[新機能]AI_FILTER関数が一般提供となったので試してみた
かわばたです。
2026年1月22日にAI_FILTER関数が一般提供となりました。
テキストや画像に対して、TRUE/FALSEを判定してフィルタリングしてくれる関数ですが、それぞれ確認していきます。
【公式ドキュメント】
AI_FILTER
対象読者
- AI_FILTER関数について確認したい方
検証環境
- SnowflakeトライアルアカウントEnterprise版
概要
AI_FILTERを使用すると、ビジネスユーザーとデータチームは、テキストの一致だけでなく、意味や意図に基づいてデータをフィルタリングできます。これにより、分析の高速化とクエリの直感性が向上し、ビジネス上の質問をSQLロジックに変換する作業が大幅に削減されます。
AI_FILTER関数は、自由形式の指示文(プロンプト)をTRUE/FALSEに分類するための関数です。
現時点でテキストと画像のフィルタリングをサポートします。
事前準備
使用するデータ
KaggleのSteam Games, Reviews, and Rankingsのデータを使用していきます。
データ容量が大きかったため、分割処理をローカル環境で行っています。
import pandas as pd
# 正しいファイルパスを指定します
input_file = '指定のファイルパス'
# 分割する行数
chunk_size = 100000
# ファイルを分割して保存
for i, chunk in enumerate(pd.read_csv(input_file, chunksize=chunk_size)):
chunk.to_csv(f'output_{i+1}.csv', index=False)
print("ファイルの分割が完了しました。")
分割したファイルをステージに格納しました。

レビューデータをバルクロード
スキーマおよびテーブルを作成しデータをバルクロードしていきます。
-- スキーマの作成
CREATE SCHEMA IF NOT EXISTS steam_schema;
-- テーブルの作成
CREATE OR REPLACE TABLE steam_reviews (
review TEXT,
hours_played VARCHAR(16777216),
helpful VARCHAR(16777216),
funny VARCHAR(16777216),
recommendation VARCHAR(16777216),
review_date VARCHAR(16777216),
game_name VARCHAR(16777216),
username VARCHAR(16777216)
);
-- バルクロード
COPY INTO steam_reviews
FROM (
SELECT
$1, -- review
$2, -- hours_played
$3, -- helpful
$4, -- funny
$5, -- recommendation
$6, -- review_date
$7, -- game_name
$8 -- username
FROM @KAWABATA_MART_DB.STEAM_SCHEMA.test -- ご自身のステージ名に置き換えてください
)
FILE_FORMAT = (
TYPE = 'CSV',
SKIP_HEADER = 1,
FIELD_DELIMITER = ',',
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
);
データとしては下記のような形です。
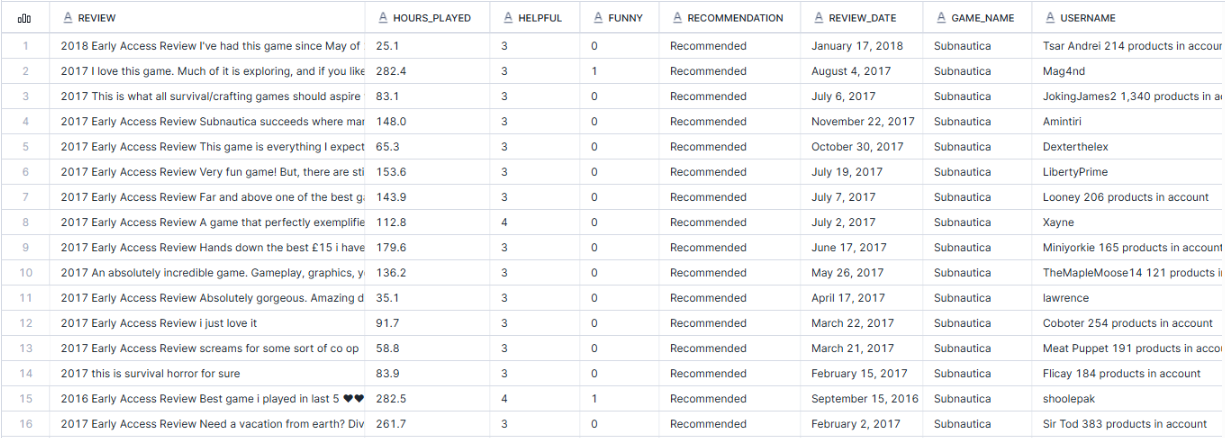
カラム定義
| No | カラム名 | 説明 | 例 |
|---|---|---|---|
| 1 | REVIEW | レビュー本文 | 2023 The game was initially not playable... |
| 2 | HOURS_PLAYED | プレイ時間 | 89.8 |
| 3 | HELPFUL | Helpful票数 | 12 |
| 4 | FUNNY | Funny票数 | 3 |
| 5 | RECOMMENDATION | 推奨フラグ(Recommended / Not Recommended) | Recommended |
| 6 | REVIEW_DATE | レビュー投稿日 | November 8, 2023 / May 1 |
| 7 | GAME_NAME | ゲーム名 | EA SPORTS™ WRC |
| 8 | USERNAME | 投稿ユーザー名 | Bacon / Pywackett-Barchetta\n787 products in account |
実際に試してみた
anti-cheatへの苦情があるレビューだけ抽出
WITH test AS (
SELECT *
FROM steam_reviews
LIMIT 100
)
SELECT *
FROM test
WHERE AI_FILTER(
PROMPT(
'In the following Steam review, is the user complaining about anti-cheat? Review: {0}',
review
)
);
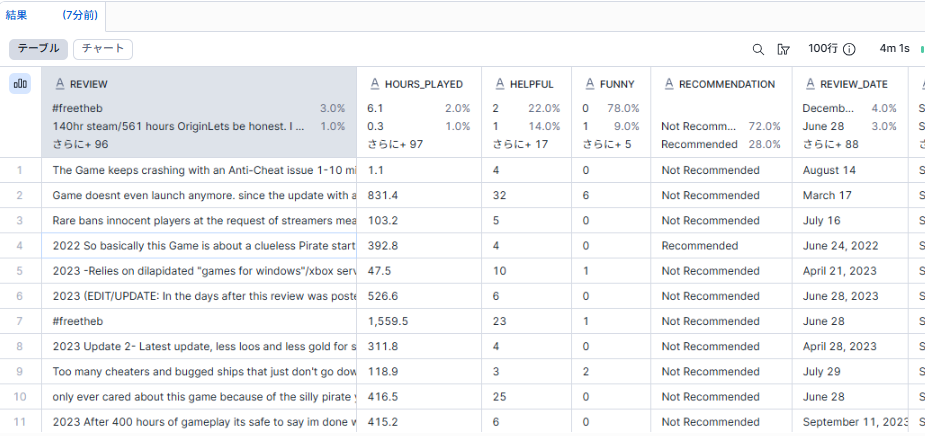
Not Recommendedの表記が多いことからおおむね正しくフィルタリングできていそうです。
TRUE/FALSEを出力・集計して割合を確認する
anti-cheatへの苦情があるレビューに対してTRUE/FALSEに分類し抽出
WITH test AS (
SELECT *
FROM steam_reviews
LIMIT 100
),
labeled AS (
SELECT
recommendation,
AI_FILTER(
PROMPT(
'Return TRUE if the review complains about kernel-level anti-cheat; otherwise return FALSE. Review: {0}',
review
)
) AS is_anticheat_complaint
FROM test
)
SELECT
recommendation,
COUNT(*) AS total,
SUM(IFF(is_anticheat_complaint, 1, 0)) AS anticheat_cnt,
anticheat_cnt / NULLIF(total, 0) AS anticheat_ratio
FROM labeled
GROUP BY recommendation
ORDER BY total DESC;
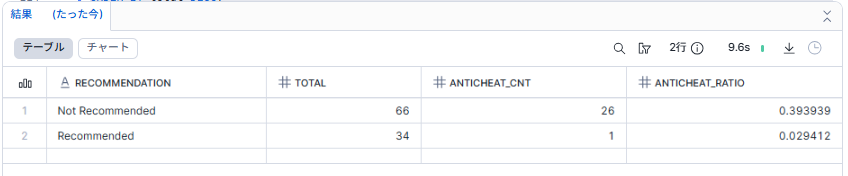
is_anticheat_complaintでTRUE/FALSEを返して分類することも可能です。
画像に対してAI_FILTERを使用
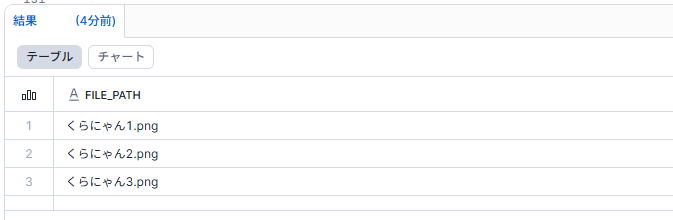
弊社マスコットキャラクターくらにゃんの画像を用いて抽出してみます。
ステージにはくらにゃんの画像のみ格納しています。
WITH pictures AS (
SELECT TO_FILE(file_url) AS png
FROM DIRECTORY(@KAWABATA_MART_DB.test.test)
)
SELECT FL_GET_RELATIVE_PATH(png) AS file_path
FROM pictures
WHERE AI_FILTER('猫の写真ですか?', png);
くらにゃん3のファイルだけ抽出してみます。

WITH pictures AS (
SELECT TO_FILE(file_url) AS png
FROM DIRECTORY(@KAWABATA_MART_DB.test.test)
)
SELECT FL_GET_RELATIVE_PATH(png) AS file_path
FROM pictures
WHERE AI_FILTER('星と猫の写真', png);
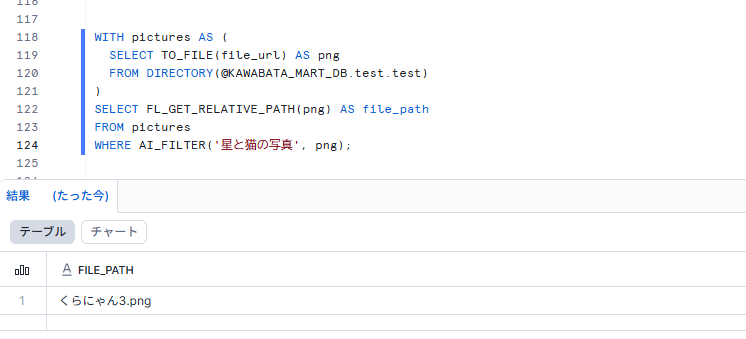
想定通りのアウトプットが出てきました。
画像データのような非構造化データに対してもアプローチできます。
ただ画像に対してAI_FILTER関数が活用できるのは、2026年1月時点で下記リージョンとなりますのでご注意ください。
| リージョン |
|---|
| AWS US West 2(Oregon) |
| AWS US East 1(N. Virginia) |
| AWS Europe Central 1(Frankfurt) |
| AWS(Cross-Region) |
まとめ
AI_FILTER関数の活用例として、
- レビューやコメントなどのテキストデータに対して、事前フィルタとして使用
- 例:肯定的意見・否定的意見
- 画像ファイルなどの非構造化データの抽出
使用する際は、「何をTRUEにしたいか」を1文で明確化することがAI_FILTER関数の品質を高めるので意識したい点です。
この記事が何かの参考になれば幸いです!







