
Amazon KendraにFAQ形式のドキュメントを登録して検索してみた
AWSが提供するエンタープライズサーチサービスのAmazon Kendraは、企業内ドキュメントのような様々な形式の 非構造化データ を対象に検索することが可能です。
同時に、 構造化データ の極みのような、質問・回答形式のよくある質問(FAQ)を特定フォーマットで用意することで、インデックスに登録して検索することができます。
このFAQ機能の使い方を共有します。
データ形式
Kendra FAQsは、よくある質問のように質問と回答を明示してインデックスに登録する機能です。
質問と回答を必須とするCSV/JSON形式に対応しており、 検索性を高めるために、独自のデータやアクセスコントロールを追記することもできます。
ベーシック CSVファイル
ベーシックCSVファイルの場合、1列目に質問、2列目に回答を記載することが必須です。
How many free clinics are in Spokane WA?, 13
How many free clinics are there in Mountain View Missouri?, 7, https://s3.region.company.com/bucket-name/directory/faq.csv
3列目はオプションで、参照元を記載します。
カスタムCSVファイル
カスタムCSVファイルの場合、CSVヘッダーで列情報、特に、以下の必須情報を明記します。
- 質問(
_question) - 回答(
_answer)
_question,_answer,_last_updated_at,custom_string
How many free clinics are in Spokane WA?, 13, 2012-03-25T12:30:10+01:00, Note: Some free clinics require you to meet certain criteria in order to use their services
How many free clinics are there in Mountain View Missouri?, 7, 2012-03-25T12:30:10+01:00, Note: Some free clinics require you to meet certain criteria in order to use their services
JSONファイル
JSONファイルの場合、
- 質問(
Question) - 回答(
Answer)
を必須とし、オプションとして
- カスタム属性(
Attributes) - アクセスコントロール(
AccessControlList)
も決められたスキーマで記載できます。
{
"SchemaVersion": 1,
"FaqDocuments": [
{
"Question": "How many free clinics are in Spokane WA?",
"Answer": "13"
},
{
"Question": "How many free clinics are there in Mountain View Missouri?",
"Answer": "7",
"Attributes": {
"_source_uri": "https://s3.region.company.com/bucket-name/directory/faq.csv",
"_category": "Charitable Clinics"
},
"AccessControlList": [
{
"Name": "user@amazon.com",
"Type": "USER",
"Access": "ALLOW"
},
{
"Name": "Admin",
"Type": "GROUP",
"Access": "ALLOW"
}
]
}
]
}
検索データ
今回は、 Amazon Kendraの日本語プロダクトページの「よくある質問」 をベーシックCSV形式で18個用意し、FAQとS3コネクタの2方式で検索し、レスポンスを確認しました。
検証で利用したCSVデータは、本文の最後にあります。
精度等はご自身のデータセットを元に評価ください。
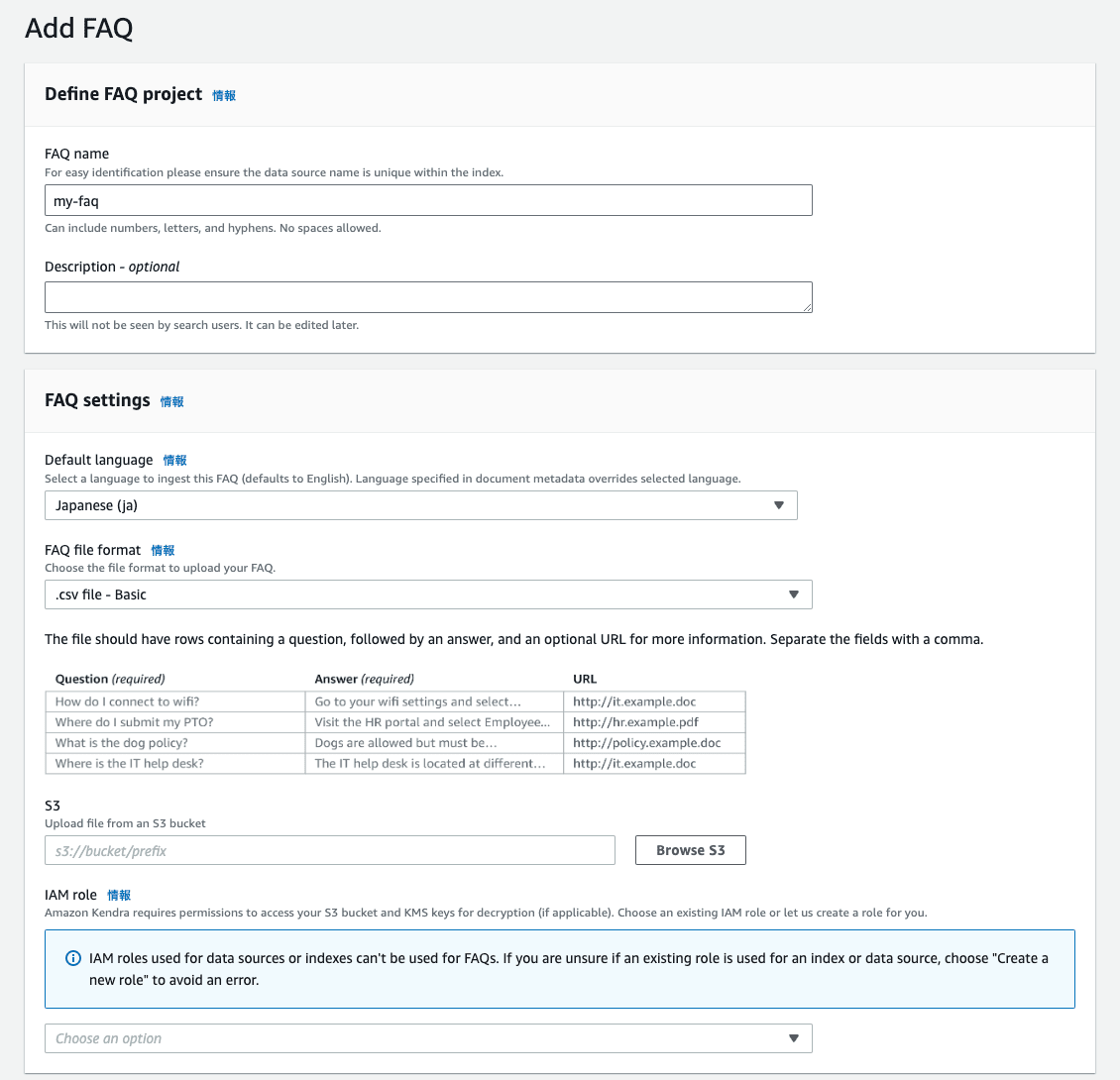
FAQの登録
Kendra のEnterpriseまたはDeveloperインデックスを作成後、サイドメニューからFAQを登録します。
S3のパスと言語を指定するくらいのため、特に迷うところはないはずです。
後述のように、2024年末に登場した GenAI インデックスは FAQ には対応しないことにご注意ください。
検索
FAQ機能とS3コネクタを使った場合の検索API、及び、QueryResultの主な違いは次の表の通りです。
| 項目 | FAQ | S3コネクタ |
|---|---|---|
| 検索API | Queryのみ | Query / Retrieve |
| Type | QUESTION_ANSWER | DOCUMENT |
| DocumentId | ランダム文字列 | S3パス |
| DocumentUri | ベーシックCSVの3列目 / _source_uri | S3パス |
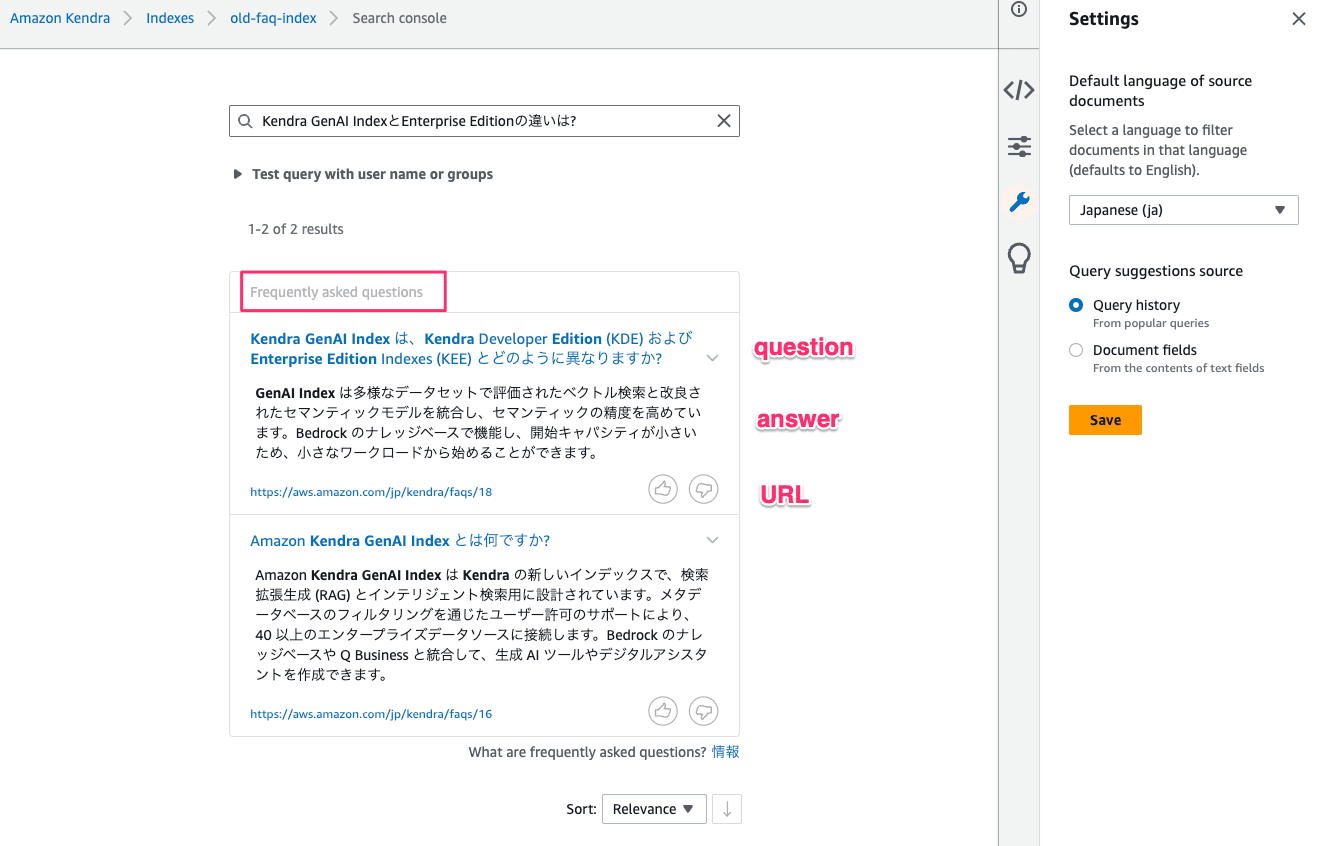
FAQ への検索
FAQデータに対してコンソールから検索すると、2/18件がマッチし、ベースCSVのきれいなデータ構造がそのまま検索結果に活用されていることがわかります
query API で問い合わせてみると、各FAQは "Type": "QUESTION_ANSWER" としてインデクシングされており、 DocumentId にはランダムな文字列が採番され、 DocumentURI(_source_uri) にはベーシックCSV形式の3列目(URL)が利用されていることがわかります。
後述のように、 FAQはretrieve APIには対応していません。
$ aws kendra query \
--index-id f0750f1a-297a-4857-a4c6-14987470661b \
--query-text 'Kendra GenAI IndexとEnterprise Editionの違いは?' \
--attribute-filter '{
"EqualsTo": {
"Key": "_language_code",
"Value": { "StringValue": "ja" }
}
}'
{
"QueryId": "86b185b9-5ea2-4bc6-baea-b054f0b43b4d",
"ResultItems": [
{
"Id": "86b185b9-5ea2-4bc6-baea-b054f0b43b4d-8ffc4bff-4a56-4d4d-a8b5-7a379bb6f0c3",
"Type": "QUESTION_ANSWER",
"Format": "TEXT",
"AdditionalAttributes": [
{
"Key": "QuestionText",
"ValueType": "TEXT_WITH_HIGHLIGHTS_VALUE",
"Value": {
"TextWithHighlightsValue": {
"Text": "Kendra GenAI Index は、Kendra Developer Edition (KDE) および Enterprise Edition Indexes (KEE) とどのように異なりますか?",
"Highlights": [
{
"BeginOffset": 0,
"EndOffset": 6,
"TopAnswer": false,
"Type": "STANDARD"
},
...
{
"BeginOffset": 67,
"EndOffset": 74,
"TopAnswer": false,
"Type": "STANDARD"
}
]
}
}
},
{
"Key": "AnswerText",
"ValueType": "TEXT_WITH_HIGHLIGHTS_VALUE",
"Value": {
"TextWithHighlightsValue": {
"Text": "GenAI Index は多様なデータセットで評価されたベクトル検索と改良されたセマンティックモデル を統合し、セマンティックの精度を高めています。Bedrock のナレッジベースで機能し、開始キャパシティが小さいため、小さなワークロードから始めることができます。",
"Highlights": [
{
"BeginOffset": 0,
"EndOffset": 5,
"TopAnswer": false,
"Type": "STANDARD"
},
{
"BeginOffset": 6,
"EndOffset": 11,
"TopAnswer": false,
"Type": "STANDARD"
}
]
}
}
}
],
"DocumentId": "8c5c671f1fd526fa356a5ffe3f3dd5c30c3ae1f3a3a4feaf0205e3b0ca4768e0b141ba3e-d82f-4afa-b45f-469b5c79d410",
"DocumentTitle": {
"Text": ""
},
"DocumentExcerpt": {
"Text": "GenAI Index は多様なデータセットで評価されたベクトル検索と改良されたセマンティックモデルを統合し、セ マンティックの精度を高めています。Bedrock のナレッジベースで機能し、開始キャパシティが小さいため、小さなワークロードから始めることができます。",
"Highlights": [
{
"BeginOffset": 0,
"EndOffset": 131,
"TopAnswer": false,
"Type": "STANDARD"
}
]
},
"DocumentURI": "https://aws.amazon.com/jp/kendra/faqs/18",
"DocumentAttributes": [
{
"Key": "_source_uri",
"Value": {
"StringValue": "https://aws.amazon.com/jp/kendra/faqs/18"
}
}
],
"ScoreAttributes": {
"ScoreConfidence": "VERY_HIGH"
},
"FeedbackToken": "AYA..."
},
...
}
S3への検索
CSVファイルを $ split -l 1 FILENAME で行ごとに分割してS3にアップロードし、 S3コネクタ でインデクシングした場合です。
コンソールから検索すると18/18の全件がマッチし、
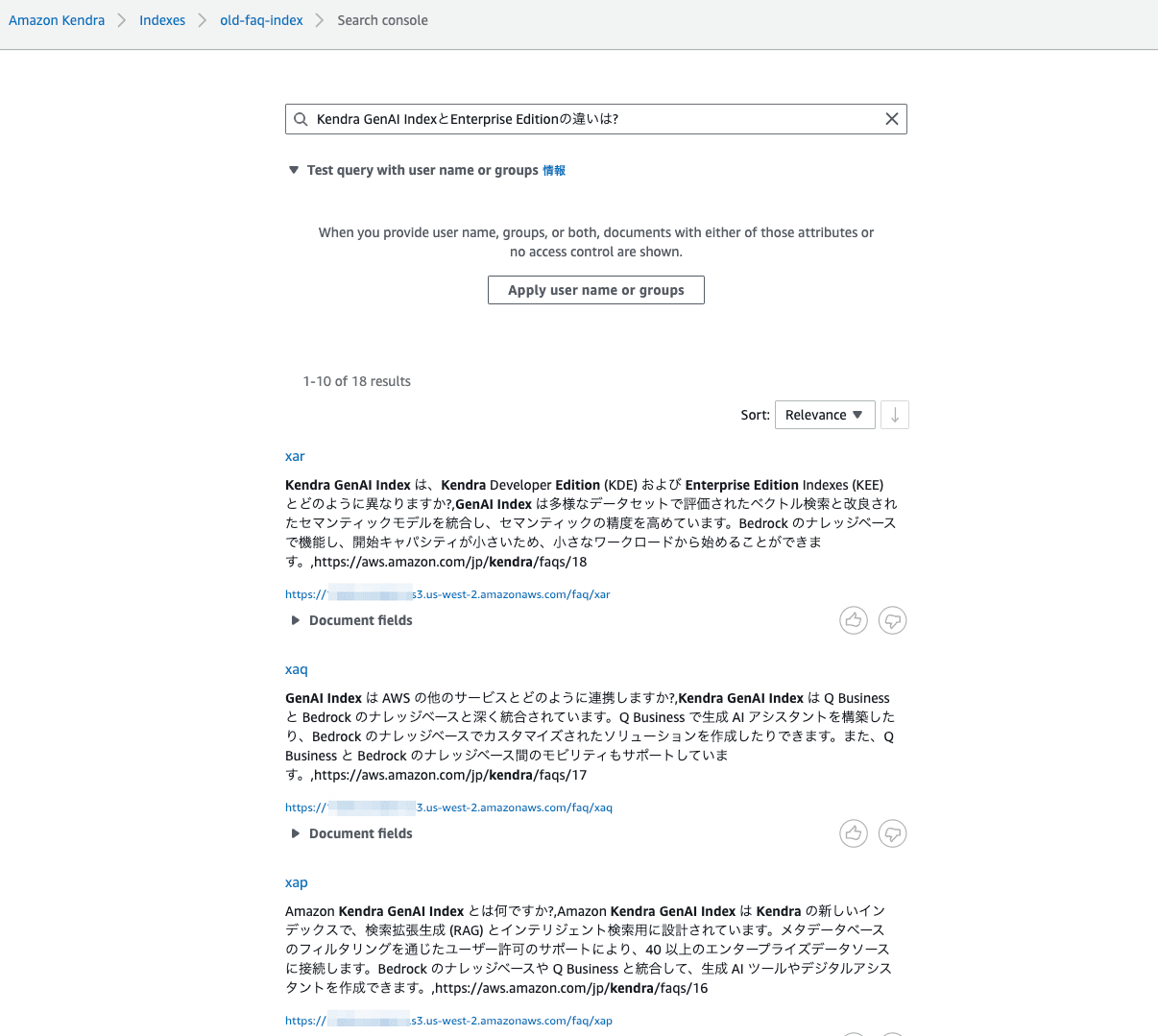
query API で問い合わせてみると、各FAQは "Type": "DOCUMENT" としてインデクシングされており、 DocumentId と DocumentURI(_source_uri) にはS3のパスが利用されていることがわかります。
$ aws kendra query \
--index-id f0750f1a-297a-4857-a4c6-14987470661b \
--query-text 'Kendra GenAI IndexとEnterprise Editionの違いは?' \
--attribute-filter '{
"EqualsTo": {
"Key": "_language_code",
"Value": { "StringValue": "ja" }
}
}'
{
"QueryId": "8c7cb392-2dab-4a89-b147-60f846c1c306",
"ResultItems": [
{
"Id": "8c7cb392-2dab-4a89-b147-60f846c1c306-40086ac2-2492-4b90-b9ac-f0ce26aaea3c",
"Type": "DOCUMENT",
"Format": "TEXT",
"AdditionalAttributes": [],
"DocumentId": "s3://YOUR-BUCKET-NAME/faq/xar",
"DocumentTitle": {
"Text": "xar",
"Highlights": []
},
"DocumentExcerpt": {
"Text": "Kendra GenAI Index は、Kendra Developer Edition (KDE) および Enterprise Edition Indexes (KEE) とどの ように異なりますか?,GenAI Index は多様なデータセットで評価されたベクトル検索と改良されたセマンティックモデルを統合し、セマンティックの精度を高めています。Bedrock のナレッジベースで機能し、開始キャパシティが小さいため、小さなワークロードから始めることができます。,https://aws.amazon.com/jp/kendra/faqs/18",
"Highlights": [
{
"BeginOffset": 0,
"EndOffset": 6,
"TopAnswer": false,
"Type": "STANDARD"
},
...
}
]
},
"DocumentURI": "https://YOUR-BUCKET-NAME.s3.us-west-2.amazonaws.com/faq/xar",
"DocumentAttributes": [
{
"Key": "_source_uri",
"Value": {
"StringValue": "https://YOUR-BUCKET-NAME.s3.us-west-2.amazonaws.com/faq/xar"
}
},
{
"Key": "s3_document_id",
"Value": {
"StringValue": "xar"
}
}
],
"ScoreAttributes": {
"ScoreConfidence": "VERY_HIGH"
},
"FeedbackToken": "AYA..."
},
...
}
注意事項
最後に、FAQ機能を評価した上で遭遇した注意事項を2つ述べます。
GenAI インデックスには対応していない
2024年末に、RAG等の生成AIに最適化されたAmazon Kendra GenAI Indexが発表されました。
FAQはこの新しいインデックスに対応しておらず、コンソールメニューにFAQはなく、GenAIインデックスに対してFAQ系APIを呼び出すと、次の様にエラーが発生します。
$ aws kendra list-faqs --index-id e937d77c-549a-4f6c-85ad-e86873a41c7d
An error occurred (ValidationException) when calling the ListFaqs operation: FAQ is not supported for GenAI index.
Kendra::Retrieve APIを使えない
FAQドキュメントの検索は query API では成功するものの retrieve API では引っかからないことに気づきます。
Kendra Query API のドキュメントには FAQ に対応していると記述があります。
A query response contains three types of results.
・Relevant suggested answers. The answers can be either a text excerpt or table excerpt. The answer can be highlighted in the excerpt.
・Matching FAQs or questions-answer from your FAQ file.
・Relevant documents. This result type includes an excerpt of the document with the document title. The searched terms can be highlighted in the excerpt.
...
一方で、Kendra Retrieve APIのドキュメントを確認すると、This doesn't include question-answer or FAQ type responses from your index. とある通り、FAQに対して retrieve API で検索することはできません。
This API is similar to the Query API. However, by default, the Query API only returns excerpt passages of up to 100 token words. With the Retrieve API, you can retrieve longer passages of up to 200 token words and up to 100 semantically relevant passages. This doesn't include question-answer or FAQ type responses from your index. The passages are text excerpts that can be semantically extracted from multiple documents and multiple parts of the same document. If in extreme cases your documents produce zero passages using the Retrieve API, you can alternatively use the Query API and its types of responses.
Kendraのドキュメント履歴を確認すると、retrieve API は、検索結果により長いトークンが好ましい RAG のようなユースケースをターゲットに、2023年に追加されています。
Retrieve semantically relevant passages using the Amazon Kendra Retrieve API for retrieval augmented generation (RAG) systems.
https://docs.aws.amazon.com/kendra/latest/dg/doc-history.html
まとめ
FAQ形式のデータをKendraにインデクシングさせるFAQ機能を紹介しました。
FAQ機能はKendraリリース当初から存在し、ヘルプセンターやFAQのような構造化データを活かして効率的にインデクシングできる一方で、retrieve APIやGenAIインデックスのような新しい機能・サービスでは対応していないことにご注意ください。
参考
- https://docs.aws.amazon.com/kendra/latest/dg/in-creating-faq.html
- https://zenn.dev/solvio/articles/5675473b392b7f
利用データ
Amazon Kendra とは何ですか?,Amazon Kendra は、機械学習を利用する高精度で使いやすいエンタープライズ検索サービスです。企業全体に散在するコンテンツ内の情報を、機械学習アルゴリズムを使用して検索し、最も適切な回答を返します。,https://aws.amazon.com/jp/kendra/faqs/1
Amazon Kendra は他の AWS のサービスとどのように連携しますか?,Amazon S3やRDSなどの一般的なAWSリポジトリ向けのネイティブコネクタを提供。Amazon Comprehend、Transcribe、Comprehend Medicalなどの他のAIサービスと連携し、文書の前処理や検索機能の強化が可能です。,https://aws.amazon.com/jp/kendra/faqs/2
Amazon Kendra にはどのようなタイプの質問ができますか?,ファクトイド型質問(誰、何、いつ、どこで)、記述的な質問、キーワード検索がサポートされています。,https://aws.amazon.com/jp/kendra/faqs/3
Amazon Kendra が探している正確な回答がデータに含まれていない場合はどうなりますか?,深層学習モデルによってランク付けされた最も関連性の高いドキュメントのリストを返します。,https://aws.amazon.com/jp/kendra/faqs/4
Amazon Kendra が回答できない質問はどのようなタイプのものですか?,ドキュメント間でのパッセージ集約または計算が必要な質問には対応していません。,https://aws.amazon.com/jp/kendra/faqs/5
Amazon Kendra を起動して実行するにはどうすればよいですか?,Amazon Kendraコンソールで、Amazon S3に保存されたドキュメントを設定。Experience Builderまたはアプリケーションプログラミングインターフェース(API)を使用して検索をデプロイできます。,https://aws.amazon.com/jp/kendra/faqs/6
会社の専門領域やビジネスの専門分野にさらに適合するよう Amazon Kendra をカスタマイズするにはどうすればよいですか?,独自のシノニムリストを用意し、特定分野に対するKendraの理解を微調整できます。様々な業界に特化した専門知識を提供しています。,https://aws.amazon.com/jp/kendra/faqs/7
Amazon Kendra ではどのようなファイルタイプがサポートされますか?,HTML、MS Office(.doc、.ppt)、PDF、テキスト形式の非構造化および半構造化データをサポート。MediaSearchソリューションでオーディオ・ビデオファイルも検索可能。,https://aws.amazon.com/jp/kendra/faqs/8
Amazon Kendra は増分データ更新をどのように処理しますか?,コネクタによるデータソースの定期的な自動同期と、Amazon Kendra APIを通じたデータ送信により、インデックスを最新に保ちます。,https://aws.amazon.com/jp/kendra/faqs/9
Amazon Kendra はどの言語をサポートしていますか?,ドキュメントのページで確認可能です。,https://aws.amazon.com/jp/kendra/faqs/10
Amazon Kendra を使用するにはどのようなコード変更を行う必要がありますか?,ネイティブコネクタ使用時はコーディング不要。Experience BuilderまたはKendra APIを使用して検索をデプロイできます。,https://aws.amazon.com/jp/kendra/faqs/11
Amazon Kendra はどのリージョンで利用できますか?,「AWS リージョン別のサービス」のページで確認可能です。,https://aws.amazon.com/jp/kendra/faqs/12
カスタムコネクタを追加することはできますか?,Kendra カスタムデータソース APIを使用して独自のコネクタを作成可能。パートナーエコシステムによるサポートも受けられます。,https://aws.amazon.com/jp/kendra/faqs/13
Amazon Kendra のセキュリティはどのように処理されていますか?,転送中と保管中のデータを暗号化。KMSキーによる暗号化、HTTPSプロトコル、TLSを使用してセキュリティを確保。,https://aws.amazon.com/jp/kendra/faqs/14
Amazon Kendra は、オーディオやビデオの記録内容から答えを見つけることができますか?,MediaSearchソリューションにより、Amazon Transcribeと組み合わせてオーディオ・ビデオコンテンツから関連する答えを検索可能。,https://aws.amazon.com/jp/kendra/faqs/15
Amazon Kendra GenAI Index とは何ですか?,Amazon Kendra GenAI Index は Kendra の新しいインデックスで、検索拡張生成 (RAG) とインテリジェント検索用に設計されています。メタデータベースのフィルタリングを通じたユーザー許可のサポートにより、40 以上のエンタープライズデータソースに接続します。Bedrock のナレッジベースや Q Business と統合して、生成 AI ツールやデジタルアシスタントを作成できます。,https://aws.amazon.com/jp/kendra/faqs/16
GenAI Index は AWS の他のサービスとどのように連携しますか?,Kendra GenAI Index は Q Business と Bedrock のナレッジベースと深く統合されています。Q Business で生成 AI アシスタントを構築したり、Bedrock のナレッジベースでカスタマイズされたソリューションを作成したりできます。また、Q Business と Bedrock のナレッジベース間のモビリティもサポートしています。,https://aws.amazon.com/jp/kendra/faqs/17
Kendra GenAI Index は、Kendra Developer Edition (KDE) および Enterprise Edition Indexes (KEE) とどのように異なりますか?,GenAI Index は多様なデータセットで評価されたベクトル検索と改良されたセマンティックモデルを統合し、セマンティックの精度を高めています。Bedrock のナレッジベースで機能し、開始キャパシティが小さいため、小さなワークロードから始めることができます。,https://aws.amazon.com/jp/kendra/faqs/18









