![[Amazon Bedrock AgentCore]Memory機能で会話履歴を記憶するエージェントを実装してみた](https://images.ctfassets.net/ct0aopd36mqt/7qr9SuOUauNHt4mdfTe2zu/8f7d8575eed91c386015d09e022e604a/AgentCore.png?w=3840&fm=webp)
[Amazon Bedrock AgentCore]Memory機能で会話履歴を記憶するエージェントを実装してみた
はじめに
こんにちは、コンサルティング部の神野です。
皆さんはAmazon Bedrock AgentCore(以下AgentCore)のMemory機能を使っていますか?先月プレビューリリースされた面白い機能です。
AgentCore Memoryの Short-term Memory と Long-term Memory はどんなことができるのかエージェントを実装しながら確認していきたいと思います!
AgentCore Memoryについて
AgentCore Memoryは、AIエージェントに「記憶」を持たせるためのマネージドサービスです。大きく分けて2種類の記憶を管理できます。
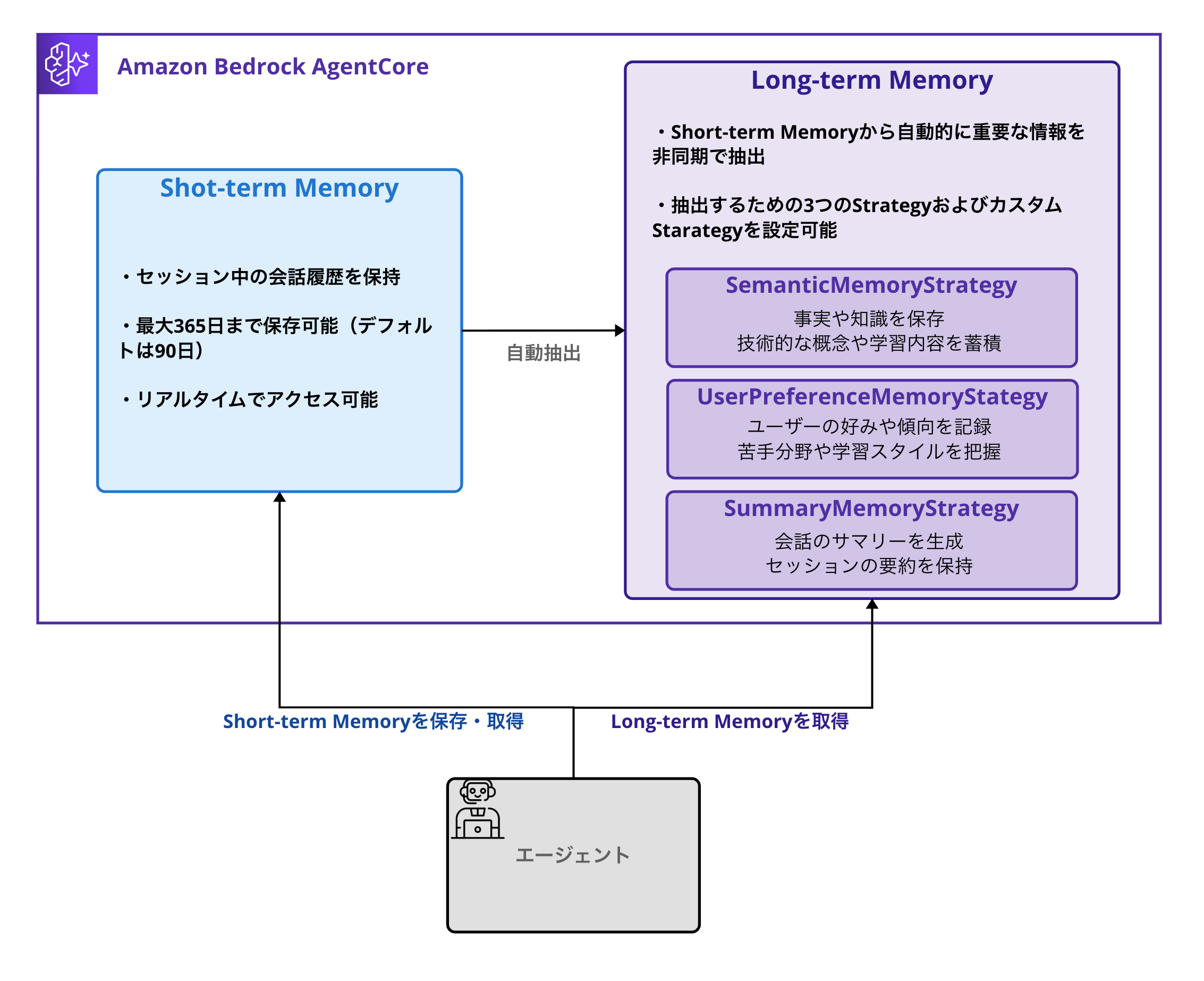
Short-term Memory
Short-term Memoryは、セッション中の会話履歴を保持する仕組みです。
特徴:
-
セッション中の会話履歴を記録可能
-
最大365日まで保存可能
- デフォルトの設定値は90日保存
-
リアルタイムでアクセス可能
-
Actor IDとSession IDでデータを整理
- Actor ID: 誰の記憶か(ユーザーやエンティティを識別)
- Session ID: どのセッション・会話の記憶か
-
生データが直接保存される
活用例
# 今日の学習セッションでの質問と回答を記録
memory_client.create_event(
memory_id=MEMORY_ID,
actor_id="engineer_alice",
session_id="python_study_20250817",
messages=[
("Pythonのデコレータについて教えて", "USER"),
("デコレータは関数を拡張する仕組みで...", "ASSISTANT")
]
)
# Memory情報を取得
events = memory_client.list_events(
memory_id=memory_id,
actor_id=actor_id,
session_id=session_id,
max_results=max_results
)
会話履歴をマネージドサービスで保持可能となります。またデフォルトで人別に振り分けるactorと会話毎に内容を切り替えるsessionといった属性が用意されているのが嬉しいですよね。
これだけでチャットボットであればユーザー別セッション毎に独立した会話履歴を保持することが可能になるイメージです。
Long-term Memory
Long-term Memoryは、Short-term Memoryから自動的に重要な情報を抽出・統合する機能です。
抽出されたインサイトはベクトルデータとして保存され、
セマンティック検索により関連性の高い記憶を効率的に取得できます。
非同期で自動的に処理される点が良いなと思いました!
3つの組み込みMemory Strategy
AWS公式ドキュメントによると、以下の3つの組み込みストラテジーが用意されています。
| Strategy | 役割 |
|---|---|
| SemanticMemoryStrategy | 事実や知識の抽出・保存 |
| UserPreferenceMemoryStrategy | ユーザーの好み・傾向を記録 |
| SummaryMemoryStrategy | 会話のサマリーを生成 |
それぞれ便利そうなストラテジーですね。用途によって使い分けできそうです。
Namespaceによるスコーピング
Namespaceは Long-term Memory を論理的にグループ化・整理するための仕組みです。階層構造(スラッシュ区切り)で定義でき、以下の変数を使用できます。
- {actorId}: 誰の記憶か(ユーザーやエンティティを識別)
- {sessionId}: どのセッション・会話の記憶か
- {strategyId}: strategyを区別するためのID
Namespace設計例
下記のようにNamespaceを設計することが可能です。
/retail-agent/customer-123/preferences: 特定の顧客の好み用
/retail-agent/product-knowledge: ユーザーがアクセスできる共有製品情報用
/support-agent/customer-123/case-summaries/session-001: 過去のサポートケースの概要用
Memory機能についてより詳細に理解したい方は下記AWS公式ブログがとっても参考になるので、ぜひご参照ください。
今回実装する技術学習アシスタント
全体構成
今回作成するエージェントの構成はこんな感じです。
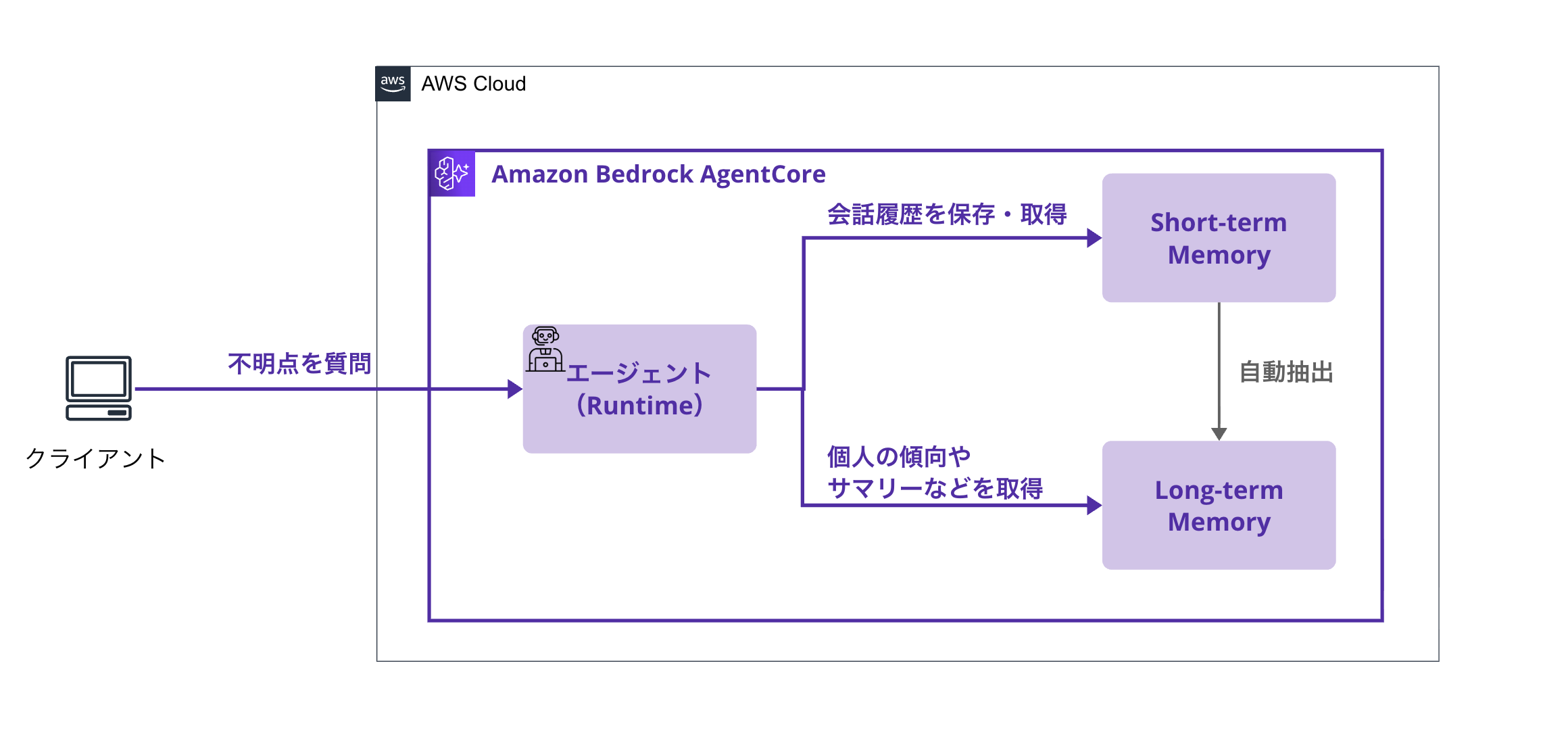
流れとしては下記になります!
-
ユーザーが技術的な質問をする
- 例:「Pythonのデコレータについて教えて」
-
エージェントが回答しながら記憶を更新
- Short-term Memory:質問と回答をセッションに記録
- Long-term Memory(非同期):
- 技術知識を抽出(SemanticMemory)
- 理解度や苦手分野を分析(UserPreference)
- セッションのサマリーを抽出(SummaryMemory)
-
学習分析機能
- 「私の苦手分野は?」→ Long-term Memory から分析
- 「最近学んだことをまとめて」→ セッションサマリーから生成
- 「Pythonについて復習したい」→ 過去の学習内容から復習ポイント提案
Memory機能を活用したエージェントを作成していきましょうー!
前提条件
必要な環境
- AWS CLI 2.28.8
- Python 3.12.6
- AWSアカウント
- 使用するリージョン:us-west-2
- モデルの有効化
- 今回は
anthropic.claude-3-5-haiku-20241022-v1:0を使用します
- 今回は
環境準備
Python環境のセットアップ
まずは仮想環境を作って必要なライブラリをインストールしていきましょう。
# プロジェクトディレクトリの作成
mkdir tech-learning-assistant
cd tech-learning-assistant
# 仮想環境の作成と有効化
python3 -m venv venv
source venv/bin/activate
必要なライブラリのインストール
requirements.txtを作成します。
strands-agents
strands-agents-tools
boto3
bedrock-agentcore
bedrock-agentcore-starter-toolkit
python-dotenv
インストールします。
pip install -r requirements.txt
環境変数の準備
.envファイルを作成して環境変数を管理します。
基本的には作成スクリプトを実行するとロールなどのARNは自動更新するような作りにしています。
モデルを変更したい場合はBEDROCK_MODEL_IDを修正ください。今回はanthropic.claude-3-5-haiku-20241022-v1:0を使用します。
# AWS設定
REGION=us-west-2
# エージェント設定
AGENT_NAME=tech_learning_assistant
# Memory設定(create_memory.pyが自動で更新)
MEMORY_ID=placeholder
# IAMロール設定(create_iam_role.pyで作成したARN)
EXECUTION_ROLE_ARN=arn:aws:iam::YOUR_ACCOUNT_ID:role/AgentCoreExecutionRole
# Bedrockモデル設定
BEDROCK_MODEL_ID=anthropic.claude-3-5-haiku-20241022-v1:0
# Agent Runtime設定(デプロイ後に更新)
AGENT_RUNTIME_ARN=arn:aws:bedrock-agentcore:us-west-2:YOUR_ACCOUNT_ID:runtime/YOUR_RUNTIME_ID
Memory作成
さて、いよいよAgentCore Memoryを作成していきます!ここは結構重要な部分なので、じっくり説明していきたいと思います。
ID階層構造の理解
AgentCore Memoryでは、3つのレベルでIDを管理します。これを理解しておくと、後の実装がぐっと楽になります!
| レベル | ID種別 | 役割・目的 | ライフサイクル | 具体例 |
|---|---|---|---|---|
| 1 | Memory ID | メモリインスタンス全体を識別 | 永続的(年単位) | TechLearningAssistantMemory_1692345678 |
| 2 | Actor ID | 個々のユーザーを識別・データ分離 | 半永続的(アカウント継続中) | engineer_alice, team_lead_bob |
| 3 | Session ID | 学習セッションごとの管理・サマリー生成 | 短期間(時間〜日単位) | python_study_20250817, react_review |
それぞれの役割
下記のようなイメージです。
- Memory ID: システム全体で一意なメモリインスタンス。
- Actor ID: ユーザー間のデータ分離を実現。アリスさんの学習データとボブさんの学習データが混ざることはありません
- Session ID: 学習セッションの単位。同じユーザーでも「今日のPython学習」と「昨日のReact復習」は別々に管理
ChatGPTのSessionIDは会話履歴タブのレコード単位とかを想像するとわかりやすいかもしれませんね。
Namespace設計の考え方
今回の技術学習アシスタントでは、以下のNamespace設計にしました。
# 技術知識:ユーザー単位で管理(セッションをまたいで蓄積)
"tech_learning/knowledge/{actorId}"
# 学習傾向:ユーザー単位で管理(長期的な学習パターン分析)
"tech_learning/preferences/{actorId}"
# サマリー:ユーザー×セッション単位で管理(学習履歴として活用)
"tech_learning/summaries/{actorId}/{sessionId}"
actor_idで分離することで、ユーザー間でデータが混ざらないし、知識は長期的に蓄積(アクター単位)、サマリーはセッション単位で管理することとします。
実装コード(詳細版)
それでは実際にMemoryを作成していきましょう!
from bedrock_agentcore.memory import MemoryClient
from bedrock_agentcore.memory.constants import StrategyType
import time
# Memory Clientの初期化
client = MemoryClient(region_name="us-west-2")
# 3つのストラテジーを定義
# それぞれに名前、説明、namespaceを設定
strategies = [
{
# 技術知識の抽出用ストラテジー
StrategyType.SEMANTIC.value: {
"name": "TechnicalKnowledgeExtractor",
"description": "技術的な知識や概念を抽出して保存",
"namespaces": ["tech_learning/knowledge/{actorId}"]
# actorIdごとに知識を分離(ユーザーAとユーザーBの知識は混ざらない)
}
},
{
# 学習傾向の記録用ストラテジー
StrategyType.USER_PREFERENCE.value: {
"name": "LearningPreferences",
"description": "学習傾向、理解度、苦手分野を記録",
"namespaces": ["tech_learning/preferences/{actorId}"]
# 各ユーザーの学習スタイルや苦手分野を個別管理
}
},
{
# セッションサマリー生成用ストラテジー
StrategyType.SUMMARY.value: {
"name": "SessionSummary",
"description": "学習セッションのサマリーを生成",
"namespaces": ["tech_learning/summaries/{actorId}/{sessionId}"]
# セッションごとにサマリーを作成(学習履歴として活用)
}
}
]
print("🚀 AgentCore Memory作成中...")
print("📝 設定内容:")
print(f" - Semantic Strategy: ユーザーごとの技術知識を保存")
print(f" - User Preference Strategy: 学習傾向・苦手分野を記録")
print(f" - Summary Strategy: セッションごとのサマリー生成")
timestamp = int(time.time())
memory_name = f"TechLearningAssistantMemory_{timestamp}"
# Memory作成(365日間のイベント保持)
memory = client.create_memory(
name=memory_name,
strategies=strategies,
description="技術学習アシスタント用のメモリ(ユーザー個別管理)",
)
memory_id = memory['id']
print(f"\n✅ Memory作成完了!")
print(f" Memory ID: {memory_id}")
print(f" Status: {memory['status']}")
# 各ストラテジーのIDを確認(自動生成される)
print(f"\n📋 生成されたStrategy IDs:")
for strategy in memory.get('strategies', []):
print(f" - {strategy['type']}: {strategy['strategyId']}")
print(f" Namespace: {strategy['namespaces'][0]}")
# .envファイルを自動で更新
with open('.env', 'r') as f:
content = f.read()
updated_content = content.replace('MEMORY_ID=placeholder', f'MEMORY_ID={memory_id}')
with open('.env', 'w') as f:
f.write(updated_content)
print(f"\n🎉 .envファイルを自動更新しました!")
実行してみましょう。
python create_memory.py
実行結果は以下のようになります。
🚀 AgentCore Memory作成中...
📝 設定内容:
- Semantic Strategy: ユーザーごとの技術知識を保存
- User Preference Strategy: 学習傾向・苦手分野を記録
- Summary Strategy: セッションごとのサマリー生成
✅ Memory作成完了!
Memory ID: TechLearningAssistantMemory_1692345678-AbC123DeF456
Status: CREATING
📋 生成されたStrategy IDs:
- SEMANTIC: TechnicalKnowledgeExtractor-xyz789abc123
Namespace: tech_learning/knowledge/{actorId}
- USER_PREFERENCE: LearningPreferences-def456ghi789
Namespace: tech_learning/preferences/{actorId}
- SUMMARY: SessionSummary-jkl012mno345
Namespace: tech_learning/summaries/{actorId}/{sessionId}
🎉 .envファイルを自動更新しました!
各ストラテジーに自動的にstrategyIdが割り当てられているのがわかりますね!これで準備完了です。
メモリ検索時の活用例
作成したMemoryを使って検索する際は、適切なnamespaceを指定することで効率的にデータを取得できます。
# 苦手分野の分析
preference_records = memory_client.retrieve_memories(
memory_id=MEMORY_ID,
namespace=f"tech_learning/preferences/{actor_id}",
query="苦手 理解困難 課題",
top_k=10
)
このように、namespace指定により必要なデータだけを効率的に取得できるのはいいですね。ユーザー単位やセッション単位で自動的に集約できるのもポイントが高いです。
クエリを書いて検索も可能です。
IAMロール作成
AgentCore Runtimeで実行するためのIAMロールを作成します。
import boto3
import json
from dotenv import load_dotenv
load_dotenv()
def create_execution_role():
print("🔐 IAM Execution Roleを作成中...")
iam = boto3.client('iam', region_name='us-west-2')
sts = boto3.client('sts', region_name='us-west-2')
# アカウントIDを動的取得
account_id = sts.get_caller_identity()['Account']
region = 'us-west-2'
# IAM Role名
role_name = "AgentCoreExecutionRole"
# Trust policy
trust_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock-agentcore.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": account_id
},
"ArnLike": {
"aws:SourceArn": f"arn:aws:bedrock-agentcore:{region}:{account_id}:*"
}
}
}
]
}
# 権限ポリシー(Memory機能用の権限を含む)
permission_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecr:BatchGetImage",
"ecr:GetDownloadUrlForLayer",
"ecr:GetAuthorizationToken"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": f"arn:aws:logs:{region}:{account_id}:*"
},
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock-agentcore:*"
],
"Resource": "*"
}
]
}
try:
# 既存のロールを確認
try:
existing_role = iam.get_role(RoleName=role_name)
print(f"✅ 既存のロールが見つかりました: {role_name}")
role_arn = existing_role['Role']['Arn']
# .envファイルを自動で更新
try:
with open('.env', 'r') as f:
content = f.read()
# EXECUTION_ROLE_ARNの行を更新
lines = content.split('\n')
updated_lines = []
arn_updated = False
for line in lines:
if line.startswith('EXECUTION_ROLE_ARN='):
updated_lines.append(f'EXECUTION_ROLE_ARN={role_arn}')
arn_updated = True
print(f"✅ .envファイルのEXECUTION_ROLE_ARNを更新しました")
else:
updated_lines.append(line)
# もしEXECUTION_ROLE_ARNの行がない場合は追加
if not arn_updated:
updated_lines.append(f'EXECUTION_ROLE_ARN={role_arn}')
print(f"✅ .envファイルにEXECUTION_ROLE_ARNを追加しました")
with open('.env', 'w') as f:
f.write('\n'.join(updated_lines))
if not content.endswith('\n'):
f.write('\n')
print(f"🎉 .envファイルを自動更新しました!")
except Exception as e:
print(f"⚠️ .envファイルの更新に失敗しました: {e}")
print(f"手動で以下をEXECUTION_ROLE_ARNに設定してください: {role_arn}")
return role_arn
except iam.exceptions.NoSuchEntityException:
pass
# IAM Roleの作成
response = iam.create_role(
RoleName=role_name,
AssumeRolePolicyDocument=json.dumps(trust_policy),
Description="Execution role for AgentCore Tech Learning Assistant"
)
role_arn = response['Role']['Arn']
print(f"✅ IAM Role作成完了: {role_name}")
# ポリシーの作成とアタッチ
policy_name = "AgentCoreExecutionPolicy"
try:
policy_response = iam.create_policy(
PolicyName=policy_name,
PolicyDocument=json.dumps(permission_policy),
Description="Permissions for AgentCore Tech Learning Assistant"
)
policy_arn = policy_response['Policy']['Arn']
print(f"✅ IAM Policy作成完了: {policy_name}")
except iam.exceptions.EntityAlreadyExistsException:
# 既存のポリシーがある場合はARNを取得
account_id = boto3.client('sts').get_caller_identity()['Account']
policy_arn = f"arn:aws:iam::{account_id}:policy/{policy_name}"
print(f"✅ 既存のポリシーを使用: {policy_name}")
# ポリシーをロールにアタッチ
iam.attach_role_policy(
RoleName=role_name,
PolicyArn=policy_arn
)
print(f"✅ ポリシーをロールにアタッチ完了")
print(f"🎉 IAM Execution Role準備完了!")
print(f"Role ARN: {role_arn}")
# .envファイルを自動で更新
try:
with open('.env', 'r') as f:
content = f.read()
# EXECUTION_ROLE_ARNの行を更新
lines = content.split('\n')
updated_lines = []
arn_updated = False
for line in lines:
if line.startswith('EXECUTION_ROLE_ARN='):
updated_lines.append(f'EXECUTION_ROLE_ARN={role_arn}')
arn_updated = True
print(f"✅ .envファイルのEXECUTION_ROLE_ARNを更新しました")
else:
updated_lines.append(line)
# もしEXECUTION_ROLE_ARNの行がない場合は追加
if not arn_updated:
updated_lines.append(f'EXECUTION_ROLE_ARN={role_arn}')
print(f"✅ .envファイルにEXECUTION_ROLE_ARNを追加しました")
with open('.env', 'w') as f:
f.write('\n'.join(updated_lines))
if not content.endswith('\n'):
f.write('\n')
print(f"🎉 .envファイルを自動更新しました!")
except Exception as e:
print(f"⚠️ .envファイルの更新に失敗しました: {e}")
print(f"手動で以下をEXECUTION_ROLE_ARNに設定してください: {role_arn}")
return role_arn
except Exception as e:
print(f"❌ IAM Role作成エラー: {e}")
return None
if __name__ == "__main__":
create_execution_role()
実行してロールARNを取得しましょう。スクリプトは自動的に.envファイルのEXECUTION_ROLE_ARNを更新してくれます。
python create_iam_role.py
実行結果
🔐 IAM Execution Roleを作成中...
✅ IAM Role作成完了: AgentCoreExecutionRole
✅ IAM Policy作成完了: AgentCoreExecutionPolicy
✅ ポリシーをロールにアタッチ完了
🎉 IAM Execution Role準備完了!
Role ARN: arn:aws:iam::123456789012:role/AgentCoreExecutionRole
✅ .envファイルのEXECUTION_ROLE_ARNを更新しました
🎉 .envファイルを自動更新しました!
エージェントの実装
いよいよメインのエージェント実装です!記憶機能を持つ学習アシスタントを作ります。
Short-term Memoryで会話履歴を自動保存してセッション間での文脈を維持しながら、analyze_learning_progress(学習進捗分析)、identify_weak_areas(苦手分野特定)、get_session_summary(セッションサマリー取得)、suggest_review_topics(復習トピック提案)の4つのツールでLong-term Memoryと連携し、ユーザーごとにパーソナライズされた技術学習支援を行うエージェントとします。
import os
from datetime import datetime
from typing import List, Dict
from bedrock_agentcore.runtime import BedrockAgentCoreApp
from bedrock_agentcore.memory import MemoryClient
from strands import Agent, tool
from strands.models import BedrockModel
from dotenv import load_dotenv
# 環境変数読み込み
load_dotenv()
# グローバル設定
MEMORY_ID = os.getenv("MEMORY_ID")
REGION = os.getenv("REGION", "us-west-2")
# Memory Clientの初期化
memory_client = MemoryClient(region_name=REGION)
# カスタムツールの定義
@tool
def analyze_learning_progress(subject: str = None) -> str:
"""
学習進捗を分析します。
特定の技術分野を指定することもできます。
"""
try:
# 現在のユーザー情報を取得(グローバル変数から)
actor_id = getattr(analyze_learning_progress, 'actor_id', 'current_user')
# 技術知識の取得
query = f"{subject} 学習" if subject else "学習した技術"
knowledge_records = memory_client.retrieve_memories(
memory_id=MEMORY_ID,
namespace=f"tech_learning/knowledge/{actor_id}",
query=query,
top_k=10
)
records = knowledge_records
if not records:
return f"まだ{subject or '技術'}の学習記録がありません。学習を始めてみましょう!"
# 分析結果の生成
progress_info = []
for record in records[:5]: # 最新5件を表示
content = record['content']['text']
progress_info.append(f"・{content}")
result = f"📊 {subject or '全体的'}の学習進捗:\n\n"
result += "\n".join(progress_info)
result += f"\n\n合計{len(records)}件の学習記録があります!"
return result
except Exception as e:
return f"学習進捗の分析中にエラーが発生しました: {str(e)}"
@tool
def identify_weak_areas() -> str:
"""苦手分野を特定します"""
try:
actor_id = getattr(identify_weak_areas, 'actor_id', 'current_user')
# 学習傾向の取得
preference_records = memory_client.retrieve_memories(
memory_id=MEMORY_ID,
namespace=f"tech_learning/preferences/{actor_id}",
query="苦手 理解困難 課題",
top_k=10
)
records = preference_records
if not records:
return "まだ十分な学習データがありません。もう少し学習を続けると、苦手分野の分析ができるようになります!"
# 苦手分野の分析
weak_areas = []
for record in records:
content = record['content']['text']
weak_areas.append(f"・{content}")
result = "🔍 苦手分野の分析結果:\n\n"
result += "\n".join(weak_areas)
result += "\n\n📈 改善提案:\n"
result += "・基礎から段階的に学習を進めましょう\n"
result += "・不明な点は遠慮なく質問してください"
return result
except Exception as e:
return f"苦手分野の分析中にエラーが発生しました: {str(e)}"
@tool
def get_session_summary(session_id: str = None, full_content: bool = True, max_summaries: int = 3) -> str:
"""学習セッションのサマリーを取得します
Args:
session_id: 取得するセッションID(未指定の場合は現在のセッション)
full_content: 完全な内容を表示するか(False の場合は200文字で切り詰め)
max_summaries: 表示するサマリー数の上限
"""
try:
actor_id = getattr(get_session_summary, 'actor_id', 'current_user')
# session_idが指定されていない場合は現在のセッションを使用
if not session_id:
session_id = getattr(get_session_summary, 'current_session_id', 'current_session')
# セッションサマリーの取得
summary_records = memory_client.retrieve_memories(
memory_id=MEMORY_ID,
namespace=f"tech_learning/summaries/{actor_id}/{session_id}",
query="学習セッション サマリー",
top_k=max(max_summaries, 5)
)
records = summary_records
if not records:
return f"セッション '{session_id}' のサマリーがまだ生成されていません。学習を続けると自動的にサマリーが作成されます!"
# セッションサマリーの表示
session_summaries = []
for i, record in enumerate(records[:max_summaries]):
content = record['content']['text']
if full_content:
# 完全な内容を表示(XMLタグの整形も含む)
if content.strip().startswith('<summary>'):
# XMLサマリーの場合は構造化して表示
formatted_content = content.replace('<topic name="', '\n🎯 **').replace('">', '**\n ')
formatted_content = formatted_content.replace('</topic>', '\n')
formatted_content = formatted_content.replace('<summary>', '').replace('</summary>', '')
session_summaries.append(f"📋 **サマリー {i+1}:**{formatted_content}")
else:
session_summaries.append(f"📋 **サマリー {i+1}:**\n{content}")
else:
# 200文字で切り詰め
session_summaries.append(f"📋 {content[:200]}...")
result = f"📊 セッション '{session_id}' のサマリー:\n\n"
result += "\n".join(session_summaries)
result += f"\n\n💡 このサマリーは学習内容を効率的に振り返るのに役立ちます!"
result += f"\n(表示件数: {len(session_summaries)}/{len(records)}件)"
return result
except Exception as e:
return f"セッションサマリーの取得中にエラーが発生しました: {str(e)}"
@tool
def suggest_review_topics() -> str:
"""復習すべきトピックを提案します"""
try:
actor_id = getattr(suggest_review_topics, 'actor_id', 'current_user')
# 過去の学習内容から復習候補を検索
knowledge_records = memory_client.retrieve_memories(
memory_id=MEMORY_ID,
namespace=f"tech_learning/knowledge/{actor_id}",
query="復習 理解 概念",
top_k=15
)
records = knowledge_records
if not records:
return "まだ復習できる学習記録がありません。継続して学習を進めましょう!"
# 復習トピックの提案
review_topics = []
for i, record in enumerate(records[:5]): # 上位5件を提案
content = record['content']['text']
review_topics.append(f"{i+1}. {content}")
result = "📚 復習におすすめのトピック:\n\n"
result += "\n".join(review_topics)
result += "\n\n💡 復習のコツ:\n"
result += "・まずは概念を思い出してから、詳細を確認\n"
result += "・実際にコードを書いて動作確認\n"
result += "・理解が曖昧な部分は質問してください"
return result
except Exception as e:
return f"復習トピックの検索中にエラーが発生しました: {str(e)}"
# メモリ管理のヘルパー関数
def save_conversation_to_memory(memory_id: str, actor_id: str, session_id: str,
user_message: str, assistant_message: str):
"""会話をメモリに保存"""
try:
memory_client.create_event(
memory_id=memory_id,
actor_id=actor_id,
session_id=session_id,
messages=[
(user_message, "USER"),
(assistant_message, "ASSISTANT")
]
)
print("✅ 会話をメモリに保存しました")
except Exception as e:
print(f"❌ メモリ保存エラー: {e}")
def load_conversation_history(memory_id: str, actor_id: str, session_id: str, max_results: int = 10):
"""過去の会話履歴を取得"""
try:
events = memory_client.list_events(
memory_id=memory_id,
actor_id=actor_id,
session_id=session_id,
max_results=max_results
)
# イベントを時系列順にソート(直接リストが返される)
sorted_events = sorted(events, key=lambda x: x['eventTimestamp'])
# 会話履歴を構築(Strandsエージェント用の正しい形式)
history_messages = []
for event in sorted_events:
for item in event.get('payload', []):
if 'conversational' in item:
conv = item['conversational']
history_messages.append({
"role": conv['role'].lower(),
"content": [{"text": conv['content']['text']}]
})
return history_messages
except Exception as e:
print(f"⚠️ 履歴取得エラー: {e}")
return []
# BedrockAgentCoreアプリケーション
app = BedrockAgentCoreApp()
# エージェントのグローバル変数
agent = None
@app.entrypoint
async def tech_learning_assistant(payload):
"""技術学習アシスタントのエントリーポイント"""
global agent
print("🎓 技術学習アシスタントを起動中...")
# ペイロードから情報取得
user_input = payload.get("message") or payload.get("prompt", "こんにちは")
actor_id = payload.get("actor_id", "default_user")
session_id = payload.get("session_id", f"session_{datetime.now().strftime('%Y%m%d_%H%M%S')}")
# ツールのactor_idとsession_idを設定(グローバル変数として)
analyze_learning_progress.actor_id = actor_id
identify_weak_areas.actor_id = actor_id
suggest_review_topics.actor_id = actor_id
get_session_summary.actor_id = actor_id
get_session_summary.current_session_id = session_id
# 初回のみ初期化
if agent is None:
print("エージェントを初期化中...")
# 環境変数からモデルIDを取得
model_id = os.getenv("BEDROCK_MODEL_ID", "anthropic.claude-3-5-haiku-20241022-v1:0")
model = BedrockModel(
model_id=model_id,
params={"max_tokens": 4096, "temperature": 0.7},
region="us-west-2"
)
# エージェントの初期化
agent = Agent(
model=model,
tools=[
analyze_learning_progress,
identify_weak_areas,
suggest_review_topics,
get_session_summary
],
system_prompt="""あなたは優秀な技術学習アシスタントです。
エンジニアの技術学習をサポートし、理解度を記録し、効果的な学習方法を提案します。
以下のツールが利用可能です:
- analyze_learning_progress: 学習進捗を分析(特定の技術分野も指定可能)
- identify_weak_areas: 苦手分野を特定
- suggest_review_topics: 復習すべきトピックを提案
- get_session_summary: 学習セッションのサマリーを取得
以下の点に注意してください:
- 技術的な質問には具体的な例を交えて説明する
- 理解度を確認しながら進める
- 苦手分野を特定したら、それに応じた学習方法を提案する
- 励ましと建設的なフィードバックを提供する
- 必要に応じてツールを活用して学習状況を把握する
"""
)
print("✅ エージェント初期化完了!")
print(f"👤 ユーザー: {actor_id}")
print(f"📝 セッション: {session_id}")
print(f"💬 質問: {user_input}")
try:
# 過去の会話履歴を取得
print("📚 過去の学習履歴を取得中...")
history_messages = load_conversation_history(MEMORY_ID, actor_id, session_id, max_results=10)
if history_messages:
print(f"✅ {len(history_messages)}件の過去メッセージを取得")
# 履歴がある場合は、エージェントのメッセージリストに設定
agent.messages = history_messages
# エージェントを実行(常に現在のユーザー入力のみを渡す)
response = await agent.invoke_async(user_input)
result = response.message['content'][0]['text']
# 会話をメモリに保存
print("💾 学習内容をメモリに保存中...")
save_conversation_to_memory(MEMORY_ID, actor_id, session_id, user_input, result)
print(f"🤖 回答: {result[:100]}...")
return result
except Exception as e:
print(f"❌ エラーが発生しました: {e}")
return f"申し訳ありません。エラーが発生しました: {str(e)}"
if __name__ == "__main__":
app.run()
デプロイ
AgentCore Runtimeへのデプロイ
下記スクリプトを使ってデプロイします。
from bedrock_agentcore_starter_toolkit import Runtime
import os
from dotenv import load_dotenv
load_dotenv()
def deploy_tech_learning_assistant():
print("🚀 技術学習アシスタントをデプロイ中...")
env_vars = {
"MEMORY_ID": os.getenv("MEMORY_ID"),
"REGION": os.getenv("REGION", "us-west-2"),
}
runtime = Runtime()
# 環境変数からIAMロールARNを取得
execution_role = os.getenv("EXECUTION_ROLE_ARN")
if not execution_role:
raise ValueError("EXECUTION_ROLE_ARN環境変数が設定されていません")
response = runtime.configure(
entrypoint="agent_tech_learning_assistant.py",
execution_role=execution_role,
auto_create_ecr=True,
requirements_file="requirements.txt",
region="us-west-2",
agent_name=os.getenv("AGENT_NAME", "tech_learning_assistant")
)
print("✅ 設定完了!デプロイを実行中...")
launch_result = runtime.launch(env_vars=env_vars)
print(f"✅ デプロイ完了!")
# Agent Runtime ARNを取得して.envファイルを自動更新
try:
# launch_resultからAgent Runtime ARNを抽出
agent_runtime_arn = None
if hasattr(launch_result, 'agent_arn'):
agent_runtime_arn = launch_result.agent_arn
elif isinstance(launch_result, dict):
agent_runtime_arn = launch_result.get('agent_arn')
if agent_runtime_arn:
print(f"🔗 Agent Runtime ARN: {agent_runtime_arn}")
# .envファイルを自動で更新
try:
with open('.env', 'r') as f:
content = f.read()
# AGENT_RUNTIME_ARNの行を更新
lines = content.split('\n')
updated_lines = []
arn_updated = False
for line in lines:
if line.startswith('AGENT_RUNTIME_ARN='):
updated_lines.append(f'AGENT_RUNTIME_ARN={agent_runtime_arn}')
arn_updated = True
print(f"✅ .envファイルのAGENT_RUNTIME_ARNを更新しました")
else:
updated_lines.append(line)
# もしAGENT_RUNTIME_ARNの行がない場合は追加
if not arn_updated:
updated_lines.append(f'AGENT_RUNTIME_ARN={agent_runtime_arn}')
print(f"✅ .envファイルにAGENT_RUNTIME_ARNを追加しました")
with open('.env', 'w') as f:
f.write('\n'.join(updated_lines))
if not content.endswith('\n'):
f.write('\n')
print(f"🎉 .envファイルを自動更新しました!")
except Exception as e:
print(f"⚠️ .envファイルの更新に失敗しました: {e}")
print(f"手動で以下をAGENT_RUNTIME_ARNに設定してください: {agent_runtime_arn}")
else:
print(f"⚠️ Agent Runtime ARNを取得できませんでした")
print(f"デプロイ結果: {launch_result}")
print("手動でAGENT_RUNTIME_ARNを.envファイルに設定してください")
except Exception as e:
print(f"⚠️ Agent Runtime ARN取得エラー: {e}")
print(f"デプロイ結果: {launch_result}")
return launch_result
if __name__ == "__main__":
deploy_tech_learning_assistant()
実行してデプロイしましょう。スクリプトは自動的に.envファイルのAGENT_RUNTIME_ARNも更新してくれます。
python deploy_agent.py
実行結果
🚀 技術学習アシスタントをデプロイ中...
✅ 設定完了!デプロイを実行中...
✅ デプロイ完了!
🔗 Agent Runtime ARN: arn:aws:bedrock-agentcore:us-west-2:123456789012:runtime/abcd1234-efgh-5678-ijkl-9012mnop3456
✅ .envファイルのAGENT_RUNTIME_ARNを更新しました
🎉 .envファイルを自動更新しました!
これで全ての設定が完了です!テストしていきましょう!
テスト・動作確認
簡単にテストできるようchat.pyといったスクリプトを用意しました。
actorとsessionを簡単に設定してエージェントとチャットできます。
コード全文
#!/usr/bin/env python3
"""
Tech Learning Assistant - 簡単チャットクライアント
使い方:
python chat.py "質問内容"
python chat.py "質問内容" --user "ユーザー名"
python chat.py "質問内容" --session "セッションID"
"""
import boto3
import json
import uuid
import sys
import argparse
import os
from dotenv import load_dotenv
load_dotenv()
class TechLearningAssistantClient:
def __init__(self):
self.client = boto3.client('bedrock-agentcore', region_name='us-west-2')
# 環境変数からAgent Runtime ARNを取得
self.agent_arn = os.getenv("AGENT_RUNTIME_ARN")
if not self.agent_arn:
raise ValueError("AGENT_RUNTIME_ARN環境変数が設定されていません")
self.default_session_id = None
self.default_actor_id = "default_user"
def chat(self, message, actor_id=None, session_id=None):
"""エージェントにメッセージを送信して応答を取得"""
if not actor_id:
actor_id = self.default_actor_id
if not session_id:
if not self.default_session_id:
self.default_session_id = str(uuid.uuid4())
session_id = self.default_session_id
runtime_session_id = str(uuid.uuid4())
payload = json.dumps({
"prompt": message,
"actor_id": actor_id,
"session_id": session_id
}).encode()
try:
response = self.client.invoke_agent_runtime(
agentRuntimeArn=self.agent_arn,
runtimeSessionId=runtime_session_id,
payload=payload
)
content_parts = []
for chunk in response["response"]:
try:
decoded = chunk.decode('utf-8')
content_parts.append(decoded)
except UnicodeDecodeError:
decoded = chunk.decode('utf-8', errors='ignore')
content_parts.append(decoded)
full_response = ''.join(content_parts)
# JSONレスポンスの場合は整形
try:
json_response = json.loads(full_response)
return json.dumps(json_response, ensure_ascii=False, indent=2)
except:
return full_response.strip('"')
except Exception as e:
return f"❌ エラーが発生しました: {str(e)}"
def main():
parser = argparse.ArgumentParser(description='Tech Learning Assistant チャットクライアント')
parser.add_argument('message', nargs='?', help='質問メッセージ')
parser.add_argument('--user', '-u', help='ユーザーID(actor_id)')
parser.add_argument('--session', '-s', help='セッションID')
args = parser.parse_args()
client = TechLearningAssistantClient()
if args.user:
client.default_actor_id = args.user
if args.session:
client.default_session_id = args.session
if args.message:
response = client.chat(args.message)
print(response)
else:
# デフォルトテスト
print("🎓 Tech Learning Assistant テストモード")
print("=" * 50)
test_questions = [
"Pythonの非同期プログラミングについて教えて",
"私の学習進捗を分析してください",
"苦手分野を教えて"
]
for i, question in enumerate(test_questions, 1):
print(f"\n{i}. {question}")
response = client.chat(question)
print(f"回答: {response[:200]}...")
if __name__ == "__main__":
main()
早速実装したMemory機能を検証していきます。
検証1: Short-term Memory(セッション内記憶)の確認
まずはReactのuseEffectについて質問してみます。actorはtest_user1、sessionはsession_test1とします。
python chat.py "ReactのuseEffectについて教えてください" \
--user "test_user1" --session "session_test1"
実行結果
会話履歴はそのまま出力しているため見づらかったらすみません・・・
useEffectの理解を深めるためのアドバイス:\n1. 簡単な例から始める\n2. 依存配列の挙動を実際に試してみる\n3. クリーンアップ関数の重要性を理解する\n4. 実際のプロジェクトで使用してみる\n\n質問や具体的な使用例について、さらに詳しく知りたいことがあればお聞きします。useEffectの理解を一緒に深めていきましょう!
次に、この会話を覚えているか確認してみます。1.簡単な例から教えてくださいと会話を記憶している前提で話します。
python chat.py "1.簡単な例から教えてください" \
--user "test_user1" --session "session_test1"
実行結果
もちろんです!useEffectの基本的な例を使って説明します。\n\n基本的な useEffect の構造:\n```javascript\nimport React, { useState, useEffect } from 'react';\n\nfunction ExampleComponent() {\n const [count, setCount] = useState(0);\n\n // 基本的なuseEffect\n useEffect(() => {\n // コンポーネントがマウントされた時、または依存配列の値が変更された時に実行される処理\n document.title = `You clicked ${count} times`;\n }, [count]); // countが変更されるたびにこのエフェクトが実行される\n\n return (\n <div>\n <p>You clicked {count} times</p>\n <button onClick={() => setCount(count + 1)}>\n Click me\n </button>\n </div>\n );\n}\n```\n\nこのシンプルな例では、以下のことを示しています:\n\n1. useEffectの基本的な構造\n2. 依存配列の使用([count])\n3. stateの変更に応じて副作用(この場合はdocument.titleの更新)を実行\n\nさらに、異なる使用例も見てみましょう:\n\n```javascript\nfunction DataFetchingComponent() {\n const [data, setData] = useState(null);\n\n useEffect(() => {\n // APIからデータを取得\n fetch('[https://api.example.com/data](https://api.example.com/data)')\n .then(response => response.json())\n .then(result => setData(result));\n }, []); // 空の依存配列 = コンポーネントマウント時に1回だけ実行\n\n return (\n <div>\n {data ? (\n <ul>\n {data.map(item => (\n <li key={item.id}>{item.name}</li>\n ))}\n </ul>\n ) : (\n <p>Loading...</p>\n )}\n </div>\n );\n}\n```\n\nこの例では:\n- 空の依存配列([])を使用して、コンポーネントのマウント時に1回だけAPIコールを実行\n- データ取得中は「Loading...」を表示\n- データ取得後にリストをレンダリング\n\nuseEffectの主なポイント:\n1. コンポーネントのライフサイクルに関連する副作用を管理\n2. 依存配列によって実行タイミングをコントロール\n3. データフェッチ、購読設定、DOM直接操作などに使用\n\n理解を深めるためのヒント:\n- 依存配列を省略すると、毎回レンダリング時に実行\n- 空の依存配列([])は初回のみ実行\n- 特定の値の変更時のみ実行したい場合は、その値を依存配列に含める\n\nさらに詳しく知りたい点や、具体的な質問はありますか?クリーンアップ関数や複雑な使用例など、掘り下げて説明できます。
会話を記録できているため、useEffectの基本的なサンプルを教えてくれましたね!
マネージドに会話履歴を保存してくれるのは嬉しいですね。難しい実装も不要ですし、いい機能だなと思いました。
検証2: 別のユーザーでの学習と長期記憶の確認
ユーザーを変えて、JavaScriptのPromiseについて学習してみます。actorはuser_alice、sessionはtest_session1とします。
python chat.py "JavaScriptのPromiseについて学習中です" --user "user_alice" --session "test_session1"
実行結果
Promiseの学習において、以下のポイントに注目してください:\n\n1. Promise作成と基本的な使用方法\n2. .then(), .catch(), .finally() メソッド\n3. Promise.all(), Promise.race() などの静的メソッド\n4. async/await構文との関係\n\n質問や、特に理解が難しい部分はありますか?具体的な例を交えて説明しますので、わからない点を教えてください。例えば、「Promiseチェーン」や「エラーハンドリング」などについて詳しく知りたいことはありますか?\n\n一緒に段階的にPromiseの理解を深めていきましょう!何か具体的に知りたいことや、つまずいている部分はありますか?
再び、test_user1とuser_aliceでそれぞれ質問します。今回はtest_user1は苦手分野を分析してと依頼してツールidentify_weak_areasを使わせて、user_aliceはツールanalyze_learning_progressを使わせます。
python chat.py "私の苦手分野を教えて" --user "test_user1"
python chat.py "私の学習進捗は?" --user "user_alice"
実行結果
test_user1
分析結果から、Reactのフック、特に`useEffect`について理解を深めたいと考えていることがわかりました。この分野は少し難しいと感じているようですね。\n\n具体的な改善提案をいくつか提示します:\n\n1. `useEffect`の基本的な概念を理解する\n - コンポーネントのライフサイクルとの関連\n - 依存配列の仕組み\n - 副作用の管理方法\n\n2. 簡単な例から始める\n - データフェッチ\n - イベントリスナーの追加と削除\n - タイマーの設定\n\n3. 学習リソース\n - 公式React documentation\n - オンラインチュートリアル\n - コーディング演習サイト\n\nさらに詳しく知りたいことや、具体的な疑問点はありますか?React hooksについて一緒に学んでいきましょう!\n\n追加で学習進捗を分析したい場合は、特定の技術分野を指定して確認することもできます。
user_alice
私からの追加アドバイス:\n1. JavaScript Promisesは非同期処理を簡潔に扱うための重要な機能です。\n2. 学習のポイント:\n - Promiseの基本構文\n - `.then()`, `.catch()`, `.finally()` メソッド\n - async/await構文\n3. 実践的な練習を心がけてください。簡単な非同期処理から始めて、徐々に複雑な処理に挑戦しましょう。\n\n何か具体的に疑問に思っていることはありますか?Promisesについてさらに詳しく説明することができます。
当たり前ですが、2人の質問内容は混じって記憶されていませんね。よかった。
ツールもしっかり動いてその結果をLLMが返信していますね!
CloudWatch Logsを確認すると、苦手分野分析ツール(identify_weak_areas)の実行詳細が記録されていました。
{
"toolResult": {
"content": [
{
"text": "🔍 苦手分野の分析結果:\n\n・{\"context\":\"User is learning about React's useEffect and asking for simple examples, indicating an interest in understanding React hooks\",\"preference\":\"Interested in learning React hooks, particularly useEffect\",\"categories\":[\"programming\",\"web development\",\"React\",\"JavaScript\"]}\n\n📈 改善提案:\n・基礎から段階的に学習を進めましょう\n・実際にコードを書いて練習しましょう\n・不明な点は遠慮なく質問してください"
}
]
}
}
UserPreferenceMemoryStrategyがユーザーからの記憶を英語で構造化していて面白いですね。
こんな形で情報を保持しているんだと勉強になりました。
実装したその他のツール
今回の記事では基本的な記憶機能を検証しましたが、エージェントには他にも学習支援ツールを実装しています。
復習提案ツール(suggest_review_topics)
@tool
def suggest_review_topics() -> str:
"""復習すべきトピックを提案します"""
# 過去の学習内容から復習候補を検索
knowledge_records = memory_client.retrieve_memories(
memory_id=MEMORY_ID,
namespace=f"tech_learning/knowledge/{actor_id}",
query="復習 理解 概念",
top_k=15
)
# 復習におすすめのトピックを5つ選んで提案
過去の学習内容を分析して、復習すべきトピックを自動提案してくれます。学習の定着度を考慮したスケジューリングに活用できそうです。
セッションサマリーツール(get_session_summary)
@tool
def get_session_summary(session_id: str = None, full_content: bool = True, max_summaries: int = 3) -> str:
"""学習セッションのサマリーを取得します"""
# セッションサマリーの取得
summary_records = memory_client.retrieve_memories(
memory_id=MEMORY_ID,
namespace=f"tech_learning/summaries/{actor_id}/{session_id}",
query="学習セッション サマリー",
top_k=max(max_summaries, 5)
)
# XMLサマリーの構造化表示や切り詰め表示にも対応
学習セッションの内容を自動要約して、効率的な振り返りが可能です。1セッションでいっぱいやり取りした時はサマリーがあるといいですね。
もし興味がある機能があったら、ぜひ試してみてくださいね!
ソースコード全体もGitHubにアップロードしています。
おわりに
Amazon Bedrock AgentCore Memoryを使って、会話履歴を記憶したり、会話履歴からインサイトを得てアドバイスをしてくれるエージェントを簡易的に作成できました!
Short-term Memoryは便利ですね。マネージドサービスで会話履歴を管理できるのは良きです。
Short-term Memory と Long-term Memory の自動連携は便利ですが、長期的に運用した時にどれぐらいの精度になるかは気になるポイントですね。
本記事が少しでも参考になれば幸いですー!最後までご覧いただきありがとうございました!










