![[プレビュー]Amazon Bedrock KnowledgeBaseとAmazon S3 Vectorsをクロスアカウント接続してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e3065182082062711612153bbdcf1d96/c04359de689df2f56eb066576ab63fb5/amazon-bedrock?w=3840&fm=webp)
[プレビュー]Amazon Bedrock KnowledgeBaseとAmazon S3 Vectorsをクロスアカウント接続してみた
はじめに
先日 Amazon S3 Vectorsがプレビューとして発表されました。
弊社でも早速ブログが書かれています。
社内でも一部界隈で盛り上がりを見せており、その中でクロスアカウント対応しているのか話題になりました。
今回は上記を実際に検証してみたのでブログにまとめてみます。
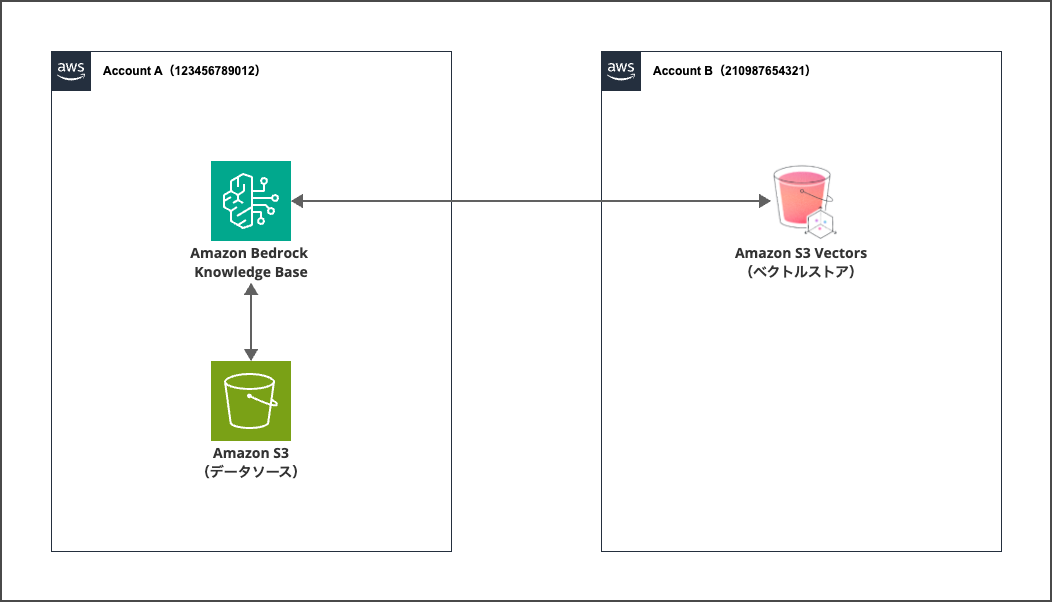
構成
構成は以下の通りとなっており、ベクトルストアであるAmazon S3 Vectorsのみ別アカウントから呼び出します。
本題ではないので今回は実施しませんが、データソースのS3を別アカウントに配置しても問題ありません。
やってみた
ベクトルバケットの作成(アカウントB)
まずはじめにベクトルバケットの作成を行います。
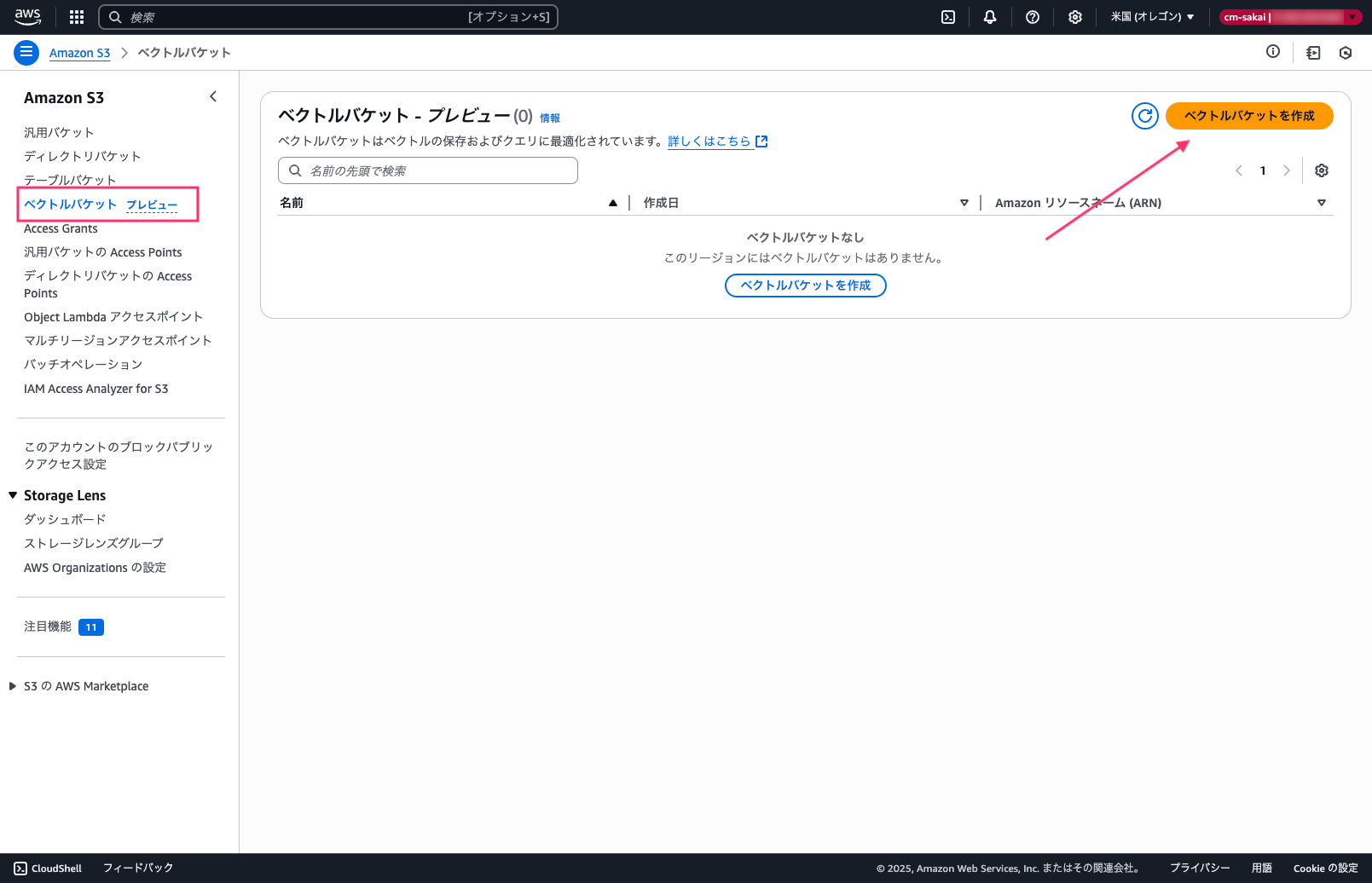
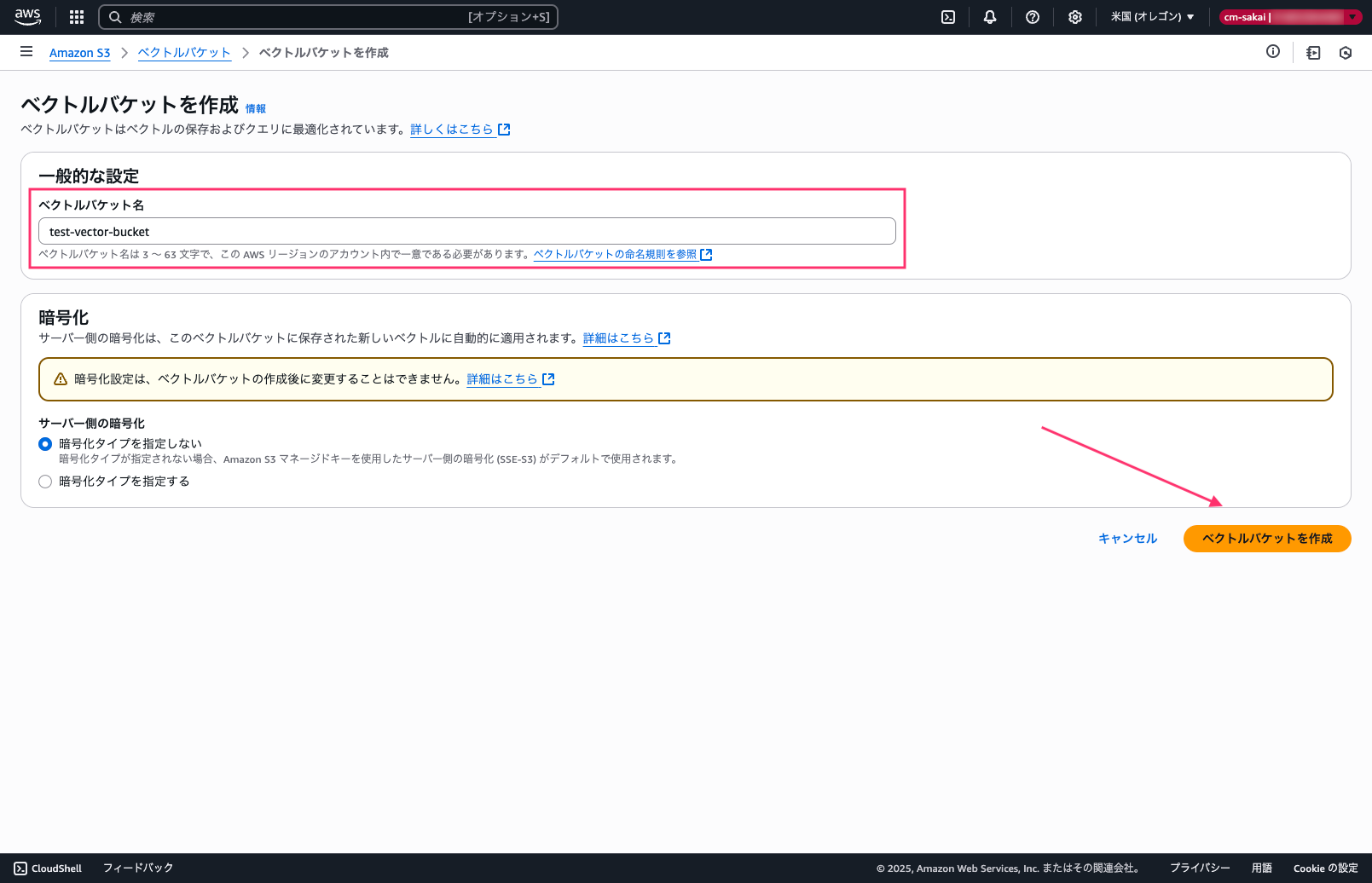
バケット名はAWSリージョンのアカウント内で一意にする必要があります。
ベクトルインデックスの作成(アカウントB)
ベクトルバケットの作成が終わったらインデックスの作成を行います。
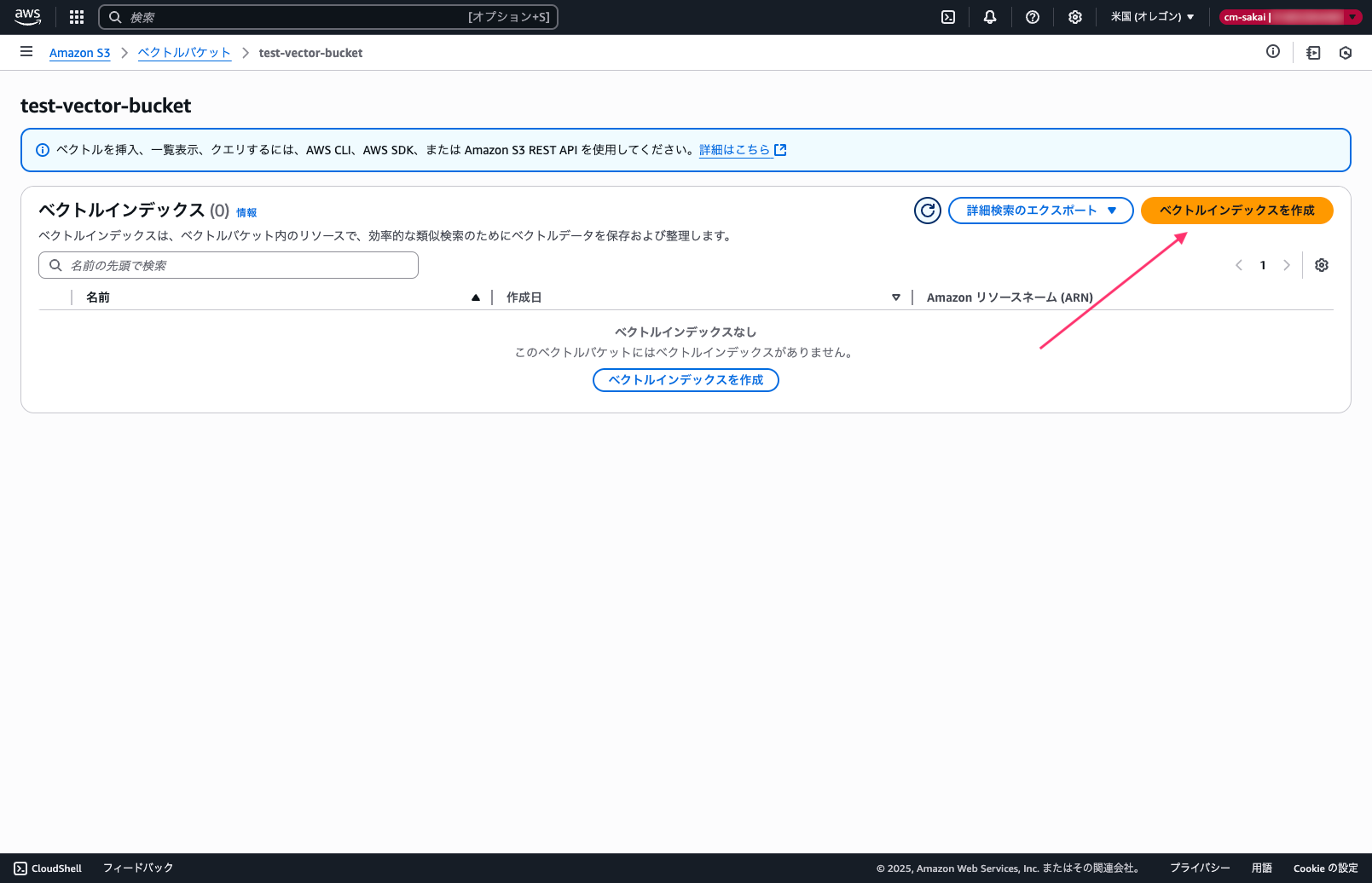
ベクトルバケット内で一意のインデックス名を設定し、ディメンションは1024に設定します。(今回は埋め込みモデルにTitan Text Embeddingsv2を使用するので1024にしています)
その他の設定はデフォルトのままインデックスを作成します。
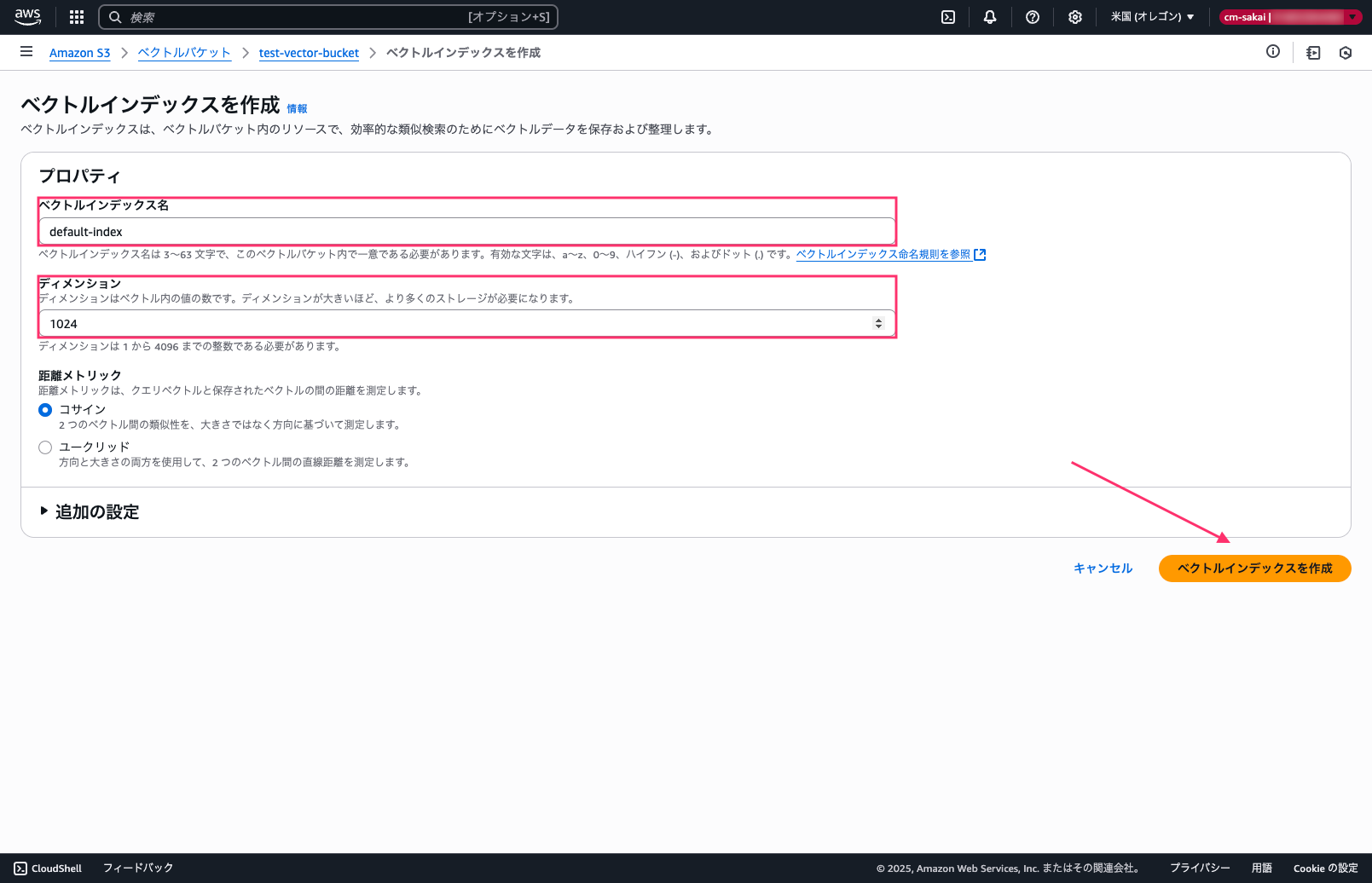
バケットポリシーの追加(アカウントB)
最後にバケットポリシーを設定して終了です。
7/18時点ではAWS CLIでのみポリシーの追加が可能です。
aws s3vectors put-vector-bucket-policy \
--vector-bucket-name <ベクトルバケット名> \
--policy file://bucket-policy.json \
--region us-west-2
bucket-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "CrossAccountAccess",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:root"
},
"Action": "s3vectors:*",
"Resource": "arn:aws:s3vectors:us-west-2:210987654321:bucket/s3-vector-bucket"
},
{
"Sid": "BedrockServiceAccess",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/AmazonBedrockExecutionRoleForKnowledgeBase"
},
"Action": [
"s3vectors:GetIndex",
"s3vectors:QueryVectors",
"s3vectors:PutVectors",
"s3vectors:GetVectors",
"s3vectors:DeleteVectors"
],
"Resource": [
"arn:aws:s3vectors:us-west-2:210987654321:bucket/s3-vector-bucket",
"arn:aws:s3vectors:us-west-2:210987654321:bucket/s3-vector-bucket/*"
]
}
]
}
IAMロールの作成(アカウントA)
以下のコマンドを実行してKnowledgeBaseで使うIAMロールを作成します。
aws iam create-role \
--role-name AmazonBedrockExecutionRoleForKnowledgeBase \
--assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'
続けてIAMポリシーを設定します。
aws iam create-policy \
--policy-name AmazonBedrockExecutionRoleForKnowledgeBasePolicy \
--policy-document file://iam-policy.json
iam-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockInvokeModelStatement",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel"
],
"Resource": [
"arn:aws:bedrock:us-west-2::foundation-model/amazon.titan-embed-text-v2:0"
]
},
{
"Sid": "S3ListBucketStatement",
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::kb-documents-bucket-123456789012"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"123456789012"
]
}
}
},
{
"Sid": "S3GetObjectStatement",
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::kb-documents-bucket-123456789012/*"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"123456789012"
]
}
}
},
{
"Sid": "S3VectorsPermissions",
"Effect": "Allow",
"Action": [
"s3vectors:GetIndex",
"s3vectors:QueryVectors",
"s3vectors:PutVectors",
"s3vectors:GetVectors",
"s3vectors:DeleteVectors"
],
"Resource": "arn:aws:s3vectors:us-west-2:210987654321:bucket/s3-vector-bucket/index/*"
}
]
}
最後に作成したポリシーをアタッチします。
aws iam attach-role-policy \
--role-name AmazonBedrockExecutionRoleForKnowledgeBasePolicy \
--policy-arn arn:aws:iam::123456789012:role/AmazonBedrockExecutionRoleForKnowledgeBase
データソース用S3バケットの作成(アカウントA)
以下のコマンドでS3バケットを作成します。
aws s3api create-bucket --bucket <任意のバケット名> --region us-west-2 \
--create-bucket-configuration LocationConstraint=us-west-2 --no-cli-pager
ナレッジベースの作成(アカウントA)
コンソールからナレッジベースの作成を試みたのですが、既存のベクトルストア(ARN)に文字入力ができずS3を参照しか選べませんでした。
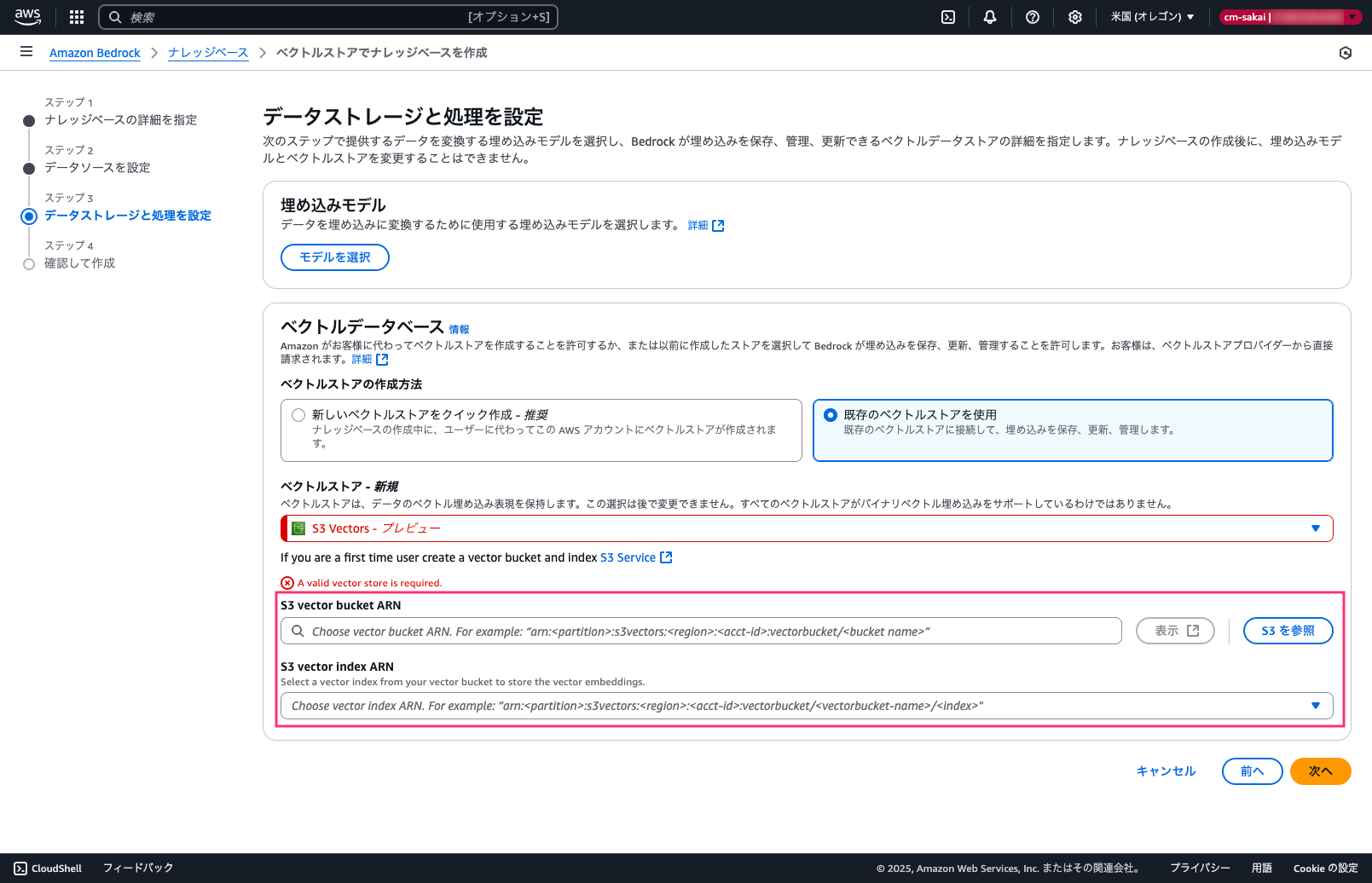
参照の場合は別アカウントのS3はもちろん選べませんので、今回はPython SDK(boto3)を使ってナレッジベースを作成することにします。
Claude Codeに生成してもらったコードを記載しておきますが、本コードを実行する際は自己責任でお願いします。
python3 create-knowledge-base.py
create-knowledge-base.py
import logging
import boto3
import json
from botocore.exceptions import ClientError
"""
アカウントA: 123456789012
アカウントB: 210987654321
"""
def create_knowledge_base(bedrock_agent_client):
"""
Create a knowledge base with S3 vector storage
:param bedrock_agent_client: boto3 Bedrock Agent client
:return: Knowledge base ID if created successfully, else None
"""
try:
# Knowledge base configuration
knowledge_base_config = {
"type": "VECTOR",
"vectorKnowledgeBaseConfiguration": {
"embeddingModelArn": "arn:aws:bedrock:us-west-2::foundation-model/amazon.titan-embed-text-v2:0"
},
}
# Storage configuration for S3 Vector
storage_config = {
"type": "S3_VECTORS",
"s3VectorsConfiguration": {
"indexArn": "arn:aws:s3vectors:us-west-2:210987654321:bucket/s3-vector-bucket/index/default-index",
"vectorBucketArn": "arn:aws:s3vectors:us-west-2:210987654321:bucket/s3-vector-bucket",
},
}
# Create the knowledge base
response = bedrock_agent_client.create_knowledge_base(
name="test-kb-s3-vectors",
description="Knowledge base using S3 Vector storage for cross-account setup",
roleArn="arn:aws:iam::123456789012:role/AmazonBedrockExecutionRoleForKnowledgeBase",
knowledgeBaseConfiguration=knowledge_base_config,
storageConfiguration=storage_config,
)
knowledge_base_id = response["knowledgeBase"]["knowledgeBaseId"]
logging.info(
f"Knowledge base created successfully with ID: {knowledge_base_id}"
)
return knowledge_base_id
except ClientError as e:
logging.error(f"Failed to create knowledge base: {e}")
return None
def create_data_source(bedrock_agent_client, knowledge_base_id):
"""
Create a data source for the knowledge base
:param bedrock_agent_client: boto3 Bedrock Agent client
:param knowledge_base_id: ID of the knowledge base
:return: Data source ID if created successfully, else None
"""
try:
# Data source configuration
data_source_config = {
"type": "S3",
"s3Configuration": {
"bucketArn": "arn:aws:s3:::kb-documents-bucket-123456789012",
"inclusionPrefixes": ["documents/"],
},
}
# Create the data source
response = bedrock_agent_client.create_data_source(
knowledgeBaseId=knowledge_base_id,
name="data-source",
dataSourceConfiguration=data_source_config,
)
data_source_id = response["dataSource"]["dataSourceId"]
logging.info(f"Data source created successfully with ID: {data_source_id}")
return data_source_id
except ClientError as e:
logging.error(f"Failed to create data source: {e}")
return None
def start_ingestion_job(bedrock_agent_client, knowledge_base_id, data_source_id):
"""
Start an ingestion job to process documents in the data source
:param bedrock_agent_client: boto3 Bedrock Agent client
:param knowledge_base_id: ID of the knowledge base
:param data_source_id: ID of the data source
:return: Ingestion job ID if started successfully, else None
"""
try:
response = bedrock_agent_client.start_ingestion_job(
knowledgeBaseId=knowledge_base_id, dataSourceId=data_source_id
)
ingestion_job_id = response["ingestionJob"]["ingestionJobId"]
logging.info(f"Ingestion job started successfully with ID: {ingestion_job_id}")
return ingestion_job_id
except ClientError as e:
logging.error(f"Failed to start ingestion job: {e}")
return None
if __name__ == "__main__":
# Configure logging
logging.basicConfig(level=logging.INFO, format="%(levelname)s: %(message)s")
# Create Bedrock Agent client
bedrock_agent_client = boto3.client("bedrock-agent", region_name="us-west-2")
# Create knowledge base
knowledge_base_id = create_knowledge_base(bedrock_agent_client)
if knowledge_base_id:
print(f"Knowledge base created successfully with ID: {knowledge_base_id}")
# Create data source
data_source_id = create_data_source(
bedrock_agent_client=bedrock_agent_client,
knowledge_base_id=knowledge_base_id,
)
if data_source_id:
print(f"Data source created successfully with ID: {data_source_id}")
# Start ingestion job
ingestion_job_id = start_ingestion_job(
bedrock_agent_client=bedrock_agent_client,
knowledge_base_id=knowledge_base_id,
data_source_id=data_source_id,
)
if ingestion_job_id:
print(f"Ingestion job started successfully with ID: {ingestion_job_id}")
print(
"Documents will be processed and vectorized into the S3 Vector bucket"
)
else:
print("Failed to start ingestion job")
else:
print("Failed to create data source")
else:
print("Failed to create knowledge base")
正常実行できていればナレッジベースが作成されているはずです。
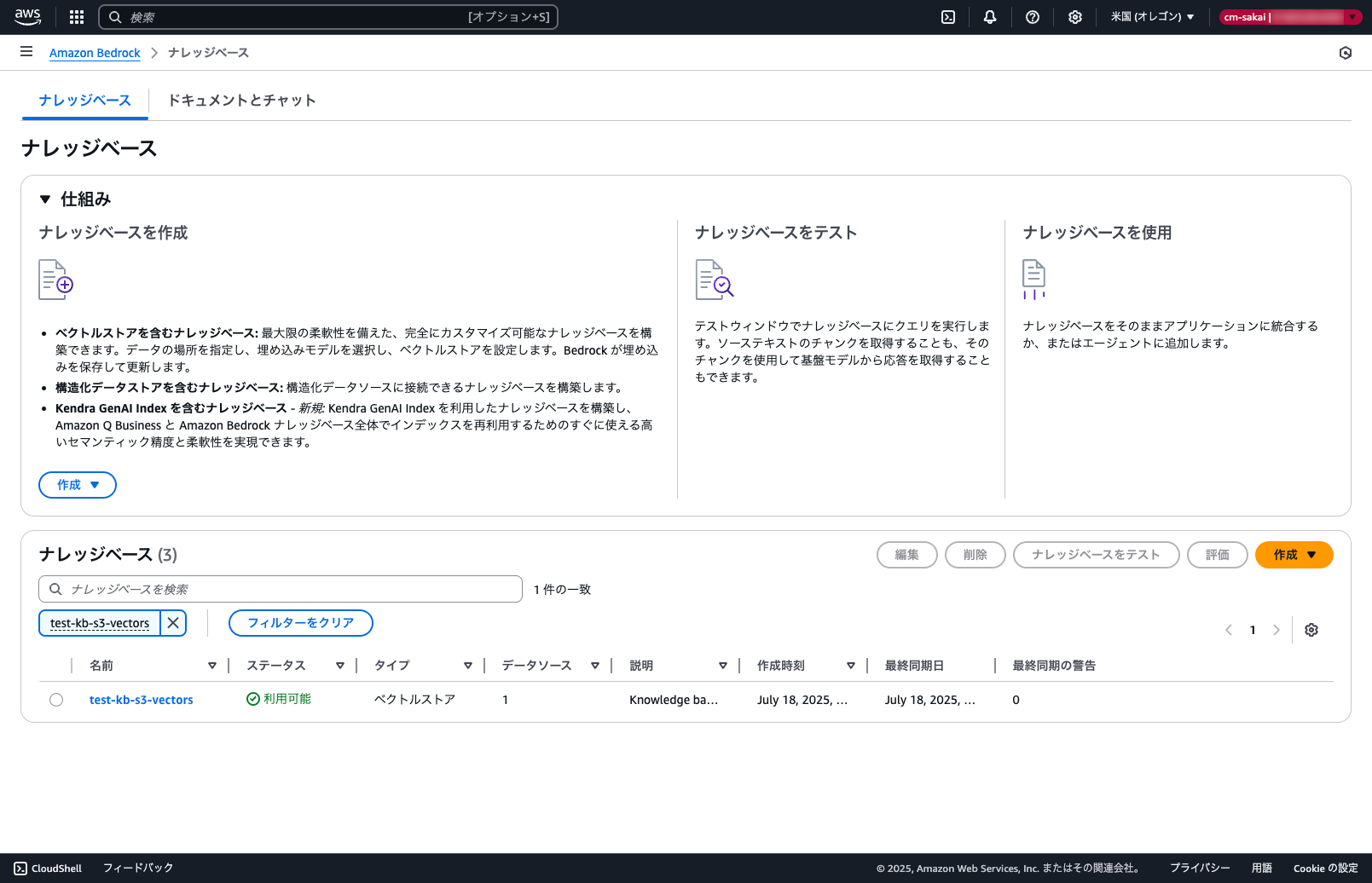
動作確認
動作確認としてクロスアカウントで構築したナレッジベースに問い合わせをしてみます。
適当なドキュメントをデータソースのS3にアップロードして同期します。
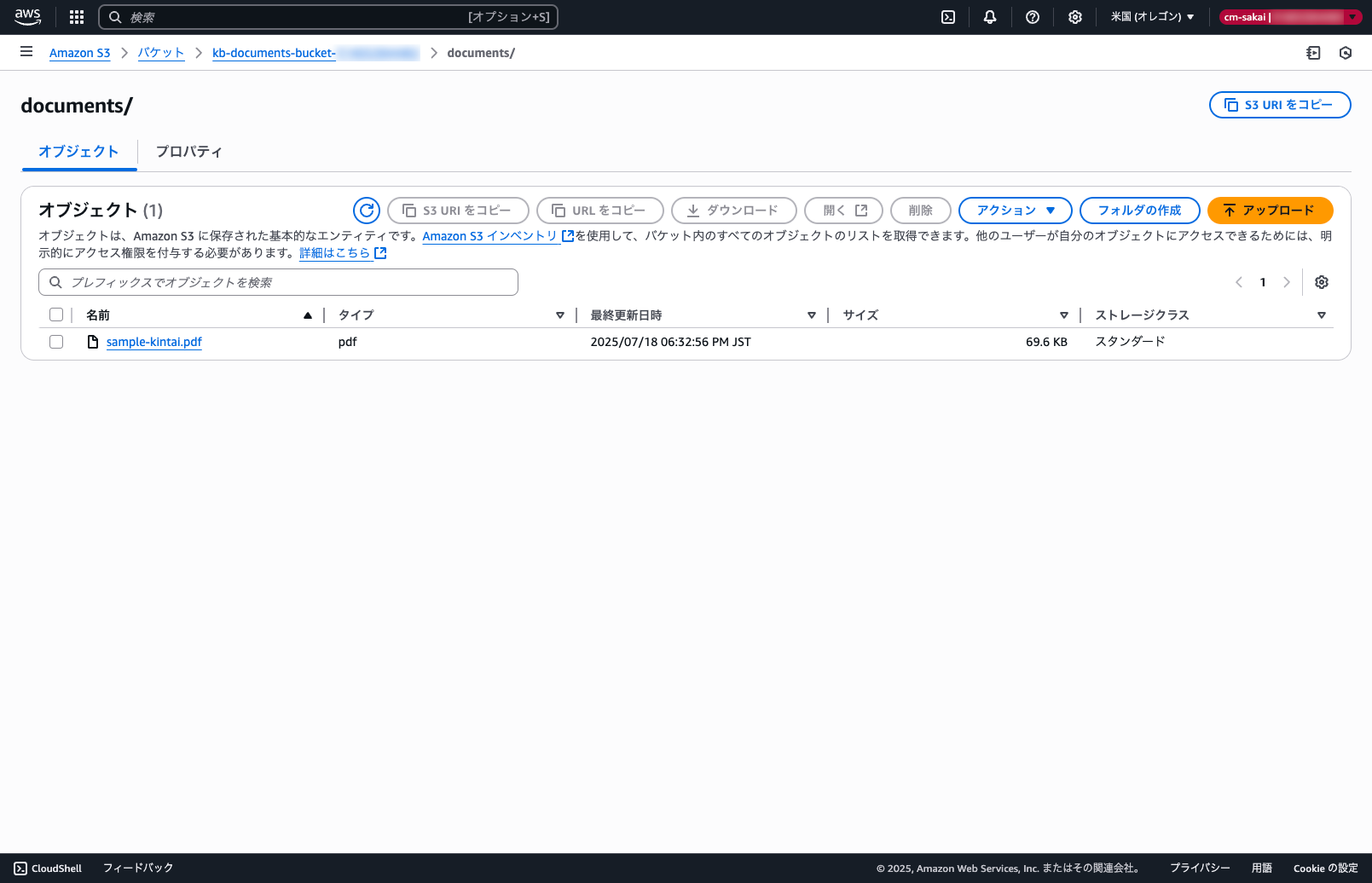
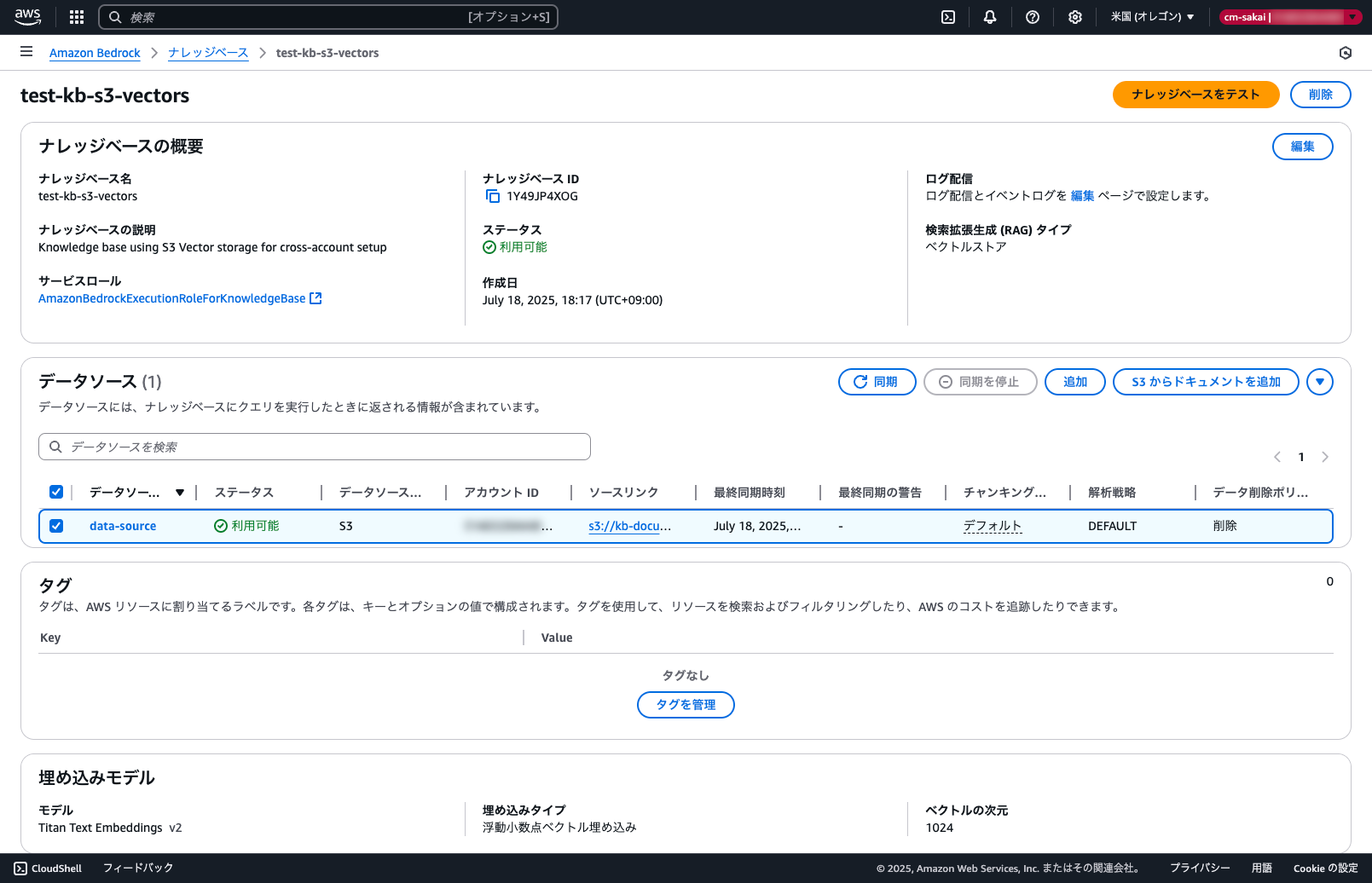
ナレッジベースをテストに進み実際に問い合わせを行ってみます。
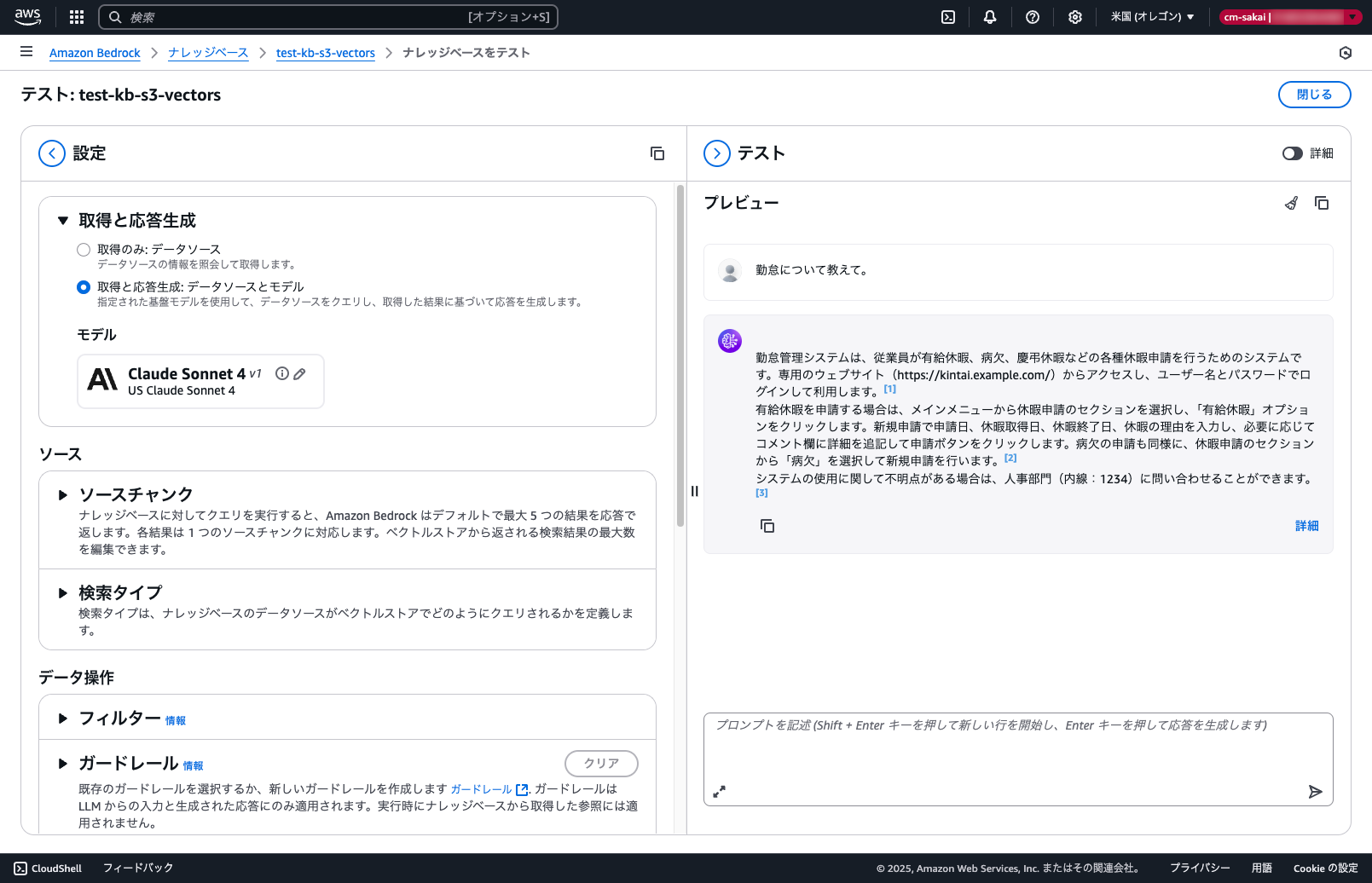
同期したドキュメントから回答が生成されていることが確認できました。
最後にアカウントBのベクトルバケットのベクトルデータを確認してみます。
aws s3vectors list-vectors \
--vector-bucket-name <ベクトルバケット名> \
--index-name <ベクトルインデックス名> \
--return-data \
--region us-west-2
データが格納されていれば以下のようなレスポンスになるはずです。
list-vectorsのレスポンス例
まとめ
今回はプレビューとして発表されたAmazon S3 VectorsとAmazon Bedrock KnowledgeBaseをクロスアカウント接続してみました。
CLIやAPIのみ対応している都合上手順が煩雑になっていますが、IaCに対応したらこのあたりは解消できそうですね。
あくまでプレビュー時点での検証結果のため、GA時には変更される可能性はあるので注意が必要です。
どなたかの参考になれば幸いです。








