
Amazon Connect AIエージェントで、音声からの文字起こしが誤認識される場合の対策
はじめに
Amazon Connect AIエージェントを利用して音声ボットを構築していると、検証中にLexの音声認識モデルによって音声からの文字起こしが誤認識されることがあります。
誤認識された状態でAIエージェントにテキストとして渡されると、そのままナレッジをクエリしてしまうため、回答不可や誤った回答につながります。
実際にCloudWatch LogsでAIが受け取ったテキスト(utterance)を確認すると、「Cognito」が「国ニート」に、「クラスメソッド」が「暗めそう」に誤認識されてしまっていることがありました。
【CloudWatch Logsの出力例】
{
"assistant_id": "af781af2-81bb-4f84-9667-9b63ee75ae7b",
"event_timestamp": 1773044926559,
"event_type": "TRANSCRIPT_UTTERANCE",
"session_id": "abb7e07e-d5dc-42a4-8f02-4e6e282d902a",
"utterance": "[CUSTOMER] 暗めそうオフィス情報を教えてください",
"session_event_id": "a19cd1b6-8857-7267-9b22-8c709d470bab"
}
【参考】
以下の設定を行うことで、AIエージェントが受け取ったテキストやクエリ結果、回答内容を全てCloudWatch Logsで確認できます。
Amazon Q in ConnectのログをCloudWatch Logsに出力して、AIの回答プロセスを確認してみた
本記事では、このLex側の音声認識エラーによってAIが正しく回答できない事象に対し、どのように専門用語を認識・処理させるべきか、対策アプローチとその使い分けについて考えてみました。
対策1:AIプロンプトで補正する(推奨)
結論から言うと、実運用において最もおすすめなのが「Amazon Connect AIエージェントのプロンプト内で、LLMに誤認識を補正させる」アプローチです。
AIエージェントのプロンプト(Self Service Pre Processingなど)に、以下のような補正ルールと具体例(Few-shot)を記述します。
【プロンプトの設定例】
【音声認識エラーの補正ルール】
音声入力の文字起こしエラーにより、専門用語が一般的な単語に誤認識される場合があります。
ユーザーの発話が文脈上不自然な場合は、以下のリストに従って「正しい用語」に読み替えた上で、QUESTIONツールの検索クエリ(query)を作成してください。
フォーマット: [誤認識されやすいワード] → [正しい用語] (適用する文脈の条件)
<補正リスト>
- 「暗めそう」「暗め」 → 「クラスメソッド」 (企業名やITベンダーに関する文脈の場合)
- 「国ニート」「コグニト」 → 「Cognito」 (AWSサービス名や認証機能に関する文脈の場合)
# 今後、誤認識が見つかった場合はここに追記してください
# - 「〇〇」 → 「△△」 (××に関する文脈の場合)
</補正リスト>
なぜこの方法が推奨なのか?
LLMの推論能力を活用することで、前後の文脈を考慮した柔軟な対応が可能になるためです。
例えば、「画面が暗めなので明るくしたい」といった文脈であれば、LLMが判断して「クラスメソッド」には変換せず、そのまま「暗め」として適切に処理してくれます。
特にITサポートなどで頻出する英単語(AWSサービス名など)や英数字の型番を扱う場合、後述するLexの仕様制限を回避できるため、この方法が最も確実で手軽な解決策となります。
対策2:Amazon Lexのカスタム語彙を設定する
もう一つの方法が、AIエージェントが内部で使用しているLexボットに対して「カスタム語彙(Custom Vocabulary)」を設定し、Lexの音声認識の段階で正しい用語として認識しやすくする(重み付けする)アプローチです。
「耳(音声認識)」の段階で根本的に直せるならこちらの方が良いのでは?と思いがちですが、日本語のLexボット(ja_JP)においては、仕様制限が存在するため注意が必要です。
日本語ボットのカスタム語彙の制限
日本語のLexボットのカスタム語彙では、入力できる文字が「ひらがな、カタカナ、漢字など」の日本語文字セットに厳格に制限されています。
そのため、「Cognito」や「AWS」といったアルファベットを含む英単語や型番をそのまま登録しようとすると、文字種エラーとなり登録自体が弾かれてしまいます。
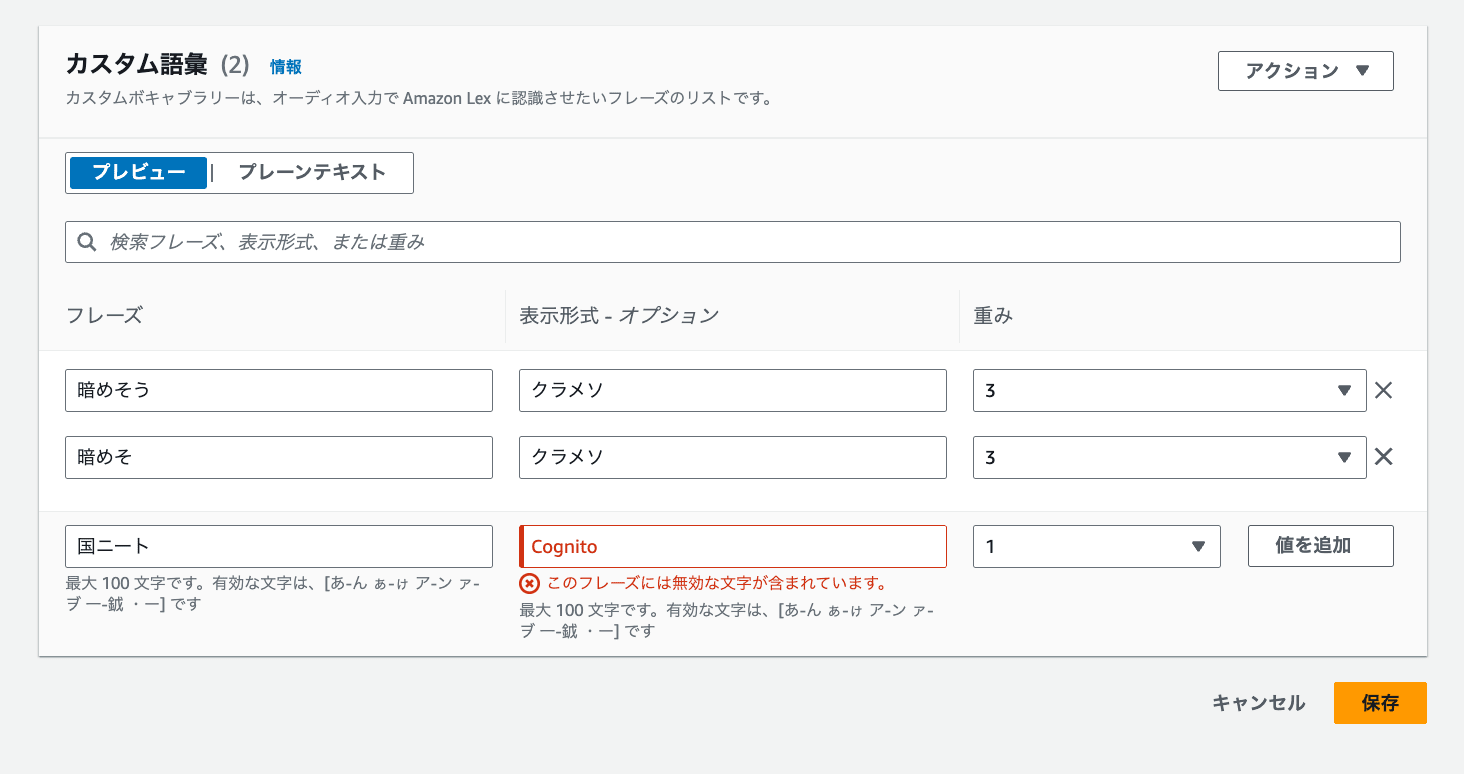
この制限があるため、英単語や型番が頻出する業務において、Lexのカスタム語彙「だけ」で誤認識対策を完結させることは実質不可能です。
2段構えの構成(参考例)
では、Lexのカスタム語彙は全く使えないのかと言うと、そうではありません。
基本的には対策1のように、プロンプト内で誤認識されたテキストのパターンを複数登録すれば解決することがほとんどです。しかし、どうしても音声認識のブレが激しく、プロンプトに書ききれない場合の「使えるかもしれない例」として、両方を組み合わせる「2段構え」のアプローチがあります。
- Lexのカスタム語彙(耳の安定化)
アルファベットは登録できないため、あえてカタカナで「コグニト」と登録し、Lexの音声認識を「コグニト」というテキストで安定して出力させるようにします。 - AIプロンプト(脳での変換)
Lexから渡ってきた「コグニト」というテキストを、対策1のプロンプト指示によって「Cognito」に変換し、ナレッジ検索へ回します。
ただし、前述の通りプロンプトで誤認識パターンを網羅すれば済むケースが多いため、必ずしも有効(必須)なアプローチというわけではありません。あくまで補助的な手段として捉えてください。
すべての誤認識パターンをプロンプトに登録する必要はない
ここまでプロンプトでの補正方法を解説しましたが、Lexの音声認識が誤認識を起こしたからといって、必ずしもプロンプトで明示的に補正ルールを書かなければならないわけではありません。
その理由として、AIエージェントの裏側では以下の2つの強力な機能が働いているためです。
1. LLMの推論能力による自動補正
LLM(大規模言語モデル)自体が高い推論能力と文脈理解力を持っているため、プロンプトに特別な指示がなくても、自動的に正しい単語を推測して適切なクエリを生成してくれることが多々あります。
【LLMが自動補正してくれる誤認識の例】
- 「移行手順」が「意向手順」になっている
- 「仕様書」が「使用書」になっている
- 「EC2」が「イーシーツー」とカタカナになっている
このように、同音異義語や漢字の変換ミス程度であれば、LLMの能力によってカバーできる範囲も広いです。
2. ベクトル検索は「音声の誤認識」に強い
さらに、AIエージェントのナレッジ検索で利用されている「ベクトル検索」の仕組みも、誤認識に対するセーフティネットになります。
ベクトル検索という技術を使うことで、キーワードが完全に一致しなくても「意味(Semantic)」が近いものを探せる「セマンティック検索(意味検索)」という機能を実現しています。
この技術により、例えば「仕様書」が「使用書」と誤認識されたままナレッジ検索のクエリとして渡されてしまった場合でも、文脈や周辺の単語(一緒に発話された型番など)から意味を推測し、正しいドキュメントをヒットさせる能力があります。
【参考】
Amazon Q in Connect は、機械学習を使用してユーザーの意図とコンテキストを理解し、キーワードが完全に一致しなくても関連する回答を返す「セマンティック検索」をサポートしています。
Amazon Q in Connect 向けにナレッジベースを最適化する | Amazon Web Services ブログ
ログを見て「回答できなかった場合」のみ登録する
これらの理由から、文字起こしのログを見て、誤認識されている単語を片っ端からプロンプトに登録していく必要はありません。
実際の運用では、「AIが誤った回答をした」「回答できなかった」という問題が起きた場合にのみCloudWatch Logsを確認し、LLMやベクトル検索でもカバーしきれなかった致命的な誤認識(「Cognito」→「国ニート」など)だけをプロンプトに追記していく、というアプローチをおすすめします。
まとめ
ここまでの考え方をまとめると、以下のようになります。
| 対策アプローチ | メリット | デメリット・注意点 | 採用の目安 |
|---|---|---|---|
| 1. AIプロンプトでの補正 | ・英単語や型番にも柔軟に対応可能 ・文脈を考慮できる(例:「暗め」の使い分け) |
・プロンプトが長くなりすぎるとトークンを消費する | 基本はコレ(第一選択) |
| 2. Lexのカスタム語彙 | ・音声認識のブレを根本から安定させることができる | ・日本語ボットではアルファベットが登録不可 ・最大500件の制限あり |
プロンプト補正だけでは拾いきれないほど認識ブレが激しい単語の補助として(カタカナ登録) |
音声ボットの構築において、AIエージェントが専門用語にうまく回答できない場合は、まずはCloudWatch LogsでLexがどう聞き間違えているかを確認し、本記事の「プロンプト補正」を主軸とした対策を試してみてください。








