Amazon DevOps Guru のベースラインを整備して1ヶ月ほど運用してみた #jawsug_asa
2025/06/10に開催された JAWS-UG朝会 #70 にて、 「 Amazon DevOps Guru のベースラインを整備して1ヶ月ほど運用してみた 」 というタイトルで登壇しました。
参加いただいた皆様、そして運営の皆様、ありがとうございました!
本ブログでセッションスライド、およびその内容を記載します。
セッションスライド
前提: AWS環境について
組織環境
- AWS Organizations 環境
- AWSアカウント数: 40以上
- 複数の利用部門/システムが存在
私の役割
- CCoEの技術メンバー として活動
- 全AWSアカウントの統制(ベースライン)
- 各利用部門とのコミュニケーション
DevOps Guru について
DevOps Guru とは?
AWSアプリケーションの運用問題を自動検出・予測するマネージド監視サービス です。
- 機械学習を使ってリソースのメトリクス/ログを分析
- 異常なパフォーマンスや障害の兆候を インサイト として自動生成
小ネタですが、昔の公式ドキュメント 機械翻訳では「DevOpsアマゾンの達人」と書かれていたみたいです。 ※ Guru は "指導者" の意味

画像引用: AWS上のアプリの障害監視をAIに任せる(DevOps Guru + Chatbotのカスタム通知) - Zenn
インサイトは2種類ある
- 事後的インサイト(reactive): 既に発生した問題を検出
- 予測的インサイト(proactive): 将来発生する可能性のある問題を予測
ほか補足
- エージェント不要でワークロードに影響なし
- 分析した分の従量課金。気軽に始められる
- 多くのリソースタイプに対応(25以上)

料金グループA: 約$2/month
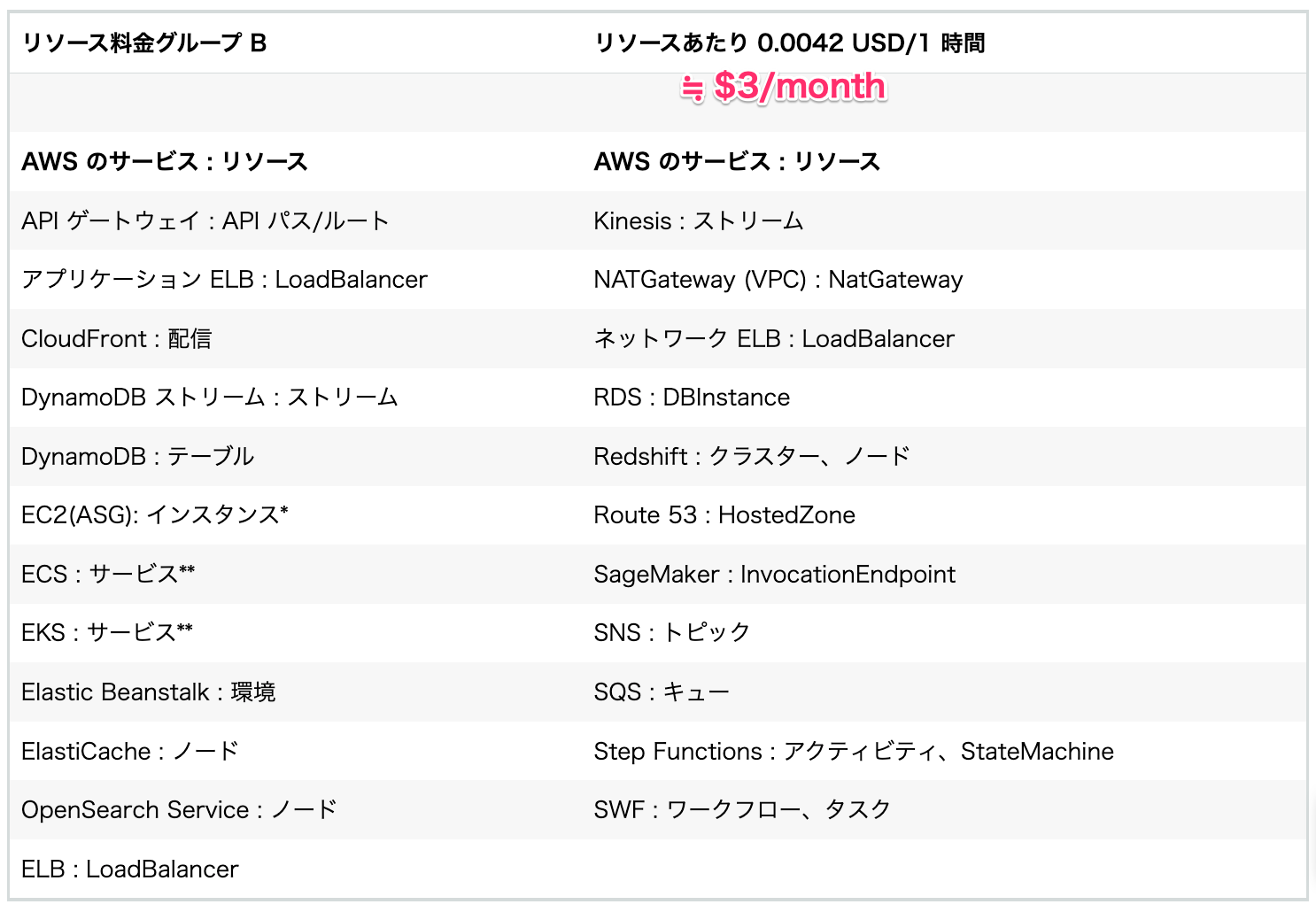
料金グループB: 約$3/month
DevOps Guru を導入してみた
目的と目標
導入の目的は以下を想定していました。
- 信頼性向上
- パフォーマンス効率向上
- コスト最適化
- RDSが総コストの相当な割合を占有
- ボトルネックとなるクエリやDB固有の問題を特定して、 パフォーマンス効率を改善できれば…
- → 結果的にコスト最適化に繋がるはず!
そして目標は以下のとおり。
- 各利用部門のAWSアカウントにてリソースに特定タグを付与するだけで、 DevOps Guru分析をすぐに開始できる状態。
実装方法
CloudFormation StackSet として全アカウントに展開しました。
AWSTemplateFormatVersion: "2010-09-09"
Description: Enable DevOps Guru baseline
Resources:
### リソース収集の設定
CollectionByTagKey:
Type: AWS::DevOpsGuru::ResourceCollection
Properties:
ResourceCollectionFilter:
Tags:
- AppBoundaryKey: devops-guru-monitoring
TagValues:
- default # 複数値指定可
### ログ異常検知機能を有効化(追加コスト無し)
EnableLogAnomalyDetection:
Type: AWS::DevOpsGuru::LogAnomalyDetectionIntegration
DependsOn: CollectionByTagKey
ResourceCollectionFilter 部分にて分析対象の 登録方法を指定します。 以下3とおりの指定があります。
- アカウント全体: サポートされる全てのAWSリソースを分析(コストに注意)
- CloudFormationスタック単位: 特定のスタックに含まれるリソースを分析
- タグベース(★今回の方式): 特定タグベースで分析
やらかしポイント: ワイルドカードの罠
最初は以下のようなテンプレートを書いちゃっていました。
# 抜粋
CollectionByTagKey:
Type: AWS::DevOpsGuru::ResourceCollection
Properties:
ResourceCollectionFilter:
Tags:
- AppBoundaryKey: devops-guru-monitoring
TagValues:
- "*" # ← ワイルドカード!
さて、このときの挙動はどうなるでしょう。 「特定タグが付いているリソース "のみ" が分析される」でしょうか?
実際には 全リソーススキャン が発生しました。 その日に気づいて、すぐにロールバックしましたが 少しコストになってしまいました。
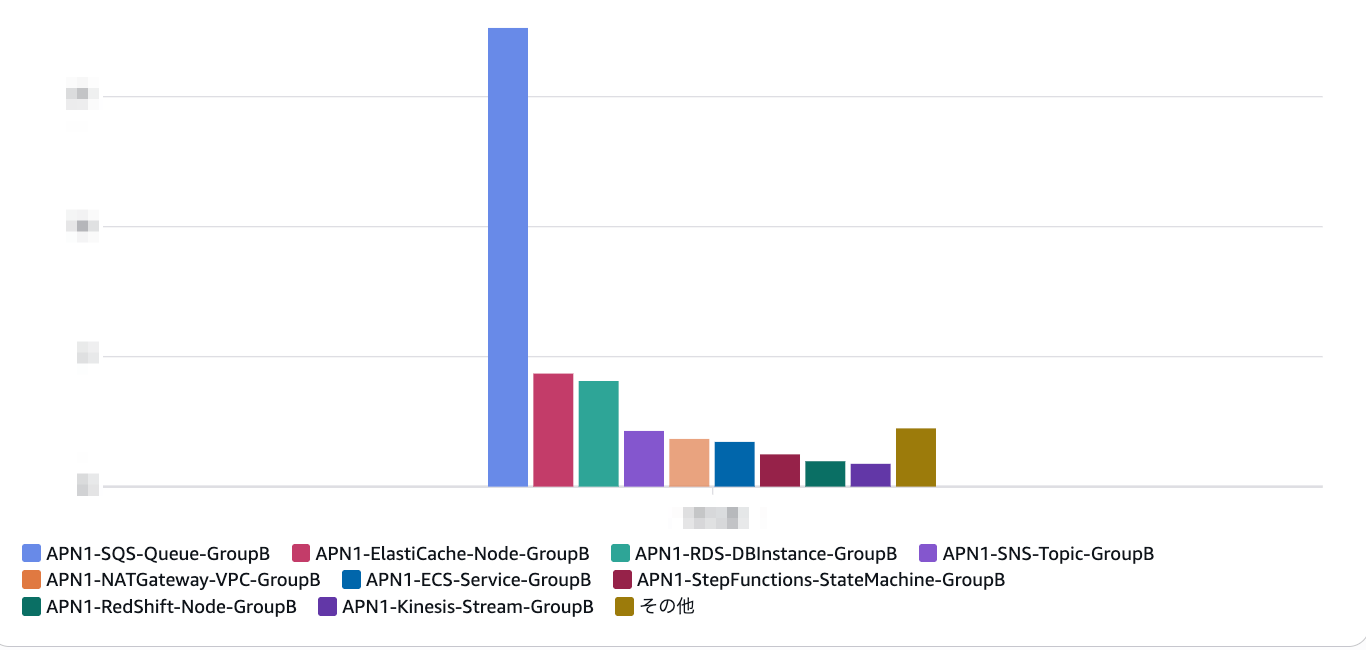
全リソーススキャンが走った日の DevOps Guru 使用タイプ別コスト
ワイルドカードを設定すると以下のような挙動になります。
- アカウント内の全リソースをスキャン する (ここ大事)
- 指定タグがあれば、その値がアプリケーション境界としてグループ化される
DevOps Guru を少し運用してみて
トライアルとして、以下2件を1~2ヶ月 分析させてみた。
- 利用部門の Aurora MySQL
- CCoE管理の NATゲートウェイ
Aurora MySQL での検証
事前に Performance Insights を有効化 ※ して、 タグを付与してもらって分析開始しました。
※ DevOps Guru for RDS の前提条件。より高精度/詳細なインサイトを生成できる
結果、インサイトは特に出なかったです😢。 (いい解釈をすると、特に問題は無かった)
CCoE管理 NATゲートウェイでの検証
前提として、 各AWSアカウントのアウトバウンド通信を、CCoE管理 NATゲートウェイに集約しています。
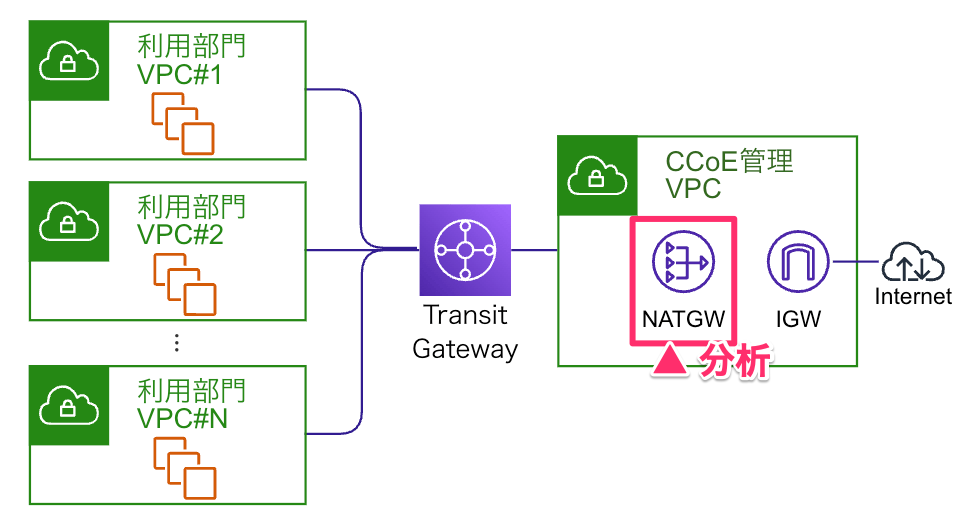
CCoE管理NATゲートウェイを分析
結果、数件のインサイトが発生しました。
NATゲートウェイのインサイトを深堀り
出てきたインサイトは The number of idle connections to NAT Gateway nat-example increased です。 実際のマネコン画面を以下に貼ります。
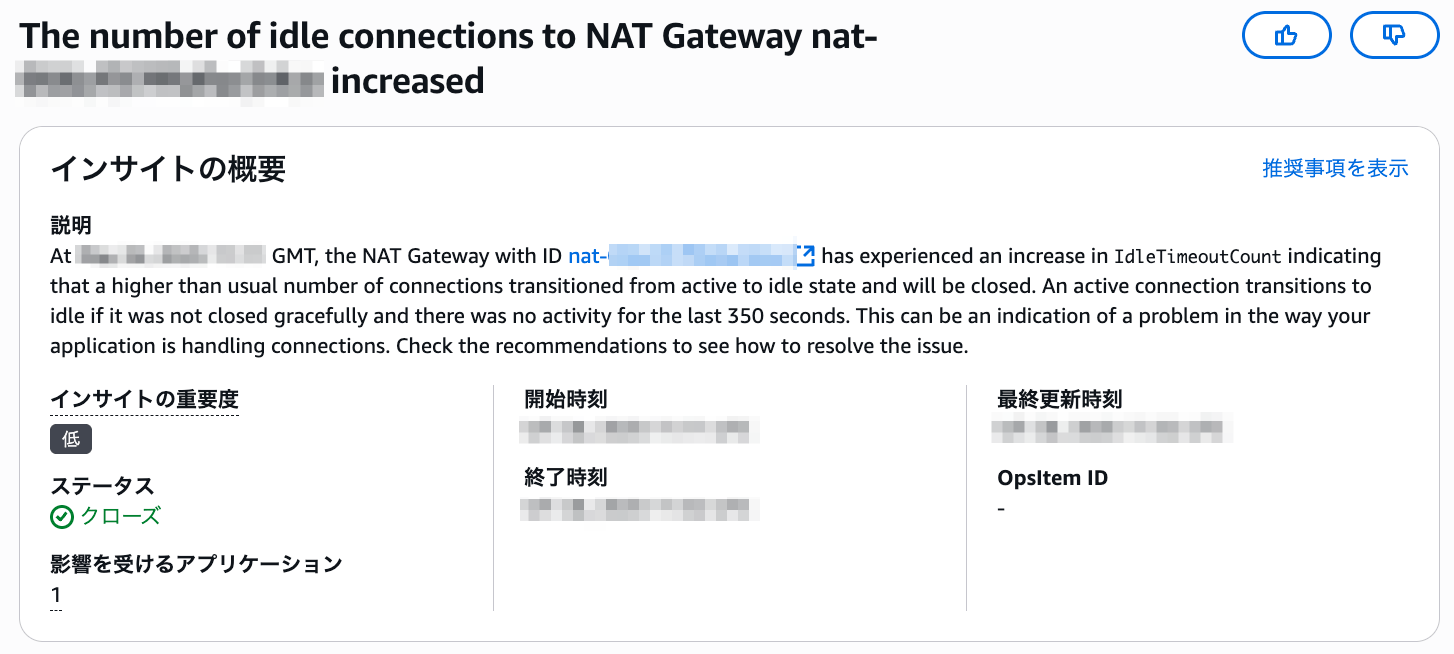
インサイトの概要
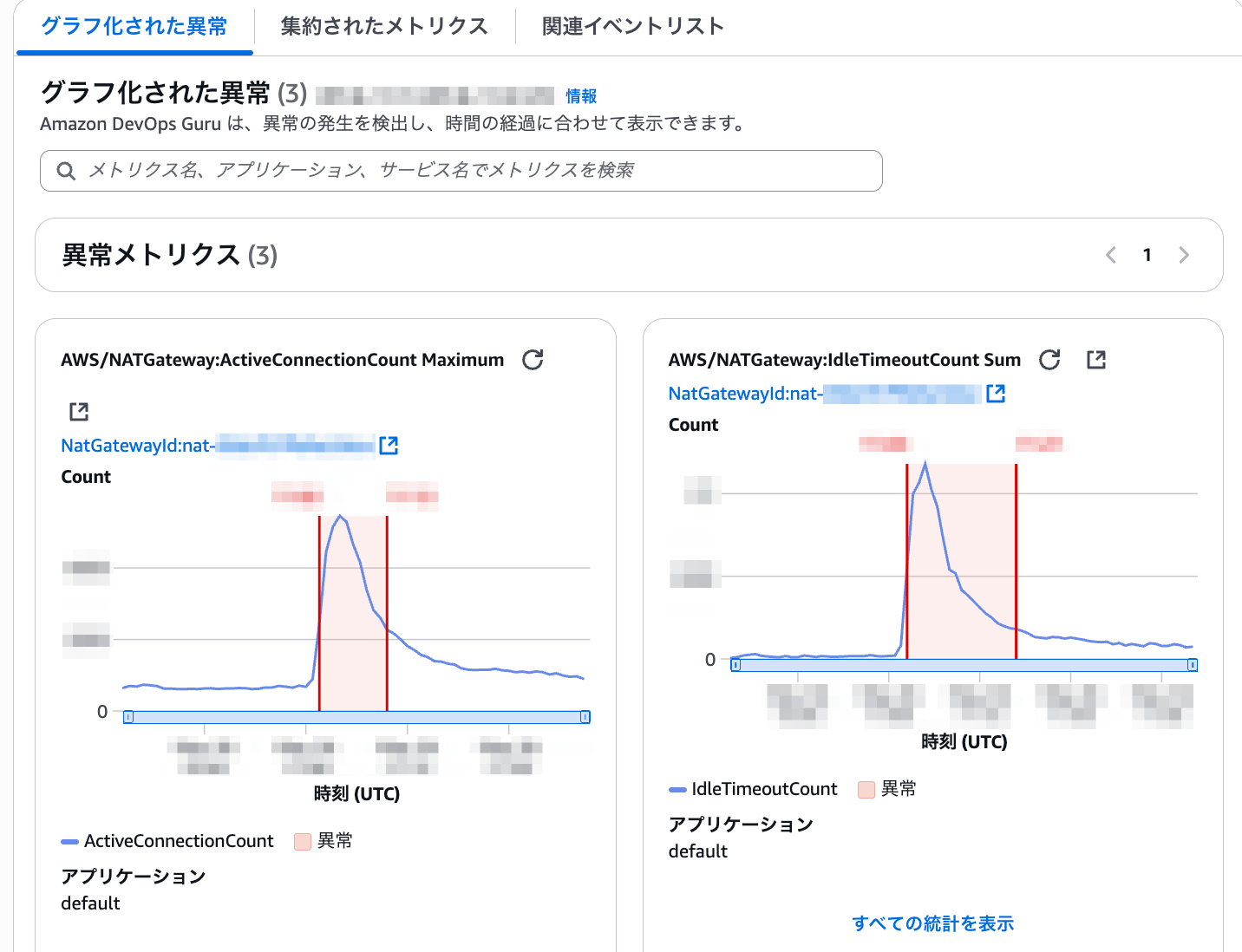
グラフ化された異常
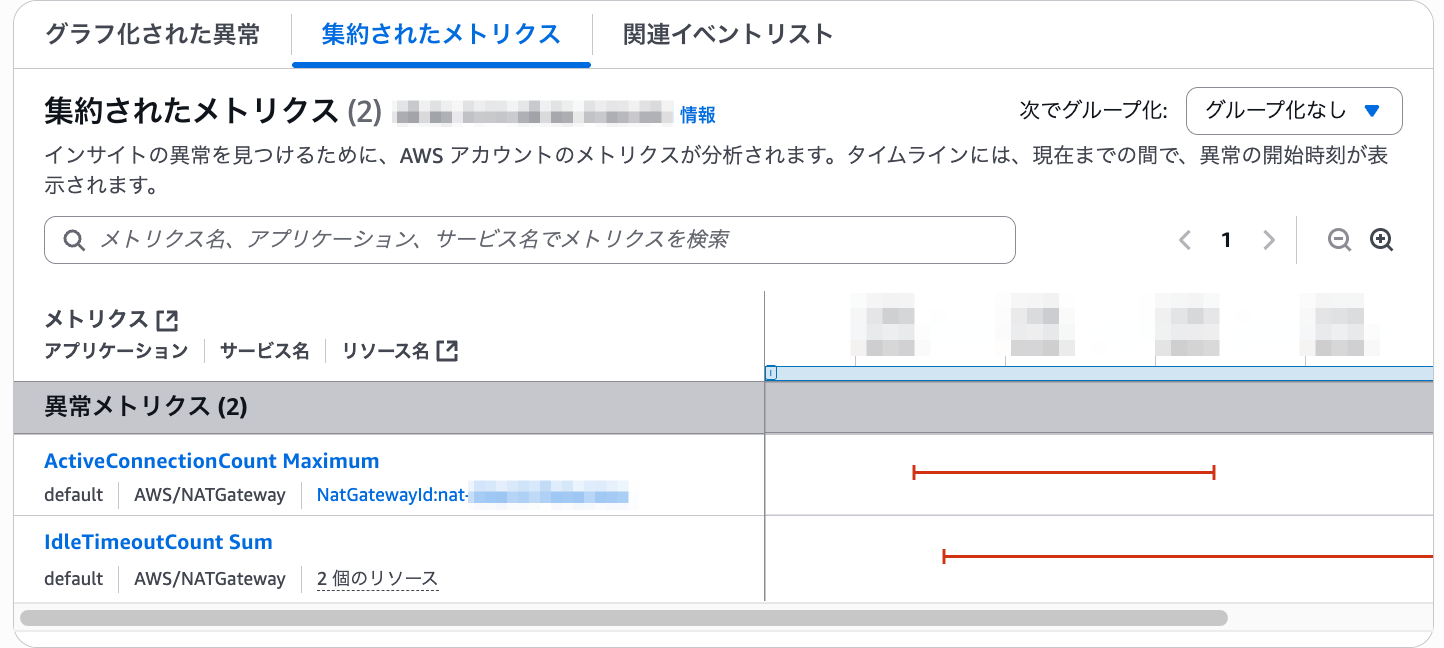
集約されたメトリクス
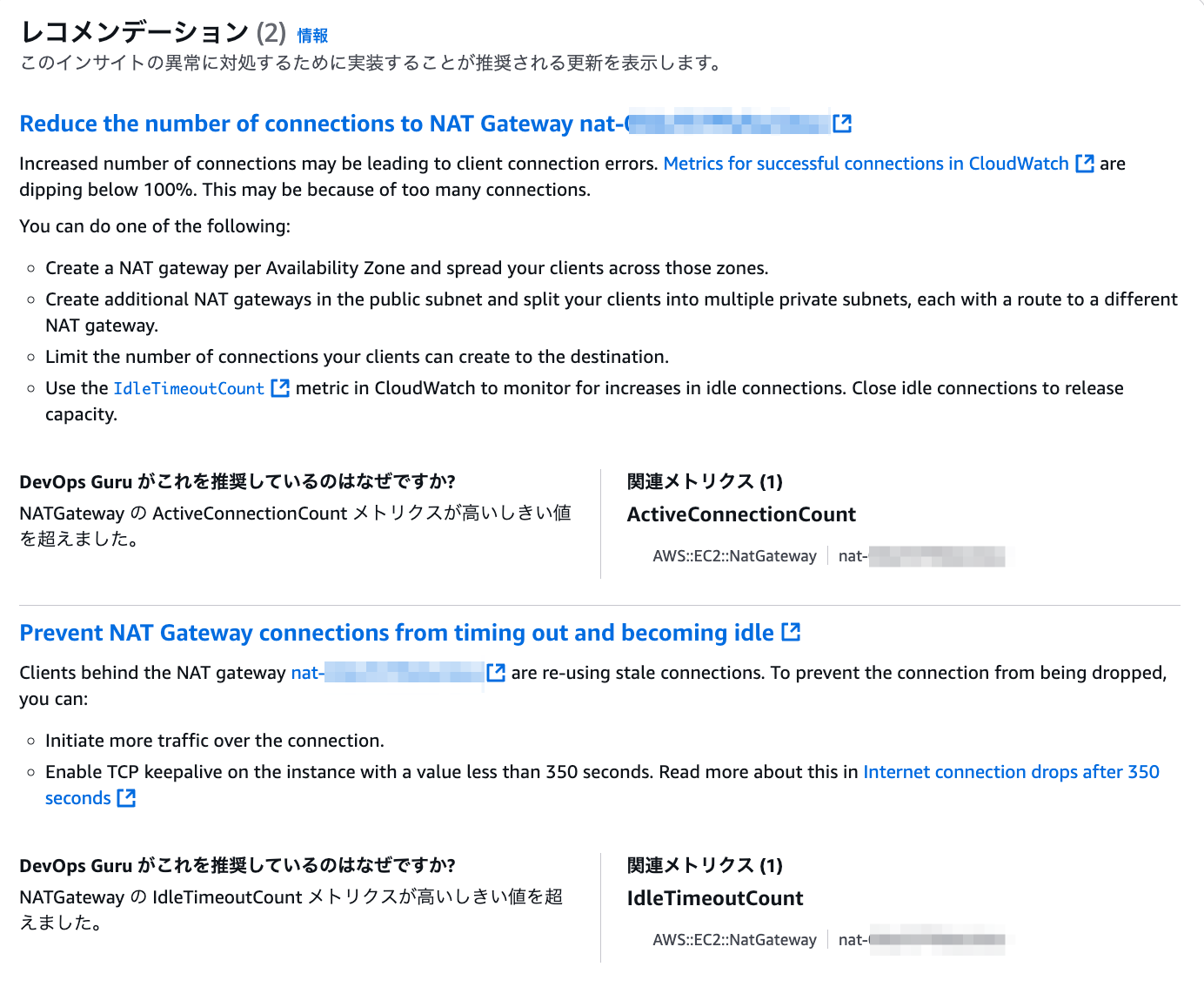
レコメンデーション
実のところ、上記 DevOps Guruインサイトの情報だけでは、 「どこからどこへの通信」が局所的に発生したかは分からなかったです。
そのため、以下追加調査をしました。
追加調査1: VPC Flow Logs の分析
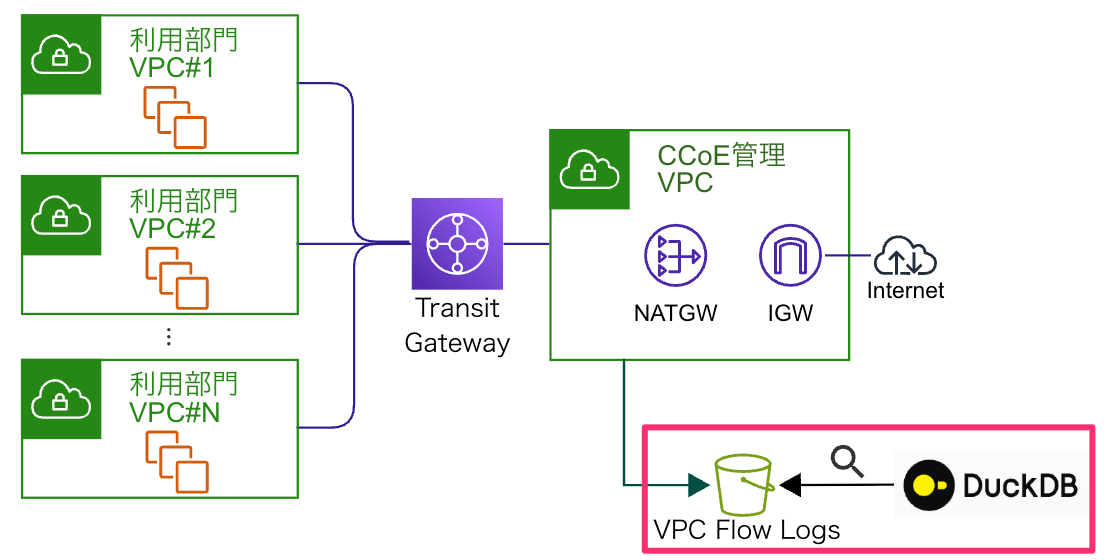
Source/DestinationのIPを特定する(参考ブログ)
追加調査2: DNSクエリログ の分析
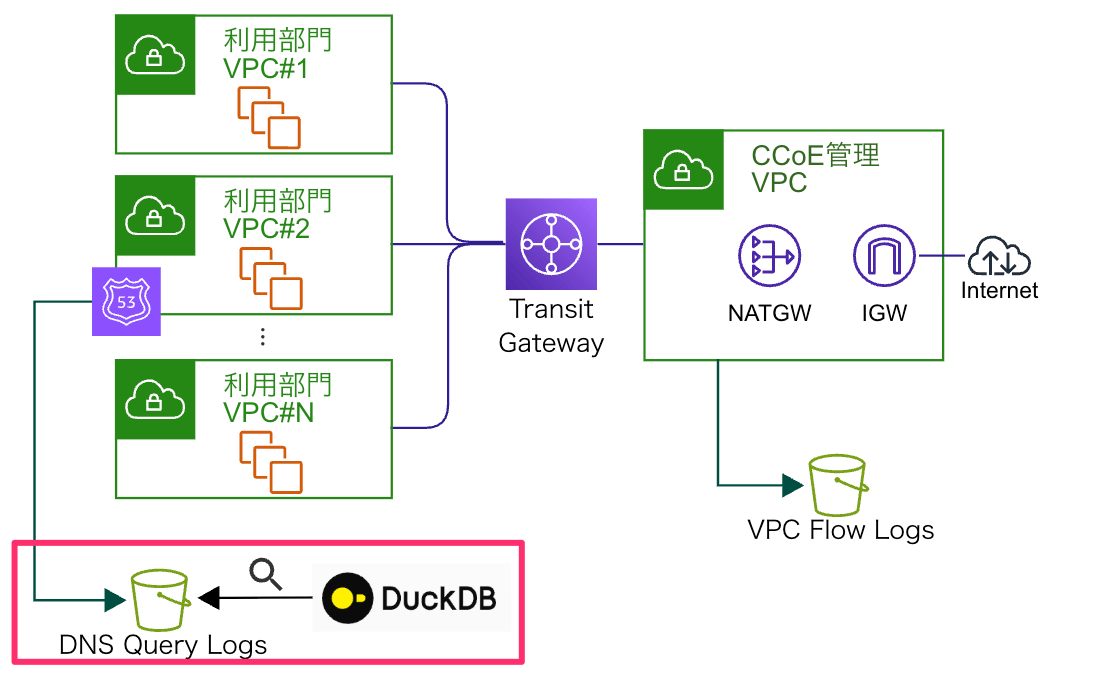
Destinationドメインを特定する(参考ブログ)
最終的に、事象をまとめて利用部門に連携、 アプリログなどを見てもらうよう依頼しました。
手動の追加調査はあったものの、 DevOps Guru インサイトきっかけで 改善のネタが生まれたのは良いことかなと思います。
通知の仕組み
しばらく触っての所感ですが、 マネージドCloudWatchアラーム みたいで良いなという感じです。
高重要度のインサイトはやっぱり通知させたい、 ということで通知の仕組みも作りました。
Tips: 注意ポイント
前提として DevOps Guru には Organizations連携機能があり、 これを使うことでメンバーアカウントを委任管理者にできます。
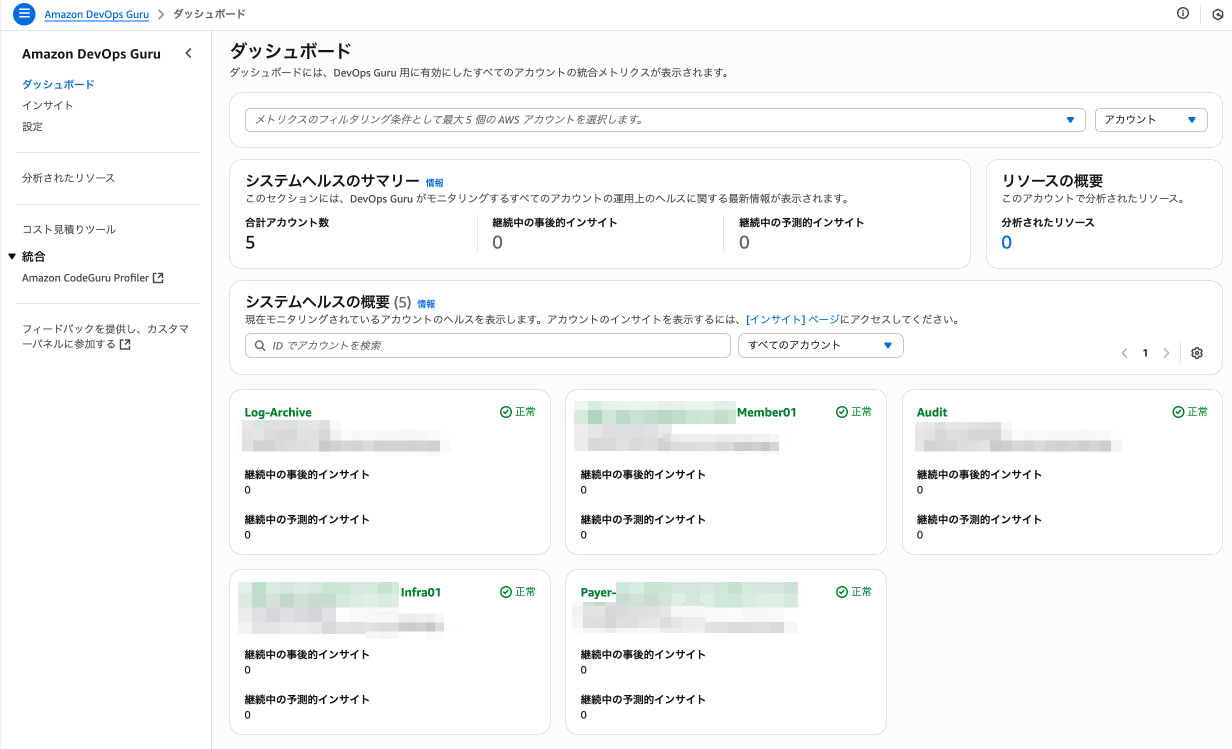
委任管理者内でインサイトを集約して確認可能
ただし委任管理者内の [設定 >SNSトピック] や EventBridgeイベントには集約されない 点に注意が必要です。
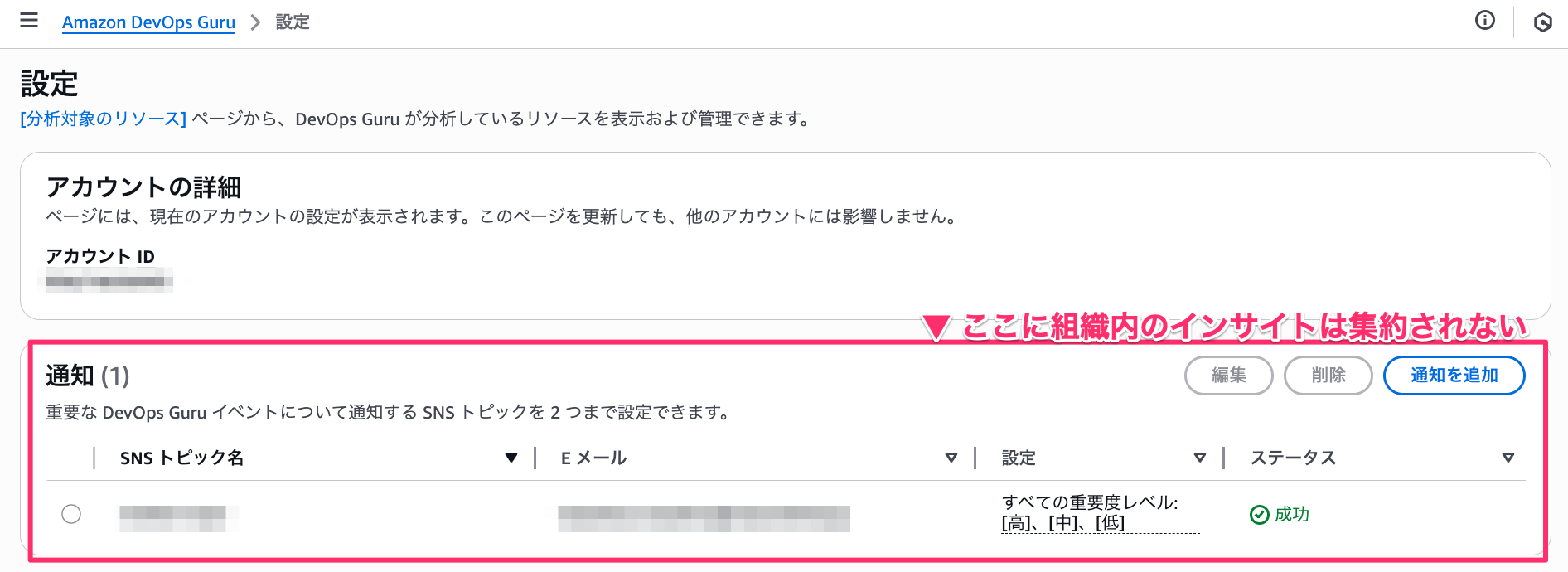
最終的に実装した通知アーキテクチャ
以下のようなアーキテクチャを作りました。
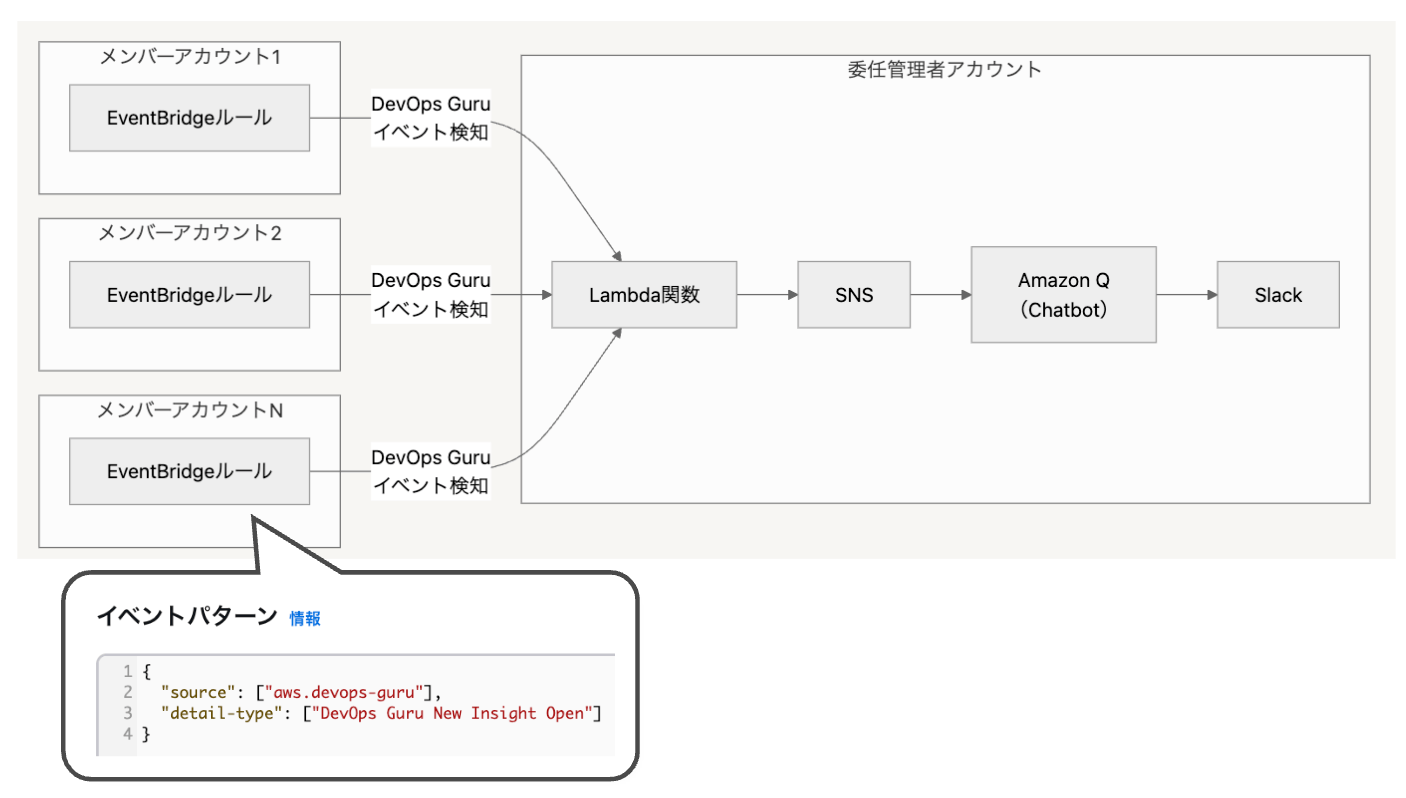
EventBridge → Lambda → SNS → Q → Slack
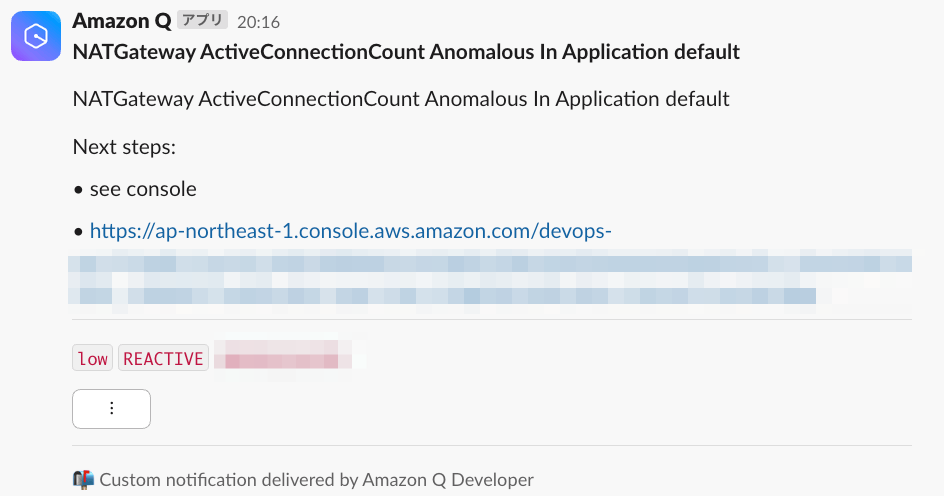
通知サンプル
(将来的には Bedrock あたりを呼び出して、インサイトを要約させて通知したいですね)
思ったこと
インサイトの通知テストがめっちゃ面倒! です。
機械学習による異常検知のため意図的な発生が難しく、 難儀しました。 ここについては GuardDuty のようなサンプル生成 API が欲しいですね…。
まとめ
以下まとめです。参考になれば幸いです。
- DevOps Guruは AWSアプリケーションの運用問題を自動検出・予測するマネージド監視サービス
- 事後的インサイト、予測的インサイトがある
- 従量課金で気軽に始められる
- 全リソーススキャンには注意
- 使ってみた感想
- 関連するメトリクスやイベントを良い感じに並べてくれる
- 推奨事項も出してくれる
- → マネージドCloudWatchアラームみたいな感じで良さそう









