![[アップデート] Amazon Redshift でサポートされた Apache Iceberg テーブルへの UPDATE、DELETE、MERGE を試してみました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-63f1274931b942e9a92e601c1127ad73/cfe87ec6d62fa2fc3c474ed4cb2f6c2e/amazon-redshift?w=3840&fm=webp)
[アップデート] Amazon Redshift でサポートされた Apache Iceberg テーブルへの UPDATE、DELETE、MERGE を試してみました
クラウド事業本部の石川です。Amazon Redshift / Amazon Redshift Serverless から Apache Iceberg テーブルに対する行レベルの UPDATE、DELETE、MERGE 操作が利用可能になりましたので、実際に試してみました。
はじめに
Redshift から Apache Iceberg テーブルに対しては、すでに append-only(INSERT)での書き込みがサポートされていました。
2026年4月23日のアップデートで、行レベルの UPDATE、DELETE、MERGE 操作が利用可能になりました。パーティション化されたテーブル・されていないテーブルの両方に対応し、MERGE では UPSERT(MATCHED 時 UPDATE、NOT MATCHED 時 INSERT)を単一ステートメントで表現できます。更新されたテーブルは Iceberg 互換の Glue や Athena などの他エンジンからも読み書きできるため、レイクハウス上のデータに対する CDC(チェンジデータキャプチャ)やSCD (Slowly Changing Dimension) の管理をシンプルな SQL で実装できるようになります。
Apache Iceberg テーブルへの UPDATE / DELETE / MERGE とは
Apache Iceberg はデータレイク上のテーブルに ACID トランザクション、スキーマ進化、タイムトラベルなどデータウェアハウスに近い機能をもたらすオープンテーブルフォーマットです。これまで Redshift は Iceberg テーブルの読み取りと INSERT までしかサポートしていなかったため、Iceberg テーブル上の更新・削除は Athena や EMR に任せる必要がありました。
今回のアップデートで以下の DML が Redshift から直接実行できるようになります。
- UPDATE: 条件に合致する行を更新。
FROM句で他テーブルを参照可能 - DELETE: 条件に合致する行を削除。
USING句で他テーブルを参照可能 - MERGE: マージ条件に応じて UPDATE / DELETE / INSERT を組み合わせた UPSERT
Iceberg 書き込みクエリはアトミックな自動コミットトランザクションとして処理され、2 つのトランザクションが同じパーティションを同時変更するとコミットが失敗する楽観的ロック方式を採用しています。
やってみた
前提条件
- Redshift Serverless のパッチバージョンが p200 以上(今回の検証環境は 1.0.266483)
- 検証リージョン: 東京リージョン(ap-northeast-1)
検証用に以下を用意します。
- 標準 S3 バケット(Iceberg データファイルの保存先)
- Glue Data Catalog データベース
- Redshift Serverless(baseCapacity=4 RPU)
- Redshift から S3 / Glue / Lake Formation へアクセスするための IAM ロール
IAM ロールの作成
Redshift Serverless が S3 / Glue / Lake Formation を操作するための IAM ロールを作成します。信頼ポリシーには redshift.amazonaws.com と redshift-serverless.amazonaws.com を指定します。
Redshift Serverless が Glue / S3 / Lake Formation を操作するためのロールを作成します。
信頼ポリシーを決めてロールを新規作成
- マネジメントコンソールで IAM を開く
- 左メニュー ロール → 右上 ロールを作成
- 信頼されたエンティティタイプ: 「カスタム信頼ポリシー」を選択
- 下のエディタに次の JSON を貼り付ける
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"redshift.amazonaws.com",
"redshift-serverless.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
- 次へ を押して「許可を追加」は何も選ばずに 次へ
- ロール名:
RedshifticebergRole-handson - ロールを作成 をクリック
インラインポリシーを追加
作成したロールの詳細画面を開き、以下を実施します。
- 許可 タブ → 許可を追加 → インラインポリシーを作成
- JSON タブに切り替えて、次の JSON を貼り付ける
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3Access",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "*"
},
{
"Sid": "GlueCatalog",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetDatabases",
"glue:CreateDatabase",
"glue:DeleteDatabase",
"glue:UpdateDatabase",
"glue:GetTable",
"glue:GetTables",
"glue:CreateTable",
"glue:UpdateTable",
"glue:DeleteTable",
"glue:GetPartitions",
"glue:BatchGetPartition",
"glue:CreatePartition"
],
"Resource": "*"
},
{
"Sid": "LakeFormation",
"Effect": "Allow",
"Action": [
"lakeformation:GetDataAccess",
"lakeformation:GetResourceLFTags",
"lakeformation:ListLFTags",
"lakeformation:GetLFTag",
"lakeformation:SearchTablesByLFTags",
"lakeformation:SearchDatabasesByLFTags"
],
"Resource": "*"
}
]
}
- 次へ → ポリシー名:
RedshifticebergPolicy→ ポリシーを作成
S3 バケットと Glue データベースの作成
Iceberg データの保存先となる S3 バケットと、カタログを保持する Glue データベースを作成します。
aws s3api create-bucket \
--bucket iceberg-handson-<account-id>-ap-northeast-1 \
--create-bucket-configuration LocationConstraint=ap-northeast-1
aws glue create-database \
--database-input 'Name=iceberg_write_blog_handson,Description=Iceberg blog'
Lake Formation 権限付与
作成した Glue データベースとテーブル(ワイルドカード)に対し、Redshift ロールへ ALL 権限を付与します。S3 ロケーションも Lake Formation に登録し、DATA_LOCATION_ACCESS を付与します。
aws lakeformation grant-permissions \
--principal DataLakePrincipalIdentifier='arn:aws:iam::<account-id>:role/RedshifticebergRole-handson' \
--resource '{"Database":{"Name":"iceberg_write_blog_handson"}}' \
--permissions ALL --permissions-with-grant-option ALL
Redshift Serverless の作成
ネームスペースとワークグループを作成します。今回は最小の 4 RPU 構成にしています。
aws redshift-serverless create-namespace \
--namespace-name iceberg-ns-handson \
--db-name dev \
--iam-roles 'arn:aws:iam::<account-id>:role/RedshifticebergRole-handson' \
--default-iam-role-arn 'arn:aws:iam::<account-id>:role/RedshifticebergRole-handson'
aws redshift-serverless create-workgroup \
--workgroup-name iceberg-wg-handson \
--namespace-name iceberg-ns-handson \
--base-capacity 4 \
--subnet-ids <subnet-ids> \
--security-group-ids <sg-id> \
--publicly-accessible
ワークグループの status が AVAILABLE になるまで 2 分ほど待ちます。
Redshift Data API 経由で SELECT version(); を実行し、パッチバージョンを確認します。
| version |
| --- |
| PostgreSQL 8.0.2 on i686-pc-linux-gnu, compiled by GCC gcc (GCC) 3.4.2 20041017 (Red Hat 3.4.2-6.fc3), Redshift 1.0.266483 |
外部スキーマの作成
Redshift 側から Glue データベースを参照する外部スキーマを作成します。
CREATE EXTERNAL SCHEMA demo_iceberg
FROM DATA CATALOG DATABASE 'iceberg_write_blog_handson'
IAM_ROLE 'arn:aws:iam::<account-id>:role/RedshifticebergRole-handson';
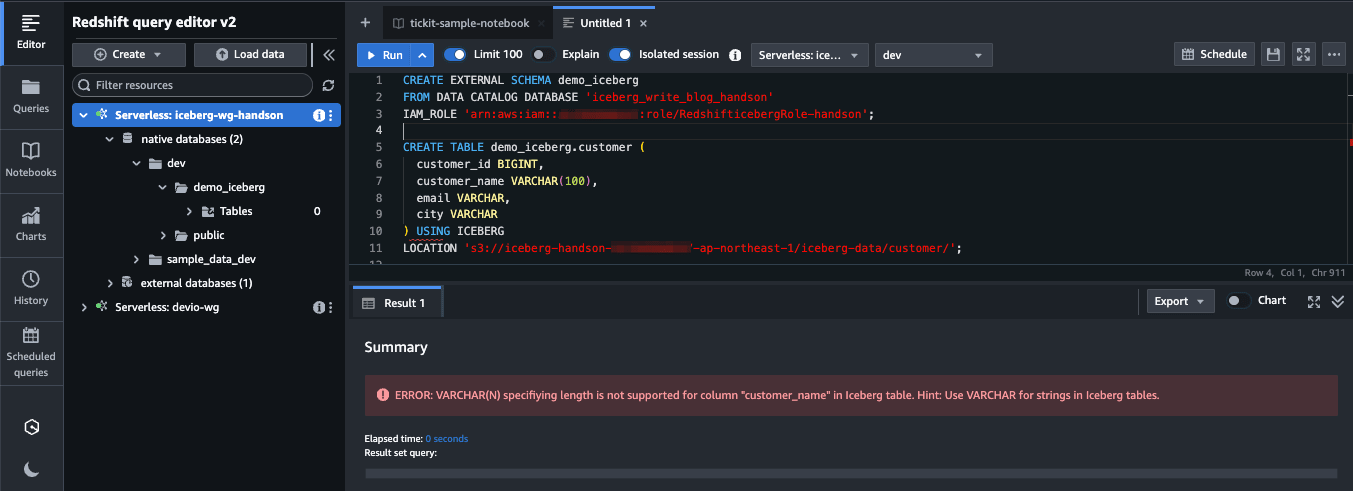
Iceberg テーブルの作成
customer という Iceberg テーブルを作成します。注意点として、Iceberg テーブルのカラム型には VARCHAR の長さ指定ができません。
CREATE TABLE demo_iceberg.customer (
customer_id BIGINT,
customer_name VARCHAR(100),
email VARCHAR,
city VARCHAR
) USING ICEBERG
LOCATION 's3://iceberg-handson-<account-id>-ap-northeast-1/iceberg-data/customer/';
ERROR: VARCHAR(N) specifiying length is not supported for column "customer_name" in Iceberg table.
Hint: Use VARCHAR for strings in Iceberg tables.
ヒントに従い、VARCHAR(100) を VARCHAR に変更して再実行します。
CREATE TABLE demo_iceberg.customer (
customer_id BIGINT,
customer_name VARCHAR,
email VARCHAR,
city VARCHAR
) USING ICEBERG
LOCATION 's3://iceberg-handson-<account-id>-ap-northeast-1/iceberg-data/customer/';
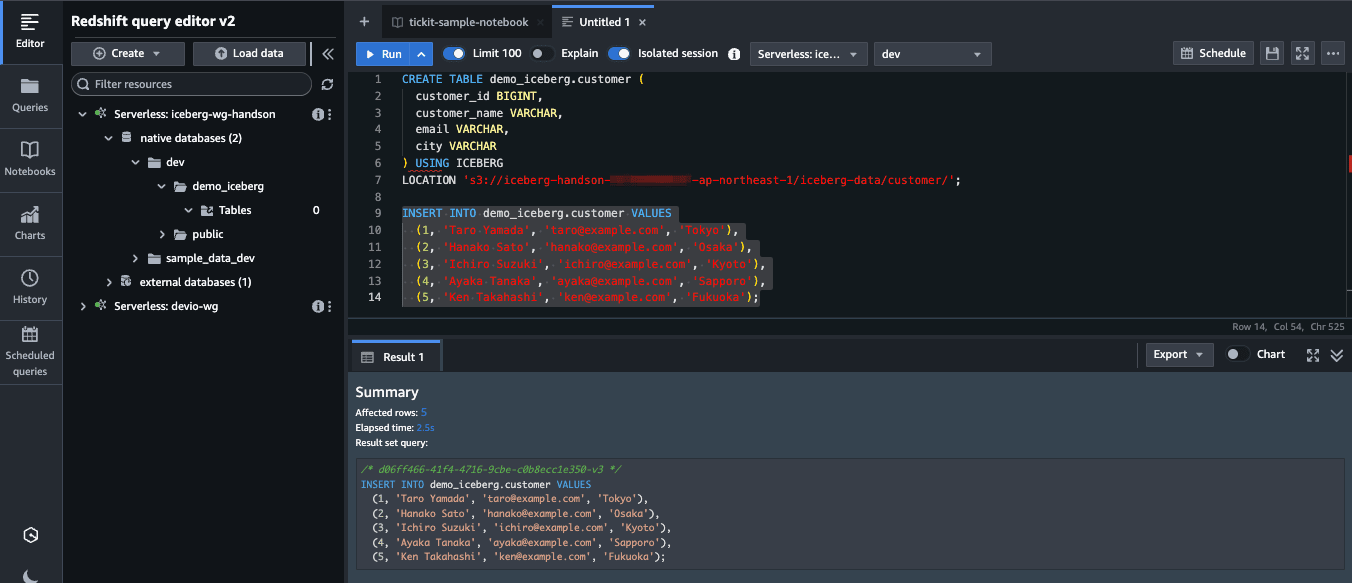
成功しました。初期データを 5 件 INSERT しておきます。
INSERT INTO demo_iceberg.customer VALUES
(1, 'Taro Yamada', 'taro@example.com', 'Tokyo'),
(2, 'Hanako Sato', 'hanako@example.com', 'Osaka'),
(3, 'Ichiro Suzuki', 'ichiro@example.com', 'Kyoto'),
(4, 'Ayaka Tanaka', 'ayaka@example.com', 'Sapporo'),
(5, 'Ken Takahashi', 'ken@example.com', 'Fukuoka');
UPDATE を試す
ここからが新機能の本番です。まずは WHERE 句で 1 行だけ更新してみます。
UPDATE demo_iceberg.customer
SET city = 'Yokohama'
WHERE customer_id = 1;
ResultRows: 1 として 1 行が更新されました。SELECT で確認します。
| customer_id | customer_name | city |
| --- | --- | --- |
| 1 | Taro Yamada | Yokohama |
次に、FROM 句で別テーブルを参照する UPDATE を試します。ソースとして public.customer_opt_out という Redshift ローカルテーブルを用意します。
CREATE TABLE public.customer_opt_out (
customer_id BIGINT,
customer_name VARCHAR(100),
cust_rec_upd_ind CHAR(1),
opt_out_ind CHAR(1)
);
INSERT INTO public.customer_opt_out VALUES
(2, 'Hanako Sato (Updated)', 'Y', 'N'),
(3, 'Ichiro Suzuki (Updated)', 'Y', 'N'),
(4, 'Ayaka Tanaka', 'N', 'Y'),
(5, 'Ken Takahashi', 'N', 'Y');
なお
public.customer_opt_outは通常の Redshift テーブルなので、VARCHAR(N) の長さ指定が可能です。長さ指定が制限されるのは Iceberg テーブルのみです。
このテーブルをソースに、FROM 句付きの UPDATE を実行します。
UPDATE demo_iceberg.customer
SET customer_name = customer_opt_out.customer_name
FROM public.customer_opt_out
WHERE customer_opt_out.cust_rec_upd_ind = 'Y'
AND customer.customer_id = customer_opt_out.customer_id;
ResultRows: 2 として 2 行が更新されました。Iceberg テーブル側のカラム値を、Redshift ローカルテーブル側の値で置き換えるジョイン UPDATE が問題なく動作します。
| customer_id | customer_name | email | city |
| --- | --- | --- | --- |
| 1 | Taro Yamada | taro@example.com | Yokohama |
| 2 | Hanako Sato (Updated) | hanako@example.com | Osaka |
| 3 | Ichiro Suzuki (Updated) | ichiro@example.com | Kyoto |
| 4 | Ayaka Tanaka | ayaka@example.com | Sapporo |
| 5 | Ken Takahashi | ken@example.com | Fukuoka |
DELETE を試す
USING 句で別テーブルを参照した条件付き DELETE です。opt_out_ind = 'Y' の顧客 2 件を削除します。
DELETE FROM demo_iceberg.customer
USING public.customer_opt_out
WHERE customer.customer_id = customer_opt_out.customer_id
AND customer_opt_out.opt_out_ind = 'Y';
ResultRows: 2 として 2 行が削除され、テーブルは 3 件になりました。
| customer_id | customer_name | email | city |
| --- | --- | --- | --- |
| 1 | Taro Yamada | taro@example.com | Yokohama |
| 2 | Hanako Sato (Updated) | hanako@example.com | Osaka |
| 3 | Ichiro Suzuki (Updated) | ichiro@example.com | Kyoto |
MERGE で UPSERT を試す
新たに orders と orders_stg という 2 つの Iceberg テーブルを作成し、MERGE で UPSERT を試します。
CREATE TABLE demo_iceberg.orders (
order_id BIGINT,
customer_id BIGINT,
order_date DATE,
total_amount DECIMAL(10,2)
) USING ICEBERG
LOCATION 's3://iceberg-handson-<account-id>-ap-northeast-1/iceberg-data/orders/';
CREATE TABLE demo_iceberg.orders_stg (
order_id BIGINT,
customer_id BIGINT,
order_date DATE,
total_amount DECIMAL(10,2)
) USING ICEBERG
LOCATION 's3://iceberg-handson-<account-id>-ap-northeast-1/iceberg-data/orders_stg/';
INSERT INTO demo_iceberg.orders VALUES
(1001, 1, DATE '2026-04-20', 5000.00),
(1002, 2, DATE '2026-04-21', 3500.00),
(1003, 3, DATE '2026-04-22', 7800.00);
INSERT INTO demo_iceberg.orders_stg VALUES
(1002, 2, DATE '2026-04-21', 9999.99),
(1003, 3, DATE '2026-04-22', 8888.88),
(1004, 1, DATE '2026-04-23', 2200.00),
(1005, 2, DATE '2026-04-24', 1500.00);
本番テーブル orders には 3 件(1001, 1002, 1003)、ステージングテーブル orders_stg には 4 件(1002, 1003 は更新用、1004, 1005 は新規)を入れた状態で MERGE を実行します。
MERGE INTO demo_iceberg.orders
USING demo_iceberg.orders_stg
ON orders.order_id = orders_stg.order_id
WHEN MATCHED THEN UPDATE SET
customer_id = orders_stg.customer_id,
order_date = orders_stg.order_date,
total_amount = orders_stg.total_amount
WHEN NOT MATCHED THEN INSERT VALUES (
orders_stg.order_id,
orders_stg.customer_id,
orders_stg.order_date,
orders_stg.total_amount
);
実行後の orders テーブルは、1001 はそのまま、1002 / 1003 は新しい値に更新され、1004 / 1005 が新規挿入された 5 件になりました。
| order_id | customer_id | order_date | total_amount |
| --- | --- | --- | --- |
| 1001 | 1 | 2026-04-20 | 5000.00 |
| 1002 | 2 | 2026-04-21 | 9999.99 |
| 1003 | 3 | 2026-04-22 | 8888.88 |
| 1004 | 1 | 2026-04-23 | 2200.00 |
| 1005 | 2 | 2026-04-24 | 1500.00 |
MERGE の制約を確認する
MERGE の挙動をもう少し細かく確認します。MATCHED 時に条件に応じて UPDATE または DELETE を分岐させたいケースがあります。
MERGE INTO demo_iceberg.orders
USING demo_iceberg.orders_stg
ON orders.order_id = orders_stg.order_id
WHEN MATCHED AND orders_stg.total_amount IS NULL THEN DELETE
WHEN MATCHED THEN UPDATE SET total_amount = orders_stg.total_amount
WHEN NOT MATCHED THEN INSERT VALUES (
orders_stg.order_id,
orders_stg.customer_id,
orders_stg.order_date,
orders_stg.total_amount
);
5行目はエラーになります。
ERROR: Multiple WHEN MATCHED clauses are not supported in MERGE statement.
WHEN MATCHED は 1 つの節しか持てません。UPDATE か DELETE のどちらか片方に絞る必要があります。
それなら WHEN MATCHED だけで DELETE する最小の MERGE はどうかと試します。削除対象の order_id を保持する Redshift ローカルテーブル public.orders_to_delete を用意します。
CREATE TABLE public.orders_to_delete (order_id BIGINT);
INSERT INTO public.orders_to_delete VALUES (1001), (1004);
このテーブルをソースに WHEN MATCHED THEN DELETE のみの MERGE を実行すると、こちらもエラーになります。
MERGE INTO demo_iceberg.orders
USING public.orders_to_delete
ON orders.order_id = orders_to_delete.order_id
WHEN MATCHED THEN DELETE;
ERROR: MERGE statement with a single WHEN clause is not enabled.
MERGE は WHEN MATCHED と WHEN NOT MATCHED をセットで書くことが必須のようです。単純な条件付き削除は MERGE ではなく DELETE ... USING で書く方が素直です。
DELETE FROM demo_iceberg.orders
USING public.orders_to_delete
WHERE orders.order_id = orders_to_delete.order_id;
これは問題なく 2 行を削除できました。
パーティション付きテーブルでの動作
bucket(4, region) と year(sale_date) のマルチレベルパーティションを持つテーブルで UPDATE を試します。
CREATE TABLE demo_iceberg.sales_history (
sale_id BIGINT,
region VARCHAR,
sale_date DATE,
amount DECIMAL(10,2)
) USING ICEBERG
LOCATION 's3://iceberg-handson-<account-id>-ap-northeast-1/iceberg-data/sales_history/'
PARTITIONED BY (bucket(4, region), year(sale_date));
初期データを 5 件 INSERT しておきます。region で 4 バケット、sale_date で年単位のパーティションが作られます。
INSERT INTO demo_iceberg.sales_history VALUES
(1, 'APAC', DATE '2024-06-15', 1000.00),
(2, 'APAC', DATE '2025-03-10', 1500.00),
(3, 'EMEA', DATE '2024-09-22', 2000.00),
(4, 'AMER', DATE '2026-01-05', 2500.00),
(5, 'AMER', DATE '2026-04-23', 3000.00);
sale_date はパーティションキーですが、そのまま UPDATE できます。2024 年のレコードを 2026 年に書き換えてみます。
UPDATE demo_iceberg.sales_history
SET sale_date = DATE '2026-04-30'
WHERE sale_id = 3;
成功し、S3 上のパーティションディレクトリも region=3/sale_date=2024/ から region=3/sale_date=2026/ へと移動したパーティションに新しいファイルが配置されました。
:
iceberg-data/sales_history/data/region=3/sale_date=2024/f953d7/20260428_19864_aa3ee668-17e6-441d-b757-66badca12d0d_65.parquet
iceberg-data/sales_history/data/region=3/sale_date=2026/1e4df4/20260428_19843_4b7ad79f-96c8-44da-a5d9-b8d9db9e3fb7_84.parquet
:
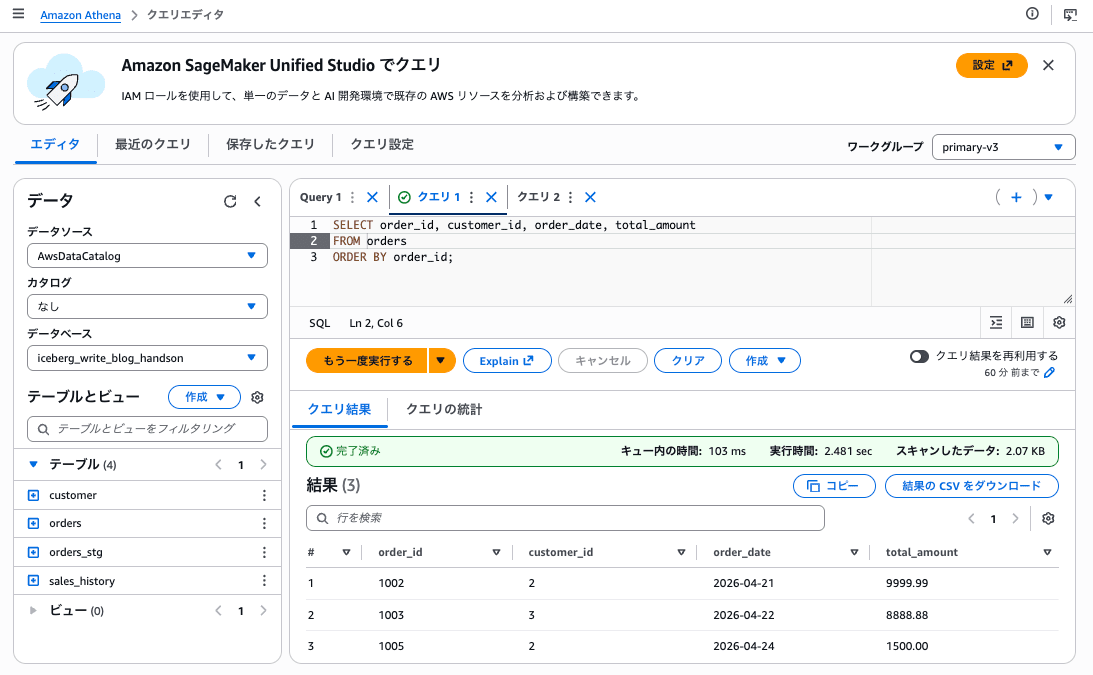
Athena から同じテーブルを読む
Redshift が書き込んだ orders テーブルを Athena からクエリし、結果が一致することを確認します。
SELECT order_id, customer_id, order_date, total_amount
FROM iceberg_write_blog.orders
ORDER BY order_id;
Redshift 側で実行した結果と同じ 3 件(UPDATE / DELETE 後の状態)が Athena でも取得でき、Redshift の書き込みが Iceberg 仕様に準拠して行われ、他エンジンとの相互運用性が保たれていることが確認できました。
S3 に生成されたファイル構造
Iceberg テーブルの S3 プレフィックスには data/ と metadata/ が作られ、書き込みのたびに以下のファイルが追加されるのが確認できました。
- Parquet データファイル
- Avro マニフェスト
- Avro スナップショットファイル
- JSON メタデータファイル
iceberg-data/orders/data/xxxx/*.parquet # 実データ(Parquet)
iceberg-data/orders/metadata/00000-....metadata.json # テーブルメタデータ
iceberg-data/orders/metadata/snap-....avro # スナップショット
iceberg-data/orders/metadata/*.manifest.avro # マニフェスト
UPDATE や MERGE を行うたびにデータファイルやメタデータが増えていくため、AWS Glue Data Catalog のテーブルオプティマイザや、Iceberg 互換エンジンによる定期的なコンパクションを推奨する旨が公式ドキュメントでも言及されています。
ALTER TABLE は未サポート
ドキュメントに記載のとおり、Iceberg テーブルに対して ALTER TABLE は使えません。
ALTER TABLE demo_iceberg.customer ADD COLUMN phone VARCHAR;
ERROR: ALTER TABLE ADD COLUMN is not supported for "iceberg" table "customer"
スキーマ変更が必要な場合は、現時点では Athena や Spark 側で行う必要があります。
補足: DROPはPURGE 相当の挙動を持たず、カタログ deregister のみ
Amazon Redshift の DROP はカタログ登録のみを削除し、S3 上のファイルはそのまま残ります。そのため、同じ名前のテーブルを再作成しようとすると、下記のエラーが出てテーブルが作成できません。
ERROR: Cannot create Iceberg table: S3 location "s3://iceberg-handson-<account-id>-ap-northeast-1/iceberg-data/sales" contains existing objects
実は OSS Iceberg でも、DROP TABLE はベストエフォート扱いで、PURGE オプションをつけて初めてデータファイル削除が試みられます。S3 のテーブルロケーションが他テーブルと共有されていたり、ユーザーがカスタムパスを指定している場合、特定のクエリエンジンがファイルを勝手に消すと他システムを破壊する恐れがあります。
同じ Iceberg テーブルを EMR / Athena / Spark などからも読み書きする前提なので、書き手の一つに過ぎない Redshift がストレージのライフサイクルまで握るべきではない、という分担の考え方なのではないでしょうか。
なお、Amazon Athena の DROP は、カタログ登録と S3 のデータロケーションをともに削除するため、DROP 後のテーブル作成も可能です。AWS のクエリエンジンによって挙動が異なる点には注意が必要です。
考察
新機能を実際に触って気づいた点を整理します。
- Redshift 単独で Iceberg テーブルに対する CDC パイプラインや SCD Type 1 / Type 2 の更新ロジックが組めるようになり、Athena や EMR を橋渡しに使う必要がなくなった
- 今回の検証環境(Redshift 1.0.266483、4 RPU)で UPDATE / DELETE / MERGE / パーティション列 UPDATE すべてが期待どおりに動作した
- Iceberg テーブルでの VARCHAR は長さ指定不可、Redshift ローカルテーブルの VARCHAR(N) とは仕様が異なる
- MERGE 文は
WHEN MATCHED/WHEN NOT MATCHEDをセットで書くことが必須で、単一節や複数 MATCHED 節は使えない - MERGE で更新条件と削除条件を同時に表現したい場合は、ロジックを DELETE / UPDATE の 2 文に分解して実行する
- ALTER TABLE がサポートされないため、スキーマ変更は Athena / EMR / Spark 側で実施する必要がある
- Iceberg 書き込みクエリはストアドプロシージャから実行できないため、複雑な ETL フローを組む際は別の制御機構(Step Functions や dbt など)が必要
今後の期待としては、ALTER TABLE の対応、複数 WHEN MATCHED 節対応、ストアドプロシージャ内実行のサポートが進むと、既存の Redshift ベースの ELT パイプラインをそのまま Iceberg 化しやすくなると思います。
まとめ
Amazon Redshift から Iceberg テーブルに対する UPDATE / DELETE / MERGE を実際に試してみました。これまで append-only だった Iceberg 書き込みが行レベルで更新可能になり、Redshift を使った CDC や SCD 処理をシンプルな SQL で実装できるようになった点は、レイクハウス運用において大きなアップデートです。
パーティション変換や他エンジンとの相互運用性もそのまま維持されるため、Athena / EMR で構築済みの Iceberg 基盤に Redshift を加えても既存ワークフローを壊さずに統合できます。一方で VARCHAR の長さ指定不可、ALTER TABLE 未サポート、MERGE の節制約など、Redshift ローカルテーブルとは異なる制限があるため、実運用前に使用したい SQL パターンを一通り検証しておくと安心です。この記事がどなたかのお役に立てば幸いです。
参考リンク









