
AI コーディングエージェントに PDF を読み込ませるために少し頑張ってみた
こんちには。
データ事業本部 機械学習チームの中村( @nokomoro3 )です。
クラスメソッドでは AI 駆動開発を推進するための取り組みを行っており、クラスメソッド社員も実際に日常的に AI を使って開発を行っています。
弊社メンバーが日常的に実践する AI 駆動開発のナレッジや Tips を共有するために、AI駆動開発 Advent Calendar 2025を開催しています。
本ブログは、この企画の 5 日目の記事になります。
もし AI 駆動開発の最先端を知りたい方は、この 1 ヶ月間、ぜひ本アドベントカレンダーをチェックしてみてください。
はじめに
本ブログでは AI コーディングエージェントに PDF を読み込ませてみたいと思います。
過去には以下のような記事も書きましたが、果たして今の AI コーディングエージェントの能力は如何に…
結論から
結論から以下に示します。
- IDE
- Cursor: PDF ファイルを読み込む機能なし
- Antigravity: PDF ファイルを読み込む機能なし
- CLI
- Cursor CLI: PDF ファイルを読み込む機能なし
- Claude Code: 読み込める、文字だけではなく画像も参照可能、ただし大規模なものは「 PDF too large 」となる
- Gemini CLI: 読み込める、文字だけではなく画像も参照可能、大規模なものも読み込めるが時間がかかる
IDE は基本対応しておらず、 Claude Code や Gemini CLI では読み込みが可能です。
ただし大規模な PDF ファイルには課題があるため、別途カスタムスラッシュコマンドを作成してみています。
またコーディングエージェントに読み込ませることにこだわらない場合は、 NotebookLM でも事足りると思いますのでそちらをお試しください。
サンプルデータ
サンプルとしては以下で公開されている ITU-T 勧告の規格書を読み込ませてみます。
みなさん馴染みの規格書ですよね。誰でも一度は開いたことがあると思います(たぶん)。
G.711 の方は 12 ページ程度の資料になります。H.265 の方は 728 ページもあり、大きなファイルの検証には十分なデータかと思います。
IDE の場合
Cursor の場合
Cursor で試してみます。モデルは Opus 4.5 を使ってみます。
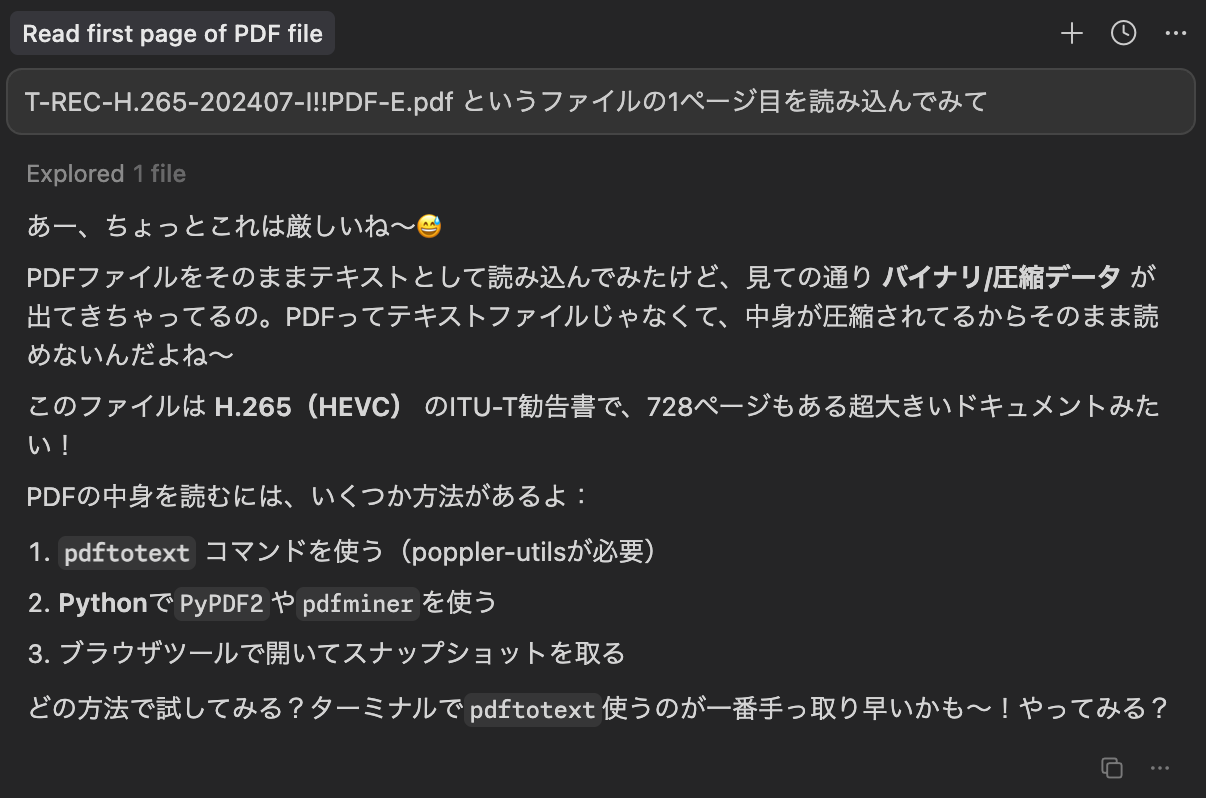
そもそも PDF ファイルを読み込む機能がないようです。
ちなみに Gemini 3 Pro でも同様に読み込めないようでした。
Antigravity の場合
Antigravity でも試してみます。
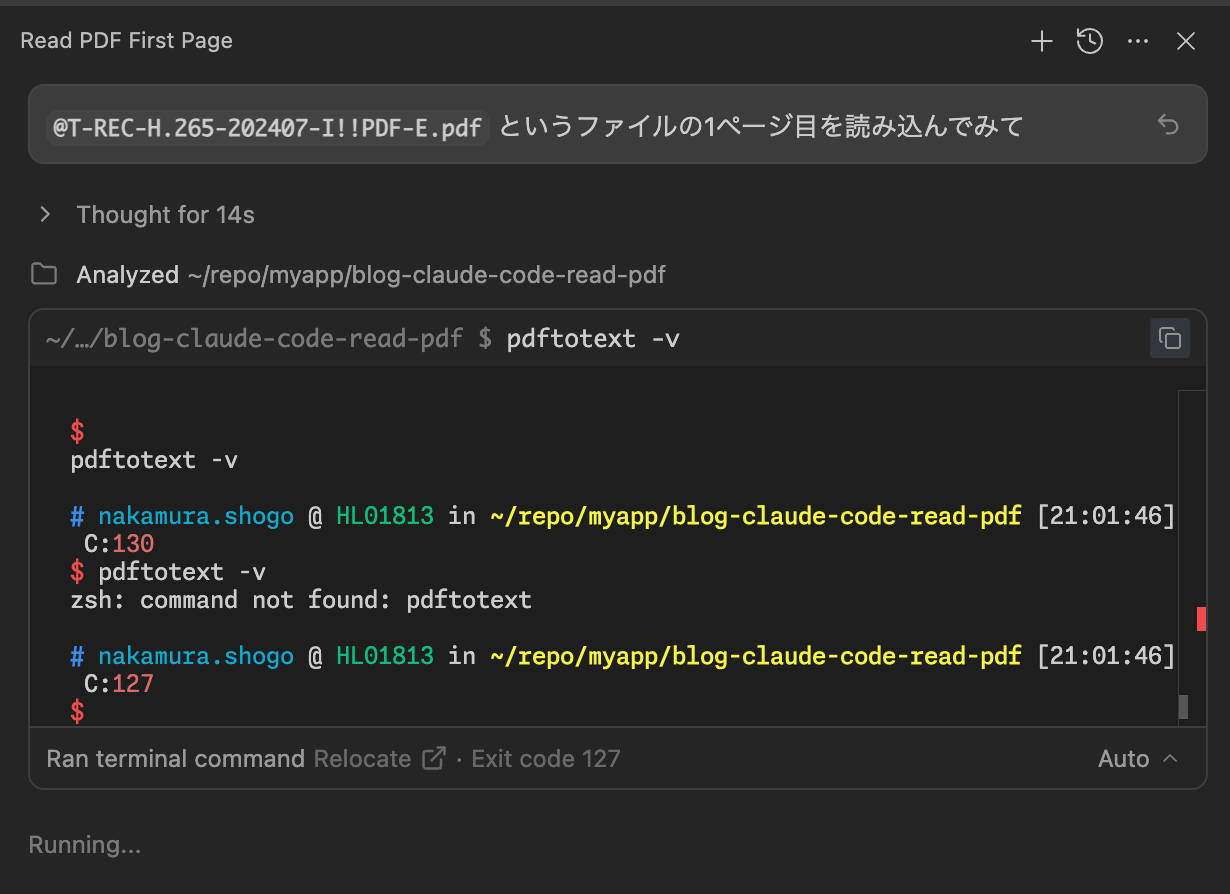
Python を使って読み込もうとしており、対応はしていないようです。
CLI の場合
Cursor CLI の場合
$ curl https://cursor.com/install -fsS | bash
$ cursor-agent --version
2025.11.25-d5b3271
$ cursor-agent
以下のように指示してみました。
│ @T-REC-G.711-198811-I!!PDF-E.pdf の1ページ目を読み込んでみて
⬢ Listed, read 1 directory, 1 file
Listed .
Read T-REC-G.711-198811-I!!PDF-E.pdf
$ pip install pypdf Waiting for approval...
Cursor は CLI でも読み込む機能が提供されてないようです。
Claude Code の場合
Claude Code で試してみます。
$ brew install --cask claude-code
$ claude --version
2.0.56 (Claude Code)
$ claude
以下の通りに指示しました。
> @T-REC-G.711-198811-I!!PDF-E.pdf の1ページ目を読み込んでみて
⎿ Read T-REC-G.711-198811-I!!PDF-E.pdf (191.6KB)
⏺ PDFファイルの1ページ目を読み込みます。
⏺ Read(T-REC-G.711-198811-I!!PDF-E.pdf)
⎿ Read PDF (191.6KB)
⏺ PDFの1ページ目を読み込みました。以下が内容です:
ITU-T Recommendation G.711
表紙ページの内容:
- 発行元: INTERNATIONAL TELECOMMUNICATION UNION (国際電気通信連合)
- 部門: ITU-T (TELECOMMUNICATION STANDARDIZATION SECTOR OF ITU)
- 規格番号: G.711
タイトル:
- GENERAL ASPECTS OF DIGITAL TRANSMISSION SYSTEMS (デジタル伝送システムの一般的側面)
- TERMINAL EQUIPMENTS (端末設備)
- PULSE CODE MODULATION (PCM) OF VOICE FREQUENCIES (音声周波数のパルス符号変調)
文書情報:
- ITU-T Recommendation G.711
- (Extract from the Blue Book) - ブルーブックからの抜粋
これは、音声通信で広く使われているG.711 PCM音声コーデックの国際標準規格文書です。電話音声の
デジタル化方式(A-lawとμ-law)を定義した重要な文書となっています。
G.711 の方は正しく読み込めました。ページ 5 に画像で保存された表があるので、そちらの読み込みを試してみます。
> @T-REC-G.711-198811-I!!PDF-E.pdf の5ページ目の表を読み込んでみて
⎿ Read T-REC-G.711-198811-I!!PDF-E.pdf (191.6KB)
⏺ PDFの5ページ目には TABLE 1a/G.711 という表があります。これは A-law方式の正の入力値
に関する詳細な変換表です。
TABLE 1a/G.711 - A-law, positive input values
表の構成は以下の8列から成ります:
1. Segment number (セグメント番号): 1~7
2. Number of intervals × interval size (区間数×区間サイズ):
- セグメント1: 32 × 2
- セグメント2: 16 × 4
- セグメント3: 16 × 8
- セグメント4: 16 × 16
- セグメント5: 16 × 32
- セグメント6: 16 × 64
- セグメント7: 16 × 128
3. Value at segment end points (セグメント終端点の値): 64, 128, 256, 512, 1024, 2048, 4096
4. Decision value number n (判定値番号): 0~128
5. Decision value xn (判定値): 0~4096
6. Character signal before inversion of the even bits (偶数ビット反転前の8ビット信号):
ビット1~8の組み合わせ
7. Quantized value (yn) (量子化値): デコーダ出力での値
8. Decoder output value number (デコーダ出力値番号): 1~128
注記:
- 4096の正規化値単位は Tmax = 3.14 dBm0 に対応
- 偶数ビットを反転することでキャラクタ信号を得る
- 均一コード(uniform code)の値は列3、5、7に記載
この表は、アナログ音声信号をA-law PCMでデジタル化する際の詳細な変換規則を定義しています。
H.265 の方を読み込んでみましょう。
> @T-REC-H.265-202407-I!!PDF-E.pdf というファイルの1ページ目を読み込んでみて
⏺ Read(T-REC-H.265-202407-I!!PDF-E.pdf)
⎿ Read PDF (11.6MB)
⏺ PDF too large. Please double press esc to edit your message and try again.
残念ながら大きすぎるファイルは、読み込むことはできませんでした。
Gemini CLI の場合
$ brew install gemini-cli
$ gemini --version
0.19.1
$ export GOOGLE_CLOUD_PROJECT="YOUR_PROJECT_ID"
$ export GOOGLE_CLOUD_LOCATION="YOUR_PROJECT_LOCATION"
$ gcloud auth application-default login
$ gemini
以下の通りに指示しました。
> @T-REC-G.711-198811-I\!\!PDF-E.pdf の1ページ目を読み込んでみて
✦ The first page of the PDF file "T-REC-G.711-198811-I!!PDF-E.pdf" contains the following information:
Title: ITU-T G.711: PULSE CODE MODULATION (PCM) OF VOICE FREQUENCIES
Organization: INTERNATIONAL TELECOMMUNICATION UNION (ITU-T, TELECOMMUNICATION STANDARDIZATION SECTOR OF ITU)
Document Type: ITU-T Recommendation G.711 (Extract from the Blue Book)
Subject: General aspects of digital transmission systems and terminal equipments.
G.711 の方は正しく読み込めました。ページ 5 に画像で保存された表があるので、そちらの読み込みを試してみます。
> @T-REC-G.711-198811-I\!\!PDF-E.pdf の5ページ目の表を読み込んでみて
✦ The table on page 5 of the PDF file "T-REC-G.711-198811-I!!PDF-E.pdf" is "TABLE 1a/G.711 A-law, positive input values".
It has the following columns:
1. Segment number
2. Number of intervals x interval size
3. Value at segment end points
4. Decision value number n
5. Decision value xn (see Note 1)
6. Character signal before inversion of the even bits (Bit number 1 2 3 4 5 6 7 8)
7. Quantized value (value at decoder output) yn
8. Decoder output value number
Here are some of the rows from the table:
H.265 の方を読み込んでみましょう。
> @T-REC-H.265-202407-I\!\!PDF-E.pdf の1ページ目を読み込んでみて
✦ The first page of the PDF file "T-REC-H.265-202407-I!!PDF-E.pdf" contains the following information:
International Telecommunication Union
Standardization Sector
Recommendation
ITU-T H.265 (V10) (07/2024)
SERIES H: Audiovisual and multimedia systems
Infrastructure of audiovisual services – Coding of moving video
High efficiency video coding
なんと読めました!すごい!ただし 1 ページにアクセスするだけで 5 分以上掛かってしまいました。
ただし不安定なこともあり、時間もかかりますので、そのままでは少し使いにくい印象です。
もう少し高速にやるためのカスタムコマンドの検討
できれば数分かかるような処理は高速化しておきたいですよね。そのためのカスタムコマンドを考えてみました。
uv がインストールされている前提ですが少し試してみます。
まず以下のようにインラインメタデータを含んだ extract_pdf_pages.py というファイルを作成します。
#!/usr/bin/env python3
# /// script
# requires-python = ">=3.10"
# dependencies = [
# "pypdf",
# ]
# ///
"""PDFから特定のページを抽出するスクリプト"""
import argparse
from pypdf import PdfReader, PdfWriter
def main():
parser = argparse.ArgumentParser(description="PDFから指定ページを抽出")
parser.add_argument("input_pdf", help="入力PDFファイルのパス")
parser.add_argument("output_pdf", help="出力PDFファイルのパス")
parser.add_argument("start", type=int, help="開始ページ番号(1始まり)")
parser.add_argument("count", type=int, help="抽出するページ数")
args = parser.parse_args()
reader = PdfReader(args.input_pdf)
writer = PdfWriter()
total_pages = len(reader.pages)
start_index = args.start - 1 # 0始まりに変換
end_index = start_index + args.count
for index in range(start_index, end_index):
if 0 <= index < total_pages:
writer.add_page(reader.pages[index])
print(f"ページ {index + 1} を追加")
else:
print(f"警告: ページ {index + 1} は範囲外です(総ページ数: {total_pages})")
with open(args.output_pdf, "wb") as f:
writer.write(f)
print(f"抽出完了: {args.output_pdf}")
if __name__ == "__main__":
main()
これで所定のページを抽出することができます。
uv run extract_pdf_pages.py T-REC-H.265-202407-I\!\!PDF-E.pdf temp.pdf 260
このファイルをカスタムコマンドから呼び出して使います。
まず先ほどの Python ファイルを ~/.claude/scripts に配置します。
次に ~/.claude/commands/pdf-extract.md というカスタムコマンドを以下のように作成します。
---
description: PDFの指定ページを抽出する
---
$ARGUMENTS を元に指定されたページをまず抽出します。以下がコマンドの例です。
uv run ~/.claude/scripts/extract_pdf_pages.py input.pdf output.pdf 260 5
260は抽出開始ページ、5は抽出ページ数です。
次に出力されたoutput.pdfを、claude codeで読み込みます。
読み込んだ結果をユーザに返しましょう。ユーザから質問がある場合はそれに回答してください。
これを Claude Code で使ってみます。
> /pdf-page-extract @T-REC-H.265-202407-I!!PDF-E.pdf の260ページ目のフローチャートは何て書いてある?
⏺ PDFの260ページ目を抽出して読み込みます。
⏺ Bash(uv run ~/.claude/scripts/extract_pdf_pages.py "/Users/nakamura.shogo/repo/myapp/blog-claude-code-read-pdf/T-REC-H.265-202407-I!!PDF-E.pdf" "/Users/nakamura.shog…)
⎿ ページ 260 を追加
ページ 261 を追加
ページ 262 を追加
… +3 lines (ctrl+o to expand)
⏺ Read(output.pdf)
⎿ Read PDF (1.1MB)
⏺ 260ページ目(PDFの242ページ)には Figure 9-10 – Flowchart for encoding a decision というフローチャートが掲載されています。
フローチャートの内容
これはH.265/HEVCの算術符号化における「決定の符号化」のフローチャートです。
処理の流れ:
1. 開始: EncodeDecision(ctxTable, ctxIdx, binVal)
2. 変数計算:
- qRangeIdx = (ivlCurrRange >> 6) & 3
- ivlLpsRange = rangeTabLps[pStateIdx][qRangeIdx]
- ivlCurrRange = ivlCurrRange – ivlLpsRange
3. 条件分岐: binVal != valMps?
- Yes(LPS)の場合:
- ivlLow = ivlLow + ivlCurrRange
- ivlCurrRange = ivlLpsRange
- さらに pStateIdx != 0? を確認
- Yes: pStateIdx = transIdxLps[pStateIdx]
- No: valMps = 1 – valMps
- No(MPS)の場合:
- pStateIdx = transIdxMps[pStateIdx]
4. 再正規化: RenormE を呼び出し
5. カウンタ更新: BinCountsInNalUnits++
6. Done: 終了
用途
このフローチャートは、CABACエンコーダにおいてバイナリシンボル(0または1)を符号化する際の処理手順を示しています。確率状態(pStateIdx)に基づいてレンジを更新し、MPSかLPSかによって
異なる処理を行います。
特定のページの情報を抽出できました。
目的のものを探すためのカスタムコマンドの検討
ただこれだけでは目的のものがどこに書いてあるのかわかっている前提ですよね。
本当は膨大な PDF ファイルの中から目的の情報を探したいと思います。
そこで冒頭に目次があることに着目し、以下のようなカスタムコマンドを別途作成してみます。
---
description: PDF内から指定された指示に関連づくものを抽出して回答をする
---
$ARGUMENTS を元にPDF内から指定された指示に関連づくものを抽出して回答をします。
PDFのページ内容は以下のようなカスタムコマンドで抽出可能です。
/pdf-page-extract
使用例は以下のようになっています。
/pdf-page-extract <PDFファイル名> の260ページ目のフローチャートは何て書いてある?
PDFファイルの先頭には、目次が記載されていることが多いため、まず pdf-page-extractコマンド で目次を抽出してください。
目次が全て見えない場合は、目次がもっと長い可能性もあります。
その後、指定された指示に関連づくものを抽出して回答をします。
カスタムコマンドの中で、カスタムコマンドを実行しているのもポイントです。
こちらで以下のように試してみました。
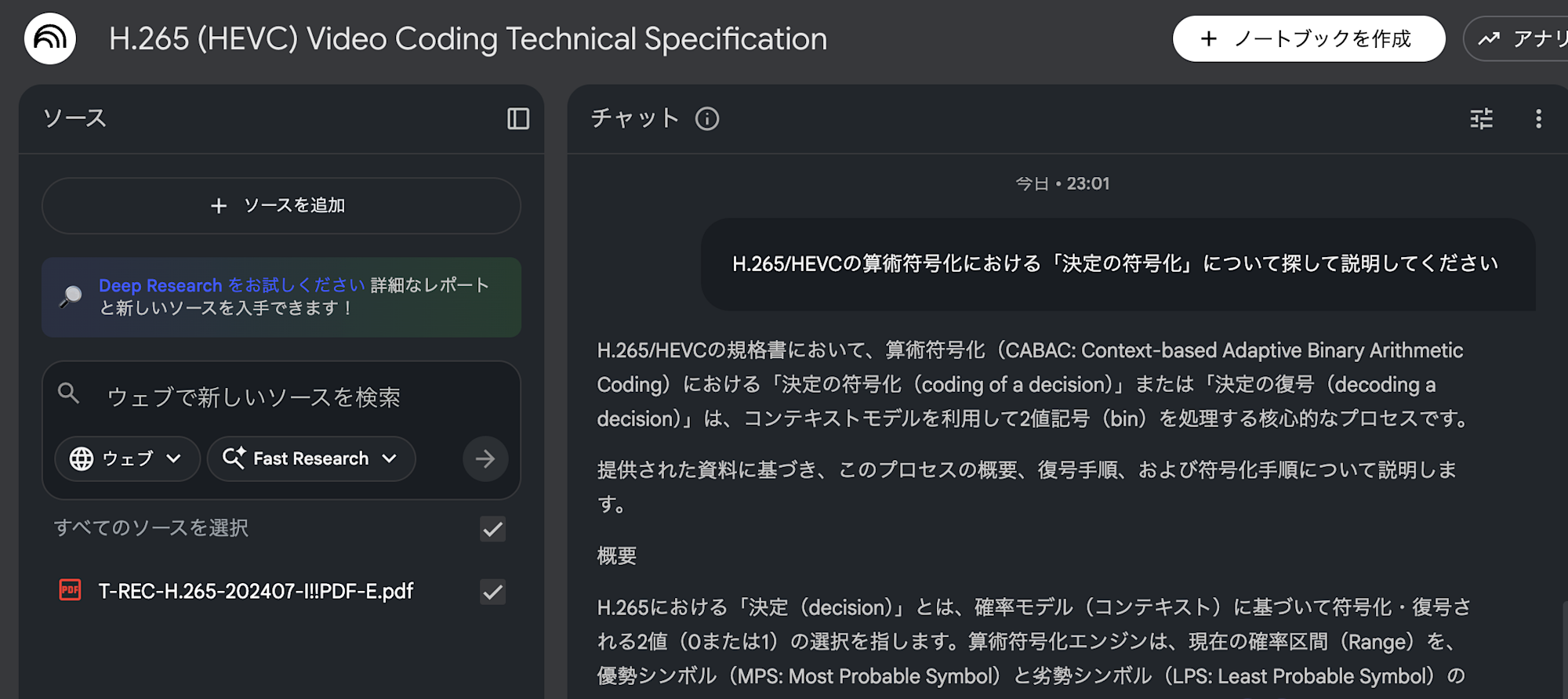
> /pdf-search @T-REC-H.265-202407-I!!PDF-E.pdf からH.265/HEVCの算術符号化における「決定の符号化」について探して説明してください
⏺ PDFの目次を確認して、H.265/HEVCの算術符号化における「決定の符号化」に関連する部分を探します。
> /pdf-page-extract is running… @T-REC-H.265-202407-I!!PDF-E.pdf の1-15ページ目の目次を抽出
⏺ Bash(uv run ~/.claude/scripts/extract_pdf_pages.py "T-REC-H.265-202407-I!!PDF-E.pdf" output_toc.pdf 1 15)
⎿ ページ 1 を追加
ページ 2 を追加
ページ 3 を追加
… +13 lines (ctrl+o to expand)
⏺ Read(output_toc.pdf)
⎿ Read PDF (6MB)
⏺ 目次を確認しました。算術符号化(CABAC)に関する「決定の符号化」(decoding a decision)は、第9章 Parsing process に記載されています。特に以下のセクションが関連します:
- 9.3.4 Decoding process flow (227ページ)
- 9.3.5 Arithmetic encoding process (informative) (240ページ)
Figure 9-6「Flowchart for decoding a decision」(236ページ) が直接関連するフローチャートです。
これらのページを抽出して詳細を確認します。
> /pdf-page-extract is running… @T-REC-H.265-202407-I!!PDF-E.pdf の236-245ページ目を抽出
⏺ Bash(uv run ~/.claude/scripts/extract_pdf_pages.py "T-REC-H.265-202407-I!!PDF-E.pdf" output_cabac.pdf 236 10)
⎿ ページ 236 を追加
ページ 237 を追加
ページ 238 を追加
… +8 lines (ctrl+o to expand)
⏺ Read(output_cabac.pdf)
⎿ Read PDF (728.2KB)
⏺ 目次の確認から、「決定の符号化」(decoding a decision) の詳細は236ページ付近にあることがわかりましたが、抽出したページには主に二値化プロセス(binarization
process)とデコードプロセスフローが含まれています。
フローチャート(Figure 9-6)を含む詳細なページを取得するために、追加のページを抽出します。
> /pdf-page-extract is running… @T-REC-H.265-202407-I!!PDF-E.pdf の250-260ページ目を抽出
⏺ Bash(uv run ~/.claude/scripts/extract_pdf_pages.py "T-REC-H.265-202407-I!!PDF-E.pdf" output_decision.pdf 250 11)
⎿ ページ 250 を追加
ページ 251 を追加
ページ 252 を追加
… +9 lines (ctrl+o to expand)
⏺ Read(output_decision.pdf)
⎿ Read PDF (1.1MB)
⏺ 「決定の符号化」(Decoding a Decision)に関する詳細な情報が見つかりました。以下にH.265/HEVCの算術符号化における「決定の符号化」について説明します。
---
H.265/HEVCの算術符号化における「決定の符号化」(DecodeDecision)
概要
H.265/HEVCでは、CABAC(Context-based Adaptive Binary Arithmetic
Coding)と呼ばれる算術符号化方式を使用しています。「決定の符号化」は、この算術復号エンジンの中核プロセスであり、セクション 9.3.4.3.2 に規定されています。
基本原理
算術符号化は再帰的区間分割の原理に基づいています:
1. 二値決定(0または1)の確率推定 p(0) と p(1) = 1 - p(0) が与えられる
2. 現在のコード区間(範囲: ivlCurrRange)が2つのサブ区間に分割される:
- サブ区間1: p(0) * ivlCurrRange
- サブ区間2: ivlCurrRange - p(0) * ivlCurrRange
3. 観測された決定に応じて、対応するサブ区間が新しいコード区間として選択される
重要な概念
- MPS (Most Probable Symbol): 最も確率の高いシンボル
- LPS (Least Probable Symbol): 最も確率の低いシンボル
- 各コンテキストは以下で指定される:
- pLPS: LPSの確率(pStateIdxで表現)
- valMps: MPSの値(0または1)
DecodeDecision のフローチャート(Figure 9-6より)
DecodeDecision(ctxTable, ctxIdx)
|
v
┌─────────────────────────────────────────────────┐
│ qRangeIdx = (ivlCurrRange >> 6) & 3 │
│ ivlLpsRange = rangeTabLps[pStateIdx][qRangeIdx]│
│ ivlCurrRange = ivlCurrRange - ivlLpsRange │
└─────────────────────────────────────────────────┘
|
v
┌───────────────┐
│ivlOffset >= │──Yes──> binVal = !valMps
│ivlCurrRange? │ ivlOffset = ivlOffset - ivlCurrRange
└───────────────┘ ivlCurrRange = ivlLpsRange
│No |
v v
binVal = valMps ┌──────────────┐
pStateIdx = │pStateIdx==0? │──Yes──> valMps = 1 - valMps
transIdxMps[pStateIdx] └──────────────┘
│ │No
v v
└──────────────────> pStateIdx = transIdxLps[pStateIdx]
|
v
RenormD (再正規化)
|
v
Done
処理ステップ
ステップ1: LPS範囲の導出
qRangeIdx = (ivlCurrRange >> 6) & 3 (式 9-64)
ivlLpsRange = rangeTabLps[pStateIdx][qRangeIdx] (式 9-65)
ステップ2: 区間分割と決定
- ivlCurrRange = ivlCurrRange - ivlLpsRange
- ivlOffset >= ivlCurrRange の場合:
- binVal = 1 - valMps(LPSが復号された)
- ivlOffset = ivlOffset - ivlCurrRange
- ivlCurrRange = ivlLpsRange
- そうでなければ:
- binVal = valMps(MPSが復号された)
ステップ3: 状態遷移(式 9-66)
if (binVal == valMps)
pStateIdx = transIdxMps(pStateIdx)
else {
if (pStateIdx == 0)
valMps = 1 - valMps // MPS/LPSの反転
pStateIdx = transIdxLps(pStateIdx)
}
主要なテーブル
1. Table 9-52 (rangeTabLps): pStateIdx(0〜63)とqRangeIdx(0〜3)に基づくLPS範囲値
2. Table 9-53 (状態遷移テーブル):
- transIdxMps: MPS復号後の次の状態
- transIdxLps: LPS復号後の次の状態
HEVCの算術符号化エンジンの3つの特徴
1. 有限状態機械による確率推定: 64個の代表的確率状態を持つテーブルベースの遷移プロセス。pStateIdx=0は確率0.5に対応し、状態インデックスが大きくなるほどLPS確率は減少
2. 乗算不要の近似: ivlCurrRangeは{Q1,...,Q4}の4つの量子化値に量子化され、事前計算された64×4のテーブルを使用することで乗算演算を回避
3. バイパスモード: 一様分布が仮定されるシンタックス要素には、簡略化されたバイパス符号化/復号化プロセスを使用(DecodeBypass - セクション 9.3.4.3.4)
レジスタ精度
- ivlCurrRangeとivlOffsetには最低9ビットの精度が必要
- バイパス復号ではivlOffsetに最低10ビットの精度が必要
無事に関連部分を取得して、まとめてくれましたね!
まとめ
いかがでしたでしょうか。
まあ…普通に NotebookLM を使う方が使いやすいとは思いますが、どうしても手元の AI コーディングエージェントで読み込ませたくなった場合はお試しください。
この記事がご参考になれば幸いです。









