 8081/tcp flink-sql-client
dfa268d17404 docker.io/apache/superset:latest /bin/bash -c pip... 12 hours ago Up 12 hours 0.0.0.0:8088->8088/tcp superset
3ce9a9200a19 localhost/iceberg_book_handson_jupyter:latest /bin/bash -c sta... 12 hours ago Up 12 hours 0.0.0.0:8888->8888/tcp, 4040/tcp iceberg_book_handson_jupyter_1
3. 各サービスへのアクセス
各URLからアクセスできます。なお、Iceberg REST CatalogはREST APIのため画面は出ません。
| サービス | URL | ユーザー/パスワード | 用途 |
|---|---|---|---|
| Jupyter Notebook | http://localhost:8888 | パスワードなし | ハンズオン実行環境 |
| MinIO Console | http://localhost:9001 | admin/password | オブジェクトストレージ管理 |
| Flink Web UI | http://localhost:8081 | - | Flinkジョブ監視 |
| Trino Web UI | http://localhost:8085 | admin | Trinoクエリ監視 |
| Hive Web UI | http://localhost:10002 | - | Hiveサーバー監視 |
| Superset | http://localhost:8088 | admin/admin | データ可視化 |
| Iceberg REST Catalog | http://localhost:8181 | - | カタログAPI |
4. 各サービスのUI
Jupyter Notebook
Trino
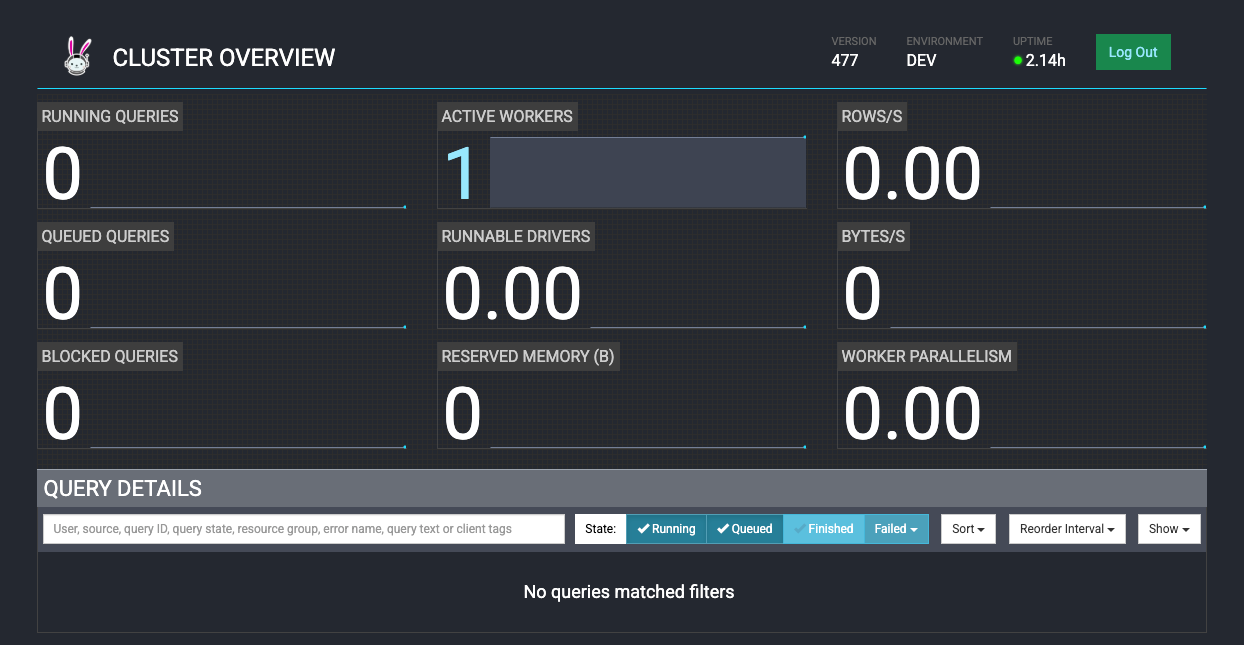
Apache Flink
HiveServer2
Superset
ハンズオンの実施
本書では章ごとにハンズオンが提供されています。ハンズオンは、examplesフォルダの下にJupyter Notebookのファイルとして提供されています。本書の解説を読み進めながら実際の動作を確認できます。
AWSのアナリティクスサービスと直結するApache Icebergの基本、分散クエリエンジンについて抜粋して紹介します。
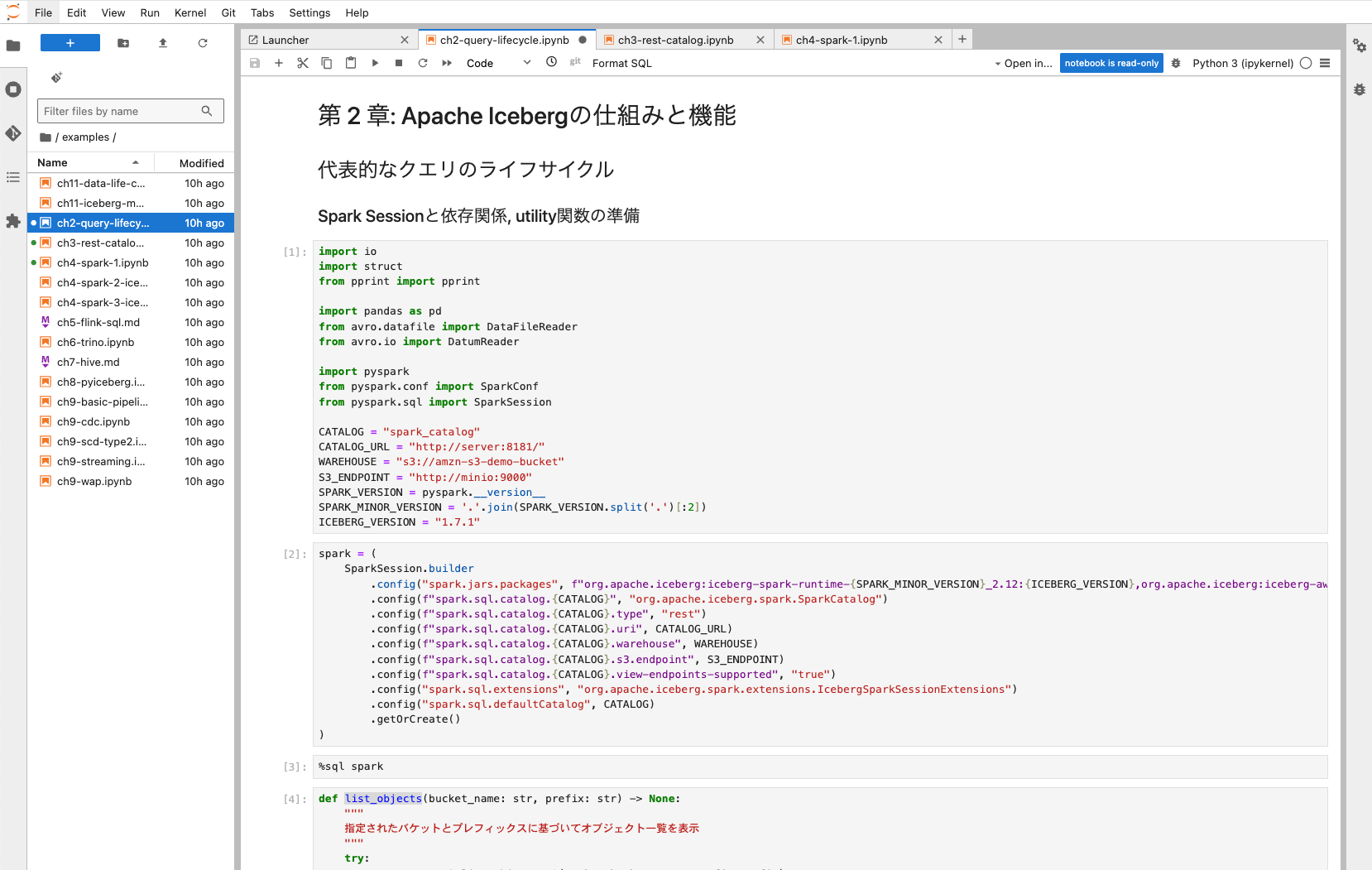
examples/ch2-query-lifecycle.ipynb
このハンズオンは、Icebergの基本的な概念やアーキテクチャ、主要な機能と、代表的なクエリのライフサイクルを理解できます。
examples/ch3-rest-catalog.ipynb
このハンズオンは、Icebergのコアとなる概念である「カタログ」と「ストレージ」、主にRESTカタログを利用してIcebergテーブルのメタデータ操作をHTTPリクエストベースで体験することに焦点を当てています。
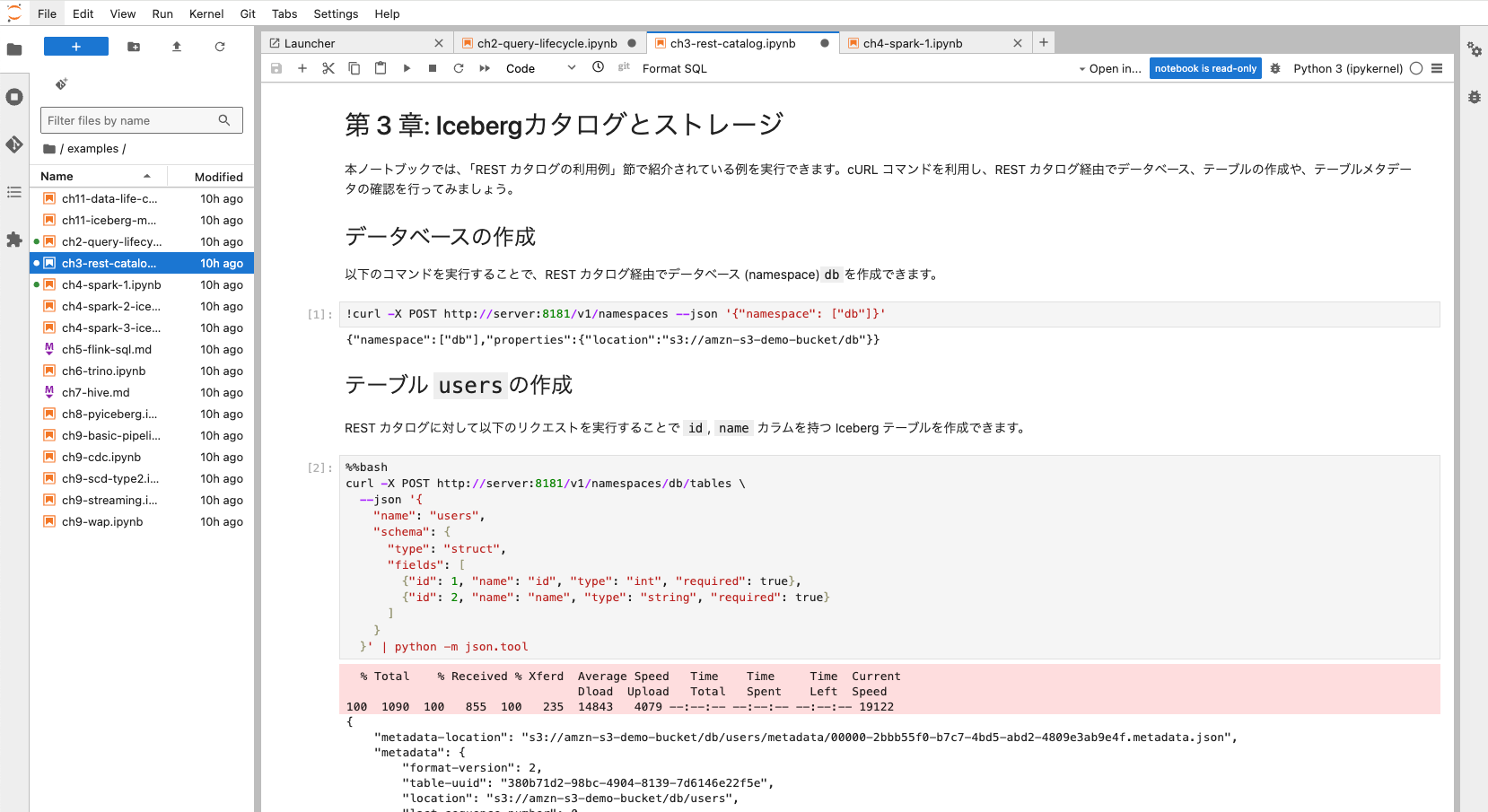
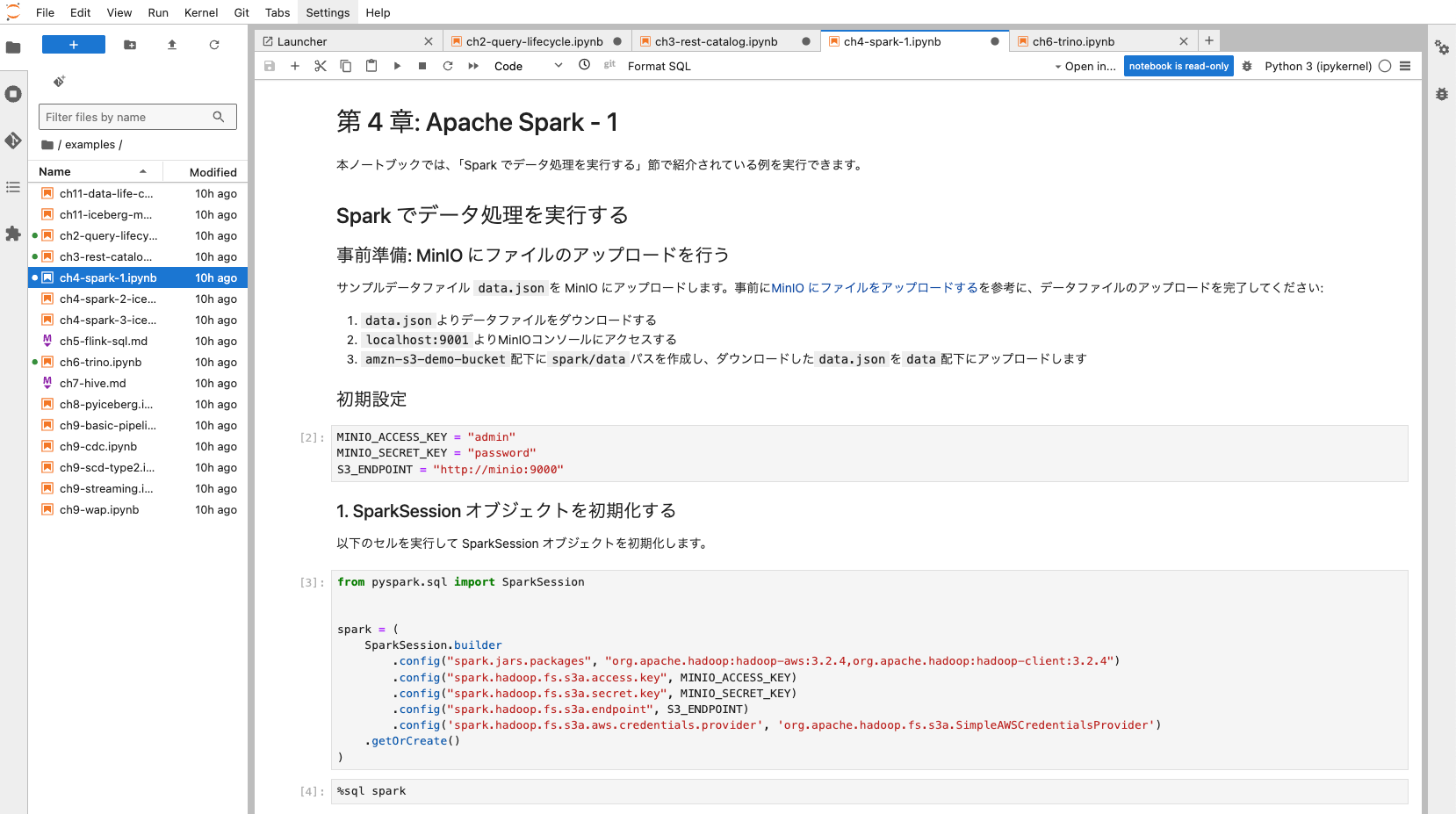
examples/ch4-spark-1.ipynb
AWSの場合、AWS Glue、Amazon EMR、Amazon Athena for Apache SparkのいずれかのサービスからApache Sparkを利用しており、欠かせないクエリエンジンです。
このハンズオンは、分散クエリエンジンApache Sparkを用いて、Icebergの機能や特性を実際に操作しながら理解します。このノートブックでは、Sparkでのデータ処理の基本的な実行方法を確認します。
ch4-spark-2-iceberg-example.ipynbでは、Spark上でIcebergの利用を開始し、基本的なテーブル操作を実行します。ch4-spark-3-iceberg.ipynbでは、Spark SQLを用いたIcebergの基本的な機能(DDL、DML)および高度な機能(スキーマ進化、MERGE INTO、プロシージャなど)を体験します。
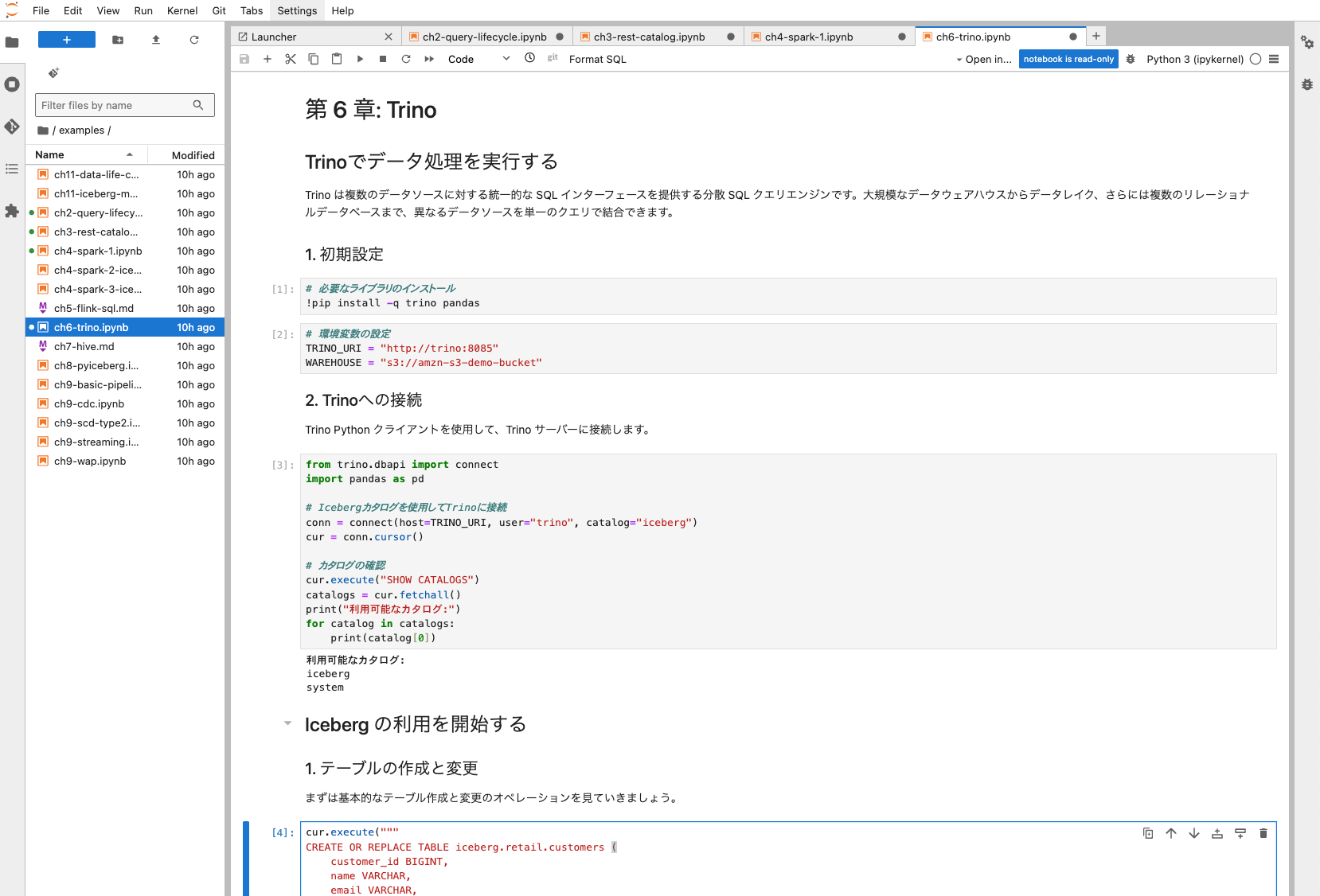
examples/ch6-trino.ipynb
AWSの場合、Amazon Athena からTrinoを利用しており、欠かせないクエリエンジンです。
このハンズオンでは、主に Python クライアント(trinoパッケージ)を使用して Trino に接続し、Iceberg テーブルに対するさまざまな SQL 操作(DDL および DML)を実践します。
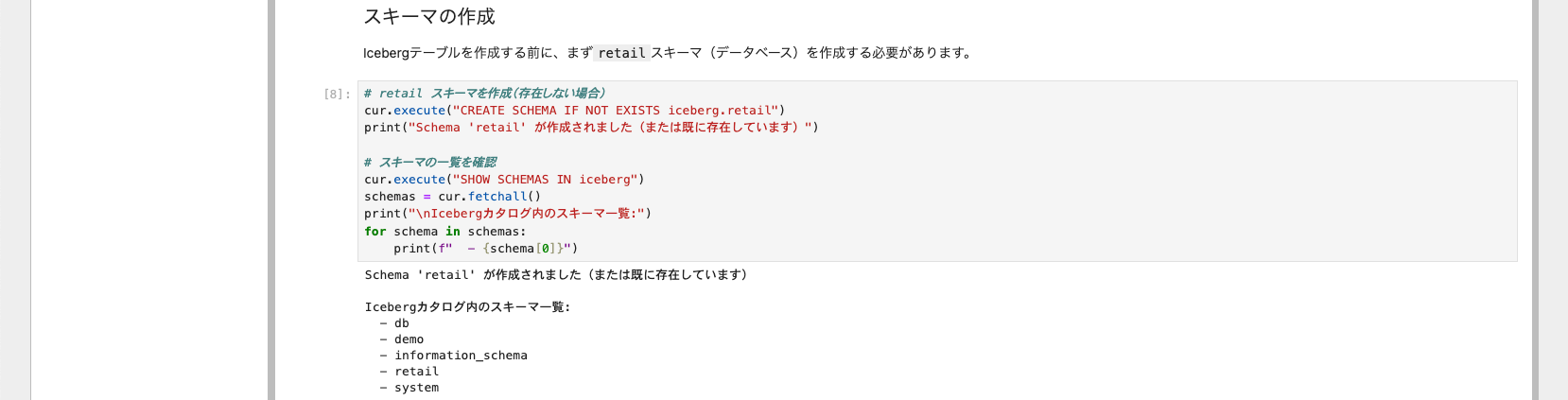
注意: ch6-trino.ipynの設定ファイルの修正
retailスキーマがないため、「Iceberg の利用を開始する」がエラーになります。そのため、「2. Trinoへの接続」の後に、下記の「スキーマの作成」を追加してください。
# retail スキーマを作成(存在しない場合)
cur.execute("CREATE SCHEMA IF NOT EXISTS iceberg.retail")
print("Schema 'retail' が作成されました(または既に存在しています)")
補足: MinIOへのファイルアップロード
ハンズオンによっては、サンプルデータをMinIOにアップロードする必要があります。
データのアップロード手順
-
MinIO Consoleへアクセス
URL: http://localhost:9001 Username: admin Password: password
-
バケットの確認
amzn-s3-demo-bucketバケットがあり、上記のハンズオンで作成されたIcebergのストレージがすでに作成されていることが確認できます。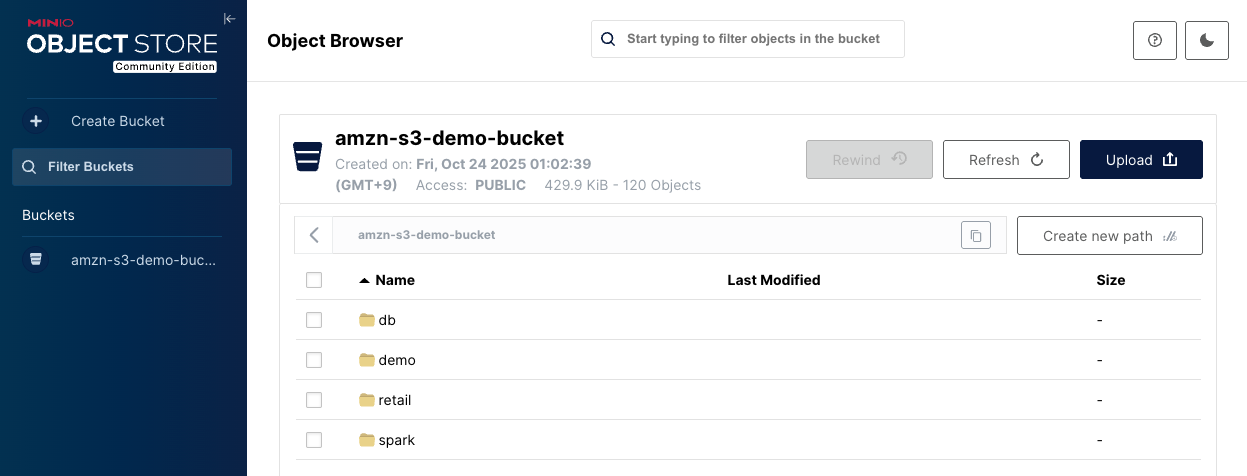
-
パスの作成とファイルアップロード
-
画面右上の「Create new path」でディレクトリを作成
-
「Upload」→「Upload File」でファイルをアップロード
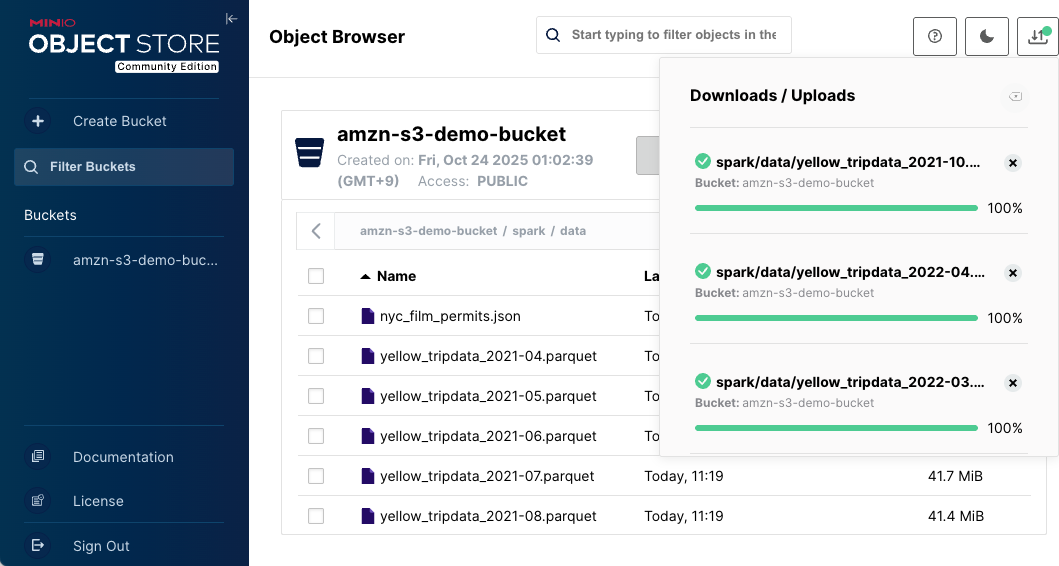
-
ハンズオン環境のコマンド集
docker-composeコマンドは、別のターミナルを立ち上げ、ハンズオンコンテンツフォルダ(iceberg_book_handson)に移動した後、実行してください。
一時停止・再開
一時停止 (Stop)
docker-compose stop
再開 (Start)
docker-compose start
クリーンナップ
ハンズオン環境の削除 (コンテナと一緒にボリュームやイメージも削除)
docker-compose down -v --rmi all
上記のコマンドでは、一部の基本イメージ(flink、jupyter、hiveなど)が残る仕様のため、手作業で削除が必要です
% docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/library/flink 1.20.1-scala_2.12 b023634d8c2b 8 months ago 789 MB
quay.io/jupyter/pyspark-notebook spark-3.5.3 6e417e3a48b8 12 months ago 4.49 GB
docker.io/apache/hive 4.0.1 e0e865f33ecf 12 months ago 1.6 GB
% docker image rm b023634d8c2b 6e417e3a48b8 e0e865f33ecf -f
Untagged: docker.io/library/flink:1.20.1-scala_2.12
Untagged: quay.io/jupyter/pyspark-notebook:spark-3.5.3
Untagged: docker.io/apache/hive:4.0.1
Deleted: b023634d8c2bd706b06036ad6ea88c177ecddcefcb8b1fc720df2c813c1eb1cc
Deleted: 6e417e3a48b80c3b4ac5b478c277f75dae43ca3624aac332b238b5f7440555d7
Deleted: e0e865f33ecfbaeba4a96b3f15ab67aa4dd2602102962aa3dcca082879c68367
※ ダウンロード(clone)したハンズオンコンテンツフォルダ(iceberg_book_handson)も削除してください。
参考リンク
最後に
ノートブックを実行すると、コンソールの標準出力に様々なサービスが連携して動作している様子が垣間見ることができます。これはAWSのサービスを利用しているだけではできない体験です。
このハンズオン環境を通じて実際に手を動かしながら得られる知見は、Apache Icebergの実践的な利用に役立つだけでなく、最新の分散クエリエンジンやAWSサービスとの連携、理解にもつながります。環境構築は初回の起動に時間を要しますが、一度整えばさまざまな章のハンズオンを自在に試すことができます。
ぜひ本書の内容と合わせて、ハンズオンを活用し、Apache Icebergの幅広い可能性を体感してください。今後のデータ分析基盤構築やビッグデータ活用のための強力なスキルセットがここにあります。
なお、本ブログの中で修正した内容については、プルリクを送ります。










