
Amazon RedshiftのRGインスタンスにCloud DataWarehouse BenchmarkでTPC-H 10GBをロードしてみた
クラウド事業本部の石川です。Amazon Redshift のパフォーマンス検証を行いたい時に手軽に使える AWS Labs 公式のベンチマークセット「CloudDataWarehouseBenchmark」を、新インスタンスタイプ RG(rg.xlarge × 2 ノード)へのTPC-Hデータの導入を試してみました。
Amazon Redshift で新しいインスタンスタイプを試したり、ワークロードのチューニングを検証したりする際、毎回独自データセットを用意するのは大変です。
AWS Labs が GitHub で公開している amazon-redshift-utils には、TPC-DS / TPC-H から派生した DDL・COPY・クエリの一式が CloudDataWarehouseBenchmark ディレクトリに格納されており、s3://redshift-downloads/ 上のサンプルデータを使ってすぐにロード検証が始められます。
今回は、2026年5月にリリースされた AWS Graviton ベースの新しい Redshift インスタンス「RG」を rg.xlarge × 2 ノード で作成し、TPC-H 10GB のデータをロードして件数とロード時間を確認するところまでをやってみました。
参考: Amazon Redshift introduces AWS Graviton-based RG instances with an integrated data lake query engine
Cloud DataWarehouse Benchmark とは
amazon-redshift-utils リポジトリ配下の src/CloudDataWarehouseBenchmark には、以下の 2 つのサブディレクトリがあります。
Cloud-DWB-Derived-from-TPCDS— TPC-DS 2.13 派生のベンチマーク資材(小売向けの意思決定支援系クエリ 99 本)Cloud-DWB-Derived-from-TPCH— TPC-H 派生のベンチマーク資材(ビジネス系クエリ 22 本)
それぞれのサブディレクトリにはデータサイズ別のディレクトリがあり、各ディレクトリには以下のファイルが含まれています。
ddl.sql— テーブル定義(CREATE TABLE)とs3://redshift-downloads/...からのCOPY文、末尾に件数検証用SELECT COUNT(*)を含むquery_0.sql— 全クエリを 1 ファイルにまとめた Power Run 用query_1.sql〜query_n.sql— 同じクエリを異なる順序で並べた Throughput Run 用
データセットのサイズ別構成
GitHub 上に実在するサイズ別ディレクトリは、TPC-H と TPC-DS で異なります(2026年5月時点)。
| ベンチマーク | 利用可能なサイズ |
|---|---|
| Cloud-DWB-Derived-from-TPCH | 10GB / 100GB / 3TB / 30TB |
| Cloud-DWB-Derived-from-TPCDS | 1TB / 3TB |
TPC-H には 1TB のディレクトリが、TPC-DS には 10GB / 100GB のディレクトリが存在しない点に注意が必要です。TPC-H 10GB に含まれる 8 テーブルの期待件数は以下の通りです。
| テーブル | 期待件数 |
|---|---|
| region | 5 |
| nation | 25 |
| supplier | 100,000 |
| customer | 1,500,000 |
| part | 2,000,000 |
| partsupp | 8,000,000 |
| orders | 15,000,000 |
| lineitem | 59,986,052 |
データの実体は s3://redshift-downloads/TPC-H/2.18/<SIZE>/ に配置されており、リージョンは us-east-1 です。同リージョンの Redshift から COPY するのが前提となります。
やってみた
前提条件
- リージョン: us-east-1
- 検証アカウントで Redshift / IAM の作成権限があること
検証では以下のリソースを新規に作成します。
| リソース | 名前 |
|---|---|
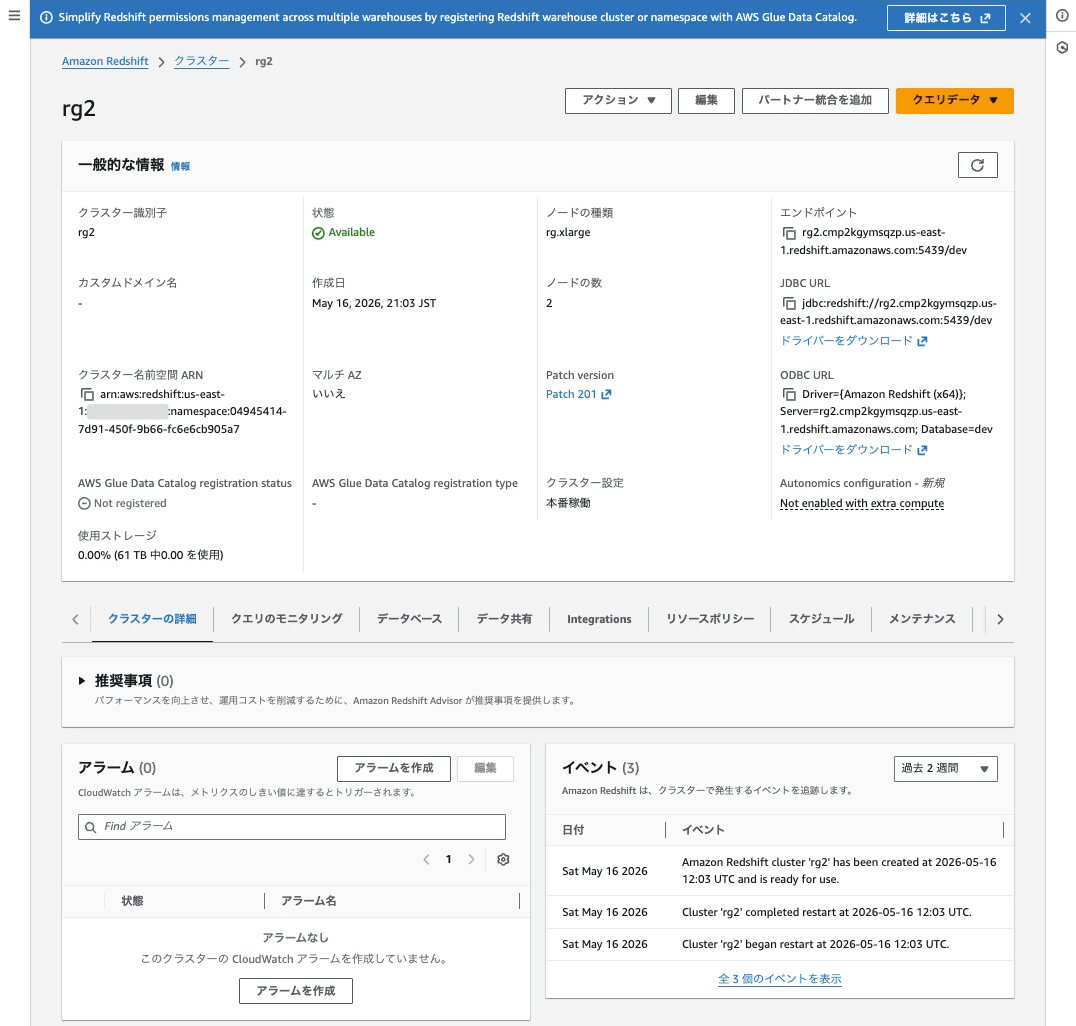
| Redshift クラスタ | rg2 |
| Redshift ノードタイプ | rg.xlarge × 2 |
| データベース | dev |
| マスターユーザー | awsuser |
| 投入先スキーマ | tpch10g |
| IAM ロール | rg2-s3-read |
ロード時間と件数
クラスタが利用可能になるまで約 4 分かかりました。RA3 ファミリーで体感していたよりも早い印象です。データファイルのロードは、Redshift Data API(aws redshift-data)経由で順次投入しました。
install_benchmark.sh 実行後、./evidence/<run_id>/copy_durations.tsv と ./evidence/<run_id>/row_counts.tsv にテーブルごとのロード時間と件数が記録されます。
実測値は以下の通りでした。Duration 列は aws redshift-data describe-statement が返した値(ナノ秒を ms に換算)、実測(壁時計) は execute-statement 発行から FINISHED をポーリングで確認するまでの実時間です。
| テーブル | Data API Duration | 実測(壁時計) | ロード件数 |
|---|---|---|---|
| region | 563 ms | 2 秒 | 5 |
| nation | 591 ms | 3 秒 | 25 |
| lineitem | 54,557 ms | 58 秒 | 59,986,052 |
| orders | 12,713 ms | 18 秒 | 15,000,000 |
| part | 2,457 ms | 7 秒 | 2,000,000 |
| supplier | 1,006 ms | 8 秒 | 100,000 |
| partsupp | 8,480 ms | 12 秒 | 8,000,000 |
| customer | 2,567 ms | 8 秒 | 1,500,000 |
| 合計 | 約 83 秒 | 約 124 秒 | — |
メトリクス
クラスターメトリクス
データウェアハウスパフォーマンス
クエリランタイム
考察
実際に試してみて気付いたポイントを整理します。
- Redshift Data API +
batch-execute-statementでpsqlを使わずに済む: AWS CLI だけで DDL/COPY/COUNT のすべてを完結できるため、ベンチマーク導入の再現性が高い。execute-statementは単一 SQL 文しか受け付けないため、複数 SQL はbatch-execute-statementを使い分けるのがポイントでした。 iam_role defaultのままでも動く: クラスタにデフォルト IAM ロールを設定しておけば、DDL 内のiam_role defaultをそのまま流せます。今回はブログ用に決定論的な動きを優先して--iam-role-arnで明示置換しました。- COPY ごとに
execute-statementを分けるとdescribe-statementのDurationでロード時間が取得できる:batch-execute-statementだと各 SQL の所要時間を取り出すロジックが複雑になります。テーブル単位の所要時間を見たい場合はテーブル数だけexecute-statementを呼ぶ作りが扱いやすいです。 - RG インスタンス(
rg.xlarge × 2)はクラスタ作成も比較的スムーズ: 検証時のクラスタ作成所要時間は約 4 分、TPC-H 10GB の最大テーブルlineitem(5,998 万行)のロードは 58 秒で完了し、全 8 テーブル合計でも 2 分強でロードが終わりました。
最後に
先日リリースされたRGインスタンスを早速検証しようとしたところ、データは手動でロードする必要があるようでした。実際に試してみたところ、手順が多くそれなりに時間がかかったため、今回はその手順をブログでご紹介することにしました。一方で、検証の用途や規模に応じてサンプルデータの量を調整できる点は、非常に使い勝手が良いと感じました。
AWS Labs 公開の CloudDataWarehouseBenchmark を使うと、TPC-H 10GB クラスのデータが COPY 一発でロードできるため、Redshift の新機能(今回は RG インスタンス)の動作確認を素早く始められます。









