![[アップデート] Amazon Bedrock に評価サンプルを使ってプロンプトを自動で最適化してくれて複数モデルの比較もできる Advanced Prompt Optimization が追加されたので使ってみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e3065182082062711612153bbdcf1d96/c04359de689df2f56eb066576ab63fb5/amazon-bedrock?w=3840&fm=webp)
[アップデート] Amazon Bedrock に評価サンプルを使ってプロンプトを自動で最適化してくれて複数モデルの比較もできる Advanced Prompt Optimization が追加されたので使ってみた
いわさです。
Amazon Bedrock にはプロンプトの最適化機能がありまして、2025 年 4 月に GA されています。
ただ、この従来の最適化機能は、単一のプロンプトを1つのモデル向けに書き換えるだけのもので、評価データを使った反復的な改善や複数モデルの比較はできませんでした。
今回のアップデートで、評価サンプルを使って反復的にプロンプトを最適化する「Advanced Prompt Optimization」が追加されました。
おそらくですが今回の新機能のリリースによって前述の従来の最適化機能は Simple Optimization と呼ばるようになったみたいです。
公式ドキュメントによると、想定されるシナリオは大きく2つあるみたいです。
Advanced Prompt Optimization (AdvPO) allows you to optimize your prompts for any model on Bedrock while comparing your original prompts to optimized prompts across up to 5 models simultaneously. You can use this if you are migrating to a new model or just want to get better performance on your current model.
- 現行モデルでの性能向上: 同じモデルのまま、プロンプトを最適化してレスポンスのスコアを上げる
- モデル移行: 現行モデルをベースラインとして、移行候補のモデルと並べてスコア・レイテンシ・コストを比較する
今回こちらを確認してみたので紹介します。
実際に使ってみる
今回は上記の2つのシナリオをそれぞれ検証してみました。東京リージョンです。
- シナリオ1(性能向上): 同じモデル(Claude Sonnet 4)でプロンプトを最適化し、スコアがどう変わるか確認
- シナリオ2(モデル移行): Claude 3.5 Sonnet v2 をベースラインとして、Claude Sonnet 4 と Nova Pro への移行を比較
入力データセットの準備
Advanced Prompt Optimization では JSONL 形式の入力ファイルを S3 に用意する必要があります。
1行が1つのプロンプトテンプレートに対応し、以下の要素をまとめて記述します。
promptTemplate: 最適化対象のプロンプト。{{変数名}}でプレースホルダーを定義するevaluationSamples: 評価用のサンプルデータ。inputVariablesにプレースホルダーに入れる値、referenceResponseに期待する回答を書くsteeringCriteria: 最適化の方向性を短い自然言語で指定する(評価方法の1つ。後述)
シナリオ1では「テキスト要約」タスクのプロンプトを用意しました。
意図的にシンプルなプロンプト(「以下のテキストを要約してください」)にして、最適化による改善が見えやすいようにしています。
{
"version": "bedrock-2026-05-14",
"templateId": "hoge-summary-v1",
"promptTemplate": "以下のテキストを要約してください。\n\nテキスト: {{text}}\n\n要約:",
"steeringCriteria": [
"CONCISE",
"ACCURATE",
"要約は原文に含まれる主要なポイントをすべて含み、原文にない情報を追加しないこと"
],
"evaluationSamples": [
{
"inputVariables": [
{
"text": "Amazon S3はオブジェクトストレージサービスで、業界をリードするスケーラビリティ、データ可用性、セキュリティ、パフォーマンスを提供します。あらゆる規模や業種のお客様がAmazon S3を使用して、データレイク、ウェブサイト、モバイルアプリケーション、バックアップとリストア、アーカイブ、エンタープライズアプリケーション、IoTデバイス、ビッグデータ分析など、さまざまなユースケースのデータを保存・保護できます。Amazon S3は管理機能を提供しており、特定のビジネス、組織、コンプライアンスの要件に合わせてデータへのアクセスを最適化、整理、設定できます。"
}
],
"referenceResponse": "Amazon S3はスケーラブルなオブジェクトストレージサービスです。データレイク、ウェブサイト、モバイルアプリ、バックアップ、アーカイブ、ビッグデータ分析などのユースケースに対応し、アクセス制御やコンプライアンスのための管理機能を備えています。"
},
{
"inputVariables": [
{
"text": "AWS Lambdaはサーバーレスコンピューティングサービスで、サーバーのプロビジョニングや管理なしにコードを実行できます。Lambdaは高可用性のコンピューティングインフラストラクチャ上でコードを実行し、サーバーとオペレーティングシステムのメンテナンス、キャパシティのプロビジョニングと自動スケーリング、ログ記録など、コンピューティングリソースのすべての管理を行います。Lambdaでは、Lambdaがサポートする言語ランタイムのいずれかでコードを提供するだけで済みます。コードをLambda関数に整理します。Lambdaサービスは必要な場合にのみ関数を実行し、自動的にスケーリングします。消費したコンピューティング時間に対してのみ課金され、コードが実行されていないときは料金が発生しません。"
}
],
"referenceResponse": "AWS Lambdaはサーバーレスコンピューティングサービスで、サーバー管理なしにコードを実行できます。インフラストラクチャ、スケーリング、ログ記録を自動的に処理し、実際に使用したコンピューティング時間に対してのみ課金されます。"
},
{
"inputVariables": [
{
"text": "Amazon DynamoDBはフルマネージドのNoSQLデータベースサービスで、シームレスなスケーラビリティとともに高速で予測可能なパフォーマンスを提供します。DynamoDBを使用すると、分散データベースの運用とスケーリングに伴う管理上の負担を軽減できるため、ハードウェアのプロビジョニング、セットアップと設定、レプリケーション、ソフトウェアパッチ適用、クラスタースケーリングについて心配する必要がありません。DynamoDBは保管時の暗号化も提供しており、機密データの保護に伴う運用上の負担と複雑さを排除します。"
}
],
"referenceResponse": "Amazon DynamoDBはフルマネージドのNoSQLデータベースで、高速なパフォーマンスとシームレスなスケーラビリティを提供します。プロビジョニング、設定、レプリケーション、パッチ適用などの管理タスクをすべて処理し、保管時の暗号化によるデータ保護も備えています。"
}
]
}
シナリオ2では「コードレビュー」タスクを用意しました。
SQLインジェクションやパストラバーサルなど明確なセキュリティ問題を含むコードを評価サンプルとして用意し、モデル間の検出能力の差が出やすいようにしています。
{
"version": "bedrock-2026-05-14",
"templateId": "hoge-code-review-v1",
"promptTemplate": "以下のコードをレビューして、バグ、セキュリティ上の問題点、改善案を指摘してください。\n\nコード:\n{{code}}\n\nレビュー結果:",
"steeringCriteria": [
"すべてのバグとセキュリティ問題を特定すること",
"具体的な修正コードを提示すること",
"問題の深刻度を明示すること"
],
"evaluationSamples": [
{
"inputVariables": [
{
"code": "import json\n\ndef handle_request(event):\n user_id = event['queryStringParameters']['user_id']\n query = f\"SELECT * FROM users WHERE id = {user_id}\"\n result = db.execute(query)\n return {\n 'statusCode': 200,\n 'body': json.dumps(result)\n }"
}
],
"referenceResponse": "問題点:\n1. SQLインジェクション脆弱性(深刻度:高): user_idがSQL文に直接埋め込まれています。パラメータ化クエリを使用してください。\n2. 入力値の検証なし(深刻度:中): queryStringParametersやuser_idがNoneの場合にKeyErrorが発生します。\n3. エラーハンドリングなし(深刻度:中): db.executeの失敗時にクラッシュします。\n4. SELECT *の使用(深刻度:低): 必要なカラムのみ選択してください。"
},
{
"inputVariables": [
{
"code": "const express = require('express');\nconst app = express();\n\napp.get('/api/files', (req, res) => {\n const filename = req.query.name;\n const filepath = '/data/' + filename;\n const content = fs.readFileSync(filepath, 'utf8');\n res.send(content);\n});\n\napp.listen(3000);"
}
],
"referenceResponse": "問題点:\n1. パストラバーサル脆弱性(深刻度:高): ユーザー入力のfilenameがそのままファイルパスに結合されています。\n2. fsモジュール未インポート(深刻度:高): fs.readFileSyncを使用していますがfsのrequireがありません。\n3. 同期的ファイル読み込み(深刻度:中): readFileSyncはイベントループをブロックします。\n4. エラーハンドリングなし(深刻度:中): ファイルが存在しない場合にサーバーがクラッシュします。"
},
{
"inputVariables": [
{
"code": "import hashlib\n\ndef authenticate(username, password):\n stored_hash = get_user_hash(username)\n input_hash = hashlib.md5(password.encode()).hexdigest()\n if input_hash == stored_hash:\n return True\n return False\n\ndef create_session(user):\n token = str(user['id']) + str(time.time())\n return token"
}
],
"referenceResponse": "問題点:\n1. 脆弱なハッシュアルゴリズム(深刻度:高): MD5は暗号学的に破られており、パスワードハッシュには不適切です。\n2. ソルトなし(深刻度:高): レインボーテーブル攻撃に脆弱です。\n3. 予測可能なセッショントークン(深刻度:高): ユーザーID+タイムスタンプで容易に推測可能です。\n4. timeモジュール未インポート(深刻度:低)\n5. タイミング攻撃脆弱性(深刻度:中): ==での文字列比較はタイミング情報が漏洩します。"
}
]
}
なお、実際の入力ファイルは JSONL 形式(1行1オブジェクト)で記述する必要があります。
上記は可読性のために整形していますが、S3 にアップロードするファイルは改行なしの1行にまとめたものです。
評価方法について補足します。
Advanced Prompt Optimization では、プロンプトの最適化をどの方向に進めるかを指定する「評価方法」を選べます。
今回は steeringCriteria を使いました。これは JSONL の中に短い自然言語で「こういう方向に最適化してほしい」という方針を書くものです。
上の例だと "CONCISE", "ACCURATE" や "すべてのバグとセキュリティ問題を特定すること" がそれにあたります。
公式ドキュメントによると、他にも以下の評価方法が選べるとのこと。
- デフォルト(何も指定しない): サービス側が用意した AI モデル(Claude Sonnet 4.6)が「正確性」「網羅性」「表現の質」の3軸で 0〜3 点を付け、正規化して 0〜1 のスコアにする
- Steering criteria(今回使用): 短い自然言語で最適化の方向性を指定する。最大5つまで。指定した基準に沿って AI が採点する
- カスタム LLM-as-a-judge: 自分で評価プロンプト(採点基準)を書いて、AI モデルに採点させる。「こういう観点で何点」を細かく定義したい場合に使う
- Lambda 関数: 独自のロジックで評価したい場合に Lambda 関数を指定する
手軽に試すなら steering criteria かデフォルトが簡単そうです。
これらの JSONL ファイルを S3 にアップロードしておきました。
シナリオ1:性能向上(同一モデルでの最適化)
Bedrock コンソールの左メニュー「構築」配下に「Advanced Prompt Optimization」が追加されています。
「New」のラベルが付いていますね。
「Create prompt optimization」からジョブを作成します。
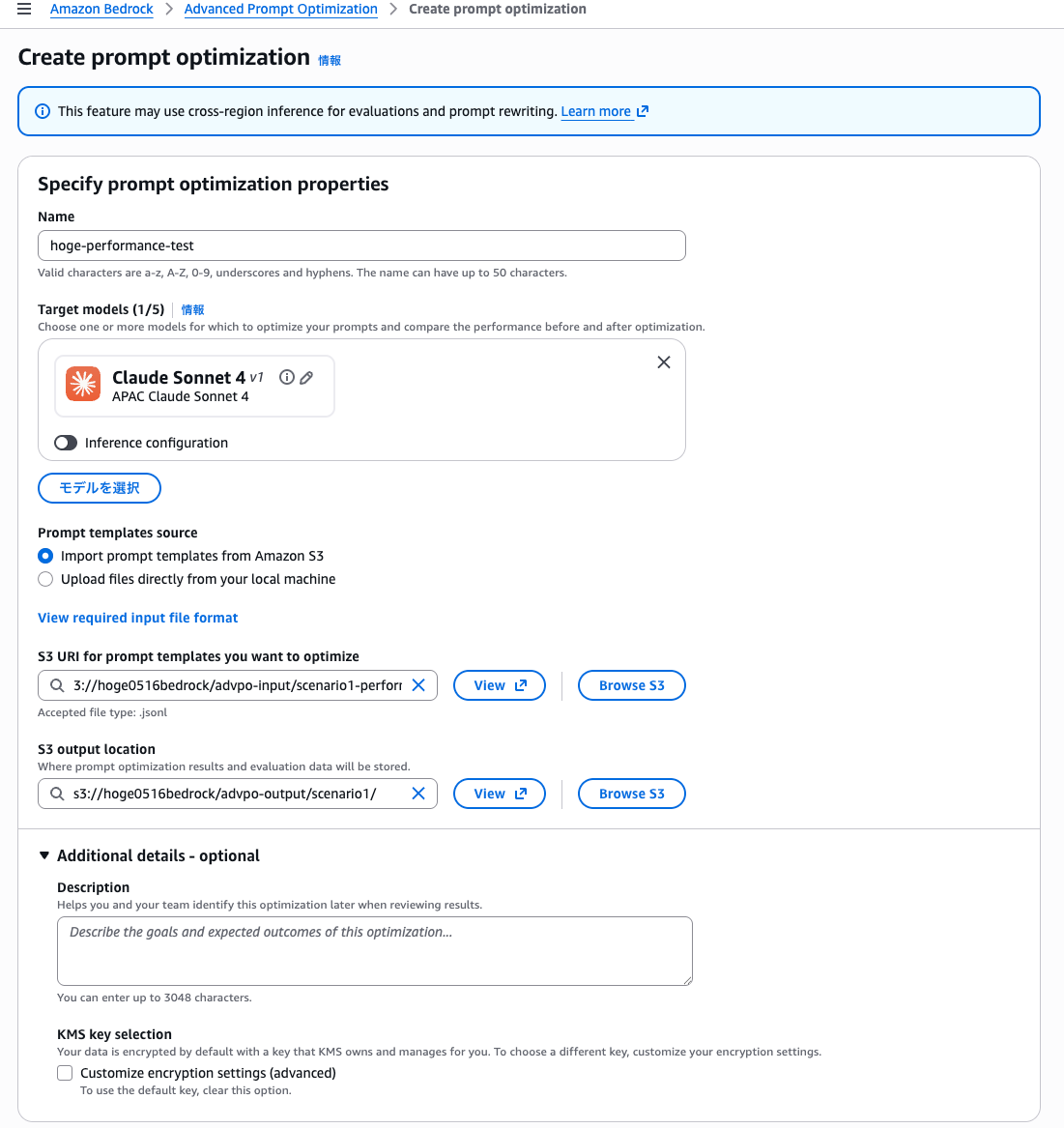
まずシナリオ1から。
ジョブ名を入力し、ターゲットモデルとして Claude Sonnet 4 を1つだけ選択しました。
「モデルを選択」ボタンを押すとモデル選択ダイアログが表示されます。
Inference configuration を ON にすると、トークン上限や Temperature などの調整ができるみたいです。今回は使わなかった。
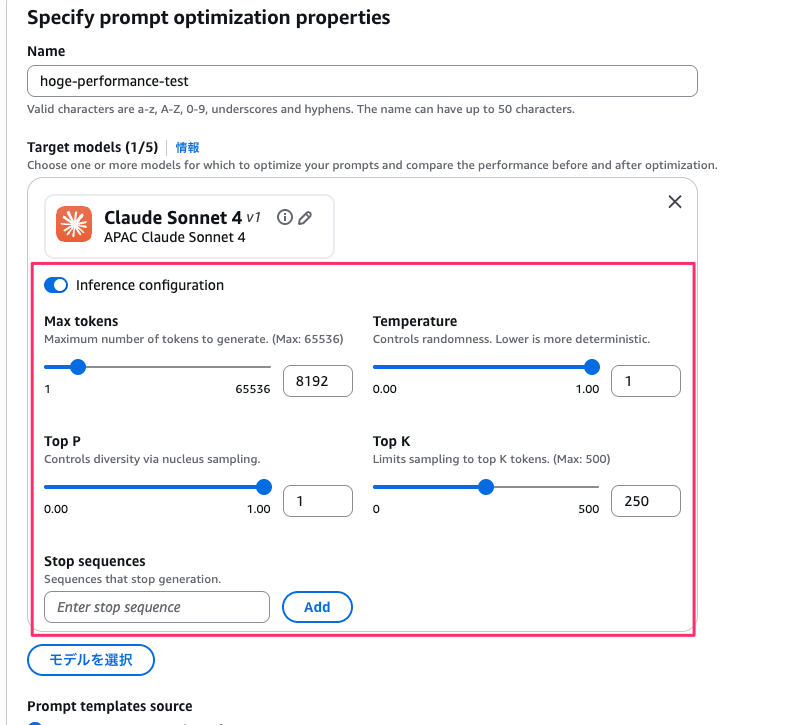
入力ファイルは S3 からのインポートとローカルからのアップロードの2つが選べます。
今回は S3 にアップロード済みなので「Import prompt templates from Amazon S3」を選択し、S3 URI と出力先を指定して「Create optimization」を押しました。
ジョブが作成されると一覧画面に遷移し、ステータスが「In progress」で表示されます。
小さいデータセットでも 15〜20 分程度かかるそうです。
14 分ほどでジョブが完了しました。
ジョブ名をクリックすると結果画面が表示されます。
Graphs / Summary tables / Detailed results の3つのタブで結果を確認できます。
まず Graphs タブ。
Quality Score が Original(最適化前)と Optimized(最適化後)で並べて表示されています。
この Quality Score は、先ほど指定した評価方法(今回は steering criteria)に沿って AI が採点したスコア(0〜1 に正規化されたもの)です。
referenceResponse(期待する回答)と実際のモデル出力を比較して採点され、最適化の反復ループの中でこのスコアが上がるようにプロンプトが書き換えられていく仕組みですね。
最適化されたことでスコアが改善されていることがわかります。
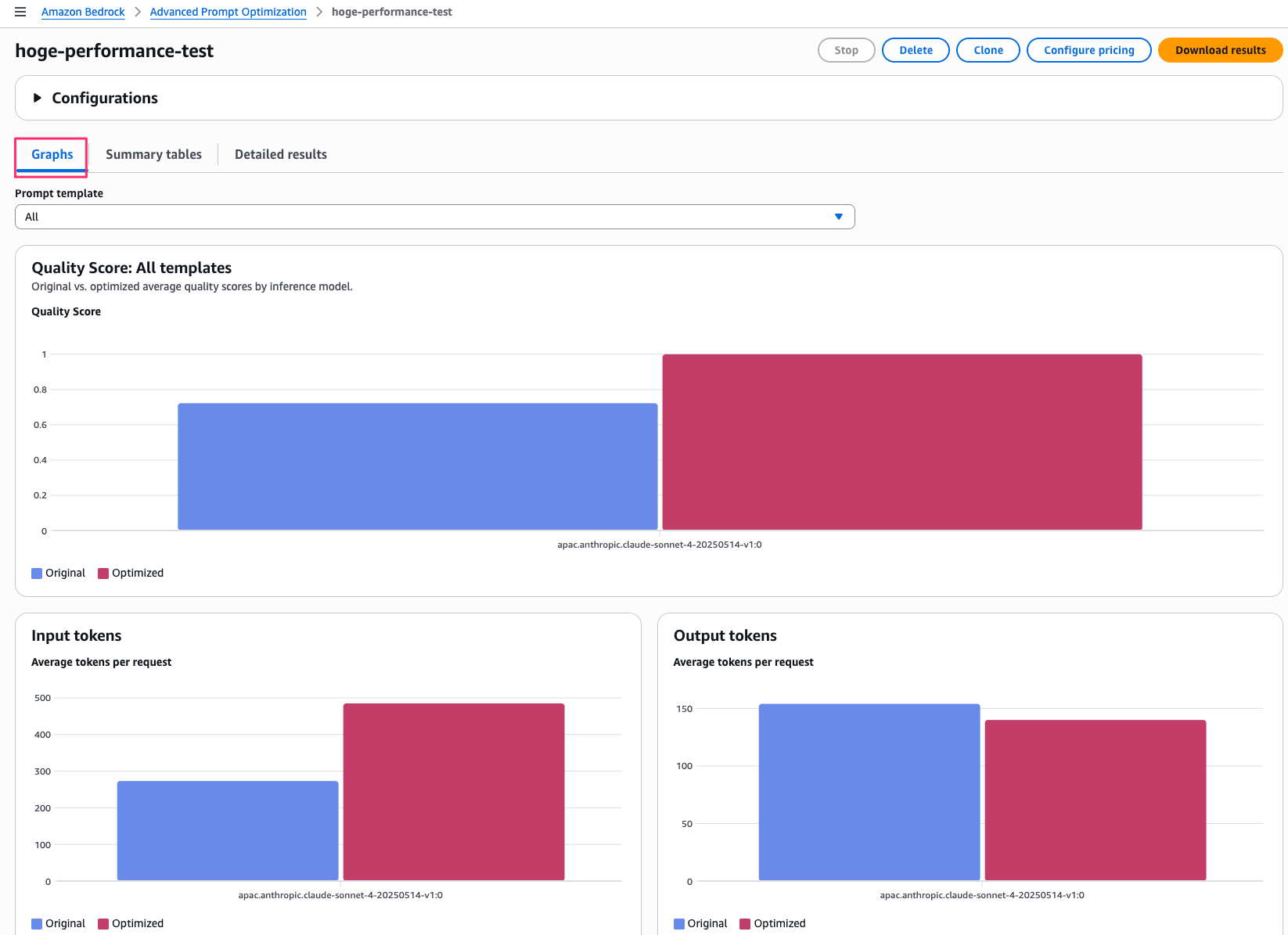
Input tokens / Output tokens / Cost optimization / TTFT(Time to First Token、最初のトークンが返ってくるまでの時間)の4つのグラフも表示されています。
最適化後はプロンプトが詳細になった分だけ入力トークンが増えていますが、TTFT はほぼ変わらずでした。
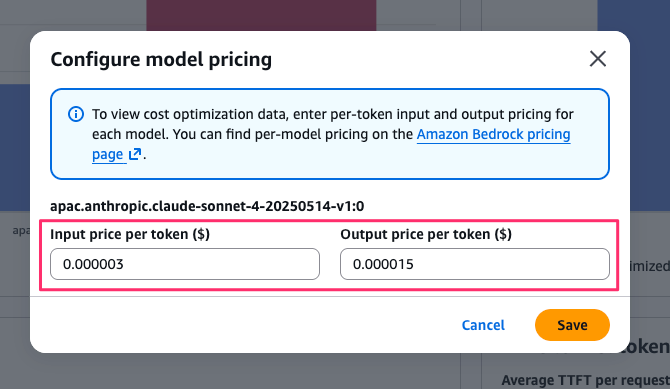
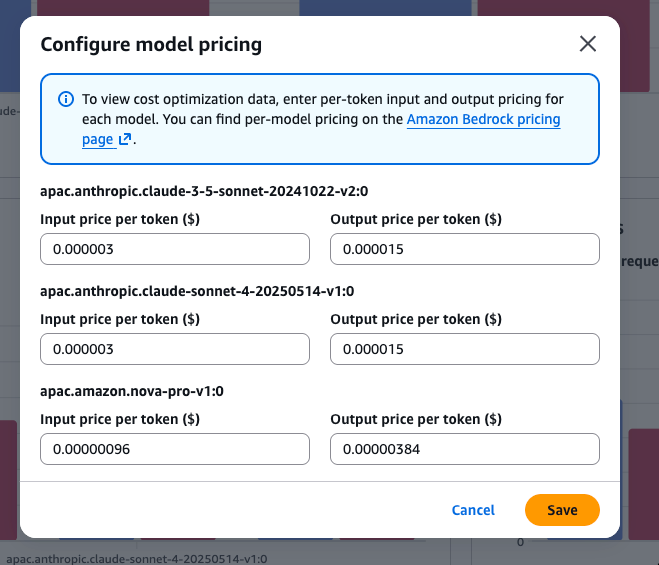
なお、Cost optimization のグラフはデフォルトでは「No pricing configured」と表示されます。
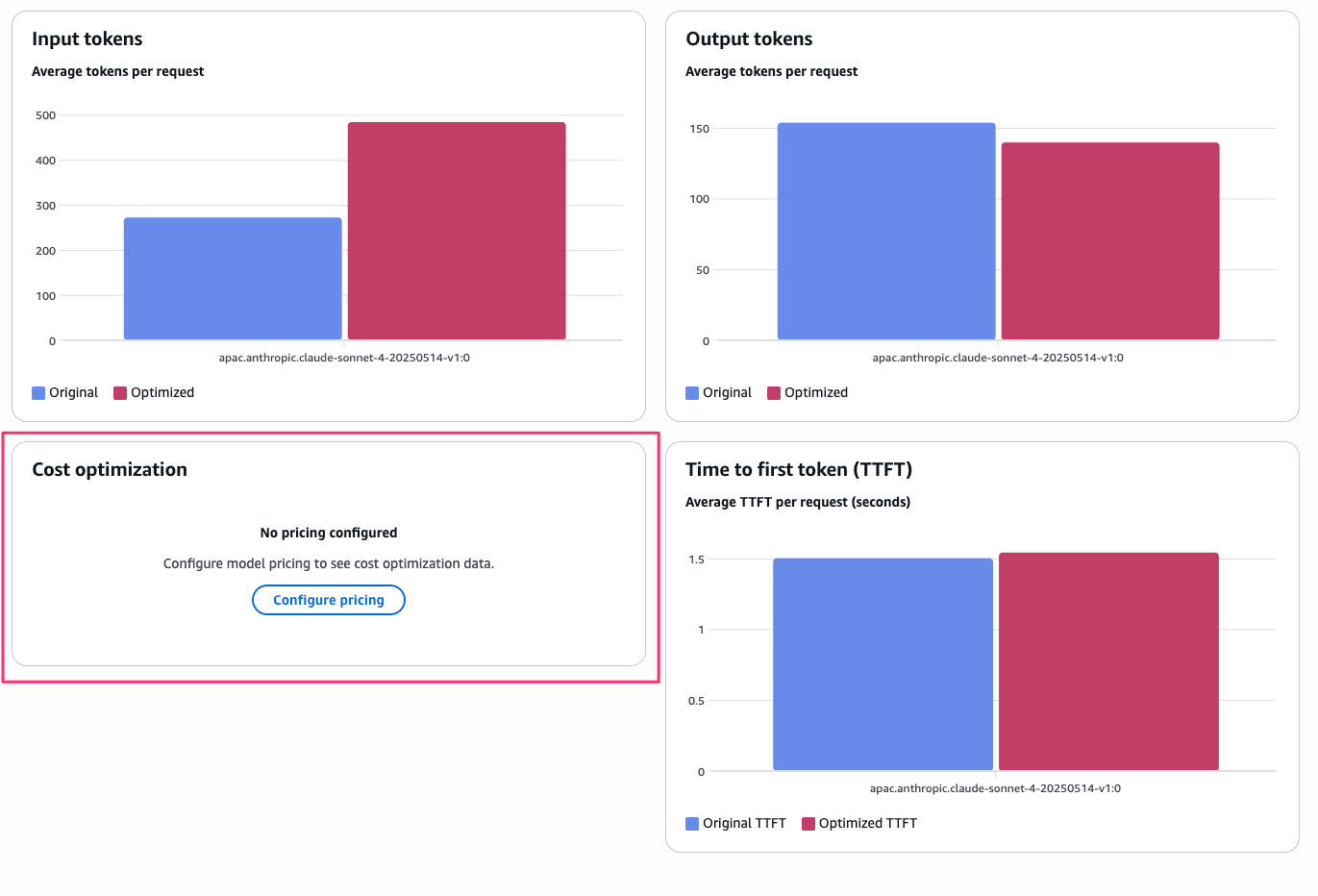
「Configure pricing」ボタンからトークン単価を手動で入力すると、リクエストあたりのコストが計算・表示される仕組みです。
次に Summary tables タブ。
テンプレートごとの最適化前後が一覧で確認できます。
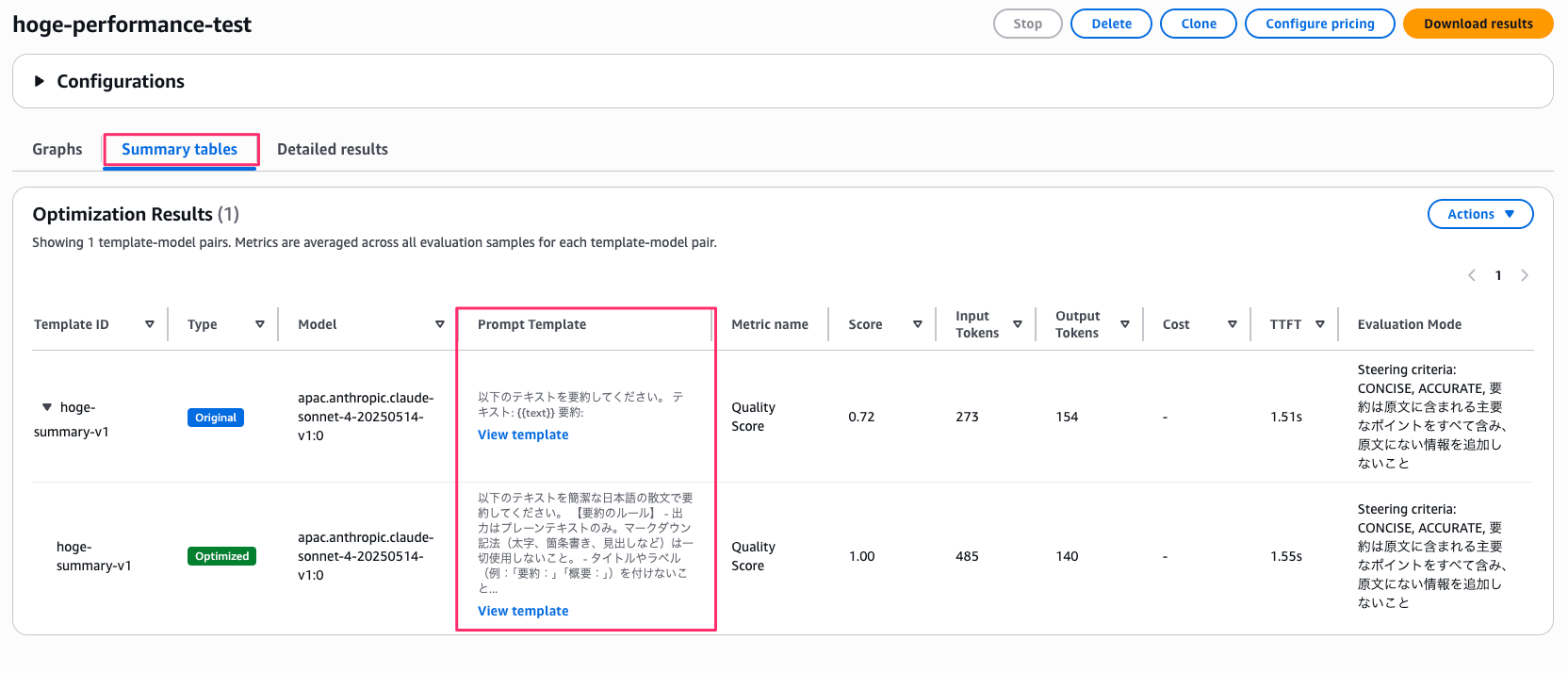
Quality Score が 0.72 → 1.00 に改善されています。
このスコア改善のためにプロンプトがどう変わったのかを確認してみます。
「View template」から確認すると、元の「以下のテキストを要約してください」というシンプルなプロンプトが、出力形式のルールや長さの目安を含む詳細なプロンプトに書き換えられていました。
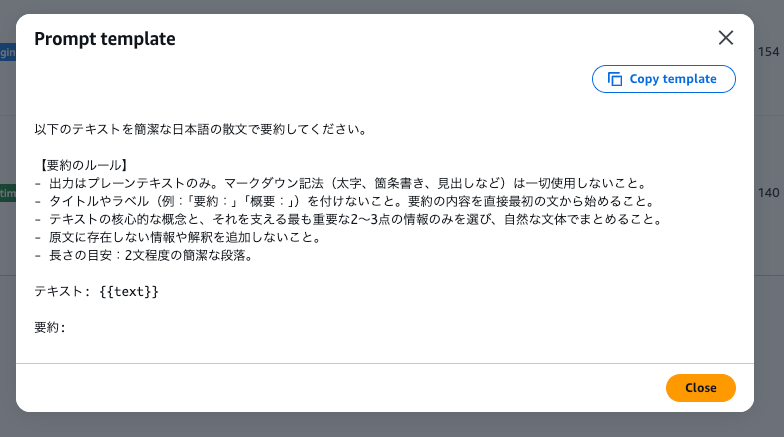
なるほど。今回 steering criteria で「CONCISE」「ACCURATE」「要約は原文に含まれる主要なポイントをすべて含み、原文にない情報を追加しないこと」と指定していましたが、その方針から具体的にどうすれば簡潔で正確になるかをルールとして生成してくれたみたいです。
ユーザーとしてはこの最適化後のプロンプトを自分のアプリケーションに適用すればスコアが上がる、ということになります。
「Copy template」ボタンでコピーできるので、そのまま使えます。
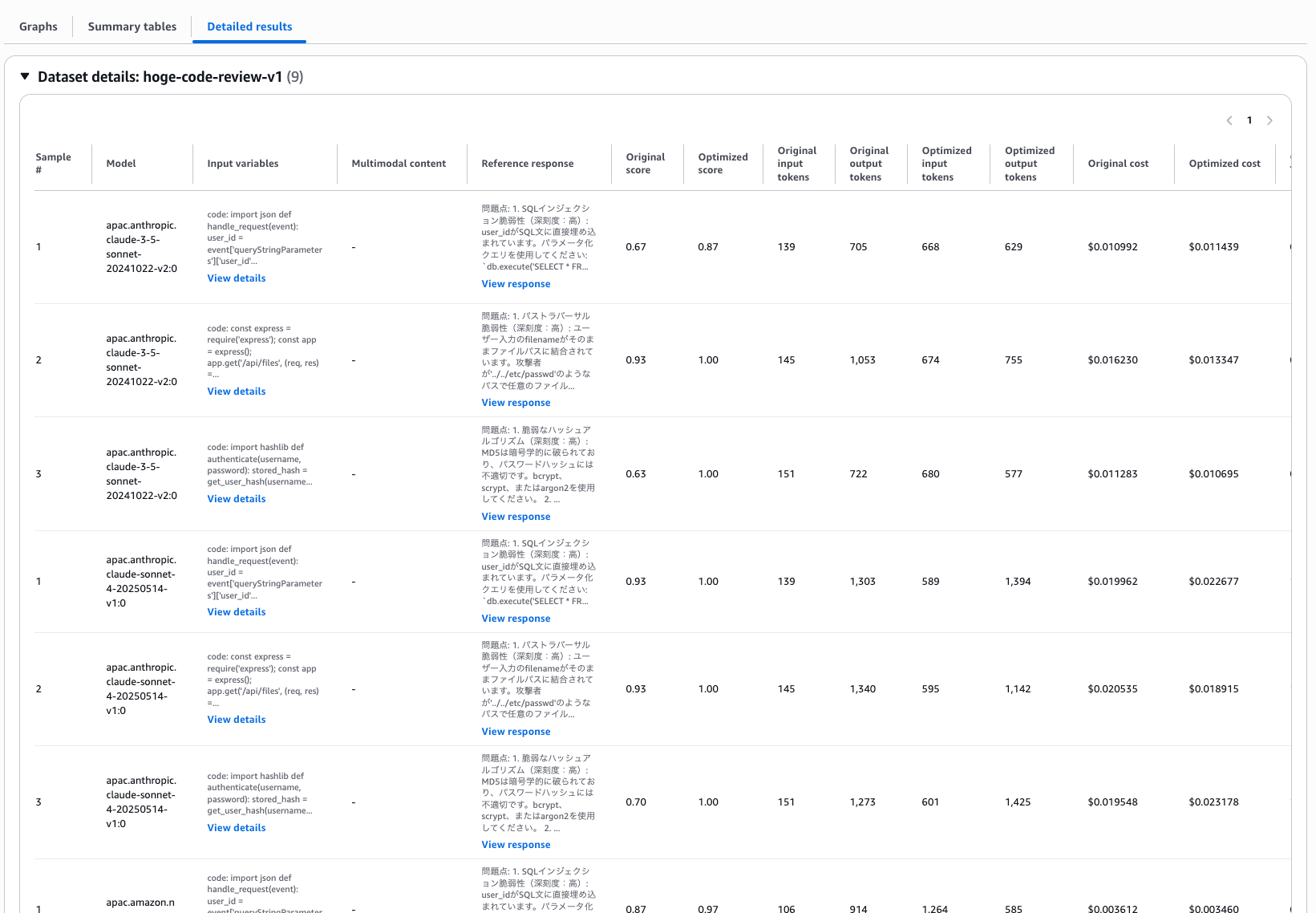
最後に Detailed results タブ。
各評価サンプルごとのスコアが確認できます。
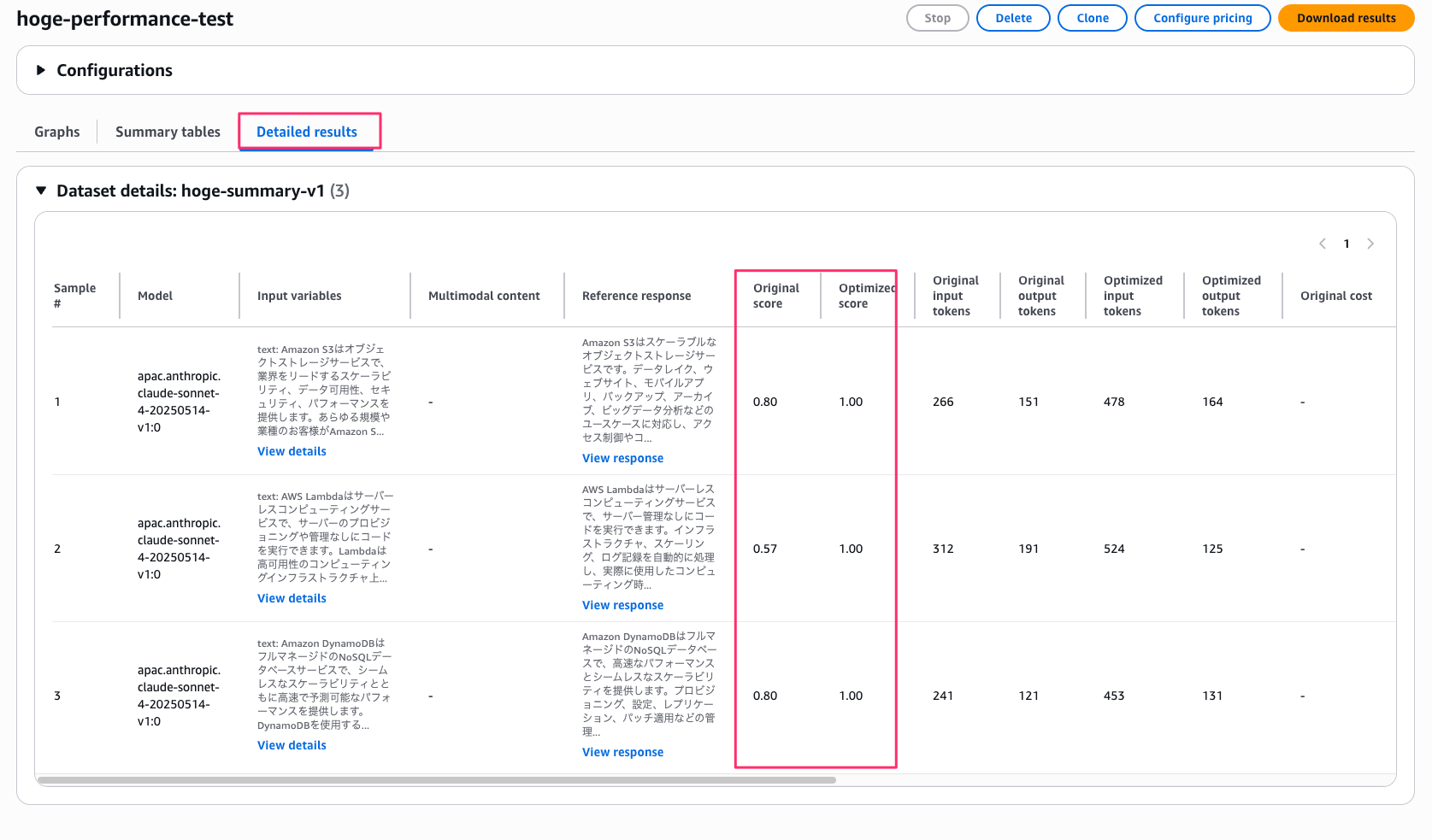
サンプルごとに個別のスコアが見えるので、特定の入力パターンでスコアが下がっていないかを確認できるのが良いですね。
シナリオ2:モデル移行(複数モデル比較)
続いてシナリオ2。
こちらは「モデルを移行しつつ、移行先のモデルに合わせてプロンプトも最適化する」というシナリオです。
単にモデルを切り替えた場合のスコア(Original)と、移行先モデル向けにプロンプトを最適化した場合のスコア(Optimized)の両方が確認できるので、「移行するだけ」と「移行 + プロンプト最適化」でどのくらい差が出るかがわかります。
ターゲットモデルを3つ選択しました。
- Claude 3.5 Sonnet v2(ベースライン)
- Claude Sonnet 4(移行候補1)
- Nova Pro(移行候補2)
こちらは 25 分ほどで完了しました。
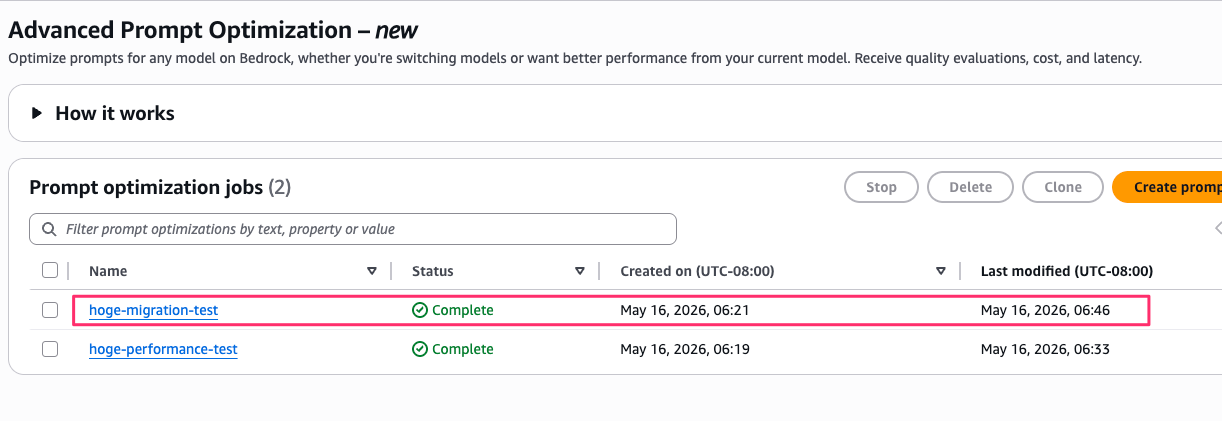
Graphs タブを見ると、3モデルの Quality Score が並んで表示されています。
どのモデルも最適化後にスコアが上がっていることがわかります。
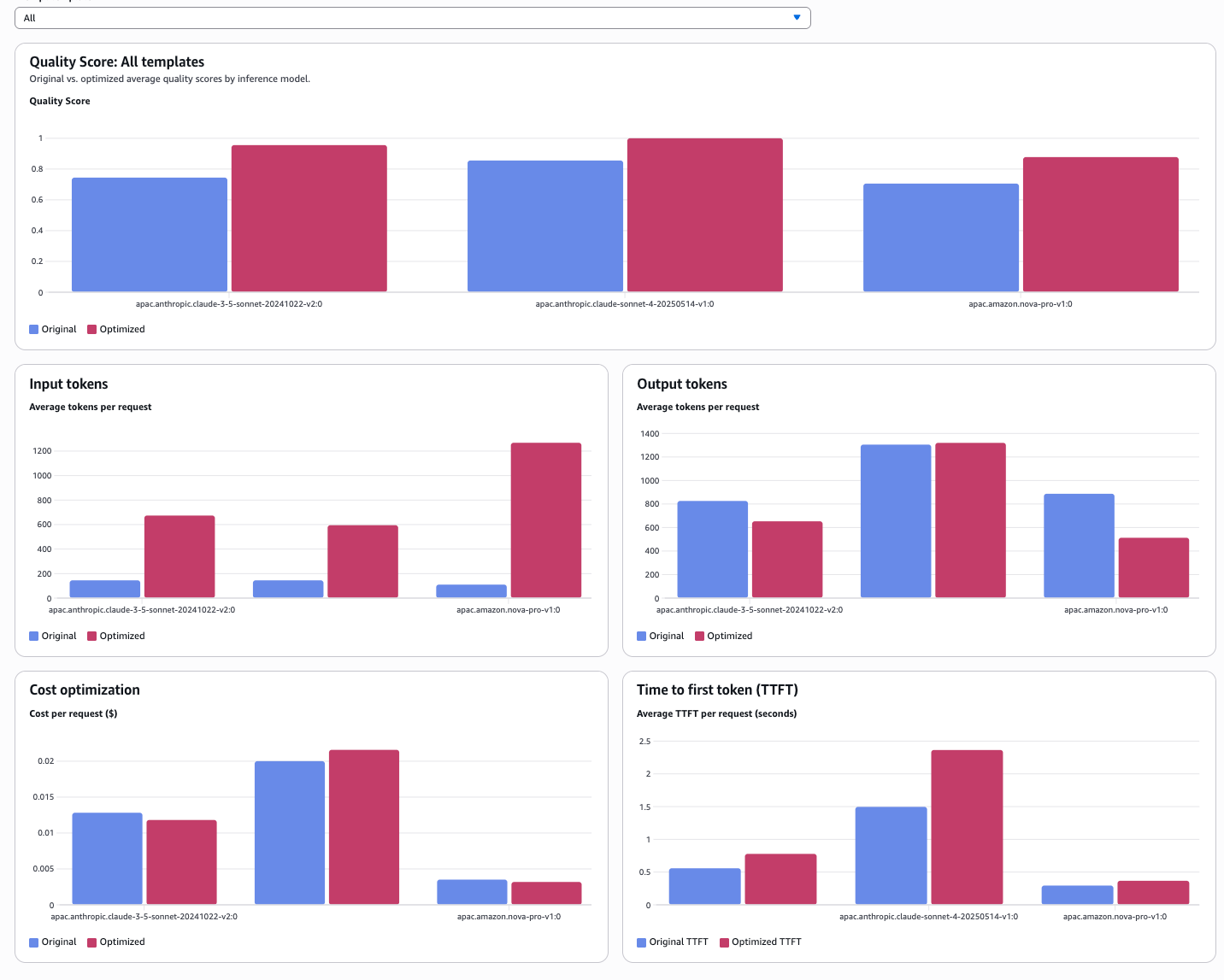
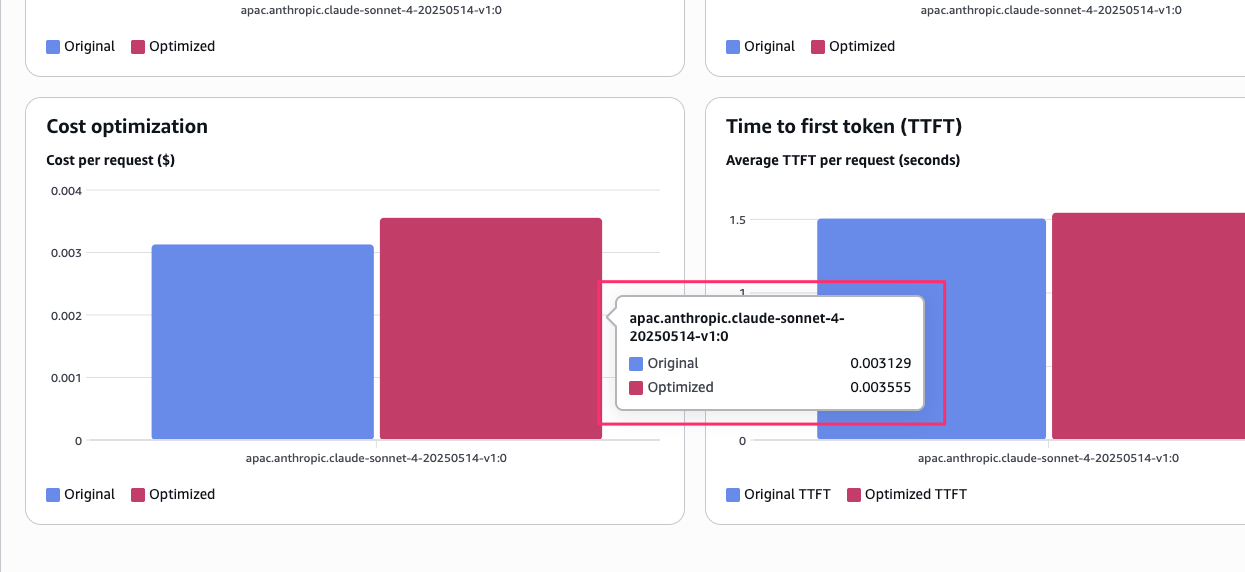
モデル移行の判断材料として面白いのは、スコアだけでなくコストと TTFT も並べて比較できる点です。
Nova Pro はコストと速度が圧倒的に良く、Claude Sonnet 4 はスコアが高い、という傾向がグラフで一目でわかります。
Configure pricing で各モデルの単価を入力すると、コスト比較のグラフも表示されます。
Summary tables タブで数値を確認してみます。
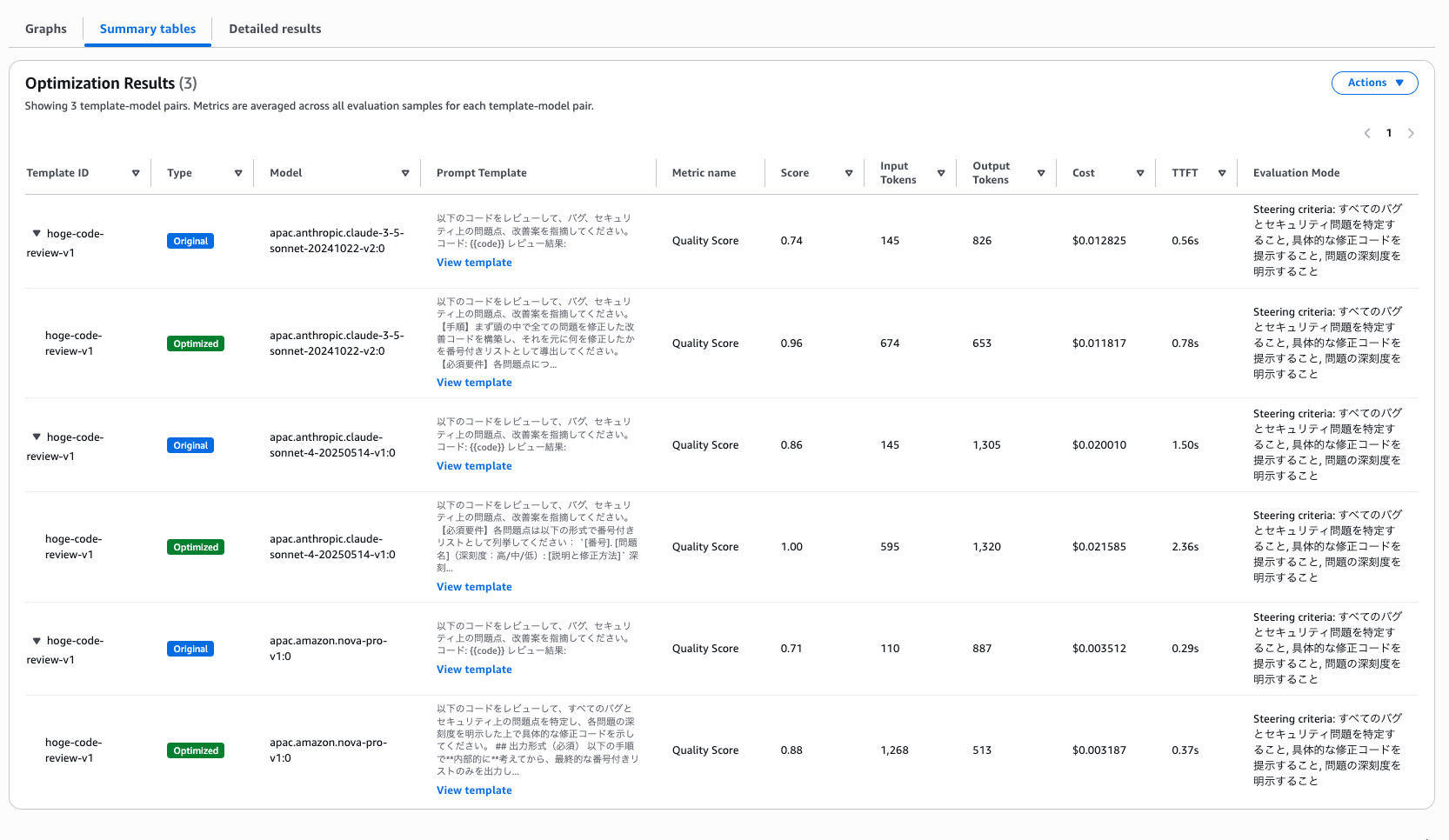
どのモデルもスコアが改善されていますが、最適化後のプロンプトが長くなる分 TTFT も増えています。
スコアを取るか、速度とコストを取るか、というトレードオフが数値で見えるのは移行判断に便利ですね。
ここで面白いのが、各モデル向けに最適化されたプロンプトの中身です。
それぞれの View template を確認していて気がついたのですが、モデルごとに最適化されたプロンプトが異なっていました。
Claude 3.5 Sonnet v2 のまま使うとしても出力形式の指定と出力例を追加することでプロンプト改善できますよって感じです。
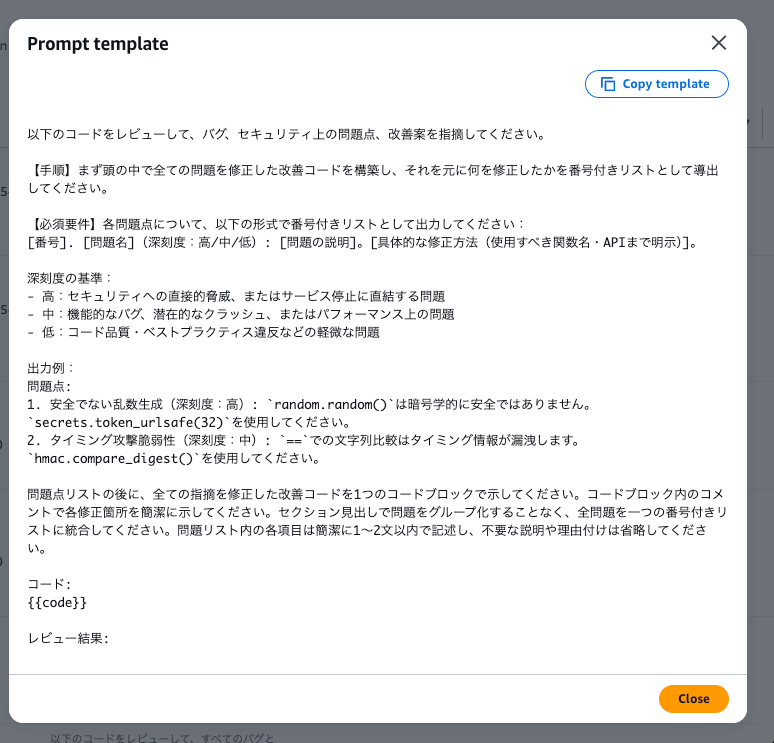
Nova Pro 向けはかなり詳細で、チェックすべきセキュリティ項目(ハッシュアルゴリズムの強度、パストラバーサル、タイミング攻撃...)が具体的にリストアップされてました。

Nova Pro はコストと速度に優れる分、具体的に「何をチェックすべきか」まで指示してあげるとスコアが上がるってことなのか。なるほどね。
モデルの特性に合わせてプロンプトの最適化のされ方を変えてくれるのはありがたい。
Detailed results タブではサンプルごとの個別スコアも確認できます。
特定の入力パターンでスコアが下がっていないかを確認するのに便利です。
マルチモーダル入力について
今回は検証していませんが、Advanced Prompt Optimization は画像(png、jpg)や PDF のマルチモーダル入力にも対応しているとのこと。
Advanced Prompt Optimization takes your prompt templates, evaluation samples, and an evaluation method, then runs iterative inference, evaluate, and rewrite loops. It outputs optimized prompts with evaluation metrics for each target model. It supports multimodal inputs including png, jpg, and PDF files.
評価サンプルの inputVariablesMultimodal フィールドで S3 上の画像や PDF を指定できるみたいです。
画像を含むプロンプト(例えば画像の説明生成や、PDF からの情報抽出など)の最適化にも使えそうですね。
料金について
Advanced Prompt Optimizer の料金は以下の料金ページにも記載されています。
最適化の評価や処理自体は Claude Sonnet 4.6 が使われていると記載がありましたが、確認してみると評価対象だったモデル Claude Sonnet 3.5 や 4、Opus の料金も少し発生していますが、Sonnet 4.6 の料金がかなり発生していました。
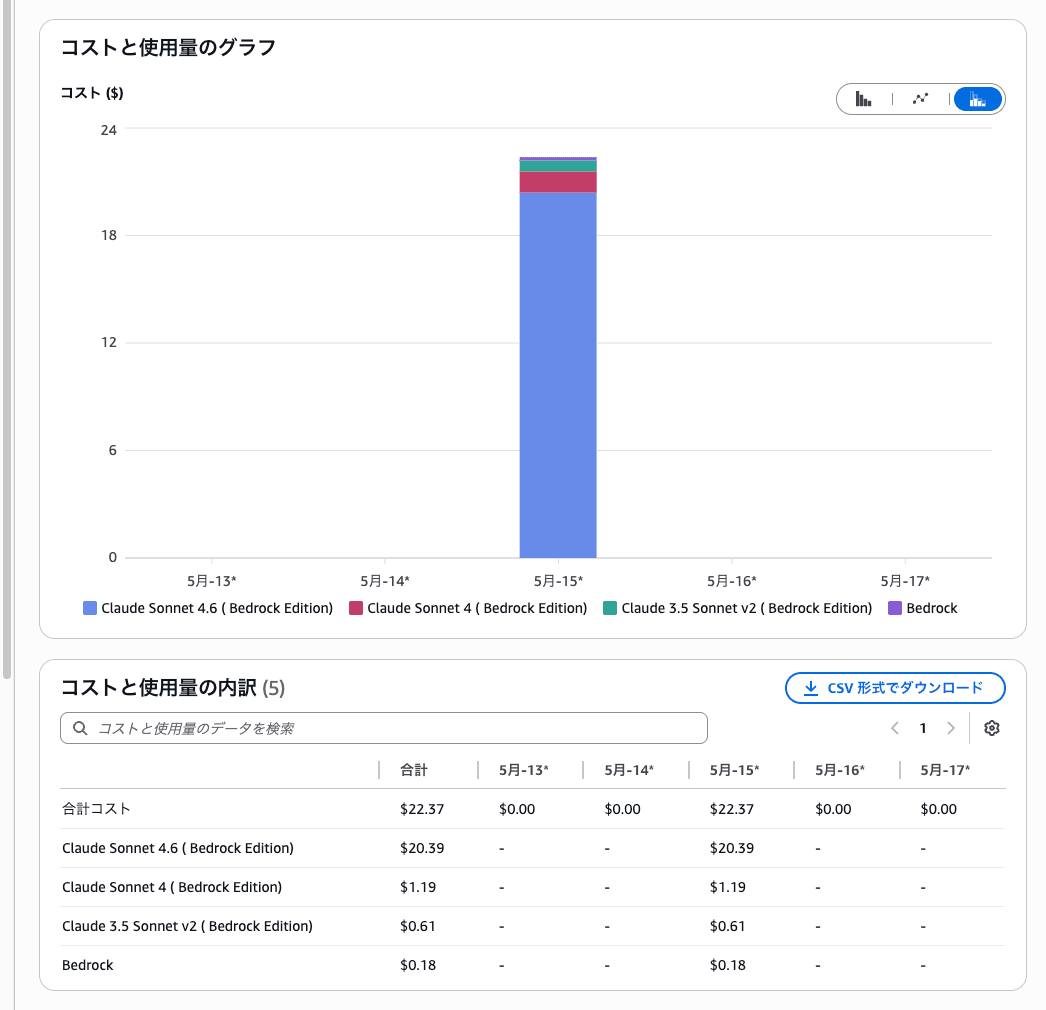
今回試したジョブ2回でこれくらいです。参考までに。
さいごに
本日は Amazon Bedrock に評価データを使ってプロンプトを反復最適化する Advanced Prompt Optimization が追加されたので使ってみました。
入力データセットの JSONL を用意するのがちょっと面倒ではありますが、一度用意してしまえば推論→評価→書き換えのループを自動で回してくれるのは楽ですね。
最適化後のプロンプトを見ると「こういう指示を追加すればスコアが上がるのか」というプロンプトエンジニアリングのヒントにもなりそうです。
モデル移行のシナリオでは、複数モデルのスコア・レイテンシ・コストを並べて比較できるので、移行先の判断材料として使えそう。
本番プロンプトの定期的なチューニングや、新モデルリリース時の移行検討には活用の幅が広そうだなと思いました。










