
【レポート】トレーニングセッション「Apply Advanced Data Prep Techniques with Multi-Tools(高度なデータ準備技術をマルチツールで適用する)」– Alteryx Inspire 2025 #AlteryxInspire
こんにちは、まつおかです。
2025年5月12日(月)~5月15日(木)まで、アメリカ・ラスベガスで開催されたAlteryxの年次カンファレンスイベント「Inspire 2025」に現地参加してきました。
当エントリではイベント1日目に行われたトレーニングセッション「Apply Advanced Data Prep Techniques with Multi-Tools(高度なデータ準備技術をマルチツールで適用する)」のレポートをお届けします。

セッション概要
当トレーニングセッションの概要は以下のとおりです。
概要
Take your data preparation skills to the next level in this course for experienced users. Learn how to streamline complex processes using the Multi-Field Formula, Multi-Row Formula, and Join Multiple tools. Through a practical, real-world scenario, you will conquer a challenging dataset and solve critical business questions. Discover advanced techniques that will revolutionize your workflow efficiency!
このコースで、経験豊富なユーザー向けにデータ準備スキルを次のレベルに引き上げましょう。
マルチフィールド数式、マルチロー数式、複数結合ツールを使用して複雑なプロセスを効率化する方法を学びます。実践的な実世界のシナリオを通じて、難しいデータセットに取り組み、重要なビジネス上の問題を解決します。ワークフローの効率を革新する高度なテクニックを発見しましょう!
コースレベル:中級
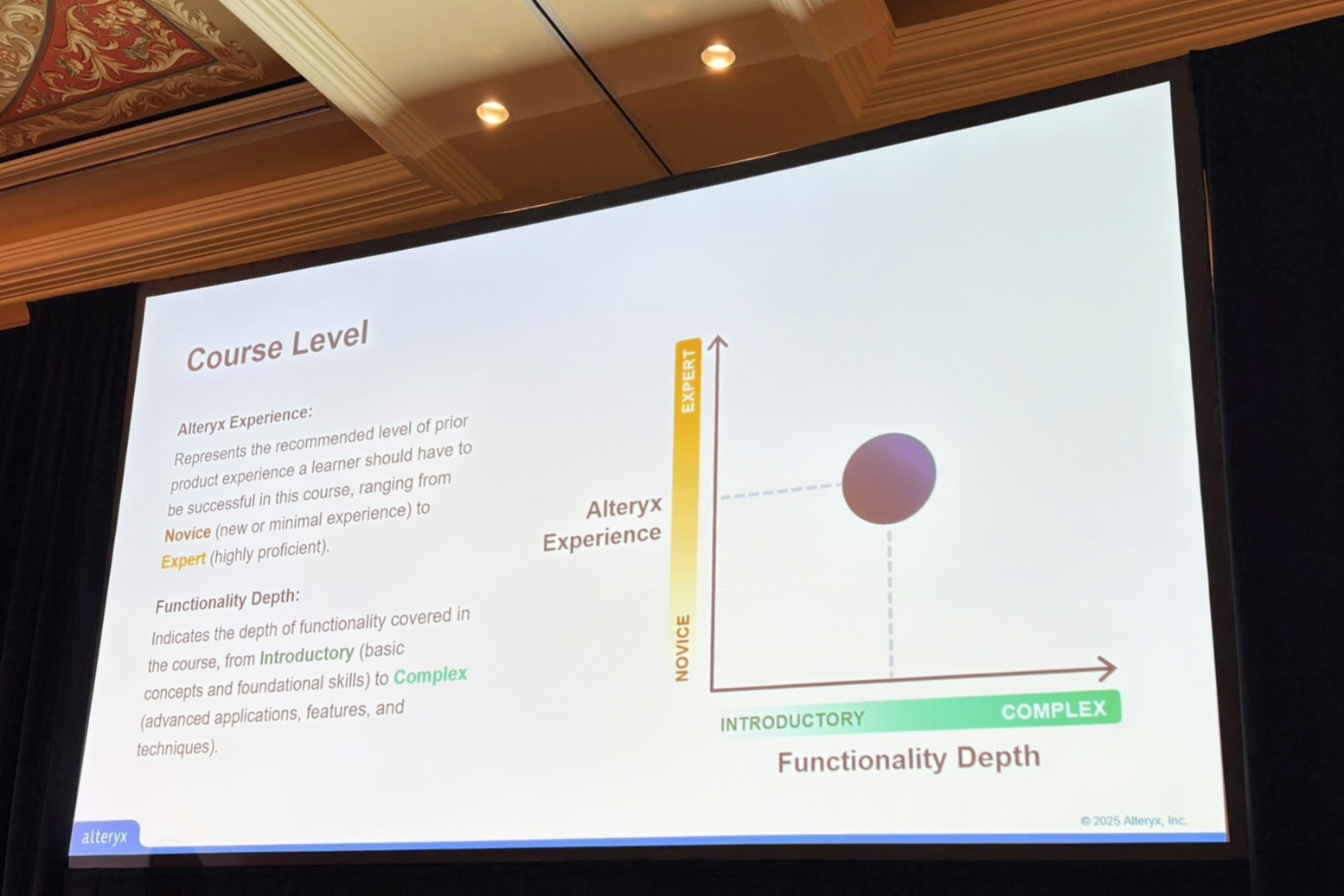
登壇者
- Dave Allam 氏
- Sr. Training Specialist at Alteryx
- シニアトレーニングスペシャリスト
- サイバーセキュリティ業界出身、データアナリストとしての豊富な経験を持ち、2016年にAlteryxと出会って以来、社内外の業務自動化やトレーニングでアナリストをサポート
セッションレポート
学習目標
このトレーニングセッションでは、次のことを学びます。
- 正規表現ツールを使用して乱雑なデータを解析する
- マルチツールを使用してデータを縦方向と横方向に効率的に処理する
まずは基礎を学んだ後、ケーススタディに入ります。
正規表現ツール

正規表現ツールには4種類の使用方法があります。
- Match(一致)
- フィールドが指定された正規表現パターンを持っているかテスト
- Parse(解析)
- 正規表現パターンに基づいてデータを列に解析
- Replace(置換)
- 正規表現パターンに基づいて特定のテキストを変更
- Tokenize(トークン化)
- 正規表現パターンに基づいて列または行に分割
メタ文字を含む文字を識別

メタ文字(正規表現において特別な意味や機能を持つ文字)は「\(バックスラッシュ)」で始まります。
正規表現における「トークン」とは、正規表現パターンを構成する斉唱の意味を持つ要素のことです。
例えば・・・
- \w:単語構成文字
- \d:数字
- \s:空白文字
- .:任意の文字
など
マークグループ
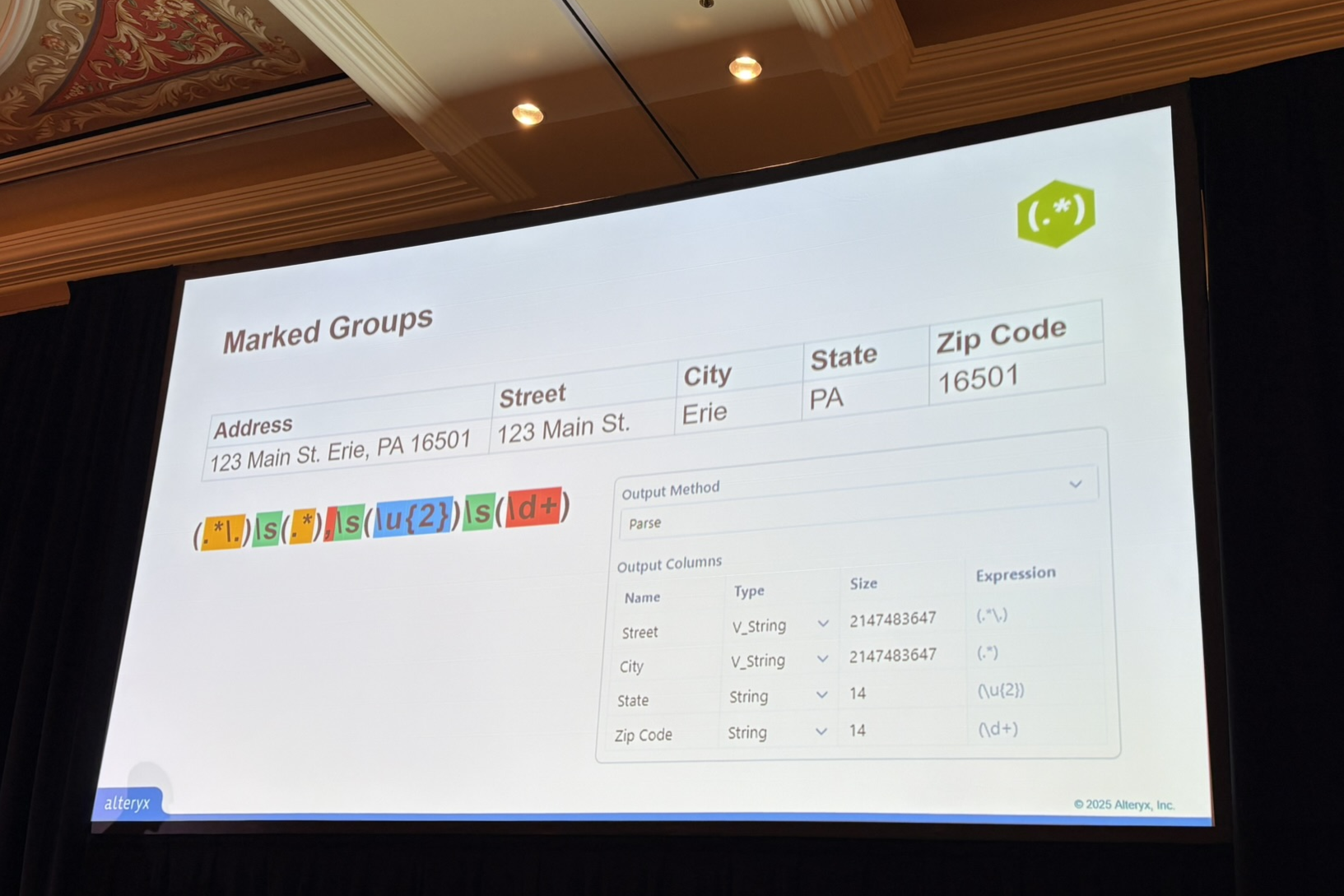
括弧「()」で囲むことで、パースしたデータの特定部分を新しいカラムとして抽出できます。
マルチツール
複雑で一貫性のないデータでも効率よく処理ができます。
-
複数フィールドフォーミュラ(Multi-Field Formula)ツール

- 複数のフィールドに式を適用
- 選択した各フィールドに適用する式を記述
-
複数行フォーミュラ(Multi-Row Formula)ツール

- 別のレコードのデータを参照し計算に使用
- 正確な計算のために行の順序が重要
アクティビティ

シナリオ
ATMトランザクションデータを複数の金融機関から要約するテーブルを作成したいと考えています。
データは非常に乱雑で、複数のファイルに存在します。
300件のトランザクションサンプルがあり、今後さらに多くのデータが届く予定です。
このデータを効率的に処理できるワークフローを構築してください。
以下の入力を組み合わせたテーブルを作成してください:
- ATMトランザクション記録
- ATM別のサービス技術者
- 銀行または金融機関別のATM所有権
- 日付別トランザクション
各金融機関について、以下の質問に答える出力を作成してください:
- 2月に各銀行が受け取った預金と引き出しの件数は?
- その月の各銀行の平均取引額は?
- その月の各銀行の預金と引き出しの合計額は?
やってみた
トレーニングではワークフローを構築するために「Start - ***.yxmd」というファイルが用意されています。
このファイルを開くと以下のようにInputファイルが配置されており、どのようなワークフローを組んでいけば良いか説明書きがありますので、それを読みながら構築を進めていきます

この説明を読みながら構築したワークフローがこちら。
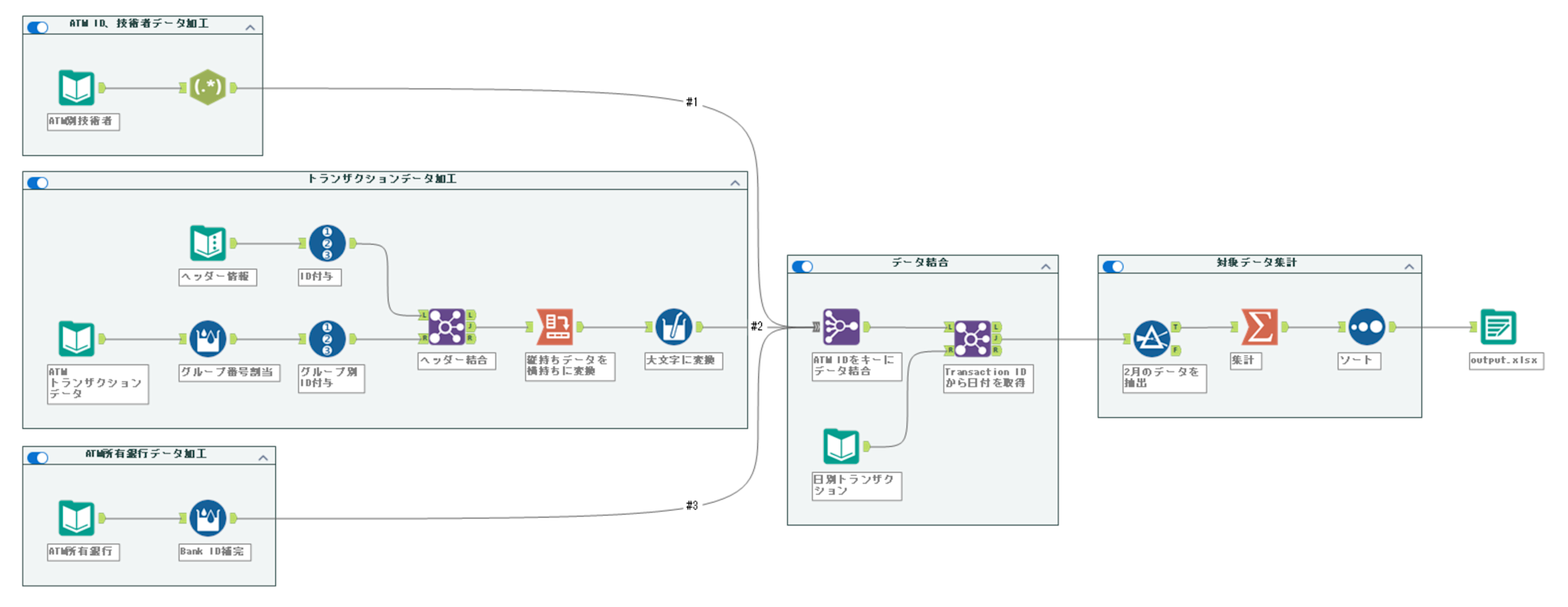
本トレーニングで学ぶべきポイントを絞り、説明していきます。
■ ATM別技術者データ加工
いちばん上のコンテナ内の処理です。
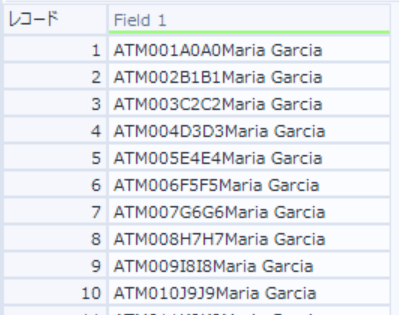
ATM別技術者データには「Field1」にATM IDと技術者の名前が連結した状態で入っていますので、これらを2つの列に分割します。
-
加工前
-
加工後
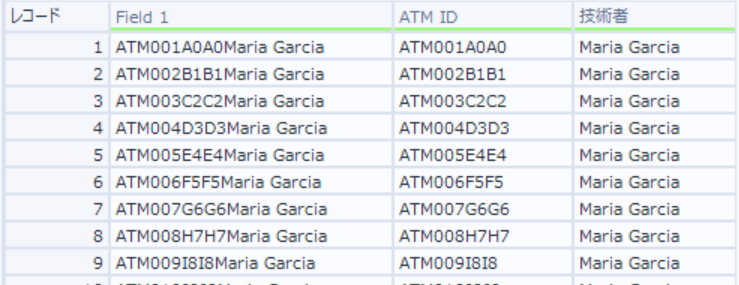
加工前のデータを見てみると、すべての行は「ATM」で始まり、そのあとに3桁の数字が続き、そして技術者の名前が続きます。
名前は大文字で始まっており、それが区切りの目印になります。
このような「一貫性のある不規則性」があるデータこそ、正規表現ツールが力を発揮します。
正規表現ツールの設定は以下のとおり。
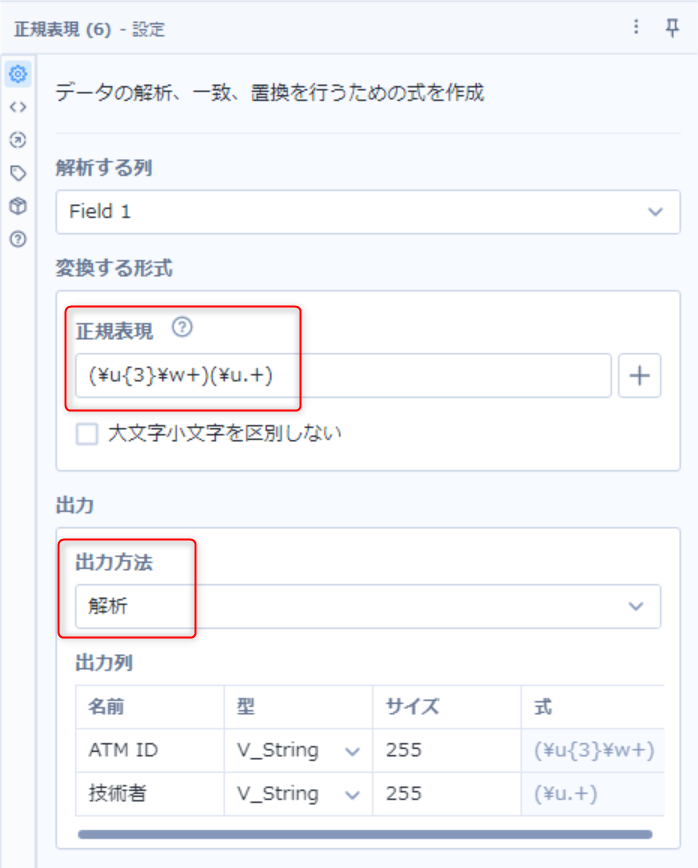
- 解析する列:Field 1
- 正規表現:(\u{3}\w+)(\u.+)
- マークグループという括弧「()」で囲うことでデータの特定部分を新しいカラムとして抽出可能
- ATM ID
- \u{3}:大文字3文字を意味する(今回の場合は「ATM」と入力しても問題なし)
- \w+:英数字を意味する「\w」と、1文字以上繰り返しを意味する「+」
- 技術者
- \u:大文字(名前の1文字目が大文字のため明示)
- .+:任意の文字を1文字以上繰り返すことを意味する
- 出力方法:解析
この設定で実行すると、列が分割されて出力されます。
■ トランザクションデータ加工
上から2番目のコンテナ内の処理です。
トランザクションデータには「Value」にデータが縦に並んだ状態で入っていますので、これを横に展開して整形する加工が必要となります
-
加工前
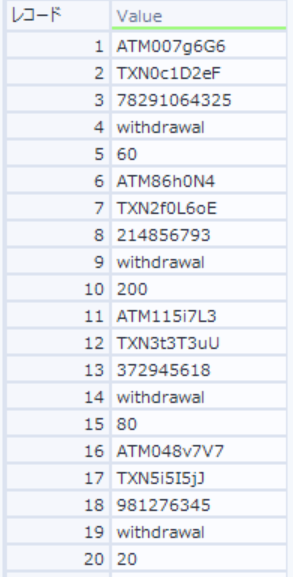
- 「ATM ID」「Transaction ID」「Account ID」「Transaction Type」「Transaction Amount」の順でデータが縦に並んでいる
-
加工後

- 横に展開して整形
処理の流れとしては以下となります。
- 同じトランザクションデータを識別するための「Group」列を追加
- GroupごとにレコードIDを付与
- ヘッダー情報を作成しレコードIDを付与
- トランザクションデータにヘッダー情報を付与
- 縦に並んだデータを横に展開
- ATM ID、Transaction IDを大文字に統一
具体的な内容は以下のとおりです。
-
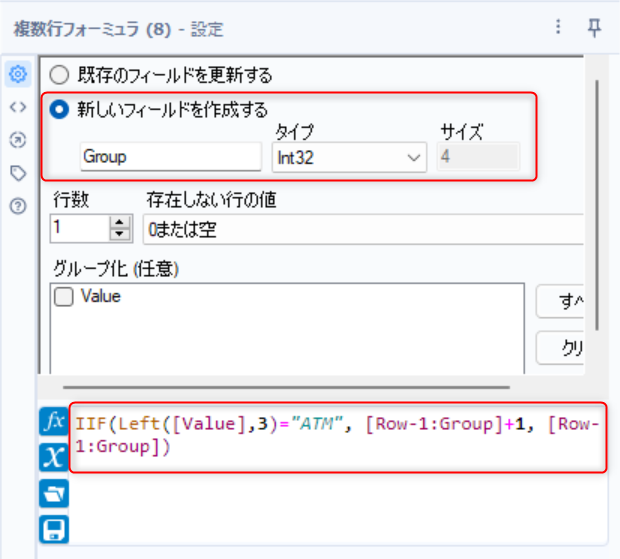
同じトランザクションデータを識別するための「Group」列を追加
-
複数行フォーミュラを使用
-
新しいフィールドを作成し、フィールド名に「Group」を入力
-
式エディタに式を入力
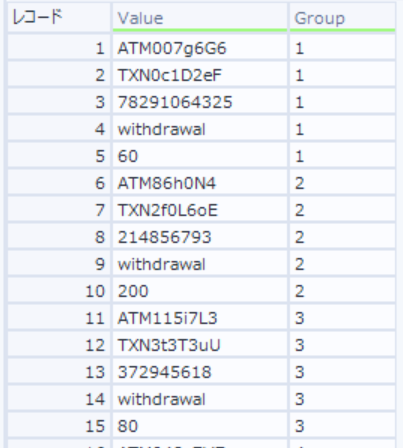
- IIF(Left([Value],3)="ATM", [Row-1:Group]+1, [Row-1:Group])
- 先頭3文字が「ATM」なら1つ前の行のGroupをカウントアップ、そうでなければ1つ前の行のGroupの値を設定
-
この時点のデータは以下のとおり(Group列が追加されている)
-
-
GroupごとにレコードIDを付与
-
レコードIDツールを使用
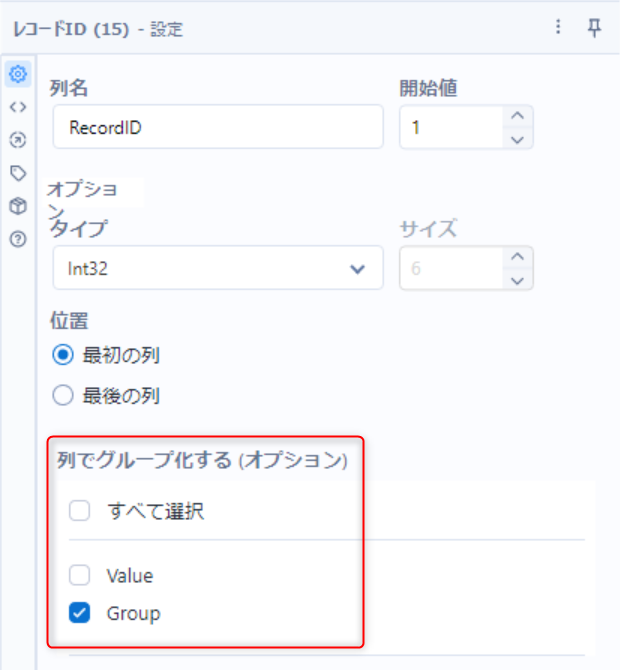
-
Group列でグループ化
-
この時点データは以下のとおり(RedordID列が追加されている)
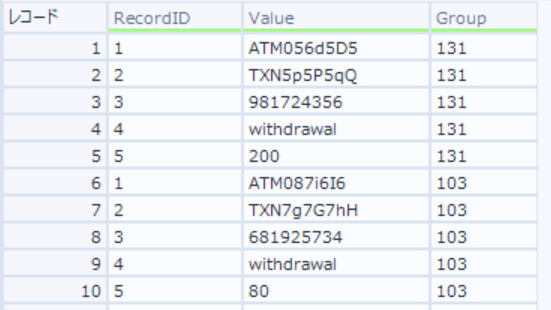
-
-
ヘッダー情報を作成しレコードIDを付与
-
テキスト入力ツールとレコードIDツールを使用
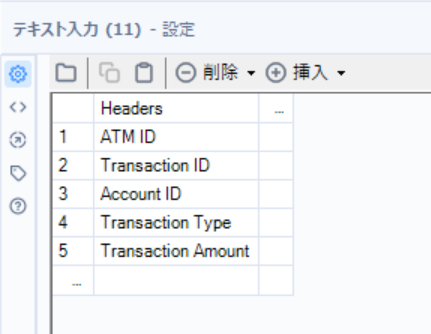
-
レコードIDを付与したあとのデータは以下のとおり
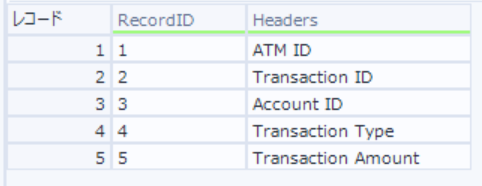
-
-
トランザクションデータにヘッダー情報を付与
-
結合ツールを使用
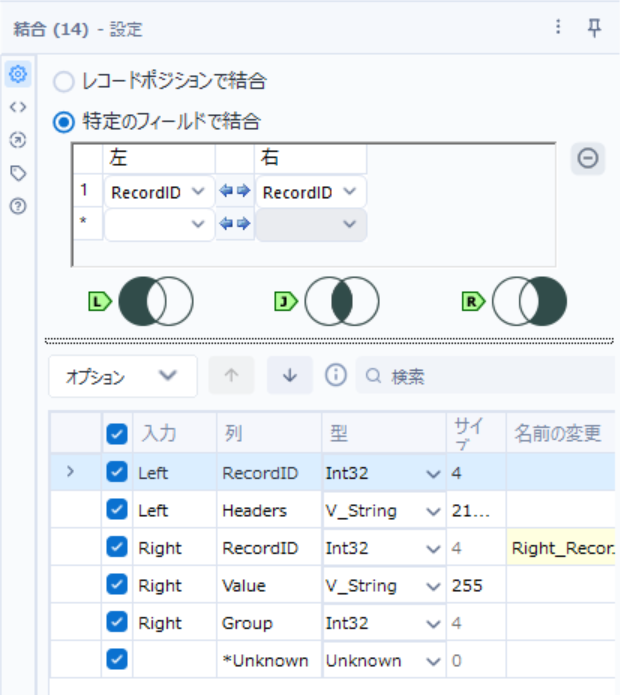
- レコードIDをキーに結合
-
この時点データは以下のとおり
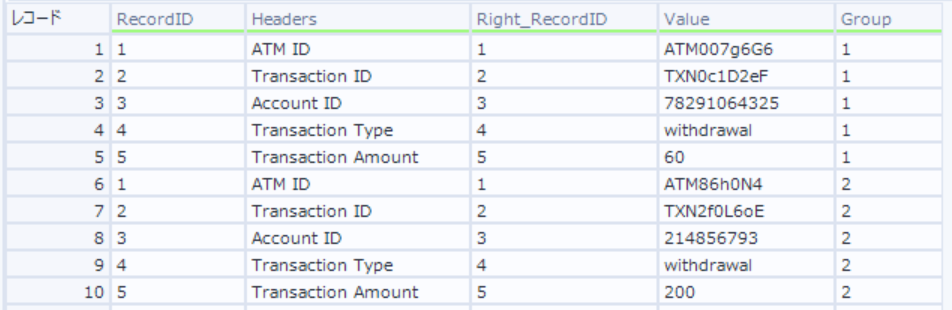
- トランザクションデータにヘッダー情報が紐付いていることを確認
-
-
縦に並んだデータを横に展開
-
クロスタブツールを使用
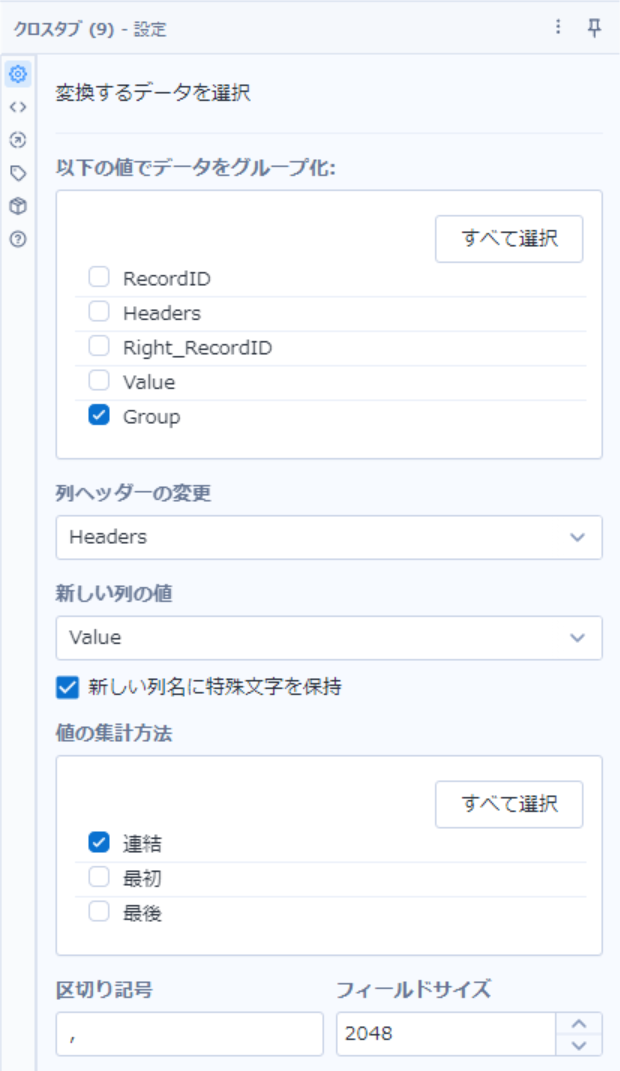
- グループ化:Group
- 列ヘッダー:Headers
- 値:Value
- 集計方法:連結
- 「新しい列名に特殊文字を保持」にチェックを入れる
- 「ATM ID」のようにヘッダーに指定した文字列に空白などの特殊文字が含まれている場合、アンダースコアに置き換えられることを防ぐことができる
-
この時点データは以下のとおり

- Groupで1行に展開され、特殊文字もそのまま列ヘッダーとなっている
-
-
ATM ID、Transaction IDを大文字に統一
-
複数フィールドフォーミュラツールを使用
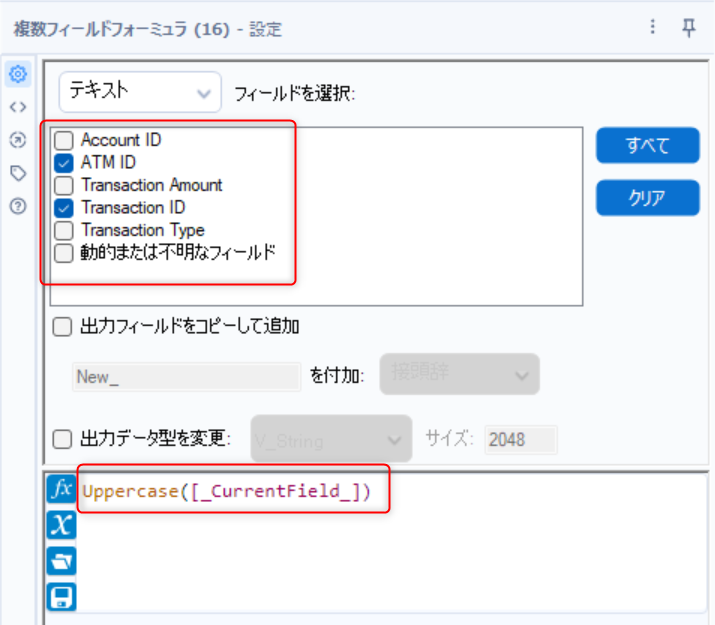
-
加工対象の列:ATM ID、Transaction ID
-
式エディタに式を入力
- Uppercase([_CurrentField_])
- Uppercase:大文字化する関数
- [_CurrentField_]:加工対象の列を意味する
- Uppercase([_CurrentField_])
-
■ ATM所有銀行データ加工
いちばん下のコンテナ内の処理です。
「Bank ID」の1行目に銀行名が入力されており、次の行以降はその銀行に属するATMであり、別の銀行に属するATMが出てきた場合新しい銀行名がBank IDに入っているという構造になっていますので、銀行名がNullの場合は直前の行の値を引き継ぐという処理が必要になります。
-
加工前
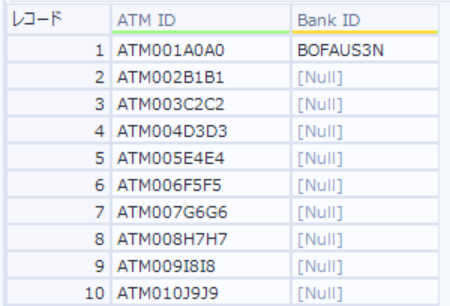
-
加工後
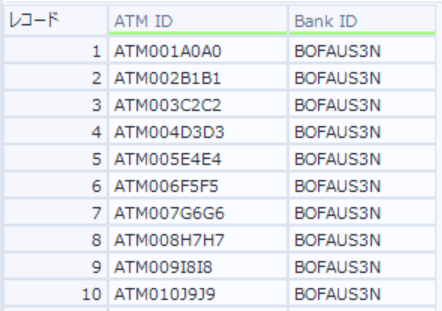
このような場合は複数行フォーミュラツールを使用します。
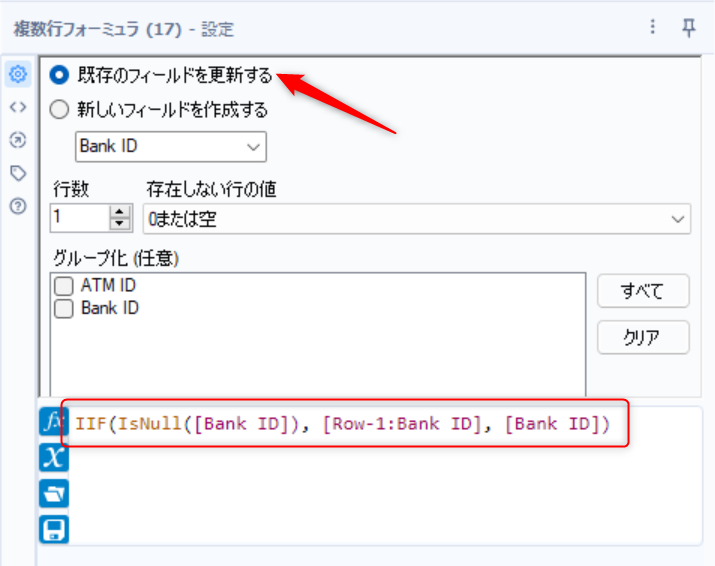
- 既存のフィールドを更新するを選択
- 式エディタに式を入力
- IIF(IsNull([Bank ID]), [Row-1:Bank ID], [Bank ID])
- 「Bank ID」がNullなら1つ前の行のBank IDを設定、そうでなければアクティブ行のBank IDを設定
これで加工後の状態になり出力されます。
■ データ結合
真ん中のコンテナ内の処理です。
整形済の3つのデータ(ATM情報、トランザクション情報、銀行情報)を複数結合ツールを使用し結合します。
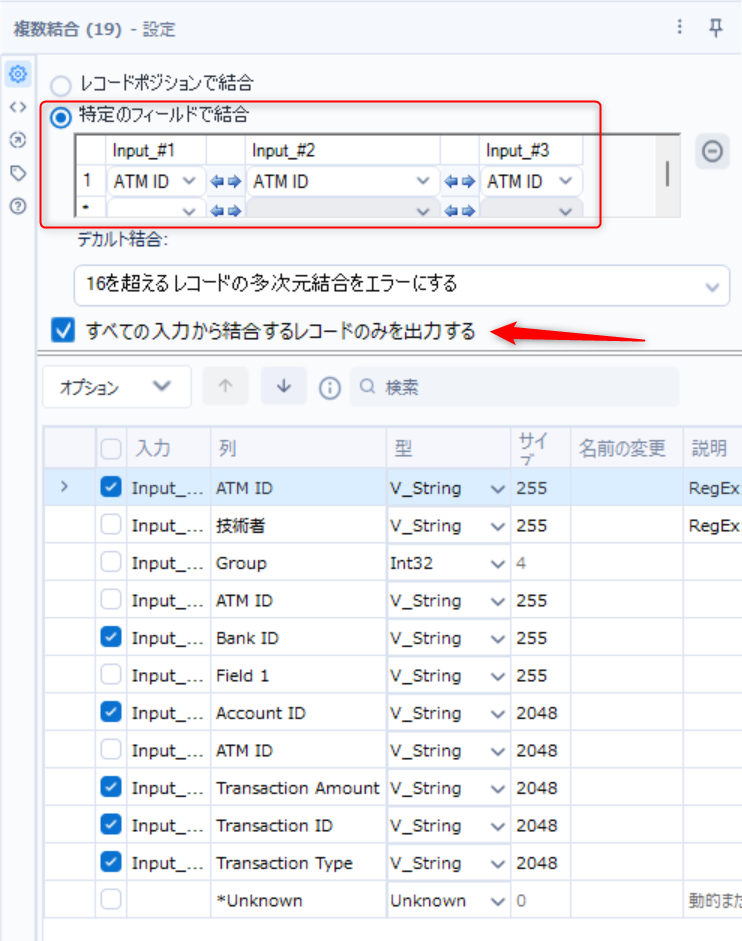
- ATM IDをキーに結合
- 「すべての入力から結合するレコードのみを出力する」にチェック
- 不要な列は除外
■ 対象データ集計
いちばん右のコンテナ内の処理です。
フィルターツールを使用し「2024年2月」のデータのみを抽出し、集計ツールで銀行ごとのトランザクション数や平均金額を集計します。
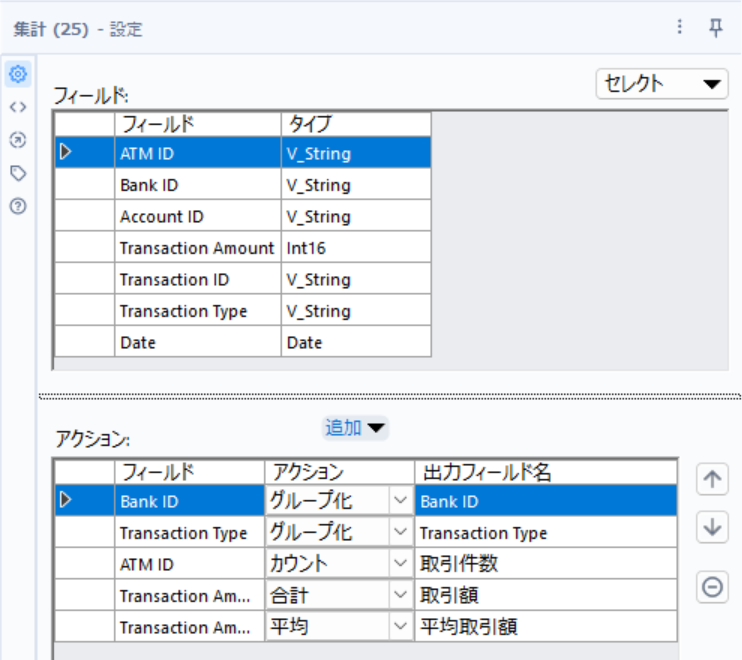
以上が一連の処理の流れになります。
さいごに
正規表現はなかなか理解が難しく使いこなせずにいる方も多いのではないでしょうか。
正規表現を設定する際、エディタの右にある「+」をクリックすると記号やメタ文字の意味を確認することができ、入力をアシストしてくれます。
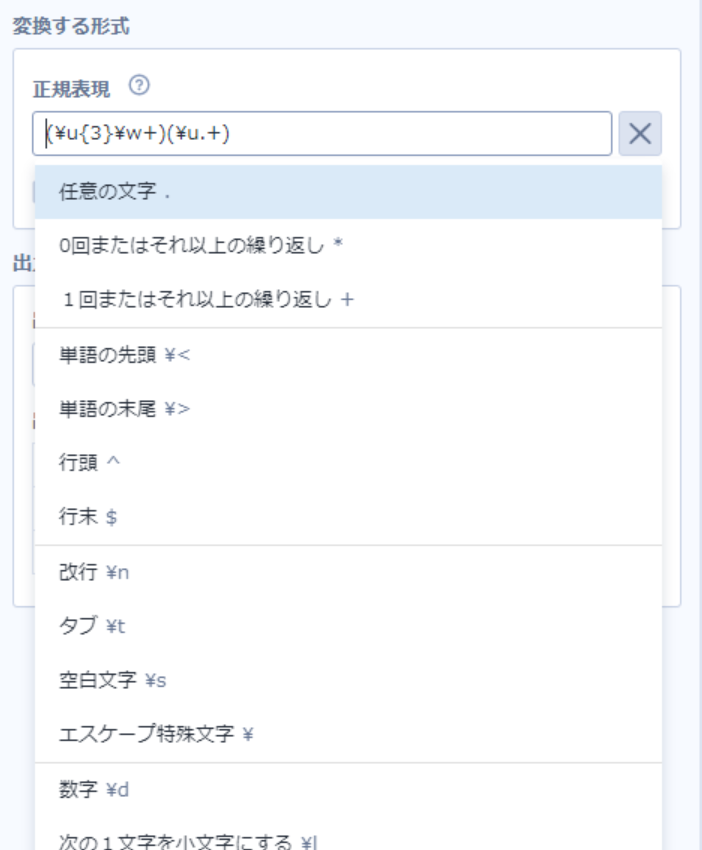
これを参考に設定したり、正規表現自体は様々な言語やツールなどでも使用されるものですので、記述方法をWeb検索してみたり、また最近では生成AIを利用して作ってもらうのも良い方法です。
ぜひ使いこなしていただき、より効率的な処理方法を身につけていただければと思います!










