
Amazon S3 FilesをLambdaからマウントして仕様検証してみた
はじめに
みなさんこんにちは、クラウド事業本部コンサルティング部の浅野です。
2026年4月7日、Amazon S3 Filesがリリースされました。
S3はオブジェクトストレージであり、従来はファイルシステムとして直接扱うことができませんでした。
今回のリリースで既存のS3バケットをNFS経由でそのままファイルシステムとしてマウントでき、ls・cat・cpなどの標準的なLinuxファイル操作でS3オブジェクトデータにアクセスできるようになりました。
AWS公式のローンチブログではEC2から実際にマウントする手順が紹介されていますので、本記事では、S3 Filesの仕様を整理した上で、実際にLambdaからマウントして仕様を細かく検証していきます。
参考: ローンチブログ
仕様確認
まず、仕様を確認していきながらイメージを深めていきます。以下が S3 Files のアーキテクチャのイメージです。
※ 出典元: 公式ドキュメント
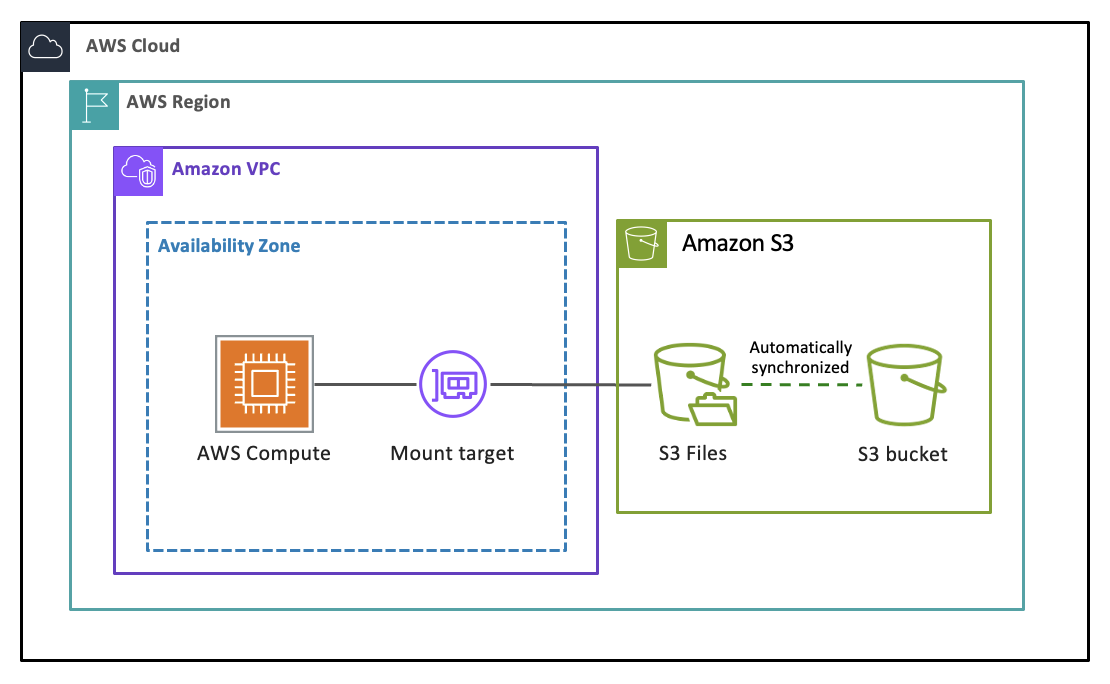
S3 Filesは内部的にはAmazon EFSのインフラを基盤としており、S3バケットとの同期を自動で管理することで、ファイルシステムとしてオブジェクトストレージ内に透過的にアクセスできる仕組みになっています。
ファイルシステムには全ファイルの「メタデータ」と頻繁にやり取りされる、「アクティブデータ」が保持されます。
キャッシュオブジェクトサイズ以下のアクティブデータはファイルシステムから高速に取得できる一方で、料金が適用され、キャッシュオブジェクトサイズを超過したファイルはS3バケットから直接読み込まれ、通常のS3 GETリクエスト料金のみが適用されるので安価です。
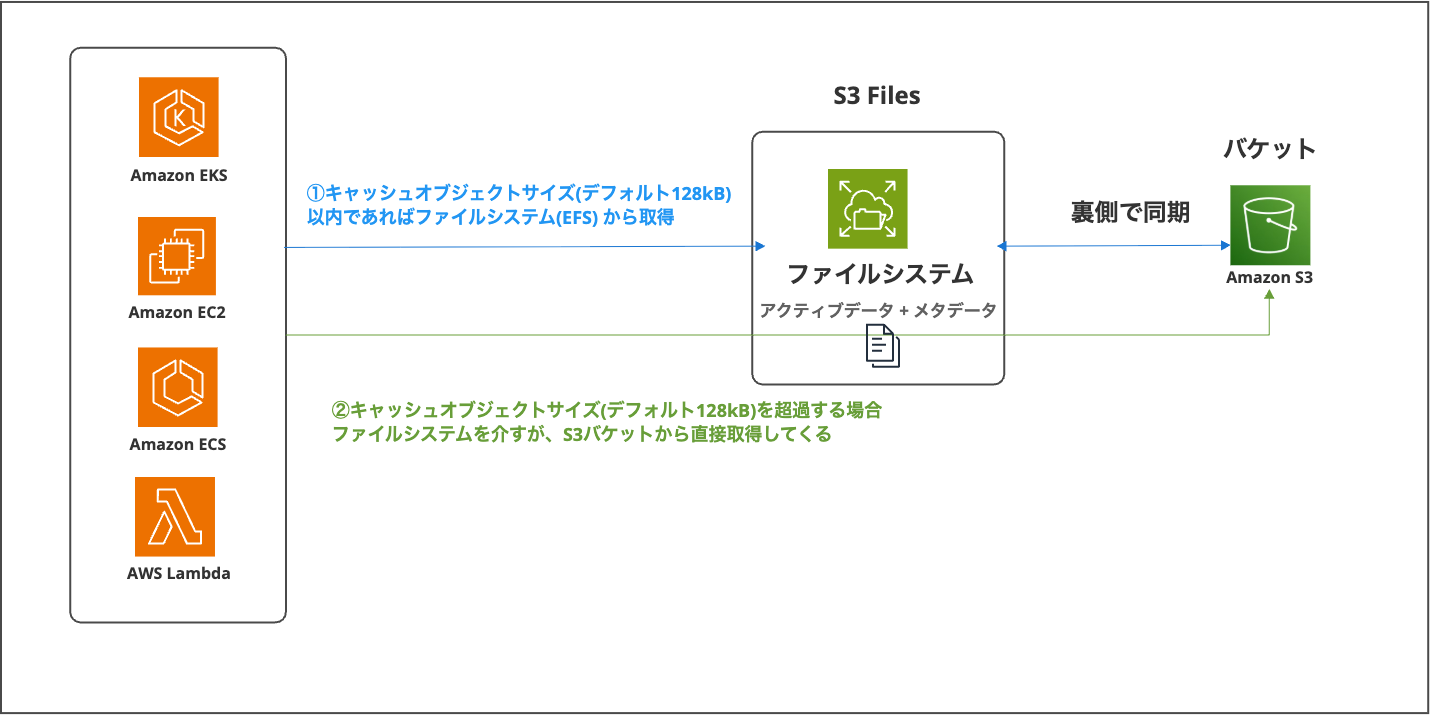
なお、公式ドキュメントでは内部のEFSを「高性能ストレージ(high-performance storage)」と表記していますが、本記事では「ファイルシステム」に統一します。
ファイルシステム内に保持されるアクティブデータサイズの閾値をsizeLessThanとして設定可能(デフォルト128kB)であり、この設定値を本記事では、「キャッシュオブジェクトサイズ」と統一しています。
同期の仕組み
S3 FilesはファイルシステムとS3バケット間で書き込み方向と読み込み方向で非対称な同期を行っています。
書き込み方向(ファイルシステム → S3)
同期タイミングについて
コンピューティングリソースからS3 Filesへの書き込みについて「約60秒」のバッファを設けてS3バケットへバックグラウンドで同期が実行されます。S3 FilesからS3バケットへの同期は変更後「約1分」で実行されます。
また、S3 Filesは同期される60秒間の間の複数の変更をまとめて単一のS3PUTオペレーションとして書き込みます。60秒以内に同一ファイルに対して複数回書き込みが行われた場合、S3バケットに反映されるのは最後の内容のみであり、S3バージョニングを有効にしていても、変更回数毎の複数バージョンを作成しないのでコスト効率化が可能です。
ファイルシステムとS3バケットの変更競合について
ファイルシステムへの書き込みとS3バケットへの直接アップロードが競合した場合、S3バケット側の内容が正として適用されます。ファイルシステム側の競合バージョンはファイルシステムルートの lost+found ディレクトリに自動的に退避され、競合が発生するとCloudWatch の LostAndFoundFiles メトリクス(名前空間: AWS/S3Files)で確認できます。
たとえば、ファイルシステム経由で /mnt/s3files/report.csv を編集したとします。S3 Files が変更内容を S3 バケットに同期する前に、別のアプリケーションが report.csv の新しいバージョンを S3 バケットに直接アップロードしました。S3 Files がこの競合を検出すると、ユーザーが編集した report.csv を「lost and found」ディレクトリに移動し、S3 バケットにあるバージョンと置き換えます。
読み込み方向(S3 → ファイルシステム)
S3バケットに対する直接変更は「S3イベント通知」で監視されており、既にファイルシステムにあるファイルへの変更は自動的に反映される一方、期限切れになったファイルや新規オブジェクトに関してはファイルシステム内にその都度同期されず、次回アクセスするタイミングでS3バケットから最新バージョンが取得されファイルシステムに同期されます。
S3 Files は、S3 イベント通知を使用して S3 バケットの変更を監視します。S3 API を使用する別のアプリケーションが S3 バケット内のオブジェクトを追加、変更、または削除すると、S3 Files は、現在ファイルシステムの高性能ストレージにデータが保存されているファイルについて、これらの変更をファイルシステムに自動的に反映します。ファイルシステムからデータが期限切れになったファイルは、次回アクセスするまで更新されません。次回アクセス時に、S3 Files は S3 バケットから最新バージョンを取得します。
インポートルールとキャッシュ期間について
S3バケットからファイルシステムへのデータインポートはインポートデータルールで制御できます。主な設定項目は以下の2つです。
| 設定項目 | デフォルト値 | 説明 |
|---|---|---|
| trigger | ON_DIRECTORY_FIRST_ACCESS | S3バケットからファイルシステムへのインポートタイミング。「ON_FILE_ACCESS」に変更するとインポート量を最小化できるが、初回読み取りレイテンシが上がる |
| sizeLessThan | 128KB | 自動インポートされるファイルサイズの上限。超えるファイルはS3から直接ストリーミング。0〜48TiBの範囲で変更可能 |
また、ファイルシステム内に保管されるデータには有効期限があり、デフォルトは「30日間」で「1日 ~ 365日」の設定が可能です。期限を超えると自動的にファイルシステムから削除され、次回アクセス時にS3バケットから再取得されます。なお、永続的にS3バケットに残るためデータロストは発生しません。
プロトコルと対応サービス
S3 FilesへのマウントはNFS「v4.2」および「v4.1」に対応しており、アクセス制御はPOSIXパーミッションとアクセスポイントの組み合わせで行います。
また、マウントできるコンピュートリソースはリリース時点で現在以下の4サービスとなっており、マウントターゲットはVPC内に配置されるため、接続元もVPC内のリソースに限定されます。
- EC2
- Lambda
- EKS
- ECS
オンプレミスからS3 Filesに接続する観点は公式ドキュメントにて言及されていませんでした。
ファイルシステムのパフォーマンスについて
スループットやIOPSはプロビジョニングする必要なく、全てワークロードに合わせて自動的にスケーリングされます。
公式ドキュメントに記載のスペックは以下の通りです。
| 項目 | スペック |
|---|---|
| 読み取りスループット(ファイルシステム全体) | 最大テラバイト/秒 |
| 書き込みスループット(ファイルシステム全体) | 1〜5 GiB/s |
| 読み取り IOPS(ファイルシステムあたり) | 最大 250,000 |
| 書き込み IOPS(ファイルシステムあたり) | 最大 50,000 |
| 読み取りスループット(クライアントあたり) | 最大 3 GiB/s |
読み取りスループットは接続するコンピューティングインスタンス数と並列度に応じてスケールし、書き込みスループットはワークロードに応じてエラスティックにスケールします。
初回アクセスのレイテンシについては、ディレクトリへの初回アクセス時にS3バケットからメタデータとキャッシュオブジェクトサイズ以下のファイルデータをインポートするため、2回目以降と比べてレイテンシが高くなります。一度インポートされた後はファイルシステムから低レイテンシで返却されます。
料金について
S3 Files の料金はファイルシステム(EFS)内に保存されているアクティブデータ量に比例する従量課金方式です。ファイルシステムに乗っているデータ量とその読み書きアクセスに対してのみ課金され、S3バケットから直接取得する場合は通常のS3のGETリクエスト料金が適用されます。
以下のブログが非常にわかりやすいので参考にして下さい。
- S3 料金ページを参照してください。
やってみた
早速確認した以下の仕様を実際に検証してみます。
- ① 基本動作確認(書き込み・読み込み・一覧取得)
- ② ファイルシステム → S3 同期(書き込み方向)
- ③ S3 → ファイルシステム 同期(読み込み方向)
- ④ 競合発生時の挙動
- ⑤ 連続書き込みのバッチ処理
構成
今回は以下の構成でLambdaからマウントして検証しました。
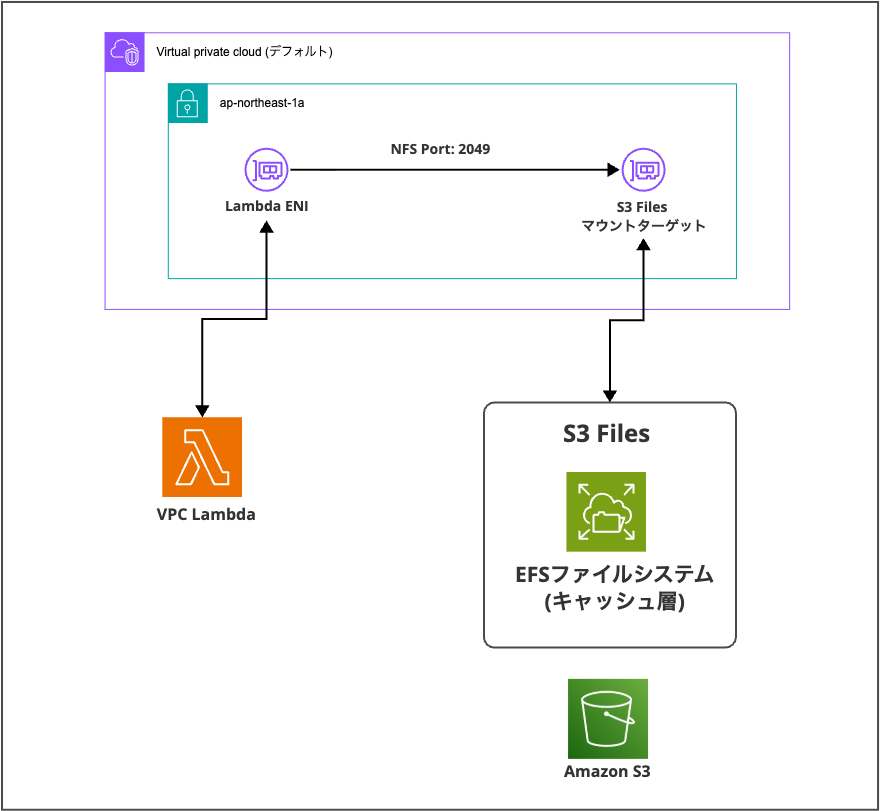
事前準備としてあらかじめ「VPC」と「サブネット」は用意しています。
- VPC: デフォルト VPC
- サブネット: ap-northeast-1a(IPv4 CIDR: 172.30.0.0/24、サブネット ID: subnet-014e8e0ef4e18965a)
セキュリティグループの作成
S3 Filesの作成前にVPC Lambda ENI, S3 Filesのマウントターゲットの両方に紐づける、セキュリティグループを作成します。
S3 FilesではNFSを用いて接続するため、ポート2049に対して開放しています。
セットアップ手順
まず、Lambda の SG にアウトバウンド TCP 2049(NFS)をマウントターゲットの SG に対して許可します。インバウンドは無しです。
- セキュリティグループ: lambda-s3files-sg
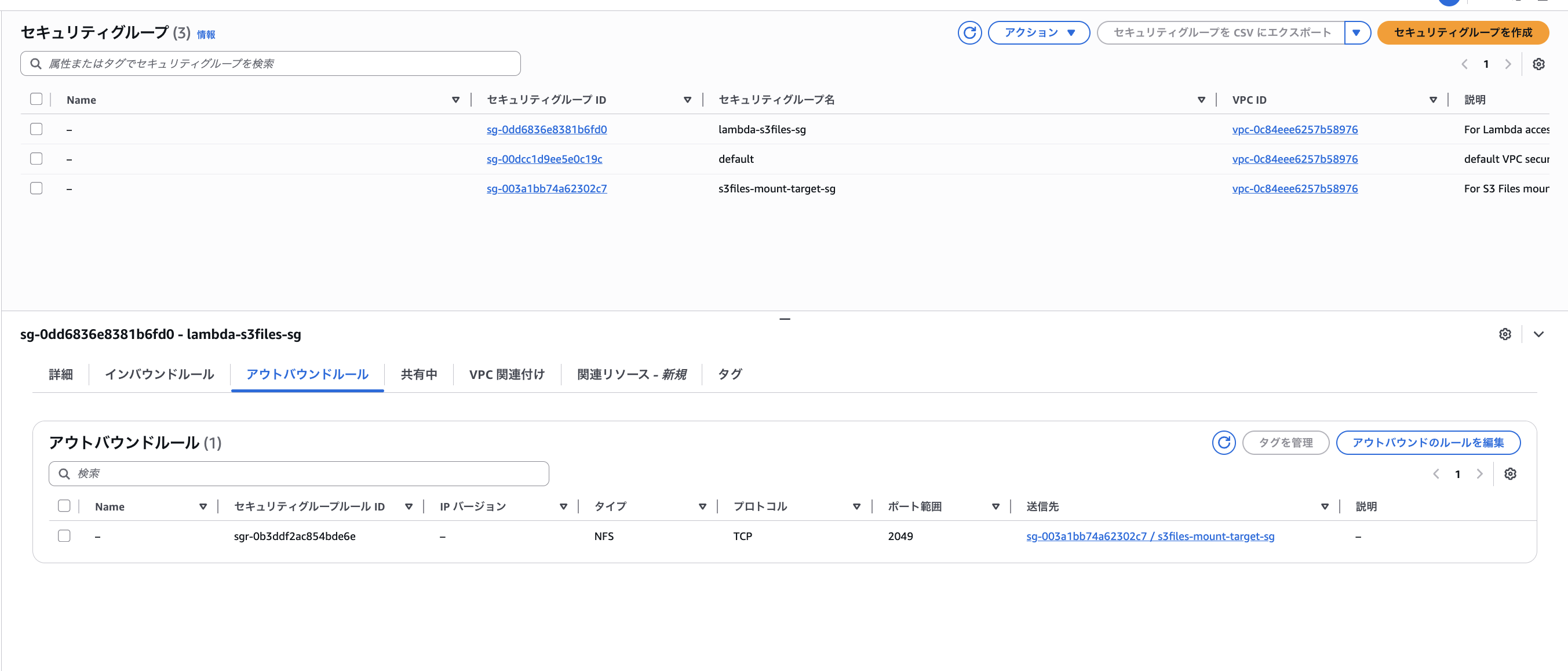
マウントターゲットのSG にはインバウンド TCP 2049 を Lambda の SG からのみ許可します。アウトバウンドは無しです。
- セキュリティグループ: s3files-mount-target-sg
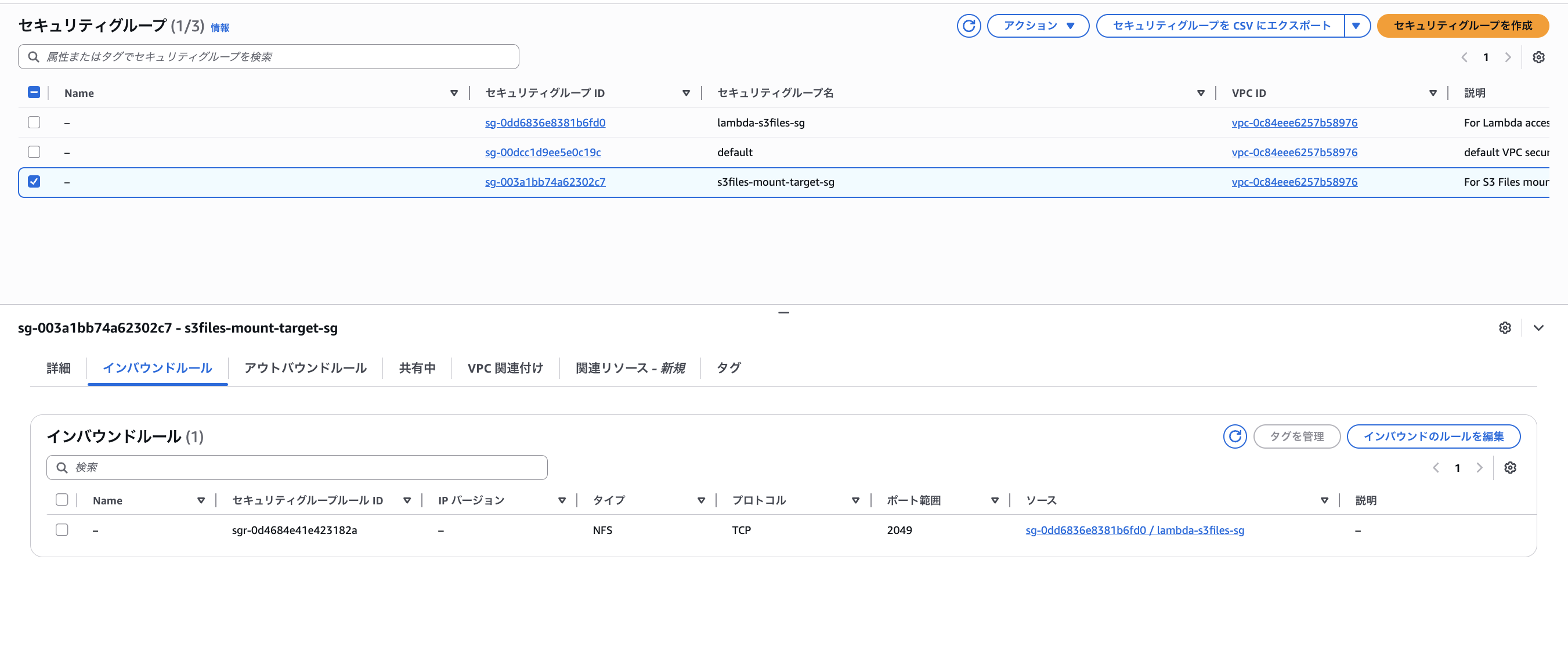
これにてセキュリティグループの準備が完了しました。
ファイルシステムの作成
続いてS3 Files のファイルシステムを作成します。
セットアップ手順
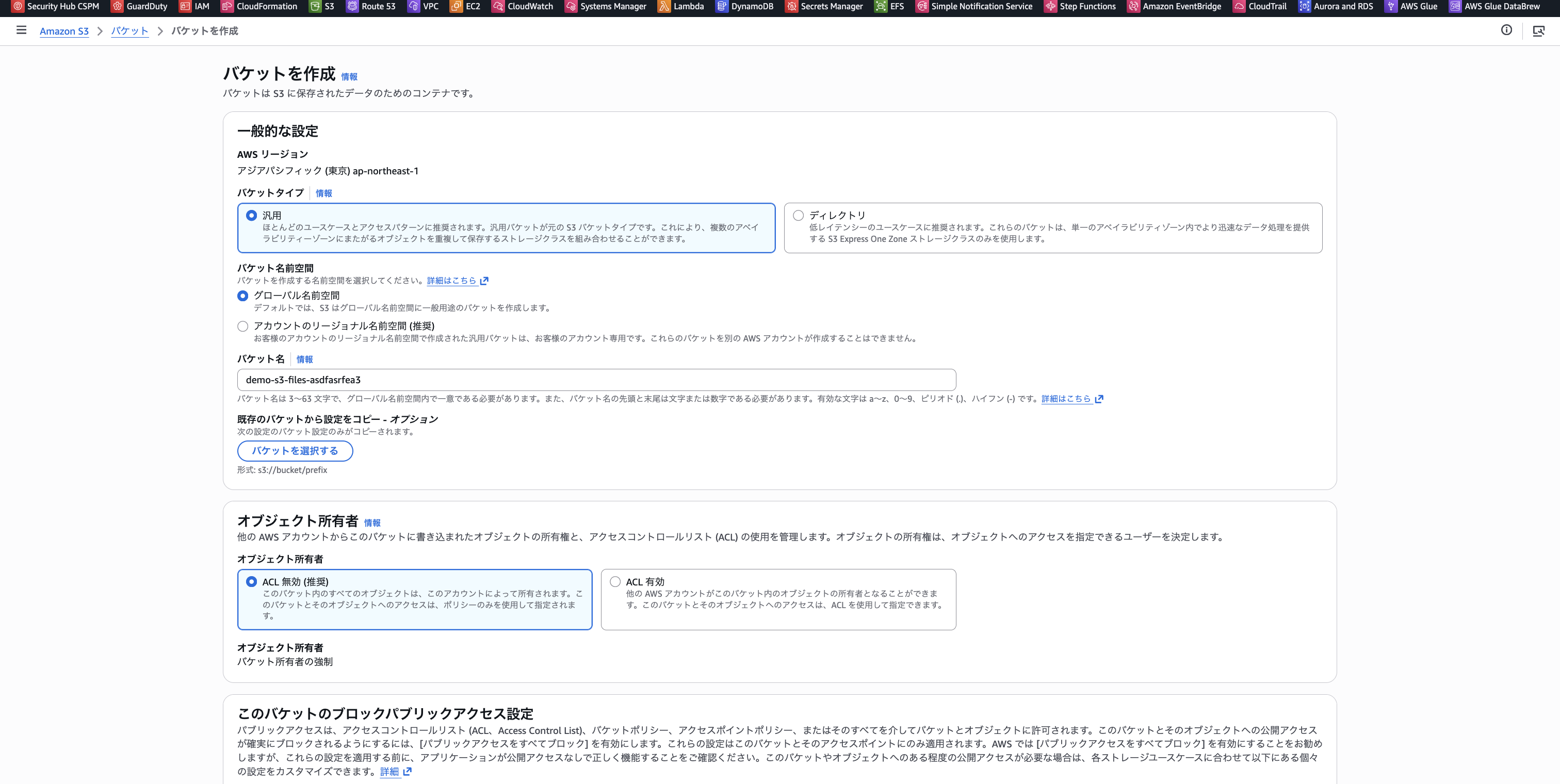
まずはじめに、S3 Files のリンク先となる S3 バケットを作成します。バージョニングの有効化が必須です。後はデフォルトで作成しました。
- デモ用バケット名: demo-s3-files-asdfasrfea3
続いて S3 コンソールの左ナビから「ファイルシステム」>「ファイルシステムの作成」を選択します。
ファイルシステム作成画面で上記作成したバケット・デフォルトVPCプレフィックスを入力します。
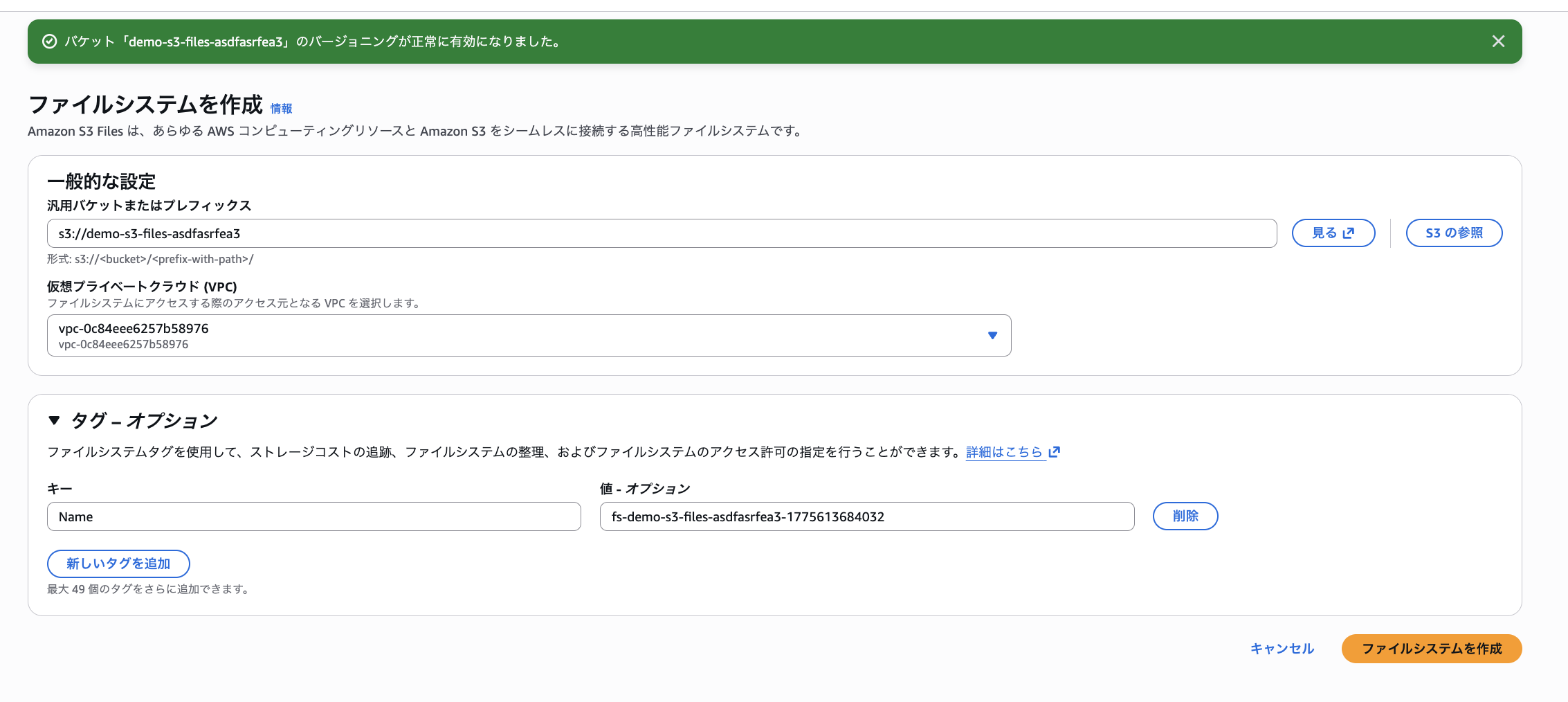
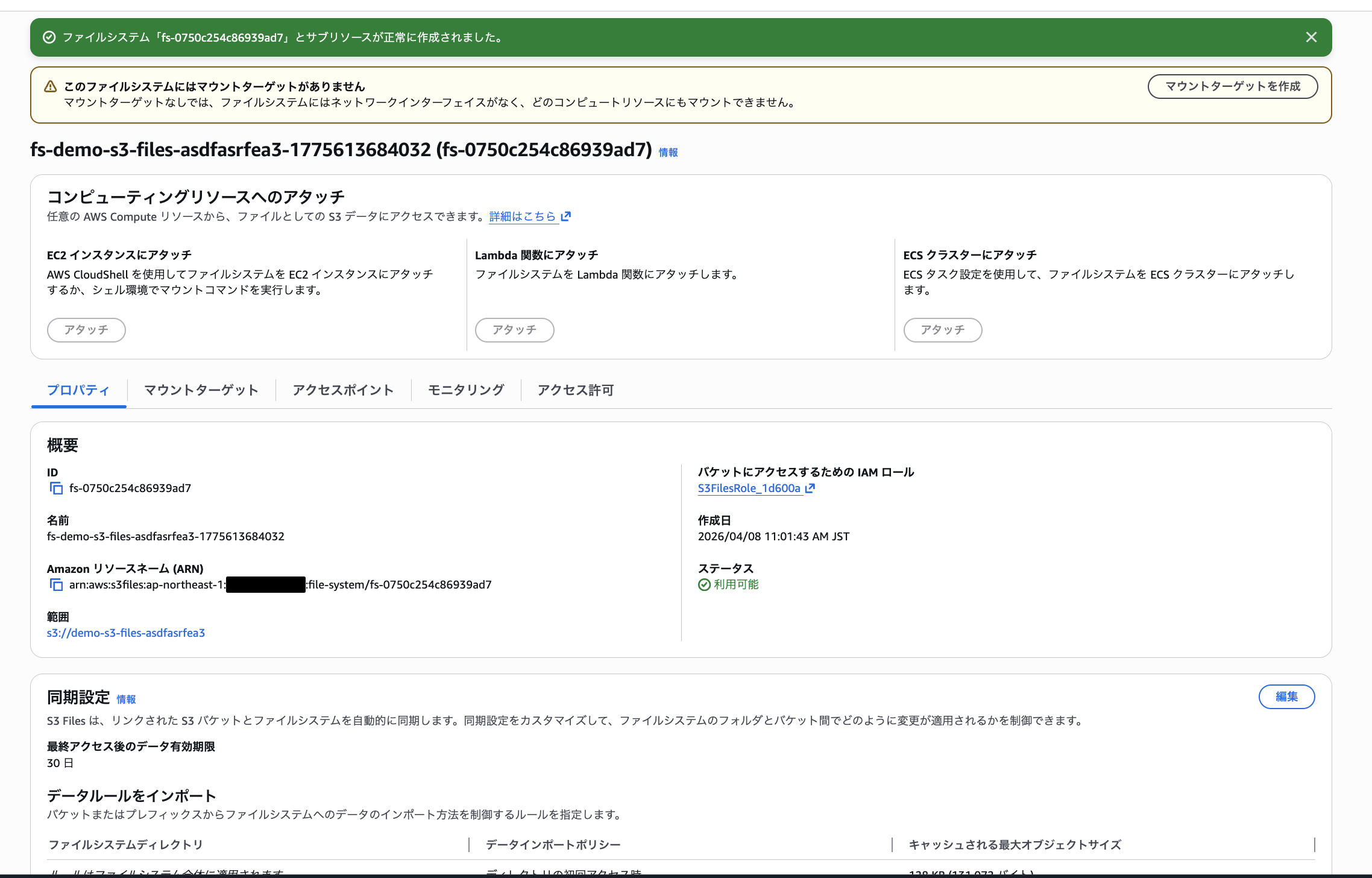
作成直後はマウントターゲットがなく警告が表示されます。続けてマウントターゲットを作成します。
続いてあらかじめ用意しているサブネットにマウントターゲットを作成します。
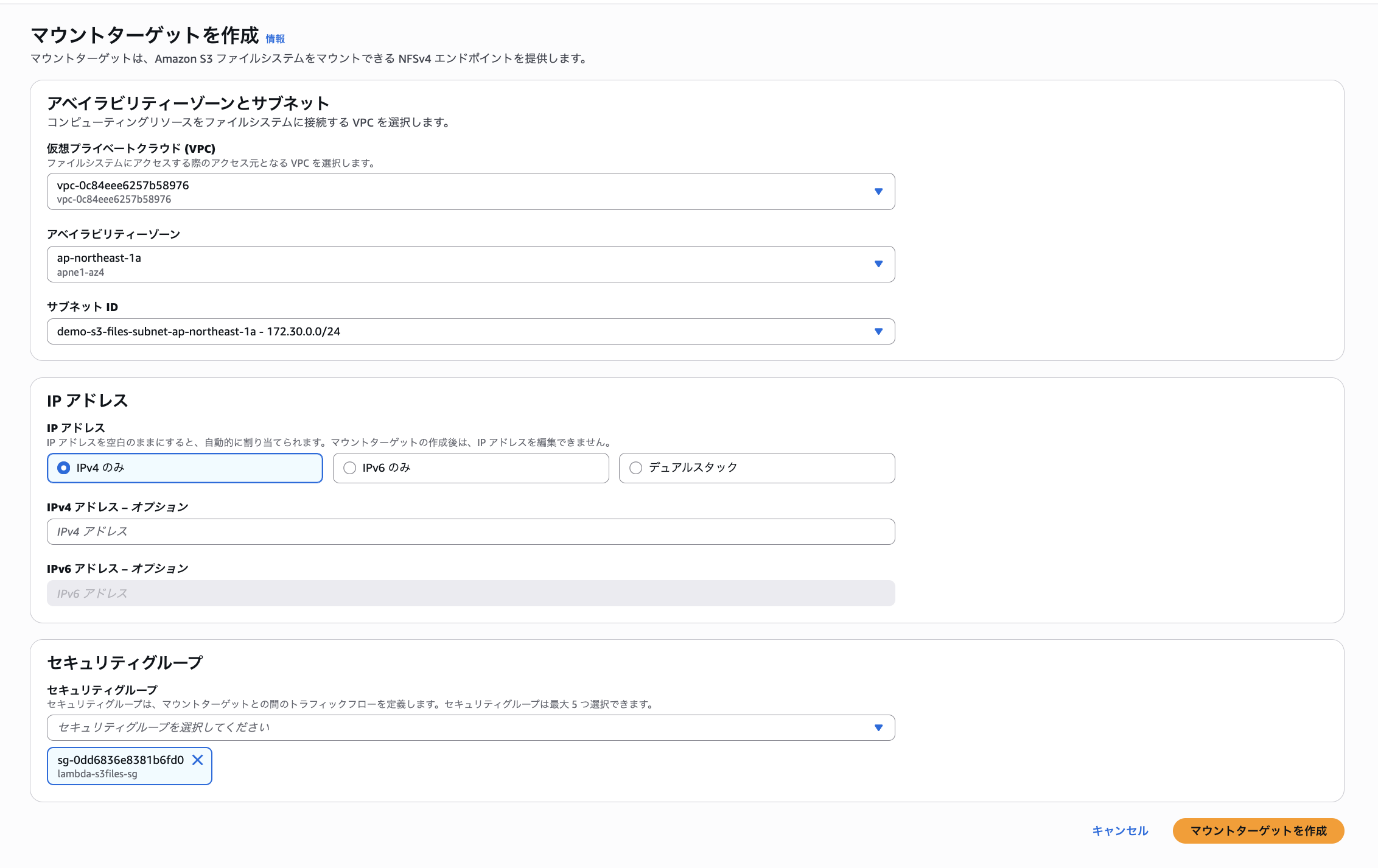
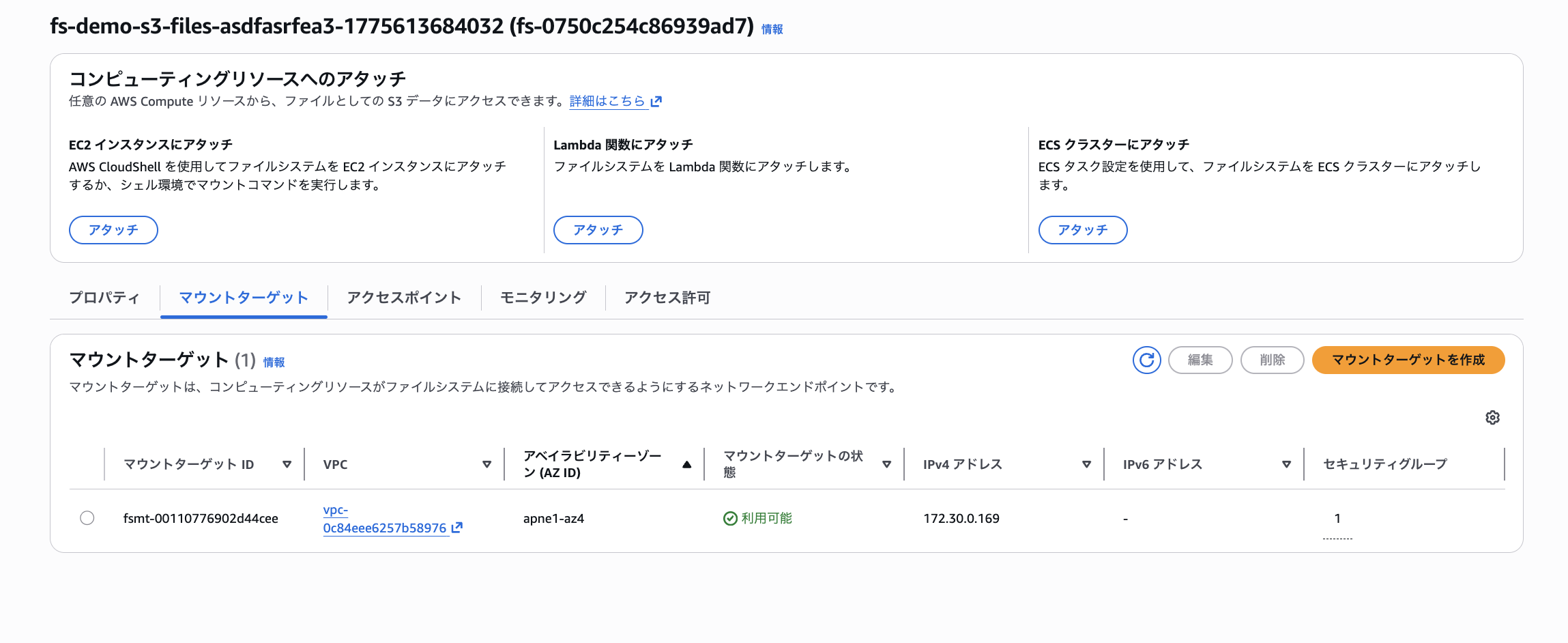
この際、あらかじめ作成したセキュリティグループ「s3files-mount-target-sg」をマウントターゲットに紐づけています。
マウントターゲットのステータスが「利用可能」になるまで待ちます。
続いてアクセスポイントの設定を確認します。ファイルシステムを作成した時点で以下のデフォルトアクセスポイントが自動作成されていました。
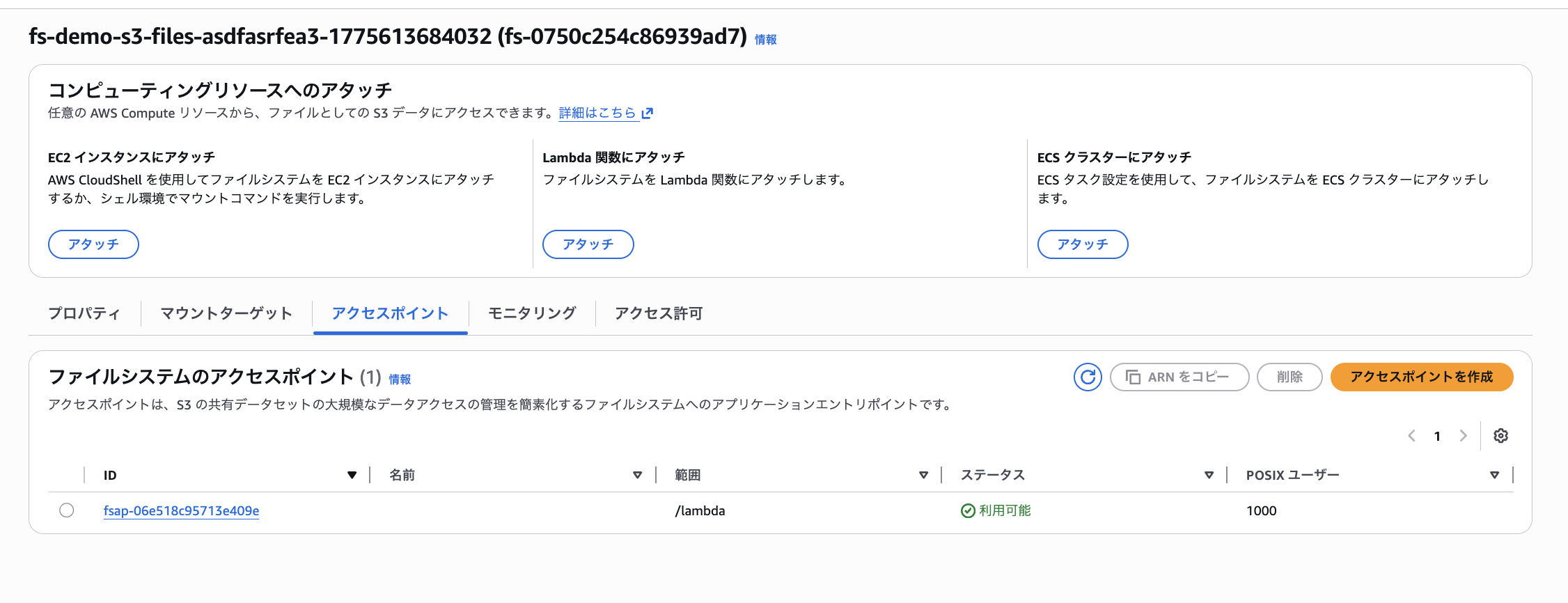
これにてS3 Filesのセットアップは完了です。
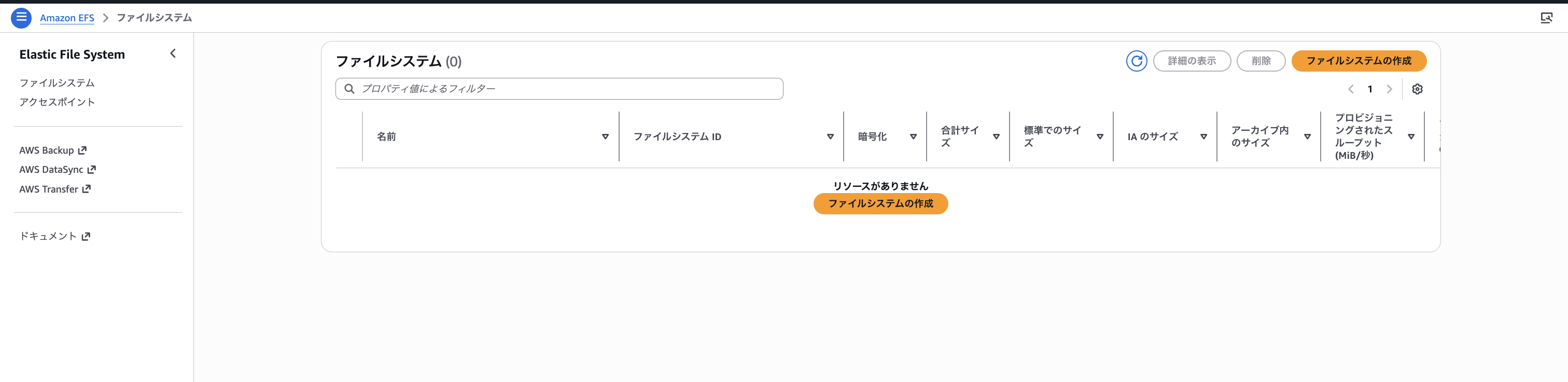
なお、S3 Files は内部的にEFSのインフラを利用していますが、以下のようにEFS コンソールには何も表示されません。マネージドにAWSにて裏側で管理してくれているというポイントをおさえておきましょう。
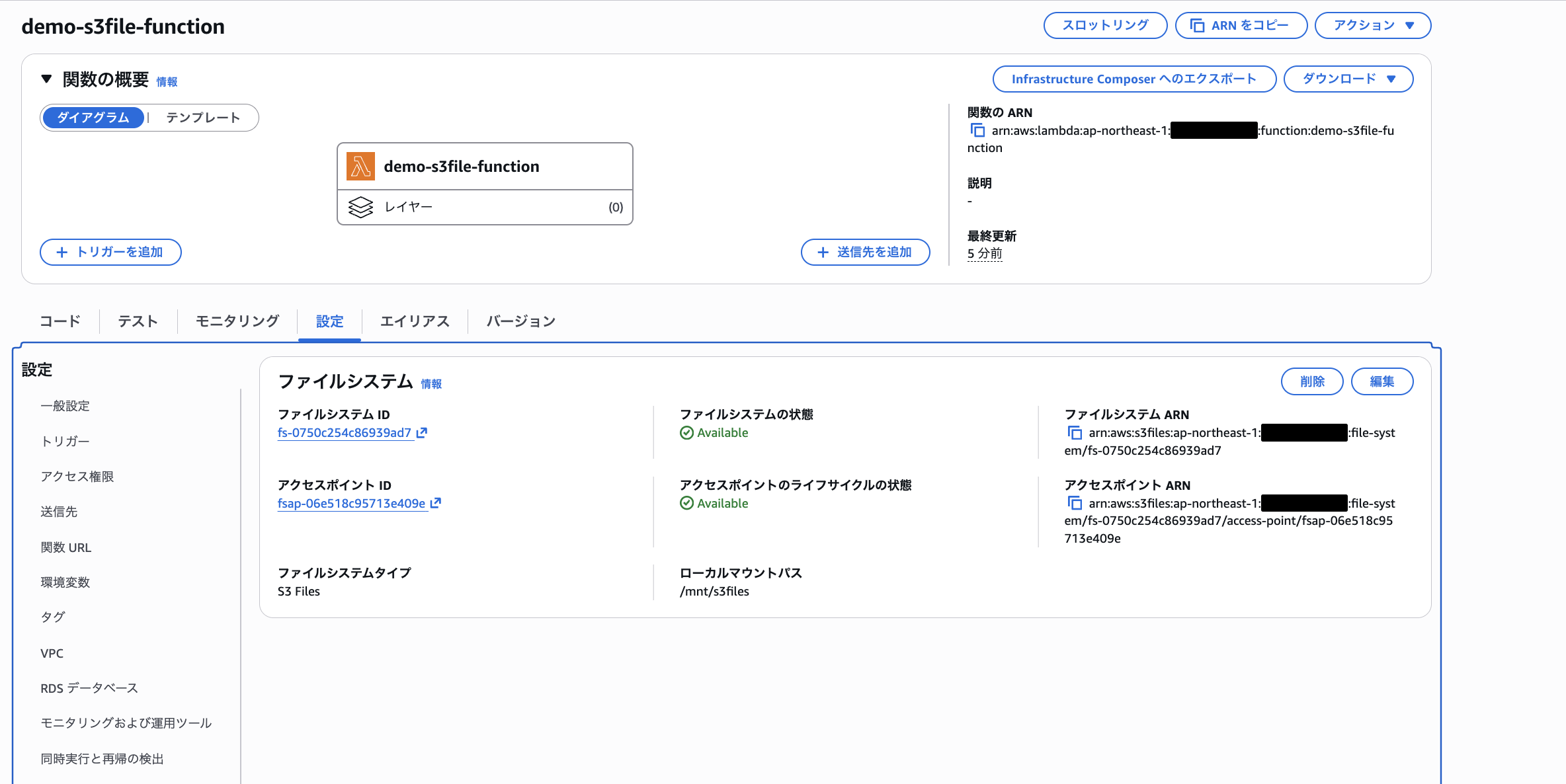
Lambda 関数の設定
S3 Filesの作成ができたのでLambda関数を作成してS3 Filesをマウントします。
Lambda セットアップ手順
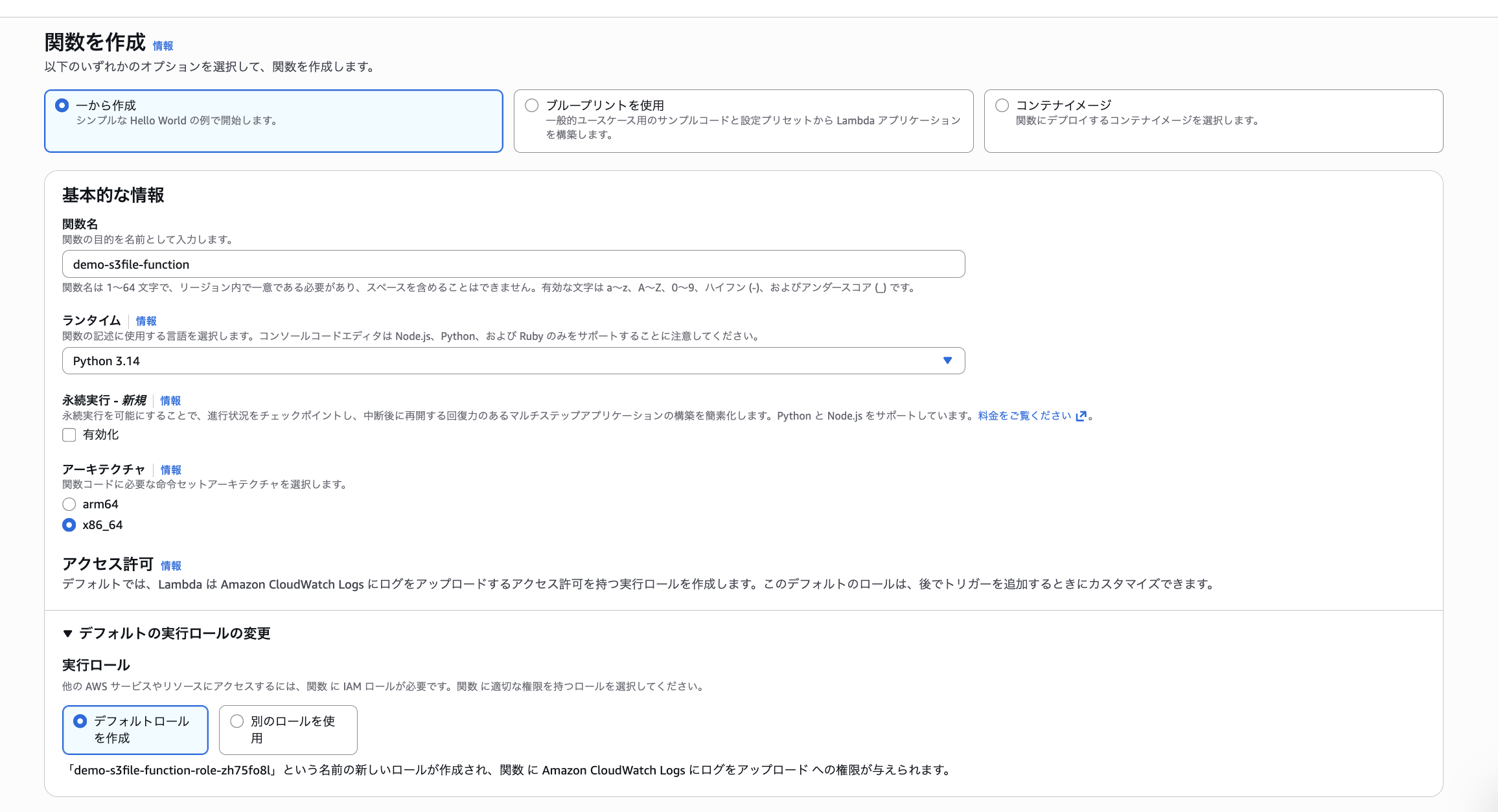
Lambda 関数を作成する際にVPCにアタッチして、サブネット・セキュリティグループを設定します。
- Lambda 関数名: demo-s3file-function
- ランタイム: python 3.14
デフォルトで作成された実行IAMロールに S3 Filesのアクセスポリシーを追加します。デフォルトで付与される CloudWatch Logs・VPC アクセスの 2 つに加え、S3 Files 用ポリシーを追加した計 3 ポリシーの構成です。
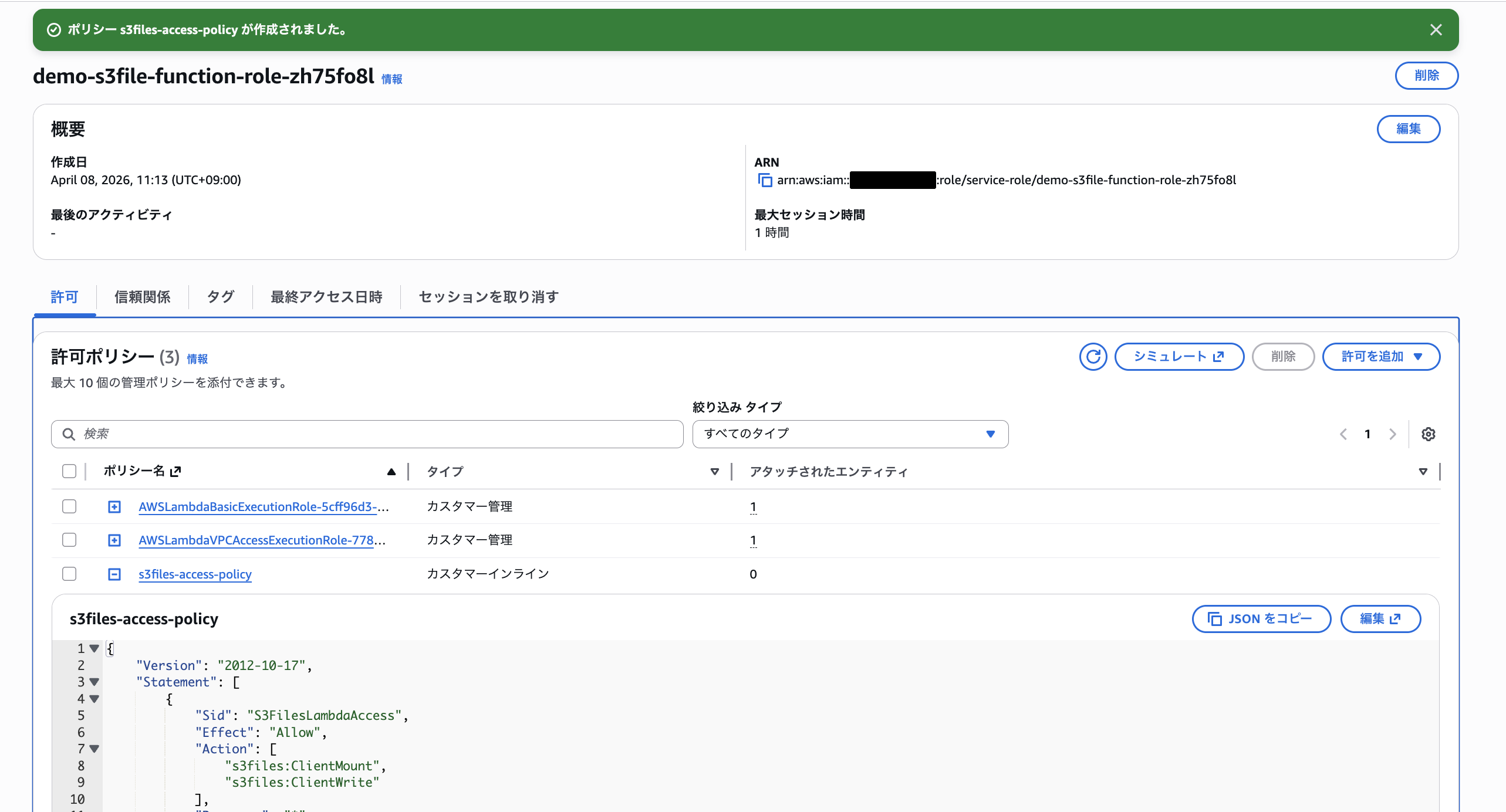
S3 Filesへのアクセス権限は以下を付与しています。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3FilesLambdaAccess",
"Effect": "Allow",
"Action": [
"s3files:ClientMount",
"s3files:ClientWrite"
],
"Resource": "*"
},
{
"Sid": "S3DirectRead",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion"
],
"Resource": "arn:aws:s3:::bucket-name/*"
},
{
"Sid": "S3FilesConsoleSetup",
"Effect": "Allow",
"Action": [
"s3files:ListFileSystems",
"s3files:ListAccessPoints",
"s3files:GetFileSystem",
"s3files:GetAccessPoint",
"s3files:CreateAccessPoint"
],
"Resource": "*"
}
]
}
続いて、Lambda 設定の「ファイルシステム」からファイルシステムをアタッチします。ファイルシステムの種類に「S3 ファイル」を選択し、先ほど作成したアクセスポイントと Lambda 内のローカルマウントパス(/mnt/s3files)を設定します。
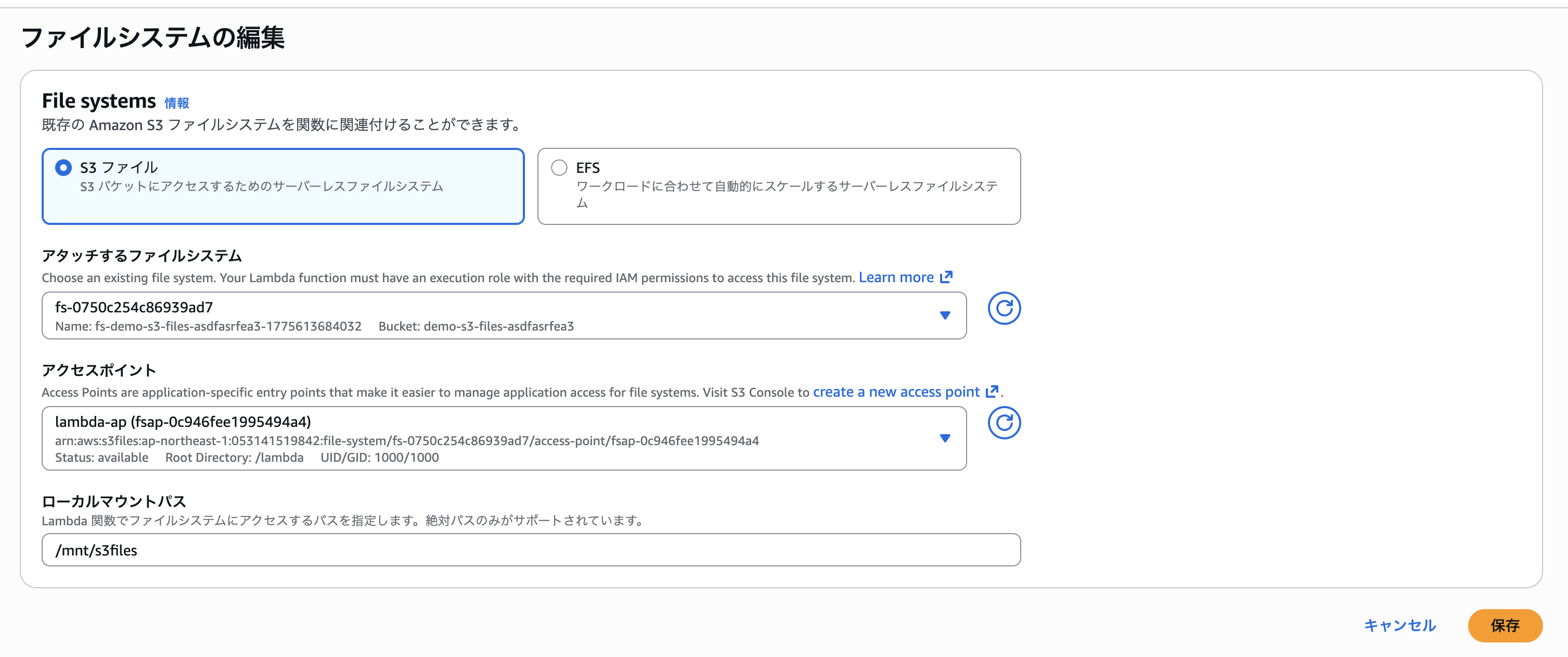
これにてLambda関数の作成とS3 Filesへのマウントが完了しました。実際に動作を確認してみます。
① 基本動作確認
マウントパス/mnt/s3filesに対して書き込み・読み込み・一覧取得の3つの操作を実行し、すべて正常に動作することを確認しました。
検証詳細
Lambda 関数のコードは以下の通りです。
import json
import os
MOUNT_PATH = "/mnt/s3files"
def lambda_handler(event, context):
action = event.get("action")
if action == "write":
filename = event.get("filename", "test.txt")
content = event.get("content", "Hello from Lambda!\n")
filepath = os.path.join(MOUNT_PATH, filename)
with open(filepath, "w") as f:
f.write(content)
return {
"statusCode": 200,
"body": json.dumps({"message": f"{filename} を書き込みました"}, ensure_ascii=False),
}
elif action == "read":
filename = event.get("filename")
filepath = os.path.join(MOUNT_PATH, filename)
with open(filepath, "r") as f:
content = f.read()
return {
"statusCode": 200,
"body": json.dumps({"content": content}, ensure_ascii=False),
}
elif action == "list":
entries = os.listdir(MOUNT_PATH)
return {
"statusCode": 200,
"body": json.dumps({"entries": sorted(entries)}, ensure_ascii=False),
}
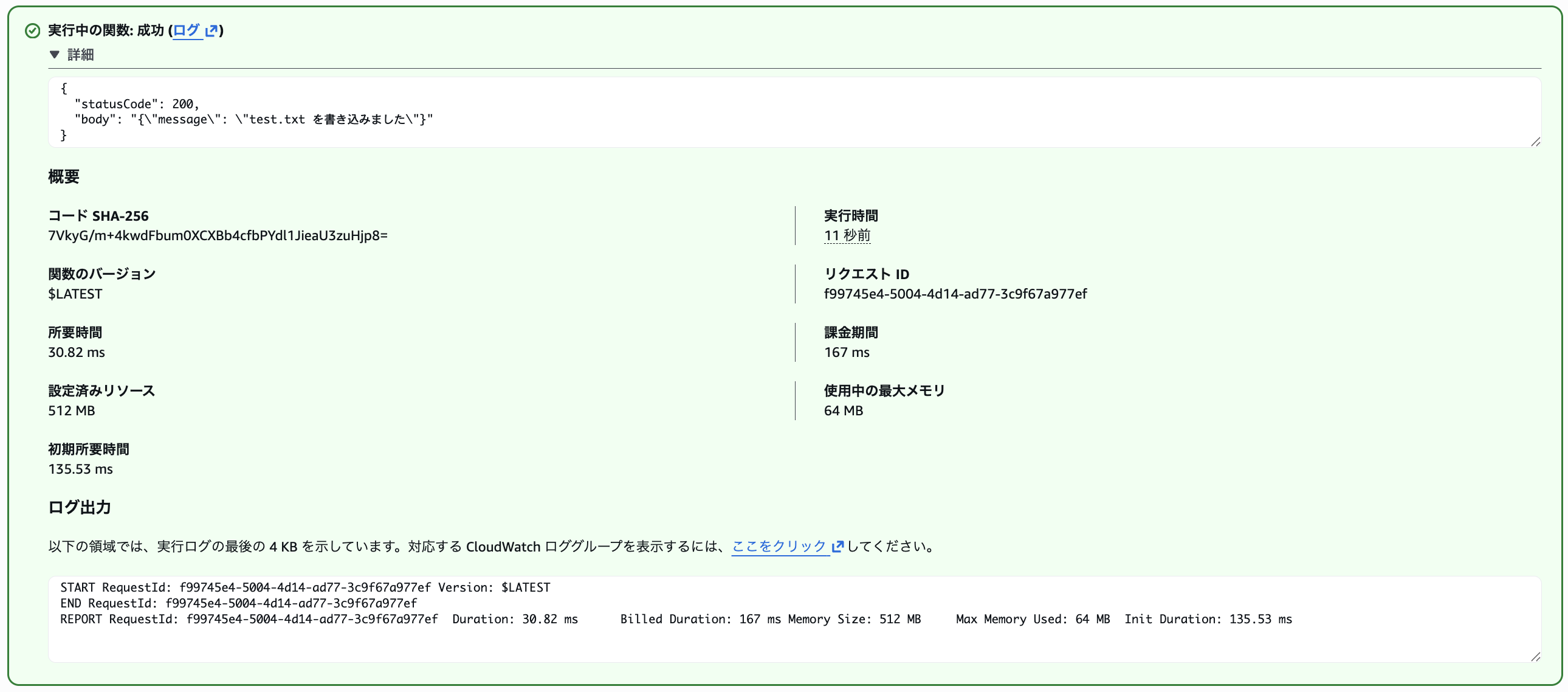
{"action": "write"} のテストイベントを実行すると、
指定したテストファイルと内容がS3 Filesに書き込まれます。以下のように書き込みが成功しました。
SDKを通してS3を操作しているのではなく、osレベルのファイル書き込みでS3バケットに対してデータが書き込めるのが今回の最大のポイントですね。
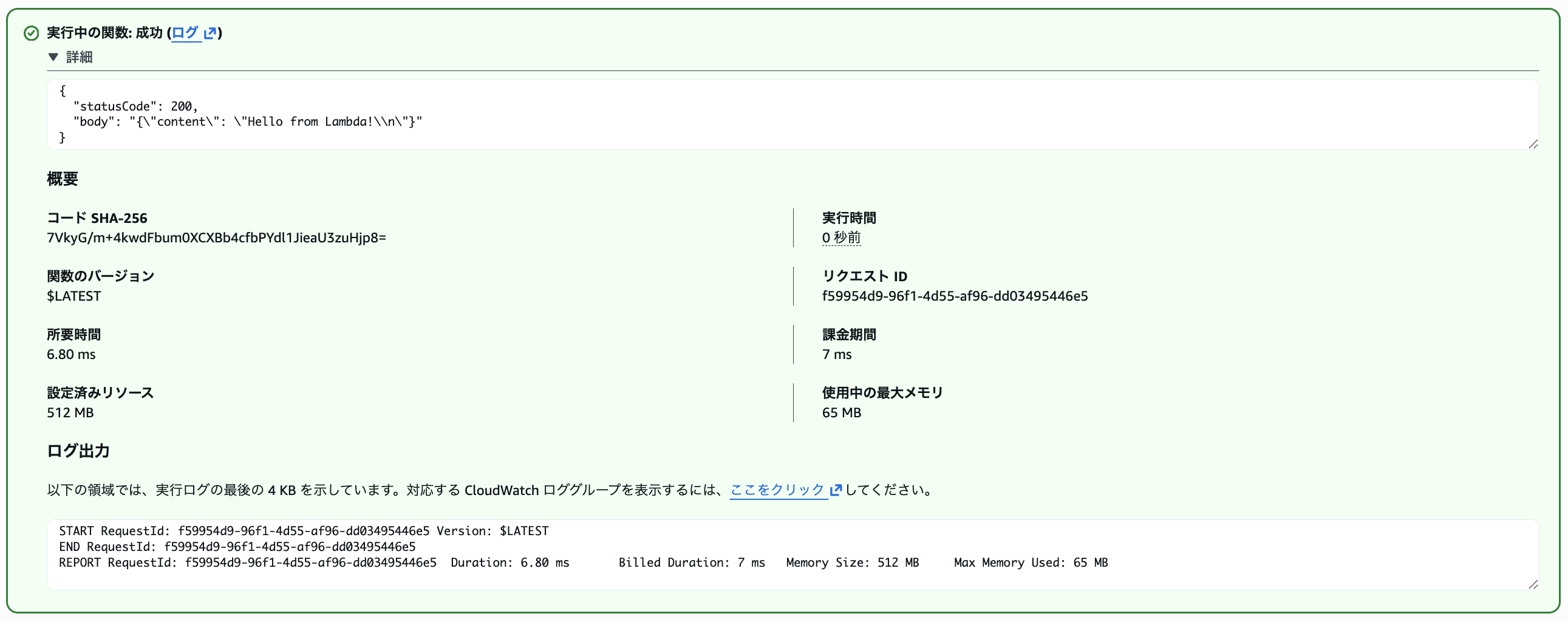
読み取りに関しても以下のように問題なくできます。
{"action": "read", "filename": "test.txt"}
リスト結果
{"action": "list"}
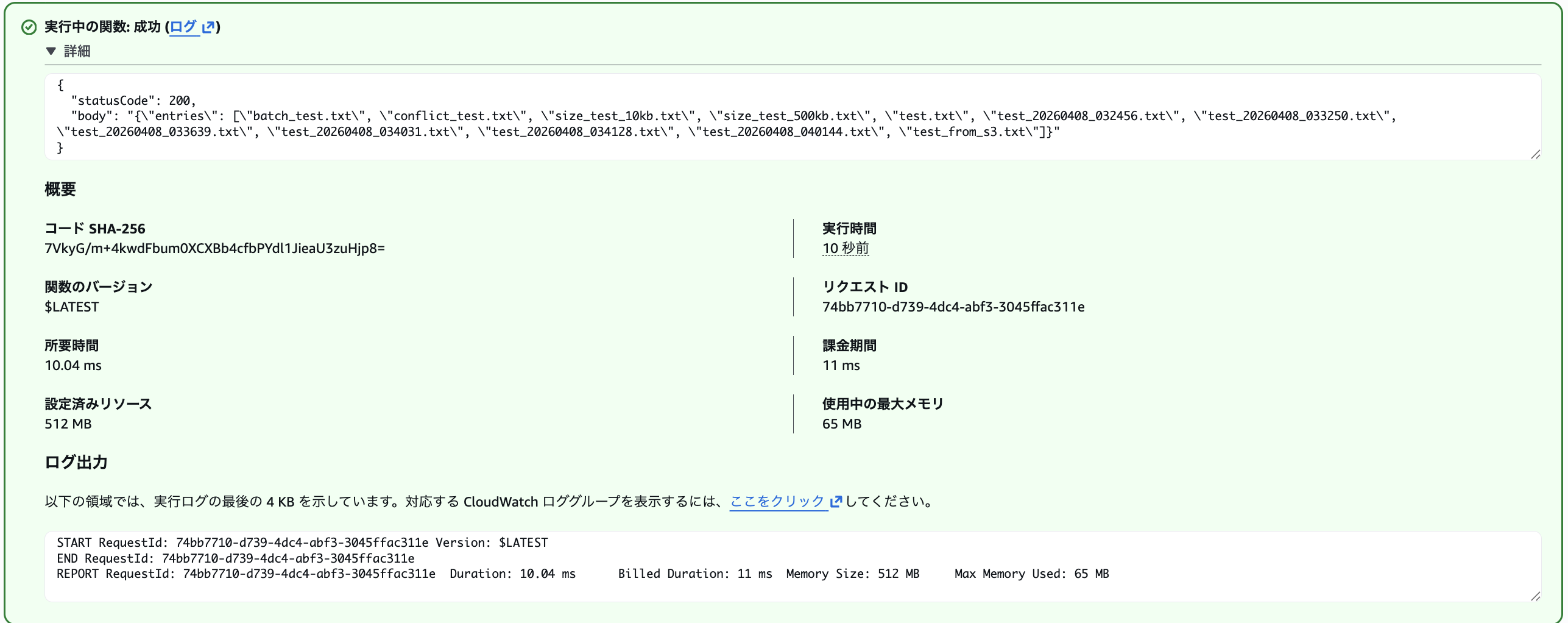
その他複数回の書き込みを行い、S3バケット内にファイルが保存されていることを確認しました。
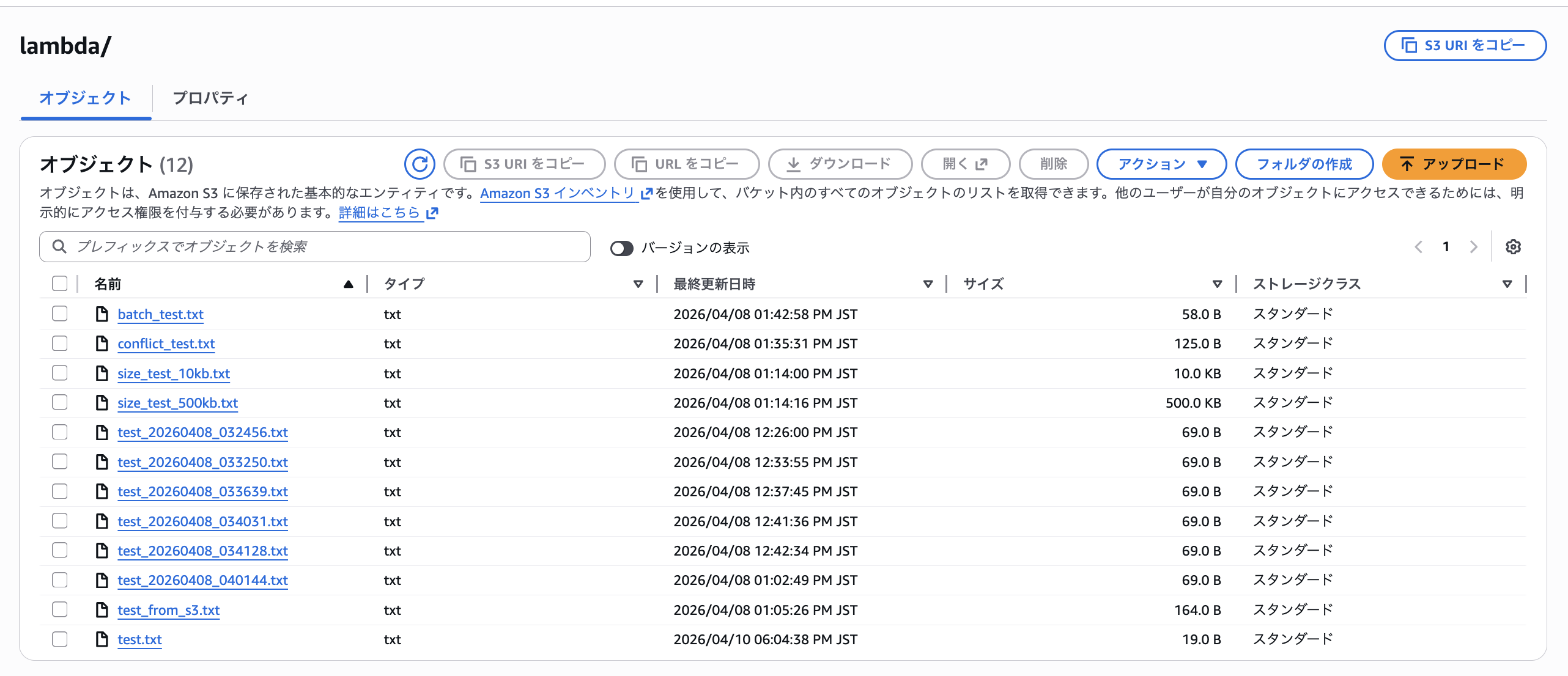
② ファイルシステム → S3バケット同期(書き込み方向)
続いて、Lambda でファイルを書き込んだ後、ファイルシステムからS3バケットにオブジェクトが現れるまでの時間を計測しました。
検証詳細
Lambda から書き込みを実行します。
# テストイベント
{"action": "write", "filename": "sync_test.txt", "content": "Written at Lambda\n"}
「18:15:20」 に書き込み成功しました。
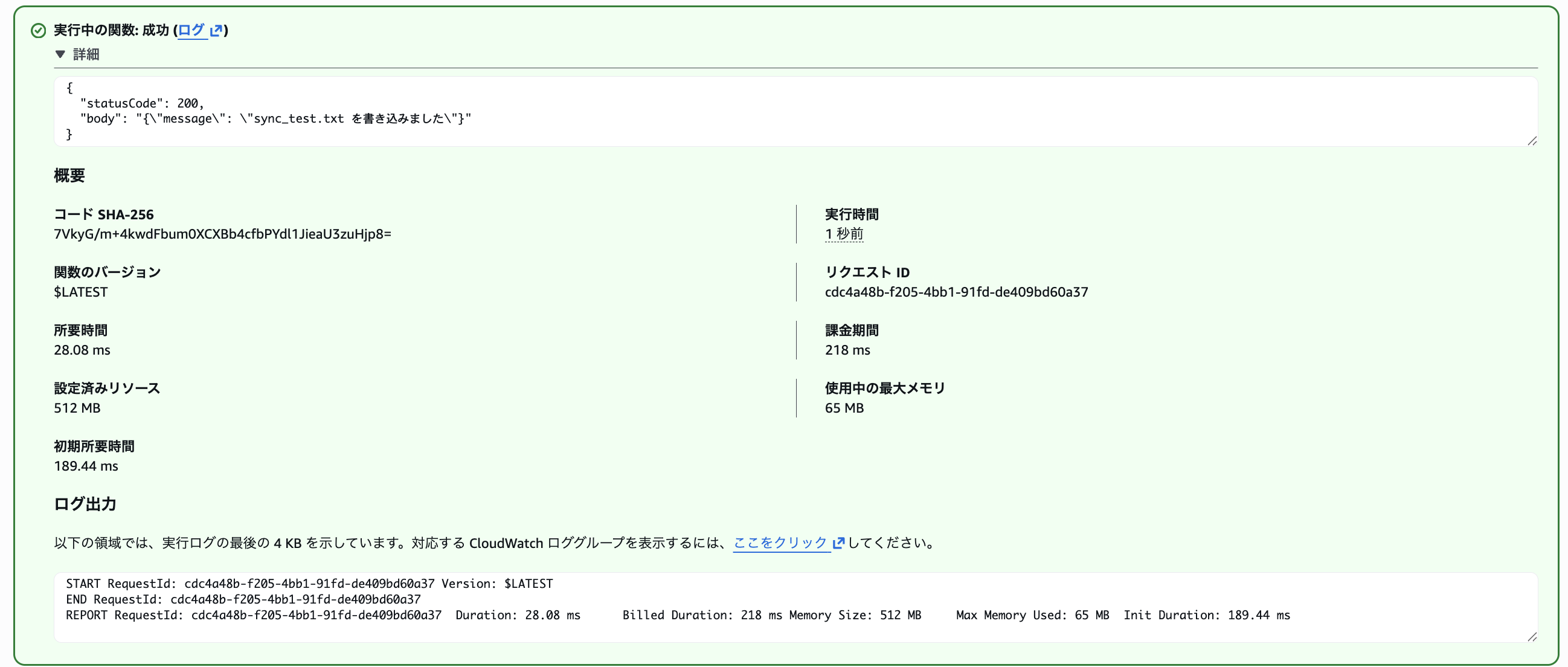
「18:16:23」 にS3バケットに現れました。「約63秒」たってS3バケットに書き込んだファイルが出現しました。
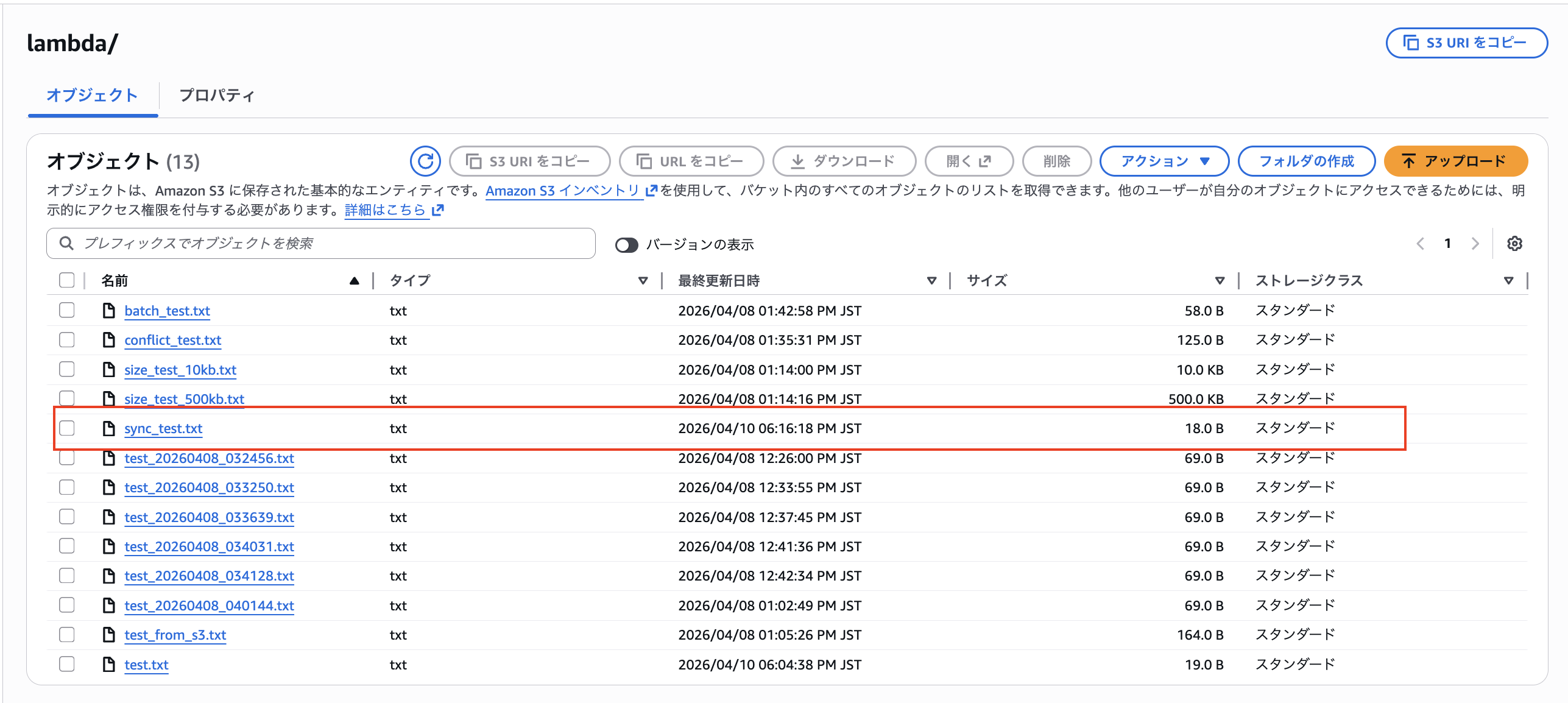
③ S3 → ファイルシステム 同期(読み込み方向)
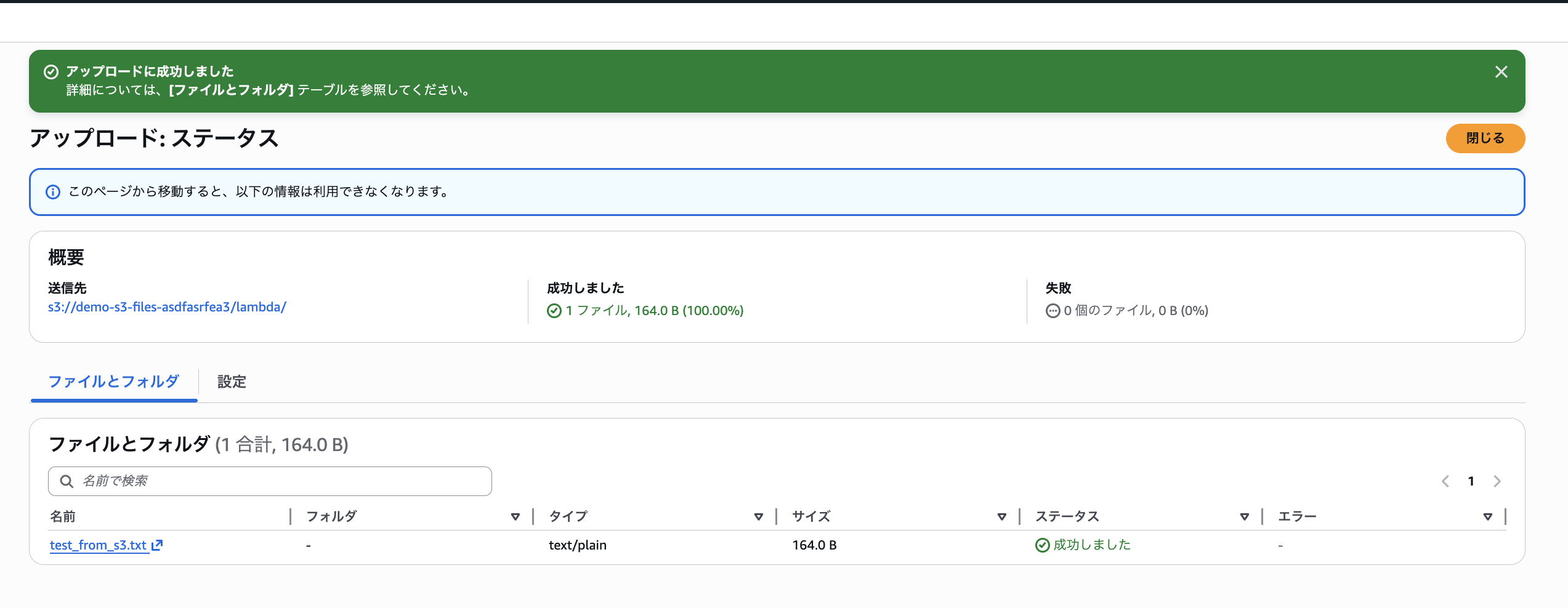
S3コンソールからlambda/test_from_s3.txtを直接アップロードし、Lambdaから時間を置かずに即座に読み込めるか確認しました。
検証詳細
S3 コンソールから lambda/ プレフィックスに test_from_s3.txt を直接アップロードします。
アップロード直後に Lambda から読み込みを実行します。
# テストイベント
{"action": "read", "filename": "test_from_s3.txt"}
S3アップロード直後に読み込みに成功しました。新規オブジェクトはファイルシステムに同期されていませんが、Lambda がreadを要求したタイミングで即座にS3バケットから取得されることを確認しました。
④ 競合発生時の挙動(lost+found)
LambdaとS3コンソールから同じファイルに同時に書き込み、競合発生時の挙動を確認しました。
検証詳細
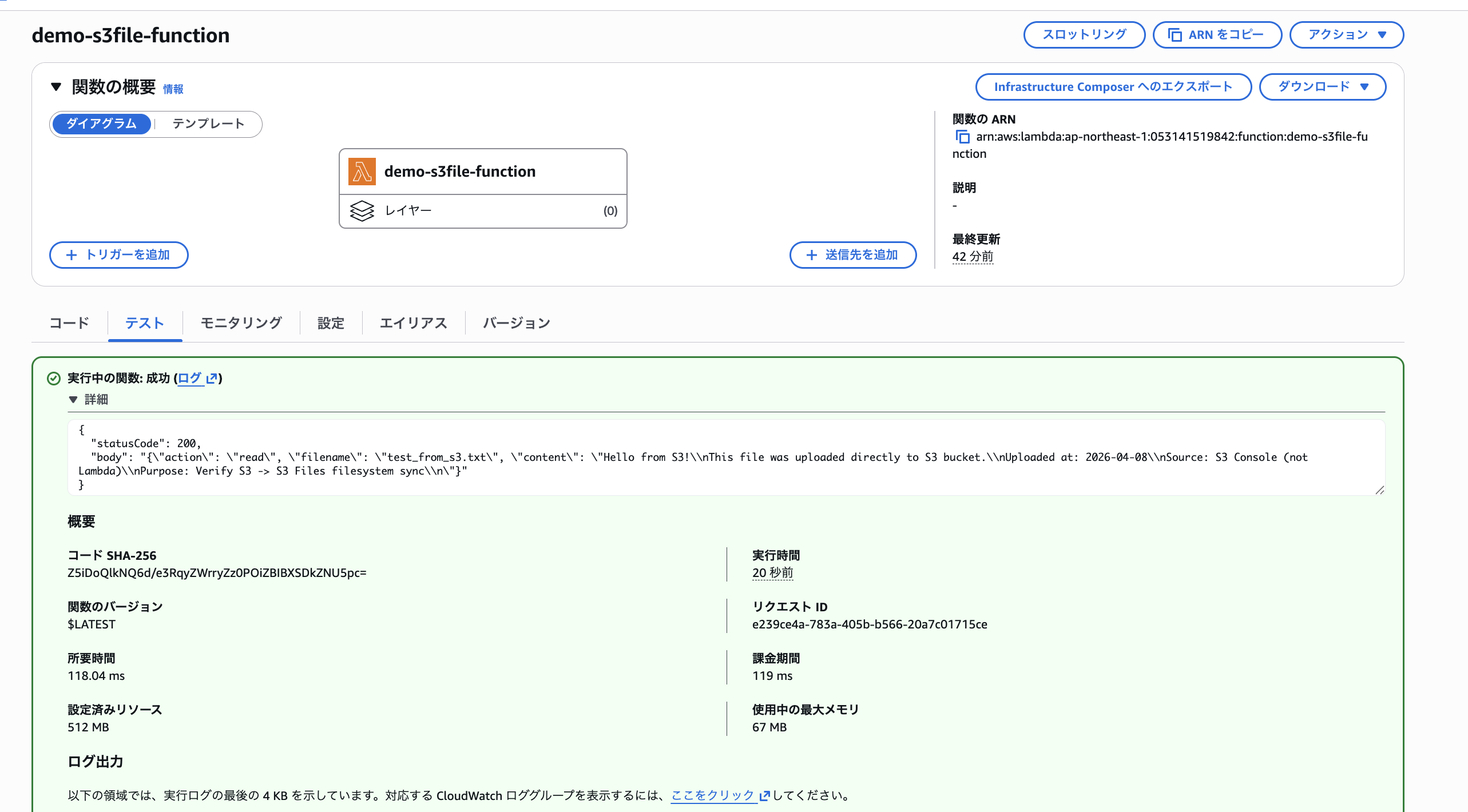
Lambda からconflict_test.txtを書き込みます。
# テストイベント
{"action": "write_conflict"}
def write_conflict():
filepath = os.path.join(MOUNT_PATH, "conflict_test.txt")
timestamp = datetime.datetime.now(datetime.timezone.utc).isoformat()
with open(filepath, "w") as f:
f.write(f"Written from Lambda\nTimestamp: {timestamp}\n")
return {
"statusCode": 200,
"body": json.dumps({
"message": "ファイルを書き込みました。60秒以内にS3コンソールから lambda/conflict_test.txt を上書きしてください。",
}, ensure_ascii=False),
}
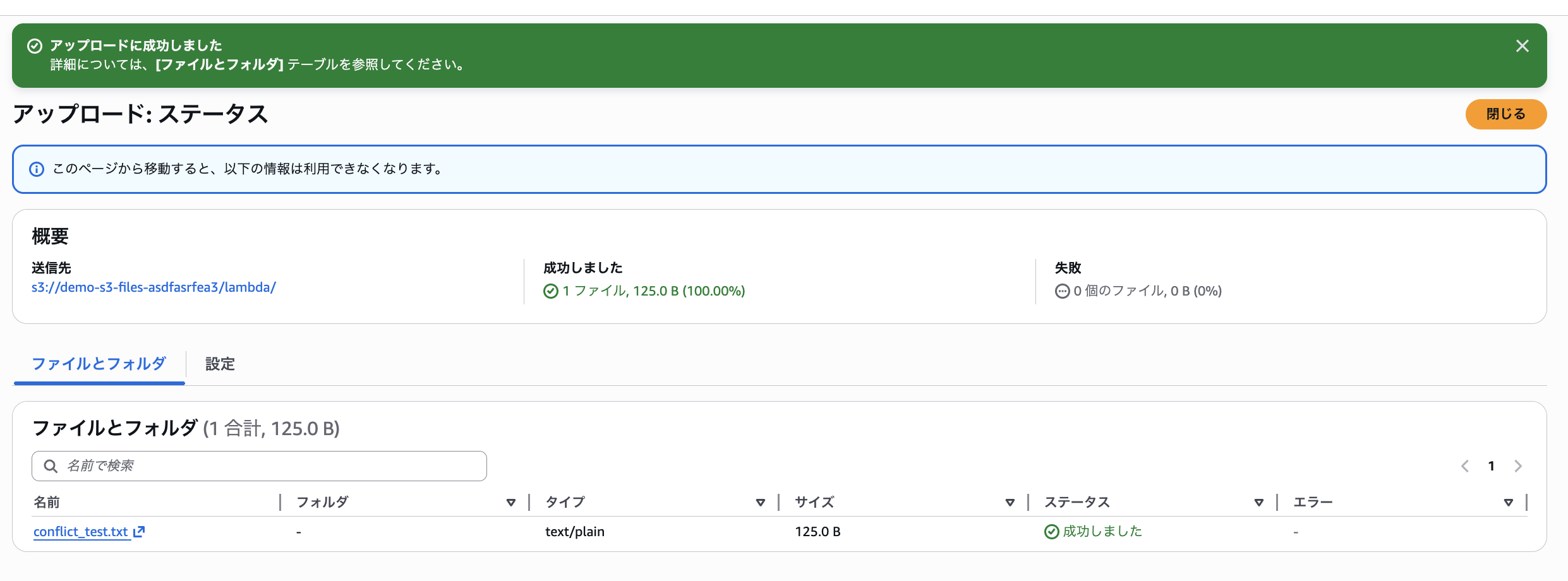
Lambdaが書き込んでから60秒以内に、S3コンソールから同じオブジェクトパスに別の内容を直接アップロードします。
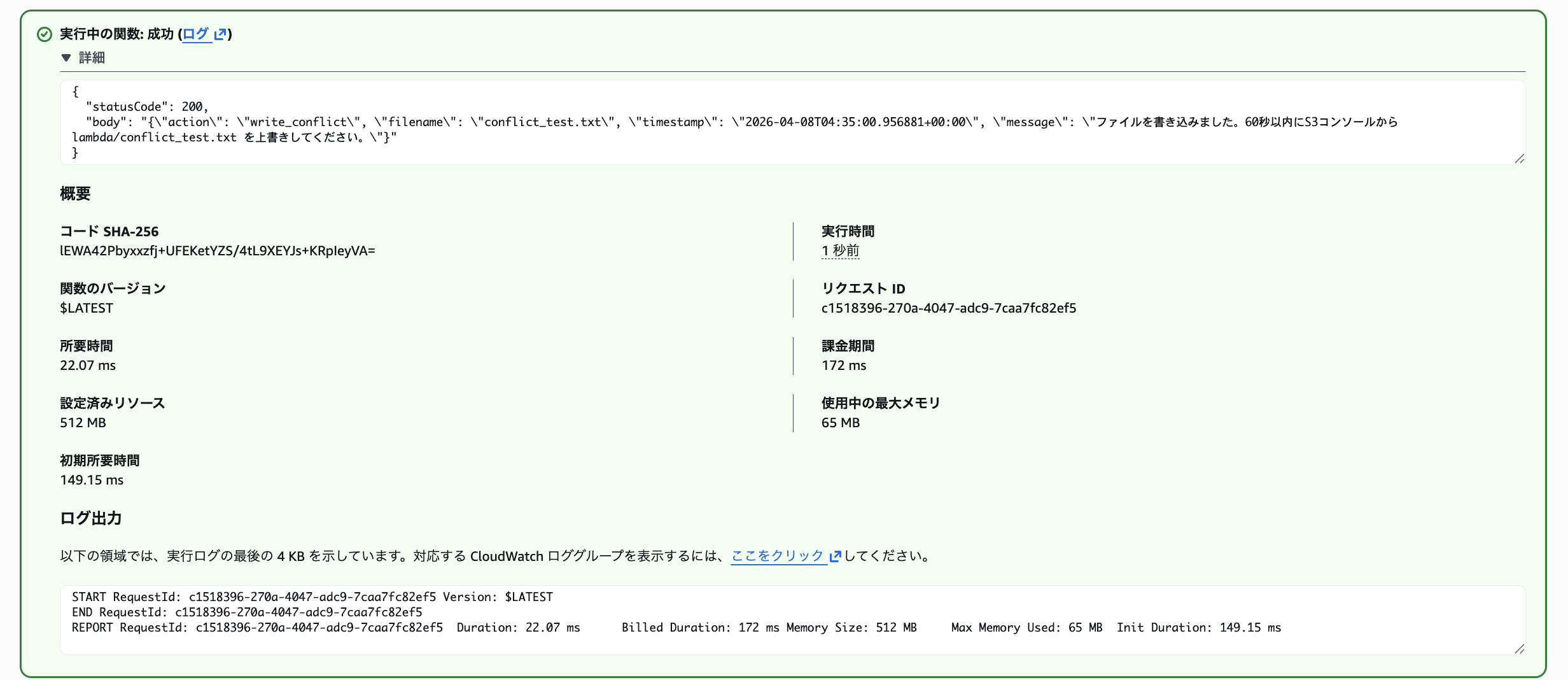
60秒後にreadで内容を確認すると、S3コンソールからアップロードした内容が適用されており、S3が正として機能していることを確認しました。
ファイル内容がLambdaで作成したものとは異なり、
Written from S3 Console (conflict test)\\nThis file was uploaded directly to S3 to trigger a conflict.\\nUploaded at: 2026-04-08\\n\で取得できています。
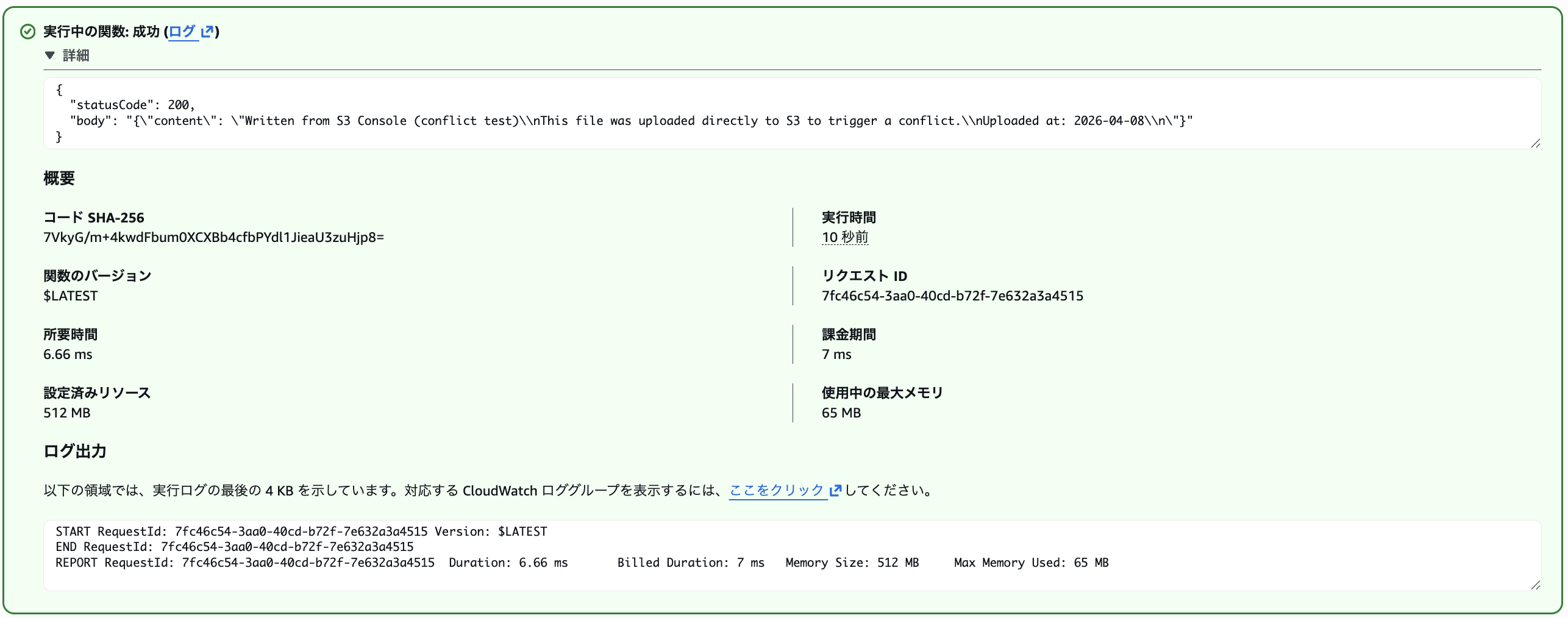
また、競合が発生するとCloudWatchのLostAndFoundFilesメトリクスが「1」に増加し、Lambda 側で作成したconflict_test.txtがlost+foundディレクトリに退避されたことも確認できました。
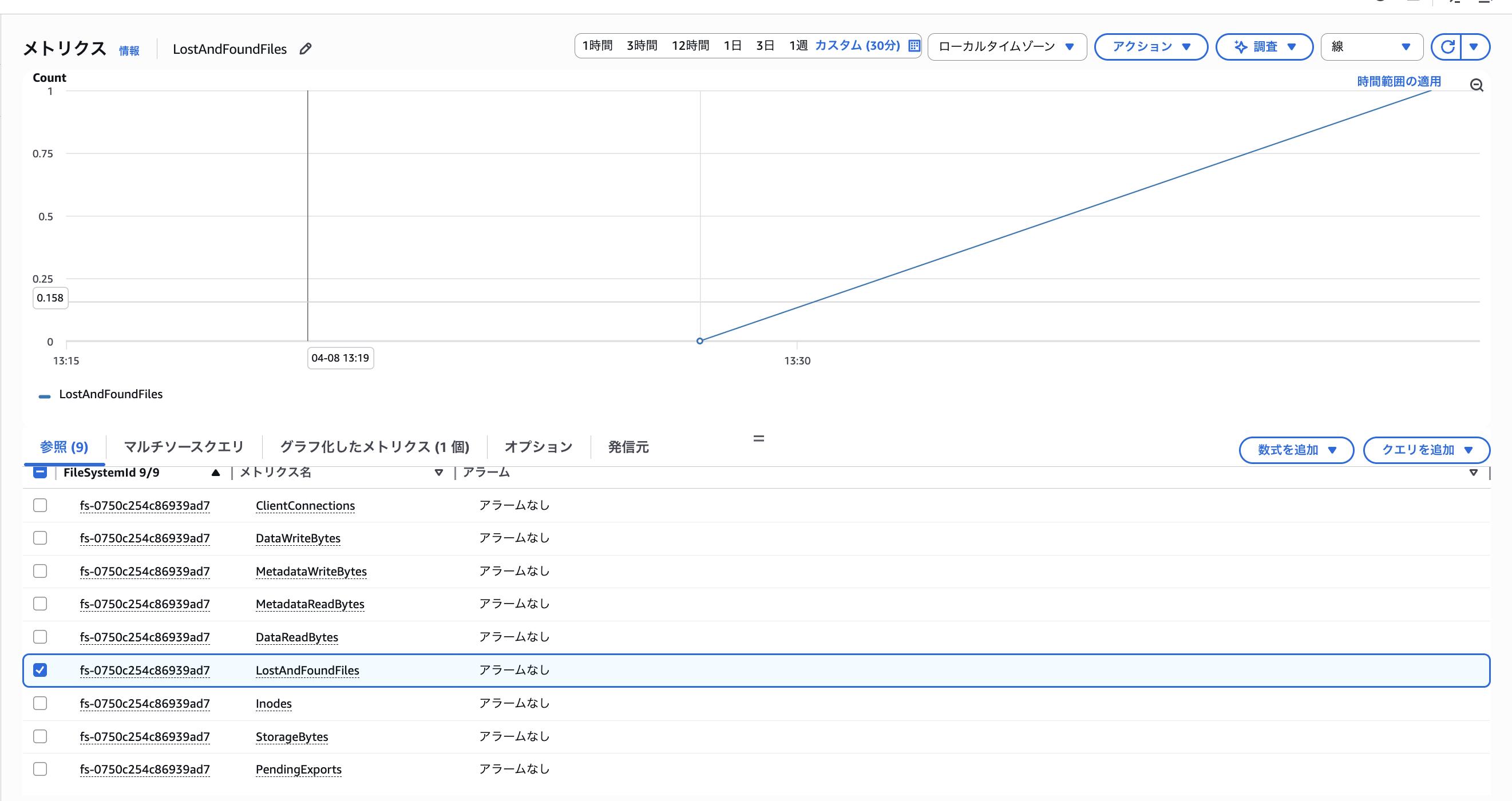
なおlost+foundディレクトリはファイルシステムルートに作成されますが、今回のアクセスポイントが /lambda にスコープされているためLambdaからは直接参照できません。LostAndFoundFiles メトリクスで確認するのが確実です。
⑤ 連続書き込み処理
同じファイルbatch_test.txtに対して内容を変えて1秒間隔で5回書き込み(合計約 5 秒)、60秒後にS3に書き込まれたバージョン数を確認しました。
検証詳細
# テストイベント
{"action": "write_rapid", "count": 5}
def write_rapid(count):
filepath = os.path.join(MOUNT_PATH, "batch_test.txt")
for i in range(count):
ts = datetime.datetime.now(datetime.timezone.utc).isoformat()
with open(filepath, "w") as f:
f.write(f"Write #{i + 1} of {count}\nTimestamp: {ts}\n")
if i < count - 1:
time.sleep(1)
5回の書き込みが完了しました。
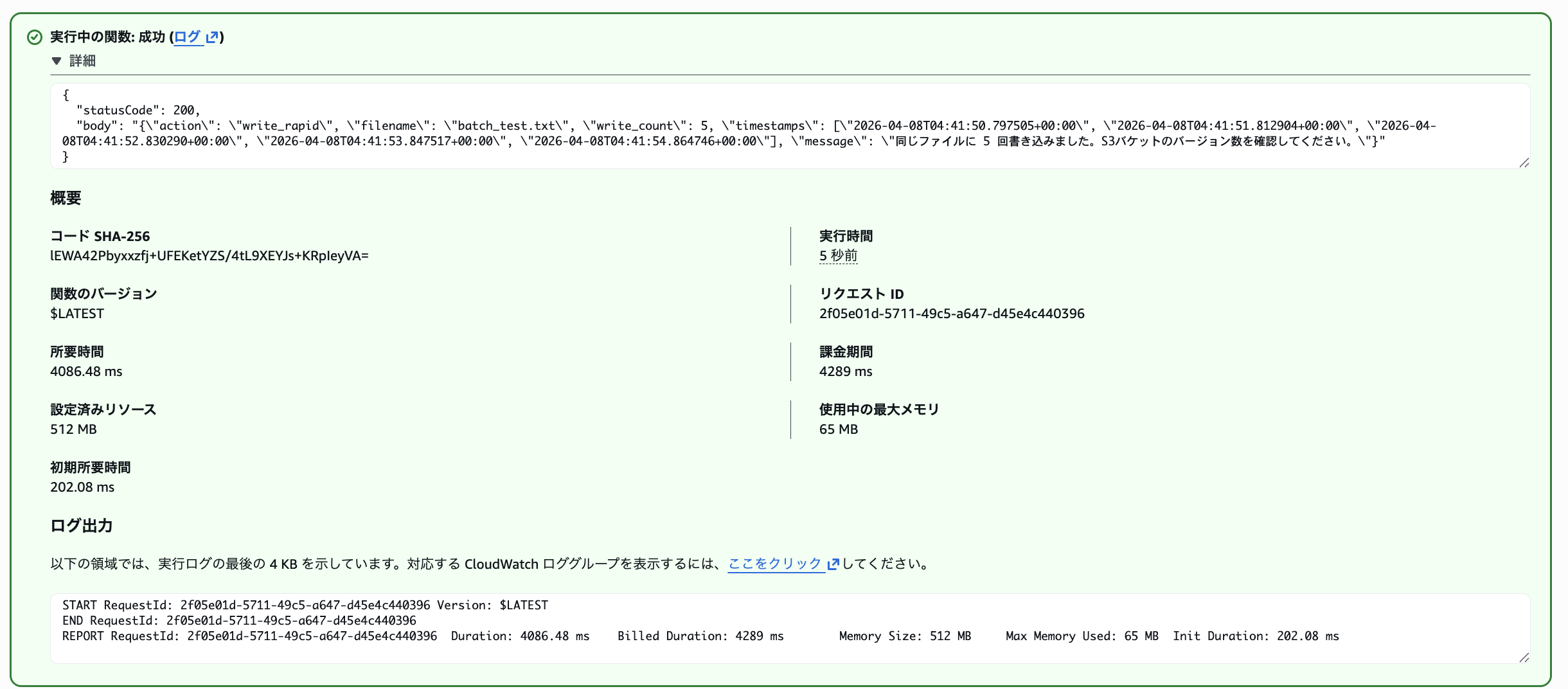
60秒後にS3バケットのバージョン履歴を確認すると、バージョンが 1 つしか作成されていません。
S3オブジェクトの内容は最後の書き込み内容のみ保持されていました。
Write #5 of 5
Timestamp: 2026-04-08T04:41:54.864746+00:00
このように60秒ウィンドウ内の変更は最後の1回の書き込みにまとめられることを確認しました。
最後に
今回はS3Filesの仕様を確認しつつ、Lambdaからマウントして動作を確認しました。
基本動作・競合・連続書き込み処理と、仕様として気になる挙動をひと通り検証してみましたが、細かな仕様が多いので実際のワークロードで安全に動かすためには、さらに検証が必要になってくると思います。
特に書き込みと読み込みで非対称な同期設計になっている点や、キャッシュオブジェクトサイズによってかかる料金が変わってくる点においては実際にアプリケーションに組み込む際に意識しておく必要があります。
今回は以上です。










