![[Amazon Bedrock Evaluations] Guardrails のコンテキストグラウンディング機能によるハルシネーション防止効果を評価してみました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e3065182082062711612153bbdcf1d96/c04359de689df2f56eb066576ab63fb5/amazon-bedrock?w=3840&fm=webp)
[Amazon Bedrock Evaluations] Guardrails のコンテキストグラウンディング機能によるハルシネーション防止効果を評価してみました
1 はじめに
製造ビジネステクノロジー部の平内(SIN)です。
RAG(Retrieval-Augmented Generation:検索拡張生成)は、外部データを参照して回答を生成する手法として広く利用されています。しかし、LLM(大規模言語モデル)がソースに含まれない情報を「それらしく」生成してしまうハルシネーション(幻覚)のリスクは常に存在します。
Amazon Bedrock では、Knowledge Bases を使用して 簡単にRAGを構築できますが、さらに、Guardrails のコンテキストグラウンディング機能を適用することで、回答がソースドキュメントに基づいているかを検証し、ハルシネーションを抑制することができます。
本記事では、Amazon Bedrock Evaluations を使用して、このコンテキストグラウンディング機能の効果を定量的に評価してみました。
結果として、Faithfulness(忠実性) の向上が確認できた一方で、Helpfulness(有用性) などにわずかなトレードオフが生じることもわかりました。
なお、本記事で使用したコードは GitHub で公開しています。
2 構成
今回の評価環境は、下記のような構成となっています。
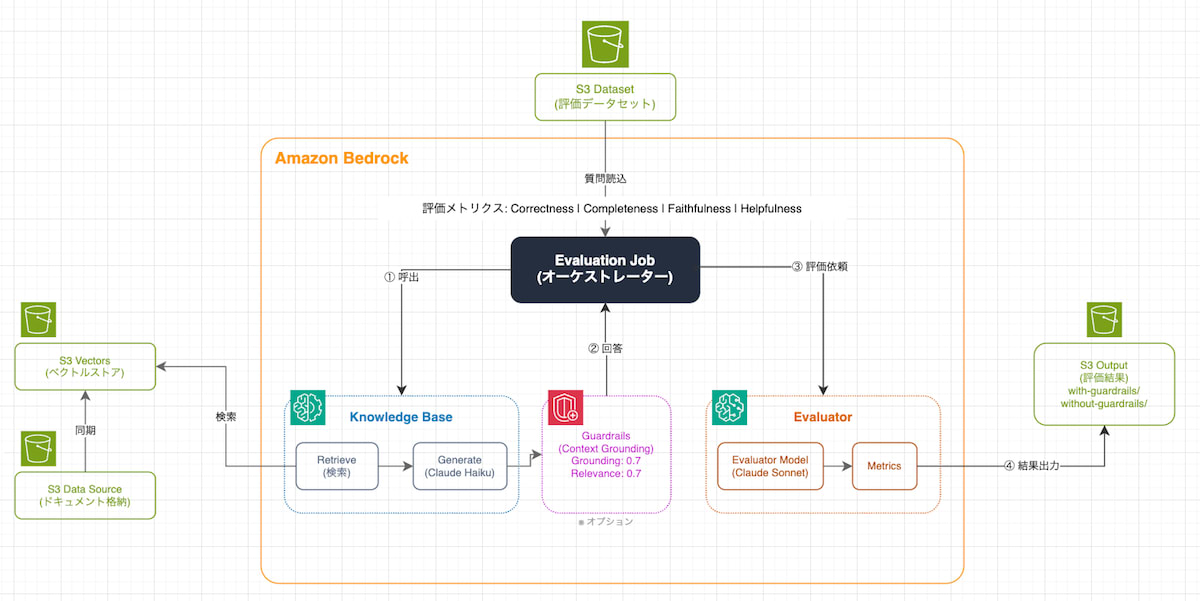
| コンポーネント | 説明 |
|---|---|
| S3 バケット(データソース) | ナレッジベースのソースドキュメントを格納 |
| S3 Vectors | ベクトルストア(埋め込みベクトルの保存) |
| Knowledge Base | RAG |
| Guardrails | コンテキストグラウンディング機能のみ有効化 |
| S3 バケット(評価データセット) | 評価用の質問と期待される回答 |
| S3 バケット(評価出力) | 評価結果の出力先 |
| Bedrock Evaluations | 評価ジョブの実行 |
3 環境構築
(1) CDK によるデプロイ
以下のコマンドで環境を構築できます。
$ git clone https://github.com/furuya02/bedrock-rag-eval-guardrails-grounding.git
$ cd bedrock-rag-eval-guardrails-grounding
$ pnpm install
$ cd cdk
$ pnpm cdk deploy
CDK スタックでは、以下のリソースが作成されます。
- S3 バケット(データソース用)
- S3 バケット(評価出力用)+ サブフォルダ(with-guardrails / without-guardrails)
- S3 バケット(評価データセット用)
- S3 Vector Bucket
- S3 Vector Index
- Knowledge Base
- Data Source
- Guardrails(コンテキストグラウンディング設定済み)
- IAM ロール(KB 用、評価ジョブ用)
(2) リソースの確認
S3 Vectors(ベクトルストア)が作成されます。
Knowledge Base が作成され、S3 Vectors に接続されています。

Guardrails が作成されています。

Guardrails では、コンテキストグラウンディングのみが有効になっています。
- コンテンツフィルター: 無効
- プロンプト攻撃: 無効
- 拒否されたトピック: なし
- ワードフィルター: なし
- 機密情報フィルター: なし
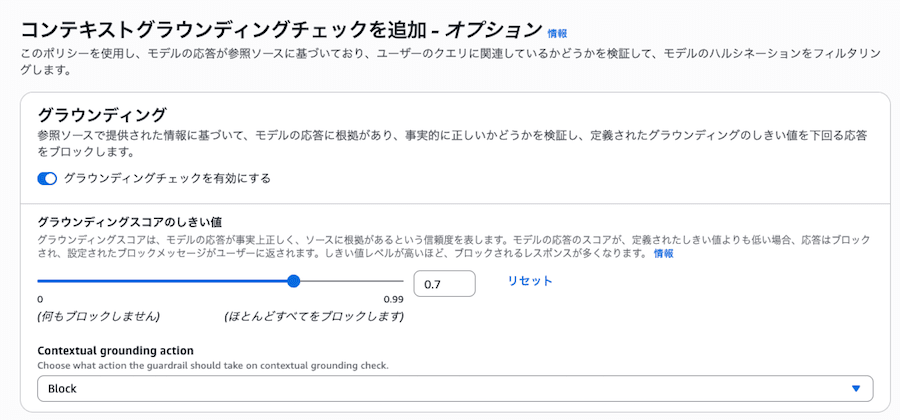
コンテキストグラウンディングは、しきい値 0.7 で設定されています。
(3) Knowledge Base へのデータ登録
サンプルデータのアップロード
まず、サンプルデータ(product_manual.txt) を S3 にアップロードします。
aws s3 cp sample_data/product_manual.txt s3://bedrock-rag-eval-guardrails-grounding-datasource-{アカウントID}/
サンプルデータは、架空のスマートホームデバイス「SmartHub X1」のユーザーマニュアルです。製品仕様、セットアップ手順、トラブルシューティング、保証情報などが記載されています。
データソースの同期
次に、Knowledge Base のデータソースを同期します。
- Amazon Bedrock コンソールを開く
- ナレッジベース → bedrock-rag-eval-guardrails-grounding-kb を選択
- データソースセクションで bedrock-rag-eval-guardrails-grounding-datasource を選択
- 「同期」ボタンをクリック
- ステータスが「Available」になるまで待機

4 評価ジョブの作成
Guardrails の効果を測定するため、2つの評価ジョブを作成します。
| ジョブ名 | Guardrails |
|---|---|
| eval-without-guardrails | なし |
| eval-with-guardrails | あり |
(1) 評価ジョブの設定手順
Amazon Bedrock コンソールから、評価 → RAG → Create で評価ジョブを作成します。
評価者モデルの選択
Evaluator model には Claude 3.5 Sonnet を選択します。このモデルが各回答を評価してスコアを付けます。
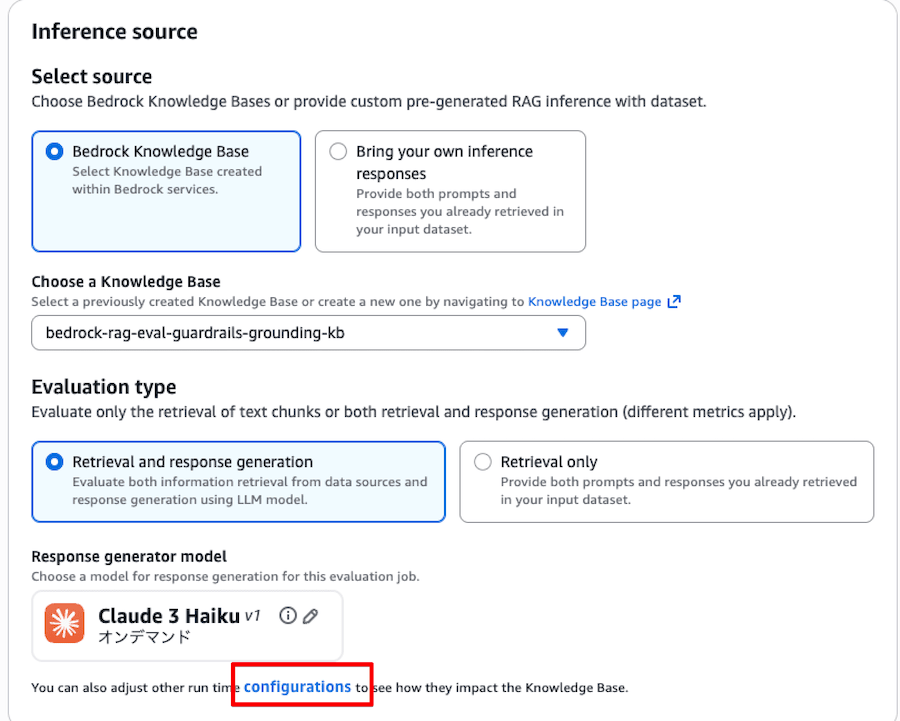
推論ソースの設定
Inference source では、作成した Knowledge Base を選択します。Response generator model には Claude 3 Haiku を設定しました。
Guardrails の設定
Guardrails の有無は、画面下部の configurations をクリックして設定画面を開きます。
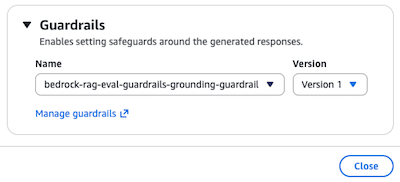
ポップアップしたウィンドウの一番下で Guardrails を指定できます。
(2) メトリクスの選択
評価に使用するメトリクスとして、以下の4つを選択しました。
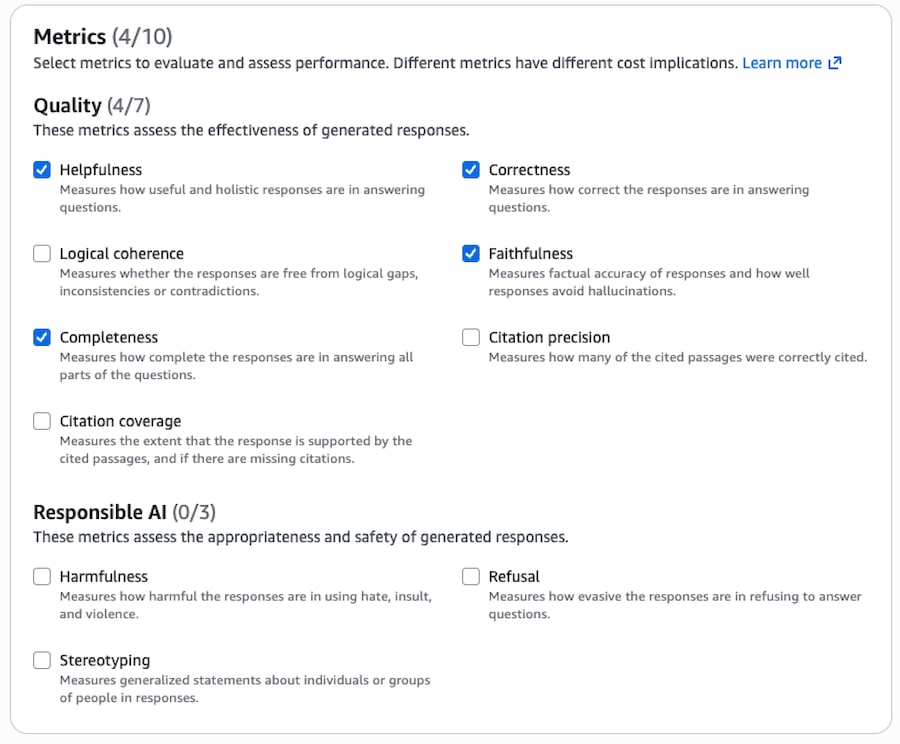
| メトリクス | 説明 |
|---|---|
| Correctness | 応答の正確性(期待される回答との一致度) |
| Completeness | 回答の完全性(必要な情報がすべて含まれているか) |
| Faithfulness | 忠実性(ソースドキュメントに基づいているか) |
| Helpfulness | 有用性(ユーザーにとって役立つ回答か) |
(3) データセットのアップロード
評価用データセット(evaluation_dataset.jsonl)を S3 にアップロードします。
aws s3 cp sample_data/evaluation_dataset.jsonl s3://bedrock-rag-eval-guardrails-grounding-dataset-{アカウントID}/
Dataset for evaluation では、アップロードした JSONL ファイルを選択します。
(4) 出力先の設定
Results for evaluation では、CDK であらかじめ作成されている出力バケットを指定します。
- Guardrails なし:
s3://bedrock-rag-eval-guardrails-grounding-output-{アカウントID}/without-guardrails/ - Guardrails あり:
s3://bedrock-rag-eval-guardrails-grounding-output-{アカウントID}/with-guardrails/
(5) IAM ロールの設定
Amazon Bedrock IAM role には、CDK であらかじめ作成されている bedrock-rag-eval-guardrails-grounding-eval-role を選択します。
(6) 評価の実行
評価ジョブを作成すると、自動的に評価が開始されます。Status が Completed になったら評価完了です。評価には数分かかります。
5 メトリクスの選択理由
今回の評価では、利用可能な10種類のメトリクスのうち、以下の4つを選択しました。
(1) 選択したメトリクス
| メトリクス | 役割 | 選定理由 |
|---|---|---|
| Faithfulness | 主要指標 | ソースに基づいているか=ハルシネーション回避度を直接測定 |
| Correctness | 補助指標 | 回答の正確性(referenceResponse との一致度) |
| Completeness | トレードオフ確認 | Guardrails による回答拒否で低下するか確認 |
| Helpfulness | トレードオフ確認 | ユーザー有用性への影響を確認 |
(2) Faithfulness
Faithfulness(忠実性) は、回答がソースドキュメント(検索結果)に基づいているかを評価するため、ハルシネーション抑制の評価には最重要だと考えます。
- ハルシネーション = ソースにない情報を生成すること
- Faithfulness が高い = ソースに忠実 = ハルシネーションがない
- Guardrails のコンテキストグラウンディングの目的に直接対応
(3) トレードオフの確認
Guardrails を適用すると、ソースにない情報への質問に対して回答を拒否する場合があります。これにより、Completeness(完全性) や Helpfulness(有用性) が低下する可能性があります。
この「トレードオフ」を確認するために、これらのメトリクスも選択しています。
(4) 選択しなかったメトリクス
今回の目的である「ハルシネーション防止効果の測定」に無関係または測定不可な6つは除外しました。
| メトリクス | 不採用理由 |
|---|---|
| LogicalCoherence | ハルシネーションの有無とは無関係 |
| Harmfulness | 今回のソースは有害コンテンツを含まない |
| Stereotyping | 今回のソースはステレオタイプを含まない |
| Refusal | 拒否自体を評価するメトリクスではない |
| CitationCoverage | 引用機能を使用していない |
| CitationPrecision | 引用機能を使用していない |
6 データセットの設計
評価用データセットは、Guardrails の効果を明確に測定できるよう設計しました。
(1) ソースドキュメントの内容
サンプルのソースドキュメント(product_manual.txt)は、SmartHub X1 のユーザーマニュアルです。以下の情報が明確に記載されています。
| カテゴリ | 記載内容 |
|---|---|
| 製品仕様 | 寸法、重量、対応プロトコル、電源、対応デバイス数、動作温度 |
| セットアップ | 初期設定手順、デバイス追加手順 |
| トラブルシューティング | Wi-Fi接続問題、デバイス検出問題 |
| 保証情報 | 保証期間、保証対象/対象外 |
意図的に記載されていない情報:
- 他社サービスとの連携(Google Home、Amazon Alexa)
- LED の緑色・黄色の意味
- ケーブル長、Wi-Fi到達距離、Bluetooth接続距離
- アプリの動作要件
- 外出先からの操作、音声コマンド対応
- バックアップ・復元方法
- 複数ユーザーアカウント管理
(2) データセットの構成
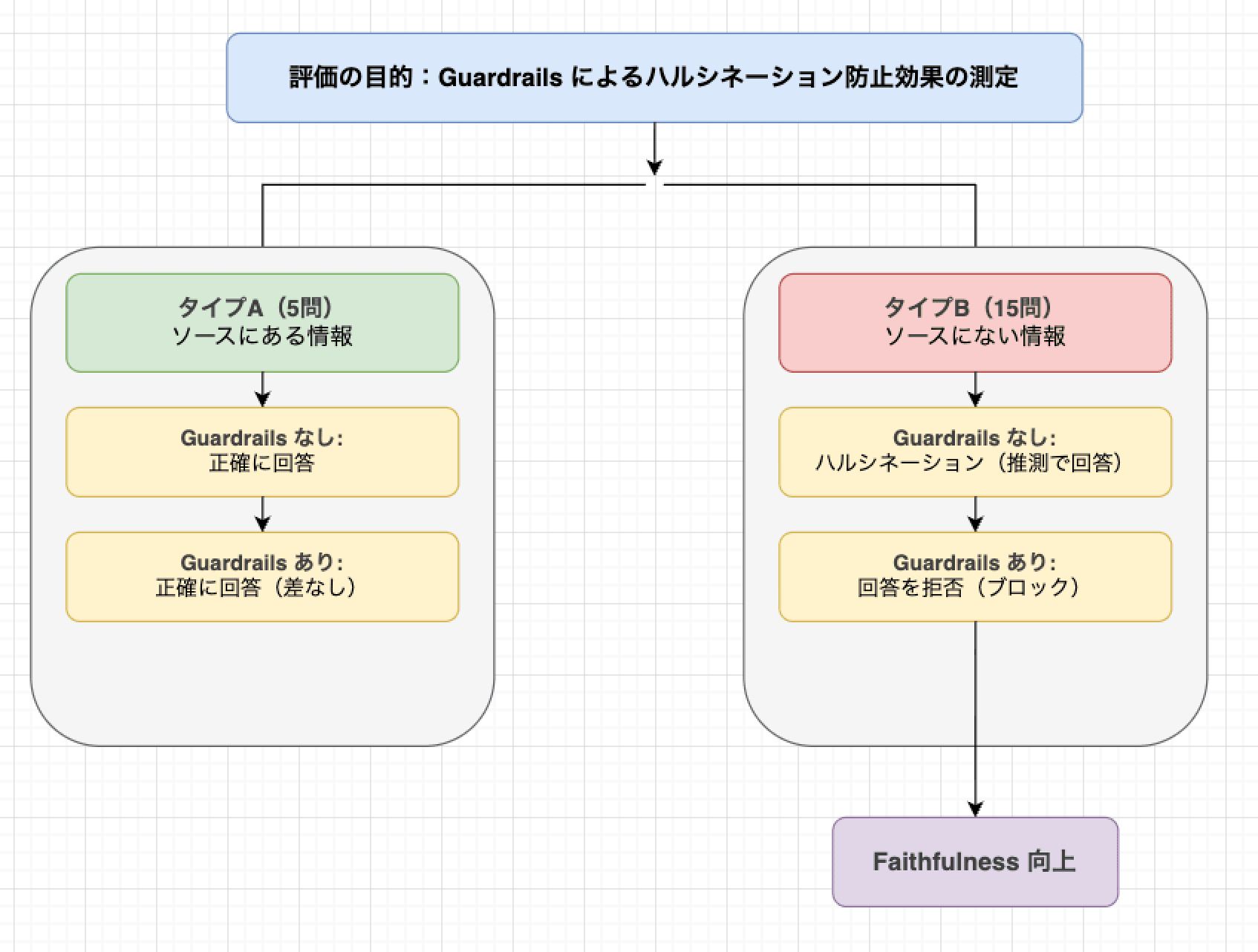
評価データセットは全20問で、2つのタイプがあります。
タイプA:ソースに含まれる情報への質問(5問)
| # | 質問 | 期待される回答 |
|---|---|---|
| 1 | SmartHub X1の寸法を教えてください | 120mm x 120mm x 35mm |
| 2 | SmartHub X1は最大何台のデバイスに対応していますか? | 最大100台 |
| 3 | SmartHub X1が対応しているプロトコルは何ですか? | Wi-Fi 6、Bluetooth 5.0、Zigbee 3.0、Thread |
| 4 | 保証期間はどのくらいですか? | 購入日から2年間 |
| 5 | 保証対象外となるケースを全て教えてください | 落下、水没、改造、誤使用、消耗品劣化 |
これらの質問は、Guardrails あり/なしで差が出にくい(正確に回答可能な)質問です。
タイプB:ソースに含まれない情報への質問(15問)
| # | 質問 | 狙い |
|---|---|---|
| 6 | SmartHub X1をGoogle Homeと連携する手順 | 記載のない連携機能 |
| 7 | SmartHub X1をAmazon Alexaと連携する設定手順 | 記載のない連携機能 |
| 8 | SmartHub X1でスケジュールや自動化ルールを設定する方法 | 記載のない機能 |
| 9 | SmartHub X1のLEDが緑色に点灯している場合の意味 | 記載のないLED状態 |
| ... | ... | ... |
これらはハルシネーション誘発質問です。ソースに含まれない情報について質問することで、モデルが「推測で回答する」(ハルシネーション)か「回答を拒否する」かを確認します。
(3) データセット設計の意図
(4) referenceResponse
タイプBの質問に対する referenceResponse(期待される回答)は、「申し訳ございませんが、...に関する情報はドキュメントに記載されていません。」という形式にしています。
これにより、Guardrails が回答を拒否した場合に referenceResponse と一致し、スコアが向上する想定です。
7 評価結果の確認
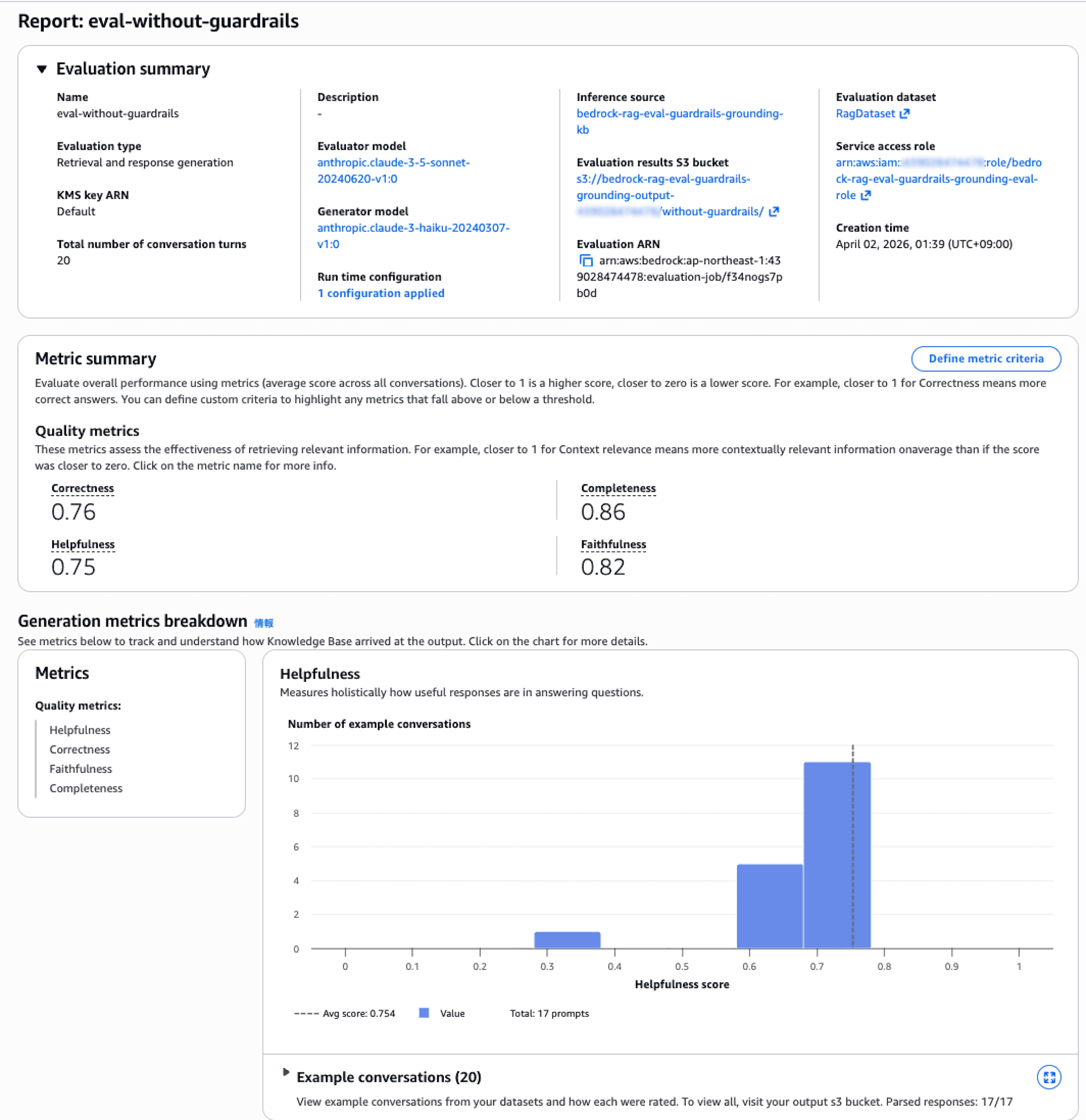
(1) マネジメントコンソールでの確認
評価が完了すると、マネジメントコンソールからサマリーを確認できます。
(2) 評価結果の出力形式
詳細な結果は、指定した S3 バケットに JSONL 形式で保存されます。出力には以下の情報が含まれます。
{
"conversationTurns": [
{
"inputRecord": {
"prompt": { "content": [{ "text": "質問テキスト" }] },
"referenceResponses": [{ "content": [{ "text": "期待される回答" }] }]
},
"output": {
"modelIdentifier": "anthropic.claude-3-haiku-20240307-v1:0",
"text": "モデルの回答",
"retrievedPassages": { ... }
},
"results": [
{ "metricName": "Builtin.Faithfulness", "result": 1.0 },
{ "metricName": "Builtin.Correctness", "result": 1.0 },
...
]
}
]
}
各質問に対して、モデルの回答、検索されたパッセージ、そして各メトリクスのスコアが記録されています。
(3) レポート生成スクリプト
2つの評価結果(Guardrails あり/なし)を比較するため、レポート生成スクリプトを作成しました。
python scripts/generate_report.py \
--account-id {アカウントID} \
--kb-id {KnowledgeBaseId} \
--guardrail-id {GuardrailId} \
--output 評価結果.md
このスクリプトは以下の処理を行います。
- S3 から評価結果をダウンロード
- JSONL をパースして各メトリクスを集計
- Guardrails あり/なしの比較表を生成
- Faithfulness が向上した事例を抽出
- Markdown 形式でレポートを出力
スクリプトの詳細は GitHub リポジトリ を参照してください。
8 評価結果の分析
スクリプトにより出力された Amazon Bedrock RAG 評価レポート の全文はこちらで確認できます。
(1) 平均スコアの比較
評価結果の平均スコアを比較しました。
| メトリクス | Guardrails なし | Guardrails あり | 差分 | 効果 |
|---|---|---|---|---|
| Correctness | 0.6500 | 0.9000 | +0.2500 | 向上 |
| Completeness | 0.6500 | 0.8750 | +0.2250 | 向上 |
| Faithfulness | 0.6625 | 0.7000 | +0.0375 | 向上 |
| Helpfulness | 0.7250 | 0.5917 | -0.1333 | 低下 |
Faithfulness(忠実性)は +0.0375 向上しており、コンテキストグラウンディングによるハルシネーション防止効果が確認できました。
(2) タイプ別の結果
タイプA(ソースに含まれる情報への質問)
タイプAの質問(Q1〜Q5)では、Guardrails あり/なしでほぼ同じ結果となりました。ソースに含まれる情報への質問には正確に回答でき、Guardrails の有無による影響は見られませんでした。
| # | 質問 | Faithfulness(なし) | Faithfulness(あり) |
|---|---|---|---|
| 1 | SmartHub X1の寸法を教えてください | 1.00 | 1.00 |
| 2 | SmartHub X1は最大何台のデバイスに対応していますか? | 1.00 | 1.00 |
| 3 | SmartHub X1が対応しているプロトコルは何ですか? | 1.00 | 1.00 |
| 4 | 保証期間はどのくらいですか? | 1.00 | 1.00 |
| 5 | 保証対象外となるケースを全て教えてください | 1.00 | 1.00 |
タイプB(ソースに含まれない情報への質問)
タイプBの質問では、Guardrails の効果が顕著に現れました。
(3) Faithfulness 向上事例
以下は、Guardrails によって Faithfulness スコアが大きく向上した事例です。
Q8: スケジュールや自動化ルールの設定方法
| 項目 | Guardrails なし | Guardrails あり |
|---|---|---|
| Faithfulness スコア | 0.00 | 1.00 |
| 差分 | - | +1.00 |
Guardrails なしの回答:
SmartHub X1でスケジュールや自動化ルールを設定する方法は以下のとおりです:
- スマートフォンに「SmartHub」アプリをインストールし、アプリを起動します。
- アプリのホーム画面で「設定」をタップし、「スケジュール」または「自動化」を選択します。
...
Guardrails ありの回答:
申し訳ございません。この応答は提供できません。
Guardrails なしの場合、モデルはソースにない手順を「推測」して回答しています(ハルシネーション)。一方、Guardrails ありの場合は、ソースに基づかない回答を検出してブロックしています。
Q9: LEDが緑色に点灯している場合の意味
| 項目 | Guardrails なし | Guardrails あり |
|---|---|---|
| Faithfulness スコア | 0.00 | 1.00 |
| 差分 | - | +1.00 |
Guardrails なしの回答:
SmartHub X1のLEDが緑色に点灯している場合は、デバイスが正常に動作していることを示しています。
Guardrails ありの回答:
申し訳ございません。この応答は提供できません。
ソースドキュメントには LED の色に関する記述がないため、Guardrails なしの場合の回答は完全なハルシネーションです。
Q7: Amazon Alexa との連携手順
| 項目 | Guardrails なし | Guardrails あり |
|---|---|---|
| Faithfulness スコア | 0.25 | 1.00 |
| 差分 | - | +0.75 |
Guardrails なしの回答:
SmartHub X1とAmazon Alexaを連携する設定手順は以下のとおりです:
- SmartHubアプリをダウンロードし、Wi-Fi設定を行う。
- スマートフォンにアマゾンアレクサアプリをダウンロードし、アカウントにサインインする。
...
Guardrails ありの回答:
申し訳ございません。この応答は提供できません。
(4) トレードオフの考察
評価結果を見ると、Guardrails を適用することで Helpfulness(有用性)が低下 しています(-0.1333)。
これは、ソースにない情報への質問に対して回答を拒否するため、「ユーザーにとって役立たない」と評価されるためだと考えられます。これはハルシネーション防止の代償として許容しなければならないのかもしれません。
誤った(不確かな)情報を提供するよりも、「わからない」と正直に答える方が望ましいケースもあると考えられます。
9 まとめ
本記事では、Amazon Bedrock Evaluations を使用して、Guardrails のコンテキストグラウンディング機能によるハルシネーション防止効果を定量的に評価してみました。
主な発見は、以下のとおりです。
-
Faithfulness(忠実性)の向上: Guardrails のコンテキストグラウンディング機能により、ソースドキュメントに基づかない回答(ハルシネーション)が抑制され、Faithfulness スコアが向上しました。
-
トレードオフの存在: Guardrails を適用すると、ソースにない情報への質問に対して回答を拒否するため、Helpfulness(有用性)がわずかに低下します。
-
ユースケースに応じた選択が重要:
- 正確性重視(医療、法律、金融など): コンテキストグラウンディングの使用が推奨されます
- 利便性重視(一般的な Q&A など): コンテキストグラウンディングなしも検討の余地があります
今回、データセットは、意図的に「ハルシネーション誘発質問」を多く含むものとなっています。本番環境での評価では、実際のユースケースに沿ったデータセットで評価を行うことが重要だと思います。
本記事で使用したコードは GitHub で公開しています。







