![[新機能] Amazon DynamoDB と Amazon SageMaker Lakehouse のZero-ETL統合を試してみました #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3aqf4zA8eWdIL3CoGscPpm/224083826f6e4dd7b971c4967b706ad8/reinvent-2024-try-jp.jpg?w=3840&fm=webp)
[新機能] Amazon DynamoDB と Amazon SageMaker Lakehouse のZero-ETL統合を試してみました #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。Amazon DynamoDB と Amazon SageMaker Lakehouse のZero-ETL統合しました。プレビュー版とはZero-ETLの設定画面やその流れがかなり変わっています。本日はこの新機能が動作する環境を構築し、データが同期される事を検証しました。
Amazon DynamoDB と Amazon SageMaker Lakehouse のZero-ETL統合
この新機能は、DynamoDB から Amazon SageMaker Lakehouse への複雑なデータパイプラインの構築と維持することなくデータが連携され、ニアリアルタイムな分析に利用できるようになります。DynamoDB のパフォーマンスや可用性にほとんど影響を与えず、読み取りキャパシティユニット(RCU)も消費しません。
Zero-ETL統合の主な利点
- ETLパイプラインの構築・管理が不要
- ソースデータが自動的にAmazon SageMaker Lakehouseにレプリケーション
- ニアリアルタイムでデータが更新され、タイムリーな分析が可能
- 複数のデータソースを単一のデータウェアハウスに統合
技術的詳細
Amazon DynamoDBとAmazon SageMaker LakehouseのZero-ETL統合は、DynamoDBテーブルからS3バケットへのデータ転送が自動化され、Apache Icebergを使用してデータ形式と構造が変換されます。
AWS Glue Data Catalogでスキーマ情報が管理され、データパーティショニングや暗号化のカスタマイズも可能です。
- Apache Icebergを使用してDynamoDBのデータ形式と構造をS3に変換
- AWS Glue Data Catalogでスキーマ情報を管理
DynamoDB テーブルの作成
AWS CLI を使用して、以下のコマンドでデータソースとなるテーブルを作成します。
aws dynamodb create-table \
--table-name devices \
--attribute-definitions AttributeName=id,AttributeType=S AttributeName=timestamp,AttributeType=S \
--key-schema AttributeName=id,KeyType=HASH AttributeName=timestamp,KeyType=RANGE \
--billing-mode PAY_PER_REQUEST
このコマンドは以下の設定でテーブルを作成します。
- テーブル名:
devices - パーティションキー:
id(文字列型) - ソートキー:
timestamp(文字列型) - 課金モード: オンデマンド (PAY_PER_REQUEST)
Point-in-Time リカバリ(PITR)を有効化の設定
AWS CLI を使用して、point-in-time-recoveryを有効化します。
aws dynamodb update-continuous-backups \
--table-name devices \
--point-in-time-recovery-specification PointInTimeRecoveryEnabled=true
1レコード追加
AWS CLI を使用して、1レコード追加します。
aws dynamodb put-item \
--table-name devices \
--item '{"id": {"S": "CM1001"},"timestamp": {"S": "2024-12-05 00:00:00"}}'
Amazon DynamoDB と Amazon SageMaker Lakehouse のZero-ETL統合を試す
事前準備1
出力先となるデータベースを事前に作成します。私はAthenaのクエリエディタで作成しました。
CREATE DATABASE dynamodb_replica;
事前準備2
AWS Glue に必要な権限を付与する IAM ロールが必要です。IAM 権限の設定に関するガイダンスについては、ご覧ください。また、
AWS Glue データカタログのリソースポリシーをAmazon DynamoDB ドキュメントページを参考に設定してください。AWS Glue のリソースポリシーであり、DynamoDBのテーブルではありません。AWS Glue のリソースポリシーは、左のメニューのData catalogのCatalog settingで設定できます。
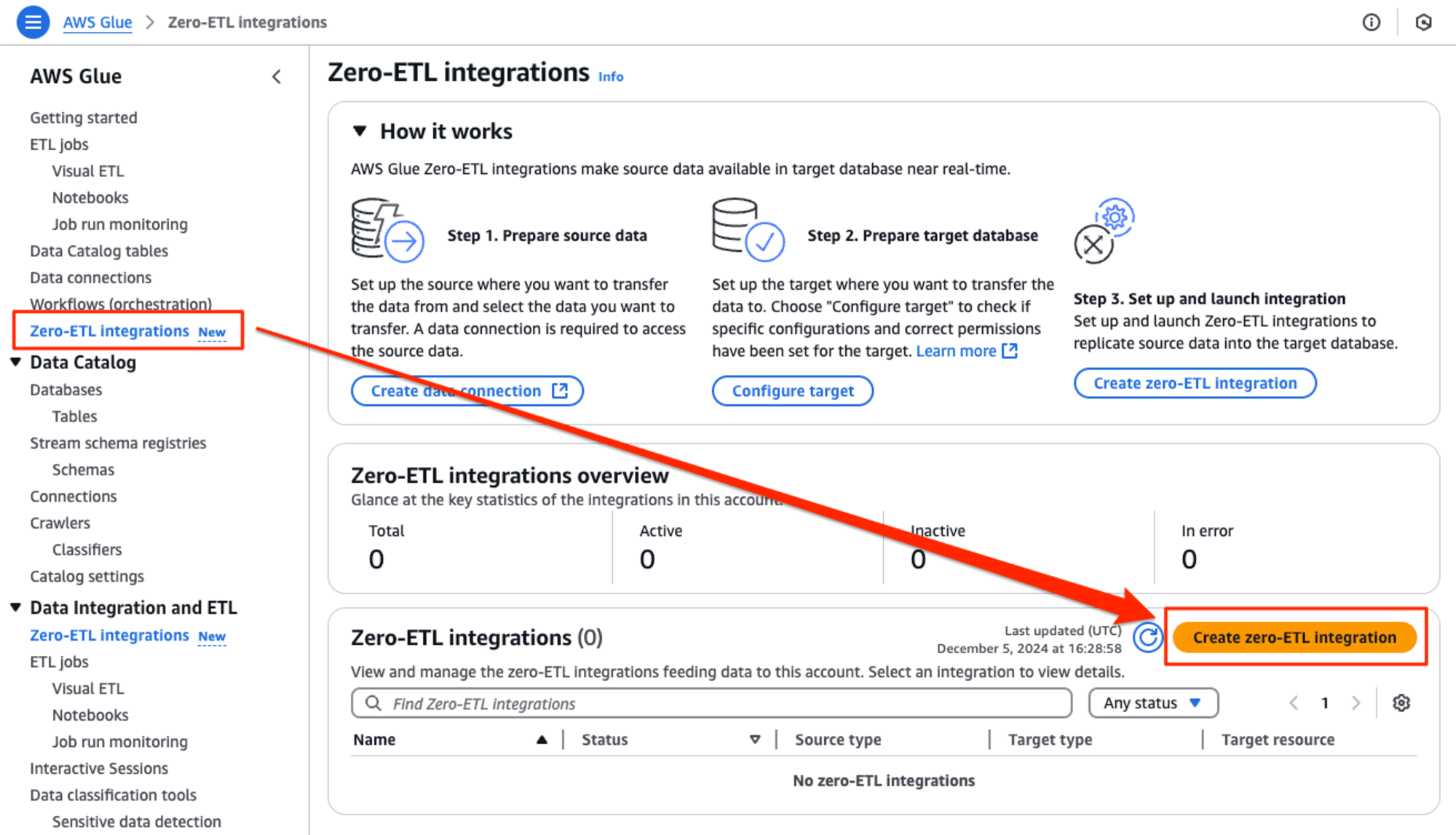
Zero-ETL integrationsを選択
Zero-ETL統合の設定を始めるには、左のメニューに新たに追加された[Zero-ETL integrations New]をクリックして、[Create zero-ETL integration]を押します。
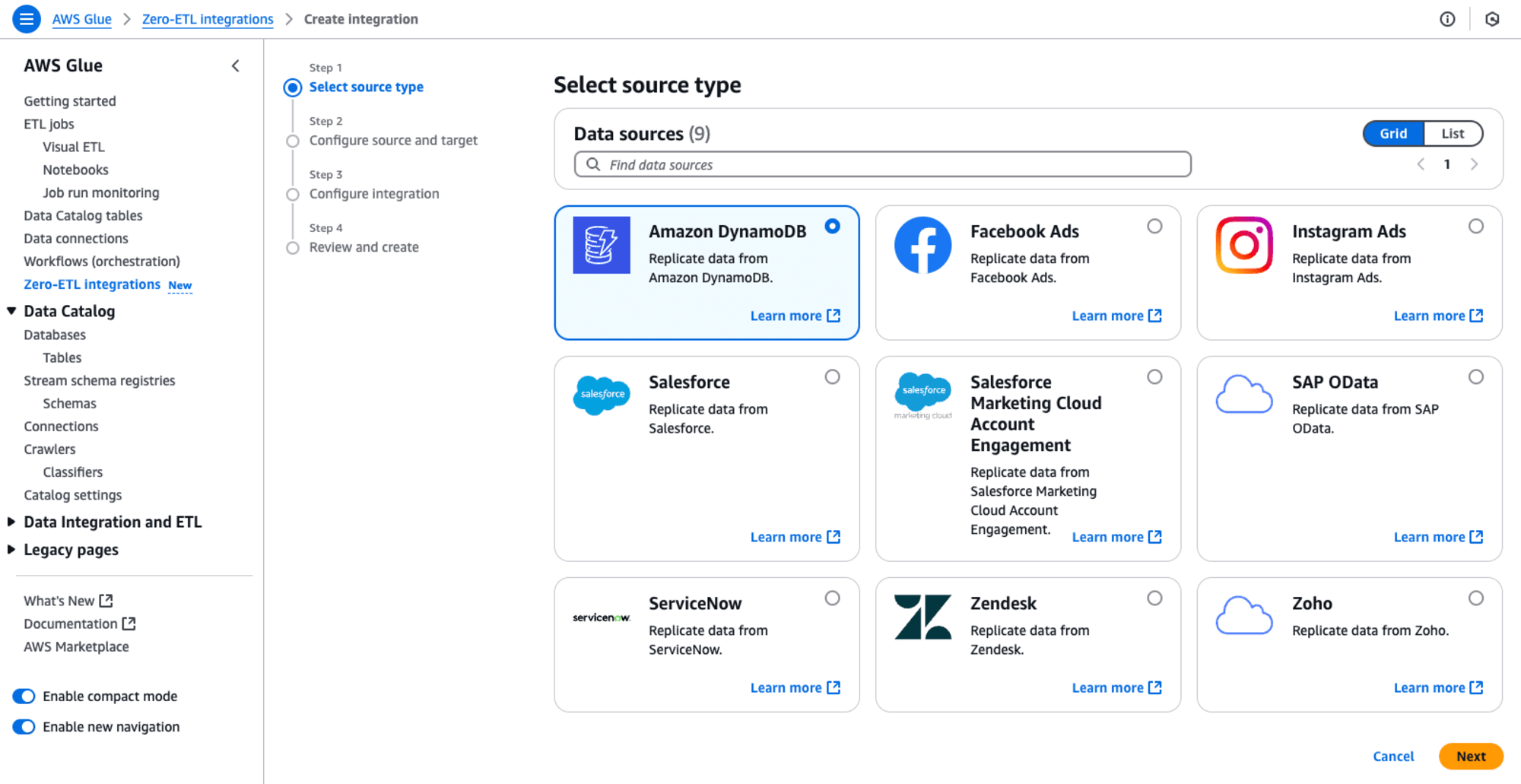
Step 1: Select source type
データソースとしてAmazon DynamoDBを選択します。
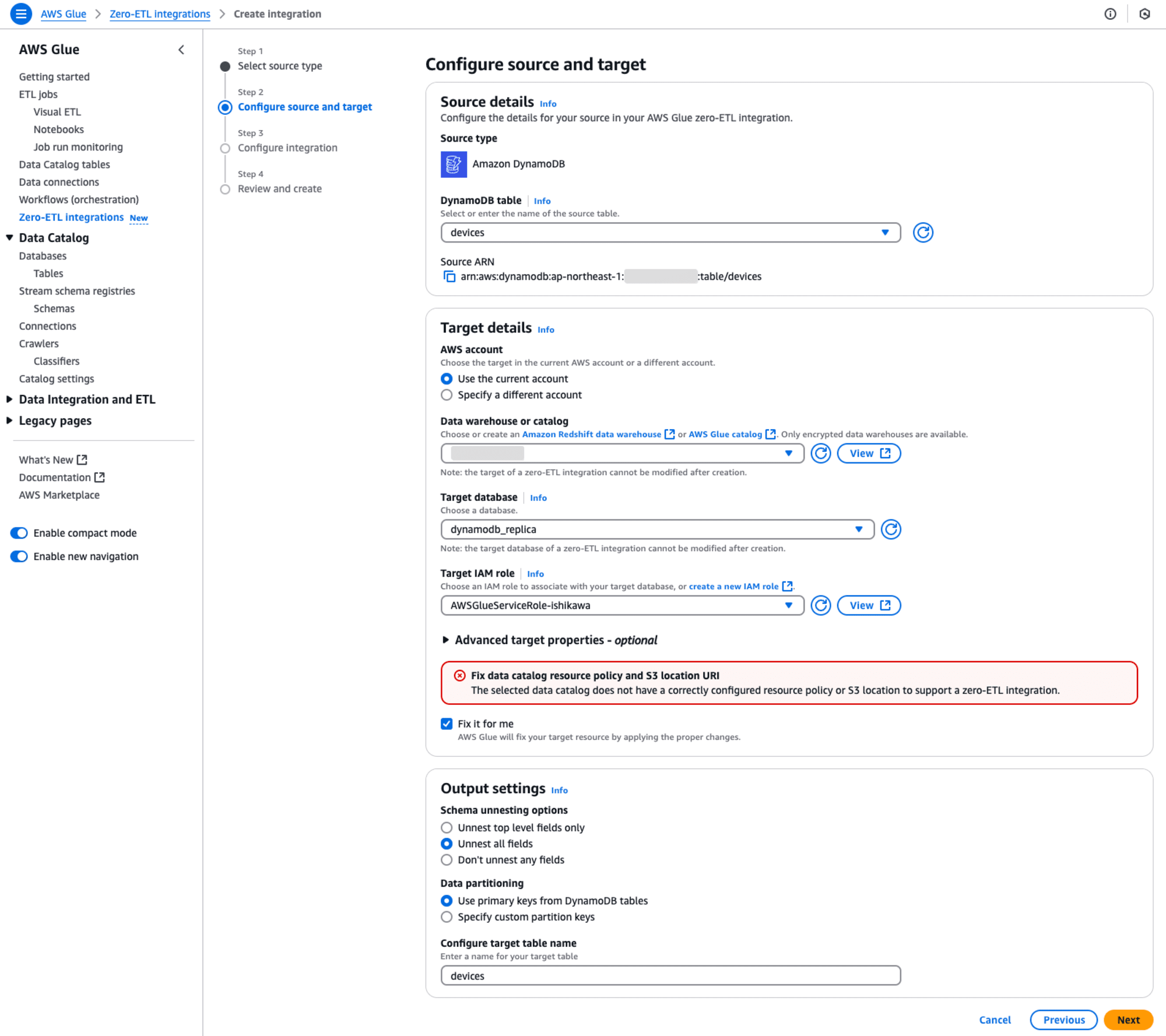
Step 2: Configure source and target
このステップでは、入力となるSource detailsと、出力となるTarget detailsを設定します。
- Source details
- DynamoDB table: 先ほど作成したテーブル(devices)を選択します。
- Target details
- Data warehouse or catalog: 実際にはAWS Glue catalogを指定すると、このAWSアカウントIDが表示されます。
- Target database: 出力先となるGlueデータベース(dynamodb_replica)を指定します。ここで指定するGlueデータベースは事前に作成してください。
- Target IAM role: AWS Glueの実行ロールを指定します。
- Fix it for me: このチェックボックスを選択します、すると必要なリソースポリシーを自動的に追加できます。
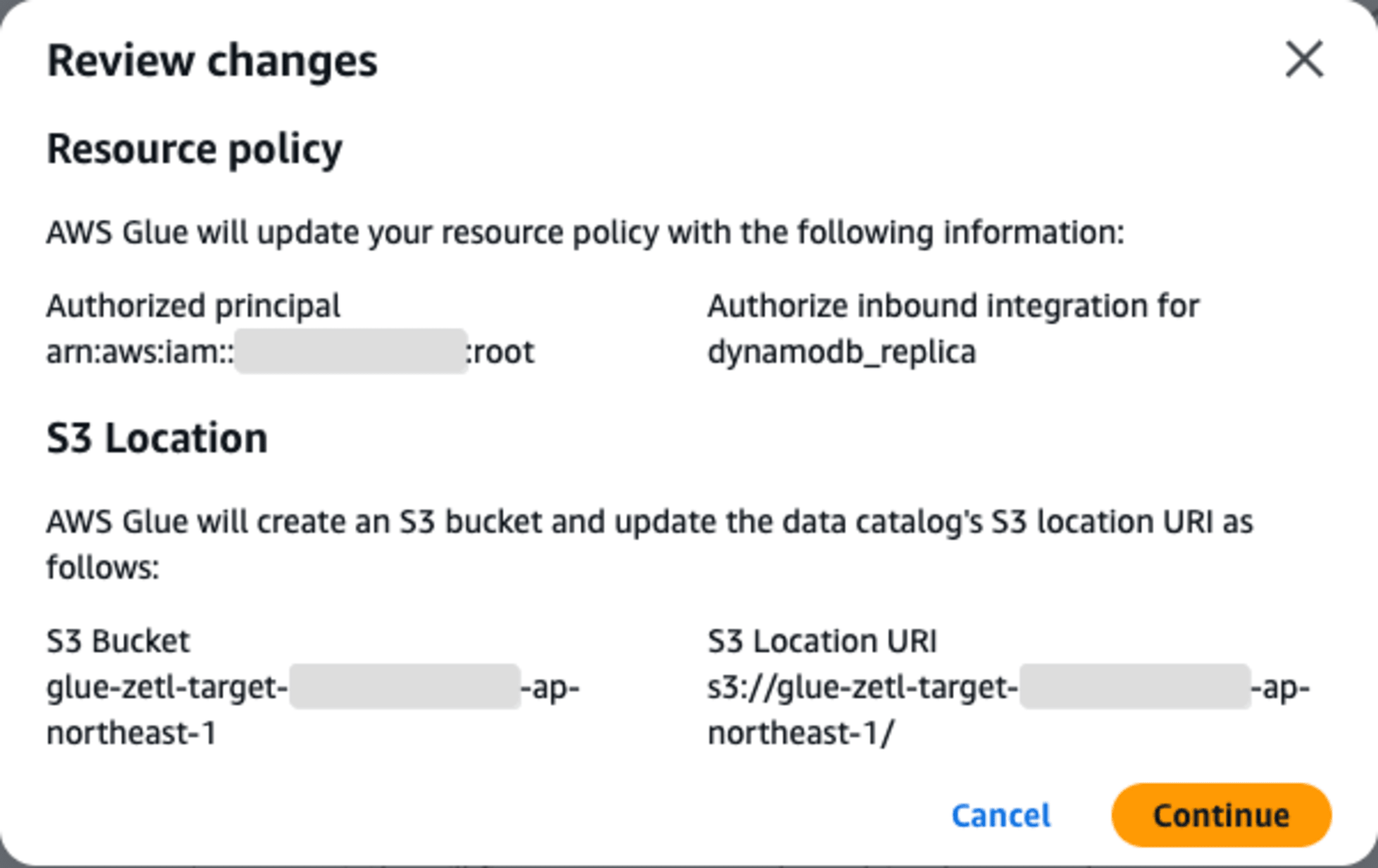
AWS Glue データカタログのリソースポリシーを設定していない場合は、**[Fix it for me]**を選択して、必要なリソースポリシーを自動的に追加できるらしいのですが、私の環境では作成されなかったために後でリソースポリシーを設定しました。そのため、ご紹介する手順では事前準備2で自分で再作成するように手順化しました。
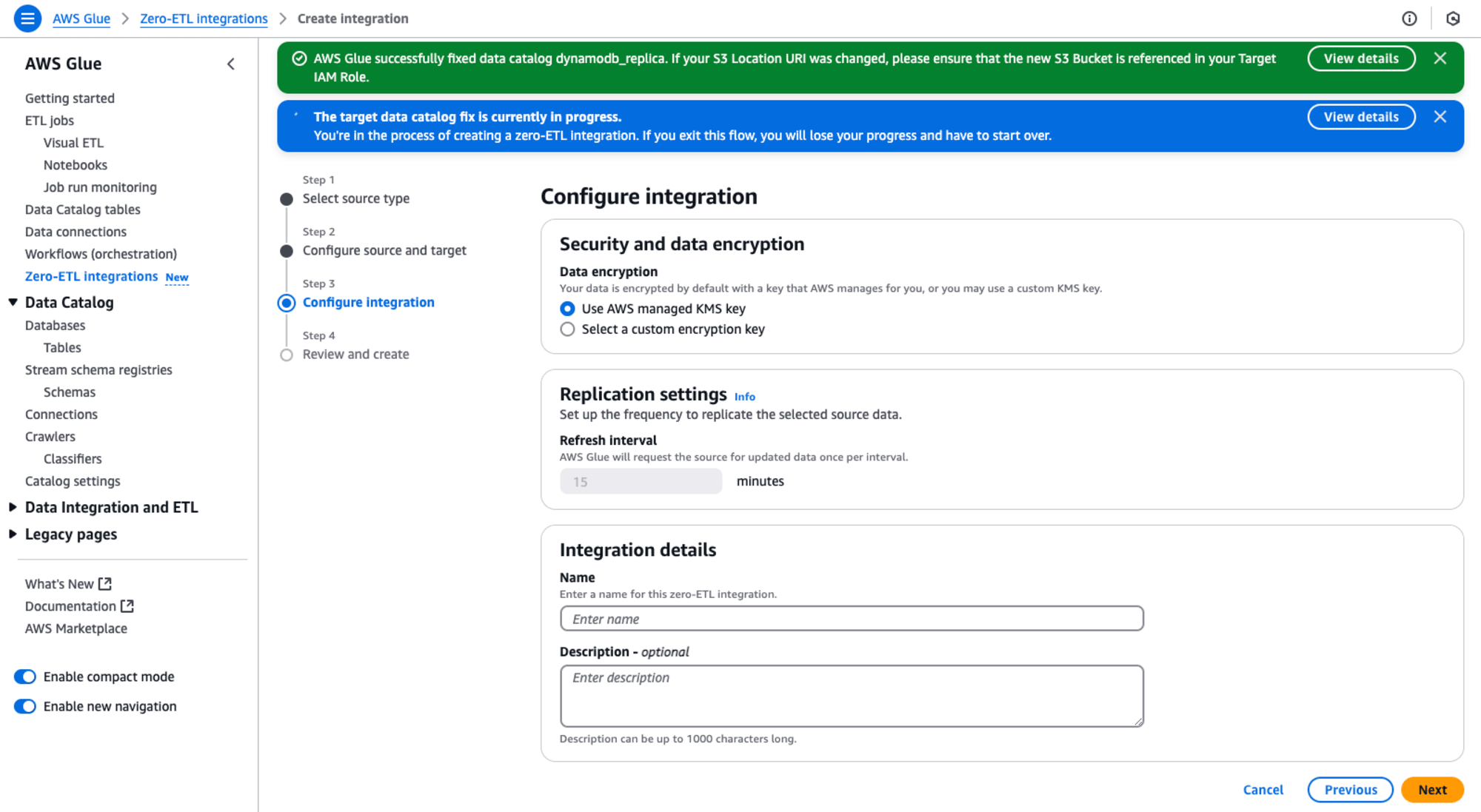
Step 3: Configure integration
Integration について設定します。ここでは、Integration details の Name にIntegrationの名前(dynamodb)を指定します。
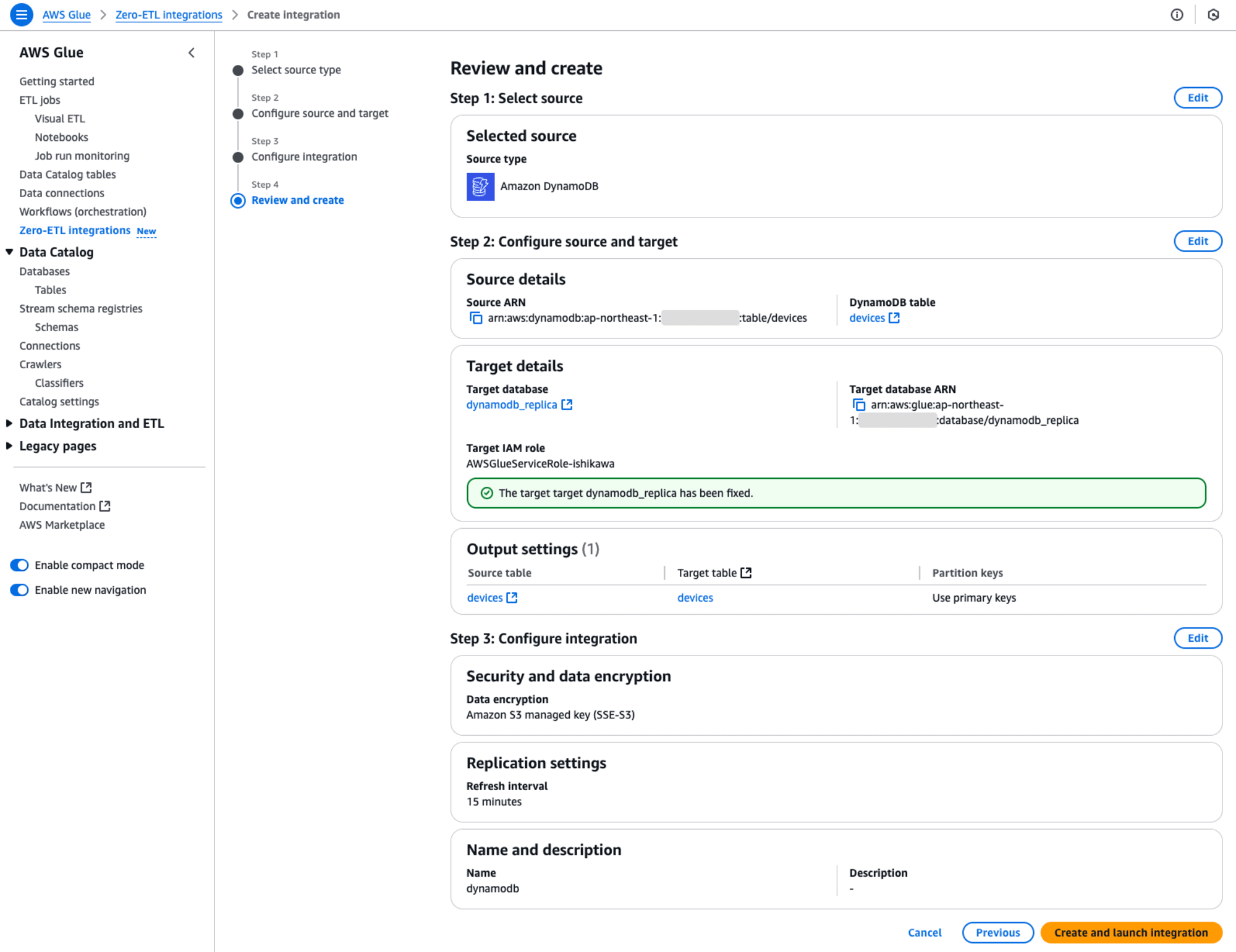
Step 4: Review and create
設定の最終確認です。[Create and launch integration]を押すと作成が開始します。
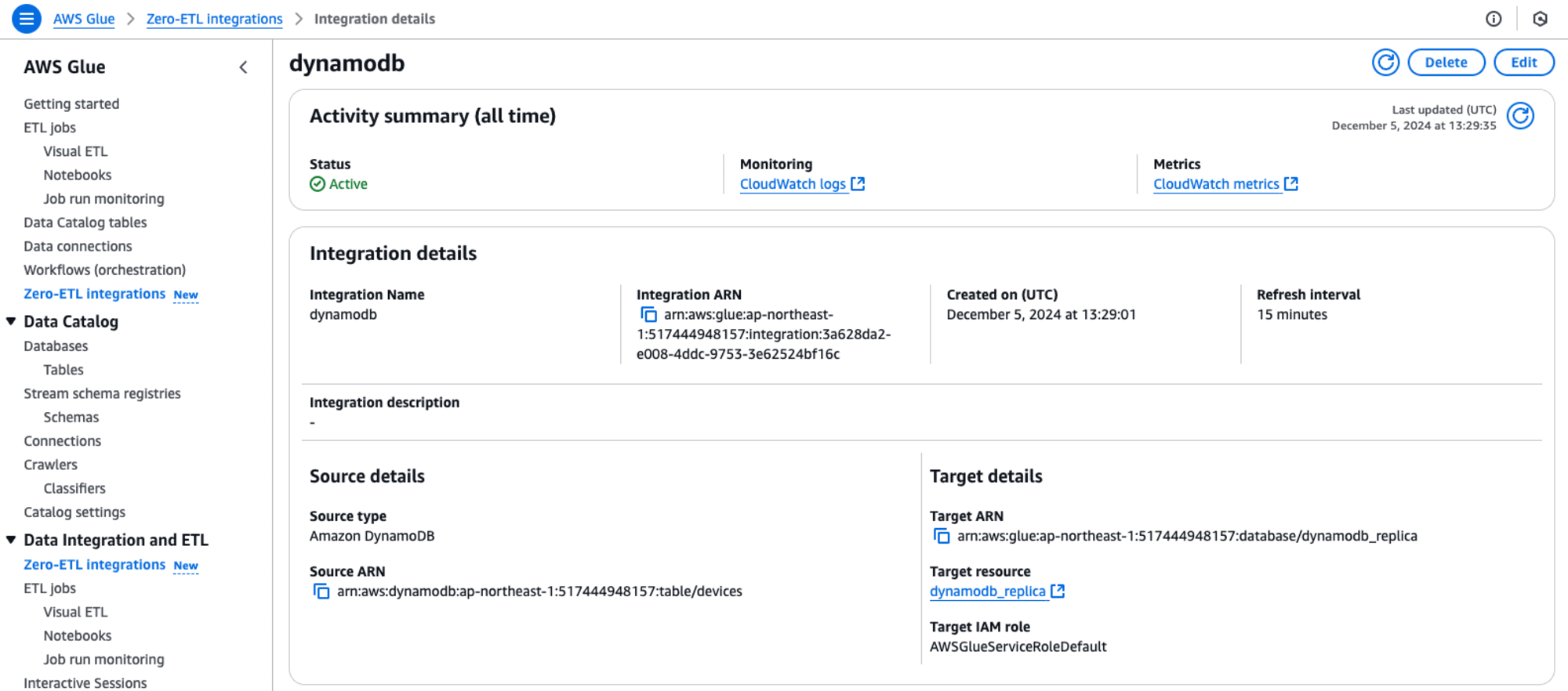
Status がActiveになったら成功です。
動作確認
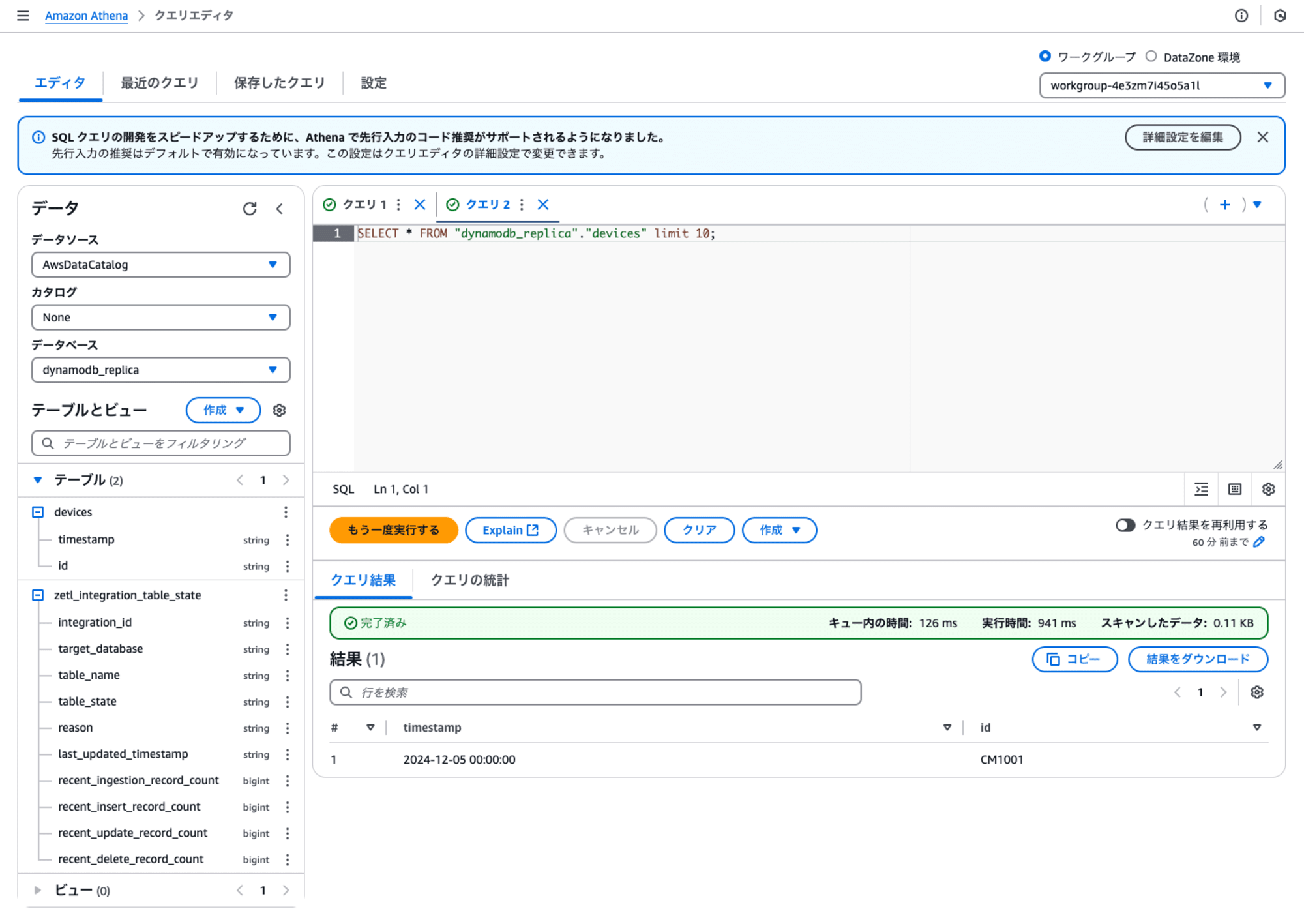
Amazon Athenaから統合されたデータを確認します。事前に作成したデータベース(dynamodb_replica)を開くと、devices と zetl_integration_table_state という2つのテーブルが作成されました。
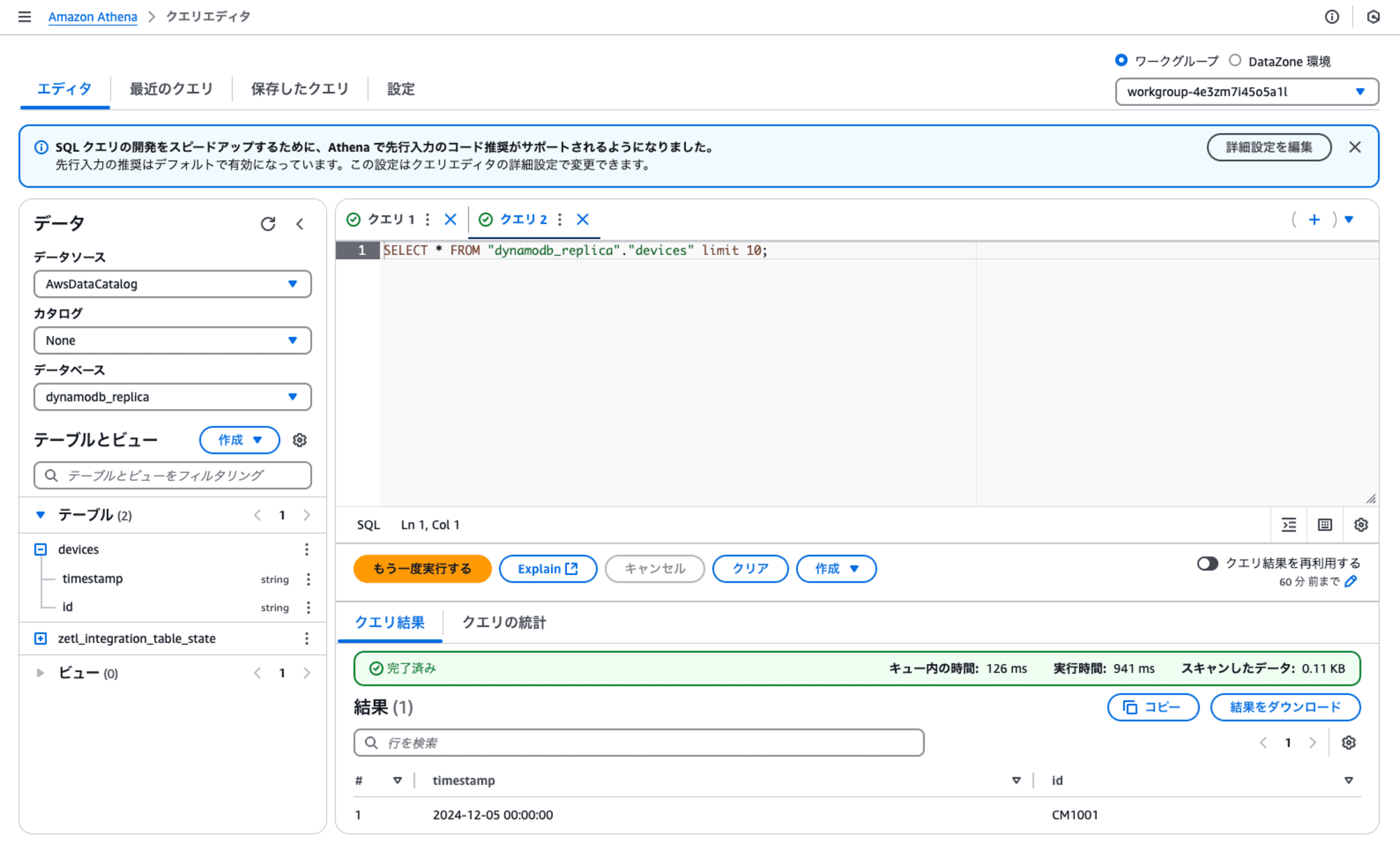
devicesは、DynamoDB上のdevicesとデータの内容が同じことが確認できました。
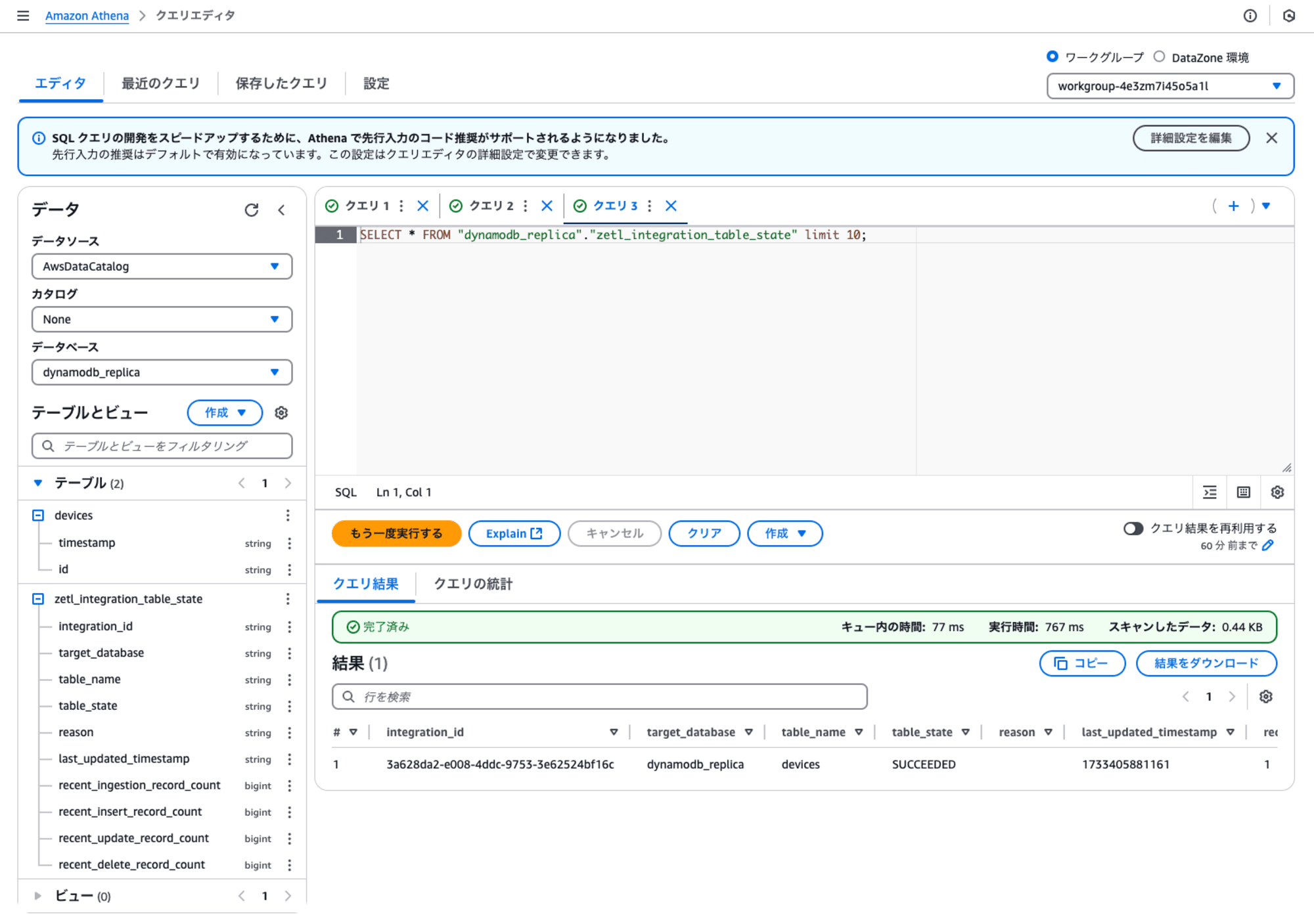
zetl_integration_table_stateテーブルは、AWSのZero-ETL統合に関連する内部テーブルの一つで、主にデータ統合の状態やメタデータを管理するために使用されます。このテーブルは、Amazon SageMaker Lakehouseのデータベース間でのデータ連携をサポートし、リアルタイムでのデータ同期を実現します。
最後に
Amazon DynamoDB と Amazon SageMaker Lakehouse のZero-ETL統合は、複雑なETLプロセスを排除し、DynamoDBからSageMaker Lakehouseへのデータ連携を自動化することで、企業はデータの価値をより迅速かつ効率的に引き出すことが可能になりました。
この統合により、運用データベースと分析環境の壁が取り払われ、リアルタイムでのデータ更新とアクセスが実現します。さらに、Apache Icebergを活用したデータ形式の変換やAWS Glue Data Catalogによるスキーマ管理など、高度な機能も備えています。
今後、この統合機能がさらに進化し、より多くの企業がデータの力を最大限に引き出せるようになることが期待されます。
合わせて読みたい










