
Amazon Connect コンタクトフロー内の音声録音でも文字起こし可能か確認してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは。
繁松です。
はじめに
Amazon Connectのコンタクトフロー内の音声録音でもContact Lensによる文字起こしが可能か確認してみました。
結論:コンタクトフロー内の音声録音でContact Lensによる文字起こしは出来ませんでした。
そのためS3バケットに録音データが出力されたことをトリガーにAmazon Transcribeで文字起こしする方法を考えてみました。
やってみた
前提
- Amazon Connectインスタンスは構築済み
- コンタクトフロー内の音声録音は設定済み
コンタクトフロー内の録音データの保存場所
Amazon Connectインスタンスのデータストレージ > 通話記録に設定されているバケットに保存されます。
標準では「s3://バケット名/connect/インスタンス名/CallRecordings/」が設定されていると思います。
コンタクトフロー内の音声録音は「s3://バケット名/connect/インスタンス名/CallRecordings/ivr/YYYY/MM/DD/」にwav形式で保存されます。
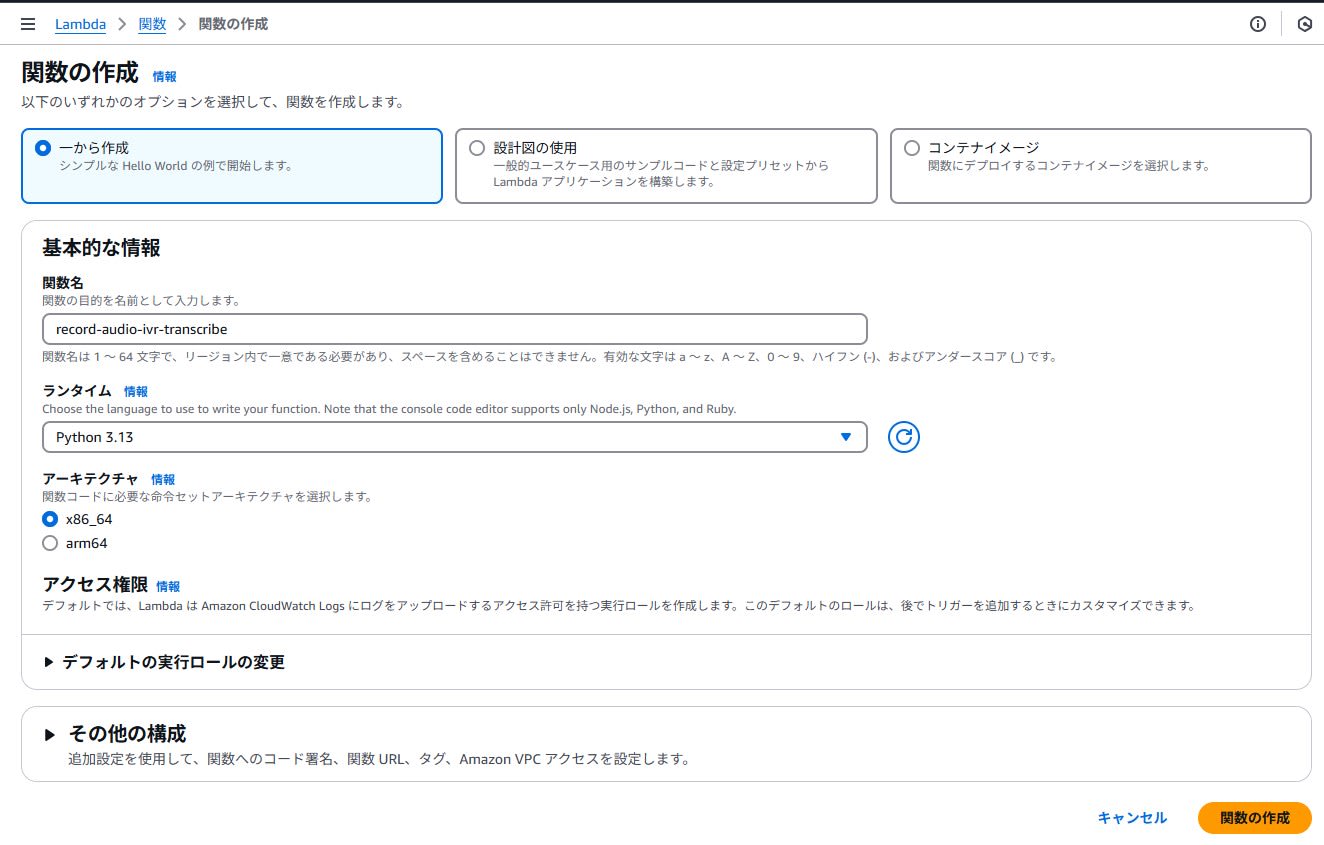
Lambda作成
コンタクトフロー内の音声録音ファイルがS3に出力されたことをトリガーにLambdaを実行し、Transcribeで文字起こしを行います。
Lambdaを作成します。
ロールポリシーの追加
LambdaのロールにAmazon Connectの設定更新に必要な以下のポリシーを追加します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"transcribe:StartTranscriptionJob",
"s3:GetObject"
],
"Resource": "*"
}
]
}
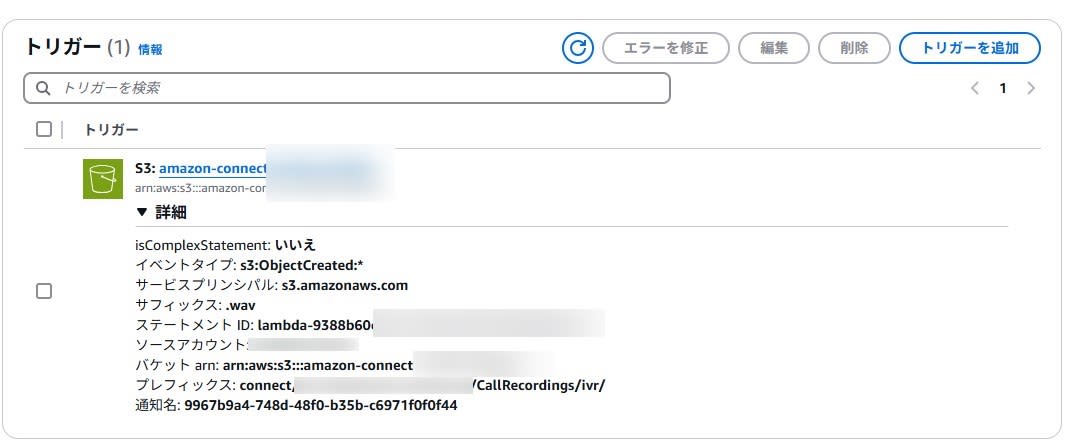
トリガー設定
LambdaのトリガーにS3を設定します。
コンタクトフローの音声録音が保存されるバケットを指定します。
コード
S3イベントからバケット名とオブジェクト名を取得しTranscribeの文字起こしを実行します。
Transcribeのジョブ名は「transcribe_コンタクトID」となります。
import boto3
import json
def lambda_handler(event, context):
# S3イベントから音声ファイルの情報を取得
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
key = key.replace('%2F', '/').replace('%3A', ':')
# Transcribeクライアントの初期化
transcribe = boto3.client('transcribe')
# ファイル名からUUID部分を抽出
file_name = key.split('/')[-1] # パスの最後の部分(ファイル名)を取得
uuid = file_name.split('_')[0] # ファイル名をアンダースコアで分割し、最初の部分(UUID)を取得
# ジョブ名の設定
job_name = f"transcribe_{uuid}"
# 文字起こしジョブの開始
response = transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': f"s3://{bucket}/{key}"},
MediaFormat='wav',
LanguageCode='ja-JP'
)
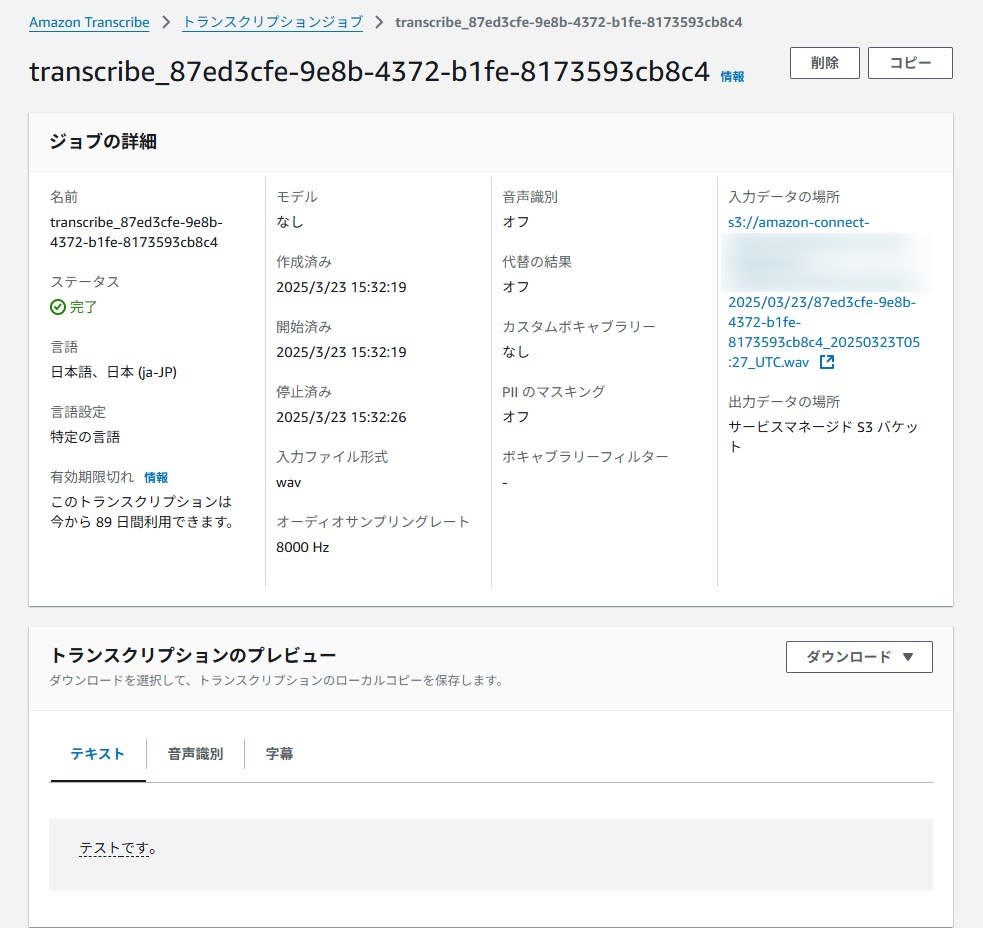
動作確認
実際に架電してみたところ、Amazon Transcribeで文字起こしされたジョブを確認できました。
さいごに
コンタクトフロー内の音声録音ではContact Lensによる文字起こしができませんでしたが、LambdaとTranscribeを利用することで文字起こしすることができました。
留守電のような用途でコンタクトフローの音声録音を利用したい場合の文字起こしも可能です。








