
Amazon CloudWatch クエリアラームが個別メトリクスの監視に対応したので試してみた
こんにちは。テクニカルサポートチームのShiinaです。
はじめに
CloudWatch で EC2 を監視する際、インスタンスごとにアラームを設定・管理するのに苦労されていませんか?
先日、Amazon CloudWatch がついに複数の個別メトリクスを単一のアラームで監視できるようになりました。
これにより、Auto Scaling などで動的に増減するリソースに対しても、監視漏れを防げます。
都度アラームを作成する必要がないため、運用負荷を大幅に削減できるようになります。
早速、GROUP BY と ORDER BY を使った Metrics Insights クエリで、動的リソースの監視を試してみました。
やってみた
今回は Auto Scaling で管理されている EC2 インスタンスの StatusCheckFailed メトリクスに対して、個別に評価を行う単一の CloudWatch アラームを設定してみました。
前提
- Auto Scaling グループを作成し、EC2 インスタンスリソースを用意
- 通知用の E メールがエンドポイントとなる SNSトピックを用意
アラームを作成する
-
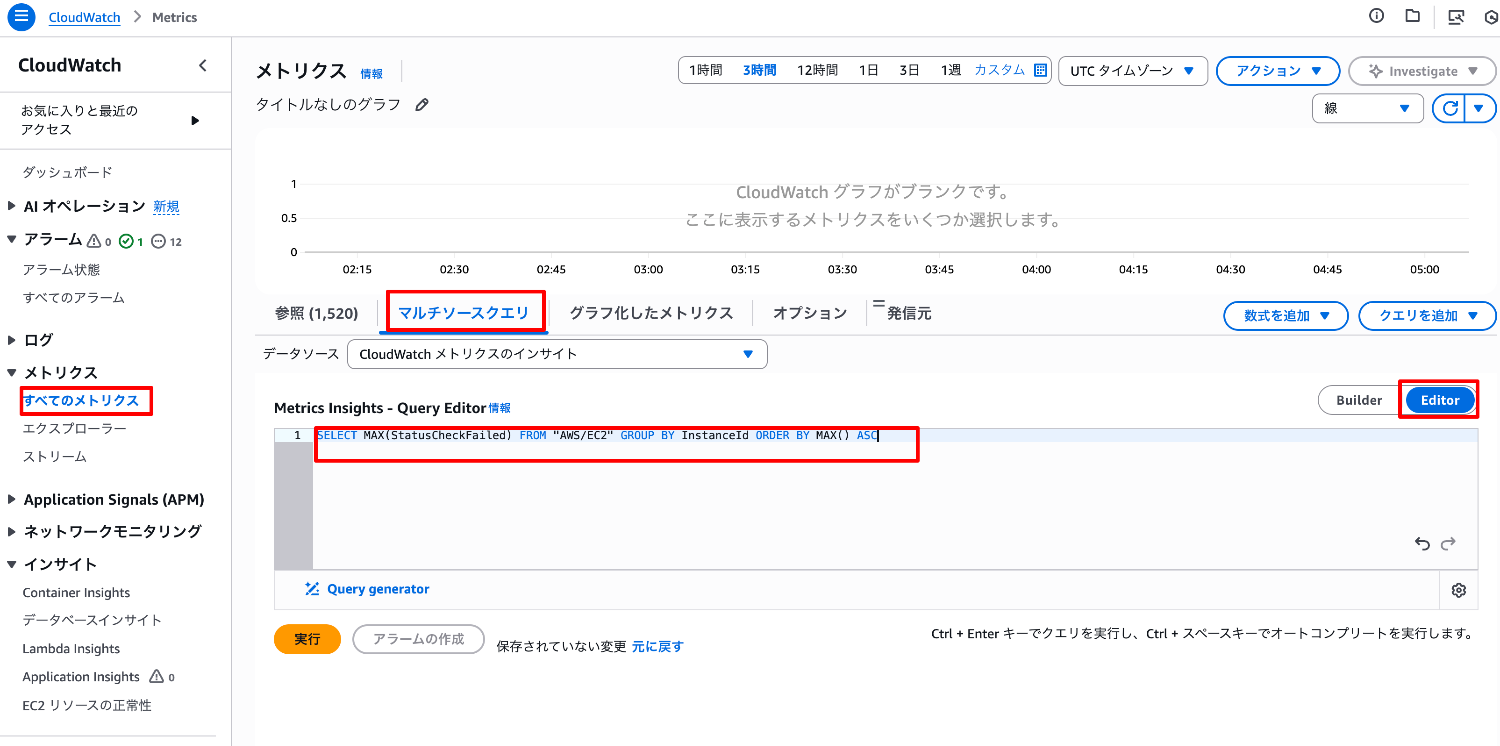
CloudWatch コンソールのナビゲーションペインより[すべてのメトリクス]を選択します。
-
マルチソースクエリタブを選択し、Editor に切り替え、以下のクエリ条件を入力します。
SELECT MAX(StatusCheckFailed) FROM "AWS/EC2" GROUP BY InstanceId ORDER BY MAX() ASC
-
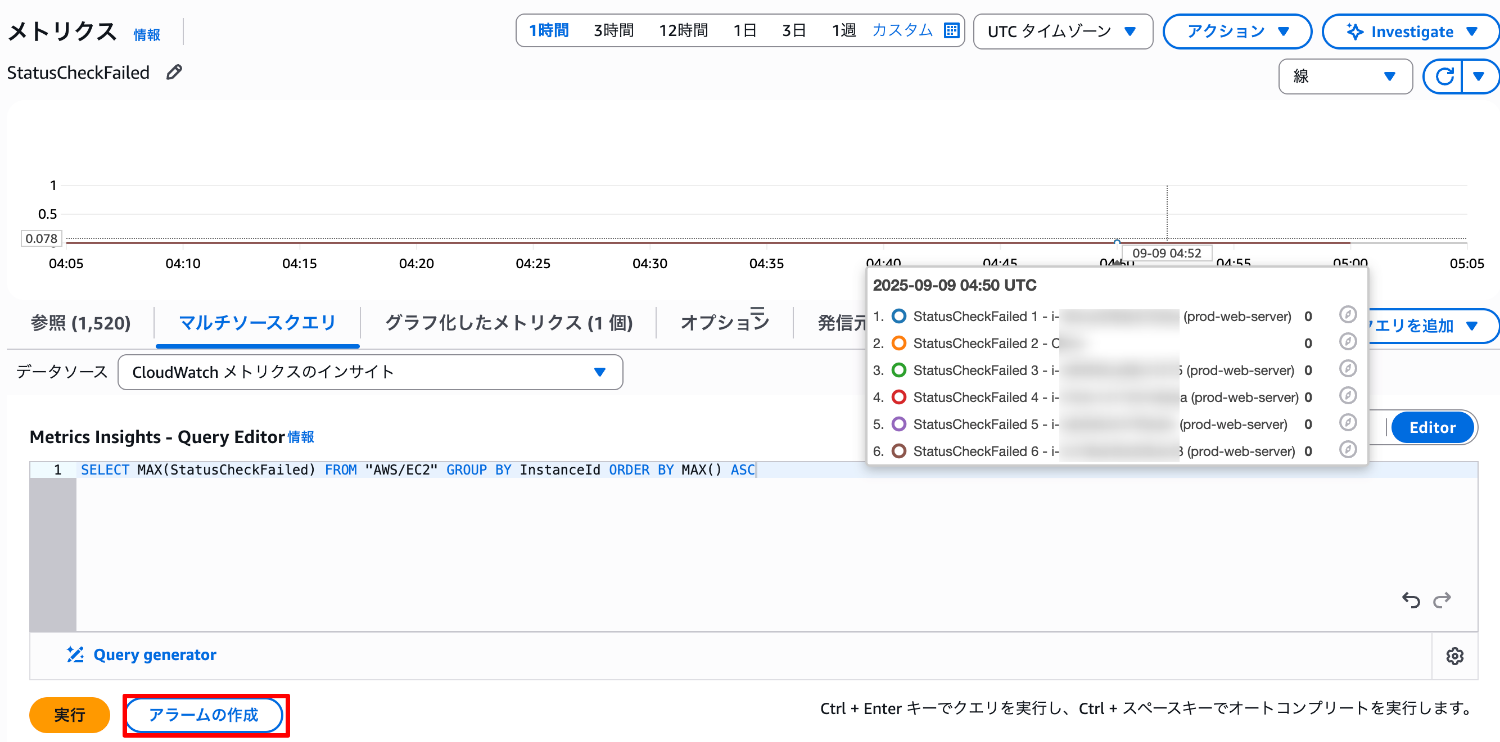
[実行]を選択し、各インスタンスID の StatusCheckFailed メトリクスの値がグラフに表示されることを確認します。
-
[アラームの作成]を選択します。
-
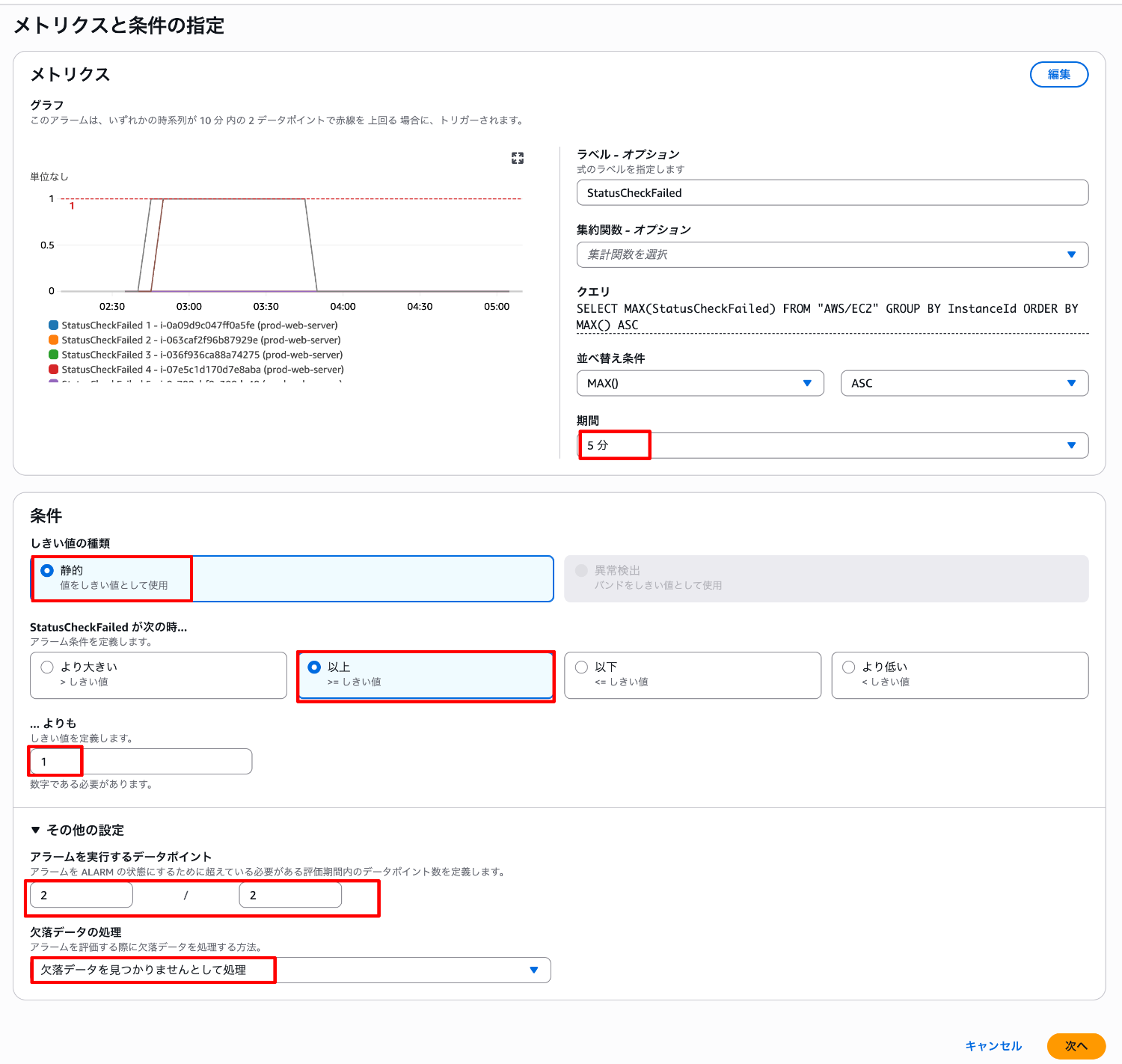
期間、しきい値、データポイントなどの条件を指定します。今回は以下の条件としました。
- 期間:5分
- しきい値:>=1
- データポイント:2/2
- 欠落データの処理:欠落データを見つかりませんとして処理
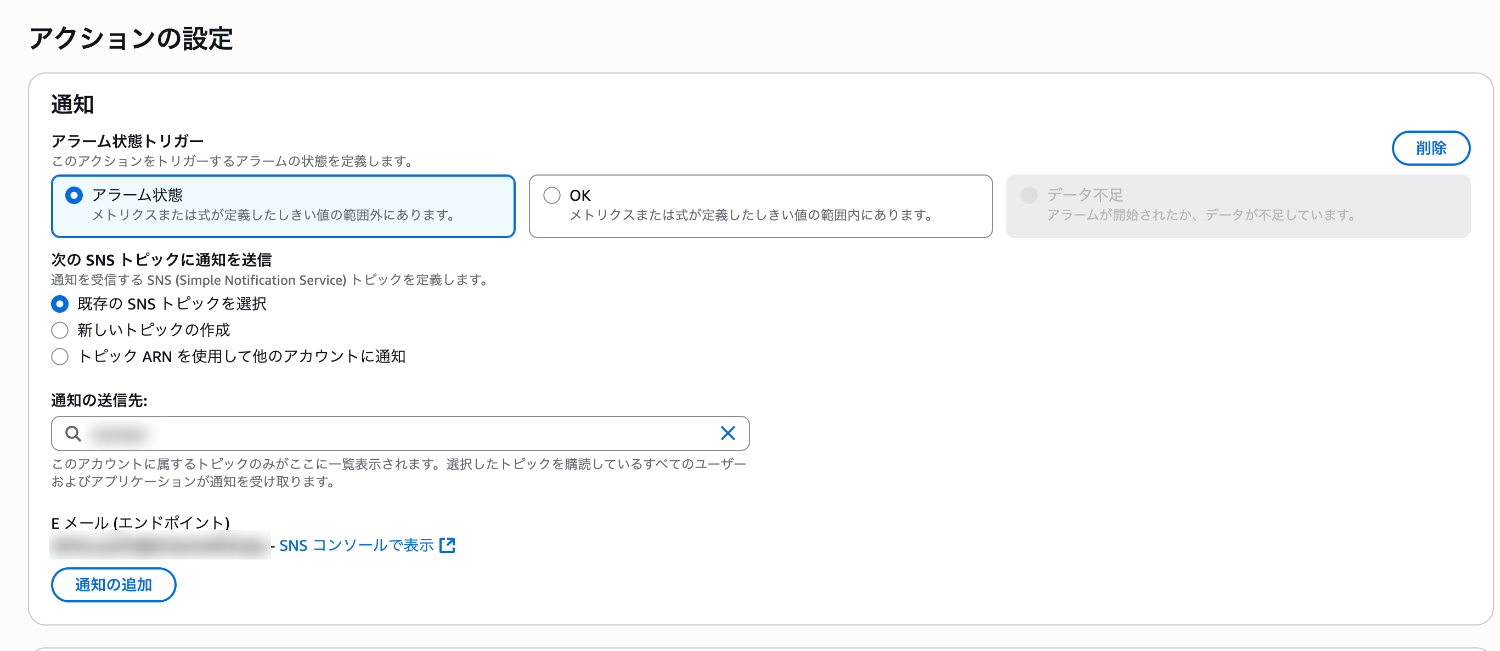
- 下記アクションの設定でアラームの作成を行ってみます。
- 通知:アラーム状態
- 通知の送信先:事前に作成した E メール (エンドポイント)のSNSトピック
- 任意のアラーム名を指定してアラームの作成を行います。
作成したアラームを確認してみる
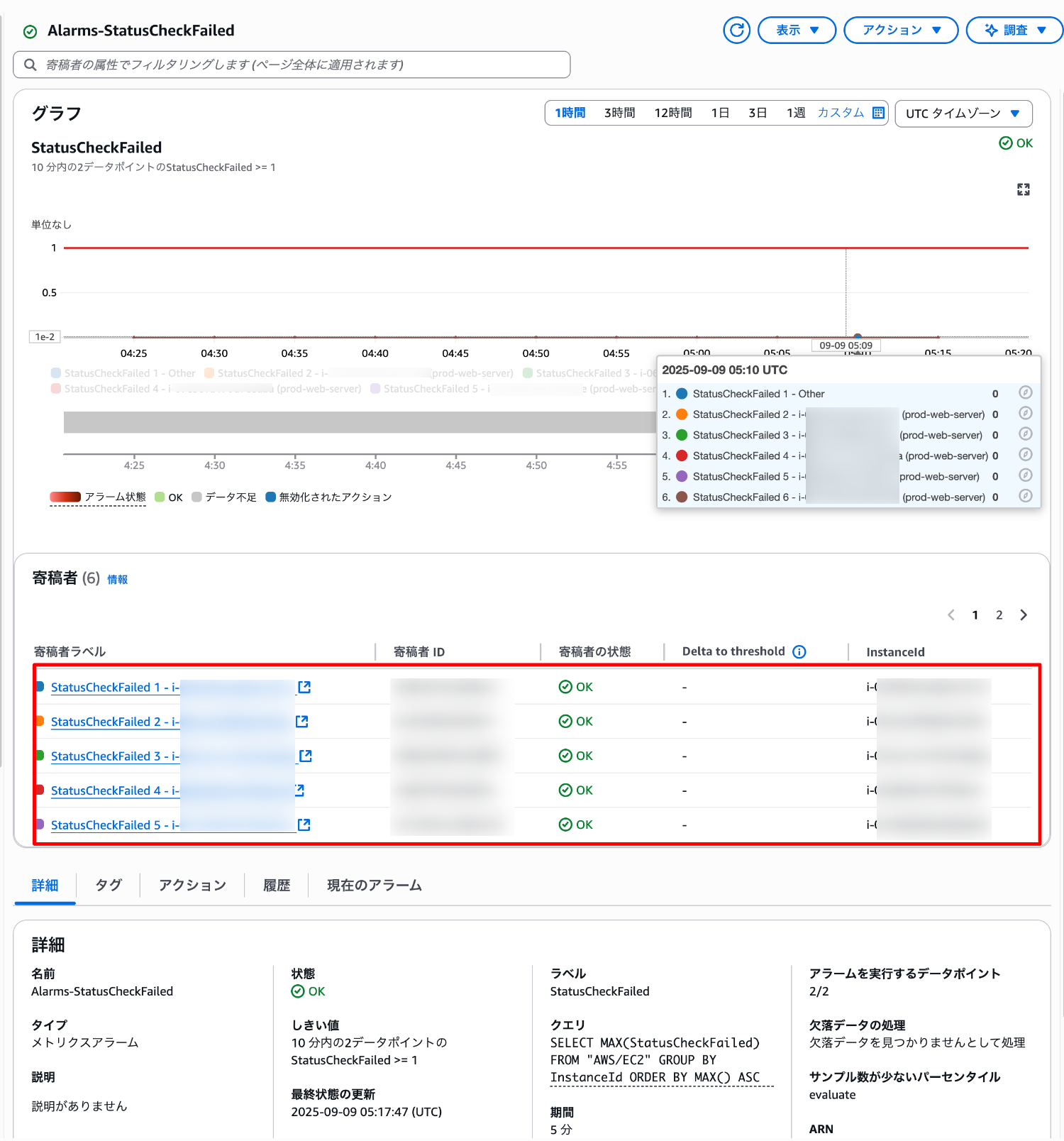
作成したアラームの状態をみてみます。
インスタンスごとに異なる StatusCheckFailed メトリクスのグラフが表示されています。
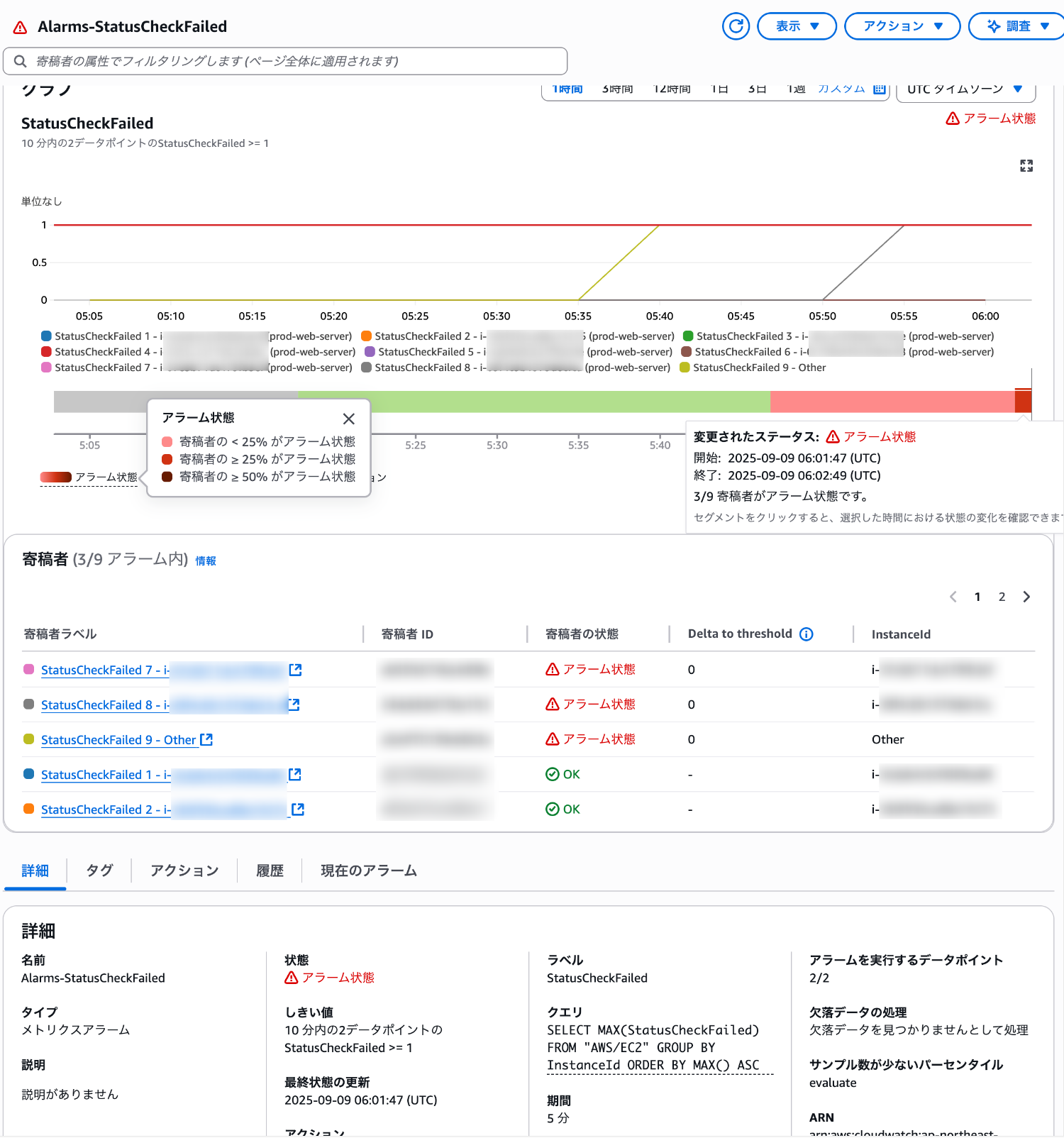
寄稿者ラベルと寄稿者 ID が表示されて、寄稿者ごとのステータスが表示されていることがわかります。
寄稿者(Contributor)とは
複数時系列アラームを構成する個別のメトリクスです。
GROUP BY で指定したディメンション(今回はInstanceId)ごとに個別の寄稿者として扱われ、それぞれが独立してアラーム条件を評価されます。
なお、特定のラベルキーが含まれていない場合、null のグループ Other が返されます。
1 つ以上の寄稿者が定義されたしきい値から逸脱すると、アラームがトリガーされる動作となります。
動的にリソースを追加してみる
Auto Scaling グループの希望するキャパシティーを増やしてみます。
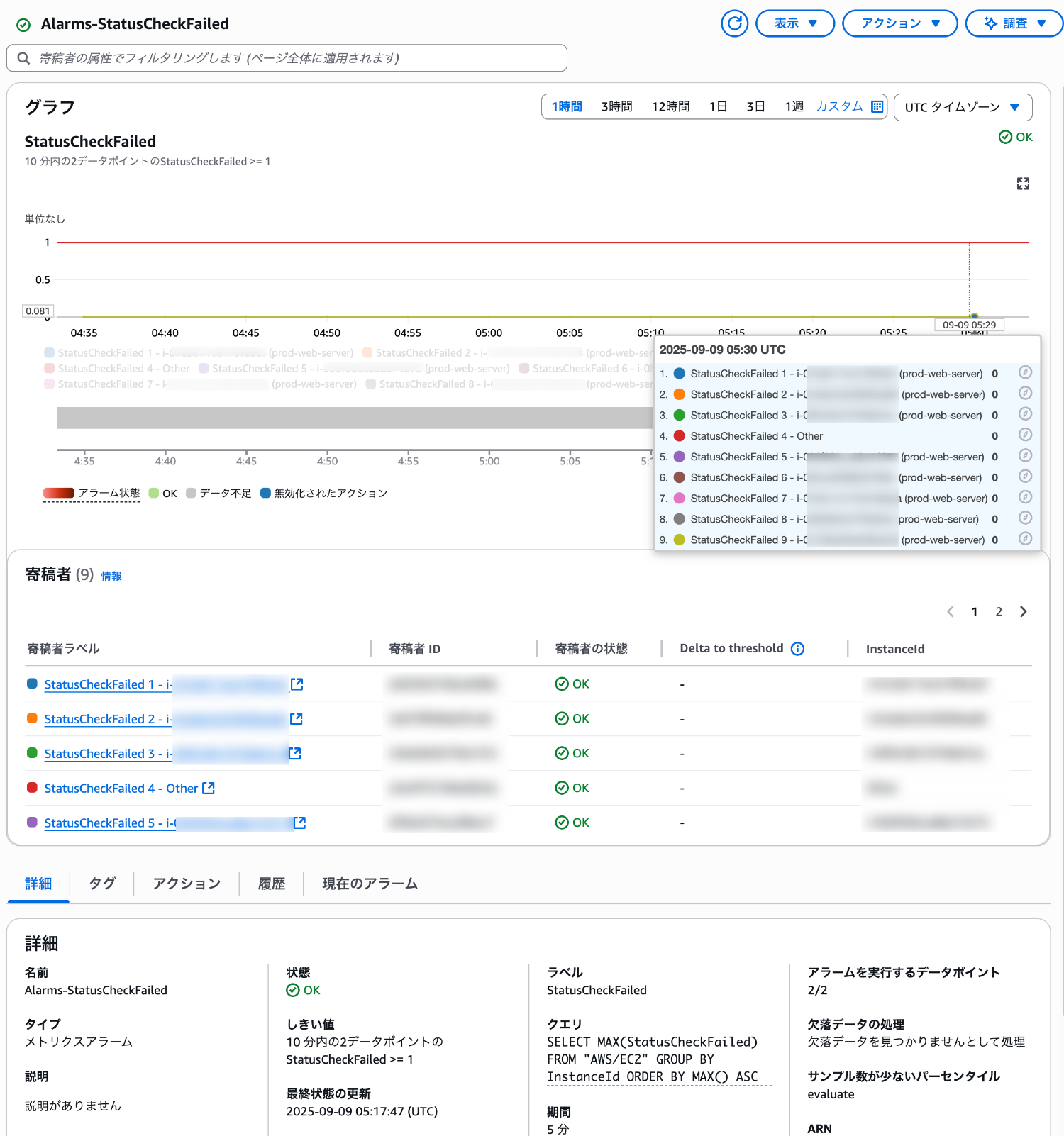
しばらくすると、CloudWatch アラームのグラフにオートスケーリングによって動的に追加された EC2 インスタンスのメトリクスが追加されました。
動的に追加されたインスタンスに対しても自動で監視対象となることを確認できました。
擬似アラート発生させてみる
StatusCheckFailed_Instance を失敗させ、擬似的に StatusCheckFailed メトリクスを発生させてみます。
EC2 インスタンス内のネットワークインターフェース(NIC)を停止させてみます。
※インターフェース名は環境により異なります。
ip link set enX0 down
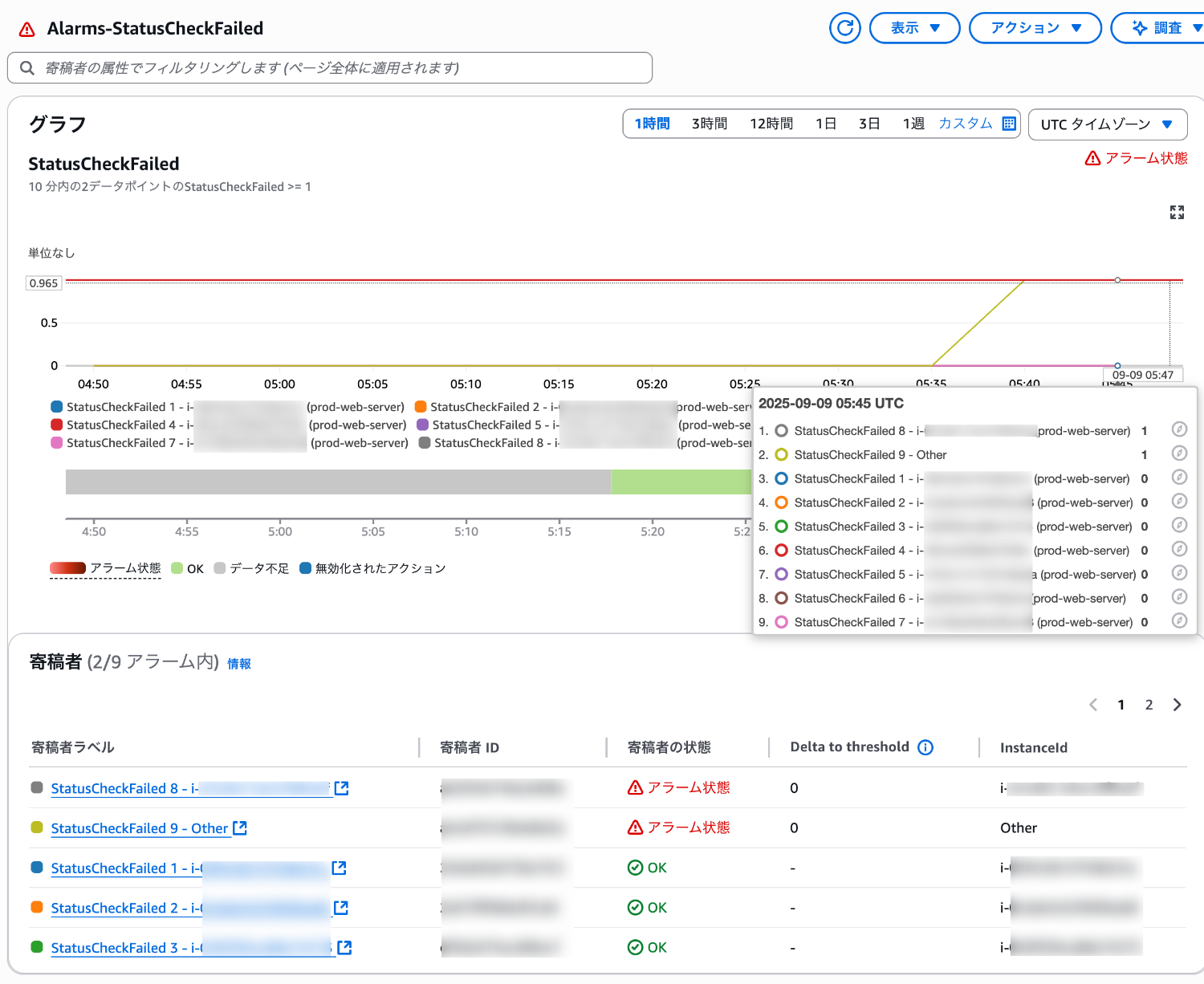
しばらくすると対象の EC2 インスタンスの寄稿者がアラーム状態になりました。
寄稿者 Other も一緒にアラーム状態になっています。
SNSトピックに設定したメールアドレス宛にメールが2通通知されました。
1通は対象 EC2 インスタンスのもの、もう一通は寄稿者 ID が Other のものでした。
- 対象 EC2 インスタンスの通知
- 寄稿者 ID Other の通知
アラーム状態中に別のインスタンスでアラームを発生させてみる
アラーム状態中に別のインスタンスでアラームが発生した場合の挙動を試してみます。
1台の EC2 インスタンスの StatusCheckFailed_Instance を失敗させ、擬似的に StatusCheckFailed メトリクスを発生させておきます。
既にアラーム状態となっていることを確認できます。
この状態で、さらに別の EC2 インスタンスの StatusCheckFailed_Instance を失敗させ、擬似的に StatusCheckFailed メトリクスを発生させます。
しばらくすると対象の EC2 インスタンスの寄稿者があらたにアラーム状態になりました。
さきほどよりもより濃い赤色に表示が変わっていました。
寄稿者のパーセンテージによって色合いが変わるようです。
SNS トピックに設定したメールアドレス宛に新たに1通メール通知が行われました。
アラームの履歴を見ると、新たに寄稿者の状態がアラーム状態に更新され、再度アクションが実行されたことがわかります。
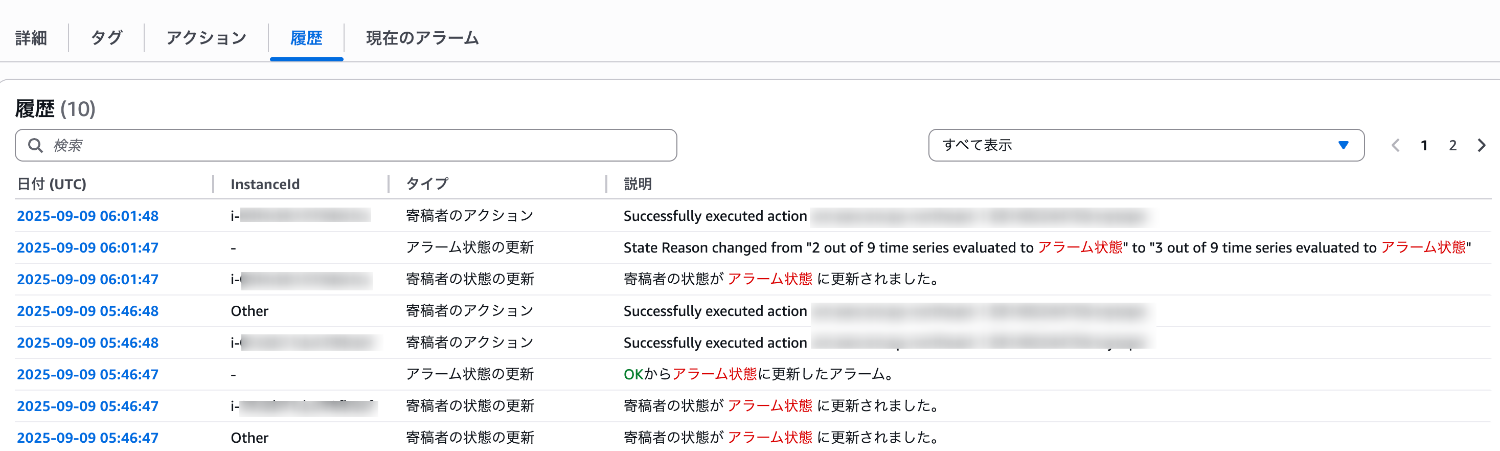
まとめ
従来はインスタンスごとにアラームを作成・管理する必要がありましたが、GROUP BY を使った Metrics Insights クエリに対してアラームが設定できます。
Auto Scaling で動的に増減する EC2 インスタンスに対しても、単一のアラームで自動的に監視対象に追加されます。
また、寄稿者(Contributor)という仕組みにより、個別のインスタンスごとにアラーム状態を管理できるようになりました。
大規模な環境や動的にリソースが変化する環境での監視運用において、非常に有用です。
本記事が参考なれば幸いです。
参考







