![[アップデート] Amazon Quick のデータソースの S3 Table Bucket サポートを試してみました](https://images.ctfassets.net/ct0aopd36mqt/2x7muHjvW69fxuVNSKWZHp/b37e05a972fc8125e9214abd764928fa/amazon-quick.png?w=3840&fm=webp)
[アップデート] Amazon Quick のデータソースの S3 Table Bucket サポートを試してみました
クラウド事業本部の石川です。Amazon Quick が Amazon S3 Tables Bucket をデータソースとしてネイティブにサポートしましたので、データソースとデータセットを作成し、Direct Query を試してみました。
Amazon S3 Tables Bucket のネイティブにサポートとは
今回のアップデートにより、Amazon Quick (旧 QuickSight)から S3 Tables Bucket 内の Apache Iceberg テーブルを「Amazon S3 Tables」というネイティブなデータソースタイプとして接続できるようになりました。
主な内容は以下のとおりです。
- データソースタイプ
S3_TABLESが追加され、S3 Table Bucket 内の Apache Iceberg テーブルにアクセス可能 - Iceberg テーブルに対して Direct Query または SPICE のいずれかを選択可能
- 中間のデータウェアハウスや OLAP レイヤーを介さず、データレイクを SSOT(Single Source of Truth )として扱える
- データセットあたり最大 20 億行(2 billion rows)まで対応
- Dataset Q&A による自然言語問い合わせや、Agentic AI を組み合わせたインサイト生成も対象
- Salesforce、SAP、Amazon Kinesis Data Firehose からの Zero-ETL によって S3 Tables に投入されたデータをニアリアルタイムで可視化可能
Amazon S3 Tables とは
Amazon S3 Tables は、Apache Iceberg テーブル形式でテーブル化されたデータを格納する S3 の Table Bucket です。スキーマ進化、トランザクション、タイムトラベルといった Iceberg のメリットをフルマネージドで利用できます。
従来手順(Athena + Resource Link 経由)との違い
これまで QuickSight から S3 Tables の Iceberg テーブルを参照するには、Lake Formation で Resource Link を作り、Athena データソース経由でクエリするのが主な方法でした。
| 観点 | 旧: Athena + Resource Link 経由 | 新: Amazon S3 Tables 直接接続 |
|---|---|---|
| データソースタイプ | ATHENA |
S3_TABLES |
| 中間カタログ | Lake Formation Resource Link を作成 | 不要(Table Bucket ARN を直接指定) |
| 必要権限 | Lake Formation 権限・Glue Catalog 権限・QuickSight サービスロール調整 | 管理アカウントで AWS Resources からアクセス許可を一度設定 |
| クエリ実行 | Athena 経由 | Quick のネイティブコネクタ経由 |
| Direct Query | Direct Query / SPICE 選択可能 | Quick から 直接 Direct Query / SPICE 選択可能 |
| データセット最大行数 | Athena 側の制約に従う | 20 億行まで |
| 特長 | Athanaの高度で柔軟なSQLやクエリエンジンが利用できる | 構成はシンプルでクエリエンジンの利用費がかからない |
旧手順はこちらのブログが詳しいですが、今回のアップデートにより設定ステップ数も必要権限も簡素化されます。
やってみた
前提条件
- AWS アカウント(QuickSight Enterprise edition )
- 検証リージョン: ap-northeast-1
- AWS CLI v2.34.42
検証データ
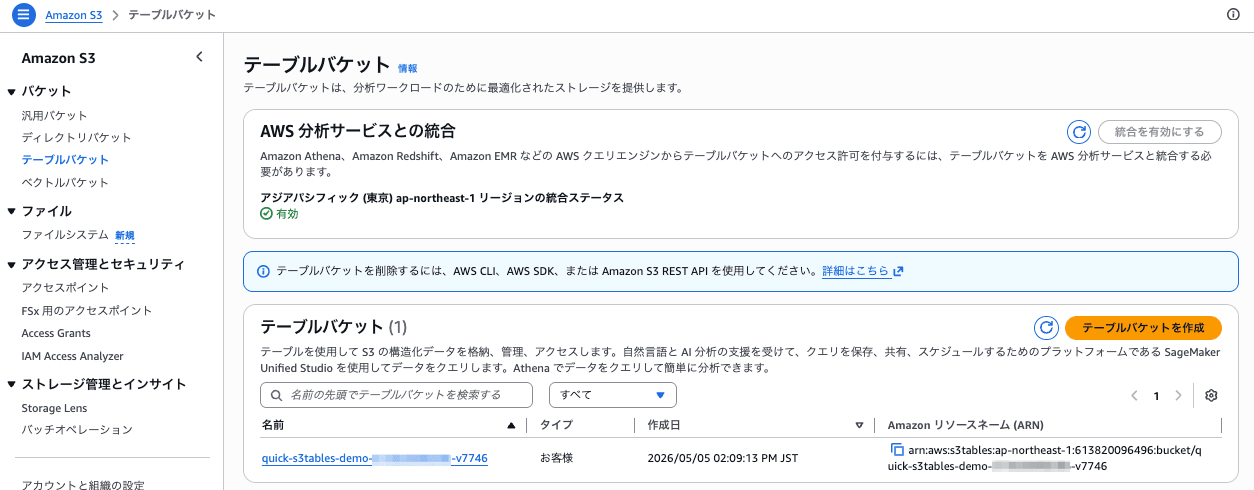
-
名前空間:
retail(1 つのみ) -
テーブル: 4 つすべて Iceberg フォーマット
S3 Table Bucket と
retailネームスペース、4 つの Iceberg テーブル(customers/products/sales/sales_summary)を作成し、Athena でサンプルデータを投入しました。今回 Amazon Quick から接続するのは、3 テーブルを JOIN 済みの非正規化マートsales_summaryです。arn:aws:s3tables:ap-northeast-1:<account-id>:bucket/quick-s3tables-demo-<account-id>-<suffix> └── retail/ ├── customers ├── products ├── sales └── sales_summary ← 今回 Quick から接続
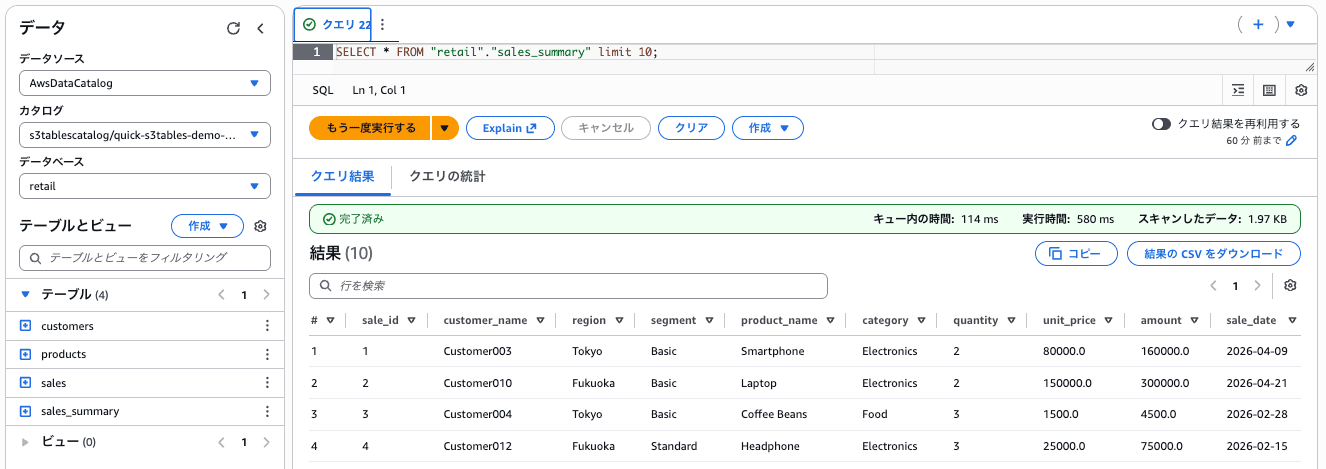
すでにAmazon Athenaからもクエリできる状態です。今回の検証では、下記のsales_summaryテーブルを用いて検証します。
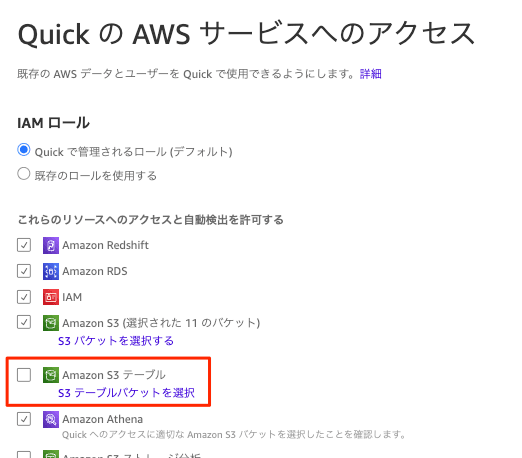
Step 1: Amazon Quick で S3 Tables アクセスを有効化
Amazon Quick アカウントとして S3 Tables へのアクセスを「許可済みリソース」として登録が必要です。[アカウントを管理]からアクセス許可の[AWSリソース]を選択、Quick の AWS サービスへのアクセス画面で、Amazon S3 テーブルのアクセスを有効化します。
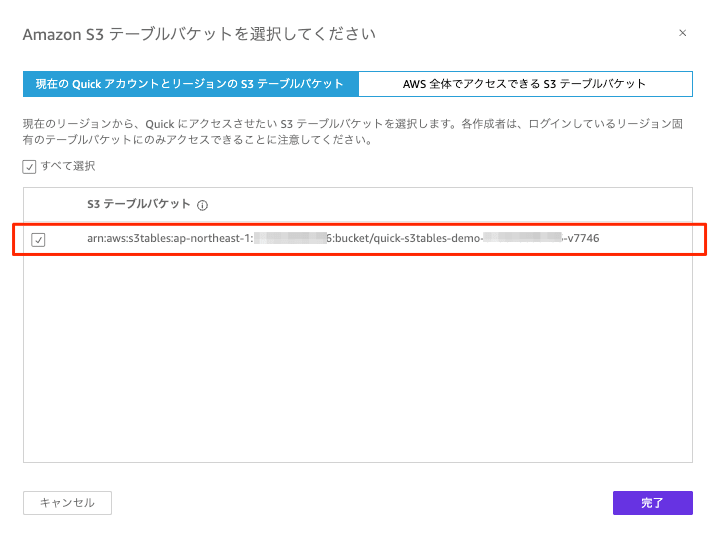
「Amazon S3 Table Bucket を選択してください」というダイアログで、 アクセスを有効化する S3 Table Bucket を選択します。
管理画面で「Amazon S3 Tables」を有効化すると aws-quicksight-s3-tables-role-v0 という専用の新しい IAM ロールが自動作成されます。
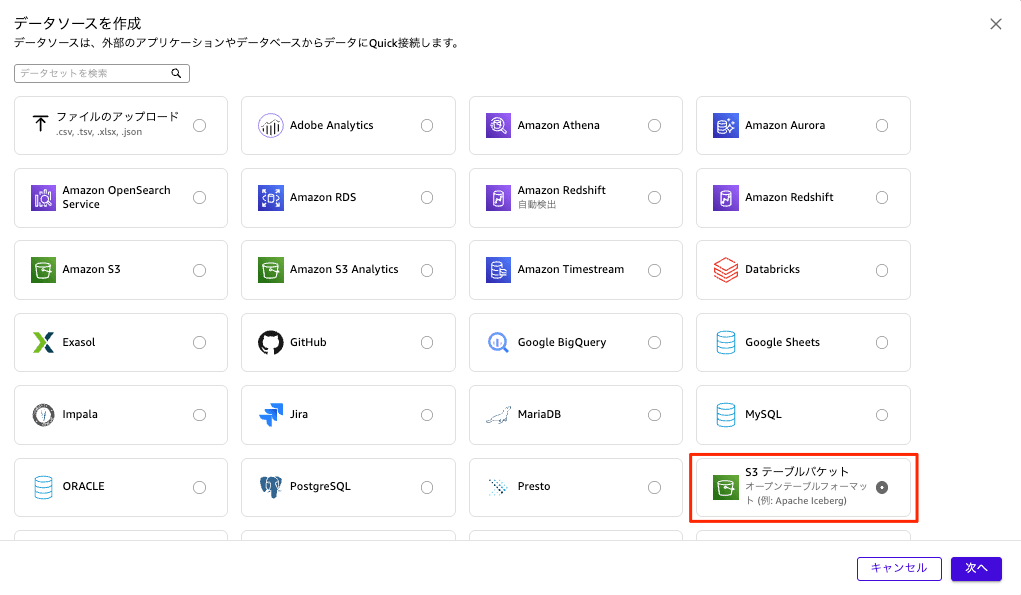
Step 2: Quick Sight データソースとデータセットを作成
[データソースを作成]ダイアログに、新たに追加された「S3 Table Bucket」を選択します。
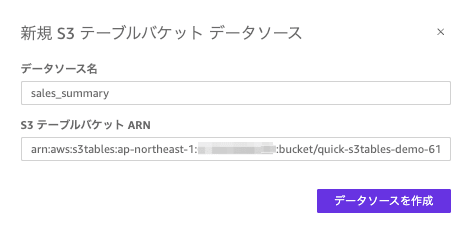
データソースとなるS3 Table Bucket のARN(S3 Tableの画面で確認)を指定します。
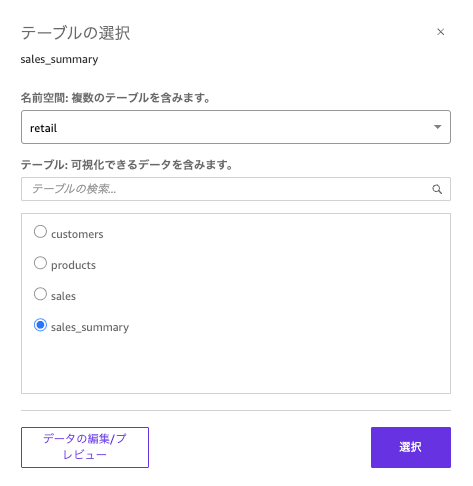
名前空間を選択します。このS3 Table Bucket の中には「retail」のみなので、そのまま選択しています。
これ以降は、他のデータセット作成と変わりません。S3 Table Bucket のテーブルデータが参照できます。
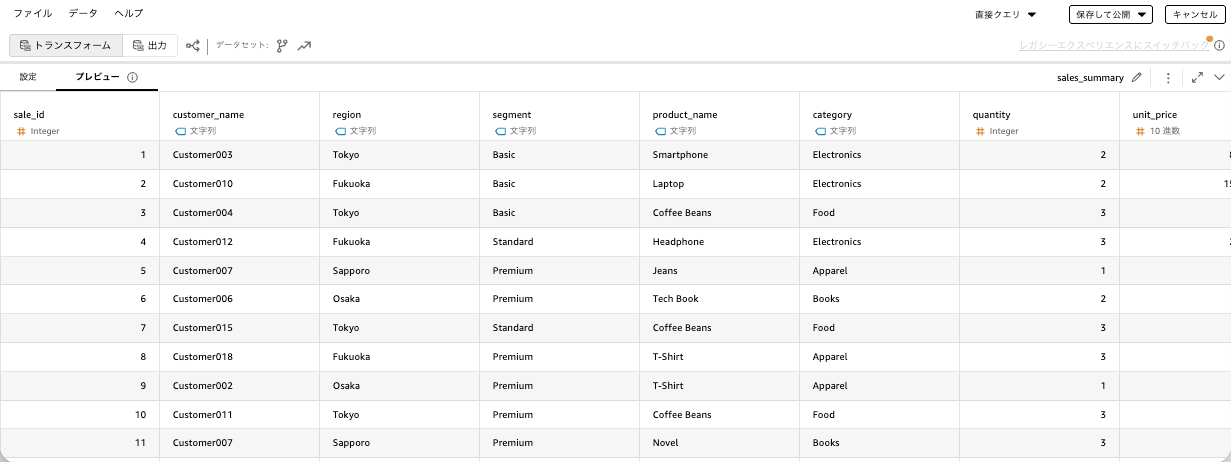
Step 3: Quick Sight の分析(Analysis)の作成
このデータを用いて分析(Analysis)の作成しました。
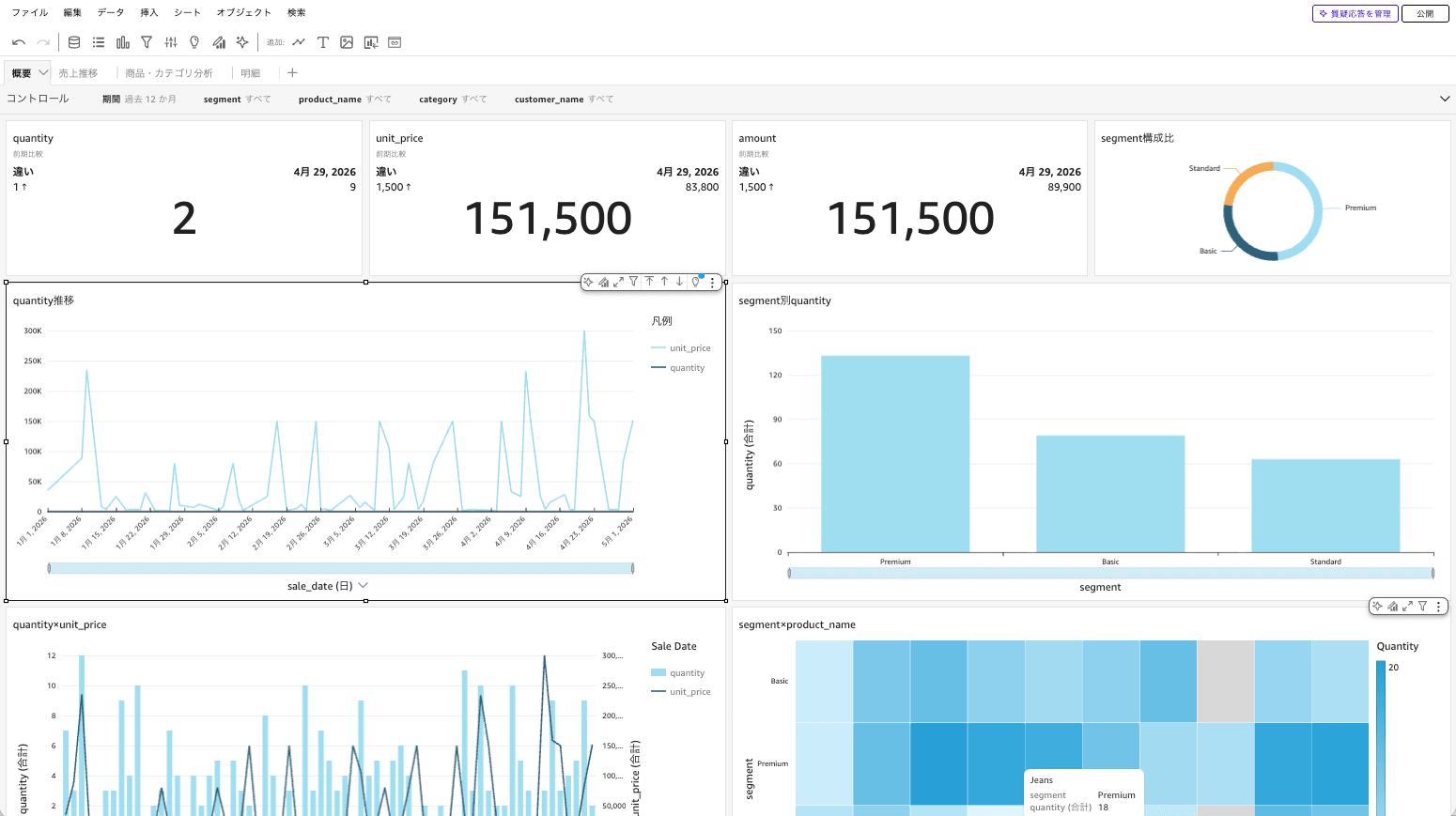
考察
CloudFormation で S3 Tables データソースを使う際にハマりやすい点を整理します。
-
アカウントレベルでの S3 Tables アクセス有効化が必須
- 従来の
aws-quicksight-service-role-v0への IAM ポリシー追加ではなく、管理画面で「Amazon S3 Tables」を有効化するとaws-quicksight-s3-tables-role-v0という専用の新しい IAM ロールが自動作成されます。Amazon Quick の管理画面で「Amazon S3 Tables」を許可済みリソースとして登録しないと CreateDataSource がAccessDeniedで失敗します。
- 従来の
-
DataSet は「新しい Data Preparation Experience」で作成
- S3 Tables データソースを参照する DataSet は、従来のレガシーエクスペアレンスでは作成でき内容です。
-
Analysis 画面でのマルチデータセット Join では Direct Query が使えない: 単独 DataSet を Analysis で開く場合は Direct Query で動作しましたが、Analysis 画面で複数 DataSet を Join しようとすると Direct Query の選択 UI がグレーアウトされ、SPICE 取り込みが事実上必須となりそうです。データレイクをそのまま Single Source of Truth として扱うアーキテクチャを目指す場合、Join が必要な分析については S3 Tables 側で事前に Iceberg ビュー、または Athena の
CREATE TABLE ... AS SELECTで結合済みテーブルを用意するなどの工夫が必要そうです
新機能の本質は、QuickSight が中間の Athena データソースを介さずに S3 Tables を直接「データソースタイプ」として扱える点にあります。Glue Data Catalog の s3tablescatalog を経由せずとも DataSource を作れるため、データレイク中心のアーキテクチャをよりシンプルに構築できる印象です。ただし、複数テーブルを跨ぐ分析を Direct Query で完結させるには現時点で制約があるため、要件に応じて単独テーブル設計や事前マテリアライズの選択肢を組み合わせる必要があります。
最後に
Amazon Quick が S3 Table Bucket をデータソースとしてネイティブにサポートしたことで、Apache Iceberg テーブル上のデータをデータウェアハウスや OLAP レイヤーを介さず BI / 生成 AI ワークロードへ直接接続できるようになりました。
Type=S3_TABLES と、新しい Data Preparation Experience に対応したデータセットが必須で、現時点でのワークフロー上の制約も把握しておく必要があります。データレイクを中心にした BI/生成 AI 基盤を構築したい方にとっては、データパイプラインの簡素化に直結する有用なアップデートです。
誤解してほしくないのが、Athena + Resource Link 経由は、Athanaの高度で柔軟なSQLやクエリエンジンが利用できるので、ユースケースに応じて使い分けていただきたいです。
合わせて読みたい










