
Amazon Q in Connect と ServiceNow 統合時、大量のナレッジ記事に対するタグ付けを実装してみた
はじめに
以前、Amazon Q in Connect と ServiceNow の統合時に、AWS Step Functions を使って定期的にナレッジへタグ付けする方法を紹介しました。
ただし、この方法には課題がありました。ServiceNow に数万件規模のナレッジが存在する場合、Step Functions のステート入出力サイズ制限(256KB)に抵触するため、全件を取得してから対象記事のみを抽出・タグ付けする構成の実装が困難でした。
そこで本記事では、Step Functions ではなく Lambda を中心とした実装に変更し、記事数が多い環境でも段階的にタグ付けを行う方法を紹介します。
構成
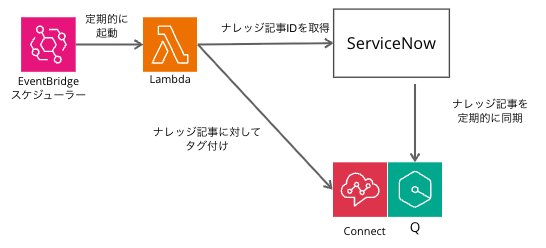
処理の流れは以下のとおりです。
- EventBridge Scheduler が定期的に Lambda を起動する
- Lambda が ServiceNow API を呼び出し、対象の公開済み記事を取得する
- Lambda が Amazon Q in Connect の API を呼び出し、同期済みコンテンツ一覧を取得する
- ServiceNow の記事番号と Q in Connect のコンテンツを照合し、一致するコンテンツへタグを付与する
前提条件
- ServiceNow でナレッジ記事を作成済みであること
- Amazon Q in Connect を有効化済みであること
- EventBridge Scheduler を作成済みであること
Amazon Q in Connect に同期されたナレッジ記事数を集計する
まず、Amazon Q in Connect に同期されているナレッジ記事数を確認します。
以下のスクリプトを AWS CloudShell で実行します。
Q_CONNECT_KB_ID は、aws qconnect list-knowledge-bases で確認できます。
cat << 'EOF' > get_q_contents.py
import boto3
import json
# 設定
Q_CONNECT_KB_ID = "0f961e7e-e9f3-45d2-8d47-86b82c87ab90"
OUTPUT_FILE = "aws_q_contents_all.txt"
REGION = "ap-northeast-1" # 適切なリージョンを指定
def get_all_contents():
client = boto3.client('qconnect', region_name=REGION)
paginator = client.get_paginator('list_contents')
print(f"Start fetching contents for KB: {Q_CONNECT_KB_ID}...")
all_numbers = []
page_count = 0
# Paginatorが自動でNextTokenを処理して全ページ取得します
try:
for page in paginator.paginate(knowledgeBaseId=Q_CONNECT_KB_ID, maxResults=100):
page_count += 1
if 'contentSummaries' in page:
for content in page['contentSummaries']:
# metadata.number を取得
if 'metadata' in content and 'number' in content['metadata']:
all_numbers.append(content['metadata']['number'])
# 進捗表示(10ページごと)
if page_count % 10 == 0:
print(f"Fetched {len(all_numbers)} items... (Page {page_count})")
except Exception as e:
print(f"Error occurred: {e}")
return all_numbers
if __name__ == "__main__":
results = get_all_contents()
# 結果をファイルに保存
with open(OUTPUT_FILE, 'w') as f:
for num in results:
f.write(f"{num}\n")
print(f"Done. Total fetched items: {len(results)}")
print(f"Saved to {OUTPUT_FILE}")
EOF
処理内容は以下の通りです。
- Amazon Q in Connect のクライアントを初期化し、
list_contentsAPI を呼び出します。 - ページネーション(
Paginator)を利用して、指定したナレッジベース内の全コンテンツを順次取得します。 - 各コンテンツのメタデータから記事番号(
number)を抽出し、リストに格納します。 - 取得した全記事番号をテキストファイルに出力し、総件数を表示します。
実行します。
$ python3 get_q_contents.py
Start fetching contents for KB: 0f961e7e-e9f3-45d2-8d47-86b82c87ab90...
Fetched 1000 items... (Page 10)
Fetched 2000 items... (Page 20)
Fetched 3000 items... (Page 30)
Fetched 4000 items... (Page 40)
Fetched 5000 items... (Page 50)
Fetched 6000 items... (Page 60)
Fetched 7000 items... (Page 70)
Fetched 8000 items... (Page 80)
Fetched 9000 items... (Page 90)
Fetched 10000 items... (Page 100)
Fetched 11000 items... (Page 110)
Fetched 12000 items... (Page 120)
Fetched 13000 items... (Page 130)
Fetched 14000 items... (Page 140)
Fetched 15000 items... (Page 150)
Fetched 16000 items... (Page 160)
Fetched 17000 items... (Page 170)
Fetched 18000 items... (Page 180)
Fetched 19000 items... (Page 190)
Fetched 20000 items... (Page 200)
Done. Total fetched items: 20210
Saved to aws_q_contents_all.txt
~ $
実行結果から、同期済みコンテンツが 20,210 件 あることが分かりました。
タグ付けルールの定義と事前準備
全件ではなく、特定のナレッジベースやカテゴリに絞ってタグ付けを行うためのルールを定義し、実装に必要なパラメータ(ID)を確認します。
対象範囲(含める/除外する条件)
本記事では、以下の条件に基づいてタグ付けの対象範囲(含める記事・除外する記事)を定義します。
- 対象
- ナレッジベース「KCS Knowledge Base (demo data)」配下の全記事
- ナレッジベース「cm-hirai」配下のカテゴリ「test」配下の記事
- 除外対象
- 上記対象範囲のうち、カテゴリ名に「アーカイブ」または「Archive」を含むカテゴリ配下の記事(子・孫カテゴリ配下を含む)
ServiceNow のナレッジベース(sys_id)を確認する
ServiceNow のインスタンス名と、Admin 権限を持つユーザー名・パスワードを使って API を実行すると、ナレッジベースの sys_id を取得できます。
これらの値は、後ほど作成する Lambda のコード内で使用します。
今回は AWS CloudShell で実行し、ナレッジベース名「cm-hirai」と「KCS Demo KB」に対応する sys_id を控えておきます。
$ curl -X GET \
"https://インスタンス名.service-now.com/api/now/table/kb_knowledge_base?sysparm_fields=sys_id,title,description" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
--user 'ユーザー名:パスワード' \
| jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 688 0 688 0 0 1128 0 --:--:-- --:--:-- --:--:-- 1127
{
"result": [
{
"sys_id": "0aa3ffa7db7c030064dd36cb7c96197f",
"description": "KCS Demo KB",
"title": "KCS Knowledge Base (demo data)"
},
{
"sys_id": "203c024fc32032107f159b377d0131bb",
"description": "",
"title": "cm-hirai"
},
Lambdaの作成
タグ付け処理を実行する Lambda 関数を作成します。
本記事では、以下の2ステップで実装を進めます。
- 対象記事抽出の確認: ServiceNow から対象記事が正しく取得できるかを確認する(タグ付けは行わない)
- タグ付け処理の実装: 確認したロジックを用いて、実際に Amazon Q in Connect へタグ付けを行う
以下の設定でLambdaを作成します。
- 実行時間:15分
- IAMポリシー
- AWSLambdaBasicExecutionRole
- 以下のIAMポリシーを適用(タグ付け処理で必要となる権限です)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"wisdom:TagResource",
"wisdom:ListContents"
],
"Resource": "*"
}
]
}
1. 対象記事抽出の確認(ドライラン)
まずは、タグ付け対象となる記事が意図した通りに抽出できるかを確認するため、ServiceNow から記事番号を取得して集計するコードをデプロイします。
スクリプト内で使用する以下の環境変数は、Amazon Q in Connect と ServiceNow の統合時に設定した値を使用します。
SERVICENOW_INSTANCESERVICENOW_USERNAMESERVICENOW_PASSWORD
実装する確認用コードは以下の通りです。
import json
import os
import time
from datetime import datetime
import urllib.request
import urllib.parse
import base64
# --- 環境変数 ---
SERVICENOW_INSTANCE = os.environ.get('SERVICENOW_INSTANCE')
SERVICENOW_USERNAME = os.environ.get('SERVICENOW_USERNAME')
SERVICENOW_PASSWORD = os.environ.get('SERVICENOW_PASSWORD')
REQUEST_TIMEOUT = int(os.environ.get('REQUEST_TIMEOUT_SECONDS', '60'))
# --- 設定:取得対象の定義 ---
# curlの結果から判明した sys_id を直接設定します
TARGET_CONFIGS = [
{
# KCS Knowledge Base (demo data)
"kb_id": "0aa3ffa7db7c030064dd36cb7c96197f",
"kb_name_log": "KCS Knowledge Base (demo data)",
"root_category_name": None # None = KB配下の全カテゴリ対象
},
{
# cm-hirai
"kb_id": "203c024fc32032107f159b377d0131bb",
"kb_name_log": "cm-hirai",
"root_category_name": "test" # 指定カテゴリ配下のみ対象
}
]
# 除外キーワード(部分一致)
EXCLUDE_KEYWORDS = ["アーカイブ", "Archive"]
# URL長制限(414 URI Too Long)回避のため、チャンクサイズを30に設定
ARTICLE_CHUNK_SIZE = 30
def lambda_handler(event, context):
if not (SERVICENOW_USERNAME and SERVICENOW_PASSWORD):
return {"statusCode": 400, "body": json.dumps({"error": "Credentials missing"})}
try:
start_time = time.time()
all_article_numbers = []
debug_info = []
# 定義された設定ごとに処理を実行
for config in TARGET_CONFIGS:
kb_id = config['kb_id']
kb_name_log = config['kb_name_log']
root_cat_name = config['root_category_name']
# 1. そのKB内の「有効な(除外されていない)」カテゴリIDリストを取得
valid_cat_ids = get_valid_categories(kb_id, root_cat_name, EXCLUDE_KEYWORDS)
# 2. 記事を取得
articles = get_articles_by_category_ids(kb_id, valid_cat_ids)
all_article_numbers.extend(articles)
debug_info.append({
"kb": kb_name_log,
"kb_id": kb_id,
"root": root_cat_name or "ALL",
"valid_categories_count": len(valid_cat_ids),
"articles_found": len(articles)
})
# 重複排除
unique_articles = sorted(list(set(all_article_numbers)))
elapsed = time.time() - start_time
return {
"statusCode": 200,
"body": json.dumps({
"total_count": len(unique_articles),
"article_numbers": unique_articles,
"details": debug_info,
"execution_time": round(elapsed, 2),
"timestamp": datetime.utcnow().isoformat()
}, ensure_ascii=False)
}
except Exception as e:
print(f"Error: {str(e)}")
return {
"statusCode": 500,
"body": json.dumps({"error": str(e)})
}
# --- ServiceNow API Helper ---
def servicenow_request(path, params=None):
base_url = f"https://{SERVICENOW_INSTANCE}.service-now.com"
query = ("?" + urllib.parse.urlencode(params)) if params else ""
url = f"{base_url}{path}{query}"
credentials = f"{SERVICENOW_USERNAME}:{SERVICENOW_PASSWORD}"
encoded = base64.b64encode(credentials.encode()).decode()
req = urllib.request.Request(url)
req.add_header('Authorization', f'Basic {encoded}')
req.add_header('Accept', 'application/json')
with urllib.request.urlopen(req, timeout=REQUEST_TIMEOUT) as resp:
return json.load(resp).get('result', [])
def get_valid_categories(kb_id, root_category_name, exclude_keywords):
"""
指定KB内の全カテゴリを取得し、以下の条件でフィルタリングしたIDリストを返す
1. root_category_name が指定されている場合、その配下のみ
2. カテゴリ名(label)に除外キーワードが含まれる場合、そのカテゴリと「全子孫」を除外
"""
# 1. KB内の全カテゴリを一括取得
all_cats = []
offset = 0
limit = 10000
while True:
res = servicenow_request('/api/now/table/kb_category', {
'sysparm_query': f"kb_knowledge_base={kb_id}",
'sysparm_fields': 'sys_id,label,parent_id',
'sysparm_limit': limit,
'sysparm_offset': offset
})
all_cats.extend(res)
if len(res) < limit:
break
offset += limit
# 2. データを使いやすい構造に変換
cat_map = {c['sys_id']: c for c in all_cats}
# 親子関係マップ
children_map = {}
for c in all_cats:
pid = c.get('parent_id', {}).get('value') if isinstance(c.get('parent_id'), dict) else c.get('parent_id')
if pid:
if pid not in children_map:
children_map[pid] = []
children_map[pid].append(c['sys_id'])
# 3. ルートカテゴリの特定
start_node_ids = []
if root_category_name:
# 名前でルートを探す(ここも部分一致にするか、正確な名前が必要)
# root_category_name も同様の問題が起きる可能性があるため、念のため strip() して比較
target_name = root_category_name.strip()
found = [c['sys_id'] for c in all_cats if c.get('label', '').strip() == target_name]
if not found:
# 完全一致で見つからない場合、部分一致で救済
found = [c['sys_id'] for c in all_cats if target_name in c.get('label', '')]
if not found:
print(f"Warning: Root category '{root_category_name}' not found in KB {kb_id}.")
return []
start_node_ids = found
else:
# KB全体
pass
# 4. 除外判定ロジック
valid_cache = {}
def is_node_valid(cid):
if cid in valid_cache:
return valid_cache[cid]
if cid not in cat_map:
return True
curr = cat_map[cid]
label = curr.get('label', '')
# A. 自身の名前チェック
for kw in exclude_keywords:
if kw in label:
valid_cache[cid] = False
return False
# B. 親のチェック
pid = curr.get('parent_id', {}).get('value') if isinstance(curr.get('parent_id'), dict) else curr.get('parent_id')
if pid and pid in cat_map:
if not is_node_valid(pid):
valid_cache[cid] = False
return False
valid_cache[cid] = True
return True
# 5. 収集
final_ids = []
if root_category_name:
# 特定ルート配下のみ収集
queue = list(start_node_ids)
visited = set()
while queue:
cid = queue.pop(0)
if cid in visited: continue
visited.add(cid)
if is_node_valid(cid):
final_ids.append(cid)
if cid in children_map:
queue.extend(children_map[cid])
else:
# KB全体から収集
for c in all_cats:
cid = c['sys_id']
if is_node_valid(cid):
final_ids.append(cid)
return final_ids
def get_articles_by_category_ids(kb_id, category_ids):
if not category_ids:
return []
articles = []
for i in range(0, len(category_ids), ARTICLE_CHUNK_SIZE):
chunk = category_ids[i : i + ARTICLE_CHUNK_SIZE]
ids_str = ",".join(chunk)
query = f"kb_knowledge_base={kb_id}^workflow_state=published^kb_categoryIN{ids_str}"
offset = 0
limit = 10000
while True:
res = servicenow_request('/api/now/table/kb_knowledge', {
'sysparm_query': query,
'sysparm_fields': 'number',
'sysparm_limit': limit,
'sysparm_offset': offset
})
if not res:
break
for r in res:
if 'number' in r:
articles.append(r['number'])
# 取得件数がlimit未満なら、もう続きはないのでループを抜ける
if len(res) < limit:
break
# limitいっぱいまで取れた場合は、続きがある可能性が高いのでoffsetを更新
offset += limit
return articles
処理内容は以下の通りです。
- 環境変数から ServiceNow の認証情報を取得し、API リクエストの準備を行います。
TARGET_CONFIGSで定義されたナレッジベースおよびカテゴリを対象に処理を開始します。get_valid_categories関数により、指定されたナレッジベース内のカテゴリ情報を取得し、除外キーワード(「アーカイブ」「Archive」)が含まれるカテゴリとその配下のカテゴリを特定して除外します。get_articles_by_category_ids関数により、有効と判定されたカテゴリIDに紐づく公開済み(published)の記事番号を ServiceNow API 経由で取得します。- 取得した記事番号のリストを重複排除し、結果をJSONとして返します。
以下が実行結果です。
{
"statusCode": 200,
"body": "{\"total_count\": 20220, \"article_numbers\": [\"KB00XXXXX\", \"KB00XXXXX\",
~~中略~~
\"KB00XXXXX\"], \"details\": [{\"kb\": \"KCS Demo KB\", \"kb_id\": \"0aa3ffa7db7c030064dd36cb7c96197f\", \"root\": \"ALL\", \"valid_categories_count\": 721, \"articles_found\": 17190}, {\"kb\": \"cm-hirai\", \"kb_id\": \"203c024fc32032107f159b377d0131bb\", \"root\": \"test\", \"valid_categories_count\": 110, \"articles_found\": 400}], \"execution_time\": 116.31, \"timestamp\": \"2025-12-21T23:51:54.308070\"}"
}
details から、以下の条件で対象記事が抽出できていることが確認できます。
- KCS Demo KB(
root=ALL):カテゴリ 721 件(除外カテゴリを除く)から 17,190 件 の記事を抽出 - cm-hirai(
root=test):カテゴリ 110 件(除外カテゴリを除く)から 400 件 の記事を抽出 - 合計:17,590 件
2. タグ付け処理の実装
対象記事が正しく抽出できていることが確認できたので、Lambda のコードを 実際にタグ付けを行うコード に更新します。
import json
import os
import time
import urllib.request
import urllib.parse
import base64
import boto3
from datetime import datetime
# --- 環境変数 ---
SERVICENOW_INSTANCE = os.environ.get('SERVICENOW_INSTANCE')
SERVICENOW_USERNAME = os.environ.get('SERVICENOW_USERNAME')
SERVICENOW_PASSWORD = os.environ.get('SERVICENOW_PASSWORD')
Q_CONNECT_KB_ID = os.environ.get('Q_CONNECT_KB_ID')
REQUEST_TIMEOUT = int(os.environ.get('REQUEST_TIMEOUT_SECONDS', '60'))
# --- 設定:取得対象の定義 ---
TARGET_CONFIGS = [
{
# KCS Knowledge Base (demo data)
"kb_id": "0aa3ffa7db7c030064dd36cb7c96197f",
"kb_name_log": "KCS Knowledge Base (demo data)",
"root_category_name": None # None = KB配下の全カテゴリ対象
},
{
# cm-hirai
"kb_id": "203c024fc32032107f159b377d0131bb",
"kb_name_log": "cm-hirai",
"root_category_name": "test" # 指定カテゴリ配下のみ対象
}
]
# 除外キーワード(部分一致)
EXCLUDE_KEYWORDS = ["アーカイブ", "Archive"]
# URL長制限(414 URI Too Long)回避のため、チャンクサイズを30に設定
ARTICLE_CHUNK_SIZE = 30
# タグ設定
TAG_KEY = "ServiceNowSync"
TAG_VALUE = "Target"
# APIレート制限対策 (10 TPS制限に対し、安全マージンを見て 0.15秒待機)
# https://docs.aws.amazon.com/ja_jp/connect/latest/adminguide/amazon-connect-service-limits.html#q-in-connect-quotas
SLEEP_INTERVAL = 0.15
# AWS Clients
qconnect_client = boto3.client('qconnect')
def lambda_handler(event, context):
print("Starting sync process...")
# 1. ServiceNowから対象記事番号を取得
print("Fetching articles from ServiceNow...")
all_article_numbers = []
for config in TARGET_CONFIGS:
valid_cat_ids = get_valid_categories(config['kb_id'], config['root_category_name'], EXCLUDE_KEYWORDS)
articles = get_articles_by_category_ids(config['kb_id'], valid_cat_ids)
all_article_numbers.extend(articles)
target_article_set = set(all_article_numbers)
print(f"ServiceNow Target Articles: {len(target_article_set)}")
# 2. Amazon Q in Connect の全コンテンツを取得し、分類する
print("Fetching Amazon Q content list and checking existing tags...")
# 分類結果を格納するリスト
untagged_targets = {} # { 'KBxxxx': 'arn:...' }
skipped_articles = [] # ['KBxxxx', 'KByyyy', ...]
# マッピング処理
paginator = qconnect_client.get_paginator('list_contents')
page_iterator = paginator.paginate(knowledgeBaseId=Q_CONNECT_KB_ID)
for page in page_iterator:
for content in page['contentSummaries']:
# 記事番号の特定
# ServiceNowコネクタの場合、metadata['number'] に記事番号が入ります
key = content.get('metadata', {}).get('number')
# もし metadata にない場合は name をフォールバックとして使用する場合の例:
# if not key: key = content.get('name')
if key and key in target_article_set:
current_tags = content.get('tags', {})
# 既にタグが付いているかチェック
if TAG_KEY in current_tags and current_tags[TAG_KEY] == TAG_VALUE:
skipped_articles.append(key)
else:
untagged_targets[key] = content['contentArn']
# --- ログ出力: スキップされた記事 ---
print(f"--- SKIPPED ARTICLES (Already Tagged: {len(skipped_articles)}) ---")
# 数が多い場合は先頭と末尾だけ表示するなど調整してください。ここでは全件出します。
if skipped_articles:
# ログ量削減のため、先頭10件のみ表示する例
print(json.dumps(sorted(skipped_articles)[:10]) + " ...and more")
else:
print("None")
print("-------------------------------------------------------------")
total_targets = len(untagged_targets)
print(f"Found {total_targets} articles that need tagging.")
if total_targets == 0:
print("All target articles are already tagged correctly.")
return {
"statusCode": 200,
"body": json.dumps({"message": "All articles are already tagged. Nothing to do."})
}
# 3. ループ処理でタグ付け実行
success_count = 0
error_count = 0
tagged_articles_log = [] # 今回タグ付けしたIDを記録
print("Starting tagging loop...")
target_items = list(untagged_targets.items())
for i, (article_num, content_arn) in enumerate(target_items):
# Lambdaの残り時間チェック (残り30秒を切ったら安全に終了)
if context.get_remaining_time_in_millis() < 30000:
print(f"Time limit approaching. Stopping after {success_count} tags.")
print(f"Remaining items: {total_targets - (i + 1)}")
break
try:
qconnect_client.tag_resource(
resourceArn=content_arn,
tags={TAG_KEY: TAG_VALUE}
)
success_count += 1
tagged_articles_log.append(article_num)
if success_count % 100 == 0:
print(f"Progress: {success_count}/{total_targets} tagged.")
time.sleep(SLEEP_INTERVAL)
except Exception as e:
print(f"Error tagging {article_num}: {str(e)}")
error_count += 1
time.sleep(SLEEP_INTERVAL)
# --- ログ出力: 今回タグ付けされた記事 ---
print(f"--- NEWLY TAGGED ARTICLES ({len(tagged_articles_log)}) ---")
if tagged_articles_log:
print(json.dumps(sorted(tagged_articles_log)[:10]) + " ...and more")
else:
print("None")
print("----------------------------------------------------------")
return {
"statusCode": 200,
"body": json.dumps({
"message": "Batch execution finished",
"total_candidates": total_targets,
"processed_count": success_count,
"error_count": error_count,
"remaining_count": total_targets - (success_count + error_count),
"is_completed": (success_count + error_count) == total_targets
})
}
# --- ServiceNow API Helper ---
def servicenow_request(path, params=None):
base_url = f"https://{SERVICENOW_INSTANCE}.service-now.com"
query = ("?" + urllib.parse.urlencode(params)) if params else ""
url = f"{base_url}{path}{query}"
credentials = f"{SERVICENOW_USERNAME}:{SERVICENOW_PASSWORD}"
encoded = base64.b64encode(credentials.encode()).decode()
req = urllib.request.Request(url)
req.add_header('Authorization', f'Basic {encoded}')
req.add_header('Accept', 'application/json')
with urllib.request.urlopen(req, timeout=REQUEST_TIMEOUT) as resp:
return json.load(resp).get('result', [])
def get_valid_categories(kb_id, root_category_name, exclude_keywords):
all_cats = []
offset = 0
limit = 10000
while True:
res = servicenow_request('/api/now/table/kb_category', {
'sysparm_query': f"kb_knowledge_base={kb_id}",
'sysparm_fields': 'sys_id,label,parent_id',
'sysparm_limit': limit,
'sysparm_offset': offset
})
all_cats.extend(res)
if len(res) < limit: break
offset += limit
cat_map = {c['sys_id']: c for c in all_cats}
children_map = {}
for c in all_cats:
pid = c.get('parent_id', {}).get('value') if isinstance(c.get('parent_id'), dict) else c.get('parent_id')
if pid:
if pid not in children_map: children_map[pid] = []
children_map[pid].append(c['sys_id'])
start_node_ids = []
if root_category_name:
target_name = root_category_name.strip()
found = [c['sys_id'] for c in all_cats if target_name in c.get('label', '')]
if not found: return []
start_node_ids = found
valid_cache = {}
def is_node_valid(cid):
if cid in valid_cache: return valid_cache[cid]
if cid not in cat_map: return True
curr = cat_map[cid]
label = curr.get('label', '')
for kw in exclude_keywords:
if kw in label:
valid_cache[cid] = False
return False
pid = curr.get('parent_id', {}).get('value') if isinstance(curr.get('parent_id'), dict) else curr.get('parent_id')
if pid and pid in cat_map:
if not is_node_valid(pid):
valid_cache[cid] = False
return False
valid_cache[cid] = True
return True
final_ids = []
if root_category_name:
queue = list(start_node_ids)
visited = set()
while queue:
cid = queue.pop(0)
if cid in visited: continue
visited.add(cid)
if is_node_valid(cid):
final_ids.append(cid)
if cid in children_map: queue.extend(children_map[cid])
else:
for c in all_cats:
if is_node_valid(c['sys_id']): final_ids.append(c['sys_id'])
return final_ids
def get_articles_by_category_ids(kb_id, category_ids):
if not category_ids: return []
articles = []
for i in range(0, len(category_ids), ARTICLE_CHUNK_SIZE):
chunk = category_ids[i : i + ARTICLE_CHUNK_SIZE]
ids_str = ",".join(chunk)
query = f"kb_knowledge_base={kb_id}^workflow_state=published^kb_categoryIN{ids_str}"
offset = 0
limit = 10000
while True:
res = servicenow_request('/api/now/table/kb_knowledge', {
'sysparm_query': query,
'sysparm_fields': 'number',
'sysparm_limit': limit,
'sysparm_offset': offset
})
if not res: break
for r in res:
if 'number' in r: articles.append(r['number'])
if len(res) < limit: break
offset += limit
return articles
処理内容は以下の通りです。
- 環境変数から ServiceNow の認証情報を取得し、API リクエストの準備を行います。
TARGET_CONFIGSで定義されたナレッジベースおよびカテゴリを対象に処理を開始します。get_valid_categories関数により、指定されたナレッジベース内のカテゴリ情報を取得し、除外キーワード(「アーカイブ」「Archive」)が含まれるカテゴリとその配下のカテゴリを特定して除外します。get_articles_by_category_ids関数により、有効と判定されたカテゴリIDに紐づく公開済み(published)の記事番号を ServiceNow API 経由で取得します。- Amazon Q in Connect の
list_contentsAPI を呼び出し、同期済みコンテンツを取得します。 - ServiceNow の対象記事番号と照合し、タグが付与されていないコンテンツのみを抽出します。
tag_resourceAPI を使用してタグ付けを実行します。この際、Lambda の残り実行時間を確認し、タイムアウトが近づくと処理を中断して次回へ持ち越します。
タグ付けの進め方と再実行について
本実装では、実行のたびに「対象件数の取得 → タグ付け済み判定 → 未処理分のみを処理」という流れで動作するため、途中で処理が中断されても、再実行時に未処理分から再開できます。
- ServiceNow から対象記事を取得(
ServiceNow Target Articles: ...) - Amazon Q in Connect 側のコンテンツ一覧を取得し、既存タグの有無を照合
- タグ付け済みの記事はスキップ(
--- SKIPPED ARTICLES (Already Tagged: ...) ---) - 未タグ付けの記事のみタグ付け(
Found ... articles that need tagging.) - 実行時間が近づいた場合は途中終了し、残りは次回へ持ち越し(
Time limit approaching...)
そのため、Lambda を複数回実行することで、最終的に対象記事すべてをタグ付けできます。完了の目安は、実行ログに Found 0 articles that need tagging. が出力されることです。
タグ付け実行時の Lambda ログの例(メッセージのみ)
初回の実行結果
Starting sync process...
Fetching articles from ServiceNow...
ServiceNow Target Articles: 17590
Fetching Amazon Q content list and checking existing tags...
--- SKIPPED ARTICLES (Already Tagged: 0) ---
-------------------------------------------------------------
Found 17590 articles that need tagging.
Starting tagging loop...
Progress: 100/17590 tagged.
Progress: 200/17590 tagged.
...
Time limit approaching. Stopping after 3142 tags.
Remaining items: 14448
このログから分かることは以下の通りです。
- 対象は 17,590件(
ServiceNow Target Articles) - 実行開始時点でタグ付け済みは 0件(
Already Tagged) - 今回タグ付けが必要(未タグ)な記事は 17,590件(
Found ... need tagging) - 今回の実行でタグ付けできたのは 3,142件(
Stopping after ... tags) - 実行後に未タグとして残ったのは 14,448件(
Remaining items)
複数回実行後(タグ付け済みがスキップされる状態)
Starting sync process...
Fetching articles from ServiceNow...
ServiceNow Target Articles: 17590
Fetching Amazon Q content list and checking existing tags...
--- SKIPPED ARTICLES (Already Tagged: 15745) ---
-------------------------------------------------------------
Found 1845 articles that need tagging.
Starting tagging loop...
Progress: 100/1845 tagged.
...
Time limit approaching. Stopping after 1200 tags.
Remaining items: 645
このログから分かることは以下の通りです。
- 対象は 17,590件
- すでにタグ付け済みとして 15,745件 はスキップ(
Already Tagged) - 今回タグ付けが必要(未タグ)な記事は 1,845件(
Found ... need tagging) - 今回の実行でタグ付けできたのは 1,200件
- 実行後に未タグとして残ったのは 645件
完了(未処理が0になった状態)
Starting sync process...
Fetching articles from ServiceNow...
ServiceNow Target Articles: 17590
Fetching Amazon Q content list and checking existing tags...
--- SKIPPED ARTICLES (Already Tagged: 17590) ---
-------------------------------------------------------------
Found 0 articles that need tagging.
All target articles are already tagged correctly.
このログから分かることは以下の通りです。
- 対象 17,590件 がすべてタグ付け済み扱い(
Already Tagged: 17590) - 未タグは 0件(
Found 0 articles that need tagging.) - 今回の実行で新たに処理するものはなく、タグ付けは完了(
All target articles are already tagged correctly.)
この状態になれば、対象範囲のタグ付けは完了です。
初回は未タグ付けの件数が多く、複数回の実行が必要になる場合があります。いったん全件のタグ付けが完了した後は、EventBridge Scheduler で定期実行(例:1日ごと、1時間ごと)することで、新規に追加・同期される記事に対して自動的にタグ付けが行われます。通常、新規記事数は多くないため、1回の実行で処理が完了する想定です。
まとめ
本記事では、Amazon Q in Connect と ServiceNow の統合環境において、大量のナレッジ記事に対して効率的にタグ付けを行うための Lambda 実装を紹介しました。
これにより、以下のメリットが得られます。
- Step Functions のペイロードサイズ制限を回避し、数万件規模の記事に対応可能
- 実行時間の制限を考慮し、処理を次回に持ち越すことで確実に全件処理が可能
- 除外キーワードによる柔軟な対象範囲の設定が可能
大量のナレッジ管理にお悩みの方の参考になれば幸いです。








